目录
- 前言
- 一、源码优化
- 1、vue3.x 采用 monorep 的理念来管理源码
- 2、vue3.x 源码采用 TypeScript 开发
- 二、性能优化
- 1、减少源码的体积
- 2、数据劫持优化
- 3、编译优化
- (1)、编译粒度的优化
- 三、语法 API 的优化
- 1、优化了编码的逻辑组织
- 2、优化了代码的逻辑复用
前言

一、源码优化
1、vue3.x 采用 monorep 的理念来管理源码
截止2023年年底,最新的 vue2.x 源码 和 vue3.x 源码 的核心部分,项目结构的“管理方式”对比:

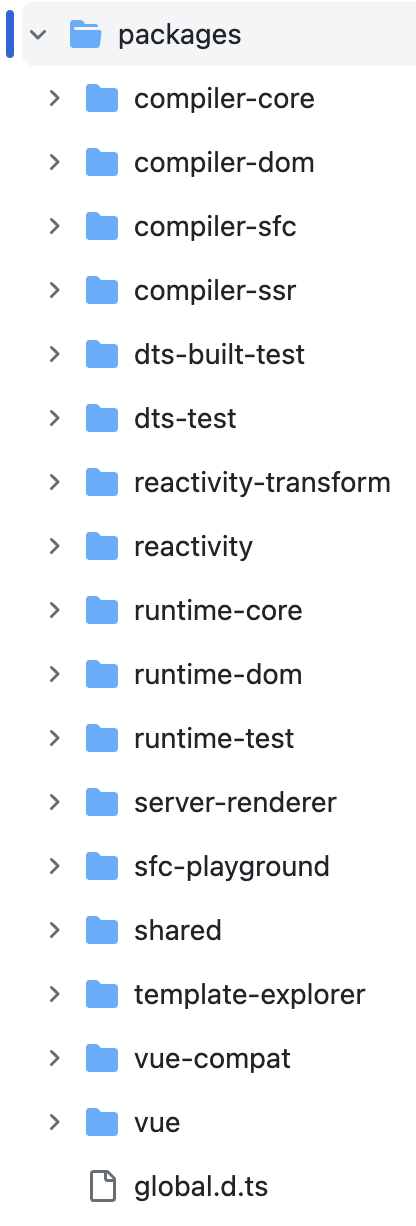
(左边是 vue2.x 源码目录)(右边是 vue3.x 源码目录)
可见:
- vue2.x 的源码托管在 src 目录下,依据功能拆分成了不同的模块;vue3.x 的源码主要是使用 monorep 的理念来开发和维护的——根据功能将不同的模块拆分到 packages 目录下面。这种变化,具有以下优点:
- 每个 package 有各自的 API、类型定义 和 测试,这使得模块拆分更细化、职责更明确、依赖关系更明确,更易于开发者使用,从而提升了自身代码的可维护性。
- 部分 package(比如:reactive 响应式库)可以独立于 vue.js 使用,减小了引用包的体积大小。
