目录
- 1 概念
- 1.1 排序
- 1.2 稳定性
- 2 常见基于比较排序算法总览
- 3 插入排序
- 3.1 直接插入排序
- 3.1.1 思想
- 3.1.2 实现
- 3.1.3 性能分析
- 3.2 折半插入排序
- 3.2.1 思想
- 3.2.2 实现
- 3.2.3 性能分析
- 3.3 希尔排序
- 3.3.1 思想
- 3.3.2 实现
- 3.3.3 性能分析
- 4 选择排序
- 4.1 选择排序
- 4.1.1 思想
- 4.1.2 实现
- 4.1.3 性能分析
- 4.1.4 双向选择排序
- 4.2 堆排序
- 4.2.1 思想
- 4.2.2 实现
- 4.2.3 性能分析
- 5 交换排序
- 5.1 冒泡排序
- 5.1.1 思想
- 5.1.2 实现
- 5.1.3 性能分析
- 5.2 快速排序
- 5.2.1 思想
- 5.2.2 实现
- 5.2.3 性能分析
- 6 归并排序
- 6.1归并排序
- 6.1.1 思想
- 6.1.2 实现
- 6.1.3 性能分析
- 7 海量数据的排序问题
- 8 总结
- 9 其他非基于比较的排序(了解)
1 概念
1.1 排序
排序,就是使一串记录,按照其中的某个或某些关键字的大小,递增或递减的排列起来的操作。
平时的上下文中,如果提到排序,通常指的是排升序(非降序)。
通常意义上的排序,都是指的原地排序(in place sort)。
1.2 稳定性
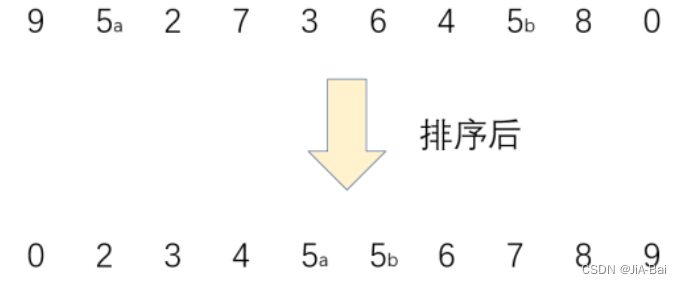
两个相等的数据,如果经过排序后,排序算法能保证其相对位置不发生变化,则我们称该算法是具备稳定性的排序算法。
如果当前这个排序,在排序过程中没有发生跳跃式的交换,那么我们认为这个排序是稳定的排序。所以堆排序不是一个稳定的排序。
- 一个排序如果是稳定的排序,那么它也可以被实现为一个不稳定的排序;
- 但是如果一个排序本身就是不稳定的排序,那么就不可能实现为一个稳定的排序。
如下图所示就是一个稳定的排序:
2 常见基于比较排序算法总览
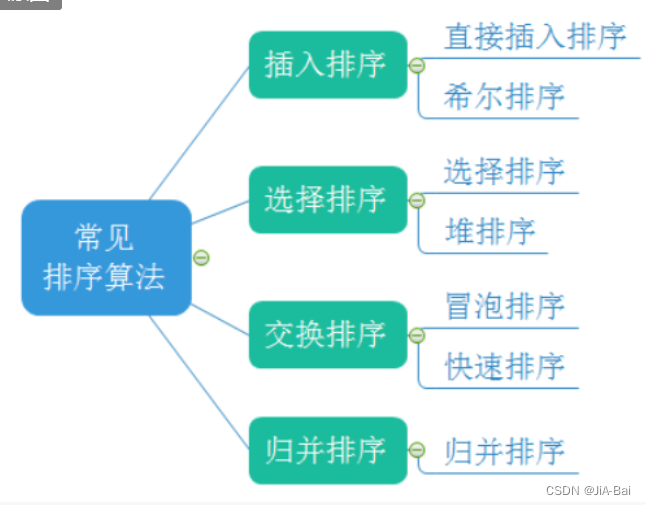
内部排序: 所有的数据都是在内存上的(程序的内存),也就是说这些所要排序的数据要在内存上可以存储。
外部排序: 数据都在磁盘上E F D等。
如下图所示就是常见的排序算法:
3 插入排序
3.1 直接插入排序
3.1.1 思想
直接插入排序是一种最简单的排序方法,它的基本思想就是:把一个数据插入到一个有序的序列中去,从而得到一个新的有序序列。
其基本步骤可以概括为两步:
- 取出一个元素,留出空位;
- 符合条件的元素右移,把取出的元素插入。
那么这样的话,我们就需要一个辅助的变量来临时缓存这个被取出的变量,一般我们把这个辅助变量称之为“哨兵”。
那么给定一组无序的数据, 实现直接插入排序的具体过程是什么样的呢?是否是一个稳定的排序呢?下面我们给定一组数据为{22, 11, 33, 10, 22},对其进行直接插入排序具体过程如下所示:
- 第一趟插入排序:
因为是取出一个元素和前一个元素对比,根据大小关系决定插入到第一个元素的左边或者右边,所以第一趟排序应该从取出第二个元素开始,即i初始值为2。
假设给定一个序列{22, 11, 33, 10, 22},首先取出第二个元素11,用11和22比较,22大于11则22右移一位,然后把11插入到22的位置,即0号下标处。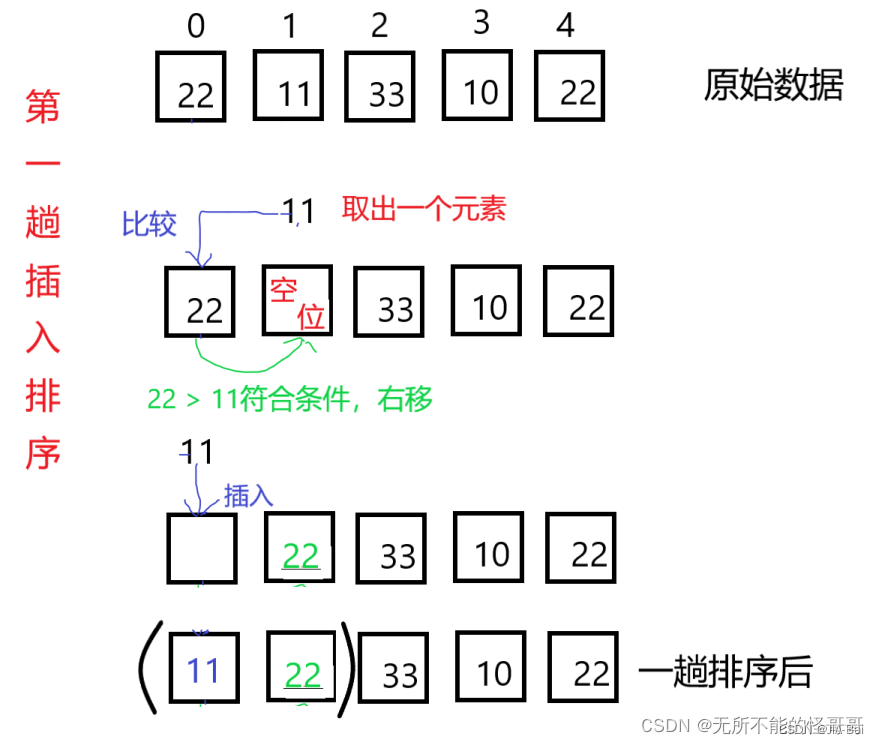 在第一趟排序中,进行了一次比较,一次元素移动。通过第一趟排序形成了一个包含两元素的有序子序列。
在第一趟排序中,进行了一次比较,一次元素移动。通过第一趟排序形成了一个包含两元素的有序子序列。 - 第二趟插入排序:
取出第三个元素,第三个元素array[2]与第二个元素array[1]对比,若:
