前情回顾
from torch.utils.data import Dataset
import torch.nn as nn
import torch.nn.functional as F
import os
import random
import torch
from nndl import Accuracy
from nndl import RunnerV3
from torch.utils.data import DataLoader
import matplotlib.pyplot as plt
import numpy as np
# 固定随机种子
random.seed(0)
np.random.seed(0)
def generate_data(length, k, save_path):
if length < 3:
raise ValueError("The length of data should be greater than 2.")
if k == 0:
raise ValueError("k should be greater than 0.")
# 生成100条长度为length的数字序列,除前两个字符外,序列其余数字暂用0填充
base_examples = []
for n1 in range(0, 10):
for n2 in range(0, 10):
seq = [n1, n2] + [0] * (length - 2)
label = n1 + n2
base_examples.append((seq, label))
examples = []
# 数据增强:对base_examples中的每条数据,默认生成k条数据,放入examples
for base_example in base_examples:
for _ in range(k):
# 随机生成替换的元素位置和元素
idx = np.random.randint(2, length)
val = np.random.randint(0, 10)
# 对序列中的对应零元素进行替换
seq = base_example[0].copy()
label = base_example[1]
seq[idx] = val
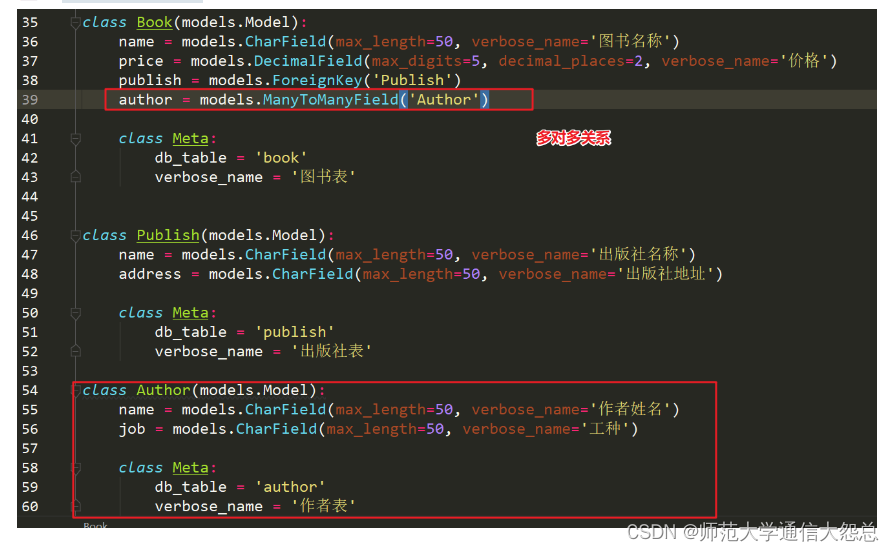
examples.append((seq, label))
# 保存增强后的数据
with open(save_path, "w", encoding="utf-8") as f:
for example in examples:
# 将数据转为字符串类型,方便保存
seq = [str(e) for e in example[0]]
label = str(example[1])
line = " ".join(seq) + "\t" + label + "\n"
f.write(line)
print(f"generate data to: {save_path}.")
# 定义生成的数字序列长度
lengths = [5, 10, 15, 20, 25, 30, 35]
for length in lengths:
# 生成长度为length的训练数据
save_path = f"./datasets/{length}/train.txt"
k = 3
generate_data(length, k, save_path)
# 生成长度为length的验证数据
save_path = f"./datasets/{length}/dev.txt"
k = 1
generate_data(length, k, save_path)
# 生成长度为length的测试数据
save_path = f"./datasets/{length}/test.txt"
k = 1
generate_data(length, k, save_path)
# 加载数据
def load_data(data_path):
# 加载训练集
train_examples = []
train_path = os.path.join(data_path, "train.txt")
with open(train_path, "r", encoding="utf-8") as f:
for line in f.readlines():
# 解析一行数据,将其处理为数字序列seq和标签label
items = line.strip().split("\t")
seq = [int(i) for i in items[0].split(" ")]
label = int(items[1])
train_examples.append((seq, label))
# 加载验证集
dev_examples = []
dev_path = os.path.join(data_path, "dev.txt")
with open(dev_path, "r", encoding="utf-8") as f:
for line in f.readlines():
# 解析一行数据,将其处理为数字序列seq和标签label
items = line.strip().split("\t")
seq = [int(i) for i in items[0].split(" ")]
label = int(items[1])
dev_examples.append((seq, label))
# 加载测试集
test_examples = []
test_path = os.path.join(data_path, "test.txt")
with open(test_path, "r", encoding="utf-8") as f:
for line in f.readlines():
# 解析一行数据,将其处理为数字序列seq和标签label
items = line.strip().split("\t")
seq = [int(i) for i in items[0].split(" ")]
label = int(items[1])
test_examples.append((seq, label))
return train_examples, dev_examples, test_examples
class DigitSumDataset(Dataset):
def __init__(self, data):
self.data = data
def __getitem__(self, idx):
example = self.data[idx]
seq = torch.tensor(example[0], dtype=torch.int64)
label = torch.tensor(example[1], dtype=torch.int64)
return seq, label
def __len__(self):
return len(self.data)
class Embedding(nn.Module):
def __init__(self, num_embeddings, embedding_dim):
super(Embedding, self).__init__()
self.W = nn.init.xavier_uniform_(torch.empty(num_embeddings, embedding_dim), gain=1.0)
def forward(self, inputs):
