文章目录
- 生产环境监测
- 常见专业名词扫盲
- 服务器平均负载
- 服务器平均负载的定义
- 如何判断平均负载值以及好坏情况
- 如果依据平均负载来判断服务器当前状况
- 系统平均负载和CPU使用率的区别
- CPU上下文切换
- 基本概念
- 3种上下文切换
- 进程上下文切换
- 线程上下文切换
- 中断上下文切换
- 查看上下文切换
- 系统性能分析命令
- vmstat(侦测系统资源的变化,常用于分析CPU整体负载)
- iostat(对磁盘和CPU使用情况的统计查看命令)
- sar
- uptime(查看CPU负载)
- free(评估内存使用情况)
- ping(测试网络连通性和状态)
- netstat -I(查看网络接口状况)
- netstat -r(查看路由)
- ethtool、iftop、nload查看网络带宽使用情况
- 系统性能分析标准
- CPU性能瓶颈定位
- 影响CPU的性能指标
- CPU使用率
- 系统负载
- 上下文切换
- CPU缓存命中率
- CPU性能分析套路
- 简介
- 若使用top发现CPU使用率高
- 若使用top发现CPU平均负载升高
- 若是top命令发现CPU大量软中断
- CPU性能方法论
- 应用程序方面
- 系统优化
- 实践示例
- 若出现内存泄漏
- nginx优化
- 补充一些系统内存参数优化
- 参考文献
生产环境监测
在系统发布到生产环境后,我们必须学会对系统实时情况进行相应监控,以避免一些性能导致导致出现**“你们网站怎么这么卡”,“怎么打开一个页面要这么久的问题”**。
常见专业名词扫盲
服务器平均负载
服务器平均负载的定义
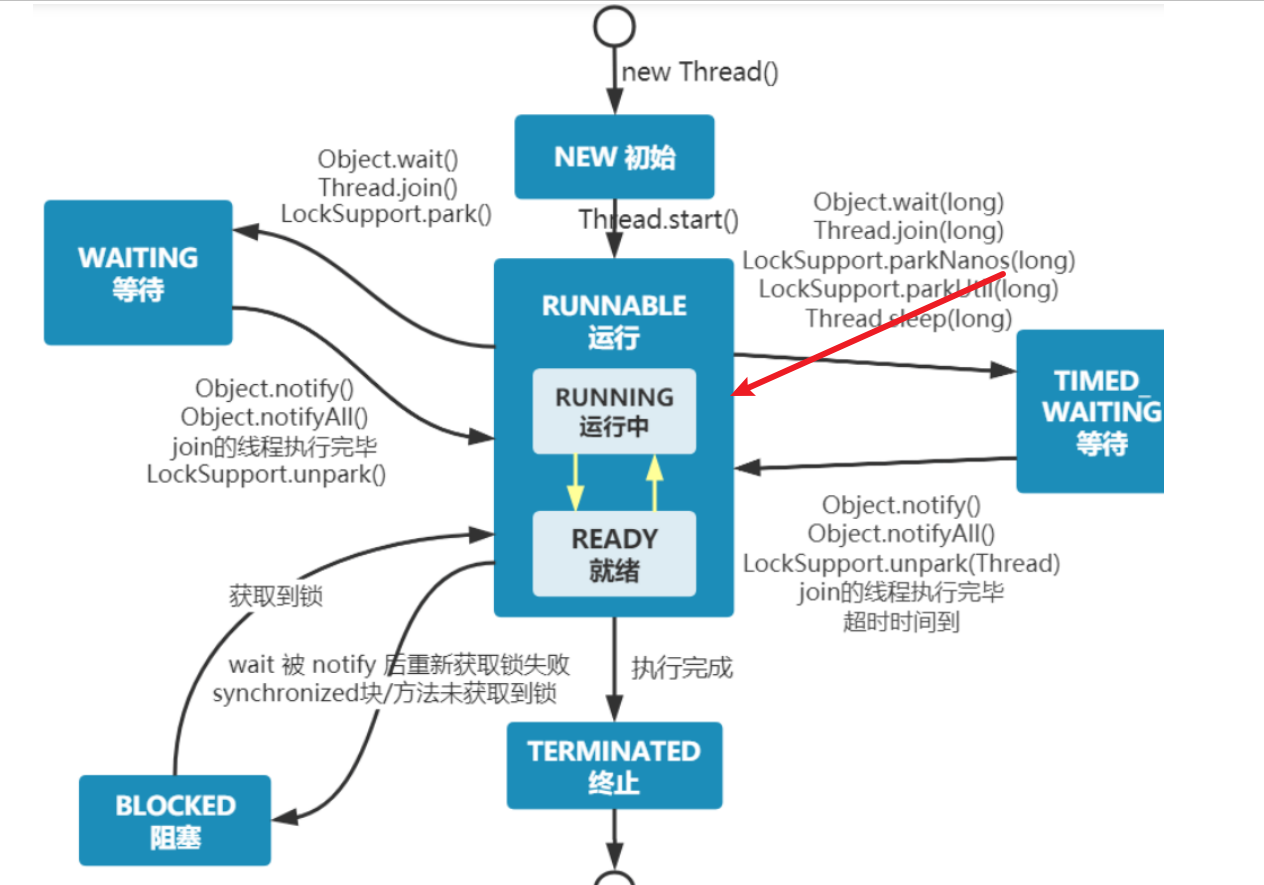
服务器平均负载指的是,某段时间里面,那些处于可运行态或者不可中断状态的进程的平均数。
可运行态:见下图,操作系统线程状态中,处于RUNNING或者READY状态的进程就是可运行态。
不可中断状态:下图中因为I/O而导致处于WAITING状态的进程。那么他们为什么称为不可中断态呢?原因其实也很简单,IO操作时常将一些数据写回本地,若此时将这个IO操作打断,这就很可能磁盘数据和进程数据不一致的情况。
如何判断平均负载值以及好坏情况
我们可以使用top、uptime等指令来查看系统平均负载。
以笔者为例使用top,可以看到load average为0.02, 0.08, 0.06,这就是最近1min、5min、15min的平均负载值。
[root@xxxx~]# top
top - 14:25:43 up 161 days, 19:07, 1 user, load average: 0.02, 0.08, 0.06
Tasks: 94 total, 1 running, 59 sleeping, 0 stopped, 0 zombie
当然,如果我们想看的更加直观也可以使用uptime
[root@xxx~]# uptime
14:27:11 up 161 days, 19:08, 1 user, load average: 0.00, 0.06, 0.06
如果依据平均负载来判断服务器当前状况
理论上平均负载小于或者等于CPU核心数是最佳的,以笔者为例,笔者键入top命令并按1键,就看到一个CPU的使用情况,这就意味者笔者的服务器为单核CPU,这就意味着平均负载小于或者等于都是属于良好的。
%Cpu0 : 1.0 us, 1.7 sy, 0.0 ni, 97.3 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
通过uptime查看,可以看出当前服务器平均负载远远小于1,说明系统平均负载值良好。
[root@iZ8vb7bhe4b8nhhhpavhwpZ ~]# uptime
14:33:18 up 161 days, 19:14, 1 user, load average: 0.43, 0.18, 0.09
小结一下,系统平均负载即单位时间内处于可运行态或者不可中断态的进程的平均数,他和CPU使用率没有直接关系。如果这个值小于或者等于CPU核心数这就说明服务器此时负载情况良好。
例如我们CPU是单核的,若1min内的平均负载为1.8,由 (1.8-1)/1=0.8 可知当前系统超载80%。这时候我们就需要进一步排查系统问题了。
系统平均负载和CPU使用率的区别
CPU使用率代表的是CPU当前繁忙程度和系统平均负载完成是两个概念,系统负载情况和CPU使用率有时候并没有关联关系,或者说CPU使用率高并不一定意味着平均负载就高,这个论点笔者总结了3个情况:
CPU密集型任务,这种情况存在大量可运行态的进程,占用大量CPU资源,有可能导致系统平均负载升高。大量IO阻塞导致不可中断态进程,这种情况很可能导致系统平均负载升高,但不意味着CPU使用率会升高,毕竟IO等待期间CPU并不会参与这些等待。- 某个进程在大量调度工作,这很可能导致CPU繁忙,但是平均负载并不会很高。
CPU上下文切换
基本概念
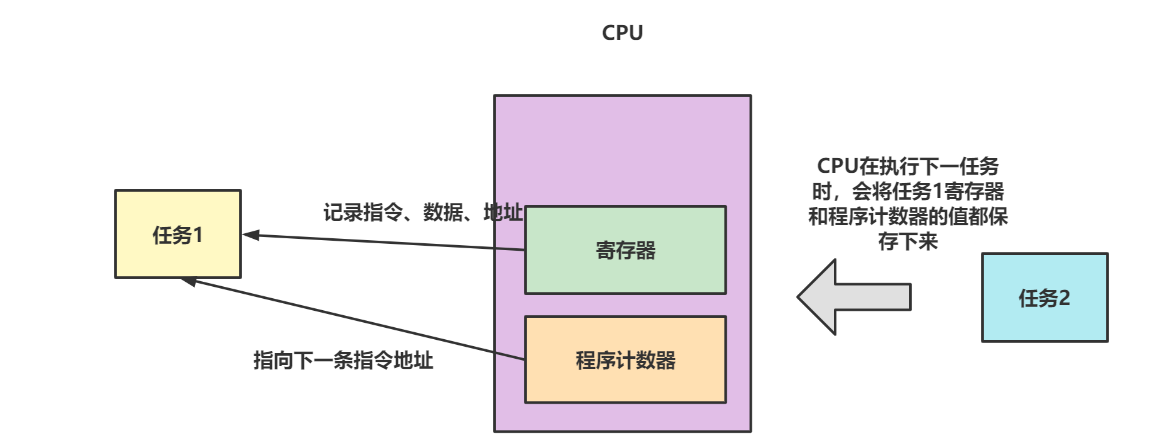
在多进程竞争CPU时,服务器平均负载会升高,而升高的原因也正是因为大量的上下文切换。
如下图,CPU会通过寄存器和程序计数器完成当前任务的工作,当因为某些原因导致CPU上下文切换时,系统就会将要被中断的任务保存到系统内核中。
3种上下文切换
进程上下文切换
进程上下文切换是由操作系统来管理的,当一个新的任务进来时,操作系统就会将当前进程的上下文信息保存到起来。