(1)array[2]>array[1],那么就把array[2]插入到原处,即不进行任何操作,结束本趟插入排序;
(2)如果array[2]<array[1],那么array[1]右移一位,array[2]继续和array[0]比较;如果array[2]>array[0],那么array[2]插入到1号位置,结束本趟插入排序;
(3)如果array[2]<array[0],那么array[0]右移一位,array[2]插入到0号位置。
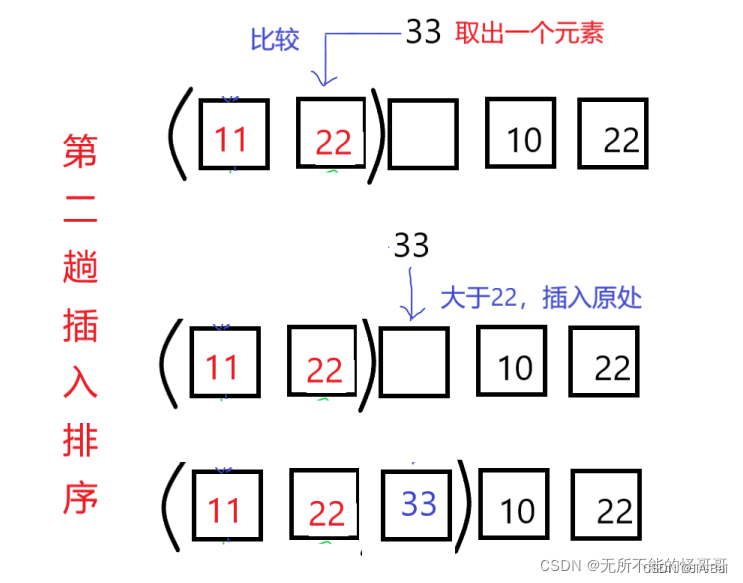
第二趟排序进行了一次比较,0次元素移动(这是最好的情况,即本来子序列就已经从小到大了)。经过第二趟排序,有序子序列加一,这也是插入法之所以称为插入的原因:把一个记录插入到一个有序的序列中。 - 第三趟插入排序:
取出第四个元素,执行比较-移动-插入三部曲操作。
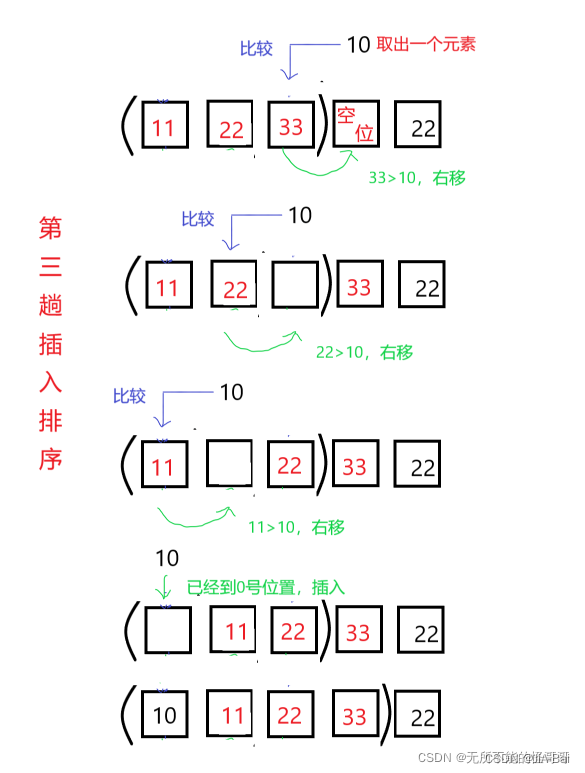
第三趟排序,进行了三次比较,三次移动,这是最坏的情况,即每次比较都要移动。经过第三趟排序,有序序列再次加1,无序序列减一。 - 第n-1趟插入排序:
第n-1趟插入排序,将进行最少1次比较,0次移动;最多n-1次比较,n-1次移动。
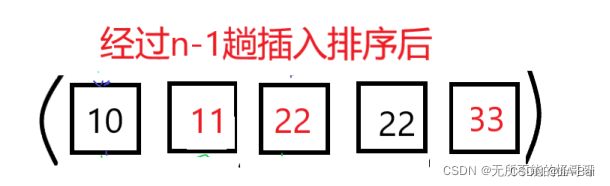
且通过示意图可以看到,红色22本来就在黑色22前面,经过插入排序后,红色22依然在黑色22前面,所以插入排序是稳定排序。
注: 此小节内容摘自博客https://blog.csdn.net/qq_43471489/article/details/125583368,具体可点击链接进入该博客学习。
3.1.2 实现
直接插入排序实现代码如下所示:
import java.util.Arrays;
public class TestSort {
/*
* 时间复杂度:
* 最坏情况下:当数据是无序的情况下是 O(n^2)
* 最好情况下:当数据有序的时候可以达到 O(n)
* 所以:结论:越有序越快。
*
* 题目:
* 1.当前有一组待排序序列,但是这组待排序序列大部分是有序的,请问下面哪个排序更适合?
* 答案:直接插入排序。
* 2. 另外:直接插入排序一般也会用在一些排序的优化上。
* 答案:快速排序
*
* 空间复杂度:
* 稳定性:稳定的排序
* */
public static void insertSort(int[] array){
for (int i = 1; i < array.length; i++) {
int tmp = array[i];
int j = i-1;
for (; j >= 0; j--) {
//如果这里是一个大于等于号,此时这个排序就不稳定了
if(array[j] > tmp){
array[j+1] = array[j];
}else {
break;
}
}
array[j+1] = tmp;
}}
public static void main(String[] args) {
int[] array = {10,3,2,7,19,78,65,127};
System.out.println(Arrays.toString(array));
insertSort(array);
System.out.println(Arrays.toString(array));
}
}
3.1.3 性能分析
| 时间复杂度 | 空间复杂度 | ||
|---|---|---|---|
| 最好 | 平均 | 最坏 | |
| O(n) | O(n^2) | O(n^2) | O(1) |
| 数据有序 | 数据逆序 |
稳定性: 稳定。
特点: 插入排序,初始数据越接近有序,时间效率越高。
3.2 折半插入排序
3.2.1 思想
