文章目录
- 项目概述
- 项目初始化
- 搭建项目初始框架
- 配置Tomcat
- 建立项目数据库
- 编写统一返回类及其工具类
- 编写数据库工具类
- 通过Filter解决Response返回中文乱码问题
- 使用Filter解决权限校验问题
- 项目主干开发
- 用户登录
- 企业管理(分页查询原生实现)
- 上传VIP申请书模板(文件上传实现)
- VIP公司的更新操作
- 国际采购管理模块
- 附:项目值得注意的技术点
- web.xml文件
- Jquery
- < base >:文档根 URL 元素
- 文件上传
- 附:项目过程中的思考
- 为什么mysql的驱动要使用Class.forName动态加载?
- 附:项目可改进点
- README
项目概述
完成一个中俄贸易服务供需平台后台管理端的后端部分,是一个原生的Javaweb项目,使用到servlet、jsp、jdbc等技术。
大致分为9个模块:
- VIP企业管理:
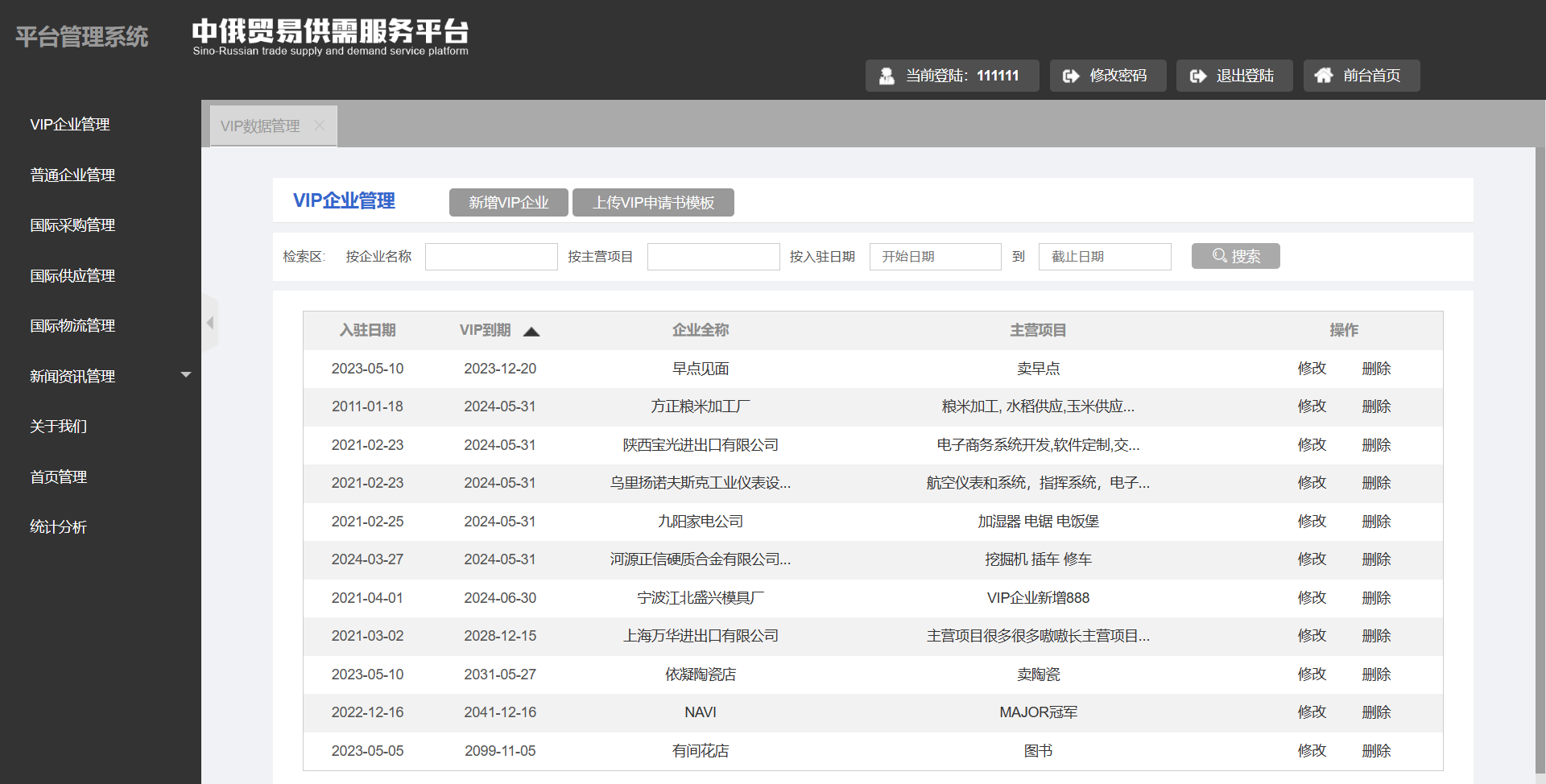
- 普通企业管理:
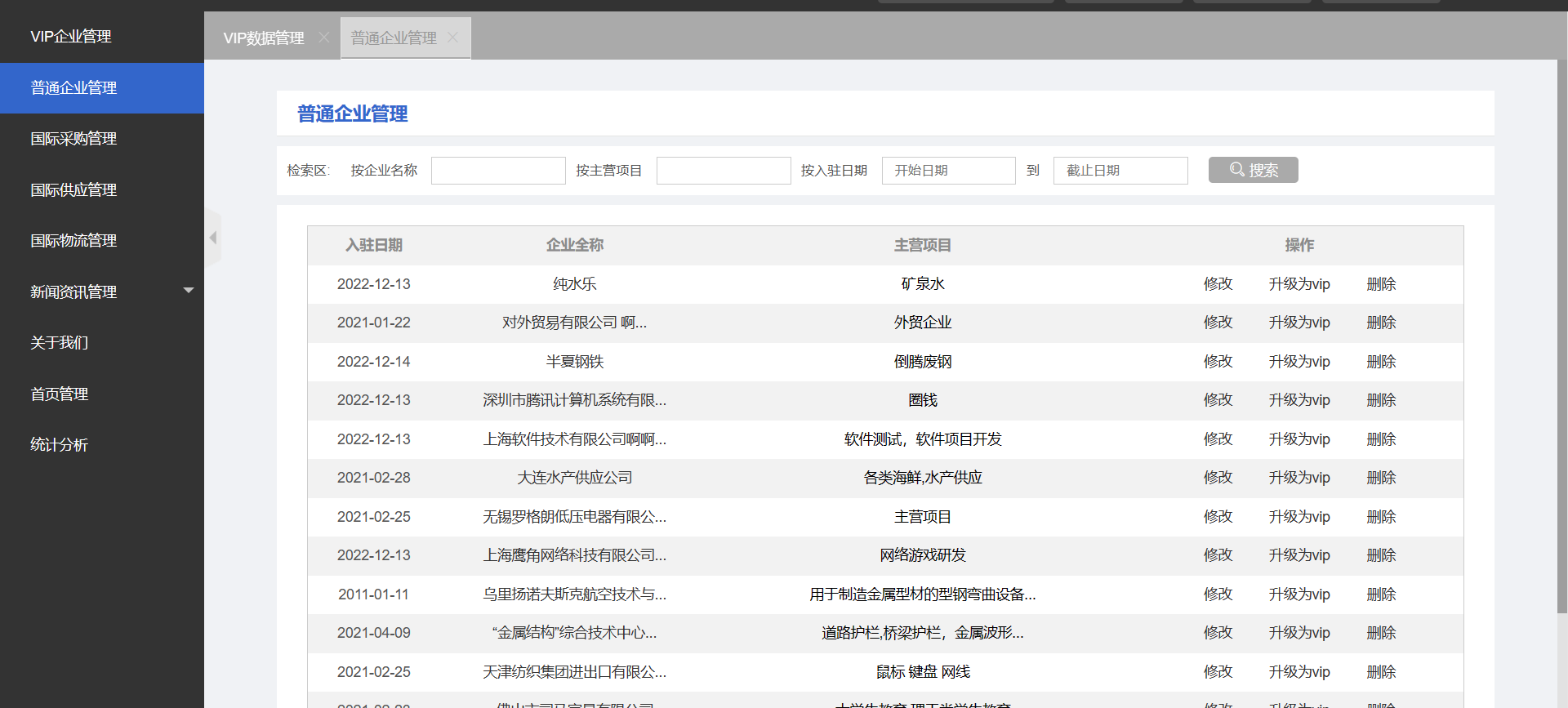
- 国际采购管理
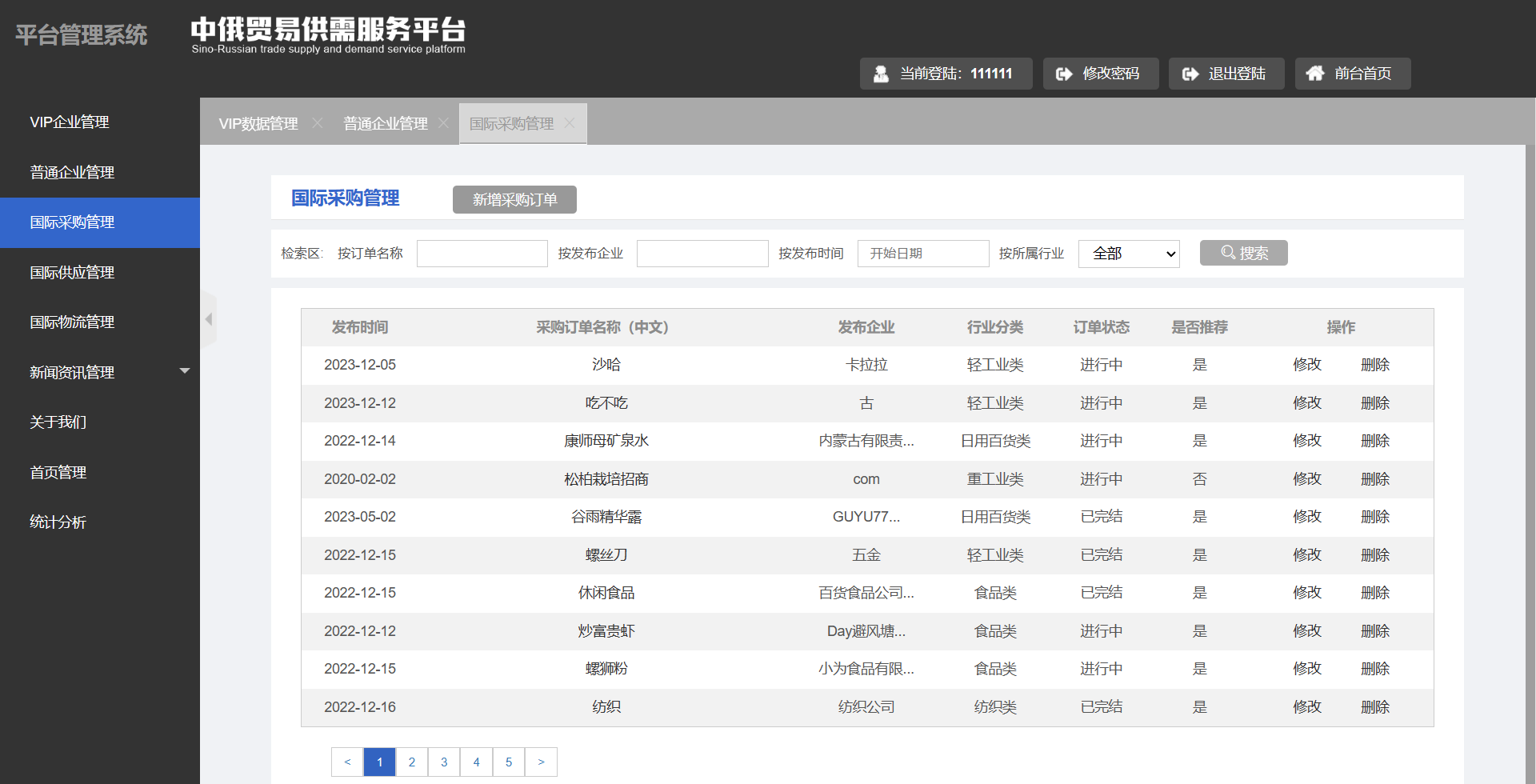
- 国际供应管理
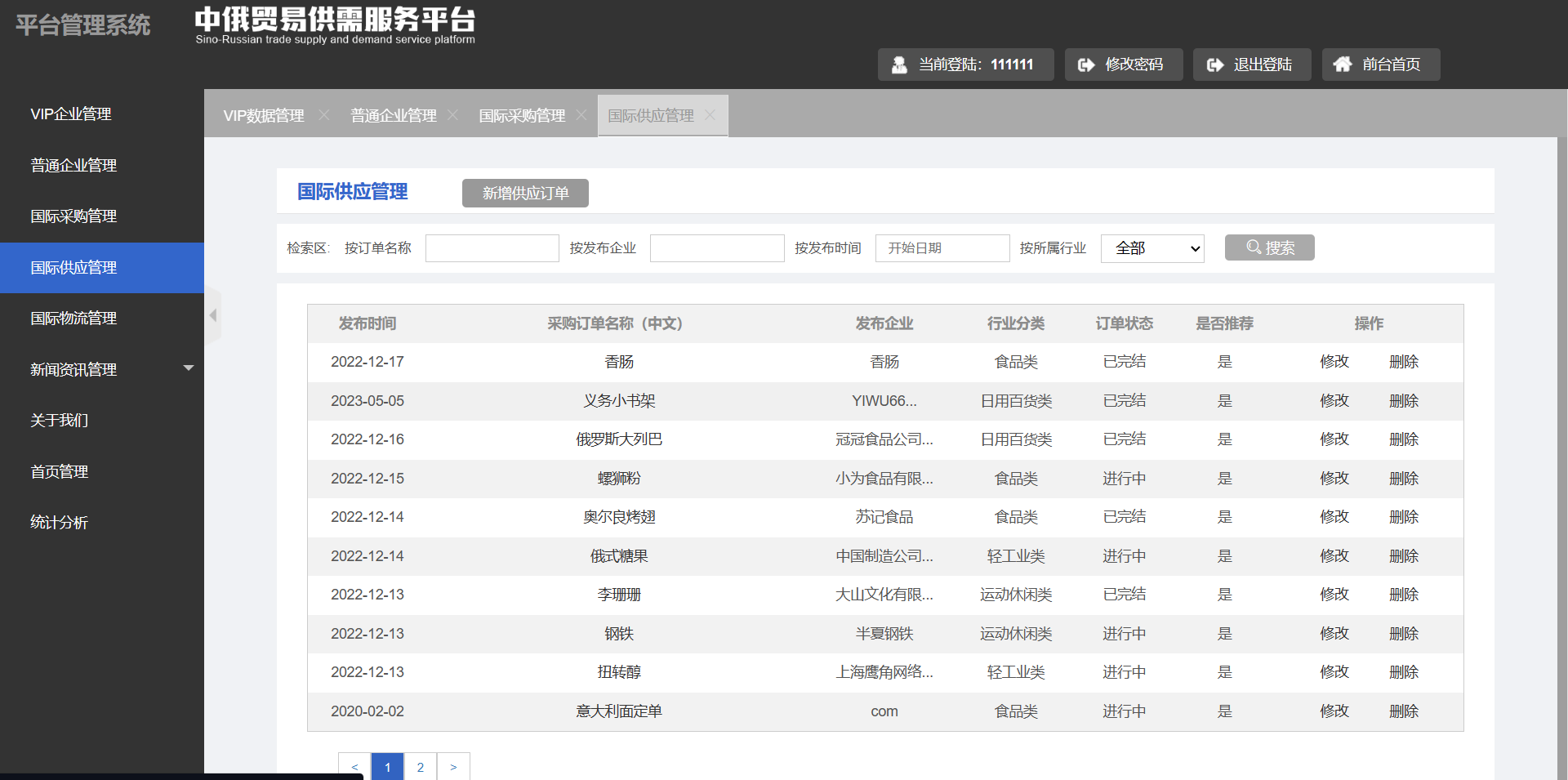
- 国际物流管理
- 新闻资讯管理
- 新闻资讯
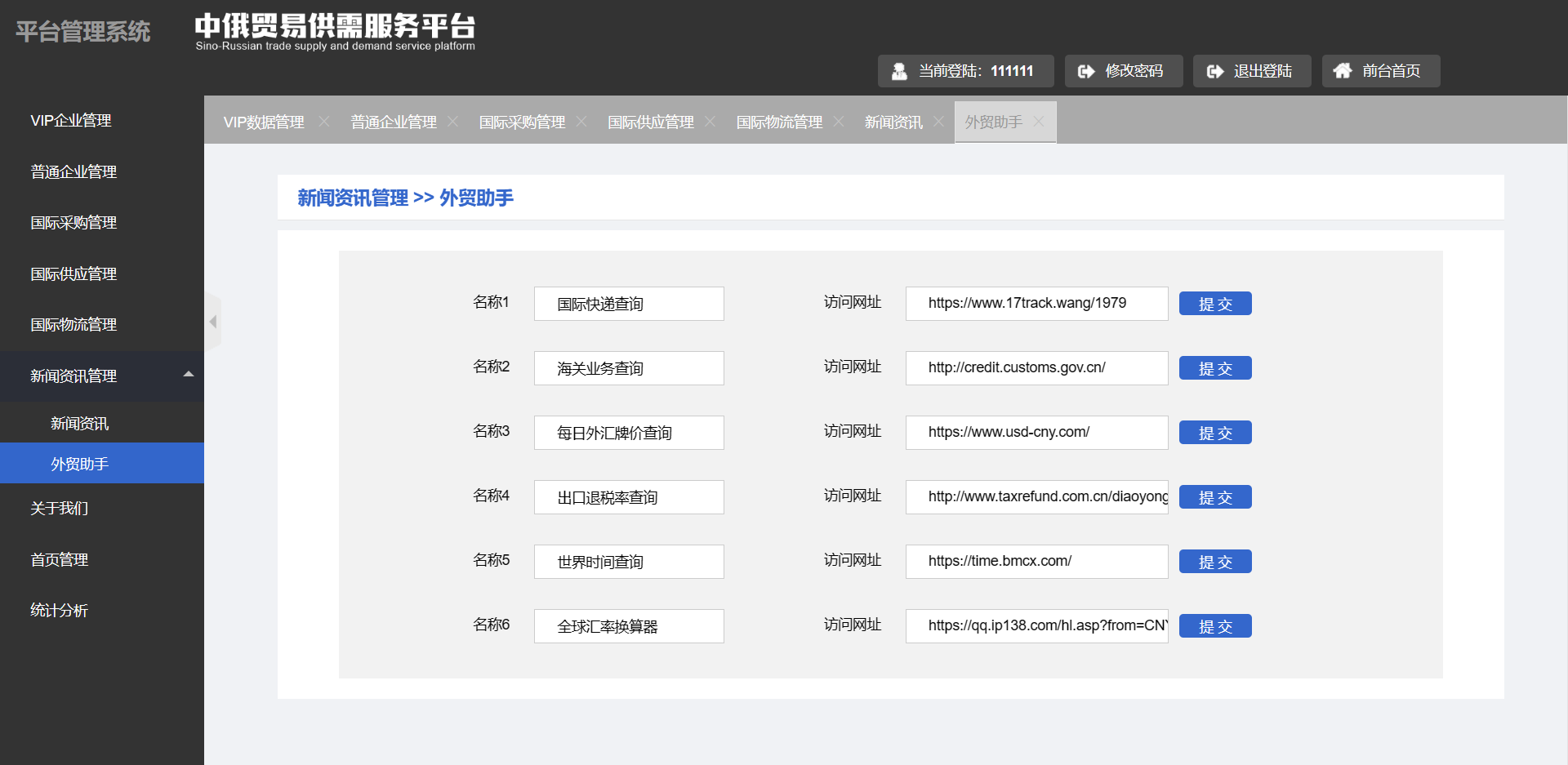
- 外贸助手
- 新闻资讯
- 关于我们
- 首页管理
- 统计分析
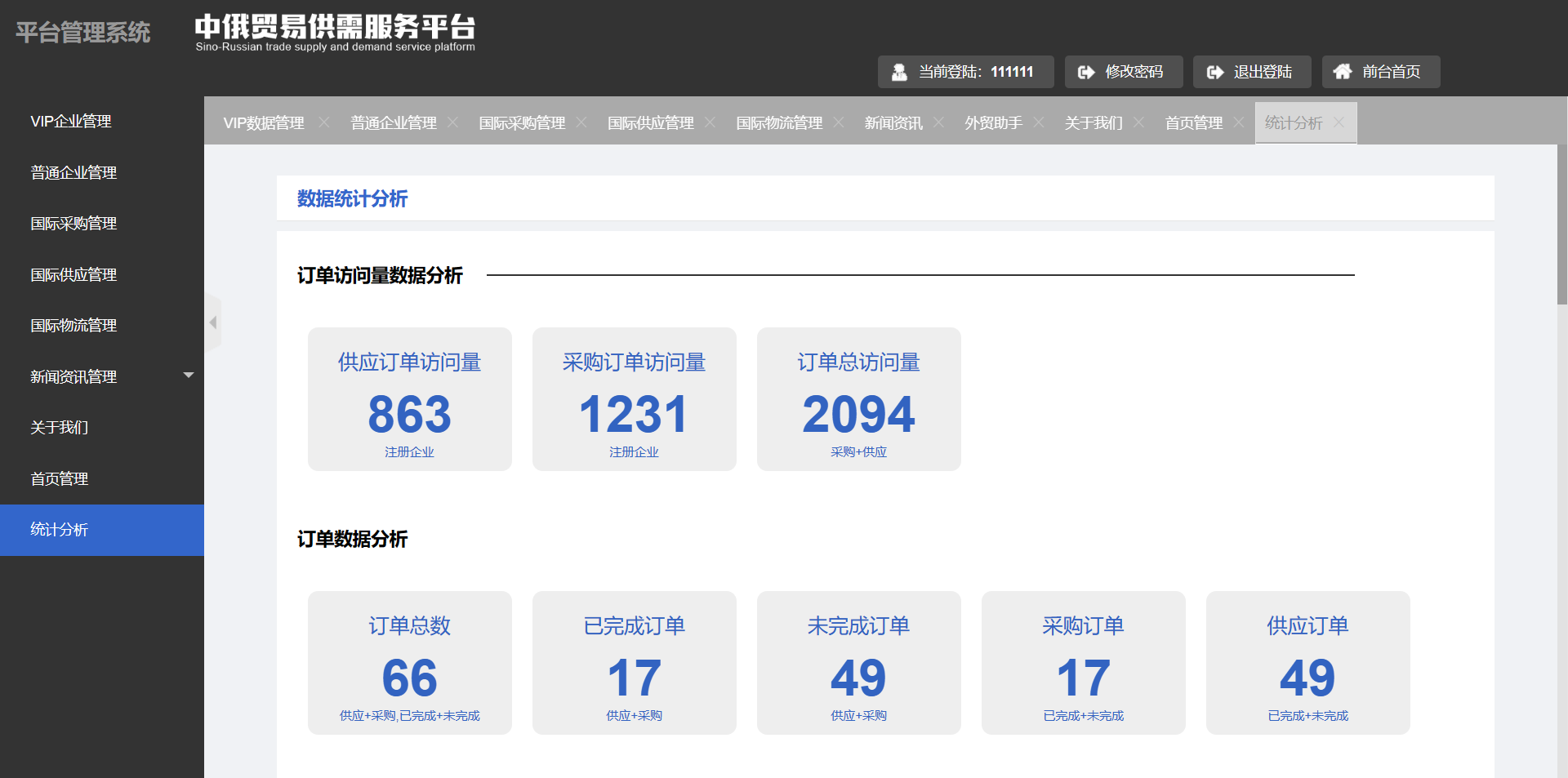
每个模块的大致技术方案:
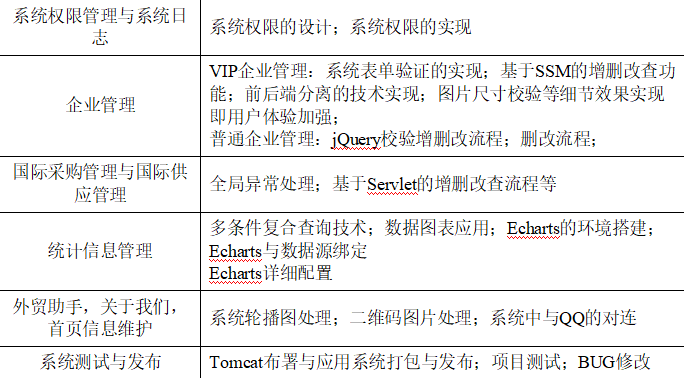
项目初始化
搭建项目初始框架
直接创建一个Maven的web项目,然后把前端现成的东西塞进去
配置Tomcat
配置Tomcat的过程可以参考我的另一篇文章:
IDEA中使用Tomcat
注意JDK版本与Tomcat的兼容性
注意为了提高效率我们要配置tomcat的热重载:
最后要以Debug模式运行
但是html的修改还是要重启服务器!
建立项目数据库
把提前准备好的sql语句放在项目的sql文件夹下,然后配置一下项目的数据源,确认所用的数据库,执行即可:
编写统一返回类及其工具类
每次返回的时候无需单独构造结果类,更加方便我们返回结果:
@Data
@AllArgsConstructor
@NoArgsConstructor
public class ResultMsg<T> implements Serializable {
private int code;
private T obj;
private String message;
public ResultMsg(int code, T obj) {
this(code, obj, "");
}
}
工具类:
public class ResultUtils {
/**
* 成功
*
* @param data
* @param <T>
* @return
*/
public static <T> ResultMsg<T> success(T data) {
return new ResultMsg<>(200, data, "success");
}
/**
* 成功
*
* @param data
* @param <T>
* @return
*/
public static <T> ResultMsg<T> success() {
return new ResultMsg<>(200, null, "success");
}
/**
* 失败
*
* @param
* @return
*/
public static ResultMsg error() {
return new ResultMsg<>(200,null,"error");
}
}
编写数据库工具类
因为我们这里使用的是原生的JDBC去操作数据库,如果我们频繁的去写创建连接以及释放资源的代码肯定会非常的麻烦,所以我们可以将这些操作抽象出来,专门写一个工具类:
public class DBUtils {
private static final String url="jdbc:mysql://127.0.0.1:3306/zemy?serverTimezone=UTC";
private static final String urlName = "你的数据库账号";
private static final String urlPwd = "你的数据库密码";
static{
//首次访问这个类的静态变量或静态方法时,类会进行初始化,然后执行这个静态代码块
try {
Class.forName("com.mysql.cj.jdbc.Driver");
} catch (ClassNotFoundException e) {
System.out.println("加载驱动类失败!");
throw new RuntimeException(e);
}
}
public static Connection getConn(){
Connection conn = null;
try {
conn = DriverManager.getConnection(url,urlName,urlPwd);
} catch (SQLException e) {
System.out.println("创建链接异常");
throw new RuntimeException(e);
}
return conn;
}
public static void closeAll(Connection conn, Statement stmt, ResultSet rs){
if(rs != null){
try {
rs.close();
} catch (SQLException e) {
throw new RuntimeException(e);
}
}
if(stmt != null){
try {
stmt.close();
} catch (SQLException e) {
throw new RuntimeException(e);
}
}
if(conn != null){
try {
conn.close();
} catch (SQLException e) {
throw new RuntimeException(e);
}
}
}
}
通过Filter解决Response返回中文乱码问题
本项目前后端并没有分开部署,所以不推荐全路径拦截,只能通过添加特定路径的方式进行精确拦截。
@WebFilter(urlPatterns = {"xxx","xxx"})
public class GlobalFilter implements Filter {
@Override
public void init(FilterConfig filterConfig) throws ServletException {
}
@Override
