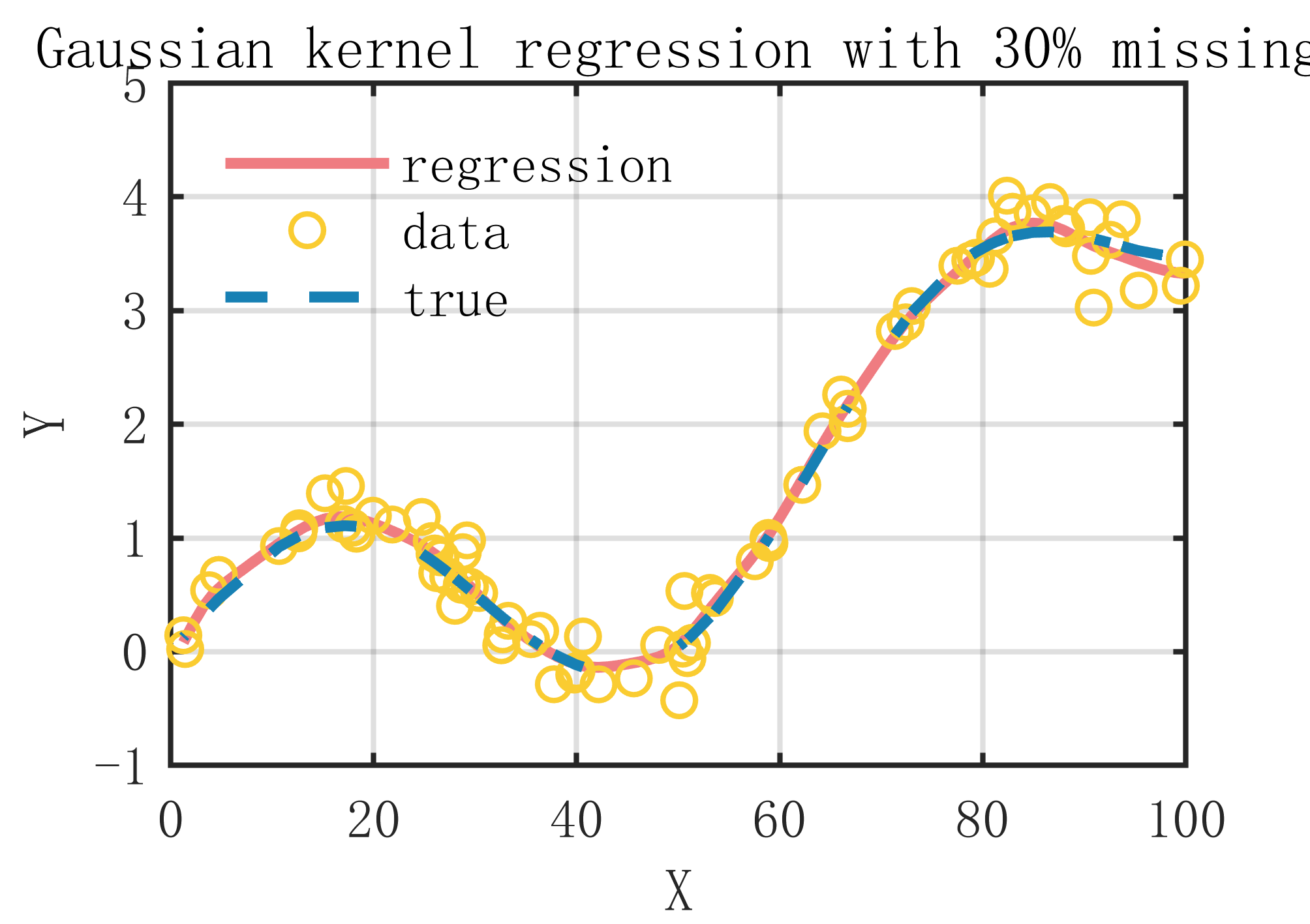
反爬虫机制
- 封IP:监控短时间内同一地址的请求次数过大
- 登录及验证码:对于监控后封IP之后短时间内继续的大量请求,要求登陆或验证码通过验证之后才能继续进行。
- 健全账号体制:即核心数据只能通过账号登录后才能进行访问。
- 动态加载数据:数据通过js进行加载,增加网站分析难度。
- …
反反爬策略
- 伪造请求头(伪装浏览器):故意告诉浏览器我不是爬虫程序我是浏览器。
- 代理IP访问:针对同一时间内大量请求网站数据遭到封IP,使用代理IP不断更换请求地址,迷惑网站,躲过反制措施。
- 请求过于频繁会触发验证码,则模拟用户操作,限制爬虫请求次数及频率,降低验证码机制的风险
- 使用对应的验证码识别手段通过网站验证
- 使用第三方工具完全模拟浏览器操作(selenium+webdriver)
- …
网站为何要反制爬虫
-
保护企业自有数据的安全。
-
保护企业服务器正常稳定运行。
-
版权等其他原因。
常见反爬机制1:代理IP
- 定义及作用
- 定义: 代替你原来的IP地址去对接网络的IP地址
- 作用: 隐藏自身真实IP,避免被封
- 获取代理IP的网站
- 西刺代理、快代理、全网代理、代理精灵、… …
- 代理IP的分类
- 透明代理: 服务端能看到 - (用户真实IP 以及 代理IP)
- 普通代理(匿名代理): - (服务端能知道有人通过此代理IP访问了网站,但不知用户真实IP)
- 高匿代理: - (服务端不能看到代理IP)
- 常用代理IP类型的特点
- 普通代理: 可用率低、速度慢、不稳定、免费或价格便宜
- 私密代理: 可用率高、速度较快、价格适中、爬虫常用
- 独享代理: 可用率极高、速度快、价格贵
普通代理
- 获取代理IP网站
西刺代理、快代理、全网代理、代理精灵、… …
-
参数类型
1、语法结构 proxies = { '协议':'协议://IP:端口号' } 2、示例 proxies = { 'http':'http://IP:端口号', 'https':'https://IP:端口号' } -
示例
使用免费普通代理IP访问测试网站: http://httpbin.org/get
import requests
url = 'http://httpbin.org/get'
headers = {
'User-Agent':'Mozilla/5.0'
}
# 定义代理,在代理IP网站中查找免费代理IP
proxies = {
'http':'http://112.85.164.220:9999',
'https':'https://112.85.164.220:9999'
}