折半插入排序是将折半查找方法与直接插入排序方法相结合,借助二分查找的思想,先查找插入位置,再移动数据,最后插入到正确的位置。
那么给定一组无序的数据, 实现折半插入排序的具体过程是什么样的呢?下面我们给定一组数据为{6, 1, 3, 5, 4,2},对其进行折半插入排序具体过程如下所示:
- 第一趟排序:
折半插入排序首先把第一个元素直接放到排好序的数组中,第二个元素可以使用直接插入排序法进行排序,从第三个元素开始进行插入排序。

- 第二趟排序:
l =0表示左,h=1表示右,m=(l+h)/2=1表示中间,其位置如下表所示,元素arr[2]=3是待插入元素,首先将其缓存到t。

此时arr[m] < t,因此修改l为m+1=1,之后重新计算m=(l+h)/2=1。

再次比较出现arr[m] > t,因此修改h为m-1=0,出现了h<l的情形,因此结束本趟的排序,记录h的位置(h=0),然后把h+1位置的元素向后移动一位,将t的值插入到arr[h+1]。
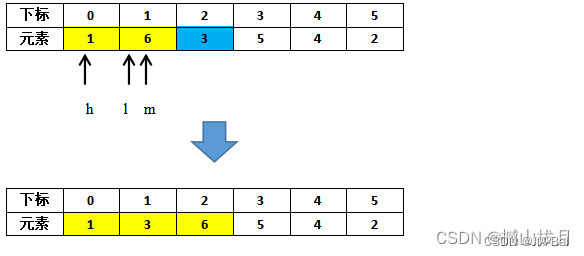
- 第三趟排序:
将元素arr[3]缓存给t,然后重复第二趟排序的方法即可。

- 第四趟排序和第五趟排序,同上述方法一样,经过五趟排序之后,就完成了对该数组的折半插入排序。
我们都知道直接插入排序是一个边比较边移动的过程,而折半插入排序是先确定插入的位置,再来进行移动。插入排序的效率是由比较的次数和移动的次数共同决定的,而折半插入排序就是通过降低比较的次数来提高排序的效率。
在有序区间选择数据应该插入的位置时,因为区间的有序性,可以利用折半查找的思想。
注: 此小节内容摘自博客https://blog.csdn.net/sunnyoldman001/article/details/127032485,具体可点击链接进入该博客学习。
3.2.2 实现
折半插入排序实现代码如下所示:
public static void bsInsertSort(int[] array) {
for (int i = 1; i < array.length; i++) {
int v = array[i];
int left = 0;
int right = i;
// [left, right)
// 需要考虑稳定性
while (left < right) {
int m = (left + right) / 2;
if (v >= array[m]) {
left = m + 1;
} else {
right = m;
}
}
// 搬移
for (int j = i; j > left; j--) {
array[j] = array[j - 1];
}
array[left] = v;
}
}
3.2.3 性能分析
| 时间复杂度 | 空间复杂度 | ||
|---|---|---|---|
| 最好 | 平均 | 最坏 | |
| O(n) | O(n^2) | O(n^2) | O(1) |
| 数据有序 | 数据逆序 |
稳定性: 稳定。
特点: 通过减少元素比较次数使得排序效率得到提高。
3.3 希尔排序
3.3.1 思想
希尔排序法又称缩小增量法。
希尔排序法的基本思想是:先选定一个整数gap,把待排序序列中所有数据分成gap个组,所有距离为(数据总数/gap)的数据分在同一组内,并对每一组内的数据分别进行直接插入排序。然后,取、重复上述分组和排序的工作。当到达gap=1时,所有记录在统一组内排好序。
那么给定一组无序的数据, 实现希尔排序的具体过程是什么样的呢?如下图所示给定了15个数据,进行希尔排序的具体过程为:
- 我们先选定一个整数gap=5,也就是将这组数据分成了5组;
- 所有距离为15/5 = 3的数据分在同一组内(也就是同种颜色线条所指的三个数字为一组,即12,8,7就是第一组;5,27,4为第二组等)。
- 对每一组内的数据分别进行直接插入排序得到一个结果。