Linux系统为进程维护一个队列,按照进程优先级、执行时长来对这个运行队列进行排序,然后就会根据某种调度算法完成进程上下文切换。
而进程上下文切换,大概由以下几种情况:
- 在某个进程执行完成了释放CPU后,就会从就绪队列中获取下一个进程。
- 某个进程因为资源不足,而挂起时,就会从就绪队列中获取下一个进程。
- 根据时间分片算法,当前进程执行时间到了,需要切换到下一个进程。
- 进程调用了sleep方法被挂起,系统就会调用其他进程。
- 进程因为硬中断被挂起,之后执行内核中的硬中断程序(硬中断的概念后续会补充)
线程上下文切换
在了解线程上下文切换前,我们必须知道线程的调度的基本单位,而进程确实资源分配的基本单位。这就意味线程是比进程更小的单位。一个进程中可以有一个或多个线程。
所以线程上下文切换分为两种情况:
- 同一个进程中线程上下文切换:这种情况多线程共享同一个线程的数据,但是寄存器和数据是私有的,当发生上下文切换时,这些数据都要被保存起来。
- 不同进程间的上下文切换:这种情况就是进程上下文切换,相比前者来说开销更大一些。
中断上下文切换
为了响应硬件事件,会将进程打断进程去响应硬件实践。注意中断上下文切换指挥记录内核态服务程序所必要的数据信息,对于用户态则不要保存和恢复进程相关的状态。
查看上下文切换
关于查看上下文切换笔者建议使用这两条指令
指令1: vmstat,它可以看到系统上下文切换的整体情况,核心参数如下:
r:正在等待或者运行的CPU任务数,如果这个数量超过CPU的数量很可能出现性能问题
b: 处于IO的进程数量。
in: 每秒系统中断的次数,包括时钟中断次数在内。
cs: 每秒发生的上下文切换次数,这个值越小越好。
指令示例
vmstat
procs -----------memory---------- ---swap-- -----io---- -system-- ------cpu-----
r b swpd free buff cache si so bi bo in cs us sy id wa st
3 0 0 344172 233584 1141036 0 0 0 3 2 2 1 1 98 0 0
上面的指令只能看到上下文切换的整体情况,若想看到每个进程的使用情况,我们建议使用pidstat
如下所示,可以看到pid为1的进程,主动上下文切换每秒0.81次,非资源上下文次数为0次。
[root@iZ8vb7bhe4b8nhhhpavhwpZ ~]# pidstat -w 5
Linux 4.19.91-24.1.al7.x86_64 (iZ8vb7bhe4b8nhhhpavhwpZ) 10/30/2022 _x86_64_ (1 CPU)
04:11:00 PM UID PID cswch/s nvcswch/s Command
04:11:05 PM 0 1 0.81 0.00 systemd
系统性能分析命令
vmstat(侦测系统资源的变化,常用于分析CPU整体负载)
[root@study ~]# vmstat [-a] [ 延 迟] [ 总计侦测 次 数 ] <==CPU/内存等信息
[root@study ~]# vmstat [ -fs] <==内存相关
[root@study ~]# vmstat [ -S 单位] <==设定显示数据的单位
[root@study ~]# vmstat [-d] <==与磁盘有关
[root@study ~]# vmstat [-p 分区槽 ] <==与磁盘有关
选项与参数:
-a :使用 inactive/active(活跃与否) 取代 buffer/cache 的内存输出信息;
-f :开机到目前为止,系统复制 (fork) 的进程数;
-s :将一些事件 (开机至目前为止) 导致的内存变化情况列表说明;
-S :后面可以接单位,让显示的数据有单位。例如 K/M 取代 bytes 的容量;
-d :列出磁盘的读写总量统计表
-p :后面列出分区槽,可显示该分区槽的读写总量统计表
使用该命令我们可以对CPU性能进行评估,查看系统资源变化情况,两秒一次输出3次
[root@localhost zhangshiyu]# vmstat 2 3
# 输出结果
# r表示运行和等待CPU时间片的进程数,若这个值长期大于CPU个数说明CPU个数不足需要增加CPU
# 即等待资源的进程数,例如等待io或者内存交换的进程
# memory相关
# swpd表示使用的虚拟内存数量,这个值若不为0且若si so长期为0,那基本可以放心,它不会影响系统内存的使用情况
# free 表示空闲的内存
# buff 缓冲区缓存的内存数量
# cache 表示页面缓存的内存数量,一般被频繁访问的页都会被缓存,如果缓存的数量较大,且io的bi较小,就说明文件系统的效率较好
# swap相关
# si表示内存调入交换区的刷量
# so表示由交换区写入内存的数量
# 注意,若上述这两个值长期不为0则说明需要增加内存了
# io表示磁盘读写情况
# bi 表示读磁盘的数量
# bo表示写入数据到磁盘的数量
# 假如我们bi bo数值较大,且wa较大则说明磁盘io性能较差,需要考虑对磁盘做调整了
# system
# in 表示某段时间磁盘中断次数
# cs 表示每秒上下文切换次数
# cpu相关
# us 用户进程所占用cpu时间比
# sy 系统进程所占用cpu时间比
# id cpu空闲所占时间比
# wa cpu等待io所占时间比
# 当us大于50%就说明用户进程过多,我们需要对用户进程进行进程优化或者进程优先级重排序了
# 当us+sy大于80%就就说明CPU资源可能不足了
# 当wa大于20%就说明io等待严重需要对磁盘控制器性能进行评估了
procs -----------memory---------- ---swap-- -----io---- -system-- ------cpu-----
