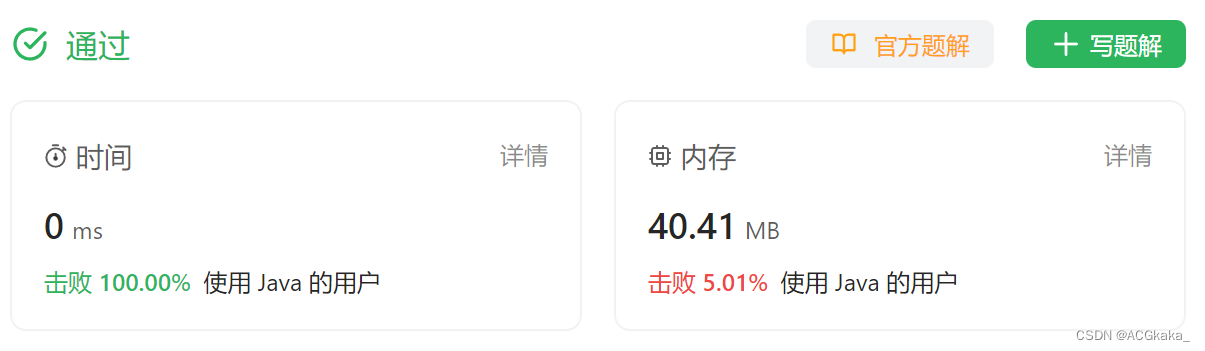
接上篇《43.验证码识别工具结合requests的使用》
上一篇我们学习了如何使用验证码识别工具进行登录验证的自动识别。本篇我们开启一个新的章节,来学习一下快速、高层次的屏幕抓取和web抓取框架Scrapy。
一、Scrapy框架的背景和特点

Scrapy框架是一个为了爬取网站数据,提取结构性数据而编写的应用框架,可以应用在包括数据挖掘,信息处理或存储历史数据等一系列程序中。
那么什么是结构化数据?举个例子,例如电子书网站的网页,里面有很多书籍的信息:
打开源码后,可以看到每个书籍都是由<li></li>标签包裹的,结构是高度重复且一致的,这种数据就称之为“结构性数据”:
Scrapy框架对这种结构性数据有着很强的处理能力。
Scrapy框架具有简单易用、高效稳定、功能强大等特点,它采用了异步IO和事件驱动的设计模式,使得其可以轻松地处理大量并发请求,提高抓取效率。同时,Scrapy框架还提供了丰富的数据处理和输出功能,方便用户进行数据清洗、分析和可视化等工作。
与其他网络爬虫框架相比,Scrapy框架具有以下优势:
简单易用:Scrapy框架提供了丰富的文档和教程,使得用户可以快速上手;
高效稳定:Scrapy框架采用了异步IO和事件驱动的设计模式,能够处理大量并发请求,提高抓取效率;
功能强大:Scrapy框架提供了丰富的数据处理和输出功能,方便用户进行数据清洗、分析和可视化等工作;
社区活跃:Scrapy框架拥有庞大的用户群体和活跃的社区,方便用户交流和学习。
二、Scrapy框架的基本概念和原理
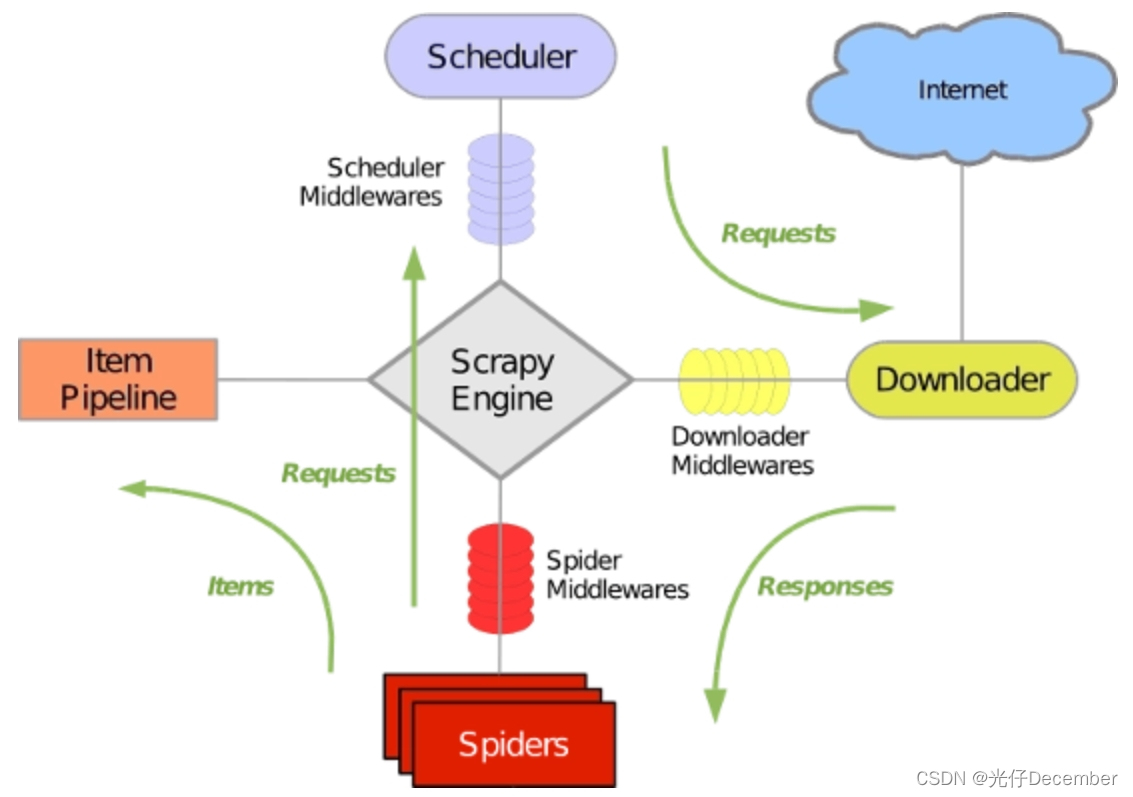
Scrapy框架的基本概念包括Item、Spider、Pipeline、Scheduler、Downloader、Engine等。其中,Item是数据模型,用于存储抓取到的数据;Spider是爬虫类,用于定义如何抓取数据;Pipeline是数据处理管道,用于对抓取到的数据进行清洗、分析和存储等工作;Scheduler是调度器,用于管理请求队列;Downloader是下载器,用于下载网页内容;Engine是引擎,用于协调各个组件的工作。
Scrapy框架的工作原理:
注:图片来自[寻_觅]博主
用户通过编写Spider类来定义如何抓取数据,然后Spider将请求发送给Scheduler,Scheduler将请求放入队列中等待处理。当Engine接收到请求后,它会通过Downloader下载网页内容,并将内容传递给Spider进行处理。Spider将处理后的数据传递给Pipeline进行进一步的处理和分析。同时,Engine还会协调各个组件的工作,确保整个抓取过程的顺利进行。
三、Scrapy框架的适用场景
Scrapy框架是一个功能强大的Python库,专为数据抓取和网页爬取而设计。它适用于各种应用场景,以下是Scrapy框架的一些主要适用场景:
1、数据挖掘和数据分析:Scrapy框架可以快速抓取大量网页数据,提取所需信息并将其存储在数据库中,供后续分析和挖掘使用。这种能力使得Scrapy在数据挖掘和数据分析领域非常有用。
2、监测网站变化:Scrapy可以定期抓取特定网站的数据,并对比新旧数据之间的差异。这种能力可以用于监测网站更新、新闻发布或其他变化。
3、收集公共数据:许多政府和公共机构公开了大量数据,使用Scrapy框架可以轻松地抓取这些数据并进行分析。例如,抓取天气预报、交通信息或公共安全数据等。
4、聚合新闻和博客文章:Scrapy可以用来抓取新闻网站、博客等网站的最新文章,并将它们聚合到一个平台上进行展示。
5、在线商店爬取:在线商店通常包含大量产品信息和价格信息。使用Scrapy框架可以快速抓取这些信息,并通过比价引擎为用户提供最优惠的商品推荐。
6、社交媒体抓取:社交媒体网站(如Twitter、Facebook等)提供了丰富的用户数据。通过Scrapy框架,可以抓取这些数据并进行分析,以便了解公众舆论、用户行为等。
7、个性化推荐系统:通过抓取用户感兴趣的网页内容,Scrapy可以帮助构建个性化的推荐系统。这些推荐可以基于用户的浏览历史、兴趣爱好或其他相关因素。
8、网页结构分析和可视化:Scrapy可以用于分析网页的结构和布局,帮助用户更好地理解网页的组织方式。此外,通过使用Scrapy的内置可视化工具,还可以轻松地将网页呈现为可读性更高的HTML或XML格式。
9、网络日志分析:企业可以使用Scrapy框架抓取和分析他们的网络日志数据,以获取有关网站流量、用户行为和其他有用信息的洞察。
总之,Scrapy框架适用于需要从互联网上抓取和分析大量数据的各种场景。无论是学术研究、商业应用还是个人项目,Scrapy都是一个强大而灵活的工具,可以帮助用户轻松地实现网页爬取任务。
四、Scrapy框架的安装与配置
1、安装Scrapy框架
在安装Scrapy之前,需要确保你的Python环境已经配置好。Scrapy框架的安装相对简单,可以通过pip命令进行安装。以下是安装Scrapy的步骤:
(1)打开终端或命令提示符,输入以下命令安装Scrapy:
pip install scrapy
(2)等待安装完成。安装完成后,可以通过输入scrapy --version命令来验证Scrapy是否成功安装,并显示安装的版本号。
2、创建第一个Scrapy项目
安装完Scrapy后,我们可以创建一个新的Scrapy项目。以下是创建Scrapy项目的步骤:
(1)在终端或命令提示符中,导航到你想要创建项目的目录。
(2)输入以下命令创建一个新的Scrapy项目:
scrapy startproject myproject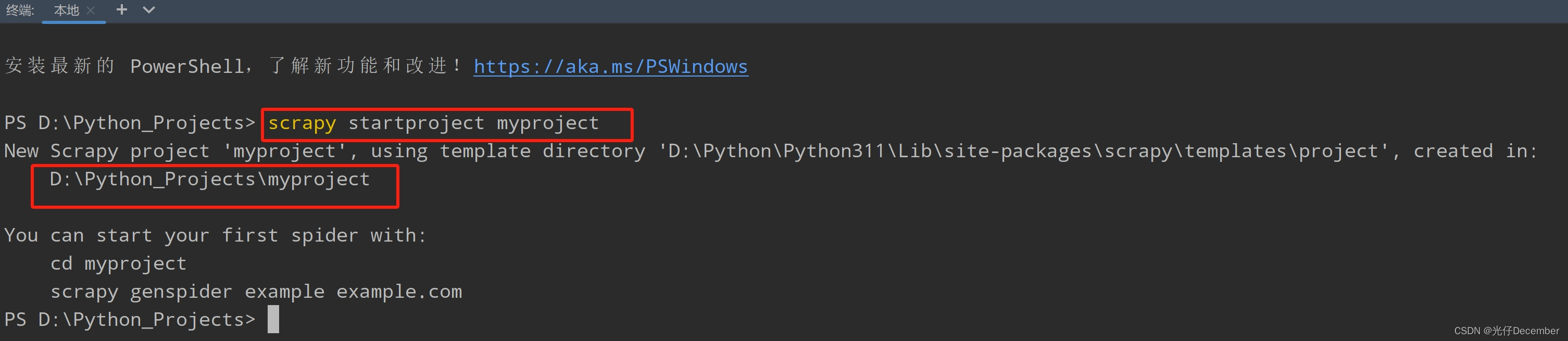
其中,myproject是你想要给项目起的名称。注意,项目名字不允许使用数字开头,也不能包含中文。
(3)执行上述命令后,Scrapy将会在当前目录下创建一个名为myproject的文件夹,并在其中生成一些基本的文件和目录结构: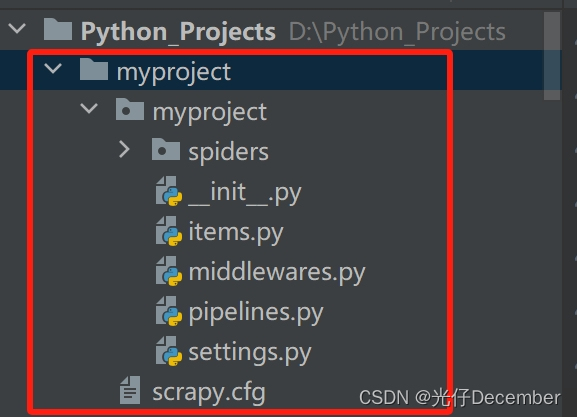
(4)目录结构介绍
3、Scrapy项目配置详解
在Scrapy项目中,有一个重要的配置文件settings.py,用于配置项目的各种参数和设置: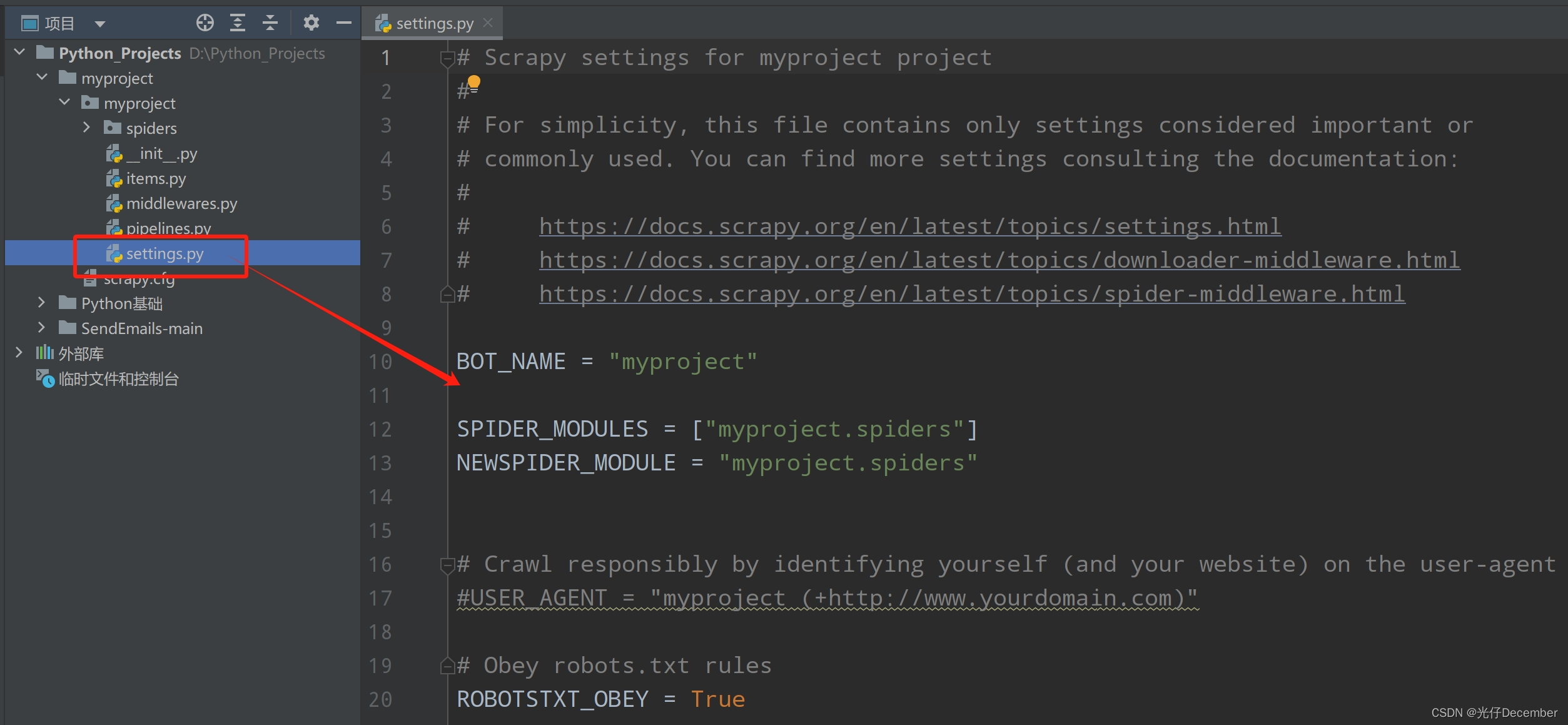
以下是一些常见的配置选项及其说明:
●ROBOTSTXT_OBEY:默认为True,表示遵守网站的robots.txt规则。如果设置为False,则忽略robots.txt文件。
●USER_AGENT:用于设置爬虫的User-Agent,可以伪装成不同的浏览器或其他客户端。
●CONCURRENT_REQUESTS:同时进行的最大请求数。可以根据需要进行调整,以充分利用系统资源。
●DOWNLOAD_DELAY:下载器在连续请求之间的延迟时间(秒)。可以用来限制爬取速度,以避免对目标网站造成过大负担。
●ITEM_PIPELINES:定义项目使用的数据处理管道。可以在这里指定自定义的Pipeline类。
●LOG_LEVEL:日志级别设置,可以选择不同的日志输出级别,如DEBUG、INFO、WARNING等。
●DUPEFILTER_CLASS:用于处理重复请求的过滤器类。可以自定义过滤器类,以便更灵活地处理重复请求。
●COOKIES_ENABLED:是否启用Cookie处理。默认为True,表示启用Cookie处理。如果设置为False,则不处理Cookie。
●HTTPCACHE_ENABLED:是否启用HTTP缓存。默认为False,表示不启用HTTP缓存。如果设置为True,则启用HTTP缓存功能,可以加速对相同网页的爬取速度。
五、Scrapy命令行工具的使用
Scrapy提供了一套命令行工具,方便用户进行项目的创建、运行和调试等操作。以下是一些常用的Scrapy命令行工具及其功能:
●scrapy startproject <project_name>:创建一个新的Scrapy项目。
