目录
一、代码作用(rpn_function.py)
二、代码解析
2.1 RegionProposalNetwork类
2.1.1 初始化函数__init__
2.1.2 正向传播过程forward
2.1.3 concat_box_prediction_layers函数
2.1.4 permute_and_flatten
2.1.5 filter_proposals
2.1.6 _get_top_n_idx
2.2 BoxCoder类(det_utils.py)
2.2.1 decode
2.2.2 decode_single
2.2.3 限制shape
2.2.4 删除小目标remove_small_boxes
2.2.5 batched_nms
一、代码作用(rpn_function.py)
如何利用AnchorsGenerator生成的anchors信息以及RPNHead预测的目标回归参数信息得到proposal,再通过一系列的算法滤除我们的proposal得到RPN模块最终输出的proposal。
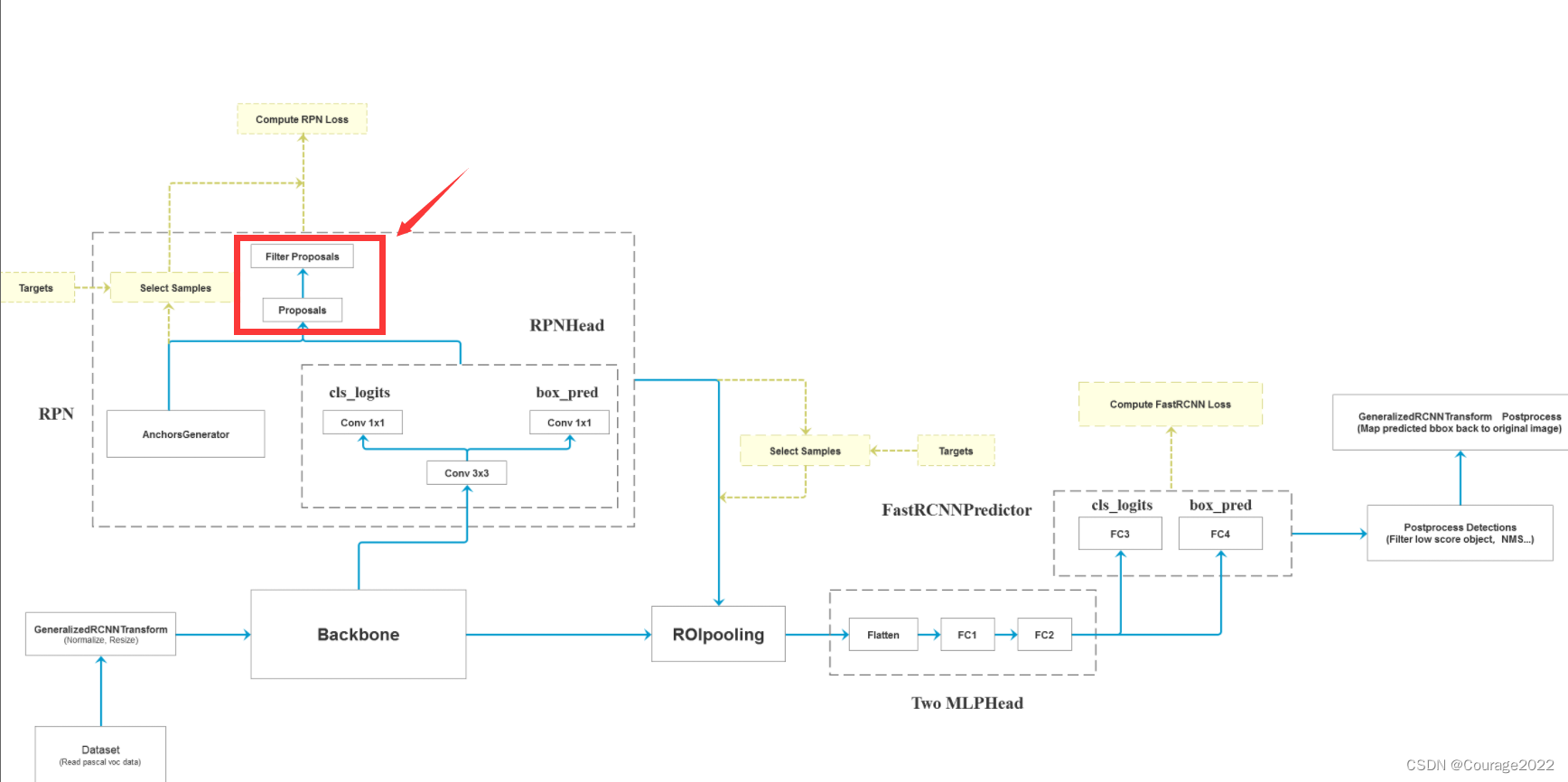
二、代码解析
2.1 RegionProposalNetwork类
2.1.1 初始化函数__init__
#anchor_generator #head #fg_iou_thresh,bg_iou_thresh rpn计算损失时,采集正负样本设置的阈值 前景背景 #batch_size_per_image RPPN在计算损失时采用正负样本的总个数 #positive_fraction 正样本占的比例 #pre_nms_top_n 在nms处理之前针对每个预测特征层所保留的目标个数 #post_nms_top_n 在nms处理之后所剩余的目标个数 即rpn输出的proposal的个数 #score_thresh 在nms处理时的阈值 def __init__(self, anchor_generator, head, fg_iou_thresh, bg_iou_thresh, batch_size_per_image, positive_fraction, pre_nms_top_n, post_nms_top_n, nms_thresh, score_thresh=0.0): super(RegionProposalNetwork, self).__init__() self.anchor_generator = anchor_generator self.head = head #简单的进行实例化而已 self.box_coder = det_utils.BoxCoder(weights=(1.0, 1.0, 1.0, 1.0)) # use during training # 计算anchors与真实bbox的iou self.box_similarity = box_ops.box_iou self.proposal_matcher = det_utils.Matcher( fg_iou_thresh, # 当iou大于fg_iou_thresh(0.7)时视为正样本 bg_iou_thresh, # 当iou小于bg_iou_thresh(0.3)时视为负样本 allow_low_quality_matches=True ) self.fg_bg_sampler = det_utils.BalancedPositiveNegativeSampler( batch_size_per_image, positive_fraction # 256, 0.5 ) # use during testing self._pre_nms_top_n = pre_nms_top_n self._post_nms_top_n = post_nms_top_n self.nms_thresh = nms_thresh self.score_thresh = score_thresh self.min_size = 1.在faster_rcnn_framework.py中我们有初始化RegionProposalNetwork类,代码如下:
# 定义整个RPN框架 rpn = RegionProposalNetwork( rpn_anchor_generator, rpn_head, rpn_fg_iou_thresh, rpn_bg_iou_thresh, rpn_batch_size_per_image, rpn_positive_fraction, rpn_pre_nms_top_n, rpn_post_nms_top_n, rpn_nms_thresh, score_thresh=rpn_score_thresh)rpn_anchor_generator是通过AnchorsGenerator类实现的:
# 若anchor生成器为空,则自动生成针对resnet50_fpn的anchor生成器 #在五个预测特征层上预测 针对每个预测特征层会使用 if rpn_anchor_generator is None: anchor_sizes = ((32,), (64,), (128,), (256,), (512,)) aspect_ratios = ((0.5, 1.0, 2.0),) * len(anchor_sizes) rpn_anchor_generator = AnchorsGenerator( anchor_sizes, aspect_ratios )Faster RCNN网络源码解读(Ⅵ) --- RPN网络代码解析(上)RPNHead类与AnchorsGenerator类解析
https://blog.csdn.net/qq_41694024/article/details/128502835 rpn_head也是我们在上篇博客中所述的类生成的。
# 生成RPN通过滑动窗口预测网络部分 if rpn_head is None: rpn_head = RPNHead( out_channels, rpn_anchor_generator.num_anchors_per_location()[0] )rpn_fg_iou_thresh=0.7, rpn_bg_iou_thresh=0.3, # rpn计算损失时,采集正负样本设置的阈值,即如果anchor与gtbox的iou值大于0.7设置为正样本,anchor与gtbox的iou值小于0.3设置为负样本,anchor与gtbox的iou值大于0.3小于0.7直接舍去。
rpn_batch_size_per_image=256, rpn_positive_fraction=0.5, # rpn计算损失时采样的总样本数,以及正样本占总样本的比例。
rpn_pre_nms_top_n_train=2000 # rpn中在nms处理前保留的proposal数(根据score)
rpn_post_nms_top_n_train=2000 # rpn中在nms处理后保留的proposal数
rpn_nms_thresh=0.7 # rpn中进行nms处理时使用的iou阈值
然后代码的初始化部分简单的初始化了一些类,我们在用到的时候再说。
self.box_similarity = box_ops.box_iou是一个计算iou的方法:在boxes.py里面
def box_iou(boxes1, boxes2): """ Return intersection-over-union (Jaccard index) of boxes. Both sets of boxes are expected to be in (x1, y1, x2, y2) format. Arguments: boxes1 (Tensor[N, 4]) boxes2 (Tensor[M, 4]) Returns: iou (Tensor[N, M]): the NxM matrix containing the pairwise IoU values for every element in boxes1 and boxes2 """ area1 = box_area(boxes1) area2 = box_area(boxes2) # When the shapes do not match, # the shape of the returned output tensor follows the broadcasting rules lt = torch.max(boxes1[:, None, :2], boxes2[:, :2]) # left-top [N,M,2] rb = torch.min(boxes1[:, None, 2:], boxes2[:, 2:]) # right-bottom [N,M,2] wh = (rb - lt).clamp(min=0) # [N,M,2] inter = wh[:, :, 0] * wh[:, :, 1] # [N,M] iou = inter / (area1[:, None] + area2 - inter) return iou
2.1.2 正向传播过程forward
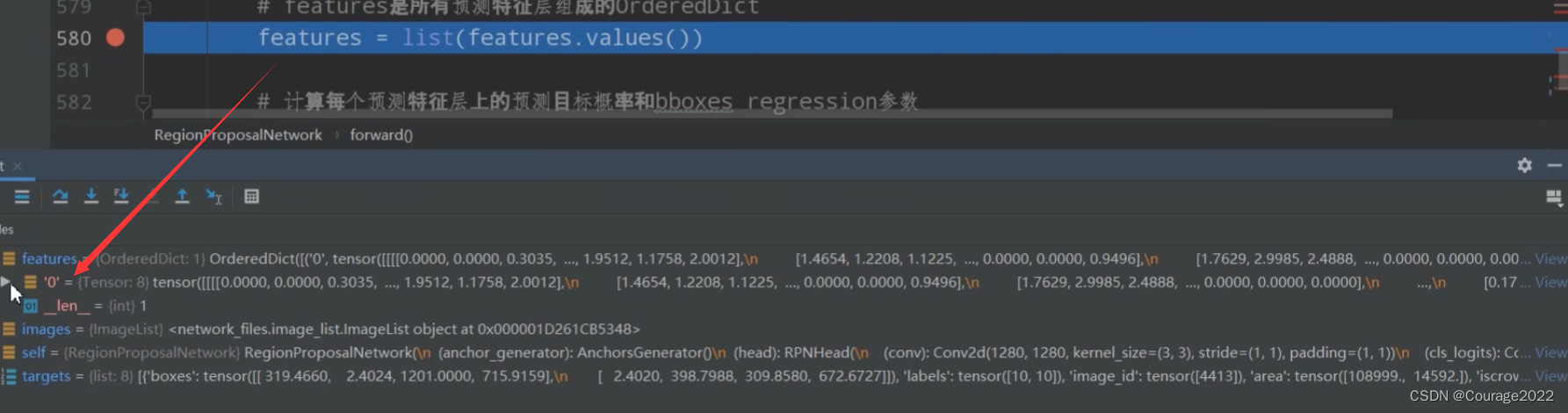
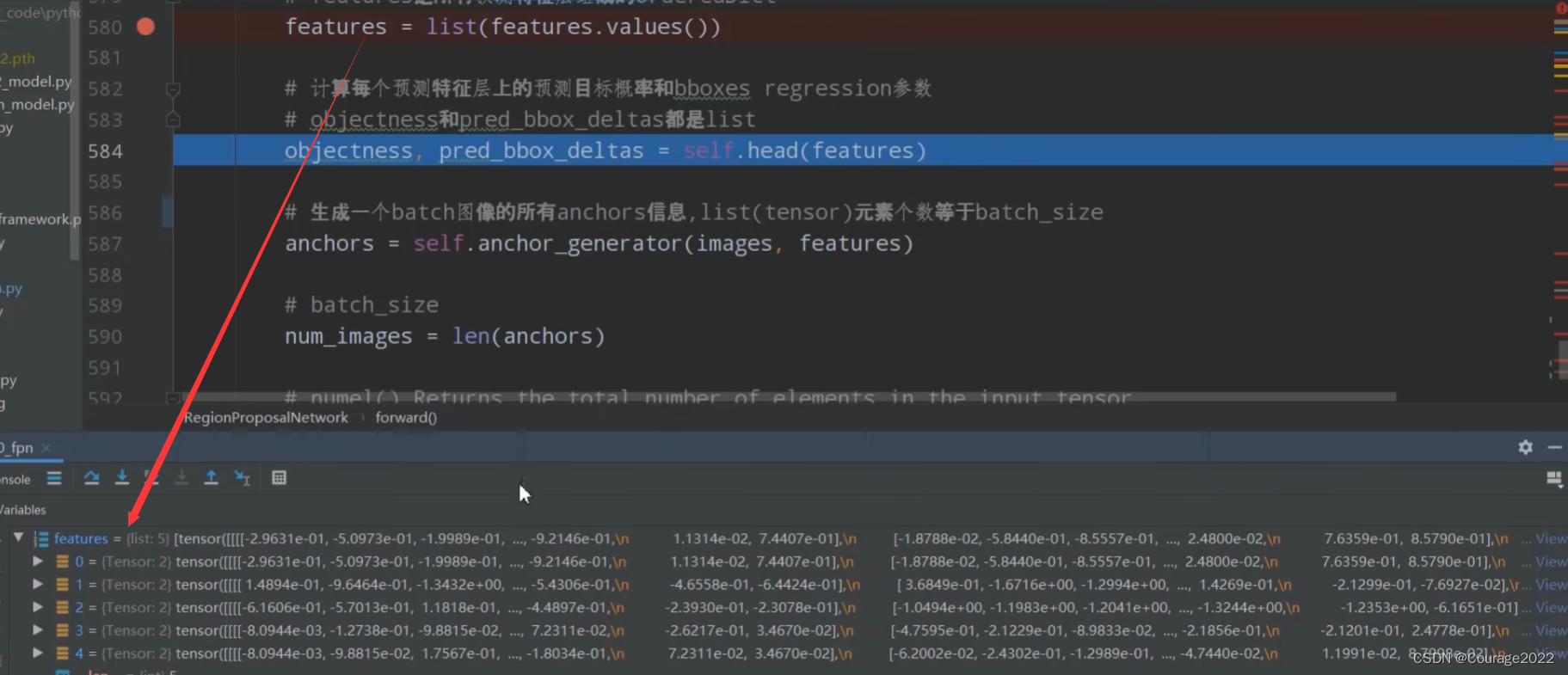
#features是预测特征层的特征矩阵 def forward(self, images, # type: ImageList features, # type: Dict[str, Tensor] targets=None # type: Optional[List[Dict[str, Tensor]]] ): # type: (...) -> Tuple[List[Tensor], Dict[str, Tensor]] """ Arguments: images (ImageList): images for which we want to compute the predictions features (Dict[Tensor]): features computed from the images that are used for computing the predictions. Each tensor in the list correspond to different feature levels targets (List[Dict[Tensor]): ground-truth boxes present in the image (optional). If provided, each element in the dict should contain a field `boxes`, with