本文整理自火山引擎云原生计算研发工程师王正和闵中元在本次 CommunityOverCode Asia 2023 数据湖专场中的《基于 Flink 构建实时数据湖的实践》主题演讲。
实时数据湖是现代数据架构的核心组成部分,随着数据湖技术的发展,用户对其也有了更高的需求:需要从多种数据源中导入数据、数据湖与数据源保持实时与一致、在发生变更时能够及时同步,同时也需要高性能查询,秒级返回数据等。所以我们选择使用 Flink 进行出入湖以及 OLAP 查询。Flink 的批流一体架构、Exactly Once 保证和完善的社区生态提供了众多 Connector 可以满足前面的需求。Flink 也同样适合 OLAP 查询,这一点将在本文进行详细介绍。
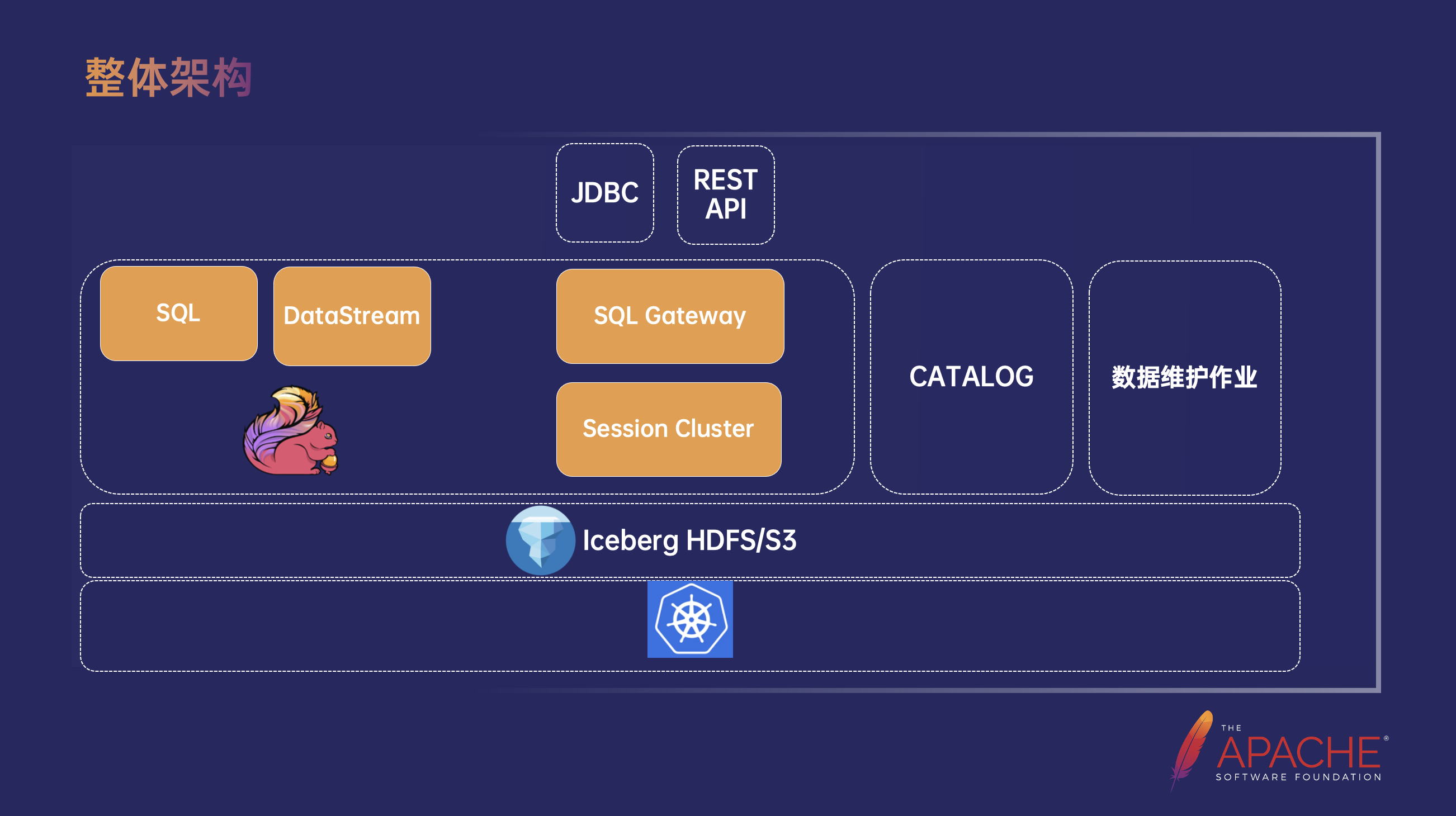
整体架构
在基于 Flink 构建实时数据湖的整体架构中,底层使用 K8s 作为容器编排和管理平台。存储层支持 HDFS 或 S3。由于 Iceberg 良好的文件组织架构和生态,所以选择了 Iceberg 作为 Table Format。计算层则使用 Flink 进行出入湖,其中 Flink SQL 是最常用的出入湖方式,同时也用 Flink Datastream API 开发了一些高阶功能,出入湖的作业使用 Flink Application Mode 运行在 K8s 上。然后通过 Flink SQL Gateway 和 Session Mode 的 Flink Cluster 进行 OLAP 查询,提供了 JDBC 和 REST API 两种接口的返回结果。当然我们也需要使用 Catalog 管理元数据,这里不仅仅指 Iceberg 的元数据,还包括了其他第三方数据源的元数据,并利用定时任务进行后续的数据维护。
数据入湖实践