# 根据索引获取对应词向量
embs = self.W[inputs]
return embs
torch.manual_seed(0)
# SRN模型
class SRN(nn.Module):
def __init__(self, input_size, hidden_size, W_attr=None, U_attr=None, b_attr=None):
super(SRN, self).__init__()
# 嵌入向量的维度
self.input_size = input_size
# 隐状态的维度
self.hidden_size = hidden_size
# 定义模型参数W,其shape为 input_size x hidden_size
if W_attr == None:
W = torch.zeros(size=[input_size, hidden_size], dtype=torch.float32)
else:
W = torch.tensor(W_attr, dtype=torch.float32)
self.W = torch.nn.Parameter(W)
# 定义模型参数U,其shape为hidden_size x hidden_size
if U_attr == None:
U = torch.zeros(size=[hidden_size, hidden_size], dtype=torch.float32)
else:
U = torch.tensor(U_attr, dtype=torch.float32)
self.U = torch.nn.Parameter(U)
# 定义模型参数b,其shape为 1 x hidden_size
if b_attr == None:
b = torch.zeros(size=[1, hidden_size], dtype=torch.float32)
else:
b = torch.tensor(b_attr, dtype=torch.float32)
self.b = torch.nn.Parameter(b)
# 初始化向量
def init_state(self, batch_size):
hidden_state = torch.zeros(size=[batch_size, self.hidden_size], dtype=torch.float32)
return hidden_state
# 定义前向计算
def forward(self, inputs, hidden_state=None):
# inputs: 输入数据, 其shape为batch_size x seq_len x input_size
batch_size, seq_len, input_size = inputs.shape
# 初始化起始状态的隐向量, 其shape为 batch_size x hidden_size
if hidden_state is None:
hidden_state = self.init_state(batch_size)
# 循环执行RNN计算
for step in range(seq_len):
# 获取当前时刻的输入数据step_input, 其shape为 batch_size x input_size
step_input = inputs[:, step, :]
# 获取当前时刻的隐状态向量hidden_state, 其shape为 batch_size x hidden_size
hidden_state = F.tanh(torch.matmul(step_input, self.W) + torch.matmul(hidden_state, self.U) + self.b)
return hidden_state
# 基于RNN实现数字预测的模型
class Model_RNN4SeqClass(nn.Module):
def __init__(self, model, num_digits, input_size, hidden_size, num_classes):
super(Model_RNN4SeqClass, self).__init__()
# 传入实例化的RNN层,例如SRN
self.rnn_model = model
# 词典大小
self.num_digits = num_digits
# 嵌入向量的维度
self.input_size = input_size
# 定义Embedding层
self.embedding = Embedding(num_digits, input_size)
# 定义线性层
self.linear = nn.Linear(hidden_size, num_classes)
def forward(self, inputs):
# 将数字序列映射为相应向量
inputs_emb = self.embedding(inputs)
# 调用RNN模型
hidden_state = self.rnn_model(inputs_emb)
# 使用最后一个时刻的状态进行数字预测
logits = self.linear(hidden_state)
return logits- generate_data生成数据集
- load_data加载数据集
- DigitSumDataset类:读取数据并转化为张量
- Embedding类:转换数据格式为向量
- SRN类:手写SRN层
- Model_RNN4SeqClass:模型汇总
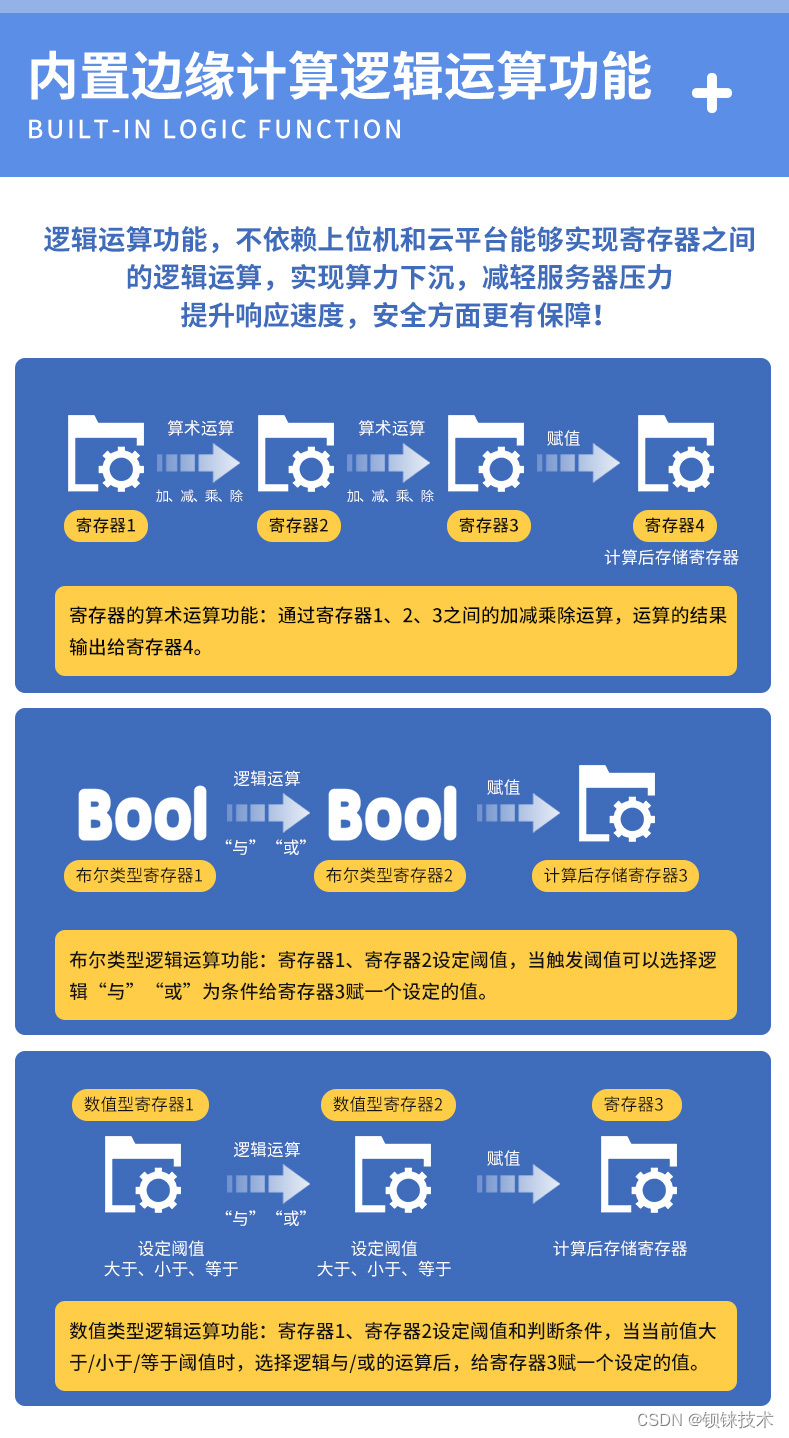
造成简单循环网络较难建模长程依赖问题的原因有两个:梯度爆炸和梯度消失。一般来讲,循环网络的梯度爆炸问题比较容易解决,一般通过权重衰减或梯度截断可以较好地来避免;对于梯度消失问题,更加有效的方式是改变模型,比如通过长短期记忆网络LSTM来进行缓解。
本节将首先进行复现简单循环网络中的梯度爆炸问题,然后尝试使用梯度截断的方式进行解决。这里采用长度为20的数据集进行实验,训练过程中将进行输出的梯度向量的范数,以此来衡量梯度的变化情况。
1 梯度打印函数
使用custom_print_log实现了在训练过程中打印梯度的功能,custom_print_log需要接收runner的实例,并通过model.named_parameters()获取该模型中的参数名和参数值. 这里我们分别定义W_list, U_list和b_list,用于分别存储训练过程中参数的梯度范数。代码如下:
W_list = []
U_list = []
b_list = []
# 计算梯度范数
def custom_print_log(runner):
model = runner.model
W_grad_l2, U_grad_l2, b_grad_l2 = 0, 0, 0
for name, param in model.named_parameters():
if name == "rnn_model.W":
W_grad_l2 = torch.norm(param.grad, p=2).numpy()
if name == "rnn_model.U":
U_grad_l2 = torch.norm(param.grad, p=2).numpy()
if name == "rnn_model.b":
b_grad_l2 = torch.norm(param.grad, p=2).numpy()
print(f"[Training] W_grad_l2: {W_grad_l2:.5f}, U_grad_l2: {U_grad_l2:.5f}, b_grad_l2: {b_grad_l2:.5f} ")
W_list.append(W_grad_l2)
U_list.append(U_grad_l2)
b_list.append(b_grad_l2)2 复现梯度爆炸现象
为了更好地复现梯度爆炸问题,使用SGD优化器将批大小和学习率调大,学习率为0.2,同时在计算交叉熵损失时,将reduction设置为sum,表示将损失进行累加。
np.random.seed(0)
random.seed(0)
torch.seed()
# 训练轮次
num_epochs = 50
# 学习率
lr = 0.2
# 输入数字的类别数
num_digits = 10
# 将数字映射为向量的维度
input_size = 32
# 隐状态向量的维度
hidden_size = 32
# 预测数字的类别数
num_classes = 19
# 批大小
batch_size = 64
# 模型保存目录
save_dir = "./checkpoints"
# 可以设置不同的length进行不同长度数据的预测实验
length = 20
print(f"\n====> Training SRN with data of length {length}.")