the locations of the ground-truth boxes. Returns: boxes (List[Tensor]): the predicted boxes from the RPN, one Tensor per image. losses (Dict[Tensor]): the losses for the model during training. During testing, it is an empty dict. """ # RPN uses all feature maps that are available # features是所有预测特征层组成的OrderedDict #提取预测特征层的特征矩阵 ,是个字典类型,我们将key抽出去只留val features = list(features.values()) # 计算每个预测特征层上的预测目标概率和bboxes regression参数 # objectness和pred_bbox_deltas都是list #均以预测特征层进行划分 shape 8(batch) 15(每个预测特征层有多少个anchor 5scanle 3 ratio) 34(高) 42(宽度) #shape 8 60(在每个cell中参数个数 每个anchor需要四个参数 15*4) 34 42 objectness, pred_bbox_deltas = self.head(features) # 生成一个batch图像的所有anchors信息,list(tensor)元素个数等于batch_size #是一个列表,有8个,每一个对应的就是图片的anchor信息 21420*4 anchors = self.anchor_generator(images, features) # batch_size = 8 num_images = len(anchors) # numel() Returns the total number of elements in the input tensor. # 计算每个预测特征层上的对应的anchors数量 # o[0].shape 15 34 42 相乘得到每个预测特征层上anchor的个数 num_anchors_per_level_shape_tensors = [o[0].shape for o in objectness] num_anchors_per_level = [s[0] * s[1] * s[2] for s in num_anchors_per_level_shape_tensors] # 调整内部tensor格式以及shape # #8 21420 1 8 21420 4 objectness, pred_bbox_deltas = concat_box_prediction_layers(objectness, pred_bbox_deltas) #objectness 171360 1 #pred_bbox_deltas 171360 4 # apply pred_bbox_deltas to anchors to obtain the decoded proposals # note that we detach the deltas because Faster R-CNN do not backprop through # the proposals # 将预测的bbox regression参数应用到anchors上得到最终预测bbox坐标 proposals = self.box_coder.decode(pred_bbox_deltas.detach(), anchors) #155040*1*4 proposals = proposals.view(num_images, -1, 4) #8 19380 4 # 筛除小boxes框,nms处理,根据预测概率获取前post_nms_top_n个目标 boxes, scores = self.filter_proposals(proposals, objectness, images.image_sizes, num_anchors_per_level) losses = {} #如果是训练模式 if self.training: assert targets is not None # 计算每个anchors最匹配的gt,并将anchors进行分类,前景,背景以及废弃的anchors #labels tensor261888 0 0 0 0 1 0.....0 #matched_gt_boxes 每张图片的anchors所对应的gtbox labels, matched_gt_boxes = self.assign_targets_to_anchors(anchors, targets) # 结合anchors以及对应的gt,计算regression参数 regression_targets = self.box_coder.encode(matched_gt_boxes, anchors) loss_objectness, loss_rpn_box_reg = self.compute_loss( objectness, pred_bbox_deltas, labels, regression_targets ) losses = { "loss_objectness": loss_objectness, "loss_rpn_box_reg": loss_rpn_box_reg } return boxes, losses传入的参数image是ImageLIst类类型,features是传入的预测特征层的特征矩阵,targets是gtbox等信息。
首先将预测特征层的特征矩阵全部提取出来,因为features是一个字典类型将val提取出来。转化成一个list放进features里。
在执行这行代码之前我们可以看到feature是一个有序的字典类型,只有一个变量,因为在mobilenet中只有一个预测特征层。
元素的shape是
,8代表batchsize,1280代表预测特征层的channel,
代表着预测特征矩阵的宽和高。
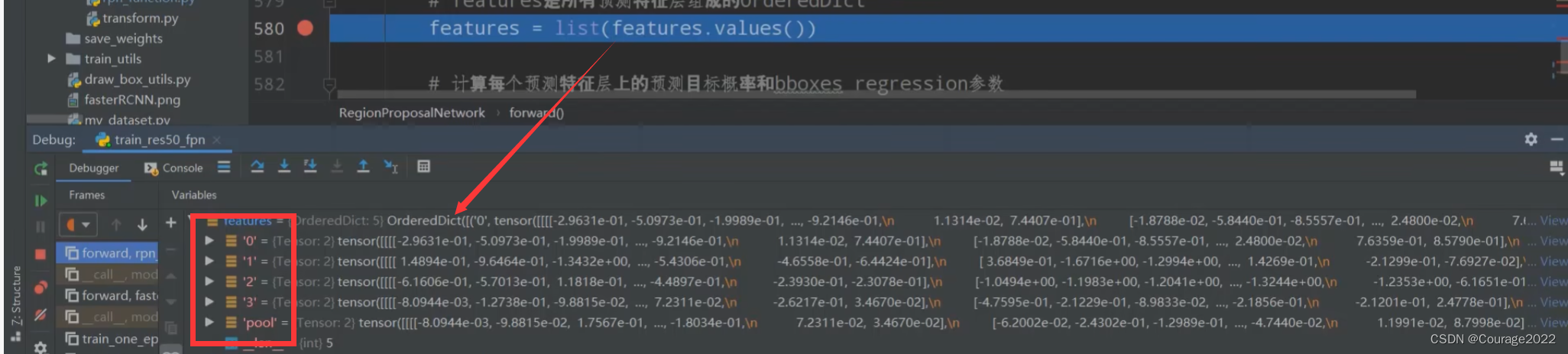
在train_res50_fpn我们再调试一下:有五个预测特征层。每个预测特征层的信息也可以查询。
我们再执行完这行代码之后我们过滤掉了key值,只要val:
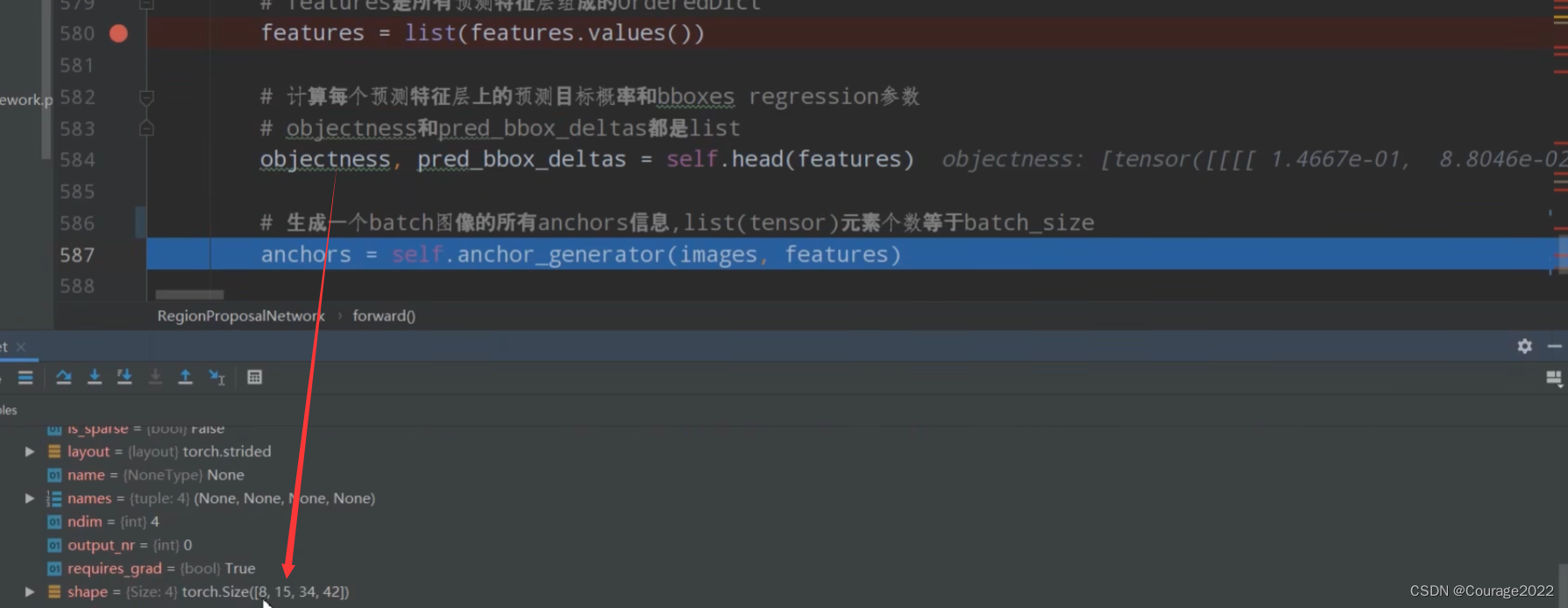
随后将预测特征层输入到我们的head类中,即RPNHead类中得到目标概率分数以及边界框回归参数。
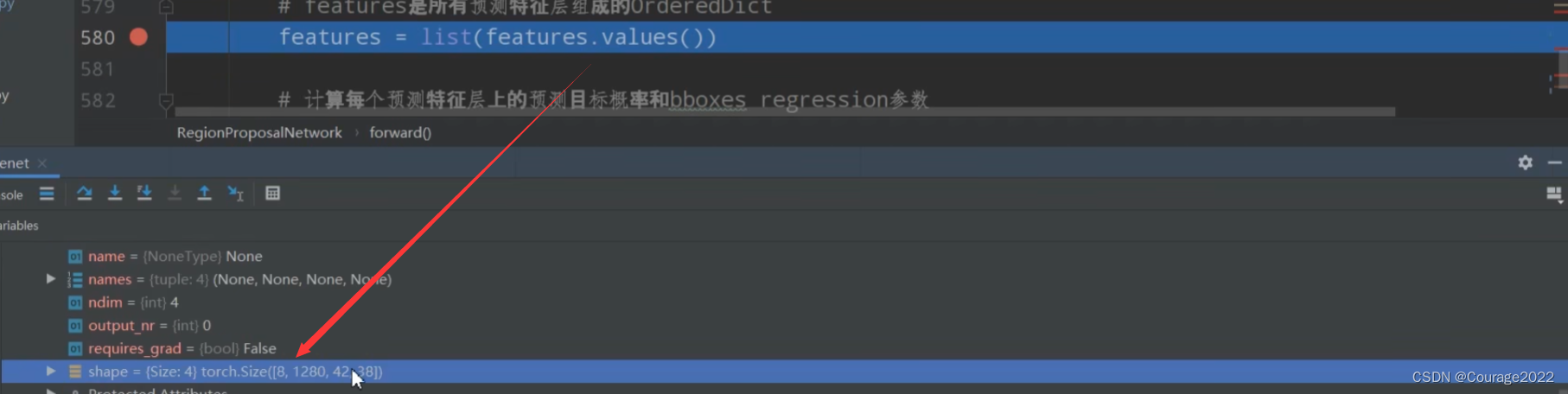
# 计算每个预测特征层上的预测目标概率和bboxes regression参数 # objectness和pred_bbox_deltas都是list #均以预测特征层进行划分 shape 8(batch) 15(每个预测特征层有多少个anchor 5scanle 3 ratio) 34(高) 42(宽度) #shape 8 60(在每个cell中参数个数 每个anchor需要四个参数 15*4) 34 42 objectness, pred_bbox_deltas = self.head(features)我们还是以mobilenet脚本为例,因为我们只有一个预测特征层,看一下objectness的shape:
8代表batch的大小,15对应在每个cell预测多少个anchor,高度和宽度。
因为一个anchor对应四个坐标,因此它的第二维度为60。
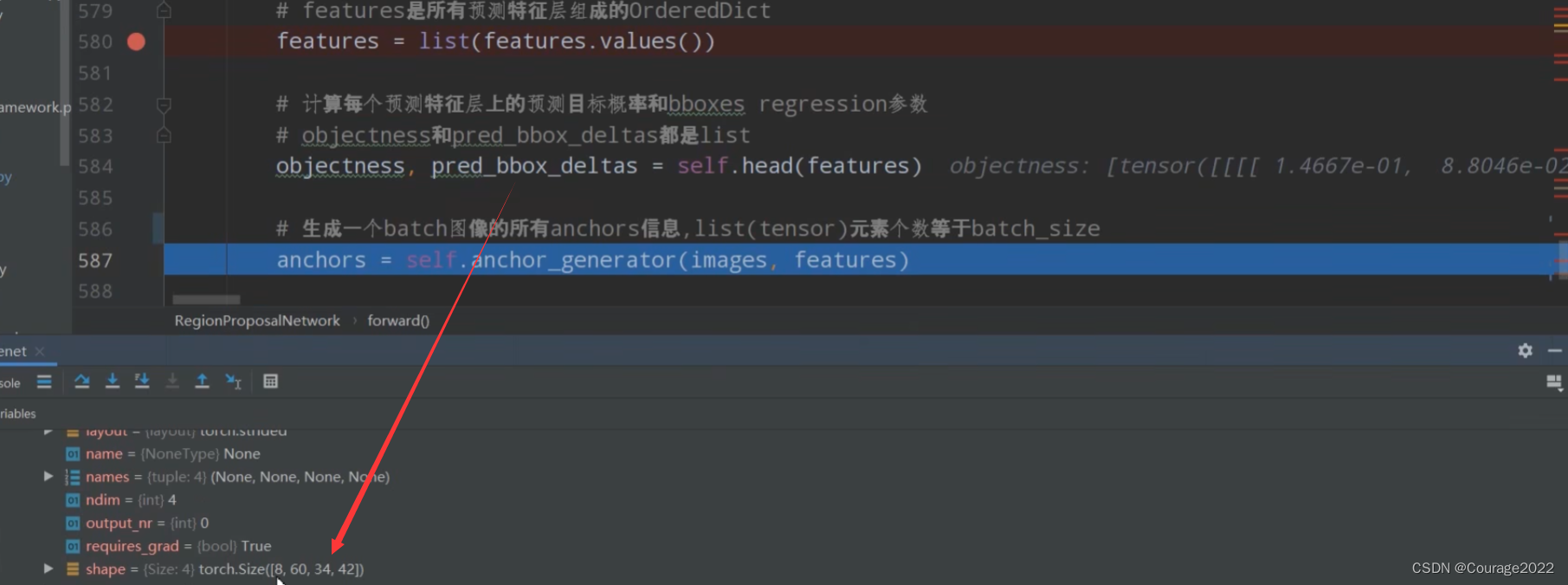
然后得到anchors,anchors = self.anchor_generator(images, features)。
这里它是个列表,列表的每一个元素对应的每一个图片的anchor信息。[21420,4]
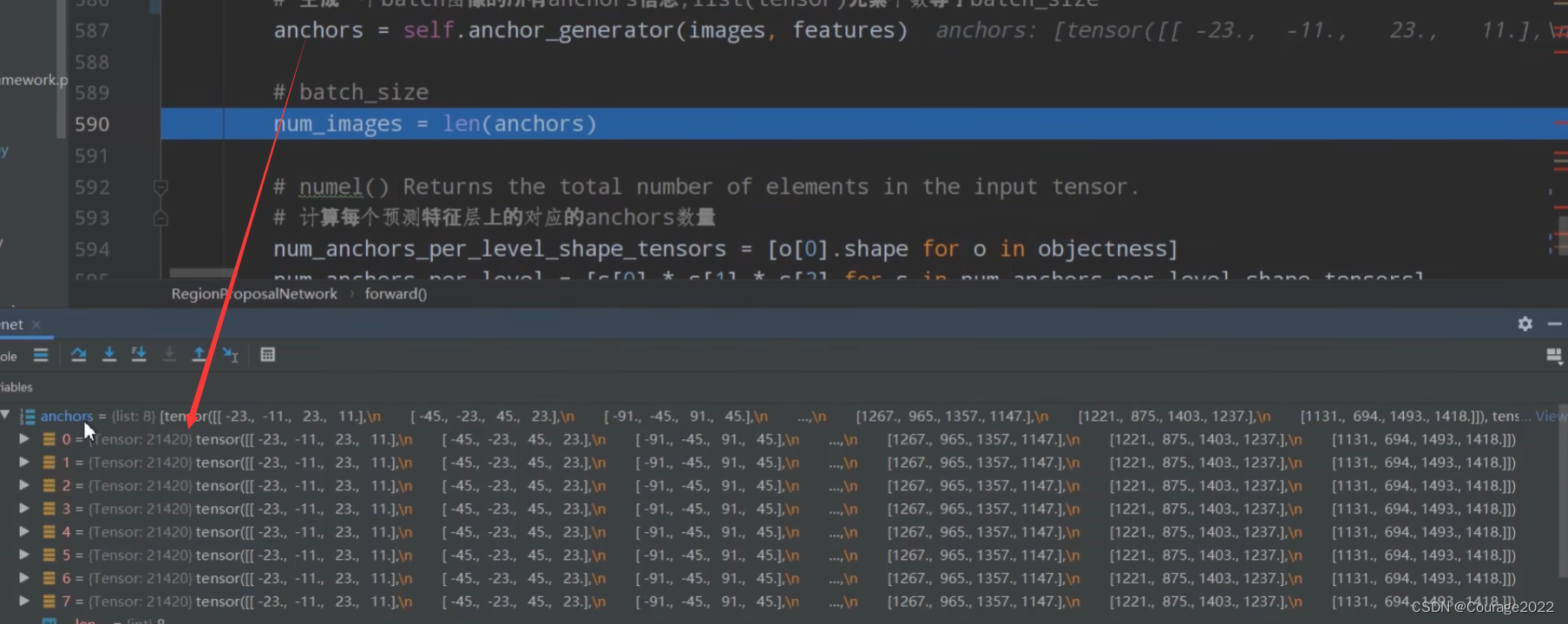