在数据入湖时 Flink 从左边的数据源获取数据,通过流或批的方式写入到 Iceberg 中。Iceberg 本身也提供了几种 Action 进行数据维护,所以针对每张表都会有数据过期、快照过期、孤儿文件清理、小文件的合并等定时调度任务,这些 Action 在实践过程中对性能的提升有很大帮助。
针对 Schema 固定,目的表也存在表到目的表的情形,通常使用 Flink SQL 进行数据导入和导出、可以写临时表,也可以把元数据存储到 Catalog 中,使用 Catalog Table 进行数据导入导入。但是为了满足客户更复杂的需求,在实践过程中我们基于 Datastream API 开发了 CDC Schema 自动变更,可以实现整库同步+自动建表的功能。
Flink SQL

Iceberg 社区支持了基本的写入和读取功能。Flink 1.17 引入了行级更新和删除的功能(FLIP-282),我们在此基础上增加了批量 Upate 和 Delete 操作,通过 RowLevelModificationScanContext 接口实现 Iceberg 的行级更新。实践过程中,通过在 Context 中记录了两个信息——事务开始时的 Snapshot ID,以及 UPDATE/DELETE 的过滤条件,用于保证批式 Update 和 Delete 的事务性。
Schema Evolution

Schema 演进是流处理中一个常见的问题,即通过在流作业过程中动态变更目的端的 Schema 保证数据的正确写入。Iceberg 本身对 Schema 变更有很好的支持。在 Iceberg 的存储架构中:Catalog 是不存储 Schema 的,只存储最新的 Metadata 文件位置。 Metadata文件存储着所有 Schema id 到 Schema 信息的映射,以及最新的 Schema id——Current-Schema-id。底下的每个 Manifest 记录一个 Schema id,代表 Manifest 底下的 Parquet 文件用的都是对应的 Schema。