这个命令刚刚我们已经创建了一个项目了,这里不再赘述。
●scrapy genspider <spider_name> <domain>:生成一个新的Spider爬虫类。
我们刚刚创建完工程后,仅仅是将框架工程搭建好了,我们具体要爬取的网络的逻辑,还是需要我们自己编写的,所以我们需要在spiders文件夹下创建我们的爬虫程序,这里的“spider_name”是爬虫文件的名字,而<domain>是我们要爬取的网页。
例如我们要爬取百度首页,我们进入spiders文件夹下输入以下命令:
scrapy genspider baidu www.baidu.com注:这里域名不需要加“https://”,因为文件内会自动拼接http头。
可以看到spiders文件夹下生成了一个名为“baidu.py”的文件: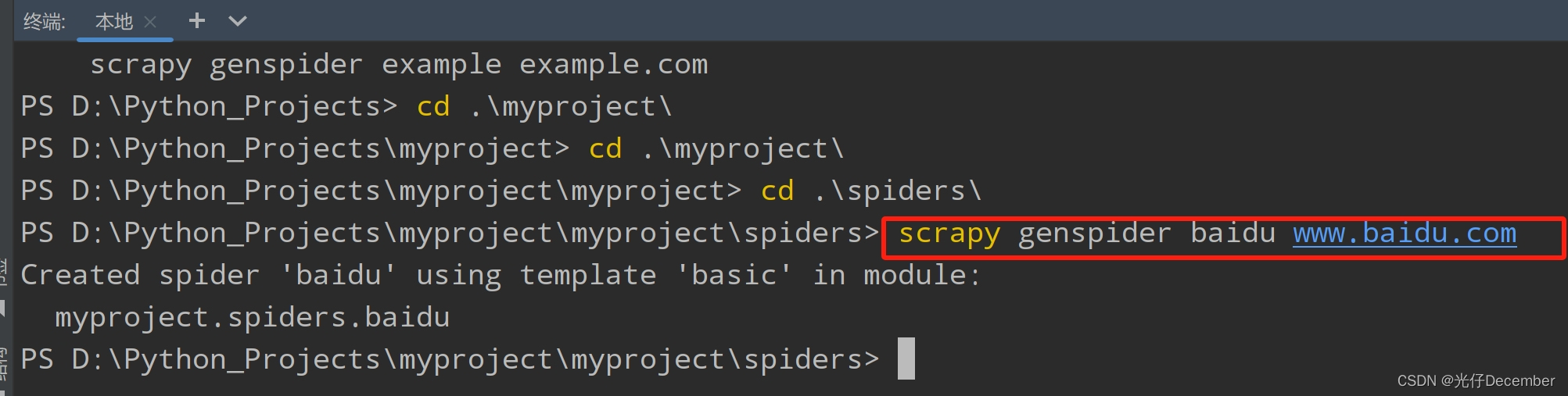
文件内容为:
import scrapy
class BaiduSpider(scrapy.Spider):
# 爬虫的名字,用于运行爬虫的时候,使用的值
name = "baidu"
# 允许访问的域名
allowed_domains = ["www.baidu.com"]
# 起始的Url地址,指的是第一次要访问的域名
start_urls = ["https://www.baidu.com"]
# 是执行了start_urls之后,执行的方法
# 方法中的response就是返回的那个对象
# 相当于 response = urllib.request.urlopen()
# 或 response = requests.get()
def parse(self, response):
pass最后一句pass语句是python中的占位符,它没有实际作用,但可以保证程序正常运行,允许我们以后再来实现具体的功能。
这里我们将pass修改为一个print语句,用来检验我们的爬虫是否执行成功。