html = requests.get(url,proxies=proxies,headers=headers,timeout=5).text
print(html)
思考: 建立一个自己的代理IP池,随时更新用来抓取网站数据
-
需求:
-
从免费代理IP网站上,抓取免费代理IP
-
测试抓取的IP,可用的保存在文件中
-
私密代理+独享代理
- 语法格式
1、语法结构
proxies = {
'协议':'协议://用户名:密码@IP:端口号'
}
2、示例
proxies = {
'http':'http://用户名:密码@IP:端口号',
'https':'https://用户名:密码@IP:端口号'
}
- 示例代码
import requests
url = 'http://httpbin.org/get'
proxies = {
'http': 'http://用户名:密码@106.75.71.140:16816',
'https':'https://用户名:密码@106.75.71.140:16816',
}
headers = {
'User-Agent' : 'Mozilla/5.0',
}
html = requests.get(url,proxies=proxies,headers=headers,timeout=5).text
print(html)
常见反爬机制2:动态页面爬虫技术
控制台抓包思路
-
静态页面
一种常见的网站、网页类型。我们爬虫所关注的特点是:该类网站的一次html请求的response中包含部分或所有所需的目标数据。
注意:静态网页目前来看存在于:
- 确确实实没什么技术含量的小网站…
- 对安全性关注度不高的某些数据,采用静态页面直接渲染出来。
特点:此类静态页面包含的数据对企业或机构来说无关痛痒,即不是那么的重要,而静态页面直接渲染的方式相对来说对技术要求又不高,成本较低,所以直接渲染出来,你爱爬你就爬无所谓
-
动态网页
一种常见的网站、网页类型。此类网页才是WWW中最常见的网页。基本现在但凡是个规模的网站,大部分都采用了动态页面技术。动态页面不会将数据直接渲染在response中,且不会一次刷新就全部加载完毕,而是伴随用户对页面的操作实现局部刷新。
动态页面的核心特点是:
- 数据不会直接渲染于response中;
- 大部分动态页面都会采用AJAX异步请求进行局部刷新;
- 结合以上特点,对响应的数据进行处理,通常采用js进行加载,且处理过程通常伴随着加密。
所以,动态页面在爬取的过程中难度就增大了,不仅要对响应页面做处理,更重要的是要追踪js加载方式甚至追踪js代码,深层次剖析请求及响应的数据体,进而采用Python进行模拟js操作,实现获取真实数据及破解加密。
-
如何判断一个页面是静态页面还是动态页面?
