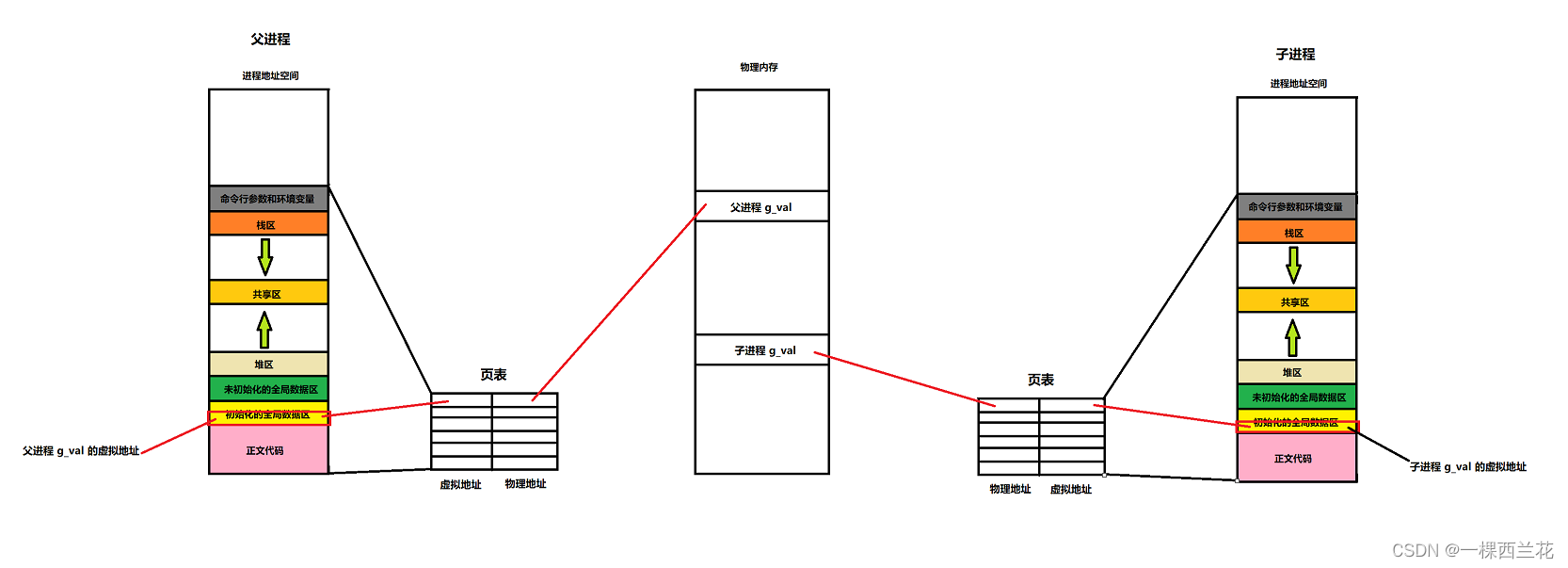
1求和
from openpyxl import load_workbook
import pandas as pd
def print_hi(name):
# Use a breakpoint in the code line below to debug your script.
print(f'Hi, {name}') # Press Ctrl+F8 to toggle the breakpoint.
