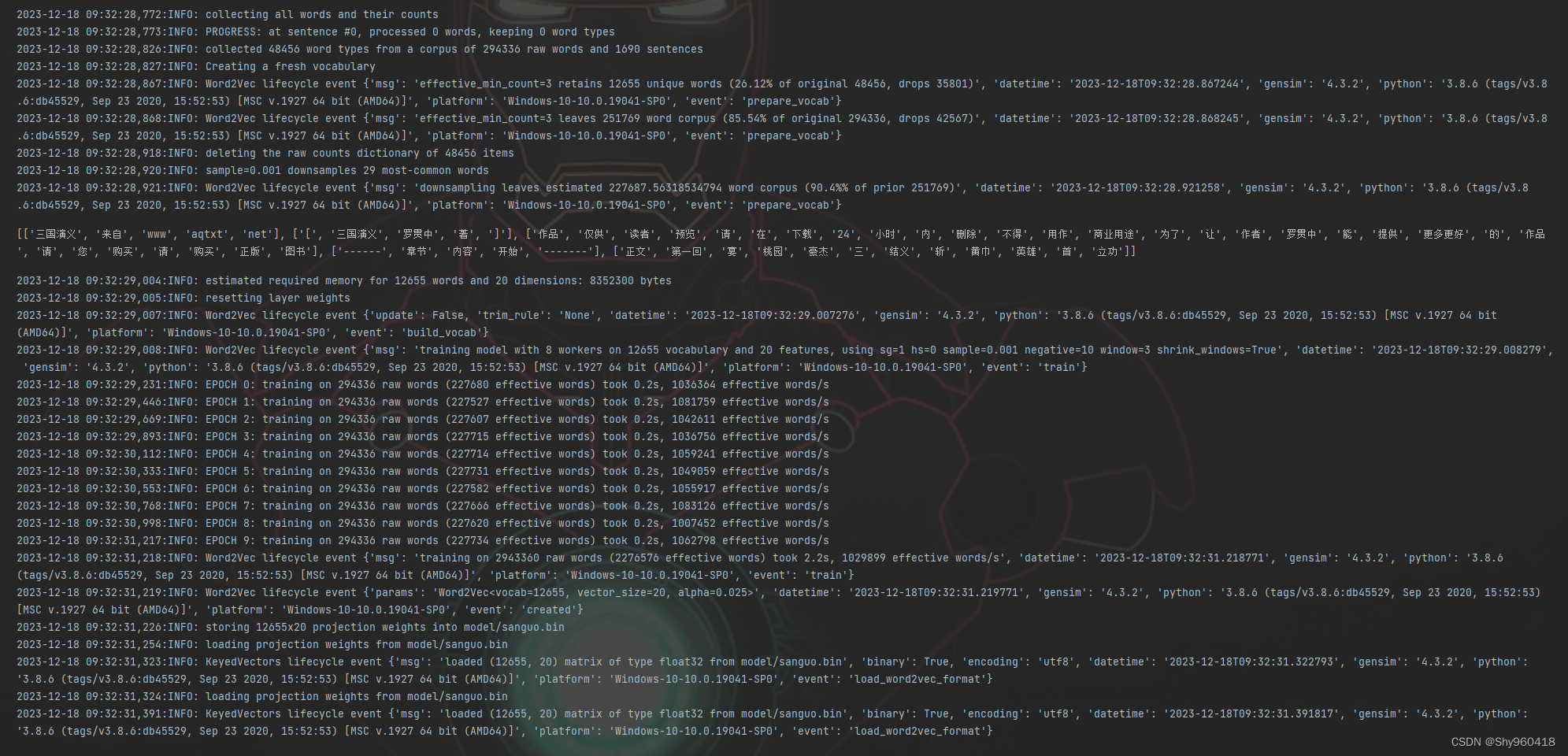
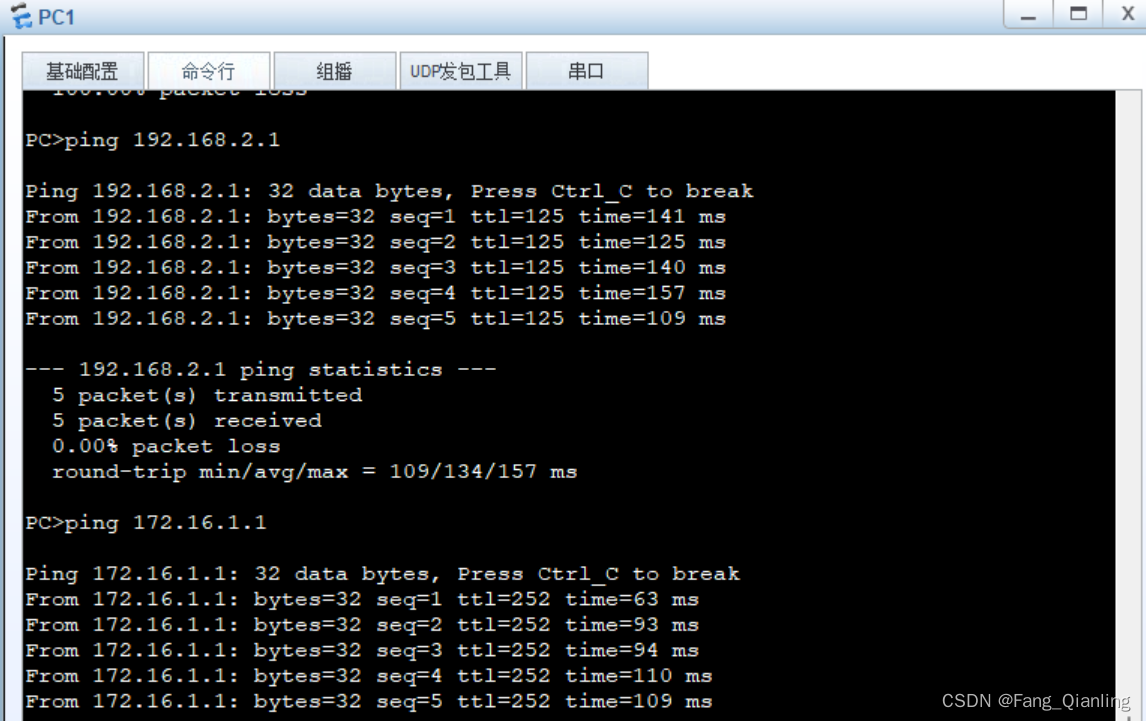
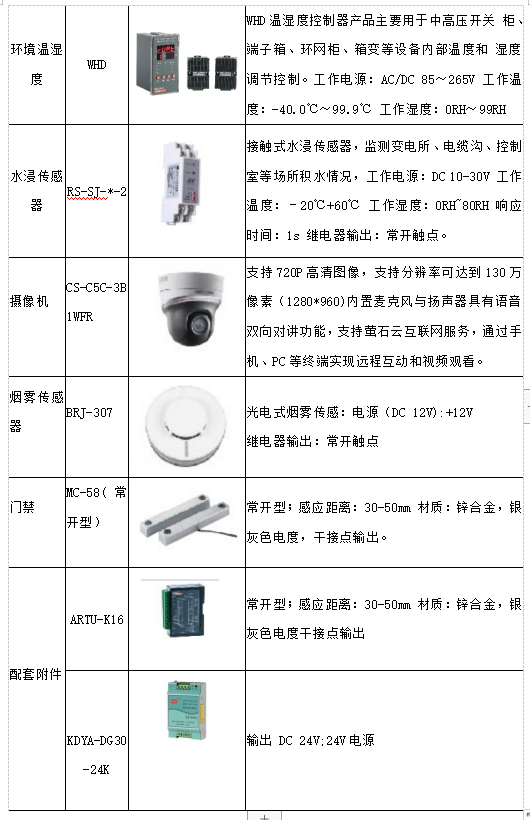
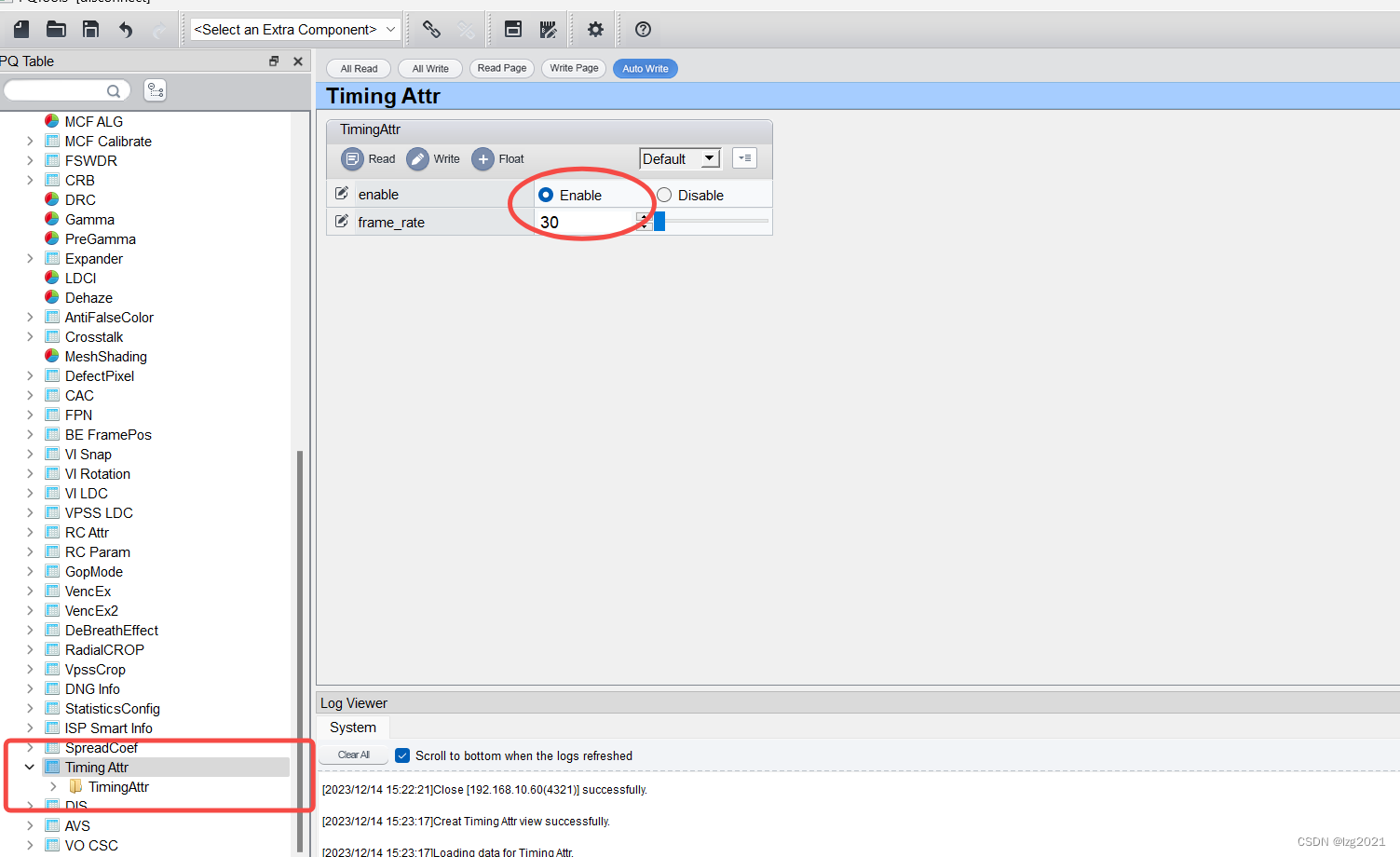
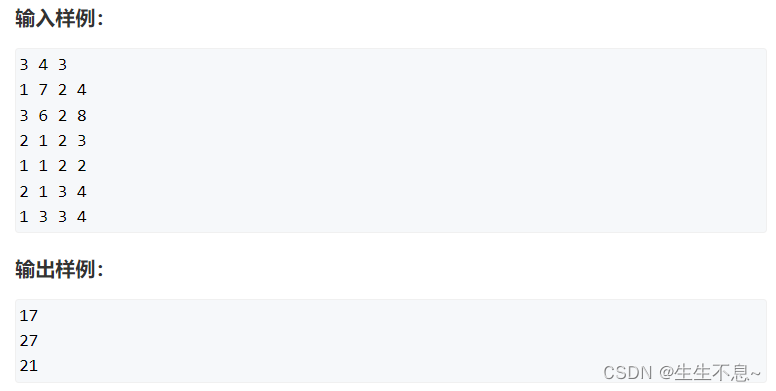
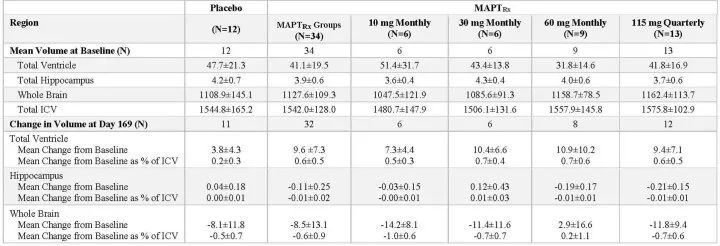
import gensim
import jieba
import re
import warnings
import logging
warnings.filterwarnings('ignore')
with open("dataset/sanguo.txt", 'r',encoding='utf-8')as f: # 读入文本
lines = []
for line in f: #分别对每段分词