- 对于这个结果我们再选定一个整数gap=3,也就是将这组数据分成了3组,所有距离为5的数据分在同一组内,对每一组内的数据分别进行直接插入排序再得到一个结果。
- 对于第四步中得到的这个结果再选定一个整数gap=1,也就是将这组数据分成了1组,对这一组数据进行直接插入排序得到最终排序结果。
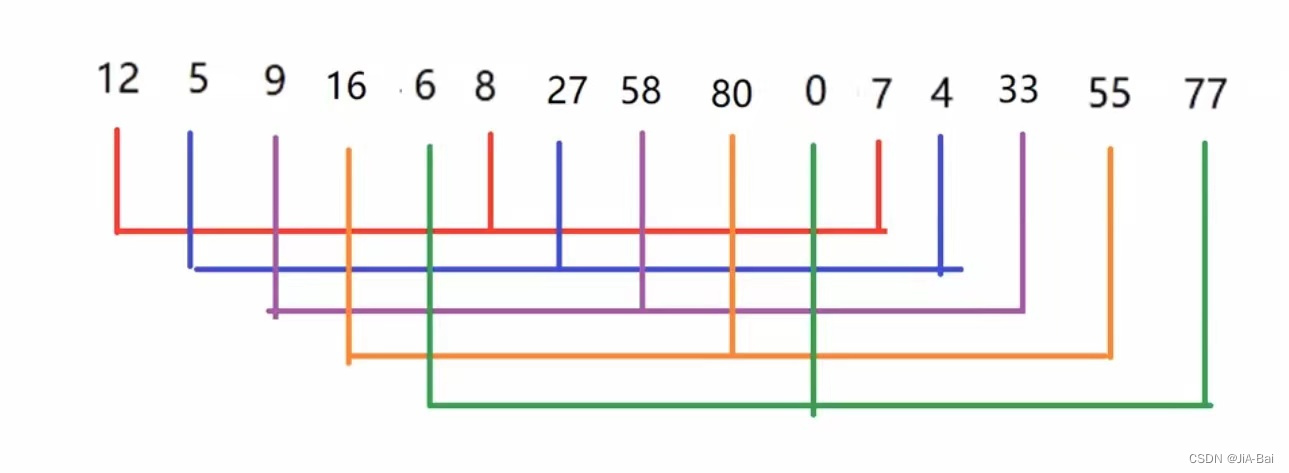
注意: 这里的gap为增量数组,也就是随机设定的这几个数字都必须降序且为素数,且最后一个值一定为1即可。
下图为一个希尔排序的示例:
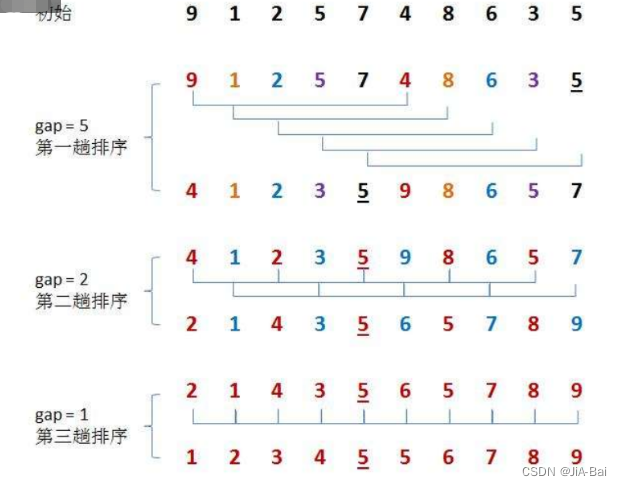
3.3.2 实现
希尔排序实现代码如下所示:
import java.util.Arrays;
public class TestSort {
//这个函数其实就是一个每组的直接插入排序了
public static void shell(int[] array,int gap){
for (int i = gap; i < array.length; i++) {
int tmp = array[i];
int j = i-gap;
for (; j >= 0; j=j-gap) {
//如果这里是一个大于等于号,此时这个排序就不稳定了
if(array[j] > tmp){
array[j+gap] = array[j];
}else {
break;
}
}
array[j+gap] = tmp;
}
}
public static void shellSort(int[] array){
int[] drr = {5,3,1};//增量数组:这几个数字都必须为素数,且最后一个值一定为1即可
for (int i = 0; i < drr.length; i++) {
shell(array,drr[i]);
}
}
public static void main(String[] args) {
int[] array = {10,3,2,7,19,78,65,127};
System.out.println(Arrays.toString(array));
shellSort(array);
System.out.println(Arrays.toString(array));
}
}
3.3.3 性能分析
由于gap取值不唯一,希尔排序的时间复杂度不好计算,因此在希尔排序的时间复杂度不固定,所以下表中的最好和平均时间复杂度均为估算。
| 时间复杂度 | 空间复杂度 | ||
|---|---|---|---|
| 最好 | 平均 | 最坏 | |
| O(n^1.3) | O(n^1.5) | O(n^2) | O(1) |
| 数据有序 | 比较难构造 |
稳定性: 不稳定。
特点:
- 希尔排序是对直接插入排序的优化。
- 当gap > 1时都是预排序,目的是让数组更接近于有序。当gap == 1时,数组已经接近有序的了,这样排序速度就会很快。这样整体而言,可以达到优化的效果。
4 选择排序
4.1 选择排序
4.1.1 思想
每一次从无序区间选出最大(或最小)的一个元素,存放在无序区间的最后(或最前),直到全部待排序的数据元素排完 。即:
- 在待排序的一组数据中,选出最小(最大)的一个数与第一个位置的数交换。
例:如下图所示序列【12,5,9,16,6】,此时i是12,j是5,j比i小,j、i所指的数字互换,得到[5,12,9,16,6];
然后j+1遇到j比i小的情况时,j、i所指的数字就互换,直到j指向最后一个数字结束第一轮选择排序,这里得到的结果还是[5,12,9,16,6]。 - 然后在剩下的数中,再找最小(最大)的数与第二个位置的数交换位置。
例:此时序列变为[5,12,9,16,6],则此时i是12,j是9,j比i小,j、i所指的数字互换,得到[5,9,12,16,6];