2、vue3.x 源码采用 TypeScript 开发
vue3.x 源码全面采用 TypeScript 开发,在编码期间 TS 会自动做类型检查,避免一些类型错误导致的问题。
vue2.x 源码一开始是用 javascript 开发的,类型检查是用 Flow.js 实现的。在 vue3.0 推出以后,用 TypeScript 重构过了。
二、性能优化
1、减少源码的体积
移除了一些冷门的 feature。比如:Filters(过滤器)、inline-template等(https://blog.csdn.net/m0_62018311/article/details/131011249)
引入 tree-shaking 的技术,减少打包的体积——依赖于ES2015(ES6)的import和export模块语法,通过编译阶段的静态分析,找到没有引入的模块并打上标记,在打包时将这些被标记的模块忽略掉。这样也就间接达到了减少项目引入的 Vue.js 包体积的目的。
2、数据劫持优化
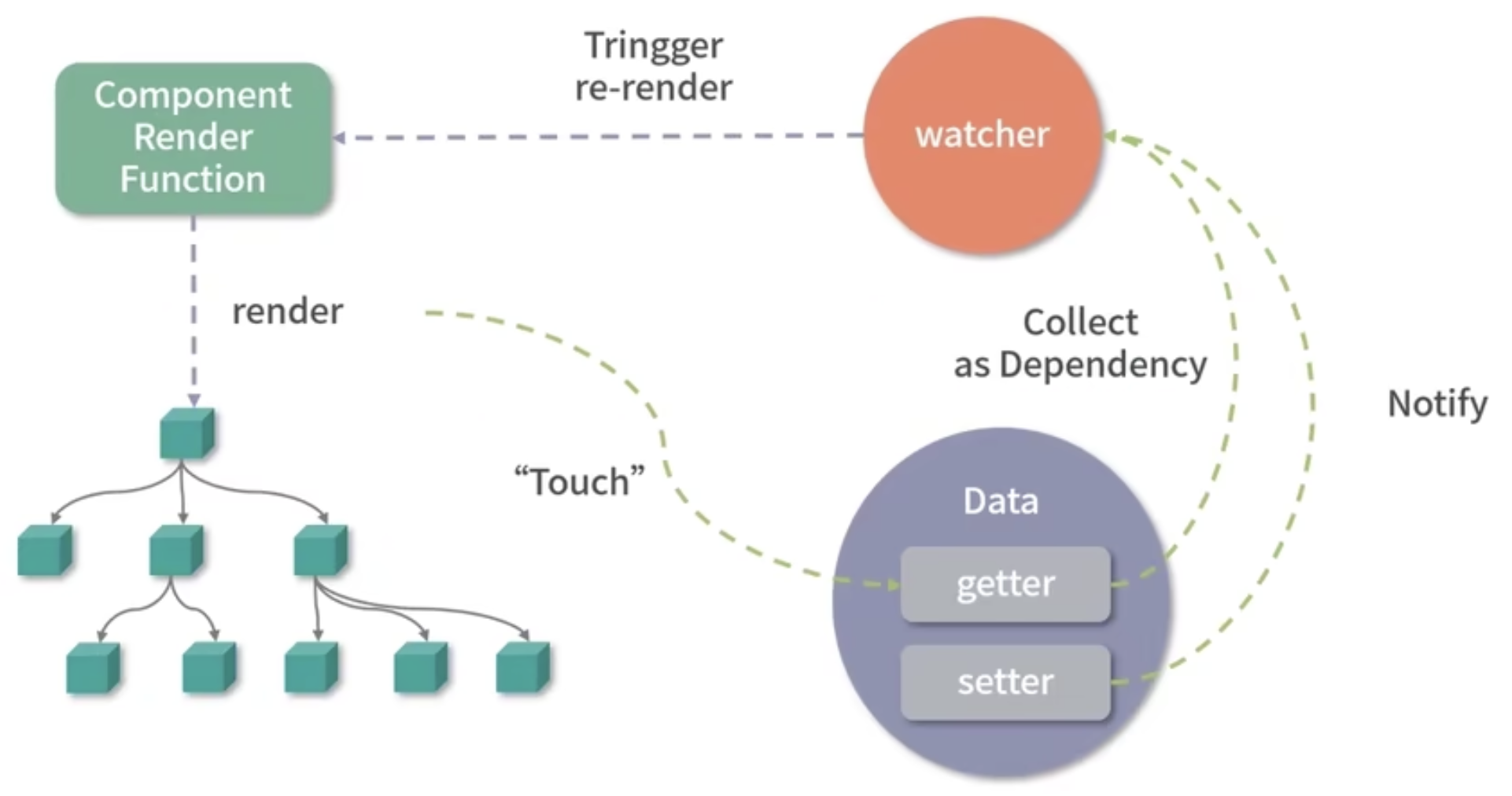
vue 的一大特色是它的数据是响应式的——DOM是数据的映射,数据变化后可以自动更新DOM。
实现“数据响应式”,必须劫持数据的访问和更新。
那么vue怎么知道更新哪一片DOM呢?