一般具有以下几个特征的页面,基本就是动态页面了:
- 页面伴随着一些鼠标键盘操作一点点刷新数据的。比如最常见的“加载更多”;
- 在elements中能解析到数据,但进入具体的response中却查找不到数据的;
- 采用AJAX异步加载的。
-
html的response中不存在所需数据怎么办?
如果当前页面的html请求的response中不存在所需数据,但elements选项中能够使用re或xpath解析到我们所需要的数据,则所需数据一定是进行了响应处理,则可以通过控制台抓包分析查找所需数据。
-
控制台抓包分析
- 打开浏览器,F12打开控制台,找到Network选项卡
- 控制台常用选项
- Network: 抓取网络数据包
- ALL: 抓取所有的网络数据包
- XHR:抓取异步加载的网络数据包
- JS : 抓取所有的JS文件
- Sources: 格式化输出并打断点调试JavaScript代码,助于分析爬虫中一些参数
- Console: 交互模式,可对JavaScript中的代码进行测试
- Network: 抓取网络数据包
- 抓取具体网络数据包后
- 单击左侧网络数据包地址,进入数据包详情,查看右侧
- 右侧:
- Headers: 整个请求信息:General、Response Headers、Request Headers、Query String、Form Data
- Preview: 对响应内容进行预览
- Response:响应内容
动态加载页面的数据爬取-AJAX
-
什么是AJAX
AJAX(Asynchronous JavaScript And XML):异步的JavaScript and XML。通过在后台与服务器进行商量的数据交换,Ajax可以使网页实现异步更新,这意味着可以在不重新加载整个网页的情况下,对网页的某部分进行更新。传统的网页(不使用Ajax)如果需要更新内容,必须重载整个网页页面。又因为传统的数据传输格式使用的是XML语法,因此叫做Ajax。但现如今的数据交互方式,基本上都选择使用JSON格式的字符串,其目的就是为了达到数据传输格式的统一。因为json支持几乎所有编程语言。使用Ajax加载的数据,即使有对应的JS脚本,能够将数据渲染到浏览器中,在查看网页源码时还是不能看到通过Ajax加载的数据,只能看到使用这个url加载的HTML代码。
-
什么是JSON
JSON(JavaScript Object Notation, JS对象简谱) 是一种轻量级的数据交换格式。它基于 ECMAScript (欧洲计算机协会制定的js规范)的一个子集,采用完全独立于编程语言的文本格式来存储和表示数据。简洁和清晰的层次结构使得 JSON 成为理想的数据交换语言。 易于人阅读和编写,同时也易于机器解析和生成,并有效地提升网络传输效率。
-
动态页面的数据加载特征
- 几乎统一采用json格式字符串传递;
- 往往伴随着用户对网页的某些操作,比如鼠标事件,键盘事件等;
- 几乎无法直接在html的response中直观看到数据;
-
动态页面数据抓取固定套路
- 请求目标url;
- F12打开控制台进行抓包分析;F12 – network – XHR/JS – 网页操作 – / 查看新增请求项 – 分析数据及规律
- 确定目标数据url/接口
- 发请求,获得response;
- 解析数据(大部分情况下解析的是json数据)
- 持久化存储
总结:常见基本反制爬虫策略(反爬机制)及处理方式
- Headers反爬虫 :Cookie、Referer、User-Agent
- 解决方案: 在浏览器控制台(F12打开)获取请求头(headers)中的对应参数,通过requests库请求该站点时携带这些参数即可
- IP限制 :网站根据IP地址访问频率进行反爬,短时间内限制IP访问
- 解决方案:
- 构造自己IP代理池,每次访问随机选择代理,经常更新代理池
- 购买开放代理或私密代理IP
- 降低爬取的速度
- 解决方案:
- User-Agent限制 :类似于IP限制
- 解决方案: 构造自己的User-Agent池,每次访问随机选择
- 对响应内容做处理
- 解决方案: 打印并查看响应内容,用xpath或正则做处理
- 动态页面技术:采用AJAX异步加载数据包,增加数据获取难度
- 解决方案:借助控制台、fiddler或其他抓包工具抓取XHR数据包,分析其请求URL及参数,最终确定所需数据的获取方式
1. 通过headers字段来反爬
1.1.通过headers中的user-agent字段来反爬
反爬原理:爬虫默认情况下没有user-agent,而是使用模块默认设置
解决方法:请求之前添加user-agent即可,更好的方式是使用user-agent池来解决(收集一堆的user-agent的方式,或者是随机生成user-agent)
import random
def get_ua():
first_num = random.randint(55, 62)