然后j+1遇到j比i小的情况时,j、i所指的数字就互换,直到j指向最后一个数字结束第一轮选择排序,这里得到的结果是[5,6,1216,9]。 - 依次类推直到第 n-1 个元素与第 n 个元素交换位置,选择排序结束。

4.1.2 实现
选择排序实现代码如下所示:
import java.util.Arrays;
public class TestSort {
/*
* 选择排序:
* 时间复杂度:O(n^2)
* 空间复杂度:O(1)
* 稳定性:不稳定
* */
public static void selectSort(int[] array){
for (int i = 0; i < array.length-1; i++) {
for (int j = i+1; j <array.length; j++) {
if(array[j] < array[i]){
int tmp = array[j];
array[j] = array[i];
array[i] = tmp;
}
}
}
}
public static void main(String[] args) {
int[] array = {10,3,2,7,19,78,65,127};
System.out.println(Arrays.toString(array));
selectSort(array);
System.out.println(Arrays.toString(array));
}
}
4.1.3 性能分析
| 时间复杂度 | 空间复杂度 |
|---|---|
| O(n^2) | O(1) |
稳定性: 不稳定。
int[] a = { 9, 2, 5a, 7, 4, 3, 6, 5b };
// 交换中该情况无法识别,保证 5a 还在 5b 前边
4.1.4 双向选择排序
思想: 每一次从无序区间选出最小 + 最大的元素,存放在无序区间的最前和最后,直到全部待排序的数据元素排完。
双向选择排序实现代码如下所示:
public static void selectSortOP(int[] array) {
int low = 0;
int high = array.length - 1;
// [low, high] 表示整个无序区间
// 无序区间内只有一个数也可以停止排序了
while (low <= high) {
int min = low;
int max = low;
for (int i = low + 1; i <= max; i++) {
if (array[i] < array[min]) {
min = i;
}
if (array[i] > array[max]) {
max = i;
}
}
swap(array, min, low);
// 见下面例子讲解
if (max == low) {
max = min;
}
swap(array, max, high);
}
}
private void swap(int[] array, int i, int j) {
int t = array[i];
array[i] = array[j];
array[j] = t;
}
理解:
- array = { 9, 5, 2, 7, 3, 6, 8 }; // 交换之前
// low = 0; high = 6
// max = 0; min = 2- array = { 2, 5, 9, 7, 3, 6, 8 }; // 将最小的交换到无序区间的最开始后
// max = 0,但实际上最大的数已经不在 0 位置,而是被交换到 min 即 2 位置了
// 所以需要让 max = min 即 max = 2- array = { 2, 5, 8, 7, 3, 6, 9 }; // 将最大的交换到无序区间的最结尾后
4.2 堆排序