r b swpd free buff cache si so bi bo in cs us sy id wa st
1 0 127232 76072 0 243072 0 0 10 0 13 18 0 0 100 0 0
0 0 127232 76056 0 243072 0 0 0 1 102 146 0 0 100 0 0
0 0 127232 76056 0 243072 0 0 0 0 93 130 0 0 100 0 0
iostat(对磁盘和CPU使用情况的统计查看命令)
iostat [ -c | -d ] [ -k ] [ -t ] [ -x [ device ] ] [ interval [ count ] ]
各个选项及参数含义如下。
-c:显⽰CPU的使⽤情况。
-d:显⽰磁盘的使⽤情况。
-k:每秒以千字节为单位显⽰数据。
-t:输出统计信息开始执⾏的时间。
-x device:指定要统计的磁盘设备名称,默认为所有的磁盘设备。
interval:指定两次统计间隔的时间。
count:按照“interval”指定的时间间隔统计的次数
如下所示每个2s输出一次,输出3次
[root@localhost zhangshiyu]# iostat -d 2 3
Linux 3.10.0-1160.el7.x86_64 (localhost.localdomain) 07/10/2022 _x86_64_ (6 CPU)
# kB_read/s 每秒读取的数据块数
# kB_wrtn/s 每秒写的数据块数
# kB_read 数据块读取总数
# kB_wrtn 数据块写的总数
Device: tps kB_read/s kB_wrtn/s kB_read kB_wrtn
sda 1.08 65.76 2.80 5941960 253198
dm-0 1.05 65.38 1.05 5907837 94946
dm-1 0.48 0.22 1.71 19788 154136
Device: tps kB_read/s kB_wrtn/s kB_read kB_wrtn
sda 0.50 3.98 0.00 8 0
dm-0 0.50 3.98 0.00 8 0
dm-1 0.00 0.00 0.00 0 0
Device: tps kB_read/s kB_wrtn/s kB_read kB_wrtn
sda 0.00 0.00 0.00 0 0
dm-0 0.00 0.00 0.00 0 0
dm-1 0.00 0.00 0.00 0 0
sar
sar命令可以很直观的看到系统CPU、运行队列、磁盘io、交换区内存、内存、网络等各个性能相关数据
sar [options] [-o filename] [interval [count] ]
各个选项及参数含义如下。
options 为命令⾏选项,sar命令的选项很多,下⾯只列出常⽤选项:
-A:显⽰系统所有资源设备(CPU、内存、磁盘)的运⾏状况。
-u:显⽰系统所有CPU在采样时间内的负载状态。
-P:显⽰当前系统中指定CPU的使⽤情况。
-d:显⽰系统所有硬盘设备在采样时间内的使⽤状况。
-r:显⽰系统内存在采样时间内的使⽤状况。
-b:显⽰缓冲区在采样时间内的使⽤情况。
-v:显⽰进程、⽂件、inode节点和锁表状态。
-n:显⽰⽹络运⾏状态。参数后⾯可跟DEV、EDEV、SOCK和
FULL。DEV显⽰⽹络接⼜信息,EDEV显⽰⽹络错误的统计数据,SOCK
显⽰套接字信息,FULL显⽰以上三个信息。它们可以单独或者⼀起使⽤。
-q:显⽰运⾏队列的⼤⼩,它与系统当时的平均负载相同。
-R:显⽰进程在采样时间内的活动情况。
-y:显⽰终端设备在采样时间内的活动情况。
-w:显⽰系统交换活动在采样时间内的状态。
-o filename:表⽰将命令结果以⼆进制格式存放在⽂件中,filename是
⽂件名。
interval:表⽰采样间隔时间,是必须有的参数。
count:表⽰采样次数,是可选参数,默认值是1。
查看CPU负载情况,每个三秒输出依次,输出5次
[root@localhost zhangshiyu]# sar -u 3 5
Linux 3.10.0-1160.el7.x86_64 (localhost.localdomain) 07/10/2022 _x86_64_ (6 CPU)
10:08:28 PM CPU %user %nice %system %iowait %steal %idle
10:08:31 PM all 0.00 0.00 0.06 0.00 0.00 99.94
10:08:34 PM all 0.00 0.00 0.06 0.00 0.00 99.94
10:08:37 PM all 0.06 0.00 0.11 0.00 0.00 99.83
10:08:40 PM all 0.00 0.00 0.06 0.00 0.00 99.94
10:08:43 PM all 0.06 0.00 0.11 0.06 0.00 99.78
Average: all 0.02 0.00 0.08 0.01 0.00 99.89
输出第一颗CPU负载情况(CPU从0开始算,第一个即为0),所以这个指令也是对单个CPU进行性能分析的有效工具