public void doFilter(ServletRequest servletRequest, ServletResponse servletResponse, FilterChain filterChain) throws IOException, ServletException {
servletResponse.setContentType("application/json;charset=utf-8");
filterChain.doFilter(servletRequest,servletResponse);
}
@Override
public void destroy() {
}
}
后期把需要处理的路径往urlPatterns 中添加即可
使用Filter解决权限校验问题
/**
* @author 十八岁讨厌编程
* @date 2023/12/15 21:18
* @PROJECT_NAME zemy
* @description
*/
@WebFilter("/*")
public class GlobalAuthFilter implements Filter {
@Override
public void init(FilterConfig filterConfig) throws ServletException {
}
@Override
public void doFilter(ServletRequest servletRequest, ServletResponse servletResponse, FilterChain filterChain) throws IOException, ServletException {
HttpServletRequest req = (HttpServletRequest)servletRequest;
HttpServletResponse resp = (HttpServletResponse)servletResponse;
//如果请求路径包含 .css .js .html .jsp 我们不做权限校验
//servlet 中 verifyCode createCode login不能控制
if (req.getRequestURI().endsWith(".css")) {
filterChain.doFilter(req,resp);
} else if (req.getRequestURI().endsWith(".js")) {
filterChain.doFilter(req,resp);
} else if (req.getRequestURI().endsWith(".html")) {
filterChain.doFilter(req,resp);
} else if (req.getRequestURI().endsWith(".jsp")) {
filterChain.doFilter(req,resp);
} else if (req.getRequestURI().endsWith("createCode")) {
filterChain.doFilter(req,resp);
} else if (req.getRequestURI().endsWith("verifyCode")) {
filterChain.doFilter(req,resp);
} else if (req.getRequestURI().endsWith("login")) {
filterChain.doFilter(req,resp);
} else {
AdminInfo loginUser = (AdminInfo) req.getSession().getAttribute("loginUser");
if (loginUser != null) {
filterChain.doFilter(req,resp);
}else {
//未登录直接重定向回登录页面
resp.sendRedirect(req.getContextPath() + "/adminlogin.jsp");
}
}
}
@Override
public void destroy() {
}
}
项目主干开发
用户登录
我们直接看登陆页面的前端界面,涉及三个接口:
- 校验验证码接口
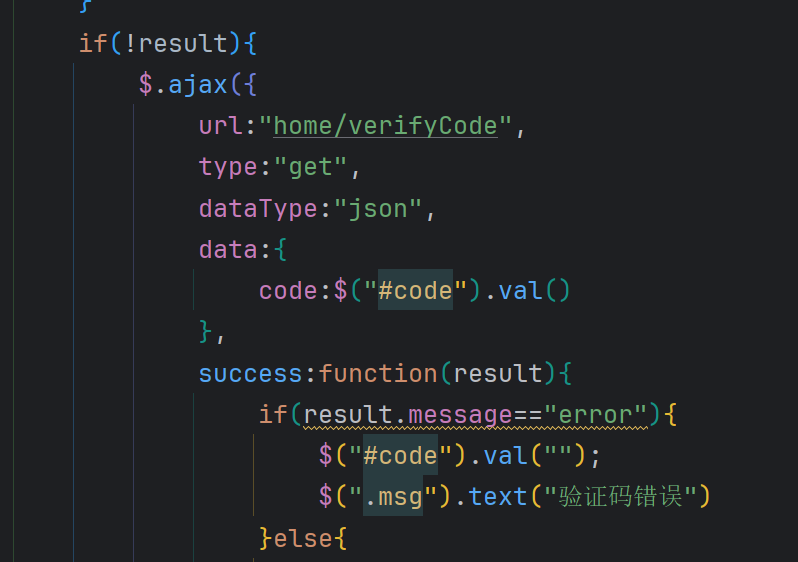
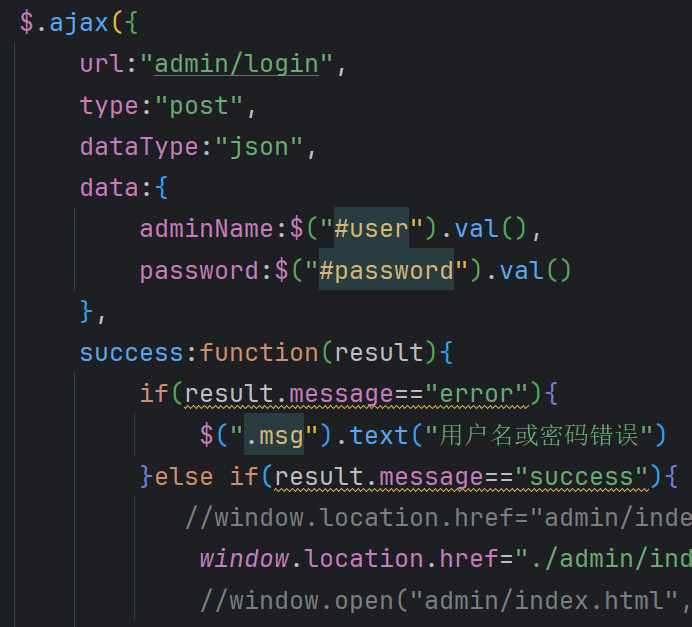
- 登录接口
- 验证码生成接口(已提供,不用管)
大致过程:
- 前端首先请求验证码生成接口拿到验证码
- 后端同时把验证码存在session中
- 前端用户提交登录信息之后
- 首先请求校验验证码接口,将前端传过来的校验码和session中的进行比较
- 如果成功则继续请求登录接口
- 登录接口根据账号密码在数据库中查询数据
- 如果查询到用户则将该用户的信息存储到session中
- 然后删除存储在session中的校验码
实现过程
编写两个servlet对请求进行处理就行:
首先编写校验验证码的servlet:HomeVerifyCodeServlet
@WebServlet("/home/verifyCode")
public class HomeVerifyCodeServlet extends HttpServlet {
@Override
protected void doGet(HttpServletRequest req, HttpServletResponse resp) throws ServletException, IOException {
String rightCode = (String)req.getSession().getAttribute("code");
String userCode = req.getParameter("code");
System.out.println("用户提交的验证码" + userCode);
System.out.println("正确的验证码" + rightCode);
if (StrUtil.isAllNotBlank(rightCode,userCode) && rightCode.equals(userCode)) {
resp.getWriter().write(JSONUtil.toJsonStr(ResultUtils.success()));
}else {
resp.getWriter().write(JSONUtil.toJsonStr(ResultUtils.error()));
}
}
}
登录servlet中涉及到数据库操作,我们首先设计数据库:
-- ----------------------------
-- Table structure for `admininfo`
-- ----------------------------
DROP TABLE IF EXISTS `admininfo`;
CREATE TABLE `admininfo` (
`id` int(11) NOT NULL auto_increment COMMENT '主键',
`adminName` varchar(30) collate utf8_unicode_ci default NULL COMMENT '登录账号',
`password` varchar(50) collate utf8_unicode_ci default NULL COMMENT '密码',
`phone` varchar(20) collate utf8_unicode_ci default NULL COMMENT '电话号',
`addTime` datetime default NULL COMMENT '添加时间',
`role` varchar(10) collate utf8_unicode_ci default NULL COMMENT '角色0普通管理员1超管',
`delFlag` varchar(1) collate utf8_unicode_ci default NULL COMMENT '0正常1删除',
`realName` varchar(30) collate utf8_unicode_ci default NULL COMMENT '真实姓名',
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COLLATE=utf8_unicode_ci;
然后根据这个表编写实体类:
@Data
public class AdminInfo {
private int id;
private String adminName;
private String password;
private String phone;
private Date addTime;
private String role;
private String realName;
private String delFlag;
}
然后我们将对这张表的操作,都写在Dao层中,例如这里我们根据账号密码去数据库查找用户:
public class AdminInfoDao {
public AdminInfo login(String adminName,String password){
AdminInfo adminInfo = null;
Connection conn = null;
PreparedStatement pstmt = null;
ResultSet rs = null;
String sql = " select * from adminInfo where adminName = ? and password = ?";
conn = DBUtils.getConn();
try {
pstmt = conn.prepareStatement(sql);
pstmt.setString(1 ,adminName);
pstmt.setString(2 ,password);
rs = pstmt.executeQuery();
if(rs.next()){
adminInfo = new AdminInfo();
adminInfo.setId(rs.getInt("id"));
adminInfo.setAdminName(rs.getString("adminName"));
adminInfo.setPassword(rs.getString("password"));
adminInfo.setPhone(rs.getString("phone"));
adminInfo.setAddTime(rs.getDate("addTime"));
adminInfo.setRole(rs.getString("role"));
adminInfo.setRealName(rs.getString("realName"));
adminInfo.setDelFlag(rs.getString("delFlag"));
}
} catch (SQLException e) {
throw new RuntimeException(e);
} finally {
DBUtils.closeAll(conn,pstmt,rs);
}
return adminInfo;
}
}
注意:这里的rs.next()方法的用法,类似于一个遍历结果集的方法,官方文档中的解释:
将光标从当前位置向前移动一行。ResultSet游标最初定位在第一行之前;第一次调用该方法会使第一行成为当前行;第二次调用会使第二行成为当前行,依此类推。
当对next方法的调用返回false时,游标将定位在最后一行之后。任何需要当前行的ResultSet方法的调用都将导致抛出SQLException。如果结果集类型为TYPE_FORWARD_ONLY,则由供应商指定其JDBC驱动程序实现是否将在随后调用next时返回false或抛出SQLException。
next方法返回值:
如果新的当前行有效,则返回true;如果没有更多行,则返回false
Dao层方法的编写步骤大致如下:
- 创建连接(工具类完成)
- 编写sql
- 执行sql
- 得到结果集ResultSet
- 遍历结果集中的结果,将结果封装成自己想要得到的对象
- 返回对象
至此一个基本的CRUD过程就完成了,后面相似的操作将不再详细解释。
然后我们在登录成功之后,前端还会调用后端接口,拿到一个登录态,只有获得了这个登录态才能进入管理页面,否则就会被重定向到登录页。接口如下:
我们编写对应的servlet:
@WebServlet("/admin/getSessionAdmin")
public class AdminGetSessionAdmin extends HttpServlet {
@Override
protected void doGet(HttpServletRequest req, HttpServletResponse resp) throws ServletException, IOException {
AdminInfo loginUser = (AdminInfo) req.getSession().getAttribute("loginUser");
if (ObjectUtil.isNotNull(loginUser)) {
//因为AdminInfo中的role属性设计中文,所以我们在响应的的时候要设置一下字符集
resp.setContentType("application/json;charset=utf-8");
resp.getWriter().write(JSONUtil.toJsonStr(ResultUtils.success(loginUser)));
System.out.println("获取用户成功");
} else {
resp.getWriter().write(JSONUtil.toJsonStr(ResultUtils.error()));
System.out.println("获取用户失败");
}
}
}
这里注意:
- Response响应字符数据的时候,如果包含中文,要进行字符集的设置
企业管理(分页查询原生实现)

这里的搜索表单会收集四个查询信息,然后调用分页查询接口,获得分页查询的数据。
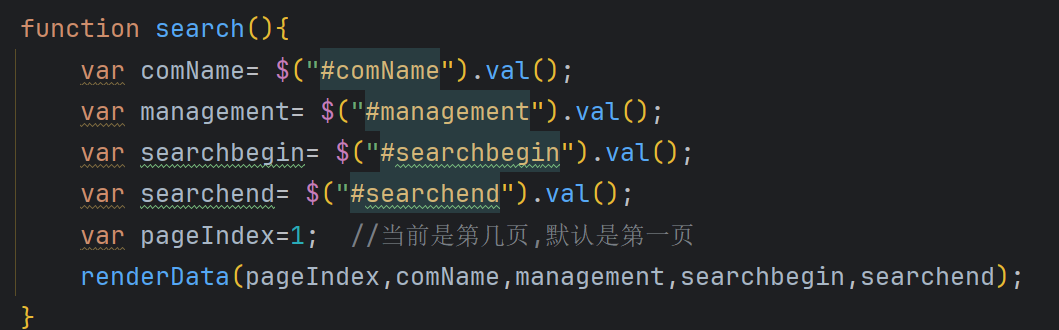
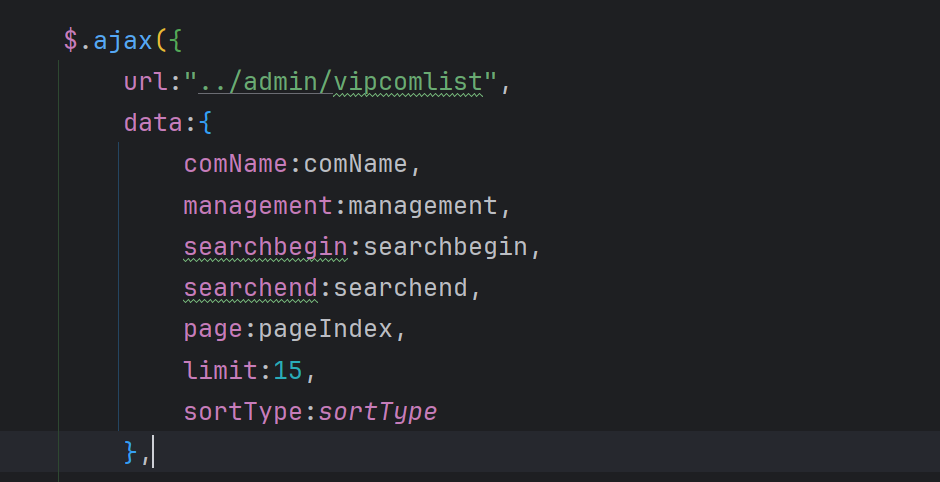
这里的调用分页查询接口的时候传入的参数有7个:
- 企业名称comName(查询参数)