4.2.1 思想
基本原理也是选择排序,只是不在使用遍历的方式查找无序区间的最大的数,而是通过堆来选择无序区间的最大的数。
注意: 排升序要建大堆;排降序要建小堆。
具体思想可借助下图和链接https://blog.csdn.net/weixin_51312723/article/details/134121250进行理解: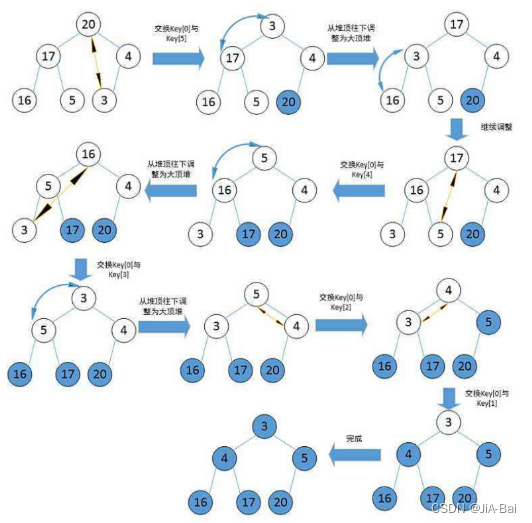
4.2.2 实现
堆排序实现代码在链接https://blog.csdn.net/weixin_51312723/article/details/134121250中的3.7.2节详见。
4.2.3 性能分析
| 时间复杂度 | 空间复杂度 |
|---|---|
| O(nlog2(n)) | O(1) |
稳定性: 不稳定。
5 交换排序
5.1 冒泡排序
5.1.1 思想
在无序区间,通过相邻数的比较,将最大的数冒泡到无序区间的最后,持续这个过程,直到数组整体有序。
- 从第一个下标开始,也就是0,比较第一个和第二个元素,如果第一个元素比第二个元素大,那就交换两者。
然后比较第二个元素和第三个元素,如果两者也不是升序,那交换两者,一直比较和交换,直到最后。 - 之后就是不断迭代上述步骤直到数组整体有序即可。
5.1.2 实现
public static void bubbleSort(int[] array) {
for (int i = 0; i < array.length - 1; i++) {
boolean isSorted = true;
for (int j = 0; j < array.length - i - 1; j++) {
// 相等不交换,保证稳定性
if (array[j] > array[j + 1]) {
swap(array, j, j + 1);
isSorted = false;
}
}
if (isSorted) {
break;
}
}}
5.1.3 性能分析
| 时间复杂度 | 空间复杂度 | ||
|---|---|---|---|
| 最好 | 平均 | 最坏 | |
| O(n) | O(n^2) | O(n^2) | O(1) |
| 数据有序 | 数据逆序 |
稳定性: 稳定。
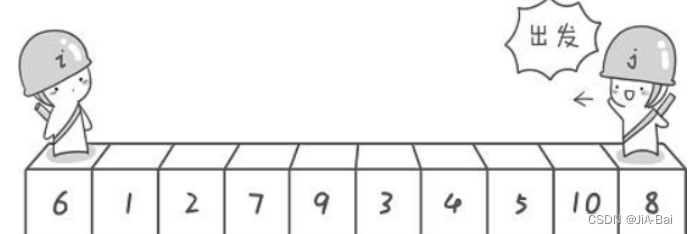
5.2 快速排序
5.2.1 思想
快速排序思想总览:
- 从待排序区间选择一个数,作为基准值(pivot);
- Partition: 遍历整个待排序区间,将比基准值小的(可以包含相等的)放到基准值的左边,将比基准值大的(可以包含相等的)放到基准值的右边;
- 采用分治思想,对左右两个小区间按照同样的方式处理,直到小区间的长度 = 1 ,代表已经有序,或者小区间的长度 = 0,代表没有数据。
选择基准的方法:
- 选择边上(左或者右):例如最简单的选择基准值的方式,选择 array[left] 作为基准值。
- 随机选取基准法:就是随机找到后边的一个下标,然后和low下标的数据进行交换,最后以low下标交换后的值作为基准。
- 几数取中(例如三数取中)法:array[left], array[mid], array[right] 大小是中间的为基准值。
具体通过选择边上(左或者右)法找基准的过程借助下图进行理解:

5.2.2 实现
快速排序实现代码如下所示:
import java.util.Arrays;
public class TestSort {
/*
* 快速排序:
* 时间复杂度:最好:O(n*log2^(n)) 最坏(有序的情况):O(n^2)
* 所以在有序的情况下我们就要优化这个快速排序!---优化方法是:使用三数取中找基准法进行优化
* 空间复杂度:O(log2^(n))
* 稳定性:不稳定
*
* 分治思想:什么时候效率最高?