[root@localhost zhangshiyu]# sar -P 0 3 5
Linux 3.10.0-1160.el7.x86_64 (localhost.localdomain) 07/10/2022 _x86_64_ (6 CPU)
10:10:38 PM CPU %user %nice %system %iowait %steal %idle
10:10:41 PM 0 0.00 0.00 0.00 0.00 0.00 100.00
10:10:44 PM 0 0.00 0.00 0.00 0.00 0.00 100.00
10:10:47 PM 0 0.00 0.00 0.00 0.00 0.00 100.00
10:10:50 PM 0 0.00 0.00 0.00 0.00 0.00 100.00
10:10:53 PM 0 0.00 0.00 0.00 0.00 0.00 100.00
Average: 0 0.00 0.00 0.00 0.00 0.00 100.00
查看磁盘使用情况,3秒输出一次,输出5次
[root@localhost zhangshiyu]# sar -d 3 5
Linux 3.10.0-1160.el7.x86_64 (localhost.localdomain) 07/10/2022 _x86_64_ (6 CPU)
10:11:14 PM DEV tps rd_sec/s wr_sec/s avgrq-sz avgqu-sz await svctm %util
10:11:17 PM dev8-0 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
10:11:17 PM dev253-0 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
10:11:17 PM dev253-1 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
10:11:17 PM DEV tps rd_sec/s wr_sec/s avgrq-sz avgqu-sz await svctm %util
10:11:20 PM dev8-0 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
10:11:20 PM dev253-0 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
10:11:20 PM dev253-1 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
10:11:20 PM DEV tps rd_sec/s wr_sec/s avgrq-sz avgqu-sz await svctm %util
10:11:23 PM dev8-0 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
10:11:23 PM dev253-0 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
10:11:23 PM dev253-1 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
10:11:23 PM DEV tps rd_sec/s wr_sec/s avgrq-sz avgqu-sz await svctm %util
10:11:26 PM dev8-0 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
10:11:26 PM dev253-0 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
10:11:26 PM dev253-1 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
10:11:26 PM DEV tps rd_sec/s wr_sec/s avgrq-sz avgqu-sz await svctm %util
10:11:29 PM dev8-0 3.67 10.67 66.33 21.00 0.00 0.91 0.18 0.07
10:11:29 PM dev253-0 4.33 10.67 66.33 17.77 0.00 0.92 0.15 0.07
10:11:29 PM dev253-1 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
Average: DEV tps rd_sec/s wr_sec/s avgrq-sz avgqu-sz await svctm %util
Average: dev8-0 0.73 2.13 13.27 21.00 0.00 0.91 0.18 0.01
Average: dev253-0 0.87 2.13 13.27 17.77 0.00 0.92 0.15 0.01
Average: dev253-1 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
查看系统内存使用情况
[root@localhost zhangshiyu]# sar -r 5 2