# Press the green button in the gutter to run the script.
if __name__ == '__main__':
filePath1 = './src/原始数据精修.xlsx'
df1 = pd.read_excel(filePath1, sheet_name='销售明细')
index_list = ['部门名称', '年度名称', '季节名称', '商品代码', '商品名称', '品牌名称', '品类名称', '颜色名称']
# 求和方法二,需将文本的列指定为索引
df1 = df1.set_index(index_list)
df1['合计'] = df1.apply(lambda x: x.sum(), axis=1)
filePath2 = './src/处理结果精修.xlsx'
#重置索引,防止单元格合并
df1 = df1.reset_index()
df1.to_excel(filePath2, sheet_name="new_sheet", index=False, na_rep=0, inf_rep=0)
print(df1)
2.去除季节年度进行聚类
#去除年度和季节进行聚类
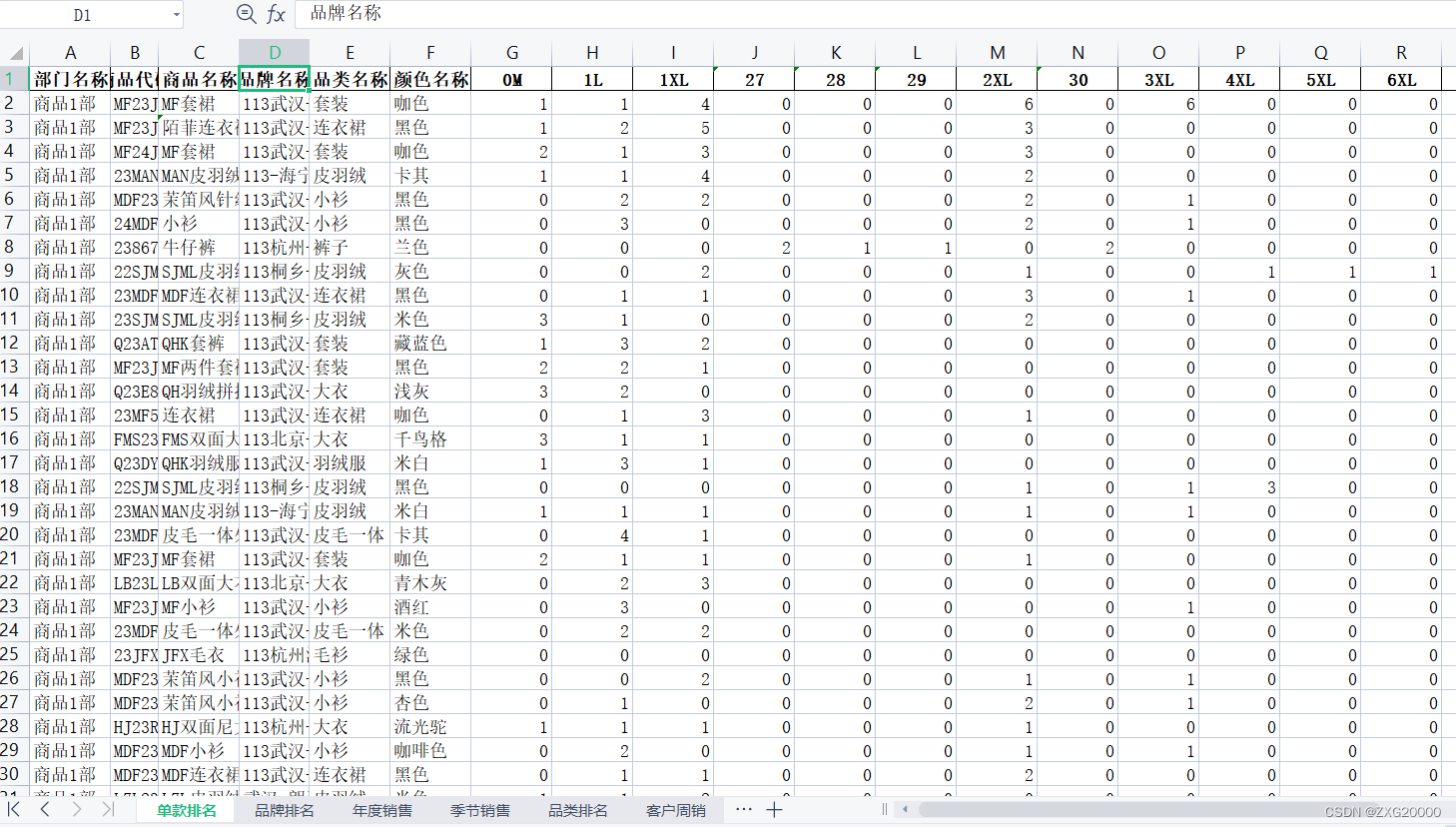
df2 = pd.read_excel(filePath2, sheet_name='单款排名')
df2.pop('年度名称')
df2.pop('季节名称')
index_list = ['部门名称', '商品代码', '商品名称', '品牌名称', '品类名称', '颜色名称']
value_list = ['0M','1L','1XL','27','28','29','2XL','30','3XL','4XL','5XL','6XL','S','均','合计']
#使用透视表聚合
df2 = df2.pivot_table(index= index_list,values=value_list,aggfunc='sum')
# 重置索引,防止单元格合并
df2 = df2.reset_index()
#将合计列放到最后面
#dataframe中某一列放到最后,并改名为销售明细
df2['销售明细'] = df2.pop('合计')
df2.to_excel(filePath2, sheet_name="单款排名", index=False, na_rep=0, inf_rep=0)
3完整数据处理过程代码
from openpyxl import load_workbook
import pandas as pd
def print_hi(name):
# Use a breakpoint in the code line below to debug your script.
print(f'Hi, {name}') # Press Ctrl+F8 to toggle the breakpoint.