* 答:每次把待排序序列均匀的划分。
*
* 调JVM的栈参数
*
* 快速排序的递归和非递归 及递归的优化方式
* */
//找基准-选择边上(左或者右)法
//最简单的选择基准值的方式,选择 array[left] 作为基准值
public static int pivot(int[] array,int start,int end){
int tmp = array[start];
while(start < end){
while(start < end && array[end] >= tmp){
end--;
}
array[start] = array[end];
//把数据赋值给start
while(start < end && array[start] <= tmp){
start++;
}
//把start下标的值给end
array[end] = array[start];
}
array[start] = tmp;
return start;
}
//三数取中找基准法
public static void swap(int[] array,int k,int i){
int tmp = array[k];
array[k] = array[i];
array[i] = tmp;
}
public static void medianOfThree(int[] array,int low,int high){
int mid = (low+high)/2;
//array[mid] <= array[low] <= array[high]
if(array[low] < array[mid]){
swap(array,low,mid);
} //array[mid] <= array[low]
if(array[low] > array[high]){
swap(array,low,high);
} // array[low] <= array[high]
if(array[mid] > array[high]){
swap(array,mid,high);
} // array[mid] <= array[high]
}
public static void insertSortBount(int[] array,int low,int high){
for (int i = low+1; i <= high; i++) {
int tmp = array[i];
int j = i-1;
for (; j >= low; j--) {
//如果这里是一个大于等于号,此时这个排序就不稳定了
if(array[j] > tmp){
array[j+1] = array[j];
}else {
break;
}
}
array[j+1] = tmp;
}
}
public static void quick(int[] array,int low,int high){
if(low >= high) return;
//if(high - low +1 <= 50){
//使用插入排序
//insertSortBount(array,low,high);
//return;//记者这里一定要return,这里说明这个区间范围有序了,直接结束
// }
//if(low < high){
medianOfThree(array,low,high);//优化方法代码
//这个之前进行一个优化
int piv = pivot(array,low,high);
quick(array,low,piv-1);
quick(array,piv+1,high);
}
}
//递归
public static void quickSort(int[] array){
long startTime = System.currentTimeMillis();//这里时间的单位是毫秒ms
quick(array,0,array.length-1);
long endTime = System.currentTimeMillis();
System.out.println(endTime- startTime);
}
//非递归
/*
* 和递归是一样的
* 时间复杂度:最好:O(n*log2^(n))
* 空间复杂度:O(n) 最好空间复杂度:log2^(n)
* */
public static void quickSort1(int[] array){
Stack<Integer> stack = new Stack<>();
int low = 0;
int high = array.length-1;
int piv = pivot(array,low,high);
if(piv > low+1){
stack.push(low);
stack.push(piv-1);
}
if(piv < high-1){
stack.push(piv+1);
stack.push(high);
}
while (!stack.empty()) {
high = stack.pop();
low = stack.pop();
piv = pivot(array,low,high);
if(piv > low+1){
stack.push(low);
stack.push(piv-1);
}
if(piv < high-1){
stack.push(piv+1);
stack.push(high);
}
}
}
//测试一下优化后的快速排100000个数据所需的时间
public static void main(String[] args) {
int[] array = new int[1_0000];
Random random = new Random();
for(int i = 0; i < array.length; i++){
//array[i] = i;
array[i] = random.nextInt(1_0000);
}
long startTime = System.currentTimeMillis();
quickSort(array);
long endTime = System.currentTimeMillis();
System.out.println(endTime-startTime);
System.out.println(Arrays.toString(array));
}
public static void main1(String[] args) {
int[] array = {10,3,2,7,19,78,65,127};
System.out.println(Arrays.toString(array));
quickSort(array);
System.out.println(Arrays.toString(array));
}
}
5.2.3 性能分析
| 时间复杂度 | 空间复杂度 | |
|---|---|---|
| 最好 | 最坏 | |
| O(n*log2^(n)) | O(n^2) | O(log2^(n)) |
| 数据有序 |
求递归的时间复杂度: 递归次数每一次遍历次数。
这里的递归次数:log2 ^ n,也就是二叉树的高度;且每一次都要遍历n次;所以此时时间复杂度为 O(nlog2^(n))。
稳定性: 不稳定。
总结:
- 选择基准值很重要,通常使用几数取中法。
- pivot 过程(使得小的数在左,大的数在右)把和基准值相等的数也选择出来。
- 分治处理左右两个小区间,待小区间小于一个阈值时(例如 48),使用直接插入排序对快速排序进行优化。插入排序越有序越快
6 归并排序
6.1归并排序
6.1.1 思想