- 主营项目management(查询参数)
- 入驻开始日期searchbegin(查询参数)
- 入驻结束日期searchend(查询参数)
- 当前页page (分页参数)
- 每面的数据量limit(分页参数)
- 排序的方式sortType(分页参数)
返回的对象要求有三个属性:
- list:分页数据
- pages:总页数
- pageNum:当前页
我们将这个对象叫做分页对象,在分页查询中这个对象至关重要,是前后端分页数据传输的关键枢纽。
这个地方前端拿到分页的数据渲染之后,又调用了一个函数pageFun:
这个函数的作用就是渲染出分页条组件:
我们每次点击切换页面的时候它就会帮我们再次把那7个参数拿去请求后端的分页查询接口。
梳理完基本的步骤之后我们就可以开始完成分页查询的具体实现了:
我们首先定义一个分页对象:
@Data
public class Page<T> {
private List<T> list;
private int pages;
private int pageNum;
}
然后我们来实现分页查询的servlet:
@WebServlet("/admin/vipcomlist")
public class VipCompanyPageQuery extends HttpServlet {
private CompanyDao companyDao = new CompanyDao();
@Override
protected void doGet(HttpServletRequest req, HttpServletResponse resp) throws ServletException, IOException {
//首先把前端传过来的参数都解构出来
String comName = req.getParameter("comName");
String management = req.getParameter("management");
String searchbegin = req.getParameter("searchbegin");
String searchend = req.getParameter("searchend");
int page = Integer.parseInt(req.getParameter("page"));
int limit = Integer.parseInt(req.getParameter("limit"));
String sortType = req.getParameter("sortType");
//调用dao层进行分页查询
Page<Company> companyPage = companyDao.companyPageQuery(
comName, management, searchbegin, searchend, page, limit, sortType
);
if (companyPage == null) {
resp.getWriter().write(JSONUtil.toJsonStr(ResultUtils.error()));
} else {
// 乱码问题通过Filter解决
// resp.setContentType("application/json;charset=utf-8");
resp.getWriter().write(JSONUtil.toJsonStr(ResultUtils.success(companyPage)));
}
}
}
注意点:
- 分页查询中的两个重要公式,一个用来确定总页数,零一个用来确定初始偏移量
然后编写相应的dao层:
public class CompanyDao {
public Page<Company> companyPageQuery(
String comName, String management,
String searchbegin, String searchend,
Integer page, Integer limit, String sortType
) {
//获得当前页面的起始偏移量
int offset = (page - 1) * limit;
List<Company> companyList = null;
Connection conn = DBUtils.getConn();
PreparedStatement pstmt = null;
ResultSet rs = null;
StringBuffer sql = new StringBuffer(" select registerTime,vipend,comName,management from company where 1=1 ");
ArrayList<String> params = new ArrayList<>();
if (StrUtil.isNotBlank(comName)) {
sql.append("and comName like ");
sql.append("'%");
sql.append(comName);
sql.append("%' ");
}
if (StrUtil.isNotBlank(management)) {
sql.append("and management like ");
sql.append("'%");
sql.append(management);
sql.append("%' ");
}
if (StrUtil.isAllNotBlank(searchbegin,searchend)) {
sql.append("and registerTime between ? and ? ");
params.add(searchbegin);
params.add(searchend);
}
//拼到这里,我们就可以确定符合条件的数据条数
int count = 0;
try {
pstmt = conn.prepareStatement(sql.toString());
for (int i = 0; i < params.size(); i++) {
pstmt.setString(i + 1,params.get(i));
}
rs = pstmt.executeQuery();
while (rs.next()){
count ++;
}
} catch (SQLException e) {
throw new RuntimeException(e);
}
System.out.println("符合条件的总条数为" + count);
//注意:limit一定要在order by后面
sql.append("order by vipend ");
sql.append(sortType);
sql.append(" limit ?,? ");
try {
pstmt = conn.prepareStatement(sql.toString());
System.out.println("分页查询sql" + sql);
for (int i = 0; i < params.size(); i++) {
pstmt.setString(i + 1,params.get(i));
}
pstmt.setInt(params.size() + 1, offset);
