从代码角度理解Mistral架构
- Mistral架构全面解析
- 前言
- Mistral 架构分析
- 分词
- 网络主干
- MixtralDecoderLayer
- Attention
- MOE
- MLP
- 下游任务
- 因果推理
- 文本分类
Mistral架构全面解析
前言
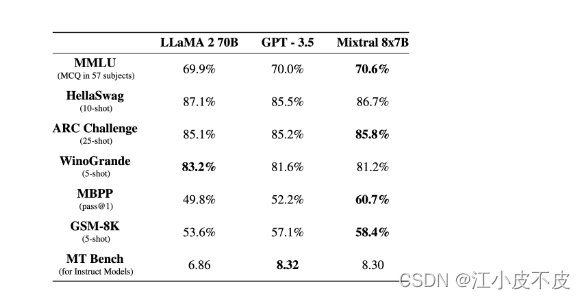
Mixtral-8x7B 大型语言模型 (LLM) 是一种预训练的生成式稀疏专家混合模型。在大多数基准测试中,Mistral-8x7B 的性能优于 Llama 2 70B。
Mixtral 8x7B 是 Mistral AI 全新发布的 MoE 模型,MoE 是 Mixture-of-Experts 的简称,具体的实现就是将 Transformer 中的 FFN 层换成 MoE FFN 层,其他部分保持不变。在训练过程中,Mixtral 8x7B 采用了 8 个专家协同工作,而在推理阶段,则仅需激活其中的 2 个专家。这种设计巧妙地平衡了模型的复杂度和推理成本,即使在拥有庞大模型参数的情况下,也能保证高效的推理性能,使得 MoE 模型在保持强大功能的同时,也具备了更优的实用性和经济性。
- 在大多数基准测试中表现优于Llama 2 70B
- 甚至足以击败GPT-3.5上下文窗口为32k
- 可以处理英语、法语、意大利语、德语和西班牙语
- 在代码生成方面表现优异
huggingface上给出基本的加载方法
from transformers import AutoModelForCausalLM, AutoTokenizer
model_id = "mistralai/Mixtral-8x7B-v0.1"
tokenizer = AutoTokenizer.from_pretrained(model_id)
model = AutoModelForCausalLM.from_pretrained(model_id)
text = "Hello my name is"
inputs = tokenizer(text, return_tensors="pt")
outputs = model.generate(**inputs, max_new_tokens=20)
print(tokenizer.decode(outputs[0], skip_special_tokens=True))
Mistral 架构分析
其它结构和llama的一模一样,知道llama结构的话,省流直接看MOE部分。
分词
分词部分主要做的是利用文本分词器对文本进行分词

tokenizer = AutoTokenizer.from_pretrained(PATH_TO_CONVERTED_TOKENIZER)
text = "Hey, are you conscious? Can you talk to me?"
inputs = tokenizer(text, return_tensors="pt")
网络主干
主干网络部分主要是将分词得到的input_ids输入到embedding层中进行文本向量化,得到hidden_states(中间结果),然后输入到layers层中,得到hidden_states(中间结果),用于下游任务。

self.embed_tokens = nn.Embedding(config.vocab_size, config.hidden_size, self.padding_idx)
self.layers = nn.ModuleList(
[MixtralDecoderLayer(config, layer_idx) for layer_idx in range(config.num_hidden_layers)]
)
self._use_flash_attention_2 = config._attn_implementation == "flash_attention_2"
self.norm = MixtralRMSNorm(config.hidden_size, eps=config.rms_norm_eps)
MixtralDecoderLayer
主干网络的layers层就是由多个MixtralDecoderLayer组成的,由num_hidden_layers参数决定,一般我们说的模型量级就取决于这个数量,7b的模型DecoderLayer层的数量是32。
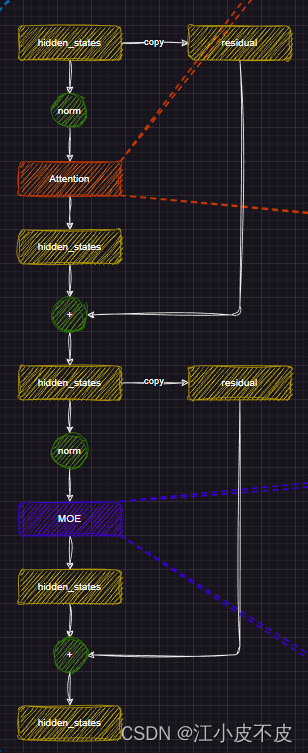
MixtralDecoderLayer层中又包含了Attention层和MOE层,主要的一个思想是利用了残差结构。
如下图所示,分为两个部分
第一部分
- 首先,将hidden_states(文本向量化的结构)进行复制,即残差
- 归一化
- 注意力层
- 残差相加
第二部分
- 首先将第一部分得到的hidden_states进行复制,即残差
- 归一化
- MLP层
- 残差相加
#复制一份
residual = hidden_states
#归一化
hidden_states = self.input_layernorm(hidden_states)
#注意力层