# Press the green button in the gutter to run the script.
if __name__ == '__main__':
filePath1 = './src/原始数据精修.xlsx'
# 加载工作簿
wb = load_workbook(filePath1)
# 获取sheet页,修改第一个sheet页面为
name1 = wb.sheetnames[0]
ws1 = wb[name1]
ws1.title = "销售明细"
wb.save(filePath1)
#销售明细
df1 = pd.read_excel(filePath1, sheet_name='销售明细')
index_list = ['部门名称', '年度名称', '季节名称', '商品代码', '商品名称', '品牌名称', '品类名称', '颜色名称']
# 求和方法二,需将文本的列指定为索引
df1 = df1.set_index(index_list)
df1['合计'] = df1.apply(lambda x: x.sum(), axis=1)
filePath2 = './src/处理结果精修.xlsx'
#重置索引,防止单元格合并
df1 = df1.reset_index()
df1.to_excel(filePath2, sheet_name="new_sheet", index=False, na_rep=0, inf_rep=0)
#单款排名
#去除年度和季节进行聚类
df2 = df1.copy()
df2.pop('年度名称')
df2.pop('季节名称')
index_list = ['部门名称', '商品代码', '商品名称', '品牌名称', '品类名称', '颜色名称']
value_list = ['0M','1L','1XL','27','28','29','2XL','30','3XL','4XL','5XL','6XL','S','均','合计']
#使用透视表聚合
df2 = df2.pivot_table(index= index_list,values=value_list,aggfunc='sum')
# 重置索引,防止单元格合并
df2 = df2.reset_index()
#将合计列放到最后面
#dataframe中某一列放到最后,并改名为销售明细
df2['销售明细'] = df2.pop('合计')
df2.sort_values(by="销售明细", axis=0, ascending=False, inplace=True)
#品牌排名
df3 = df1.copy()
# 使用透视表聚合
df3 = df3.pivot_table(index='品牌名称', values='合计', aggfunc='sum')
# 重置索引,防止单元格合并
df3 = df3.reset_index()
# 将合计列放到最后面
# dataframe中某一列放到最后,并改名为销售明细
df3['销售明细'] = df3.pop('合计')
df3.sort_values(by="销售明细", axis=0, ascending=False, inplace=True)
#年度销售
df4 = df1.copy()
# 使用透视表聚合
print(df4)
df4 = df4.pivot_table(index=['年度名称', '季节名称'], values='合计', aggfunc='sum')
# 重置索引,防止单元格合并
df4 = df4.reset_index()
# 将合计列放到最后面
# dataframe中某一列放到最后,并改名为销售明细
df4['销售明细'] = df4.pop('合计')
df4.sort_values(by="销售明细", axis=0, ascending=False, inplace=True)
#季节销售
df5 = df1.copy()
#使用透视表聚合
df5 = df5.pivot_table(index=['季节名称'], values='合计', aggfunc='sum')
# 重置索引,防止单元格合并
df5 = df5.reset_index()
df5['销售明细'] = df5.pop('合计')
df5.sort_values(by="销售明细", axis=0, ascending=False, inplace=True)
#品类排名
df6 = df1.copy()
# 使用透视表聚合
df6 = df6.pivot_table(index=['品类名称'], values='合计', aggfunc='sum')
# 重置索引,防止单元格合并
df6 = df6.reset_index()
df6['销售明细'] = df6.pop('合计')
df6.sort_values(by="销售明细", axis=0, ascending=False, inplace=True)
# print(df1)
# 加载工作簿
filePath2 = './src/处理结果精修.xlsx'
wb = load_workbook(filePath2)
#客户周销
df7 = pd.DataFrame({'商店名称':[], '销售数量':[]})
#创建表
ws2 = wb.create_sheet("单款排名")
ws3 = wb.create_sheet("品牌排名")
ws4 = wb.create_sheet("年度销售")
ws5 = wb.create_sheet("季节销售")
ws6 = wb.create_sheet("品类排名")
ws7 = wb.create_sheet("客户周销")
wb.save(filePath2)
#将生成的工作表导入到程序中
result_sheet = pd.ExcelWriter(filePath2, engine='openpyxl') # 先定义要存入的文件名xxx,然后分别存入xxx下不同的sheet
df1.to_excel(result_sheet, "销售明细", index=False, na_rep=0, inf_rep=0)
df2.to_excel(result_sheet, "单款排名", index=False, na_rep=0, inf_rep=0)
df3.to_excel(result_sheet, "品牌排名", index=False, na_rep=0, inf_rep=0)
df4.to_excel(result_sheet, "年度销售", index=False, na_rep=0, inf_rep=0)
df5.to_excel(result_sheet, "季节销售", index=False, na_rep=0, inf_rep=0)
df6.to_excel(result_sheet, "品类排名", index=False, na_rep=0, inf_rep=0)
df7.to_excel(result_sheet, "客户周销", index=False, na_rep=0, inf_rep=0)
# 这步不能省,否则不生成文件
result_sheet._save()
初始文件格式

最终结果,处理完成
4格式处理
通过openpyxl进行格式处理
#销售明细
# 加载工作簿
wb1 = load_workbook('Mytest.xlsx')
# 获取sheet页
ws2 = wb1['销售明细']
示例
from openpyxl import Workbook
from openpyxl.styles import Font
# 创建一个新的工作簿和工作表
workbook = Workbook()
sheet = workbook.active
# 创建一个字体对象并设置属性
font = Font(
name='Arial', # 字体名称
size=12, # 字体大小
bold=True, # 是否加粗
italic=True, # 是否斜体
underline='single', # 下划线类型:single、double、none等
strike=True, # 是否有删除线
color='FF0000' # 字体颜色,十六进制RGB值
)
# 在单元格A1中应用字体样式
sheet['A1'].font = font
sheet['A1'].value = 'Hello, World!'
# 保存工作簿
workbook.save('E:\\UserData\\Desktop\\font_example.xlsx')
销售明细的格式代码
# 销售明细
# 加载工作簿
wb1 = load_workbook(filePath2)
# 获取sheet页
ws1 = wb1['销售明细']
#设置字体
# 创建一个字体对象并设置属性
font = Font(
name='微软雅黑', # 字体名称
size=18, # 字体大小
bold=True, # 是否加粗
italic=False, # 是否斜体
underline='none', # 下划线类型:single、double、none等
strike=False, # 是否有删除线
color='000000', # 字体颜色,十六进制RGB值
vertAlign='baseline'
)
dept_name = ws1['A2'].value
ws1.insert_rows(0, 1) #插入一行
min_row = ws1.min_row
max_row = ws1.max_row
min_col = ws1.min_column
max_col = ws1.max_column
#设置单元格格式
# 调整行高
ws1.row_dimensions[1].height = 24
#合并单元格
# 需要合并的左上方和右下方单元格坐标
ws1.merge_cells(start_row=1, start_column=1, end_row=1, end_column=max_col)
# 在单元格A1中应用字体样式
ws1['A1'].font = font
ws1['A1'].value = dept_name + '销售明细'
# 设置字体居中
ws1['A1'].alignment = Alignment(horizontal='center', vertical='center')
#设置颜色
#行
for cell in ws1['2']:
cell.fill = PatternFill("solid", fgColor="FFFF00")
cell.border = Border(left=Side(style='thin'), bottom=Side(style='thin'), right=Side(style='thin'), top=Side(style='thin'))
#列
for cell in ws1[number_to_column(max_col)]:
cell.fill = PatternFill("solid", fgColor="FFFF00")
cell.border = Border(left=Side(style='thin'), bottom=Side(style='thin'), right=Side(style='thin'),
top=Side(style='thin'))
#最后一行
# 行
for cell in ws1[max_row+1]:
cell.fill = PatternFill("solid", fgColor="FFFF00")
cell.border = Border(left=Side(style='thin'), bottom=Side(style='thin'), right=Side(style='thin'),
top=Side(style='thin'))
# 调整行高
ws1.row_dimensions[max_row+1].height = 24
# 合并单元格
# 需要合并的左上方和右下方单元格坐标
ws1.merge_cells(start_row=max_row+1, start_column=1, end_row=max_row+1, end_column=8)
cell = ws1.cell(column=1, row=max_row+1)
cell.font = font
cell.value = '合计'
# 设置字体居中
cell.alignment = Alignment(horizontal='center', vertical='center')
# 保存工作簿
wb1.save(filePath2)
将列序号转变为excel序号
import string
def number_to_column(n):
"""Convert a number to the corresponding column letter in Excel"""
column = ""
while n > 0:
n -= 1
column = string.ascii_uppercase[n % 26] + column
n //= 26
return column
# Example usage
print(number_to_column(1)) # Output: "A"
完整代码
from openpyxl import load_workbook
import pandas as pd
from openpyxl.styles import *
import string
def print_hi(name):