pstmt.setInt(params.size() + 2, limit);
rs = pstmt.executeQuery();
companyList = new ArrayList<>();
while (rs.next()){
Company company = new Company();
company.setComName(rs.getString("comName"));
String vipend = rs.getString("vipend");
company.setVipend(vipend);
company.setManagement(rs.getString("management"));
String registerTime = rs.getString("registerTime");
company.setRegisterTime(registerTime);
companyList.add(company);
}
} catch (SQLException e) {
throw new RuntimeException(e);
}finally {
DBUtils.closeAll(conn,pstmt,rs);
}
//封装要返回的分页对象
Page<Company> companyPage = new Page<>();
int totalNum = (count - 1) / limit + 1;
companyPage.setPages(totalNum);
companyPage.setList(companyList);
companyPage.setPageNum(page);
return companyPage;
}
}
注意点:
- limit一定要在order by后面
- 动态拼接那里的逻辑就是使用1=1去占一个位置,这样后面拼接其他条件的时候可以保持格式统一
- 拼接的时候使用StringBuffer这样提升效率
- 日期格式不方便转换,这里直接使用的字符串
上传VIP申请书模板(文件上传实现)
实现原理可以看项目中的技术点那一栏
前端传输的表单:
<form id="form-doc" enctype="multipart/form-data">
<input style="display:none" type="file" id="vipdoc" name="vipdoc" onchange="uploadDoc()" >
</form>
/**
* @author 十八岁讨厌编程
* @date 2023/12/15 0:37
* @PROJECT_NAME zemy
* @description
*/
@WebServlet("/admin/uploadVipDoc")
@MultipartConfig
public class VipDocUpLoadServlet extends HttpServlet {
@Override
protected void doPost(HttpServletRequest req, HttpServletResponse resp) throws ServletException, IOException {
// 设置编码
req.setCharacterEncoding("UTF-8");
//获取上传到文件
Part file = req.getPart("vipdoc");
//获取文件信息
System.out.println("文件名:" + file.getSubmittedFileName());
System.out.println("文件类型:" + file.getContentType());
System.out.println("文件大小:" + file.getSize());
//指定每个用户文件存放的位置
AdminInfo loginUser = (AdminInfo) req.getSession().getAttribute("loginUser");
int id = loginUser.getId();
String contextPath = req.getServletContext().getRealPath("/");
String userPath = contextPath + "vipdocs" + File.separator + id;
if (!FileUtil.exist(userPath)) {
FileUtil.mkdir(userPath);
}
//把文件写入到磁盘中的指定目录
try {
file.write(userPath + File.separator + file.getSubmittedFileName());
//返回响应
resp.getWriter().write(JSONUtil.toJsonStr(ResultUtils.success("文件上传成功" + file.getSubmittedFileName())));
} catch (IOException e) {
e.printStackTrace();
resp.getWriter().write(JSONUtil.toJsonStr(ResultUtils.success("文件上传失败")));
}
}
}
代码注意点:
- 我们对每一个用户的上传文件要进行单独的隔离,防止多用户想用文件名文件的重覆盖,这里我们使用用户的id作为用户独立文件夹的名字
- 文件分隔符使用的是File.separator,而不是直接“/”进行拼接,其内部会自动根据系统环境使用对应的文件分割符,增强了程序的健壮性
这个地方为了最快速、最简单、最清晰的实现一个文件上传servlet,代码中并没有添加安全校验的内容。对前端传递过来的文件进行校验是一种常见的安全措施,以确保接收的文件符合预期。以下是一些常见的文件校验方法:
-
文件类型检查:验证文件的扩展名或MIME类型,以确保它们与预期的文件类型相匹配。这可以防止恶意用户通过修改文件扩展名或伪装文件类型来上传危险文件。
-
文件大小检查:限制上传文件的大小,以防止上传过大的文件占用服务器资源或导致性能问题。
-
文件内容验证:对上传的文件进行内容验证,以确保其符合预期的格式和结构。例如,对于图像文件,可以检查其是否真正是有效的图像文件,而不是伪装成图像的恶意代码。
-
文件名检查:验证文件名是否包含非法字符或特殊字符,以防止潜在的路径遍历攻击或文件名注入攻击。
-
病毒扫描:使用病毒扫描引擎对上传的文件进行扫描,以检测是否包含已知的病毒或恶意软件。
-
文件权限控制:确保上传的文件在存储或访问时具有适当的权限设置,以防止未经授权的访问或意外的敏感信息泄露。
需要注意的是,这些校验方法应根据具体的应用场景和安全需求进行调整和组合使用。此外,后端服务器也应该对接收到的文件进行进一步处理和验证,以确保系统的安全性和可靠性。
VIP公司的更新操作
我们大致梳理一下更新的流程:
- 用户点击修改按钮
- 页面会携带修改公司的id进行页面跳转(类似于动态路由的思想)
- 前端根据公司id请求后端信息将公司信息进行回显
- 用户修改公司信息之后点击提交
- 前端将信息重新传递给后端更新接口完成更新
这里有一个注意点,图片的回显是怎么做到的?
-
在初次上传图片阶段,图片的回显完全依赖于前端实现
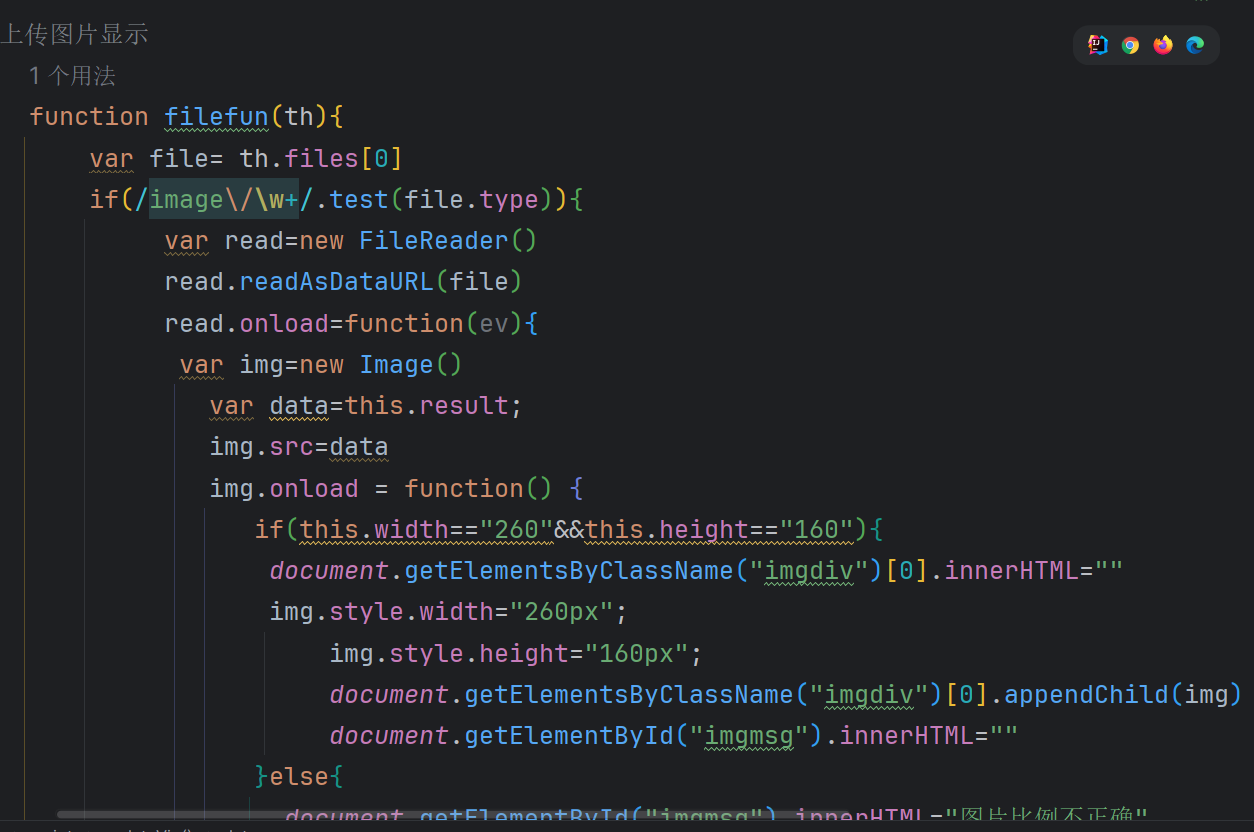
-
而在后期的修改阶段,前端在显示图片的时候是根据图片在服务器中的保存路径进行回显

也就是说在后端我们要干的事情就两个:
- 一个是将上传的图片保存在服务器中
- 使用接收到的数据去更新公司信息
servlet代码:
/**
* @author 十八岁讨厌编程
* @date 2023/12/15 18:33
* @PROJECT_NAME zemy
* @description
*/
@WebServlet("/admin/updateVipCompany")
@MultipartConfig
public class VipCompanyUpdateServlet extends HttpServlet {
private CompanyDao companyDao = new CompanyDao();
@Override
protected void doPost(HttpServletRequest req, HttpServletResponse resp) throws ServletException, IOException {
// 设置编码
req.setCharacterEncoding("UTF-8");
//先将前端所有传递过来的信息解构出来
int comid = Integer.parseInt(req.getParameter("comid"));
String comName = req.getParameter("comName");
String contacts = req.getParameter("contacts");
String telephone = req.getParameter("telephone");
String userName = req.getParameter("userName");
String vipbegin = req.getParameter("vipbegin");
String vipend = req.getParameter("vipend");
String management = req.getParameter("management");
int recommend = Integer.parseInt(req.getParameter("recommend"));
int category = Integer.parseInt(req.getParameter("category"));
String brief = req.getParameter("brief");
String detailed = req.getParameter("detailed");
//首先处理图片的的上传
//获取上传到文件
Part file = req.getPart("files");
//如果用户上传了图片我们才进行上传操作
if (StrUtil.isNotBlank(file.getSubmittedFileName())) {
//获取文件信息
System.out.println("文件名:" + file.getSubmittedFileName());
System.out.println("文件类型:" + file.getContentType());
System.out.println("文件大小:" + file.getSize());
//指定每个公司图片文件存放的位置
String contextPath = req.getServletContext().getRealPath("/");
String companyPath = contextPath + "mainImage" + File.separator + comid;
if (!FileUtil.exist(companyPath)) {
FileUtil.mkdir(companyPath);
}
//把文件写入到磁盘中的指定目录
try {
file.write(companyPath + File.separator + file.getSubmittedFileName());
} catch (IOException e) {
e.printStackTrace();
resp.getWriter().write(JSONUtil.toJsonStr(ResultUtils.error("文件上传失败导致更新失败")));
return;
}
}
//接下来更新公司信息
int result = companyDao.updateCompanyById(
comid,comName,contacts,telephone,userName,vipbegin,
vipend,management,recommend,category,brief,detailed,file.getSubmittedFileName()
);
if (result < 0) {
resp.getWriter().write(JSONUtil.toJsonStr(ResultUtils.error("更新失败")));
}
resp.getWriter().write(JSONUtil.toJsonStr(ResultUtils.error("更新成功")));
}
}
注意点:
- 注意如果前端包含文件上传,也就是使用的multipart/form-data这种MIME格式进行的表单提交,那么我们在servlet中进行处理的时候第一件事就是设置编码格式,否则我们拿到的值都会出现异常。(如果使用了过滤器则可以忽略)
注意:如果前端使用multipart/form-data进行传输,那么servlet中必须使用@MultipartConfig注解之后,才能使用HttpServletRequest.getParameter拿到参数。
dao层代码:
public int updateCompanyById(int comid, String comName,
String contacts, String telephone,
String userName, String vipbegin,
String vipend, String management,
int recommend, int category,
String brief, String detailed,
String submittedFileName)
{
Connection conn = null;
PreparedStatement statement = null;
ArrayList<String> params = new ArrayList<>();
StringBuffer sql = new StringBuffer(" update company " +
"set comName=?,contacts=?,telephone=?,userName=?, vipbegin=?," +
"vipend=?,management=?,recommend=?,category=?,brief=?");
//因为这里前端的detailed、mainImage的值不会被记忆,所以这里我们要将这两个值判一下空
if (StrUtil.isNotBlank(detailed)) {
sql.append(",detailed=?");
params.add(detailed);
}
if (StrUtil.isNotBlank(submittedFileName)) {
sql.append(",mainImage=?");
params.add(submittedFileName);
}
sql.append(" where comid=? ");
int ret = 0;
conn = DBUtils.getConn();
try {
statement = conn.prepareStatement(sql.toString());
statement.setString(1,comName);
statement.setString(2,contacts);
statement.setString(3,telephone);
statement.setString(4,userName);
statement.setString(5,vipbegin);
statement.setString(6,vipend);
statement.setString(7,management);
statement.setInt(8,recommend);
statement.setInt(9,category);
statement.setString(10,brief);
for (int i = 0; i < params.size(); i++) {
statement.setString(11 + i,params.get(i));
}
statement.setInt(10 + params.size() + 1,comid);
ret = statement.executeUpdate();
} catch (SQLException e) {
throw new RuntimeException(e);
} finally {
DBUtils.closeAll(conn,statement,null);
}
return ret;
}
注意点:
- 这个地方可能因为前端引入了第三方组件的原因,detailed和上传的图片如果没有进行修改,即使表单中它们的值不为空,提交的信息中他们的值还是会为空。所以我们在servlet层以及dao层插入了一些判空逻辑,如果相关值为空,那么我们就保留原值。(如果不这样的话就会导致,我们没有修改的值,会更新为空)
国际采购管理模块
增删改查步骤和前面一样,但是有一个注意点:
行业分类我们的表中只有businessid,而如果想要得到对应的内容则需要去查business表,相当于有一个子查询。但是如果这样做的话会非常的影响性能,考虑到business是一个具有长期稳定性的分类信息,我们直接写一个工具类,将business的id与其对应的值维护成一个HashMap,这样在分页查询中就不会出现相当多的子查询,如此就可以大大增加分页查询的效率。
/**
* @author 十八岁讨厌编程
* @date 2023/12/16 10:24
* @PROJECT_NAME zemy
* @description
*/
public class BusinessUtils {
private static final Map<Integer,String> BUSINESSMAP = new HashMap<>();
static {
BUSINESSMAP.put(1,"轻工业类");
BUSINESSMAP.put(2,"重工业类");
BUSINESSMAP.put(3,"农业类");
BUSINESSMAP.put(4,"纺织类");
BUSINESSMAP.put(5,"日用百货类");
BUSINESSMAP.put(6,"食品类");
BUSINESSMAP.put(7,"运动休闲类");
BUSINESSMAP.put(8,"3C产品");
}
public static String getBusinessNameById(Integer id){
return BUSINESSMAP.get(id);
}
}
附:项目值得注意的技术点
web.xml文件
需要注意的是:web.xml并不是必须的,一个web工程可以没有web.xml文件
web.xml文件是Java Web应用的一个重要的配置文件,它定义了Web应用中的各个组件(Servlet, Filter, Listener等)以及部署信息。web.xml文件的主要作用有:
- 配置欢迎页面,即当用户访问Web应用的根目录时,显示的默认页面。
- 配置Servlet,即将一个Java类映射到一个或多个URL上,以便处理用户的请求。
- 配置Filter,即在Servlet执行前后,对请求或响应进行拦截或修改。
- 配置Listener,即监听Web应用中的事件,如ServletContext的创建和销毁,Session的创建和销毁等。
- 配置全局参数,即在Web应用中定义一些键值对,供不同的组件共享。
- 配置错误页面,即当用户访问的页面不存在或发生异常时,显示的友好页面⁷。
- 配置安全约束,即限制用户对Web应用中的资源的访问权限。
web.xml文件的格式遵循XML规范,它的根元素是<web-app>,它的子元素有<display-name>, <context-param>, <filter>, <filter-mapping>, <listener>, <servlet>, <servlet-mapping>, <session-config>, <mime-mapping>, <welcome-file-list>, <error-page>, <security-constraint>, <login-config>, <security-role>等⁹。web.xml文件的位置一般在WebContent/WEB-INF目录下。
web项目加载web.xml过程:
Tomcat启动web项目时,web容器就会首先加载web.xml文件,加载过程如下:
-
web项目加载web.xml,读取context-param和listener这两个结点
-
创建一个ServletContext(Servlet上下文),整个项目会共享这个ServletContext
-
容器将
<context-param>转换为键值对,并交给ServletContext -
容器创建
<listener>中的类实例,创建监听器
所以说只要修改了web.xml文件,我们就要重启服务器。
Jquery
这个技术已经使用的比较少了,这里我们简单的了解几种语法就行
jQuery 语法是通过选取 HTML 元素,并对选取的元素执行某些操作。
基础语法: $(selector).action()
- 美元符号定义 jQuery
- 选择符(selector)“查询"和"查找” HTML 元素
- jQuery 的 action() 执行对元素的操作
实例:
-
$(this).hide()- 隐藏当前元素 -
$("p").hide()- 隐藏所有<p>元素 -
$("p.test").hide()- 隐藏所有 class=“test” 的<p>元素 -
$("#test").hide()- 隐藏 id=“test” 的元素
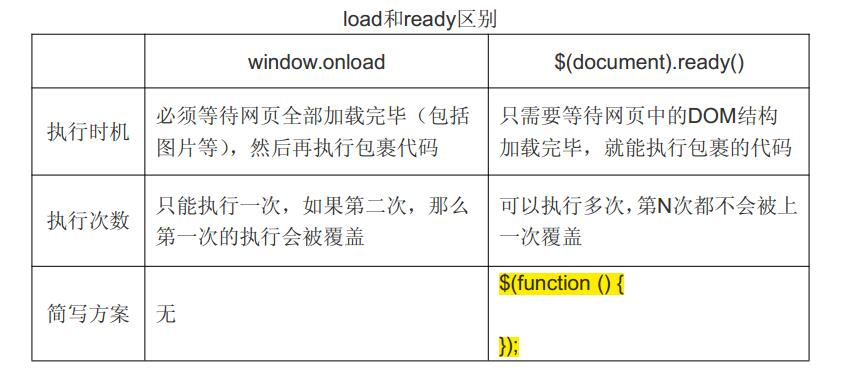
文档就绪时间
你也许已经注意到在我们的实例中的所有 jQuery 函数位于一个 document ready 函数中:
$(document).ready(function(){
// 开始写 jQuery 代码...
});
这是为了防止文档在完全加载(就绪)之前运行 jQuery 代码,即在 DOM 加载完成后才可以对 DOM 进行操作。
你可以理解为:
<script>标签在<body>标签的后面执行
如果在文档没有完全加载之前就运行函数,操作可能失败。下面是两个具体的例子:
- 试图隐藏一个不存在的元素
- 获得未完全加载的图像的大小
提示:简洁写法(与以上写法效果相同):
$(function(){
// 开始写 jQuery 代码...
});
以上两种方式你可以选择你喜欢的方式实现文档就绪后执行 jQuery 方法。
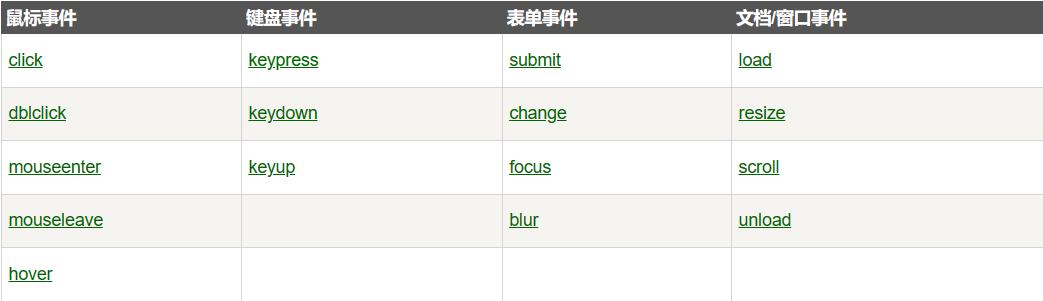
常见的DOM事件:
使用jquery发送Ajax
语法:
$.ajax({name:value, name:value, ... })
参数:
- complete(xhr,status):请求完成时运行的函数(在请求成功或失败之后均调用,即在 success 和 error 函数之后)。
- contentType:发送数据到服务器时所使用的内容类型。默认是:“application/x-www-form-urlencoded”。
- data:规定要发送到服务器的数据。
- dataType:预期的服务器响应的数据类型
- error(xhr,status,error):如果请求失败要运行的函数
- success(result,status,xhr):当请求成功时运行的函数
- type:规定请求的类型(GET 或 POST)
- url:规定发送请求的 URL
< base >:文档根 URL 元素
HTML <base> 元素 指定用于一个文档中包含的所有相对 URL 的根 URL。一份中只能有一个 <base> 元素。
一个文档的基本 URL,可以通过使用 document.baseURI (en-US) 的 JS 脚本查询。
如果文档不包含 <base> 元素,baseURI 默认为 document.location.href(也就是资源的路径,例如http://localhost/zemy_war/test.html这个url的基本URL就是http://localhost/zemy_war)。
文件上传
首先我们要知道一个东西MIME:
在浏览器中,MIME(Multipurpose Internet Mail Extensions)用来标识和处理不同类型的文件和数据。它是一种标准化的方式,用于指示服务器和浏览器如何处理和解释传输的数据。
以下是MIME在浏览器中的主要作用:
-
内容类型识别:通过MIME类型,浏览器可以确定传输的数据的类型。例如,浏览器可以根据MIME类型判断一个文件是HTML文档、图像、音频、视频或其他类型的文件。这样浏览器就能够根据文件类型采取相应的处理方式,如选择正确的插件或使用适当的处理器来展示内容。
-
数据传输:MIME类型指示了数据的编码方式和格式,帮助浏览器正确解析和处理数据。例如,对于文本文件,MIME类型可以指示编码方式(如UTF-8、ISO-8859-1等),以确保浏览器正确地解析文本内容。
-
文件下载:当浏览器接收到服务器返回的文件时,通过MIME类型,浏览器可以确定如何处理该文件。如果浏览器无法直接展示文件内容,它可以选择下载文件或使用适当的应用程序打开。
-
安全性:MIME类型也用于帮助浏览器执行安全策略。浏览器可以根据MIME类型对传入的文件进行验证和检查,以防止潜在的安全威胁。例如,浏览器可以阻止执行具有危险MIME类型的文件,如可执行文件或潜在的恶意脚本。
在前端表单中有三种MIME编码:
- application/x-www-form-urlencoded(默认)
- text/plain
- multipart/form-data
这三种MIME类型指示了不同的表单数据编码方式,它们在表单数据的传输和解析过程中有一些区别:
-
application/x-www-form-urlencoded:这是最常见的表单数据编码方式,默认情况下也是浏览器提交表单时使用的编码方式。在这种编码方式下,表单数据会被编码为键值对的形式,使用key1=value1&key2=value2的格式进行传输。键名和键值会进行URL编码,特殊字符会被转义为%XX的形式。例如,空格会被编码为+或%20。这种编码方式适用于大多数简单的表单数据提交,如搜索表单、登录表单等。 -
text/plain:这种编码方式下,表单数据会被视为纯文本进行传输,不会进行任何编码或转义。每个表单字段的名称和值都会以纯文本的形式传输,字段之间使用换行符分隔。这种编码方式适用于包含特殊字符(如换行符)的文本数据提交,或者需要保留空格和特殊字符原始形式的表单数据。 -
multipart/form-data:这是一种复杂的表单数据编码方式,适用于包含文件上传的场景。在这种编码方式下,表单数据会被分割为多个部分,每个部分包含一个表单字段或一个文件。每个部分都有自己的头部信息,包括字段名称、文件名等。这种编码方式允许同时上传多个文件,并且不会对文件内容进行编码或转义。这种编码方式常用于文件上传功能,如上传图片、上传附件等。
我们在进行文件上传的时候前端就要指定POST请求以及multipart/form-data这种MIME格式。
本项目中前端通过Ajax将文件传给后端:
function uploadDoc(){
$.ajax({
url : "../admin/uploadVipDoc",
data: new FormData($("#form-doc")[0]),
type : "POST",
// 告诉jQuery不要去处理发送的数据,用于对data参数进行序列化处理 这里必须false
processData : false,
// 告诉jQuery不要去设置Content-Type请求头
contentType : false,
success : function(data) {
alert(data.message);
}
});
}
那么我们后端怎么接收前端传递过来的文件呢?
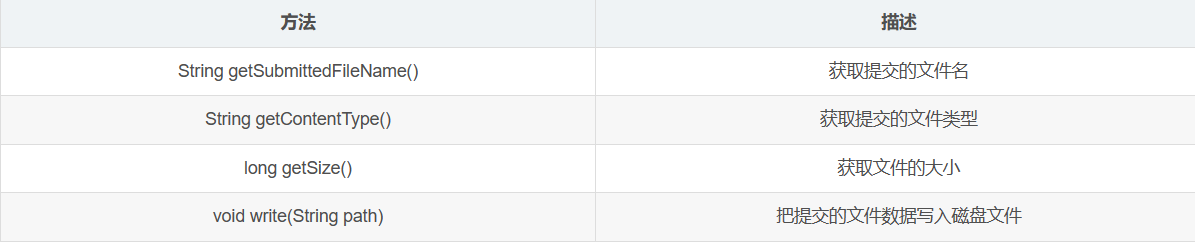
@MultipartConfig表示文件类型的注解,加入这个注解就可以使用对文件处理的Part类方法。
@WebServlet("/upload")
@MultipartConfig
public class UpLoadServlet extends HttpServlet {
@Override
protected void doPost(HttpServletRequest req, HttpServletResponse resp) throws ServletException, IOException {
// 设置编码
req.setCharacterEncoding("UTF-8");
resp.setContentType("text/html; charset=utf-8");
//获取上传到文件
Part file = req.getPart("uploadFile");
//获取文件信息
System.out.println("文件名:" + file.getSubmittedFileName());
System.out.println("文件类型:" + file.getContentType());
System.out.println("文件大小:" + file.getSize());
//把文件写入到磁盘中的指定目录
file.write("d:/test/" + file.getSubmittedFileName());
//返回响应
resp.getWriter().write("文件上传成功:" + file.getSubmittedFileName());
}
}
注意:
- 这里要通过HttpServletRequest中的getPart()来获取上传的文件,而不是getParameter()。
注意:如果前端使用multipart/form-data进行传输,那么servlet中必须使用@MultipartConfig注解之后,才能使用HttpServletRequest.getParameter拿到参数。
附:项目过程中的思考
为什么mysql的驱动要使用Class.forName动态加载?