third_num = random.randint(0, 3200)
fourth_num = random.randint(0, 140)
os_type = [
'(Windows NT 6.1; WOW64)', '(Windows NT 10.0; WOW64)', '(X11; Linux x86_64)',
'(Macintosh; Intel Mac OS X 10_12_6)'
]
chrome_version = 'Chrome/{}.0.{}.{}'.format(first_num, third_num, fourth_num)
ua = ' '.join(['Mozilla/5.0', random.choice(os_type), 'AppleWebKit/537.36',
'(KHTML, like Gecko)', chrome_version, 'Safari/537.36']
)
return ua
1.2.通过referer字段或者是其他字段来反爬
反爬原理:爬虫默认情况下不会带上referer字段,服务器通过判断请求发起的源头,以此判断请求是否合法
解决方法:添加referer字段 (表示一个来源,告知服务器用户的来源页面)
1.3.通过cookie来反爬
- 会话(Session)跟踪是Web程序中常用的技术,用来跟踪用户的整个会话。常用的会话跟踪技术是Cookie与Session。Cookie通过在客户端记录信息确定用户身份,Session通过在服务器端记录信息确定用户身份
- session机制:
- 除了使用Cookie,Web应用程序中还经常使用Session来记录客户端状态。Session是服务器端使用的一种记录客户端状态的机制,使用上比Cookie简单一些,相应的也增加了服务器的存储压力
- Session是另一种记录客户状态的机制,不同的是Cookie保存在客户端浏览器中,而Session保存在服务器上。客户端浏览器访问服务器的时候,服务器把客户端信息以某种形式记录在服务器上。这就是Session。客户端浏览器再次访问时只需要从该Session中查找该客户的状态就可以了。
- 如果说Cookie机制是通过检查客户身上的“通行证”来确定客户身份的话,那么Session机制就是通过检查服务器上的“客户明细表”来确认客户身份。Session相当于程序在服务器上建立的一份客户档案,客户来访的时候只需要查询客户档案表就可以了
- **cookie模拟登录适用场景 **: 需要登录验证才能访问的页面
- cookie模拟登录实现的三种方法
# 方法1(利用cookie)
1、先登录成功1次,获取到携带登陆信息的Cookie(处理headers)
2、利用处理的headers向URL地址发请求
# 方法2(利用requests.get()中cookies参数)
1、先登录成功1次,获取到cookie,处理为字典
2、res=requests.get(xxx,cookies=cookies)
# 方法3(利用session会话保持)
1、实例化session对象
session = requests.session()
2、先post : session.post(post_url,data=post_data,headers=headers)
1、登陆,找到POST地址: form -> action对应地址
2、定义字典,创建session实例发送请求
# 字典key :<input>标签中name的值(email,password)
# post_data = {'email':'','password':''}
3、再get : session.get(url,headers=headers)
通过请求参数来反爬
2.1.通过从html静态文件中获取请求数据(github登录数据)
反爬原理:通过增加获取请求参数的难度进行反爬
解决方法:仔细分析抓包得到的每一个包,搞清楚之间的联系

2.2.通过发送请求获取请求数据
反爬原理:通过增加获取请求参数的难度进行反爬
解决方法:仔细分析抓包得到的每一个包,搞清楚之间的联系,搞清楚请求参数的来源
3.通过js生成请求参数(后面的js逆向破解加密)
反爬原理:js生成了请求参数
解决方法:分析js,观察加密实现的过程,通过js2py获取js的执行结果,或者使用selenium来实现
4.通过验证码来反爬
反爬原理:对方服务器通过弹出验证码强制检验用户浏览行为
解决方法:打码平台或者是机器学习的方法识别验证码,其中打码平台廉价易用,更值得推荐

通过css来反爬
反爬原理:源码数据不为真实数据,需要通过css位移才能产生真实数据
解决方法:计算css的偏移
通过js动态生成数据进行反爬
反爬原理:通过js动态生成
解决思路:解析关键js,获得数据生成流程,模拟生成数据
通过编码格式进行反爬
反爬原理:不使用默认编码格式,在获取响应之后,通常爬虫使用utf-8格式进行解码,此时解码结果将会是乱码或者报错
解决思路:根据源码进行多格式解码,获取真正的解码格式