# Use a breakpoint in the code line below to debug your script.
print(f'Hi, {name}') # Press Ctrl+F8 to toggle the breakpoint.
def number_to_column(n):
"""Convert a number to the corresponding column letter in Excel"""
column = ""
while n > 0:
n -= 1
column = string.ascii_uppercase[n % 26] + column
n //= 26
return column
# Press the green button in the gutter to run the script.
if __name__ == '__main__':
filePath1 = './src/原始数据精修.xlsx'
# 加载工作簿
wb = load_workbook(filePath1)
# 获取sheet页,修改第一个sheet页面为
name1 = wb.sheetnames[0]
ws1 = wb[name1]
ws1.title = "销售明细"
wb.save(filePath1)
#销售明细
df1 = pd.read_excel(filePath1, sheet_name='销售明细')
index_list = ['部门名称', '年度名称', '季节名称', '商品代码', '商品名称', '品牌名称', '品类名称', '颜色名称']
# 求和方法二,需将文本的列指定为索引
df1 = df1.set_index(index_list)
df1['合计'] = df1.apply(lambda x: x.sum(), axis=1)
filePath2 = './src/处理结果精修.xlsx'
#重置索引,防止单元格合并
df1 = df1.reset_index()
df1.to_excel(filePath2, sheet_name="new_sheet", index=False, na_rep=0, inf_rep=0)
#单款排名
#去除年度和季节进行聚类
df2 = df1.copy()
df2.pop('年度名称')
df2.pop('季节名称')
index_list = ['部门名称', '商品代码', '商品名称', '品牌名称', '品类名称', '颜色名称']
value_list = ['0M','1L','1XL','27','28','29','2XL','30','3XL','4XL','5XL','6XL','S','均','合计']
#使用透视表聚合
df2 = df2.pivot_table(index= index_list,values=value_list,aggfunc='sum')
# 重置索引,防止单元格合并
df2 = df2.reset_index()
#将合计列放到最后面
#dataframe中某一列放到最后,并改名为销售明细
df2['销售明细'] = df2.pop('合计')
df2.sort_values(by="销售明细", axis=0, ascending=False, inplace=True)
#品牌排名
df3 = df1.copy()
# 使用透视表聚合
df3 = df3.pivot_table(index='品牌名称', values='合计', aggfunc='sum')
# 重置索引,防止单元格合并
df3 = df3.reset_index()
# 将合计列放到最后面
# dataframe中某一列放到最后,并改名为销售明细
df3['销售明细'] = df3.pop('合计')
df3.sort_values(by="销售明细", axis=0, ascending=False, inplace=True)
#年度销售
df4 = df1.copy()
# 使用透视表聚合
print(df4)
df4 = df4.pivot_table(index=['年度名称', '季节名称'], values='合计', aggfunc='sum')
# 重置索引,防止单元格合并
df4 = df4.reset_index()
# 将合计列放到最后面
# dataframe中某一列放到最后,并改名为销售明细
df4['销售明细'] = df4.pop('合计')
df4.sort_values(by="销售明细", axis=0, ascending=False, inplace=True)
#季节销售
df5 = df1.copy()
#使用透视表聚合
df5 = df5.pivot_table(index=['季节名称'], values='合计', aggfunc='sum')
# 重置索引,防止单元格合并
df5 = df5.reset_index()
df5['销售明细'] = df5.pop('合计')
df5.sort_values(by="销售明细", axis=0, ascending=False, inplace=True)
#品类排名
df6 = df1.copy()
# 使用透视表聚合
df6 = df6.pivot_table(index=['品类名称'], values='合计', aggfunc='sum')
# 重置索引,防止单元格合并
df6 = df6.reset_index()
df6['销售明细'] = df6.pop('合计')
df6.sort_values(by="销售明细", axis=0, ascending=False, inplace=True)
# print(df1)
# 加载工作簿
filePath2 = './src/处理结果精修.xlsx'
wb = load_workbook(filePath2)
#客户周销
df7 = pd.DataFrame({'商店名称':[], '销售数量':[]})