在渲染DOM的时候访问了数据,我们可以对它进行访问劫持,这样就在内部建立的依赖关系,也就知道对应的DOM是什么了。实际的实现要比这更复杂,内部依赖了一个watcher结构来管理这些依赖:
vue2.x 通过 Object.defineProperty 这个API劫持数据的getter和setter:
Object.defineProperty(data, 'a', {
get() {},
set(){}
})
但这个API有些缺陷:
- 它必须先知道要拦截的key是什么,所以它并不能检测对象属性的添加和删除。vue2.x 为了解决这个问题增加了 $set 和 $delete 的实例方法,这无疑给使用者增加了额外的心智负担。
- 如果我们定义的数据过于复杂,就会有相当大的性能负担。这是因为:vue 无法判断你在运行时到底要访问哪个属性,所以对于一个嵌套层级较深的对象,如果要劫持到它内部深层次的对象的变化,就需要递归便利这个对象,执行 Object.defineProperty 把每一层对象都变成响应式的对象的。
为了解决上述两个问题,vue3.x 采用了 Proxy API来做数据劫持:
const observed = new Proxy(data, {
get() {},
set(){}
})
由于它劫持的是整个对象,所以自然对整个对象的删除和增加都能检测到。
但是,Proxy API并不能监听到内部深层次的对象的变化。因此,vue3.x 采用了在 getter 中去递归响应式。这样的好处是,真正访问到的内部对象才会变成响应式,而不是无脑递归。这无疑大大提升了性能。
3、编译优化
下图是 vue2.x 从创建 vue 实例开始到渲染成 DOM 的过程:
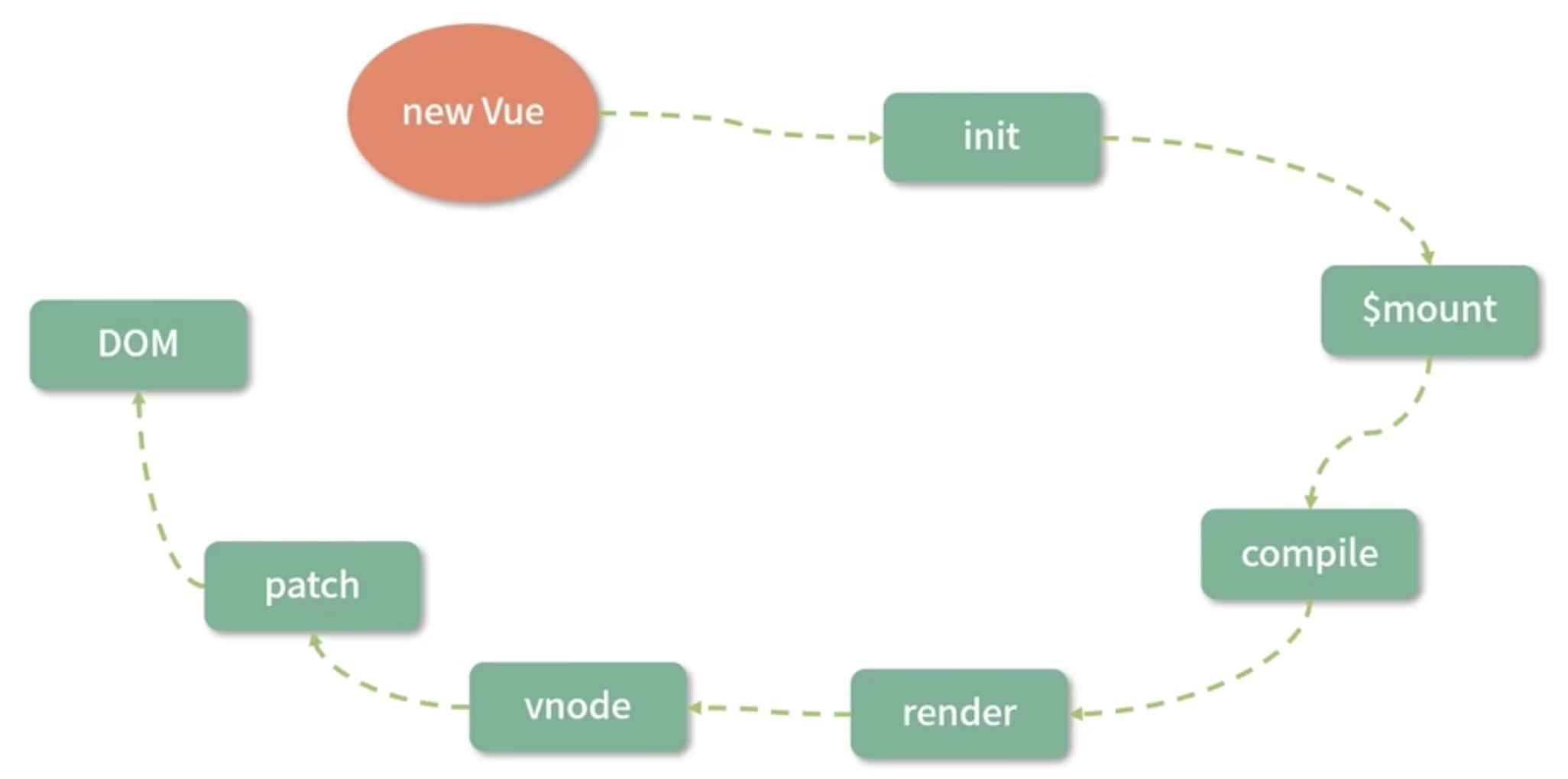
上面说过的响应式就是发生在图中的 init 阶段。
另外,“template compiled to render function” 的流程可以借助 view-loader 在 webpack 编译阶段离线完成,并非一定要在运行时完成。所以想要优化整个vue.js的运行时,除了数据部分的优化,还可以在耗时较多的patch阶段想办法。于是,vue3.x 在编译阶段优化了编译的结果,来实现了运行时 patch 阶段的优化。
(1)、编译粒度的优化
vue2.x 的数据更新并触发重新渲染的粒度是组件级的:

虽然,vue2.x 能保证触发更新的组件最小化,但是单个组件内部依然需要遍历该组件的整个 v-node 树,比如我们要更新以下组件:
<template>
<div id="content">
<p>1</p>
<p>2</p>
<p>{{number}}</p>
<p>4</p>
<p>5</p>
</div>
</template>
一个div中有5个p标签,只有第3个p标签是动态数据number,整个diff过程如图所示:

可以看到,因为这段代码只有一个动态节点, 所以这里有很多的diff和遍历都是不需要的。这就导致 v-node 的性能和模板大小正相关,跟动态节点数量无关。当一些组件整个模板只有少量动态节点时,这些便利都是性能的浪费,理想状态只需要diff这个绑定number的p标签即可。vue.3.x 做到了。