归并排序(MERGE-SORT)是建立在归并操作上的一种有效的排序算法,该算法是采用分治法(Divide andConquer)的一个非常典型的应用。将已有序的子序列合并,得到完全有序的序列;即先使每个子序列有序,再使子序列段间有序。若将两个有序表合并成一个有序表,称为二路归并。具体过程如下图所示: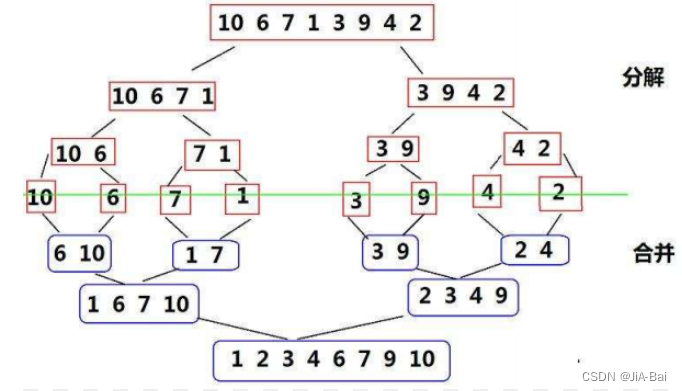
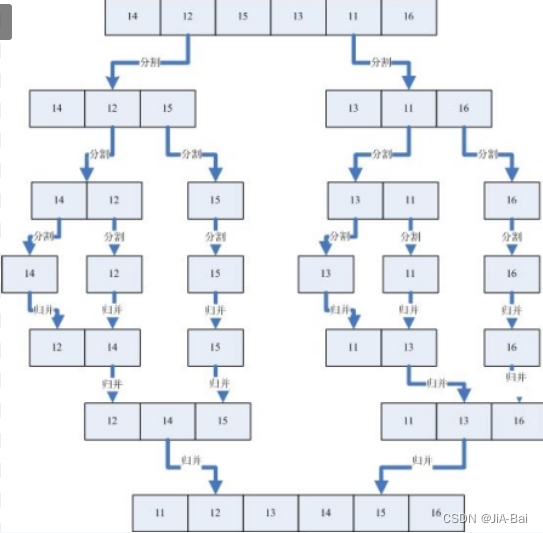
6.1.2 实现
归并排序实现代码如下所示:
import java.util.Arrays;
import java.util.Random;
import java.util.Stack;
public class TestSort {
/*
* 归并排序
* 稳定性:稳定
* 不管好坏时间复杂度都是:O(n*log2^(n))
* 空间复杂度:O(n)
*
* 堆排 归并 不管好坏时间复杂度都是:O(n*log2^(n))
* 快排最坏情况下时间复杂度是O(n^2)
* */
public static void merge(int[] array,int start,int mid,int end){
int s1 = start;
//int e1= mid;
int s2 = mid+1;
//int e2 = end;
int[] tmp = new int[end-start+1];
int k = 0;//tmp数组的下标
while(s1 <= mid && s2 <= end){
if(array[s1] <= array[s2]){
tmp[k++] = array[s1++];
}else{
tmp[k++] = array[s2++];
}
}
//有可能第一个段还有数据 有可能第二个段也有数据
while(s1 <= mid){
tmp[k++] = array[s1++];
}
while(s2 <= end){
tmp[k++] = array[s2++];
}
for (int i = 0; i < tmp.length ; i++) {
array[i+start] = tmp[i];
}
}
public static void mergeSortInternal(int[] array,int low,int high){
if(low >= high) return;
int mid = (low+high)/2;
mergeSortInternal(array,low,mid);
mergeSortInternal(array,mid+1,high);
//合并的操作
merge(array,low,mid,high);
}
//递归
public static void mergeSort(int[] array){
mergeSortInternal(array,0,array.length-1);
}
//非递归
public static void merge1(int[] array,int gap){
int s1 = 0;
int e1 = s1+gap-1;
int s2 = e1+1;
int e2 = s2+gap-1 < array.length ? s2+gap-1:array.length-1;
int[] tmp = new int[array.length];
int k = 0;//下标
//当有两个归并段的时候
while(s2 < array.length) {
//当有两个归并段 且 这两个段内都要有数据
while (s1 <= e1 && s2 <= e2) {
if (array[s1] <= array[s2]) {
tmp[k++] = array[s1++];
} else {
tmp[k++] = array[s2++];
}
}
while (s1 <= e1) {
tmp[k++] = array[s1++];
}
while (s2 <= e2) {
tmp[k++] = array[s2++];
}
s1 = e2 + 1;
e1 = s1 + gap - 1;
s2 = e1 + 1;
e2 = s2 + gap - 1 < array.length ? s2 + gap - 1 : array.length - 1;
}
//退出上面循环后,那么把s1段内的数据给拷贝下来,因为 有可能e1已经越界了
while (s1 <= e1) {
tmp[k++] = array[s1++];
}
for (int i = 0; i < tmp.length; i++) {
array[i] = tmp[i];
}
}
public static void mergeSort2(int[] array){
for (int i = 1; i < array.length; i*=2) {
merge1(array,i);
}
}
public static void main(String[] args) {
int[] array = new int[1_0000];
Random random = new Random();
for(int i = 0; i < array.length; i++){
//array[i] = i;
array[i] = random.nextInt(1_0000);
}
long startTime = System.currentTimeMillis();
mergeSort(array);
long endTime = System.currentTimeMillis();
System.out.println(endTime-startTime);
System.out.println(Arrays.toString(array));
}
}
6.1.3 性能分析
| 时间复杂度 | 空间复杂度 |
|---|---|
| O(nlog2^(n)) | O(n) |
稳定性: 稳定。
优化总结: 在排序过程中重复利用两个数组,减少元素的复制过程。
7 海量数据的排序问题
外部排序: 排序过程需要在磁盘等外部存储进行的排序。
前提: 内存只有 1G,需要排序的数据有 100G
因为内存中因为无法把所有数据全部放下,所以需要外部排序,而归并排序是最常用的外部排序。
- 先把文件切分成 200 份,每个 512 M;
- 分别对 512 M 排序,因为内存已经可以放的下,所以任意排序方式都可以;
- 进行 200 路归并,同时对 200 份有序文件做 归并 过程,最终结果就有序了。
8 总结
| 排序方法 | 最好时间复杂度 | 平均时间复杂度 | 最坏时间复杂度 | 空间复杂度 | 稳定性 | |
|---|---|---|---|---|---|---|
| 交换排序 | 冒泡排序 | O(n) | O(n^2) | O(n^2) | O(1) | 稳定 |
| 插入排序 | 直接插入排序 | O(n) | O(n^2) | O(n^2) | O(1) | 稳定 |
| 插入排序 | 折半插入排序 | O(n) | O(n^2) | O(n^2) | O(1) | 稳定 |
| 选择排序 | 选择排序 | O(n^2) | O(n^2) | O(n^2) | O(1) | 不稳定 |
| 插入排序 | 希尔排序 | O(n) | O(n^1.3) | O(n^2) | O(1) | 不稳定 |
| 选择排序 | 堆排序 | O(nlog2(n)) | O(nlog2(n)) | O(nlog2(n)) | O(1) | 不稳定 |
| 交换排序 | 快速排序 | O(nlog2(n)) | O(nlog2(n)) | O(n^2) | O(log2^(n)) ~ O(n) | 不稳定 |
| 归并排序 | 归并排序 | O(nlog2(n)) | O(nlog2(n)) | O(nlog2(n)) | O(n) | 稳定 |
9 其他非基于比较的排序(了解)
- 计数排序
- 基数排序
- 桶排序