如果 Iceberg 发生了 Schema 变更,Metadata 文件会记录新的 Schema,并把 Current-Schema-id 指向新的 Schema。后续启动的写入作业就会按照新的 Schema 去生成新的 Parquet 数据文件和对应的 Manifest 文件。读取时会根据最新的 Schema-id 对应读取,即使底层存在不同 Schema 的 Manifest 文件也会使用新的 Schema 信息进行读取。
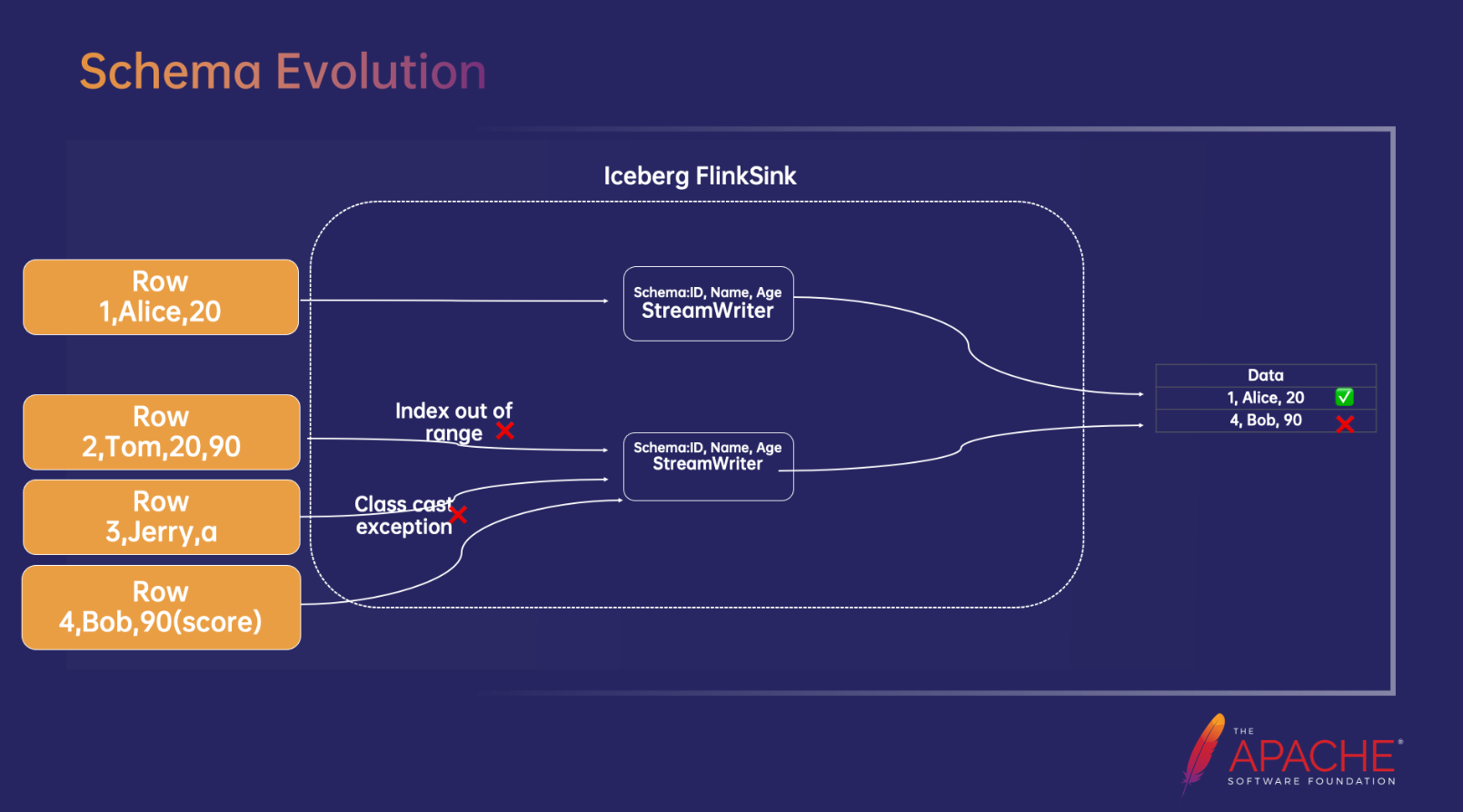
目前 Iceberg 提供的 Flinksink 并不支持 Schema 变更,Iceberg 默认的 Flinksink 会给每一个需要写入的 Parquet 文件创建一个 Streamwrtier,而这个 Streamwriter 的 Schema 是固定的,否则 Parquet 文件的写入就会报错。上图示例中原始 Schema 是 id、name、age,在 Schema 匹配情况下的写入不会报错,所以 Row 1 可以写入;Row 2 写入时由于长度不符合,所以会报错:Index out of range;Row 3 写入时,由于数据类型不匹配,会报错:Class cast excetpion;Row 4 写入时虽然类型和长度都匹配,但 Schema 含义不同,最终会在结果文件中写入一条脏数据。
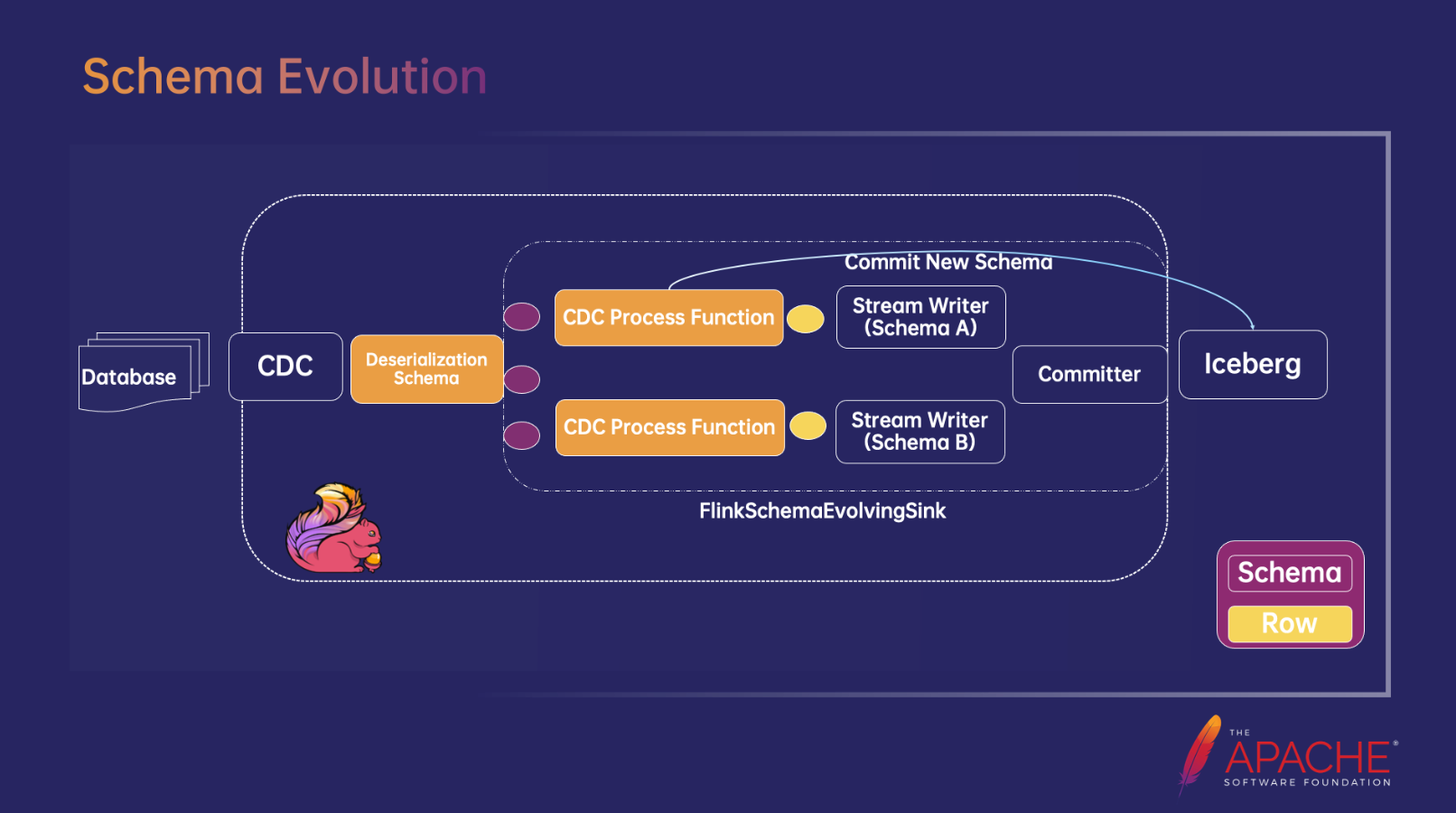
针对 Schema 变更要解决的问题主要有两个:1)怎么知道每条 Row 对应哪个 Schema?2)怎么在一个作业里写多种 Schema 数据?