hidden_states, self_attn_weights, present_key_value = self.self_attn(
hidden_states=hidden_states,
attention_mask=attention_mask,
position_ids=position_ids,
past_key_value=past_key_value,
output_attentions=output_attentions,
use_cache=use_cache,
padding_mask=padding_mask,
)
#加上残差
hidden_states = residual + hidden_states
#复制一份
residual = hidden_states
#归一化
hidden_states = self.post_attention_layernorm(hidden_states)
#mlp
hidden_states = self.mlp(hidden_states)
#加上残差
hidden_states = residual + hidden_states
outputs = (hidden_states,)
if output_attentions:
outputs += (self_attn_weights,)
if use_cache:
outputs += (present_key_value,)
return outputs
Attention
进行位置编码,让模型更好的捕捉上下文信息
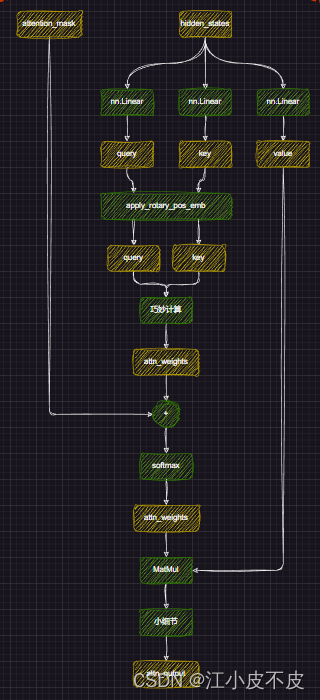
#经过线性层
query_states = self.q_proj(hidden_states)
key_states = self.k_proj(hidden_states)
value_states = self.v_proj(hidden_states)
#多头注意力形状变换
query_states = query_states.view(bsz, q_len, self.num_heads, self.head_dim).transpose(1, 2)
key_states = key_states.view(bsz, q_len, self.num_key_value_heads, self.head_dim).transpose(1, 2)
value_states = value_states.view(bsz, q_len, self.num_key_value_heads, self.head_dim).transpose(1, 2)
kv_seq_len = key_states.shape[-2]
#计算cos、sin
#计算旋转位置嵌入
cos, sin = self.rotary_emb(value_states, seq_len=kv_seq_len)
query_states, key_states = apply_rotary_pos_emb(query_states, key_states, cos, sin, position_ids)
#计算权重
key_states = repeat_kv(key_states, self.num_key_value_groups)
value_states = repeat_kv(value_states, self.num_key_value_groups)
attn_weights = torch.matmul(query_states, key_states.transpose(2, 3)) / math.sqrt(self.head_dim)
#加上掩码
attn_weights = attn_weights + attention_mask
#计算softmax
attn_weights = nn.functional.softmax(attn_weights, dim=-1, dtype=torch.float32).to(query_states.dtype)
attn_output = torch.matmul(attn_weights, value_states)
attn_output = self.o_proj(attn_output)
MOE
MOE层,也就是我们的专家模块,简单来说,主要干的就是通过一个线性层,得到8个专家,从这8个专家中选出最专业的2个,把他们的权重相加,输入到MLP层,得到最终的结果。
- attention层得到的hidden_states经过控制门(nn.Linear)得到8个输出。(有点像多分类)
- t通过softmax计算8个输出的概率值
- 从8个中选择概率值最高的两个专家
- 概率最高的两个专家进行权重相加,并计算相对概率值
- 这两个专家输入到MLP层中进行一系列计算得到最后结果
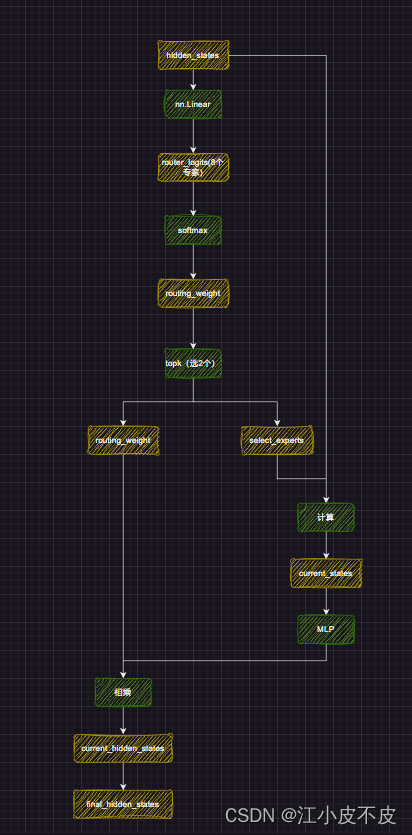
batch_size, sequence_length, hidden_dim = hidden_states.shape
hidden_states = hidden_states.view(-1, hidden_dim)