vue.3.x 通过编译阶段对静态模板的分析,编译生成了 block tree:
- block tree 是一个模板基于动态节点指令切割的嵌套区块,每个区块内部节点结构是固定的。
- block tree 的每个区块只需要以一个Array来追踪自身包含的动态节点。
借助 block tree,vue.js 将 v-node 更新性能由与模板整体大小正相关提升为与动态内容的数量相关。这是一个非常大的性能突破。
除此之外,vue3.x 在编译阶段还做了:slot编译优化、事件侦听函数的缓存优化、运行时重写diff算法,这些之后会说。
三、语法 API 的优化
vue3.x 推出了 Composition API 。
Composition API 相较于 Options API 的优势:
- Composition API 优化了编码的逻辑组织——将某个逻辑关注点的相关代码全部放在一个函数里。
- Composition API 优化了代码的逻辑复用——使用 hooks 取代了 mixin。
1、优化了编码的逻辑组织
相较于 Options API,Composition API 优化了编码的逻辑组织。
Options API 的好处是写法非常符合人的逻辑思维,对新手比较友好——Options API 的设计是按照 method、computed、data、props 这些不同的选项分类的。当组件小的时候这种分类方式一目了然,但是在大型组件中,一个组件可能有多个逻辑关注点,当使用 Options API 的时候,每个关注点都有自己的 options,如果需要修改一个逻辑的关注点,就需要在单个文件中不断的上下切换寻找。
Composition API 解决了这个问题,就是将某个逻辑关注点相关的代码全部放到一个函数里,这样当需要修改一个功能时就不需要在文件中跳来跳去了。

2、优化了代码的逻辑复用
在 vue2.x 的 Options API 中,可以使用 mixin 来做代码的逻辑复用。使用单个 mixin 的问题不大,但是当我们的组件混入大量不同的 mixin 的时候,会存在两个非常明显的问题:
- 命名冲突:每个 mixin 都可以定义自己的 props、data,他们之间是无感的,所以很容易定义相同的变量名,导致命名冲突。
- 数据来源不清晰:对组件而言,如果模板中使用不在当前组件中定义的变量,那么就不会太容易知道这些变量在哪里定义的,这就是数据来源不清晰。
mixin 的以上问题在 Composition API 中均得到了解决——定义 hook 函数,在组件中使用 hook 函数。
Composition API 除了在逻辑复用方面有优势,还有更好的类型支持。因为他们都是一些函数,在调用函数时,自然所有的类型都被推导出来了。不像 Options API 所有的东西都使用 this。
另外,Composition API 对 tree-shaking 友好,代码也更容易压缩。
虽然 Composition API 有诸多优势,它也有一定的缺陷,之后再说。
关于 Composition API 的具体实现和设计原理,也在之后说。
【参考资源】
vue3.x 的源码 github 地址
vue3 源码解析教程
全网最详细 Vue3 源码解析