针对第一个问题,在 Flink CDC Connector 中可以为每条记录设置包含 Schema 信息。所以我们需要实现一个反序列化方法,输出一条记录,包含 Row 和它对应的 Schema 信息,也就是图中紫色的部分,由此就解决了第一个问题。
针对第二个问题,支持多种 Schema 混写,需要为不同的 Schema 创建不同的 Streamwriter,每个 Streamwriter 对应一种 Schema。由此在 Iceberg Sink Connector 增加了新的 FlinkSchemaEvolvingSink,它会判断进入的数据是否和当前的 Schema 匹配,如果不匹配,就会向 Iceberg Commit 新的 Schema信息,返回 Schema id 后再按新 Schema 写数据、Commit 数据,即上图中对蓝色线条的描述,如果 Schema 是已经生成过的,就返回旧的 Schema id。FlinkSchemaEvolvingSink 中维护一个 Streamwriter 的 Map,其中 Key 是 Schema ID,当 Schema 传递过来之后会判断是否含有该 Schema的 Writer,如果没有就会去创建一个 Writer,这样就可以满足在同一个作业中写入多种 Schema 信息。
整库同步和自动建表

在 Flink 任务 Jobgraph 生成之前,需要一个 Catalog 模块读取源表的信息,同步在 Iceberg 端创建或者变更对应的目的表,同时在 Jobgraph 中增加对应表的 Sink 信息。
在 Flink 作业运行过程中,每条 Binlog 记录会通过一个反序列化解析器生成一条记录,这条记录包含了 Tableid 和 Row 两部分内容,即图上紫色部分的记录。随后对这条记录进行 Split,将 Row 按照 Table id 拆开后再经过 Keyby Partition 操作后写入到下游表中。

整个流程主要由以下四部分组成:
-
反序列化器会解析 Event 事件和数据。为了防止在流转过程中 Class Cast Exception,数据类型需要保持和源 Schema 保持相同,这个就需要对每种类型做测试,通过使用 Flink CDC 里面的测试用例对每种类型进行比对。
-
Catalog Module 主要负责自动建表和更新表内容,并需要和反序列化器保持一致的类型转换方式。
-
Table Spilt 能够实现 Source 复用的功能,给每张表创建一个 Sideoutput Tag,并输出到下游。
-
因为 Iceberg Sink 会对每个 Partition 创建对应的 Fanout Writer,占用的内存很大。所以我们需要对表的 Partition 字段进行 Keyby 操作,用来减少 OOM 次数。因为 Iceberg 有隐式分区的特性,所以需要对隐式分区的字段 Transform 之后再进行 Keyby 操作。
数据查询实践
为什么选择 Flink
-
在架构上,Flink 支持 JDBC 驱动程序、SQL-Gateway 和会话模式。Flink 会话集群是一个典型的 MPP (大规模并行处理)架构,每个查询不需要申请新的资源。用户可以通过 JDBC 驱动程序轻松提交 SELECT 语句,并在秒级甚至亚秒级取回结果。
-
强大的批处理能力。Flink OLAP 可以采取许多批处理操作和优化。同时,OLAP 中也存在大量查询,Flink 可以根据 Flink 的批处理的能力支持它们,而不需要像其他 OLAP 引擎那样引入外部批处理引擎。
-
Flink 支持 QUERY/INSERT/UPDATE 等标准 SQL 语法,满足 OLAP 用户的交互需求。
-
强大的连接器生态系统。Flink 为输入和输出定义了全面的接口,并实现了许多嵌入式连接器,如数据库、数据湖仓库。用户也可以基于这些接口轻松实现定制的连接器。
OLAP 架构
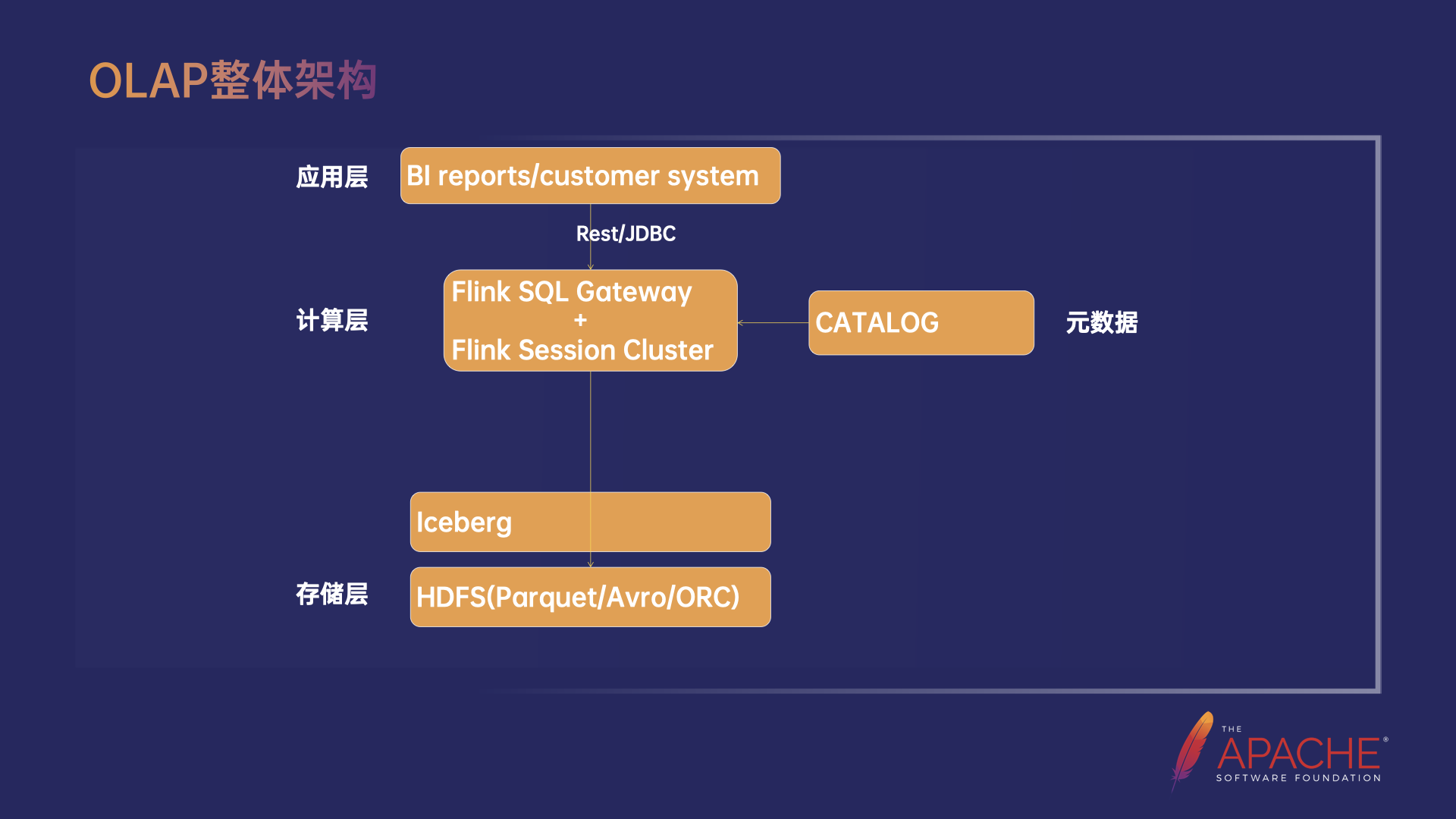
Flink OLAP 的整体架构,分为 Flink SQL Gateway 和 Flink Session Cluster 两部分。首先,用户使用 Client 通过 Rest 接口提交一个 Query,先经过 Gateway 的 SQL 解析和优化过程,生成作业的执行计划后通过高效的 Socket 接口提交给 Flink Session Cluster 上的 JobManager 到对应的 TaskManager 上,执行后将结果返回给 Clienht。JobManager 上的 Dispatcher 会创建一个对应的 JobMaster,之后 JobMaster 根据集群内的 TaskManager 按照一定的调度规则进行 Task 部署。
优化措施
Query 生成优化
-
Plan 缓存
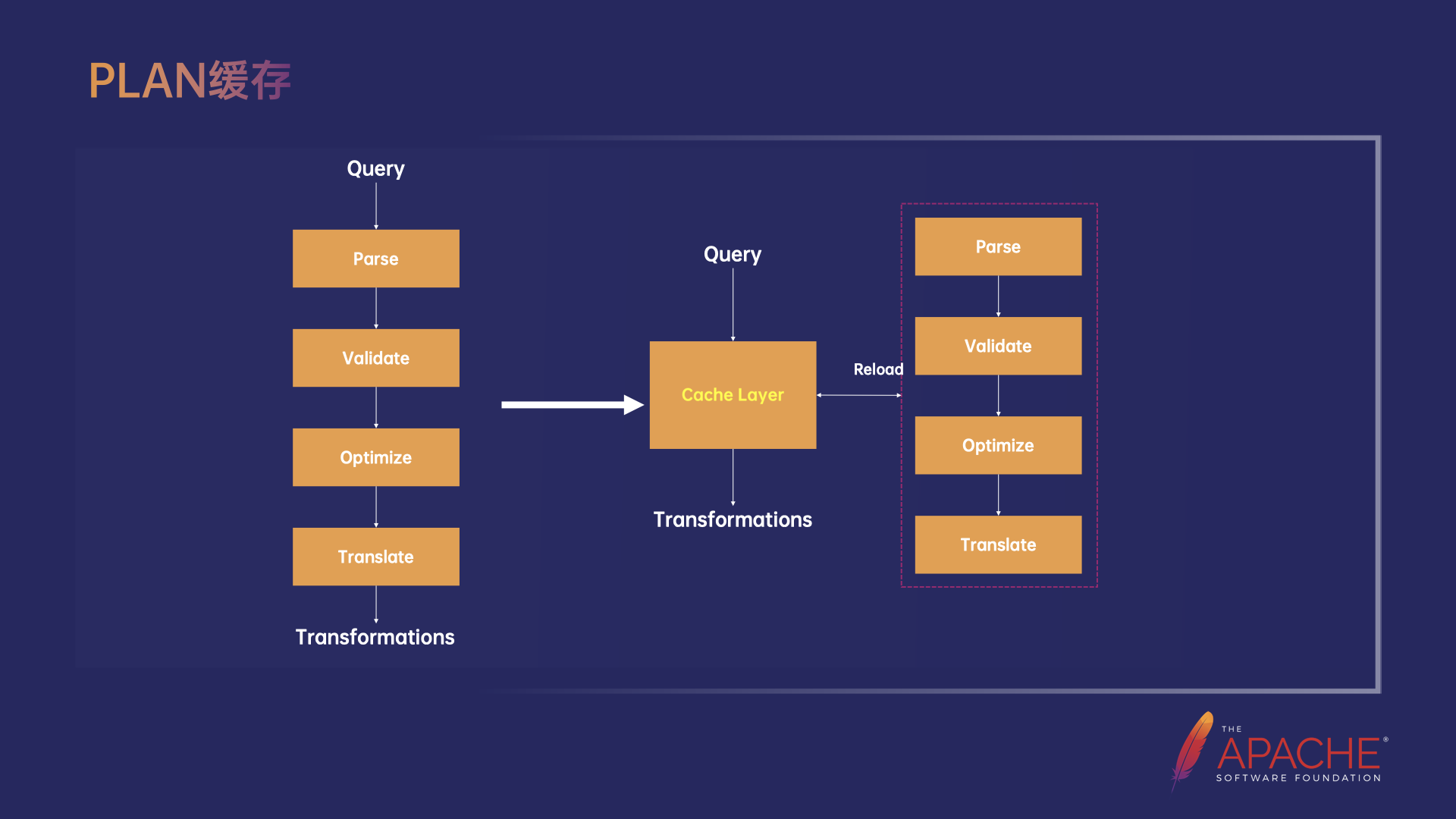
第一个优化点是 Plan 缓存。在 OLAP 场景下,Query 有两个典型的特点:一个是业务上有很多重复的 Query,这一点和流式是不一样的,第二个特点是查询耗时的要求是亚秒级,我们通过分析发现,Plan 阶段的耗时有几十到几百毫秒,占比是比较高的。因此通过支持 Plan 缓存,对 Query 的 Plan 结果 Transformations 进行缓存,避免相同 Query 的重复 Plan 问题。
此外,也支持了 Catalog Cache 加速元信息的访问,以及 ExecNode 的并行 Translate,使 TPC-DS Plan 的耗时降低了 10% 左右。
-
算子下推
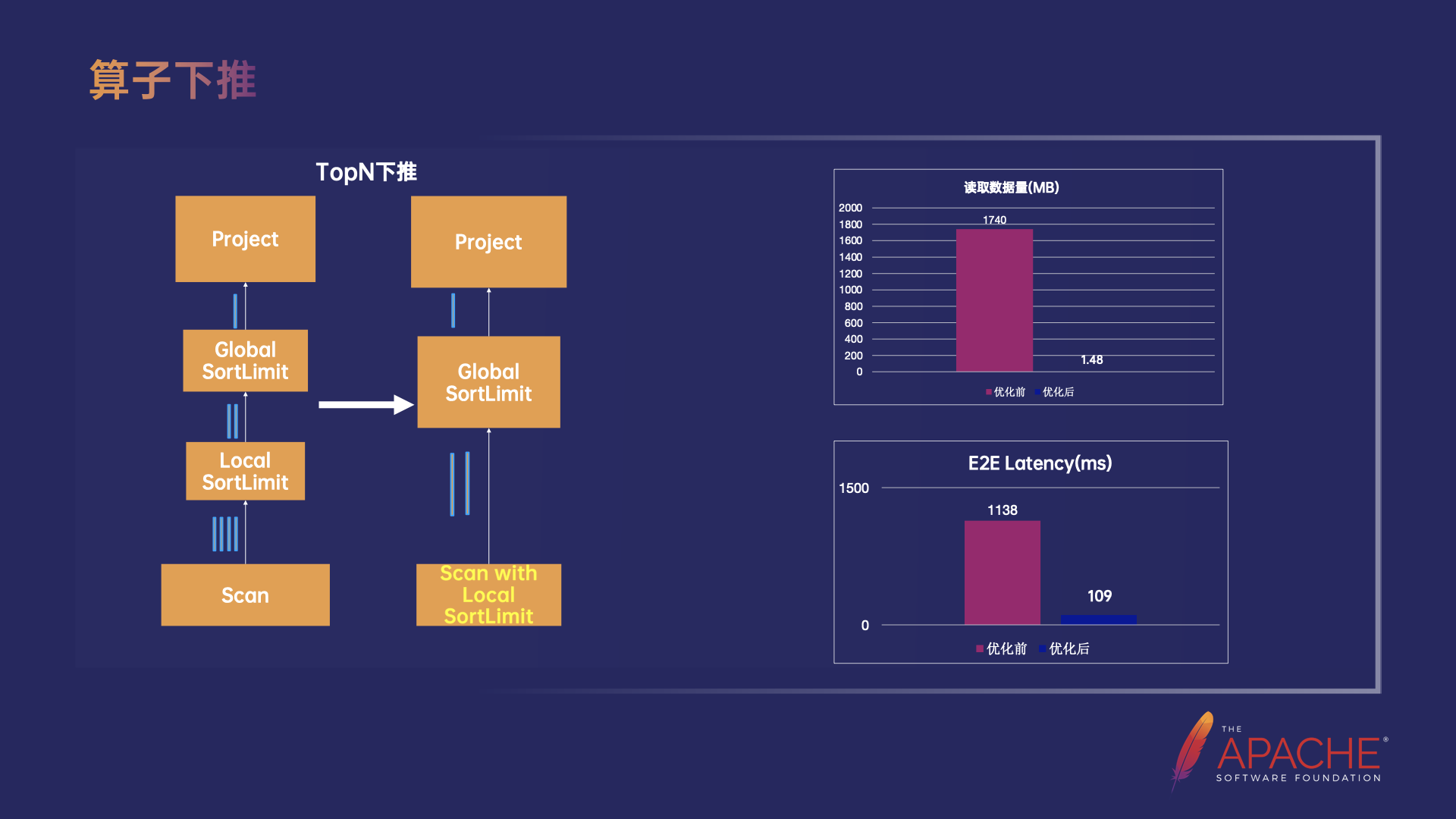
第二个优化是算子下推,在存算分离架构下算子下推是一类非常重要的优化,它的核心思路是通过尽可能的将一些算子下推到存储层计算来大幅减少 Scan 的数据量,降低外部的 IO,同时也减少了 Flink 引擎需要处理的数据量,从而明显提升了 Query 的性能。
在字节内部的实践中,有一个典型的业务的大部分 Query 都取用 TopN 数据,因此我们支持了 TopN 的下推,从图中可以看出,把 Local 的 SortLimit 算子,也就是 Local 的 TopN 算子下推到了 Scan 节点,最终在存储层做 TopN 计算,以此大大降低了从存储读取的数据量。优化的效果非常明显,Scan 节点从存储读取的数据量降低了 99.9%,业务 Query 的 Latency 降低了 90.4% 左右。
除此之外,我们还支持了更多的算子下推,包括 Aggregate 下推,Filter 下推和 Limit 下推等。
Query 执行优化
-
ClassLoader 复用
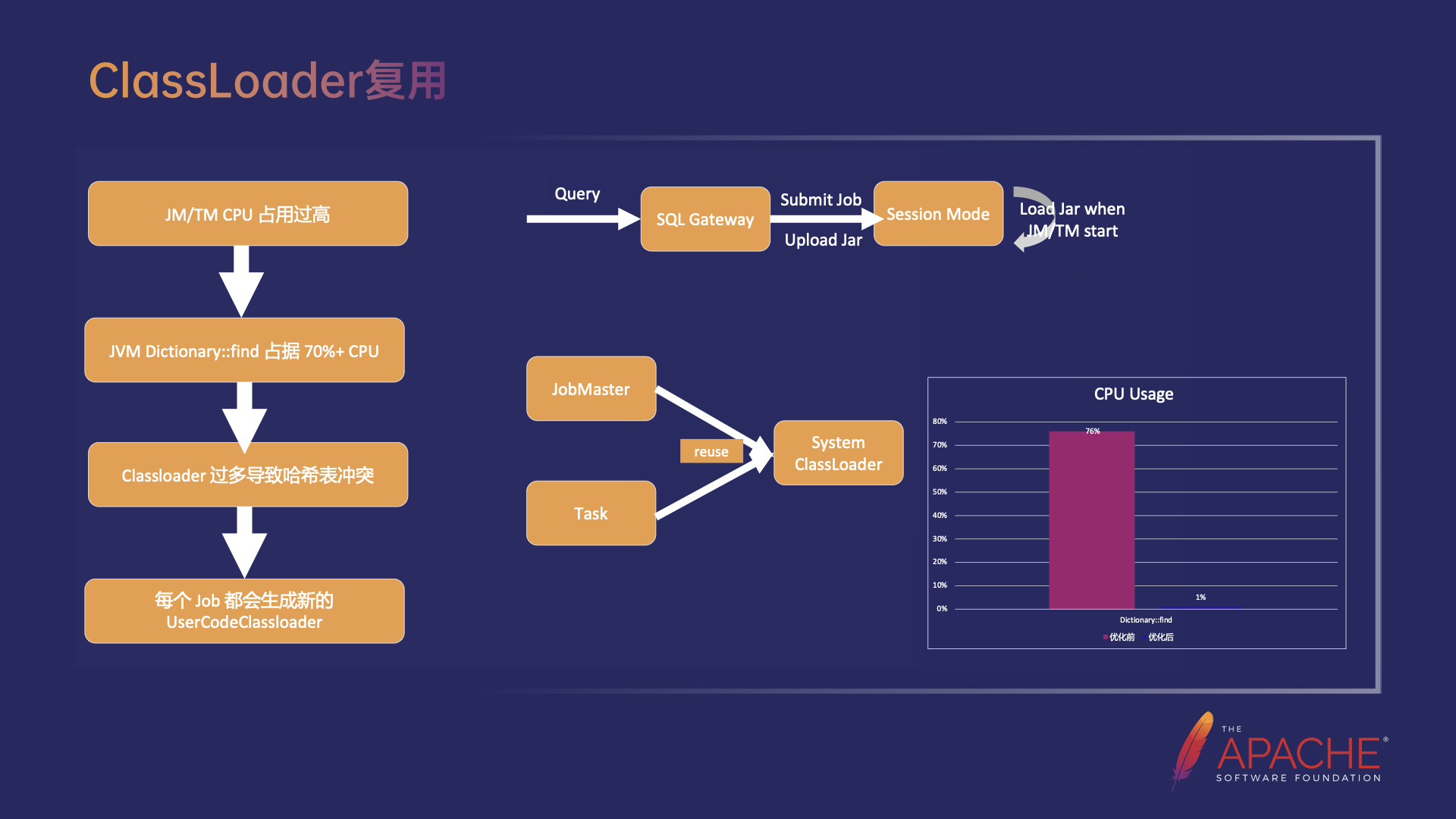
在 ClassLoader 复用中首先来分析一个在 OLAP 下频繁创建 Classloader 引发 CPU 占用过高的问题。我们发现 JM/TM 的 CPU 占用在线上很高。通过火焰图分析,JVM 的 Dictionary::find 方法占据了 70% 以上的 CPU,在进一步分析 JVM 源码时发现 JVM 在加载了 Class 之后,为了加速从 Class Name 到 Classloader 的查找,会维护一个叫做 SystemDictionary 的哈希表(Key 是 Class Name,Value 是 Classloader 实例)。在 Classloader 数量非常多的时候,比如线上出现了超过 2w 的 Classloader 的情况下,哈希表中会存在大量的冲突,使查找的过程非常缓慢,即整个JM 大部分的 CPU 都会消耗在这个步骤中。
通过定位发现,这些 Classloader 都是 UserCodeClassloader,是用于动态加载用户的 Jar 包的,每个 Job 都会创建新的 UserCodeClassloader,从右下图中可以看出,新 Job 的 JobMaster 和 TM 上该 Job 的 Task 都会创建新的 UserCodeClassloader,导致 JM 和 TM 上的 Classloader 过多。除此之外,Classloader 过多还会导致 JVM Metaspace 空间不足,进而频繁的触发 Metaspace Full GC。
因此我们做了 Classloader 复用的优化,主要分为两步,首先优化了依赖 Jar 的方式,由于 OLAP 场景下依赖的第三方 Jar 包是相对固定的,可以直接放在 JM 和 TM 启动的 Classpath 下,并不需要每个作业单独的提交 Jar 包。接着对于每个作业在 JobMaster 和 Task 初始化时直接复用 System Classloader。经过 Classloader 复用之后,JM 中 Dictionary::find 所占的 CPU 使用从 76% 下降到 1%,同时,Metaspace Full GC 的频率显著降低。
-
CodeGen 缓存优化

这个优化的前提是我们发现了在 OLAP 下 Codegen 源代码编译占据 TM CPU 过多的问题,在当前的 Codegen 缓存流程中,Flink SQL 中大量算子使用了 Codegen 生成计算逻辑,比如 Codegen Operator 中的 Generated Class,其中的 Code 就是 Codegen 生成的 Java 源代码,在 Operator 初始化时,需要编译 Java 源代码并加载为 Class。为了避免重复的编译,当前已经有了缓存的机制,会根据 Class Name 映射到 Task 所用的 Classloader,再映射到编译好的 Class。
但是在当前的缓存机制下,存在两个问题,首先是当前的机制只实现了同一个作业内部,同一个 Task 的不同并发的复用,但是对于同一个 Query 的多次执行依然存在重复编译,这是因为 Codegen 生成 Java 源代码时为了避免命名冲突,代码的类名和变量名的后缀采用了进程级别的自增 ID,导致了同一 Query 的多次执行,类名和代码的内容都会发生变化,因此无法命中缓存。另外一个问题是,每次编译和加载 class 都会创建一个新的ByteArrayClassloader,频繁创建 Classloader 会导致 Metaspace 碎片严重,并引发 Metaspace Full GC,造成服务的抖动。
为了避免跨作业代码的重复编译,实现跨作业的 Class 共享,我们需要优化缓存的逻辑,实现相同源代码到编译好的 Class 的映射。这里有两个难点:
-
首先是如何保证相同逻辑的算子所生成的代码相同;
-
如何设计 Cache Key 唯一识别相同的代码。
对于第一个难点,我们在 Codegen 代码生成的时候,把类名和变量名中的自增 ID 从全局粒度替换为 Local Context 粒度,使得相同逻辑的算子能生成相同的代码。对于第二个难点,我们设计了基于 Classloader 的 Hash 值 + Class Name + 代码的长度 + 代码的 md5 值的四元组作为 Cache Key 来唯一识别相同的代码。
Codegen 缓存优化的效果是非常明显的,TM 侧代码编译的 CPU 使用率从之前的 46% 优化到 0.3% 左右,Query 的 E2E Latency 降低了 29.2% 左右,同时 Metaspace Full GC 的时间也降低了 71.5% 左右。
物化视图
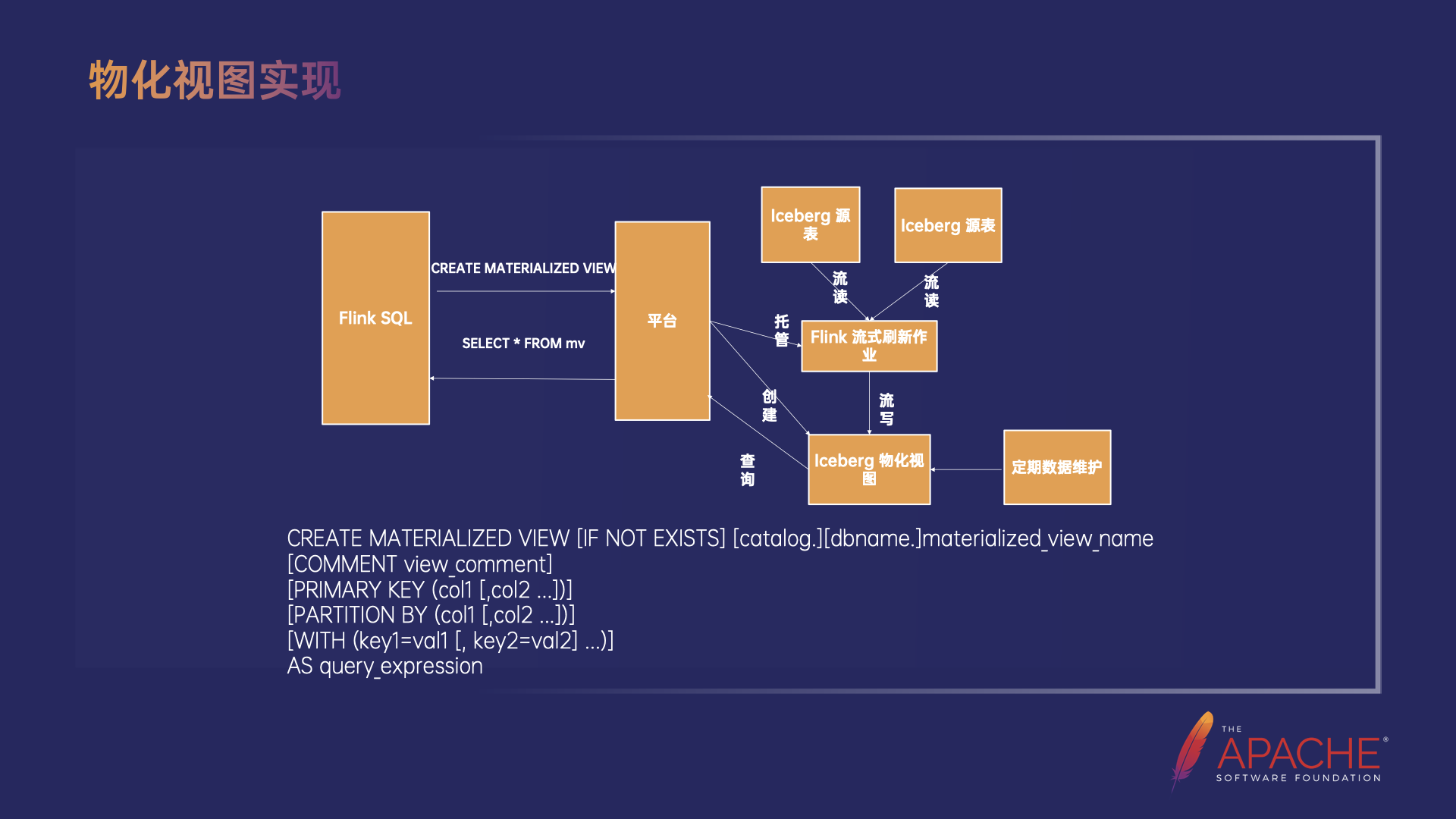
-
首先用户通过 Flink SQL 向平台发送创建物化视图的请求;
-
平台负责创建 Iceberg 物化视图、启动 Flink 作业刷新物化视图,并且托管这个作业来保证它持续运行。
-
Flink 刷新作业就会持续从源表流读增量数据,做增量计算得到增量的结果后流式写到物化视图。
-
最终用户就能直接通过查物化视图拿到原本需要做全量计算才能获得的结果。
以上就是实现物化视图主要的流程,目前我们的 Iceberg 物化视图还只是一个普通的 Iceberg 表,未来会在 Iceberg 层面记录更完善的元数据,用来支持判断数据的新鲜程度,也会基于已有的物化视图自动重写和优化用户的查询。其中定期数据维护会包括:过期数据清理、过期快照清理、孤儿文件清理、数据/元数据小文件合并等。
总结和展望
后续工作的重点将主要围绕自动化创建物化视图、物化视图的查询重写、自动调优数据维护任务的参数(包括执行频率、合并文件大小等),以及数据冷热分层/Data cache的相关工作展开。



![20、清华、杭州医学院等提出:DA-TransUNet,超越TranUNet,深度医学图像分割框架的[皇帝的新装]](https://img-blog.csdnimg.cn/direct/79895009754b4df682785a691f4f2fe7.jpeg)