Linux 3.10.0-1160.el7.x86_64 (localhost.localdomain) 07/10/2022 _x86_64_ (6 CPU)
10:12:16 PM kbmemfree kbmemused %memused kbbuffers kbcached kbcommit %commit kbactive kbinact kbdirty
10:12:21 PM 61632 934072 93.81 0 221380 4138808 133.82 273440 389208 4
10:12:26 PM 61632 934072 93.81 0 221380 4138808 133.82 273440 389208 4
Average: 61632 934072 93.81 0 221380 4138808 133.82 273440 389208 4
查看网络使用情况
#IFACE 本地网卡接口的名称
#rxpck/s 每秒钟接受的数据包
#txpck/s 每秒钟发送的数据库
#rxKB/S 每秒钟接受的数据包大小,单位为KB
#txKB/S 每秒钟发送的数据包大小,单位为KB
#rxcmp/s 每秒钟接受的压缩数据包
#txcmp/s 每秒钟发送的压缩包
#rxmcst/s 每秒钟接收的多播数据包
[root@localhost zhangshiyu]# sar -n DEV 5 3
Linux 3.10.0-1160.el7.x86_64 (localhost.localdomain) 07/10/2022 _x86_64_ (6 CPU)
10:14:34 PM IFACE rxpck/s txpck/s rxkB/s txkB/s rxcmp/s txcmp/s rxmcst/s
10:14:39 PM lo 0.00 0.00 0.00 0.00 0.00 0.00 0.00
10:14:39 PM virbr0-nic 0.00 0.00 0.00 0.00 0.00 0.00 0.00
10:14:39 PM virbr0 0.00 0.00 0.00 0.00 0.00 0.00 0.00
10:14:39 PM ens33 0.20 0.00 0.03 0.00 0.00 0.00 0.00
10:14:39 PM IFACE rxpck/s txpck/s rxkB/s txkB/s rxcmp/s txcmp/s rxmcst/s
10:14:44 PM lo 0.00 0.00 0.00 0.00 0.00 0.00 0.00
10:14:44 PM virbr0-nic 0.00 0.00 0.00 0.00 0.00 0.00 0.00
10:14:44 PM virbr0 0.00 0.00 0.00 0.00 0.00 0.00 0.00
10:14:44 PM ens33 0.40 0.40 0.05 0.06 0.00 0.00 0.00
10:14:44 PM IFACE rxpck/s txpck/s rxkB/s txkB/s rxcmp/s txcmp/s rxmcst/s
10:14:49 PM lo 0.00 0.00 0.00 0.00 0.00 0.00 0.00
10:14:49 PM virbr0-nic 0.00 0.00 0.00 0.00 0.00 0.00 0.00
10:14:49 PM virbr0 0.00 0.00 0.00 0.00 0.00 0.00 0.00
10:14:49 PM ens33 0.20 0.20 0.01 0.03 0.00 0.00 0.00
Average: IFACE rxpck/s txpck/s rxkB/s txkB/s rxcmp/s txcmp/s rxmcst/s
Average: lo 0.00 0.00 0.00 0.00 0.00 0.00 0.00
Average: virbr0-nic 0.00 0.00 0.00 0.00 0.00 0.00 0.00
Average: virbr0 0.00 0.00 0.00 0.00 0.00 0.00 0.00
Average: ens33 0.27 0.20 0.03 0.03 0.00 0.00 0.00
uptime(查看CPU负载)
例如笔者服务器为单核CPU,若平均负载大于1则说明CPU繁忙,如下所示,此时CPU负载情况还算空闲
[zhangshiyu@localhost ~]$ uptime
23:08:03 up 1 day, 57 min, 3 users, load average: 0.20, 0.06, 0.06
free(评估内存使用情况)
如下所示,以M为单位查看内存使用情况,我们可以看出可用内存为130M,差不多为内存的14%,说明我们的内存可能有些不足了需要考虑加大内存了。我们评估的标准是可用内存大于20%基本资源可以满足需求
[root@localhost zhangshiyu]# free -m
total used free shared buff/cache available
Mem: 972 681 84 19 206 130
Swap: 2047 138 1909
ping(测试网络连通性和状态)
如下所示,时间基本在16毫秒,0% packet loss的丢包率,网络状态还算可观
[root@iZ8vb7bhe4b8nhhhpavhwpZ ~]# ping -c 3 www.baidu.com
PING www.a.shifen.com (110.242.68.3) 56(84) bytes of data.