注意:JDBC4.0以后(mysql-connector-java 5.1.6之后) + java6 以后,不再需要显示调用Class.forName()加载驱动了。因为使用了SPI动态加载机制。
实际上就是为了加载类时,调用静态初始化块中的注册函数,我们可以看看mysql连接件的jar包:
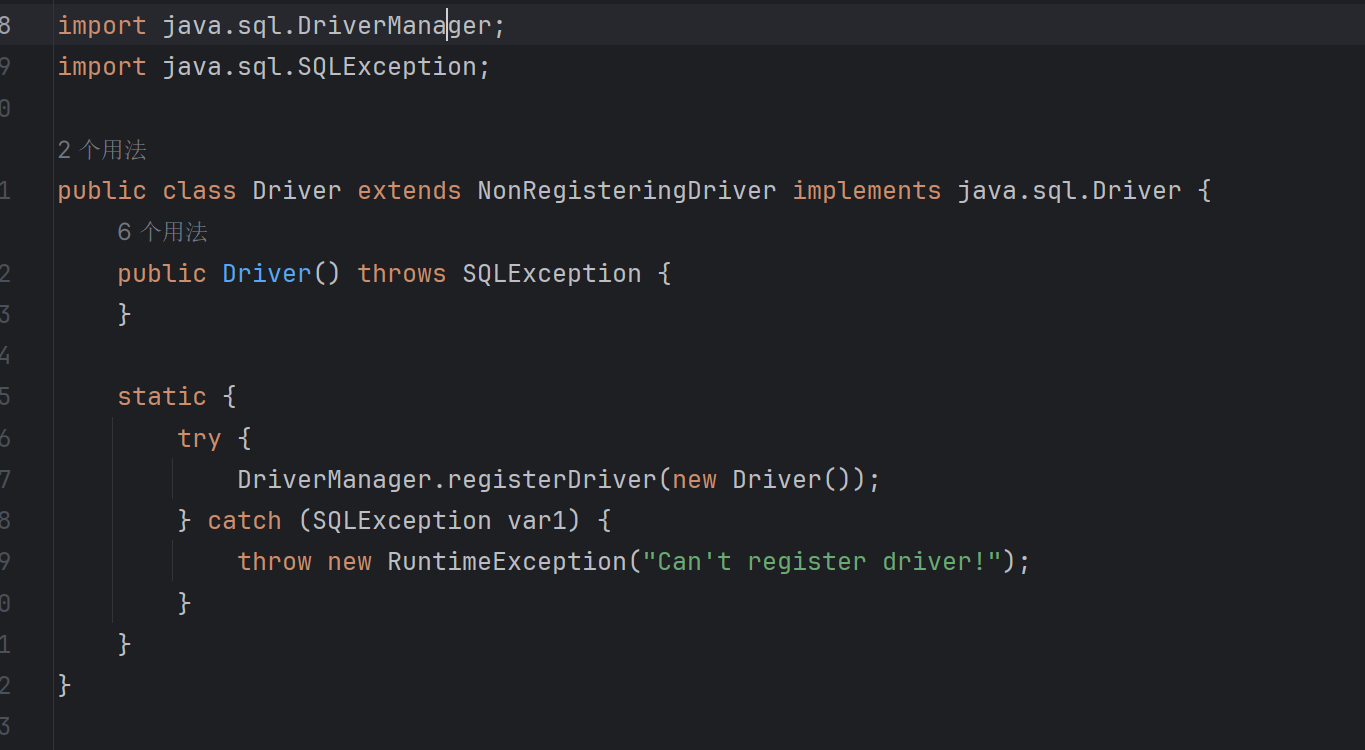
- DriverManager是java提供的一个驱动注册类,第三方驱动只有在这里注册了才能使用。
- java.sql.Driver是java提供的第三方驱动的接口,所有的接入的第三方驱动都要满足
当然我们也可以直接调用DriverManager类中的registerDriver(new com.mysql.jdbc.Driver())来进行驱动的注册,这样就不用Class.forName了。
触发这个静态代码块的方式有很多,你可能会问new也行啊,确实可以,但是没必要,我们可以对比一下几种方式:
Class.forName():将类的.class文件加载到jvm中之外,还会对类进行解释,执行类中的static代码块。
ClassLoader.loadClass():只会将.class文件加载到jvm中,不会执行static中的内容,只有在newInstance才会去执行static块。
new可以粗略地理解为:【加载class文件到jvm + 初始化static代码块】(Class.forName) +构造实例(newInstance)
new相比于Class.forName()多了一个实例化的步骤,然而这个驱动对象我们是使用不到的,创建出来也没有什么用,所以能简则简。
附:项目可改进点
项目初始化阶段
- 缺少对枚举类的应用,例如错误码等信息应该使用枚举类来定义,如此更加规范。
用户登录部分
- 用户的账户、密码是明文保存非常的危险
- 单点登录改进成分布式登录
数据库部分
- 频繁的获取和释放数据库连接非常的消耗资源,所以我们可以使用数据库连接池,例如使用alibaba的Druid
- 动态拼接sql,会涉及到大量的字符串操作,使用原生的String非常的影响性能,可以使用StringBuilder或者StringBuffer进行代替
分页查询部分
-
在分页查询部分其实存在着很多bug,我们自己写分页查询会有很多的疏漏,这是一种浪费时间的造轮子行为。一般在开发中我们一般会使用专业的第三方组件帮助我们完成分页查询的过程。
-
这里我列举本项目中分页查询的bug
- 在使用条件查询的时候分页数是不准确的,并不会随着符合条件的数据量改变总页数,造成该bug的原因是因为我们的分页数是在条件查询之前得出来的(已修复)
-
同时分页查询中我们使用了模糊查询,这个地方并不方便使用
?占位然后通过PreparedStatement去赋值,所以本项目中使用的是字符串拼接,但这就会造成很大的安全性漏洞,例如SQL注入等危险。
公司信息删除
- 为了确保日后数据的恢复以及与运行效率,在一个规范的项目中一般很少直接在数据库中去删除,而是使用逻辑删除。也就是添加一个删除标志位,通过这个标记位来标志数据是否被删除。
README
使用简述:
-
首先创建zemy这个数据库
-
将sql文件夹下的zemy.sql执行(不要使用老师给的数据库,里面的数据有很多问题)【这个步骤需要在idea里面配置好你的数据源】
-
将DBUtils工具类中的数据库账户以及密码改成自己的。
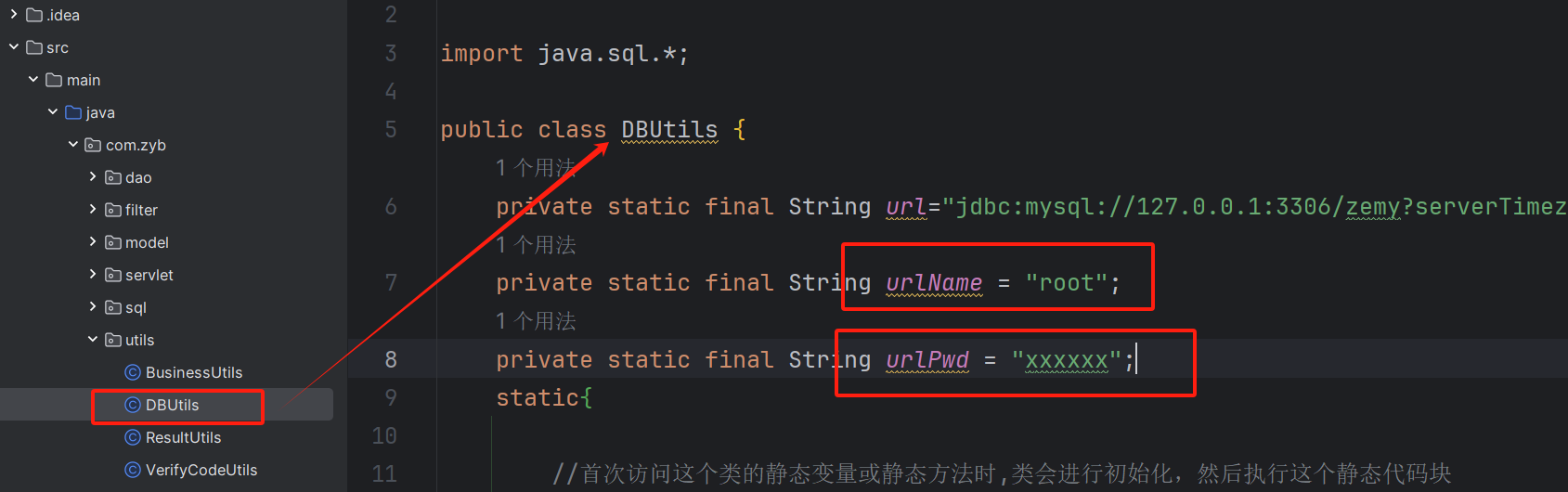
-
接下来将项目部署到Tomcat中即可,如何部署可以看项目初始化中的配置Tomcat一栏,或者看网上的其他教程
注意:
- 老师给的前端代码有很多漏洞,我做了很多修改,所以不要单独把后端拿出来使用
- 国际采购、国际供应、新闻咨询这三个模块我只完成了查功能,增删改的实现方法因为于前面几个模块高度重合所以我并没有进行实现,后续可能会进行补充。