#这里通过一个线性层,得到8个输出(n_experts),也就是所谓的专家。
# router_logits: (batch * sequence_length, n_experts)
router_logits = self.gate(hidden_states)
#这里通过softmax计算8个输出的概率值,如(0.2,0.3,0.0833,0.0833,0.0833,0.0833,0.0833,0.0833)
routing_weights = F.softmax(router_logits, dim=1, dtype=torch.float)
#从8个中选择概率值最高的两个专家((0.2,0.3)
routing_weights, selected_experts = torch.topk(routing_weights, self.top_k, dim=-1)
#概率最高的两个专家进行权重相加,并计算相对概率值((0.2,0.3)->(0.4,0.6)
routing_weights /= routing_weights.sum(dim=-1, keepdim=True)
routing_weights = routing_weights.to(hidden_states.dtype)
#初始化最终结果
final_hidden_states = torch.zeros(
(batch_size * sequence_length, hidden_dim), dtype=hidden_states.dtype, device=hidden_states.device
)
#掩码
expert_mask = torch.nn.functional.one_hot(selected_experts, num_classes=self.num_experts).permute(2, 1, 0)
for expert_idx in range(self.num_experts):
expert_layer = self.experts[expert_idx]
#通过掩码找到top2的位置
idx, top_x = torch.where(expert_mask[expert_idx])
if top_x.shape[0] == 0:
continue
top_x_list = top_x.tolist()
idx_list = idx.tolist()
#top2对应的向量
current_state = hidden_states[None, top_x_list].reshape(-1, hidden_dim)
#经过mlp
current_hidden_states = expert_layer(current_state) * routing_weights[top_x_list, idx_list, None]
#加到final_hidden_states中
final_hidden_states.index_add_(0, top_x, current_hidden_states.to(hidden_states.dtype))
final_hidden_states = final_hidden_states.reshape(batch_size, sequence_length, hidden_dim)
return final_hidden_states, router_logits
MLP
mlp层的主要作用是应用非线性激活函数和线性投影。
- 首先将attention层得到的结果经过两个线性层得到gate_proj和up_proj
- gate_proj经过激活函数,再和up_proj相乘
- 最后经过一个线性层得到最后的结果
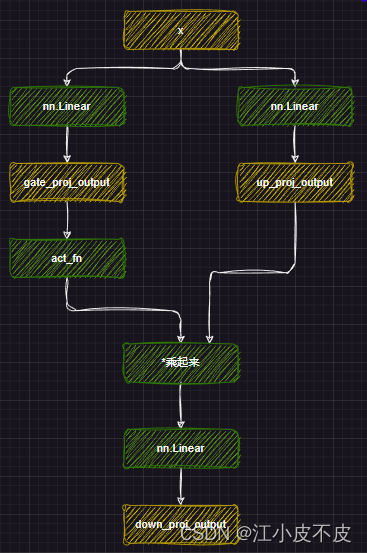
self.gate_proj = nn.Linear(self.hidden_size, self.intermediate_size, bias=False)
self.up_proj = nn.Linear(self.hidden_size, self.intermediate_size, bias=False)
self.down_proj = nn.Linear(self.intermediate_size, self.hidden_size, bias=False)
self.act_fn = ACT2FN[config.hidden_act]
down_proj = self.down_proj(self.act_fn(self.gate_proj(x)) * self.up_proj(x))
下游任务
因果推理
所谓因果推理,就是回归任务。
self.lm_head = nn.Linear(config.hidden_size, config.vocab_size, bias=False)
文本分类
即分类任务
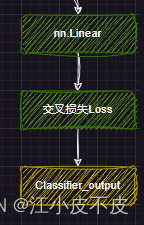
self.score = nn.Linear(config.hidden_size, self.num_labels, bias=False)