temp = jieba.lcut(line) #结巴分词 精确模式
words = []
for i in temp:
#过滤掉所有的标点符号
i = re.sub("[\s+\.\!\/_,$%^*(+\"\'””《》]+|[+——!,。?、~@#¥%……&*():;‘]+", "", i)
if len(i) > 0:
words.append(i)
if len(words) > 0:
lines.append(words)
print(lines[0:5])#预览前5行分词结果
# 调用Word2Vec训练 参数:size: 词向量维度;window: 上下文的宽度,min_count为考虑计算的单词的最低词频阈值
logging.basicConfig(format='%(asctime)s:%(levelname)s: %(message)s', level=logging.INFO) #输出日志
model = gensim.models.Word2Vec(lines,vector_size = 20, window = 3 , min_count = 3, epochs=10, negative=10,sg=1, workers=8)
# 第一种方法 保存一般模型
# model.save('训练w2v模型相关/zhihu_w2v.model')
# model_1 = word2vec.Word2Vec.load('训练w2v模型相关/zhihu_w2v.model')
# print("模型1:", model_1)
## 第二种方法 以保存词向量的方式保存模型 二进制
model.wv.save_word2vec_format('model/sanguo.bin', binary=True)
# 通过加载词向量加载模型模型
model = gensim.models.KeyedVectors.load_word2vec_format('model/sanguo.bin', binary=True)
print(r"\n模型2:", model)
print("两个词的相似度为:", model.similarity("孔明", "刘备"))
print("两个词的相似度为:", model.similarity("曹操", "刘备"))
# 第三种方式 保存词向量 与第二种方法相同 只是非二进制文件
# model.wv.save_word2vec_format('33.txt', binary=False)
# 加载模型
model = gensim.models.KeyedVectors.load_word2vec_format('model/sanguo.bin', binary=True)
# print(r"孔明的词向量:\n",model.wv.get_vector('孔明'))
# print(model.wv.most_similar('孔明', topn = 20))# 与孔明最相关的前20个词语
# print(model.doesnt_match('孔明')) # 与孔明最不相关的词语
输出结果: