Python 爬虫开发完整环境部署
前言:
关于本篇笔记,参考书籍为 《Python 爬虫开发实战3 》 笔记做出来的一方原因是为了自己对 Python 爬虫加深认知,一方面也想为大家解决在爬虫技术区的一些问题,本篇文章所使用的环境为:python 3.6.2 64 位
在此其中,我们可能会碰到不兼容的问题,所以有些软件会降低版本来达到兼容,其实这一点大家没必要较真,一个 python 版本,或者一个库的版本,都代表着一个时间,随着 python3 的出现,就代表着 python2 的不兼容,那么库于库之间,代码于代码之间,就会存在一种依存关系,有些库会更新,而有的就不会跟新,但旧的不代表它已经被淘汰,而是一代技术的成熟,以上是我对版本迭代的思考。
我想,以我现在的水平,还达不到窥探源码来修改这些不兼容的问题,所以既然不兼容,那么我就来兼容它即可,python 亦是如此。
0x01 请求库的安装
爬虫可以简单分为几步:抓取页面,分析页面,存储数据
当我们在抓取页面的时候,需要模拟浏览器向服务器发出请求,所以需要用到一些 python 库来实现 HTTP 请求操作
这里,我们出现了三个库 requests,Selenium,aiohttp
install
请求库:
C:\Users\yangh>pip install requests
'标准请求库'
C:\Users\yangh>pip install selenium
'Selenium是一个自动化测试工具,利用它我们可以驱动浏览器执行特定的动作,如点击、下拉等操作。对于一些JavaScript渲染的页面来说,这种抓取方式非常有效。下面我们来看看Selenium的安装过程'
C:\Users\yangh>pip3 install aiohttp
'异步请求抓取数据'
C:\Users\yangh>pip3 install cchardet aiodns
'字符集编码库,与加速 DNS 解析库 '
Software:
ChromeDriver['Chrome 对应']:https://chromedriver.storage.googleapis.com/index.html
GeckoDriver['Firefox 对应']:https://github.com/mozilla/geckodriver/releases
ChromeDriver 安装简介
作用:配合 selenium 库,来达到与浏览器配合,能够与 chrome 配合
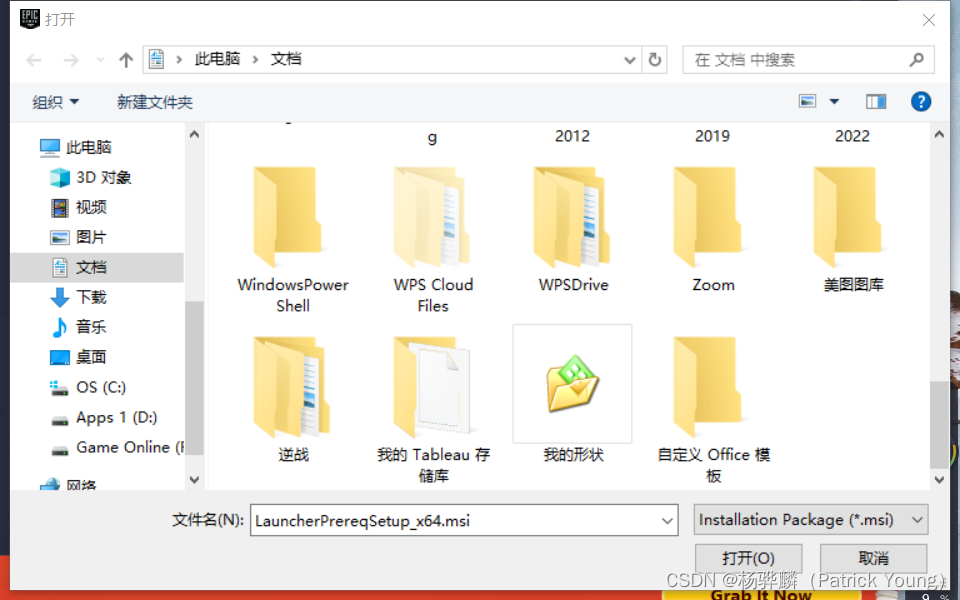
- 先进入网站:https://chromedriver.storage.googleapis.com/index.html
查看 Chrome 版本
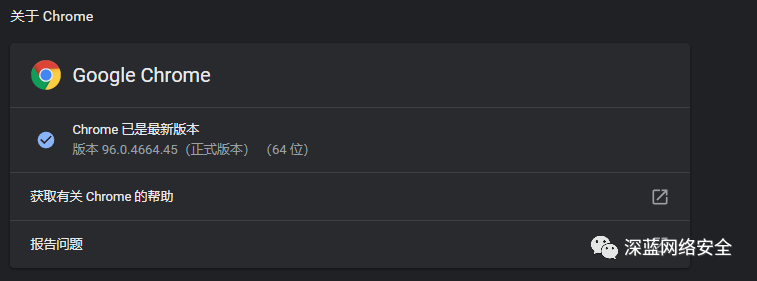
下载对应版本软件
配置环境变量,并把其放在 python/Script 目录下
验证
GeckoDriver 安装简介
作用:配合 selenium 库,来达到与浏览器配合,能够与 firefox 配合
GeckoDriver 安装也与之大同小异,直接下载最新版,然后对应 64/32 解压,拖到 …/python/Script/
验证
PhantomJS 安装简介
作用:
PhantomJS 是一个无界面的、可脚本编程的WebKit浏览器引擎,它原生支持多种Web标准:DOM操作、css选择器、JSON、Canvas以及SVG。Selenium支持PhantomJS,这样在运行的时候就不会再弹出一个浏览器了。而且PhantomJS的运行效率也很高,还支持各种参数配置
- 官方网站:http://phantomjs.org
- 官方文档:http://phantomjs.org/quick-start.html
- 下载地址:http://phantomjs.org/download.html
- API接门说明:http://phantomjs.org/api/command-line.html
PhantomJS 与 ChromeDriver 配置操作一样,添加到 python/Script 文件夹,然后加入环境变量
验证
这里,由于不想修改 selenium 版本,就没安装完毕
0x02 解析库安装
在抓取网页代码之后,下一步就是提取网站中的信息,提取信息的方式有多种多样,可以使用正则来提取,'但是正则写起来会相对比较繁琐'。这里还有许多强大的解析库,如,'lxml,Beautiful Soup,pyquery'等,此外还提供了非常强大的解析方法,如 'XPath 解析和 CSS 选择器解析等',利用他们我们可以高效的从网页中提取有效信息
install
1:C:\Users\yangh>pip3 install lxml
2:C:\Users\yangh>pip3 install beautifulsoup4 (beautifulsoup4 即 bs4)
3:C:\codeEnvironment\python\wheel>pip3 insatll pyquery-1.4.3-py3-none-any.whl
4:C:\Users\yangh>pip install pillow
lxml 参考
lxml 是 python 的一个解析库,支持 HTML 和 XML 的解析,支持 XPath 解析方式
官方网站:http://lxml.de
GitHub:https://github.com/lxml/lxml
PyPI:https://pypi.python.org/pypi/lxml
Beautiful Soup 参考
Beautiful Soup 是 Python 的一个 HTML 或 XML 解析库,我们可以用它方便地从网页中提取数据,它拥有强大的 API 和多样的 解析方式
官方文档:https://www.crummy.com/software/Beautifu1Soup/bs4/doc
中文文档:https://www.crummy.com/software/Beautifu!Soup/bs4/doc.zh
PyPI:https://pypi.python.org/pypi/beautifulsoup4
Test Beautiful soup4
>>> from bs4 import BeautifulSoup
>>> soup = BeautifulSoup('<p>Hello</p>','lxml')
>>> print(soup.p.string)
Hello
只要输出 hello 即成功
pyquery 参考
url:https://pypi.org/project/pyquery/#files
pyquery 同样是一个强大的页面解析工具,它提供了和 Jquery 类似的语法来解析 HTML 文档,支持 CSS 选择器
参考链接
- GitHub:https://github.com/gawel/pyquery
- PyPI:https://pypi.python.org/pypi/pyquery
- 官方文档:http://pyquery.readthedocs.io
resserocr 参考
在爬虫过程中,难免会遇到各种各样的验证码,而大多数验证码还是 '图形验证码',这时候我们就可以直接用 OCR 来识别
tesserocr 是 Python 的一个OCR识别库,但其实是对tesseract做的一层PythonAPI封装,所以它的核心是tesseract。因此,在安装tesserocr之前,我们需要先安装 tesseract
相关链接
- tesserocrGitHub: https://github.com/sirfz/tesserocr
- tesserocrPyPI: https://pypi.python.org/pypi/tesserocr
- tesseract 下载地址:http://digi.bib.uni-mannheim.de/tesseract[^ 下载来后,全勾上安装即可]
- tesseractGitHub : https://github.com/tesseract-ocr/tesseract
- tesseract 语言包:https://github.com/tesseract-ocr/tessdata
- tesseract 文档:https://github.com/tesseract-ocr/tesseract/wiki/Documentation
- Releases · simonflueckiger/tesserocr-windows_build (github.com)[^ 到这里下载 wheel 文件]
下载安装好后,直接进 OCR 目录:Tesseract-OCR ,复制目录 tessdata 粘贴给 python 根目录一份即可完成安装
验证
测试 tesserocr
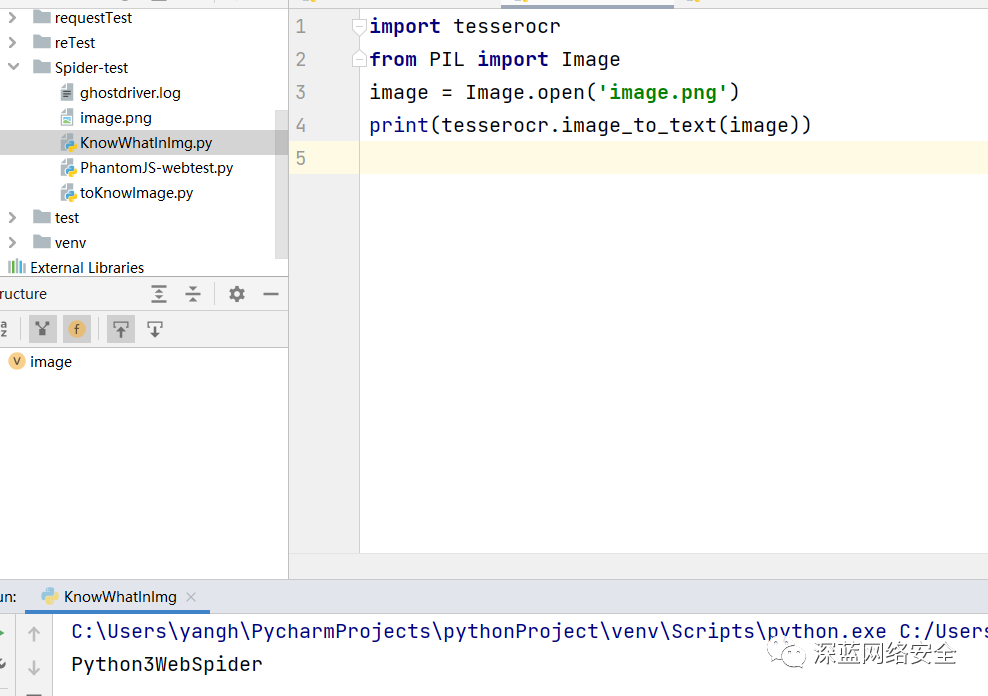
若正常输出图片内容,则安装成功
测试 tesseract
0x03 数据库的安装
作为数据存储的重要部分,数据库同样是必不可少的,数据库可以分为关系型数据库,和非关系型数据库(NOsql),
关系型数据库如:SQLite、MySQL、Oracle、SQL Server、DB2
非关系型数据库:MongoDB、Redis,他们存储形式是键值对,存储形式更加灵活
以下,我们来介绍三种数据库,Mysql 以及 MongoDB、Redis
MySQL 安装参考
下载地址:https://www.mysql.com/cn/downloads
也可以通过国内的 phpstudy 一键搭建
注意,通过官网下载的需要开启本地服务 MySQL
MongoDB 的安装
MongoDB 是由 C++ 语言编写的非关系型数据库,是一个基于分布式文件存储的开源数据库系统,其内容存储形式类似JSON对象,它的字段值可以包含其他文档、数组及文档数组,非常灵活。MongoDB支持多种平台,包括Windows、Linux、MacOS、Solaris等,在其官方网站(https://www. mongodb.com/download-center)均可找到对应的安装包。
- 官方网站:https://www.mongodb.com
- 官方文档:https://docs.mongodb.com
- GitHub:https://github.com/mongodb
- 中文教程:http://www.runoob.com/mongodb/mongodb-tutorial.html
- 下载网址:MongoDB Community Download | MongoDB
- MongoDB安装(超详细)
Redis 安装
- 官方网站:https://redis.io
- 官方文档:https://redis.io/documentation
- 中文官网:http://www.redis.cn
- GitHub:https://github.com/antirez/redis
- 中文教程:http://www.runoob.com/redis/redis-tutorial.html
- RedisDesktop Manager: https://redisdesktop.com
- Redis Desktop Manager GitHub: https://github.com/uglide/RedisDesktopManager
- 下载 redis:https://github.com/microsoftarchive/redis/releases
- 下载 redis 可视化程序:https://wwx.lanzoui.com/it7Eqnacdeh
下载来后一键安装即可默认用户 root 密码 root
0x04 存储库的安装
我们上面只说到存储数据的一个方式,即数据库,但是我们要数据库与我们的 python 交互,那么就需要 '存储库',如 'Mysql 需要安装 PyMySQL','MongoDB 需要安装 PyMongo 等'
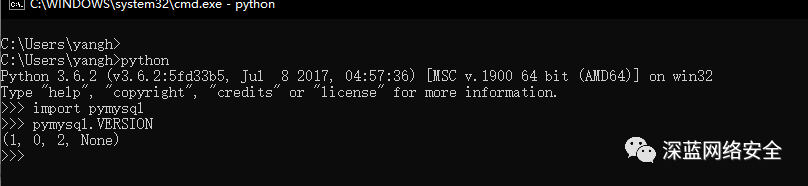
PyMySQL 安装
C:\Users\yangh>pip3 install pymysql
验证
相关链接
- GitHub:https://github.com/PyMySQL/PyMySQL
- 官方文梢:http://pymysql.readthedocs.io/
- PyPl: https://pypi.python.org/pypi/PyMySQL
PyMongo 安装
C:\Users\yangh>pip3 install pymongo
验证

相关链接
- GitHub:https://github.com/mongodb/mongo-python-driver
- 官方文档:https://api.mongodb.com/python/current/
- PyPI: https://pypi.python.org/pypi/pymongo
redis-py 安装
C:\Users\yangh>pip3 install redis
验证
输出如下即成功安装
C:\Users\yangh>python
Python 3.6.2 (v3.6.2:5fd33b5, Jul 8 2017, 04:57:36) [MSC v.1900 64 bit (AMD64)] on win32
Type "help", "copyright", "credits" or "license" for more information.
>>> import redis
>>> redis.VERSION
(4, 0, 2)
相关链接
- GitHub:https://github.com/andymccurdy/redis-py
- 官方文档:https://redis-py.readthedocs.io/
RedisDump 安装
RedisDump 作用与 Redis 的导入导出工具,基于 Ruby 实现,所以需要先下载 'Ruby'
Ruby for windows
访问网站:https://rubyinstaller.org/downloads/ 下载即可
gem 安装
这里我们安装 ruby 后就能使用 gem 命令,来下载 RedisDump
验证
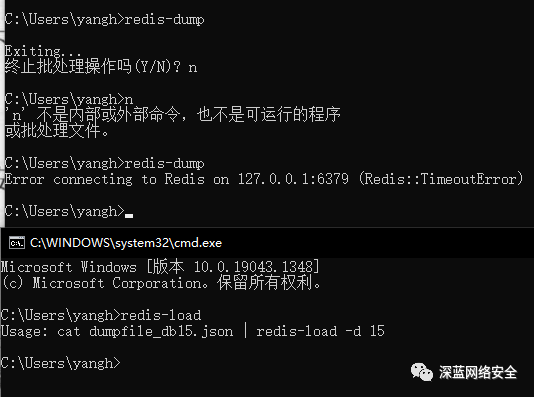
相关链接
- GitHub:https://github.com/delano/redis-dump
- 官方文档:http://delanotes.com/redis-dump
- Ruby http://www.ruby-lang.org/zh_cn/documentation/installation
0x05 Web 库的安装
Python 也有 Web 程序服务 'Flask,Django 等',我们可以用他们来开发 '网站' 和 '接口',我们主要拿来做 'API 接口',供 我们的 '爬虫' 使用
比如,维护一个嗲鲤齿,代理保存在 Redis 数据库中,我们要将代理池作为一个公共的组件使用,那么如何构建一个方便的平台来供我们获取这些代理呢?最适合的就是 Web 服务提供的 'API 接口','我们只需要请求接口即可获取新的代理'
Flask 安装
Flask 是一个轻量级的 Web 服务程序,它简单、易用、灵活、主要用于 API 服务
C:\Users\yangh>pip3 install flask
验证
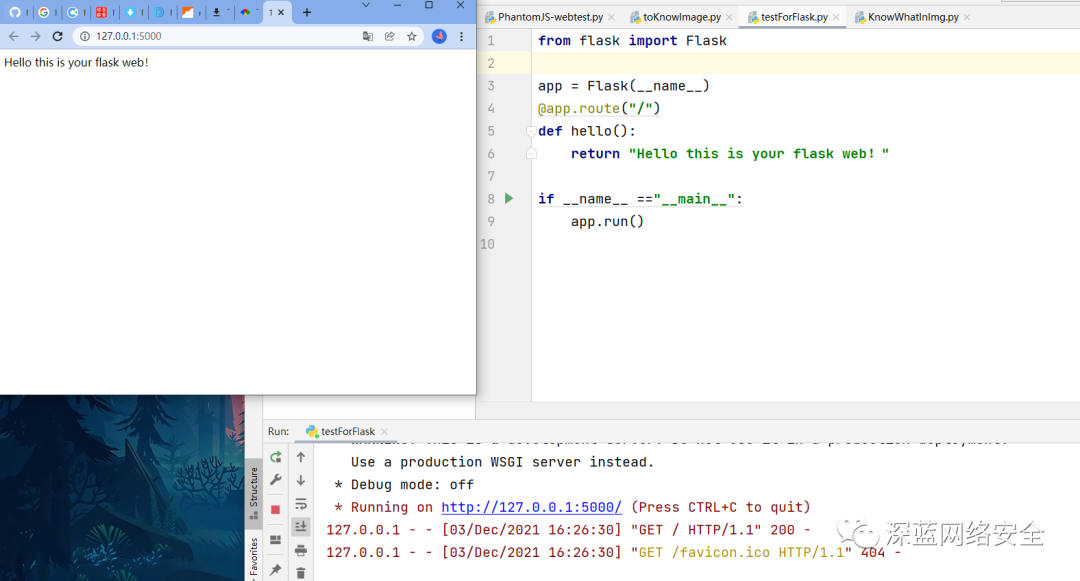
后面,我们会利用 Flask+Redis 维护动态代理池和 Cookies 池
相关链接
- GitHub:https://github.com/pallets/flask
- 官方文档:http://flask.pocoo.org
- 中文文档:http://docs.jinkan.org.docs/flask
- PyPI :https://pypi.python.org/pypi/Flask
Tornado 的安装
Tornado 是一个支持 “异步” 的web框架,通过使用 “非阻塞 I/O 流”,它可以支撑成千上万的开放链接!
C:\Users\yangh>pip3 install tornado
验证
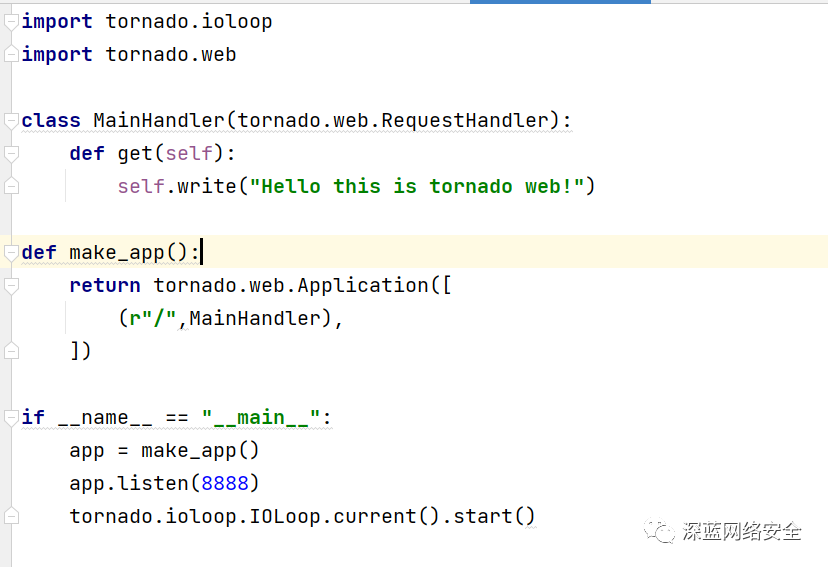
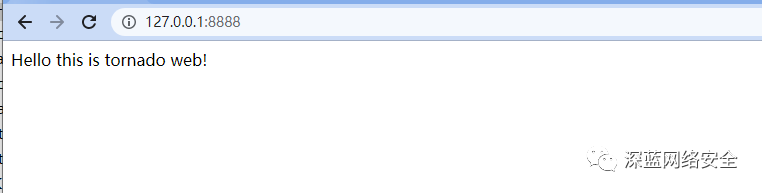
后面,我们会利用 Tomado+Redis 来搭建一个ADSL拨号代理池
相关链接
- GitHub:https://github.com/tomadoweb/tomado
- PyPI:https://pypi.python.org/pypi/tomado
- 官方文档:http://www.tomadoweb.org
0x06 APP 爬取相关库的安装
除了 Web 网页,爬虫也可以抓取 'App 的数据',App 中的页面要加载出来,首先需要获取数据,而这些数据一般是通过请求服务器的接口来获取的。由于 App 没有浏览器这种可以比较直观的看到后台请求的工具,所以主要用一些抓包技术来抓取数据
本地测试工具有:
- Charles
- mitmproxy
- mitmdump
- Appium
一些简单的接口可以通过 Charles 或 mitmproxy分析,找出规律,然后直接用程序模拟来抓取了,但如果遇到更加复杂的接口,就需要利用 mitmdump 对接 python来抓取到的请求和响应进行实时处理和保存,另外,既然要做规模采集,就需要自动化 App 的操作而不是人工采集,这里我们还会需要一个工具 Appium,它可以像 Selenium 一样对 App 将那些自动化控制,如自动化模拟 App 的点击,下拉等操作
Charles 的安装
下载:https://www.charlesproxy.com/latest-release/download.do
破解:https://www.zzzmode.com/mytools/charles/
安装 CA 证书:
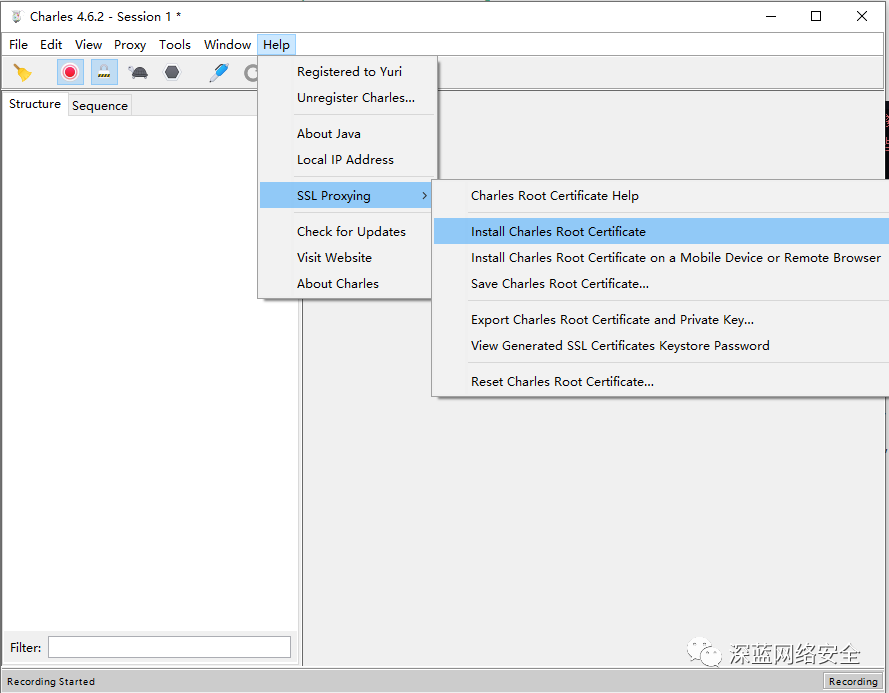
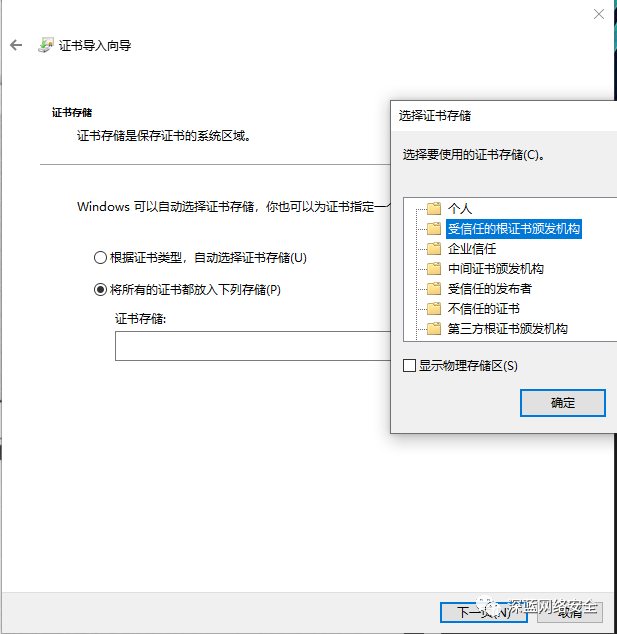
安装完后可同时设置 Android 于之存在一个局域网,参考以下即可
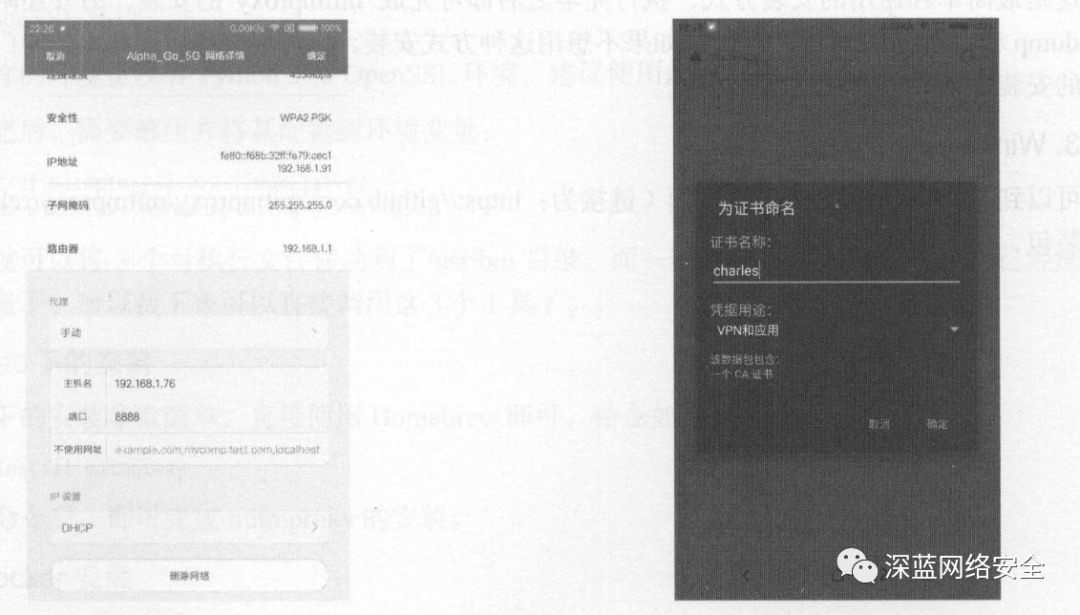
如果你的手机是Android系统,可以按照下面的操作进行证书配置。在Android系统中,同样需要设置代理为Charles的代理。设置完毕后,电脑上就会出现一个提示窗口,询问是否信任此设备,此时直接点击Allow按钮即可。接下来,像iOS设备那样,在手机浏览器上打开chls.pro/ssl,这时会出现一个提示框
mitmproxy 安装
mitmproxy是一个支持 HTTP 和 HTTPS 的抓包程序,类似 Fiddler,charles功能,只不过,它通过控制台的形式操作。
此外,mitmproxy 还有两个关联组件,一个是 mitmdump,它是 mitmproxy 的命令行接口,利用它可以对接 Python 脚本,实现监听后的处理;另一个是mitmweb 它是一个 web 程序,通过它以清除地观察到 mitmproxy 捕获的请求。
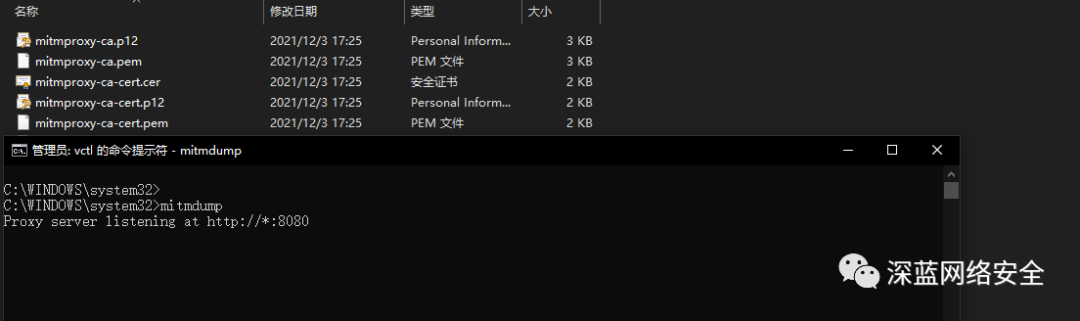
C:\Users\yangh>pip install mitmproxy==5.0.0
即可查看到 CA 证书
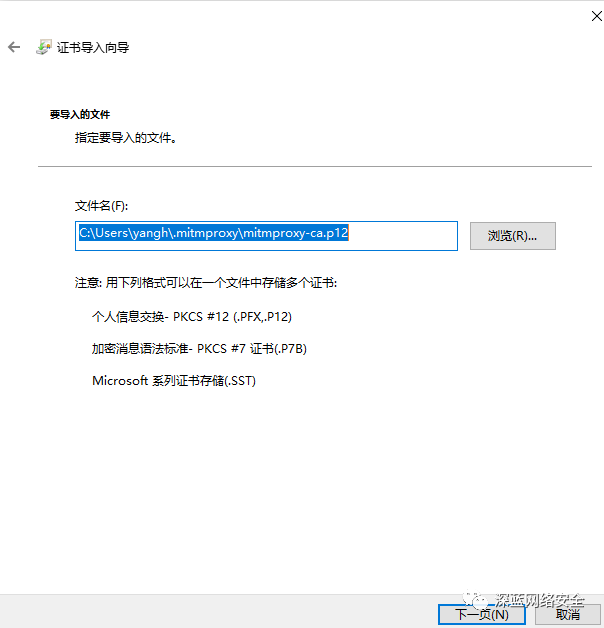
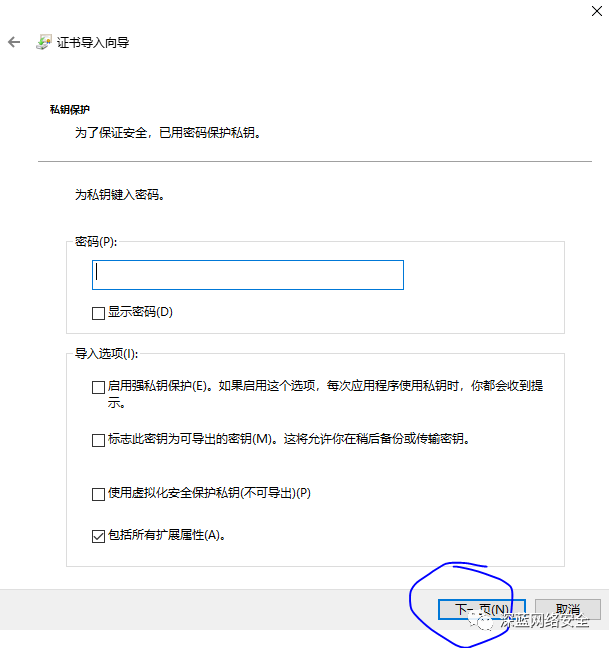
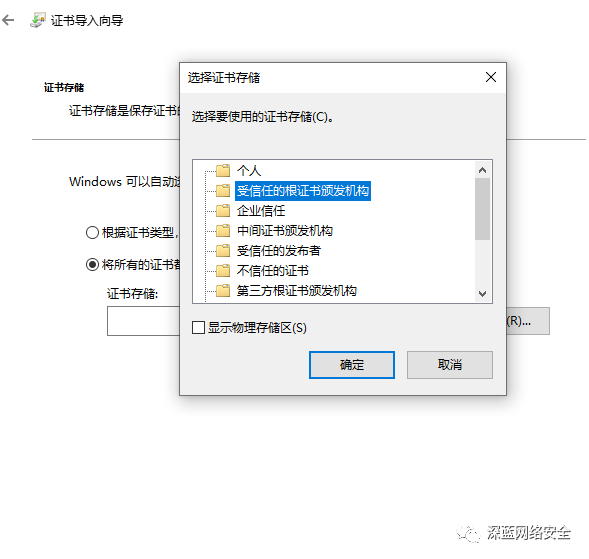
安装 CA 证书
跟着图片步骤走即可
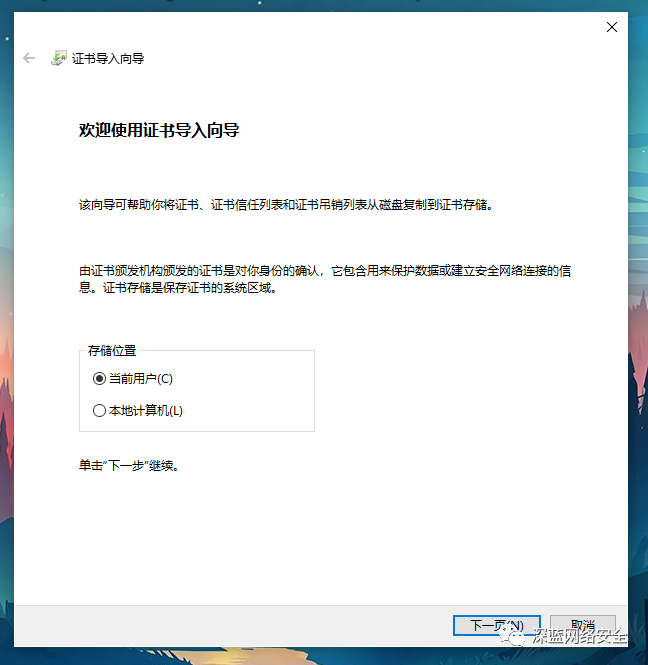
证书配置
对于 mitmproxy来说,如果想要截取 HTTPS 请求,就需要设置证书。mitmproxy 在安装后会提供一套 CA 证书,只要客户端信任即可,步骤如下
相关链接
- GitHub:https://github.com/mitmproxy/mitmproxy
- 官方网站:https://mitmproxy.org
- PyPI: https://pypi.python.org/pypi/mitmproxy
- 官方文档:http://docs.mitmproxy.org
- mitmdump脚本:http://docs.mitmproxy.org/en/stable/scripting/overview.html
- 下载地址:https://github.com/mitmproxy/mitmproxy/releases
- DockerHub:https://hub.docker.com/r/mitmproxy/mitmproxy
Appium 安装
首先,需要安装Appium。Appium负责驱动移动端来完成一系列操作,对于iOS设备来说,它使用苹果的UIAutomation来实现驱动;对于Android来说,它使用UIAutomator和Selendroid来实现驱动同时Appium也相当于一个服务器,我们可以向它发送一些操作指令,它会根据不同的指令对移动设备进行驱动,以完成不同的动作。
下载网址:https://github.com/appium/appium-desktop/releases
安装完后即可显示如下即安装成功:

以上,我们可以配合 Android 模拟器等来实现即可!
0x07 爬虫核心框架安装
我们直接用 requests、Selenium 等库来写爬虫,如果爬取量不是太大,速度要求不高,是完全可以满足需求的。但是写多了就会发现其内部许多代码和组件是可以重复利用的,如果我们把这些组件抽离出来,将各个功能模块化,就会慢慢形成一个框架雏形,这样慢慢培养它,就像自己养虫子一样,爬虫框架也会越来越来完善。
我们利用框架,就可以不再去关心某些功能的具体实现,只需要关系爬取的逻辑即可。同时也可大大简化代码量,而且框架会变得清晰,爬取效率也会高很多。所以,如果有一定基础,上手框架是一种好的选择。
以下我们主要介绍 pyspider 和 Scrapy 两种框架。
Pyspider 安装
简介:
pyspider是国人 binux 编写的一个网络爬虫框架,它拥有强大的 WebUI、脚本编辑器、任务监控器、项目管理器、结果处理器。同时支持多种数据库后端、多种消息队列、还支持 JavaScript 渲染页面的爬取
安装
C:\Users\yangh>pip3 install pyspider
验证:

常见 windows 错误
1:Command ”python setup.py egg_info”failedwith error code 1 in /tmp/pip-build-vXo1W3/pycurl
这是PyCurl安装错误,此时需要安装PyCurl库。从 http://www.lfd.uci.edu/~gohlke/pythonlibs/#pycurl 找到对应的Python版本,然后下载相应的wheel文件即可。比如Windows64位、Python3.6,则需要下载pycurl-7.43.0-cp36-cp36m-win _ amd64.whl,随后用pip安装即可,命令如下
C:\codeEnvironment\python\wheel>pip install pycurl-7.43.0.4-cp36-cp36m-win_amd64.whl
2:若出现报错即直接停止 pyspider 进程,说明 wsgidav ,werkzeug 版本过高,操作如下
C:\Users\yangh>pip uninstall wsgidav
C:\Users\yangh>pip install wsgidav==2.0.1
C:\Users\yangh>python -m pip uninstall werkzeug