print("我的第一个爬虫")●scrapy crawl <spider_name>:运行指定的Spider爬虫类进行爬取任务。
编写完爬虫后,我们需要使用crawl命令来执行我们的爬虫文件,spider_name就是我们上面创建的爬虫程序:
scrapy crawl baidu效果:
这里看到爬取被拒绝了,是因为百度的robots.txt不允许我们爬取该页面。这里解释一下robots.txt,它是一个“君子协议”,该文件规定了搜索引擎抓取工具可以访问网站上的哪些网址,并不禁止搜索引擎将某个网页纳入索引。
我们可以输入“https://www.baidu.com/robots.txt”地址,来查看百度的爬虫允许规则:
可以看到包含“baidu”在内的域名都不允许爬取。
那怎么办呢?我们可以设置settings.py中设置“ROBOTSTST_OBEY”参数为False,表示不遵循网站的反爬虫协议,这样就可以爬取相关页面了(当然这里不提倡哈,大家知道就好):
再运行一次爬虫程序,可以看到我们的print内容已经打印出来了: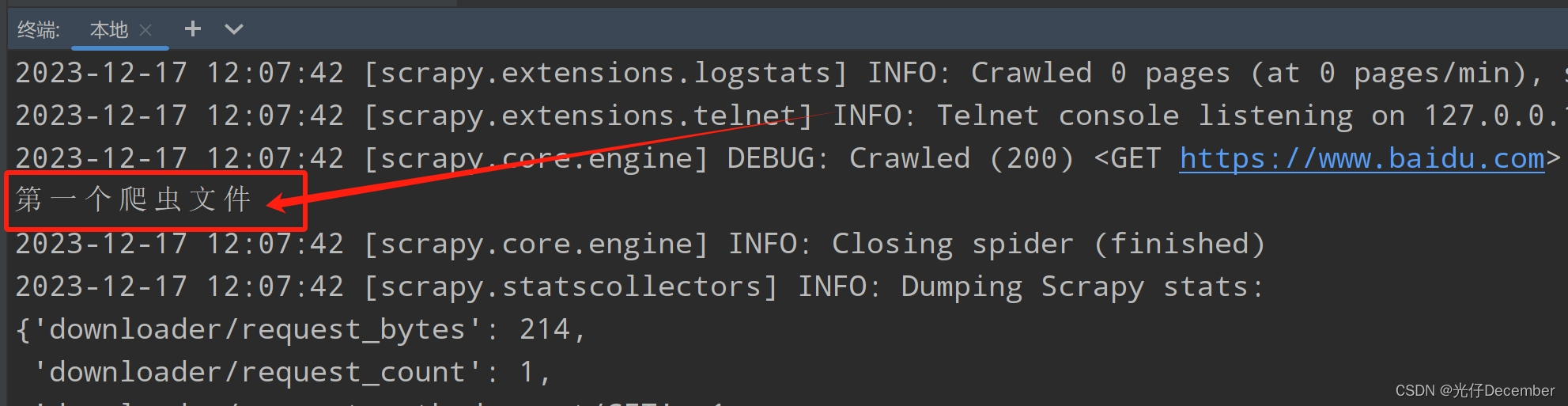
●scrapy list:列出当前项目中可用的Spider爬虫类。
还有以下指令,大家需要的话可以自己详细了解下:
●scrapy fetch <url>:下载指定的网页内容,并显示其内容和相关信息。
●scrapy view <url>:在浏览器中打开指定的网页链接,方便用户查看网页结构和样式等信息。
●scrapy shell <url>:启动一个交互式的Scrapy Shell环境,方便用户进行网页的调试和测试。
关于Scrapy的基本介绍和安装已经全部讲解完毕了,下一篇我们详细讲解一下Scrapy框架的核心组件。
参考:尚硅谷Python爬虫教程小白零基础速通
转载请注明出处:https://guangzai.blog.csdn.net/article/details/135043242