# 加载长度为length的数据
data_path = f"./datasets/{length}"
train_examples, dev_examples, test_examples = load_data(data_path)
train_set, dev_set, test_set = DigitSumDataset(train_examples), DigitSumDataset(dev_examples),DigitSumDataset(test_examples)
train_loader = DataLoader(train_set, batch_size=batch_size)
dev_loader = DataLoader(dev_set, batch_size=batch_size)
test_loader = DataLoader(test_set, batch_size=batch_size)
# 实例化模型
base_model = SRN(input_size, hidden_size)
model = Model_RNN4SeqClass(base_model, num_digits, input_size, hidden_size, num_classes)
# 指定优化器
optimizer = torch.optim.SGD(lr=lr, params=model.parameters())
# 定义评价指标
metric = Accuracy()
# 定义损失函数
loss_fn = nn.CrossEntropyLoss(reduction="sum")
# 基于以上组件,实例化Runner
runner = RunnerV3(model, optimizer, loss_fn, metric)
# 进行模型训练
model_save_path = os.path.join(save_dir, f"srn_explosion_model_{length}.pdparams")
runner.train(train_loader, dev_loader, num_epochs=num_epochs, eval_steps=100, log_steps=1,
save_path=model_save_path, custom_print_log=custom_print_log) 接下来,可以获取训练过程中关于,
和
参数梯度的L2范数,并将其绘制为图片以便展示,相应代码如下:
def plot_grad(W_list, U_list, b_list, save_path, keep_steps=40):
# 开始绘制图片
plt.figure()
# 默认保留前40步的结果
steps = list(range(keep_steps))
plt.plot(steps, W_list[:keep_steps], "r-", color="#e4007f", label="W_grad_l2")
plt.plot(steps, U_list[:keep_steps], "-.", color="#f19ec2", label="U_grad_l2")
plt.plot(steps, b_list[:keep_steps], "--", color="#000000", label="b_grad_l2")
plt.xlabel("step")
plt.ylabel("L2 Norm")
plt.legend(loc="upper right")
plt.show()
plt.savefig(save_path)
print("image has been saved to: ", save_path)
save_path = f"./images/6.8.pdf"
plot_grad(W_list, U_list, b_list, save_path) 展示了在训练过程中关于,
和
参数梯度的L2范数,可以看到经过学习率等方式的调整,梯度范数急剧变大,而后梯度范数几乎为0. 这是因为
为
型函数,其饱和区的导数接近于0,由于梯度的急剧变化,参数数值变的较大或较小,容易落入梯度饱和区,导致梯度为0,模型很难继续训练.

我们发现梯度在epoch为1的时候就已经收敛为0了,收敛速度很快
梯度变化图像如下:

接下来,使用该模型在测试集上进行测试。