C:\Users\yangh>python -m pip install werkzeug==0.16.1
重新启动 pyspider 即可
相关链接
- 官方文档:http://docs.pyspider.org
- PyPI: https://pypi.python.org/pypi/pyspider
- GitHub:https://github.corn/binux/pyspider
- 官方教程:http://docs.pyspider.org/en/latest/tutorial
- 在线实例:http://demo.pyspider.org
- pyspider 坑参考:https://blog.csdn.net/huangzyi/article/details/114289498
- 踩坑参考:https://blog.csdn.net/lang_niu/article/details/104501473
- 踩坑参考:https://blog.csdn.net/qq_39542714/article/details/106835145
- 踩坑参考:https://blog.csdn.net/weixin_30408675/article/details/97132148
Scrapy 安装
Scrapy 是一个十分强大的爬虫框架,依赖的库比较多,至少需要依赖的库有 Twisted 14.0、lxml 3.4 和 pyOpenSSL 0.14.在不同的平台环境下,它所依赖的库也各不相同,所以在安装 Scrapy 之前,必须把基本库环境安装好,这里笔者只介绍关于 windows 10 的安装
依赖:Anaconda 安装
关于这一种安装方法,大家注意,如果本地已经安装了 Python,就不要用 conda 的安装了,参考后面的安装即可
关于 Anaconda 的安装方式,大家可以去看这篇文章:
https://blog.csdn.net/ITLearnHall/article/details/81708148)
在此不再赘述
安装好后直接输出该命令即可安装完毕:conda install Scrapy
依赖 lxml 安装
C:\Users\yangh>pip install lxml
依赖 pyOpenSSL
关于 pyOpenSSL 直接去官网下载 whl 文件安装即可:https://pypi.python.org/pypi/pyOpenSSL#downloads
C:\codeEnvironment\python\wheel>pip install pyOpenSSL-17.2.0-py2.py3-none-any.whl
依赖 Twisted 安装
下载地址:http://www.lfd.uci.edu/~gohlke/pythonlibs/#twisted 下载wheel文件
C:\codeEnvironment\python\wheel>pip install Twisted-20.3.0-cp36-cp36m-win_amd64.whl
依赖 PyWin32
从官方网站下载对应版本的安装包即可
链接为:https://sourceforge.net/projects/pywin32/files/pywin32/Build%20221
下载过来后,直接双击 exe 安装即可
End Scrapy 安装
C:\Users\yangh>pip3 install Scrapy
验证
C:\codeEnvironment\python\wheel>Scrapy
Scrapy 2.5.1 - no active project
Usage:
scrapy <command> [options] [args]
Available commands:
bench Run quick benchmark test
commands
fetch Fetch a URL using the Scrapy downloader
genspider Generate new spider using pre-defined templates