64 bytes from 110.242.68.3 (110.242.68.3): icmp_seq=1 ttl=50 time=16.8 ms
64 bytes from 110.242.68.3 (110.242.68.3): icmp_seq=2 ttl=50 time=16.9 ms
64 bytes from 110.242.68.3 (110.242.68.3): icmp_seq=3 ttl=50 time=16.9 ms
--- www.a.shifen.com ping statistics ---
3 packets transmitted, 3 received, 0% packet loss, time 2001ms
rtt min/avg/max/mdev = 16.875/16.918/16.951/0.153 ms
netstat -I(查看网络接口状况)
[root@localhost zhangshiyu]# netstat -I
Kernel Interface table
Iface表⽰⽹络设备的接⼜名称。
MTU表⽰最⼤传输单元,单位为字节。
RX-OK/TX-OK表⽰已经准确⽆误地接收/发送了多少数据包。
RX-ERR/TX-ERR表⽰接收/发送数据包时产⽣了多少错误。
RX-DRP/TX-DRP表⽰接收/发送数据包时丢弃了多少数据包。
RX-OVR/TX-OVR表⽰由于误差⽽遗失了多少数据包。
Flg表⽰接⼜标记。其中,各个选项的含义如下。
L表⽰该接⼜是个回环设备。
B表⽰设置了⼴播地址。
M表⽰接收所有数据包。
R表⽰接⼜正在运⾏。
U表⽰接⼜处于活动状态。
O表⽰在该接⼜上禁⽤arp。
P表⽰⼀个点到点的连接。
Iface MTU RX-OK RX-ERR RX-DRP RX-OVR TX-OK TX-ERR TX-DRP TX-OVR Flg
ens33 1500 35195 0 0 0 2756 0 0 0 BMRU
lo 65536 3260 0 0 0 3260 0 0 0 LRU
virbr0 1500 0 0 0 0 0 0 0 0 BMU
netstat -r(查看路由)
[root@localhost zhangshiyu]# netstat -r
Kernel IP routing table
Destination Gateway Genmask Flags MSS Window irtt Iface
default gateway 0.0.0.0 UG 0 0 0 ens33
192.168.0.0 0.0.0.0 255.255.255.0 U 0 0 0 ens33
192.168.122.0 0.0.0.0 255.255.255.0 U 0 0 0 virbr0
ethtool、iftop、nload查看网络带宽使用情况
如果我们对服务器带宽质量存疑的话,可以用这三条命令了解详情
ethtool eth0
iftop可以查看实时网络使用情况
iftop
nload则是查看进入和出网卡的流量
nload eth0
输出结果如下所示
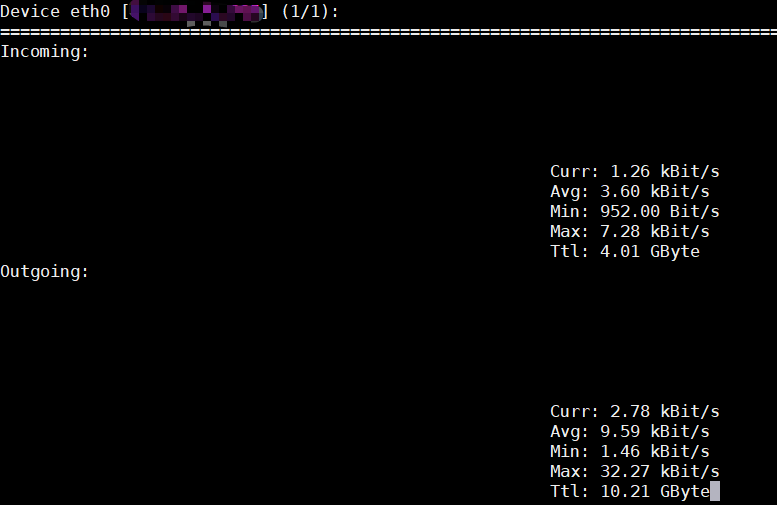
Incoming也就是进入网卡的流量,Outgoing也就是从这块网卡出去的流量,每一部分都有下面几个。
Curr:当前流量
Avg:平均流量
Min:最小流量
Max:最大流量
Ttl:总流量
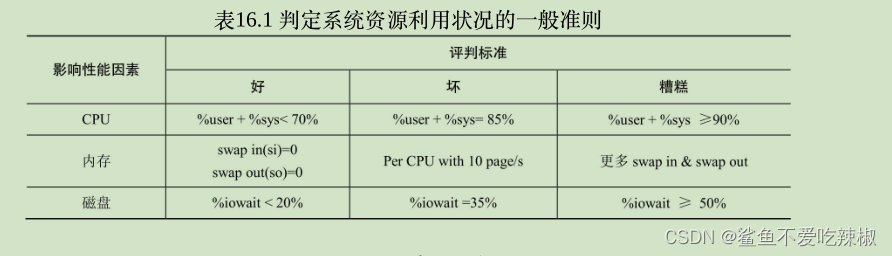
系统性能分析标准
了解性能分析标准前,我必须了解几个系统参数
%user:表示用户模式下消耗CPU所占的时间比
%sys:系统模式下消耗时间所占百分比
si:从磁盘写入交换区内存的数量
so:从交换区内存写入磁盘的数量
iowait表示系统等待输入输出完成所占时间的百分比
CPU性能瓶颈定位
影响CPU的性能指标
CPU使用率
- 用户CPU使用率:在用户态运行时间所占CPU运行时间的百分比。这个值越大则说明用户的应用程序很繁忙。
- 系统CPU使用率:在内核态运行的时间所占CPU运行时间所占比,这个值越大说明系统内核很繁忙。
- 等待I/O的CPU使用率:等待IO时间所占CPU运行时间占比,这个值越大说明当前程序大量时间处于和硬件设备交互。
- 硬中断CPU使用率:硬中断即将数据从DMA缓冲区将数据拷贝到网络中断程序时段。
- 软中断CPU使用率:软中断即将网络中断程序将缓冲数据拷贝到系统内核这一时段,这个值越大就以为着系统内部发生中断的次数越大。
我们可以通过pidstat来查看每个应用用户CPU使用率和系统CPU使用率,如下所示对应分别为 %usr 、%system
[root@iZ8vb7bhe4b8nhhhpavhwpZ ~]# pidstat
Linux 4.19.91-24.1.al7.x86_64 (iZ8vb7bhe4b8nhhhpavhwpZ) 10/30/2022 _x86_64_ (1 CPU)
04:16:15 PM UID PID %usr %system %guest %CPU CPU Command
04:16:15 PM 0 1 0.01 0.01 0.00 0.01 0 systemd
系统负载
这个上文已经长篇介绍过了,不多赘述。
上下文切换
这个上文已经长篇介绍过了,不多赘述。
CPU缓存命中率
提高CPU缓存命中率的文章笔者之前也详细描述过,感兴趣的读者可以看看下面这篇文章,整体来说提高CPU缓存命中率的手段有两个:
1. 学会将常见的数据存放到cache line中避免置换
2. 在if/else逻辑中将常见的逻辑放到第一个if上,提高分支预测器的命中率
提高CPU缓存命中率知识小结
CPU性能分析套路
简介
通常笔者建议使用这3条命令作为核心展开性能问题排查:
- top:查看CPU使用率、平均负载、僵尸进程等。
- vmstate:查看上下文切换、总段次数、运行状态和不可中断状态的进程数。
- pidstat:查看用户态、内核态、自愿和非自愿上限切换次数。
若使用top发现CPU使用率高
- 使用top命令查看用户性能指标,如果用户CPU使用率过高,则使用pidstatt定位程序的CPU使用率情况。
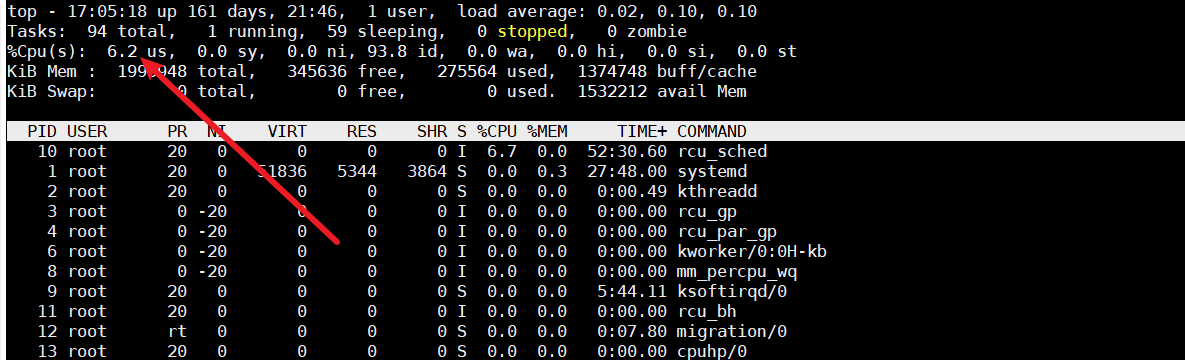
- 使用pidstat以及pidstat -w查看每个应用程序的使用详情
若使用top发现CPU平均负载升高
- 使用top定位发现CPU平均负载过高。平均负载高就意味着两种情况,一种是某个进程比较繁忙,另一个就是进程数过多或者IO情况过多。这时候我们就需要使用vmstat来定位
如果是r多,则说明运行状态进程多,若b多则说明不可中断进程多。
[root@iZ8vb7bhe4b8nhhhpavhwpZ ~]# vmstat
procs -----------memory---------- ---swap-- -----io---- -system-- ------cpu-----
r b swpd free buff cache si so bi bo in cs us sy id wa st
2 0 0 346220 233584 1141172 0 0 0 3 3 3 1 1 98 0 0
- 根据上文分析若是r多导致卡顿,则使用pidstat进行进程分析即可。
- 若是b过多则说明IO情况比较多,则需要配合sar命令确定%iowait。
若是top命令发现CPU大量软中断
这个就可以参考笔者之前写的这篇文章了内容比较详细
CPU软中断小结
CPU性能方法论
应用程序方面
- 编译器优化
- 算法优化
- 异步处理
- 多线程替代多进程
- 利用好缓存
系统优化
- CPU绑定:将进程绑定到指定的CPU上,提高缓存命中率提高程序执行效率。
- CPU独占
- 调整进程优先级,使用nice等命令调整进程优先级,参考Linux进程管理
实践示例
若出现内存泄漏
应用程序可以访问用户空间以及内存段,内存段分为:只读内存段、数据内存段、堆内存段、栈内存段、文件映射段
1. 只读内存段:将用户常量或者程序代码保存的地方,不会出现内存泄漏。
2. 数据内存段:常用于存储全局变量或者静态变量等,数据基本不变,不会导致泄漏。
3. 栈内存段:由操作系统分配的,如果大小超过指定空间就会被回收
4. 堆内存段:应用程序常会创建大小未知的对象,这都是基于操作系统的malloc创建的,所以需要用户手动管理,若没有及时清理很可能导致内存泄漏
5. 文件映射段:和堆内存段差不多,每个应用程序都有自己的共享内存以及动态链接库,若使用不当也可能造成内存泄漏。
这类问题,我们该如何推断出呢?
- 首先通过
top命令查看内存使用情况,如下图所示
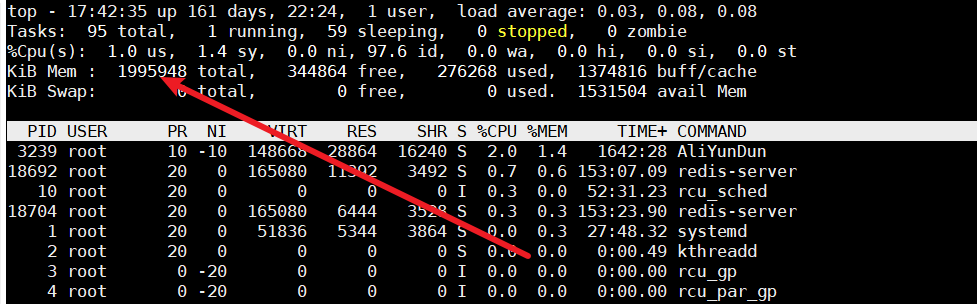
- 若过高则使用
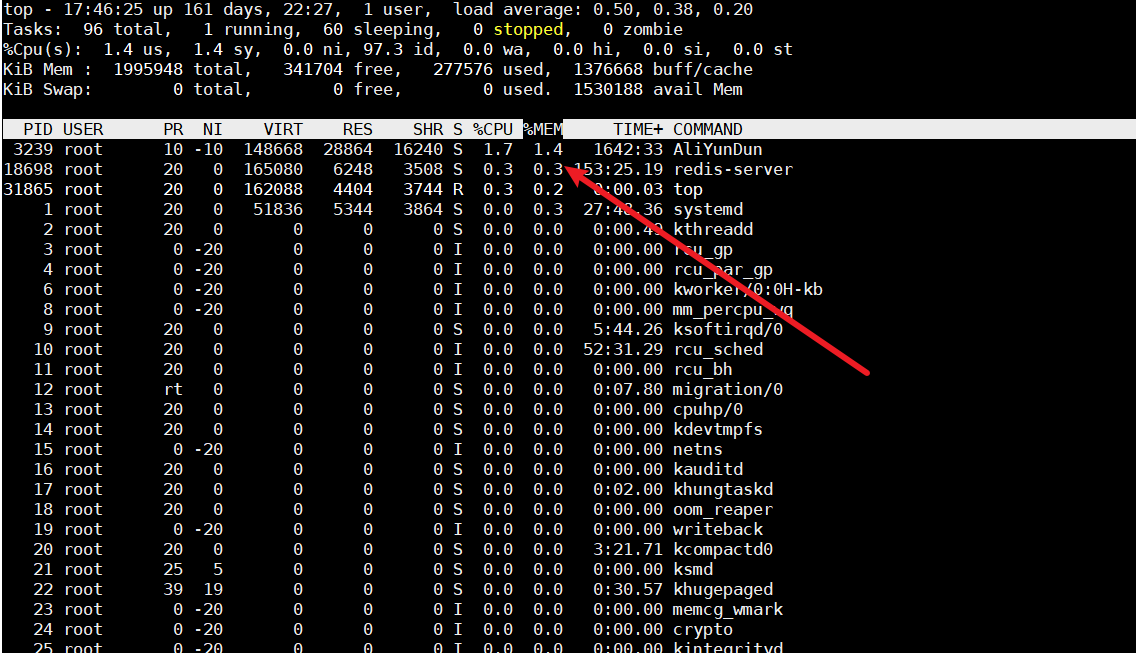
vmstate 5监控当前服务器内存的变化,若不断上升则说明有程序内存泄漏了 - 然后我们再回到top看看是哪个
pid的进程mem使用率过高,逐个排查
nginx优化
对于上述的表述可能过于抽象,近期笔者基于此理论思路对nginx服务器进行了优化,整体优化指令和思考方向都与本篇文章大抵相同,感兴趣的读者可以看看
Nginx性能优化
补充一些系统内存参数优化
系统安装完成后,优化⼯作并没有结束。接下来。还可以对系统内核参数进⾏优化。不过,内核参数的优化要和系统中部署的应⽤结合起来整体考虑。例如,如果系统部署的是Oracle 数据库应⽤,那么就需要对系统共享内存段(kernel.shmmax、kernel.shmmni、kernel.shmall)、系统信号量(kernel.sem)、⽂件句柄(fs.file-max)等参数进⾏优化设置;如果部署的是 Web 应⽤,那么就需要根据 Web 应⽤特性进⾏⽹络参数的优化,例如,
net.ipv4.ip_local_ port_range决定该服务器向外连接(即以客户端的身份)的端口范围,同样根据这个范围我们可以知道客户端连接到这台服务器同一个端口的连接数为28231
cat /proc/sys/net/ipv4/ip_local_port_range
32768 60999
net.ipv4.tcp_tw_reuse决定处于TIME-WAIT的socket连接是否可以用于新的tcp连接
[zhangshiyu@localhost ~]$ cat /proc/sys/net/ipv4/tcp_tw_reuse
# 输出结果默认0,表示关闭
0
net.core.somaxconn表示当前系统中未完全建立连接关系tcp连接,这些连接都会被存放到一个backlog队列中,然后交由socket server一次性将这些连接处理掉。当server处理速度较慢时,既有可能出现backlog队列被填满,导致大量连接被拒绝。所以设置合适数量的连接数也是很重要的。
[root@localhost zhangshiyu]# cat /proc/sys/net/core/somaxconn
# 该连接数默认为128
128
参考文献
鸟哥的Linux私房菜
循序渐进Linux(第2版)
net.ipv4.ip_local_port_range到底是干啥的?
[656]linux查看服务器带宽