print(f"Evaluate SRN with data length {length}.")
# 加载训练过程中效果最好的模型
model_path = os.path.join(save_dir, f"srn_explosion_model_{length}.pdparams")
runner.load_model(model_path)
# 使用测试集评价模型,获取测试集上的预测准确率
score, _ = runner.evaluate(test_loader)
print(f"[SRN] length:{length}, Score: {score: .5f}")结果如下:

3 使用梯度截断解决梯度爆炸问题
梯度截断是一种可以有效解决梯度爆炸问题的启发式方法,当梯度的模大于一定阈值时,就将它截断成为一个较小的数。一般有两种截断方式:按值截断和按模截断.本实验使用按模截断的方式解决梯度爆炸问题。
按模截断是按照梯度向量的模进行截断,保证梯度向量的模值不大于阈值
,裁剪后的梯度为:
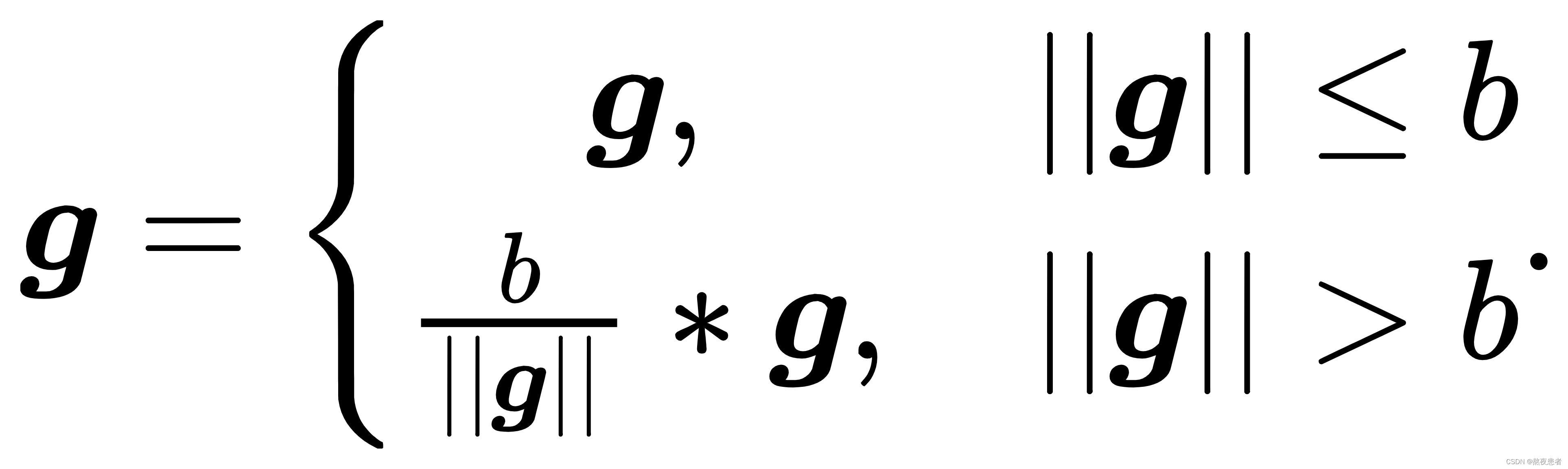
当梯度向量的模不大于阈值
时,
数值不变,否则对
进行数值缩放。
在引入梯度截断之后,将重新观察模型的训练情况。这里我们重新实例化一下:模型和优化器,然后组装runner,进行训练。代码实现如下:
# 清空梯度列表
W_list.clear()
U_list.clear()
b_list.clear()
# 实例化模型
base_model = SRN(input_size, hidden_size)
model = Model_RNN4SeqClass(base_model, num_digits, input_size, hidden_size, num_classes)
# 定义clip,并实例化优化器
optimizer = torch.optim.SGD(lr=lr, params=model.parameters())
# 定义评价指标
metric = Accuracy()
# 定义损失函数
loss_fn = nn.CrossEntropyLoss(reduction="sum")
# 实例化Runner
runner = RunnerV3(model, optimizer, loss_fn, metric)
# 训练模型
model_save_path = os.path.join(save_dir, f"srn_fix_explosion_model_{length}.pdparams")
runner.train(train_loader, dev_loader, num_epochs=num_epochs, eval_steps=100, log_steps=1, save_path=model_save_path, custom_print_log=custom_print_log)在引入梯度截断后,获取训练过程中关于,
和
参数梯度的L2范数,并将其绘制为图片以便展示,相应代码如下:
save_path = f"./images/6.9.pdf"
plot_grad(W_list, U_list, b_list, save_path, keep_steps=100)展示了引入按模截断的策略之后,模型训练时参数梯度的变化情况。可以看到,随着迭代步骤的进行,梯度始终保持在一个有值的状态,表明按模截断能够很好地解决梯度爆炸的问题.

接下来,使用梯度截断策略的模型在测试集上进行测试。
print(f"Evaluate SRN with data length {length}.")
# 加载训练过程中效果最好的模型
model_path = os.path.join(save_dir, "srn_explosion_model_20.pdparams")
runner.load_model(model_path)
# 使用测试集评价模型,获取测试集上的预测准确率
score, _ = runner.evaluate(test_loader)
print(f"[SRN] length:{length}, Score: {score: .5f}")
由于为复现梯度爆炸现象,改变了学习率,优化器等,因此准确率相对比较低。但由于采用梯度截断策略后,在后续训练过程中,模型参数能够被更新优化,因此准确率有一定的提升。