runspider Run a self-contained spider (without creating a project)
settings Get settings values
shell Interactive scraping console
startproject Create new project
version Print Scrapy version
view Open URL in browser, as seen by Scrapy
[ more ] More commands available when run from project directory
Use "scrapy <command> -h" to see more info about a command
相关链接:
- 官方网站:https://scrapy.org
- 官方文档:https://docs.scrapy.org
- PyPI:https://pypi.python.org/pypi/Scrapy
- GitHub:https://github.com/scrapy/scrapy
- 中文文梢:http://scrapy-chs.readthedocs.io
Scrapy-Splash 安装
Scrapy-Splash 是一个 Scrapy 中支持 JavaScript 渲染的工具
Scrapy-Splash 的安装分为两部分。
1:Splash 服务的安装,具体通过 Docker 安装后会启动一个 Splash 服务,我们可以通过它的接口来实现 JavaScript 页面的加载
2:Scrapy-Splash 的 Python 库的安装,安装之后即可在 Scrapy 中使用 Splash 服务
在安装之前需要先确保自己有 docker 这个应用,若没有,可以参考 笔者的笔记 docker 的安装于部署
安装
docker run -p 8050:8050 scrapinghub/splash
验证
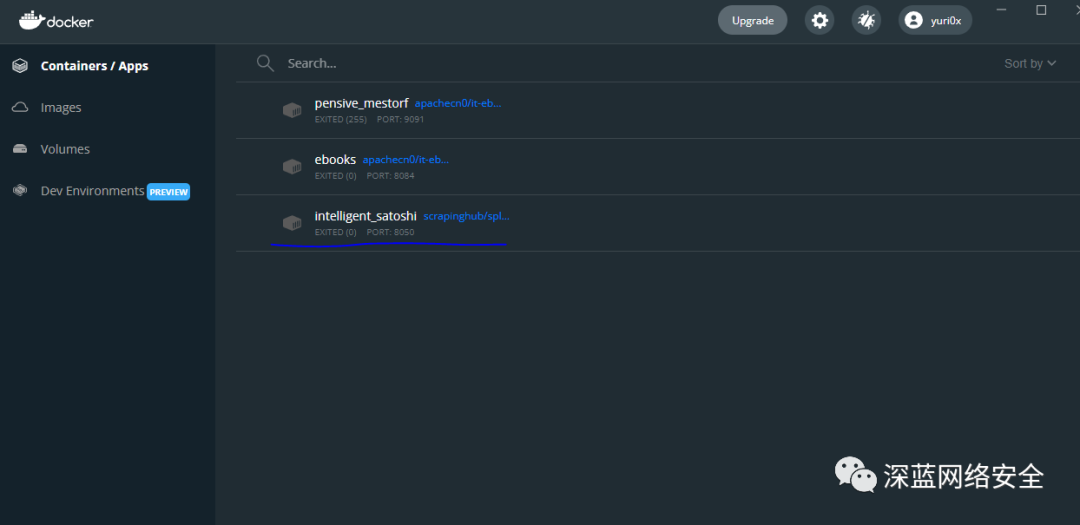
可以看到,docker 已经把镜像拉过来了。以后要运行 Scrapy-Splash 直接本地开 docker 即可
相关链接
- GitHub: https://github.com/scrapy-plugins/scrapy-splash
- PyPI: https://pypi.python.org/pypi/scrapy-splash
- 使用说明:https://github.com/scrapy-plugins/scrapy-splash#configuration
- Splash官方文档:http://splash.readthedocs.io
Scrapy-Redis 安装
Scrapy-Redis 是 Scrapy 的分布式扩展模块,有了它,我们就可以实现 Scrapy 分布式爬虫的搭建
C:\Users\yangh>pip3 install scrapy-redis
验证:
导入库不报错即可

相关链接
- GitHub:https://github.com/rmax/scrapy-redis
- PyPI:https://pypi.python.org/pypi/scrapy-redis
- 官方文档:http://scrapy-redis.readthedocs.io
0x08:部署其他相关库
Scrapyrt 安装
pip3 install scrapyrt
后面运行,需要在一个 scrapy 项目中运行才可,默认存在 9080 端口,使用 -p 端口切换
scrapyrt -p 9081
Gerapy 安装
pip3 install gerapy

![[DroneCAN]CAN-Convertor控制CAN电调电机](https://img-blog.csdnimg.cn/direct/e36b8708d49d40f5b6d48950a694f640.png)