#创建表
ws2 = wb.create_sheet("单款排名")
ws3 = wb.create_sheet("品牌排名")
ws4 = wb.create_sheet("年度销售")
ws5 = wb.create_sheet("季节销售")
ws6 = wb.create_sheet("品类排名")
ws7 = wb.create_sheet("客户周销")
wb.save(filePath2)
#将生成的工作表导入到程序中
result_sheet = pd.ExcelWriter(filePath2, engine='openpyxl') # 先定义要存入的文件名xxx,然后分别存入xxx下不同的sheet
df1.to_excel(result_sheet, "销售明细", index=False, na_rep=0, inf_rep=0)
df2.to_excel(result_sheet, "单款排名", index=False, na_rep=0, inf_rep=0)
df3.to_excel(result_sheet, "品牌排名", index=False, na_rep=0, inf_rep=0)
df4.to_excel(result_sheet, "年度销售", index=False, na_rep=0, inf_rep=0)
df5.to_excel(result_sheet, "季节销售", index=False, na_rep=0, inf_rep=0)
df6.to_excel(result_sheet, "品类排名", index=False, na_rep=0, inf_rep=0)
df7.to_excel(result_sheet, "客户周销", index=False, na_rep=0, inf_rep=0)
# 这步不能省,否则不生成文件
result_sheet.save()
# 销售明细
# 加载工作簿
wb1 = load_workbook(filePath2)
# 获取sheet页
ws1 = wb1['销售明细']
#设置字体
# 创建一个字体对象并设置属性
font = Font(
name='微软雅黑', # 字体名称
size=18, # 字体大小
bold=True, # 是否加粗
italic=False, # 是否斜体
underline='none', # 下划线类型:single、double、none等
strike=False, # 是否有删除线
color='000000', # 字体颜色,十六进制RGB值
vertAlign='baseline'
)
dept_name = ws1['A2'].value
ws1.insert_rows(0, 1) #插入一行
min_row = ws1.min_row
max_row = ws1.max_row
min_col = ws1.min_column
max_col = ws1.max_column
#设置单元格格式
# 调整行高
ws1.row_dimensions[1].height = 24
#合并单元格
# 需要合并的左上方和右下方单元格坐标
ws1.merge_cells(start_row=1, start_column=1, end_row=1, end_column=max_col)
# 在单元格A1中应用字体样式
ws1['A1'].font = font
ws1['A1'].value = dept_name + '销售明细'
# 设置字体居中
ws1['A1'].alignment = Alignment(horizontal='center', vertical='center')
#设置颜色
#行
for cell in ws1['2']:
cell.fill = PatternFill("solid", fgColor="FFFF00")
cell.border = Border(left=Side(style='thin'), bottom=Side(style='thin'), right=Side(style='thin'), top=Side(style='thin'))
#列
for cell in ws1[number_to_column(max_col)]:
cell.fill = PatternFill("solid", fgColor="FFFF00")
cell.border = Border(left=Side(style='thin'), bottom=Side(style='thin'), right=Side(style='thin'),
top=Side(style='thin'))
#最后一行
# 行
for cell in ws1[max_row+1]:
cell.fill = PatternFill("solid", fgColor="FFFF00")
cell.border = Border(left=Side(style='thin'), bottom=Side(style='thin'), right=Side(style='thin'),
top=Side(style='thin'))
# 调整行高
ws1.row_dimensions[max_row+1].height = 24
# 合并单元格
# 需要合并的左上方和右下方单元格坐标
ws1.merge_cells(start_row=max_row+1, start_column=1, end_row=max_row+1, end_column=8)
cell = ws1.cell(column=1, row=max_row+1)
cell.font = font
cell.value = '合计'
# 设置字体居中
cell.alignment = Alignment(horizontal='center', vertical='center')
# 保存工作簿
wb1.save(filePath2)