计算每个预测特征层上的对应的anchors数量。
# numel() Returns the total number of elements in the input tensor. # 计算每个预测特征层上的对应的anchors数量 # o[0].shape 15 34 42 相乘得到每个预测特征层上anchor的个数 num_anchors_per_level_shape_tensors = [o[0].shape for o in objectness] num_anchors_per_level = [s[0] * s[1] * s[2] for s in num_anchors_per_level_shape_tensors]objectness是对应预测特征层的个数,由于我们在mobilenet中只有一个,因此o[0].shape等于[15,34,42],将其×起来得到每个预测特征层中的anchors的个数。
我们将objectness及pred_bbox_deltas输入到concat_box_prediction_layers函数中调整tensor的信息。
最终得到的信息是
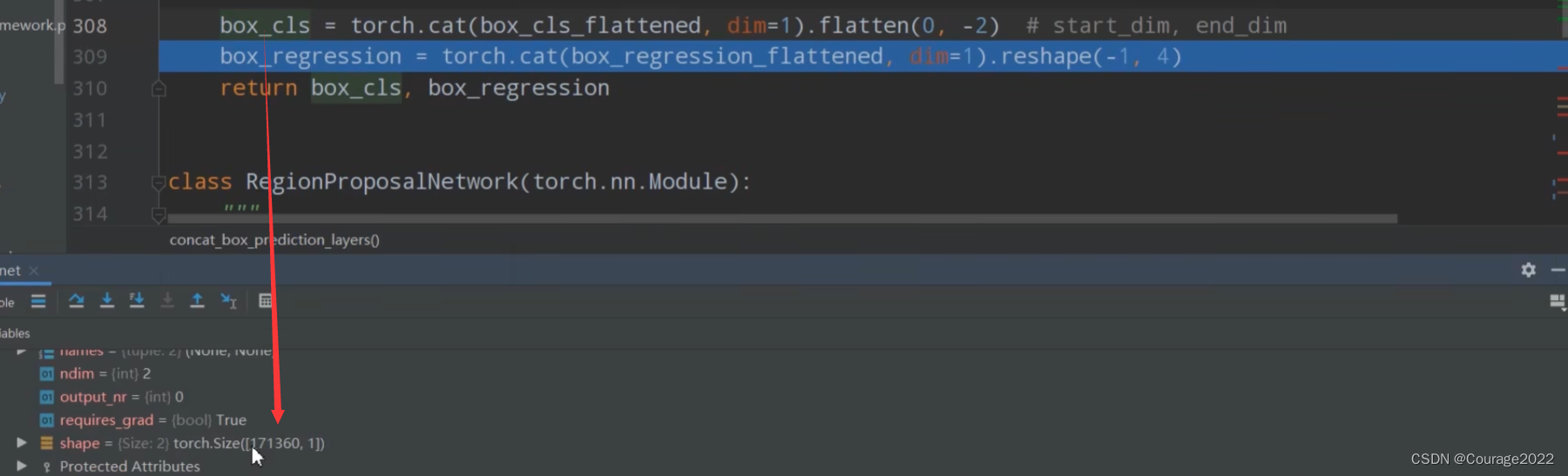
objectness :171360 * 1
pred_bbox_deltas :171360 * 4
存储的是预测前景背景信息及目标边界框预测信息。
将预测的bbox regression参数应用到anchors上得到最终预测bbox坐标。
proposals = self.box_coder.decode(pred_bbox_deltas.detach(), anchors)我们得到的proposal的坐标的shape是
的。
我们再对proposal进行如下处理:
proposals = proposals.view(num_images, -1, 4)我们得到的proposal的坐标的shape是
的。
再利用filter_proposals方法对proposal进行过滤。(2.1.5节)
# 筛除小boxes框,nms处理,根据预测概率获取前post_nms_top_n个目标 boxes, scores = self.filter_proposals(proposals, objectness, images.image_sizes, num_anchors_per_level)最终得到过滤后的final_boxes, final_scores。

2.1.3 concat_box_prediction_layers函数
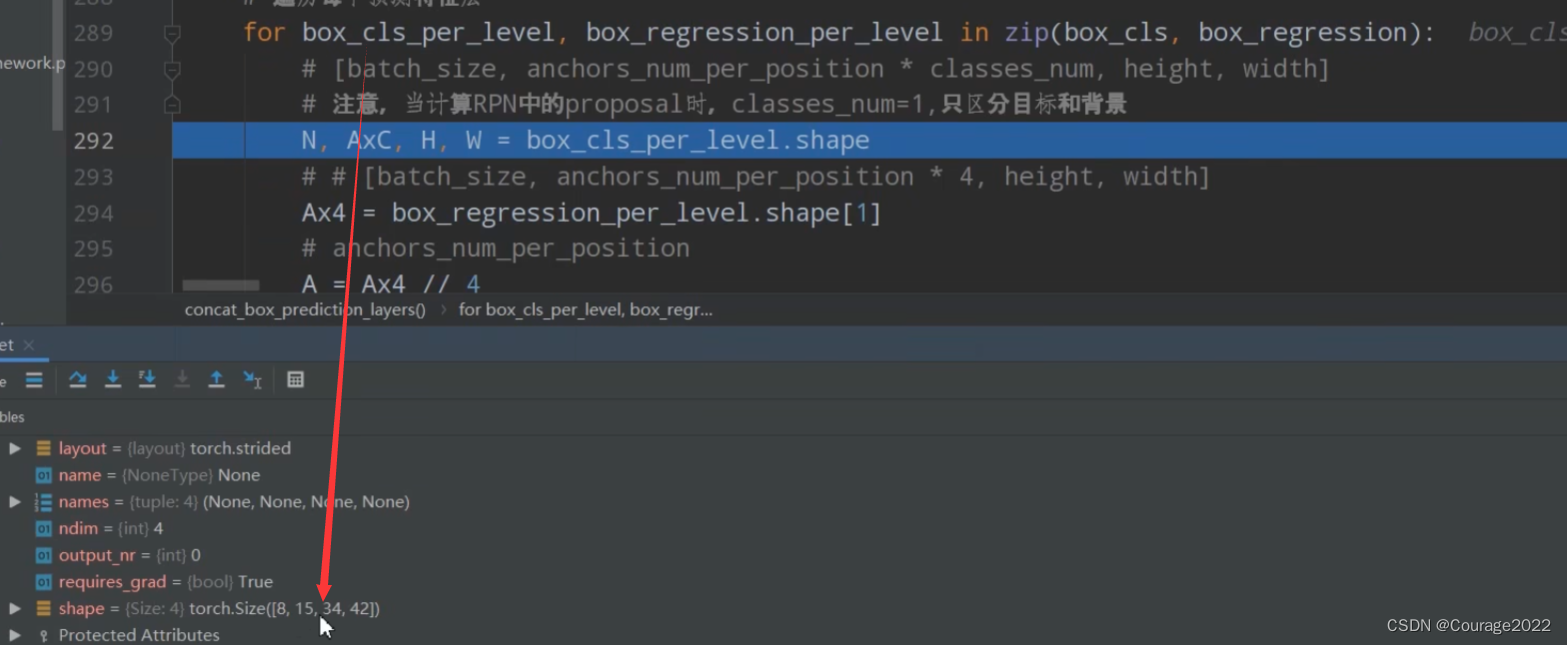
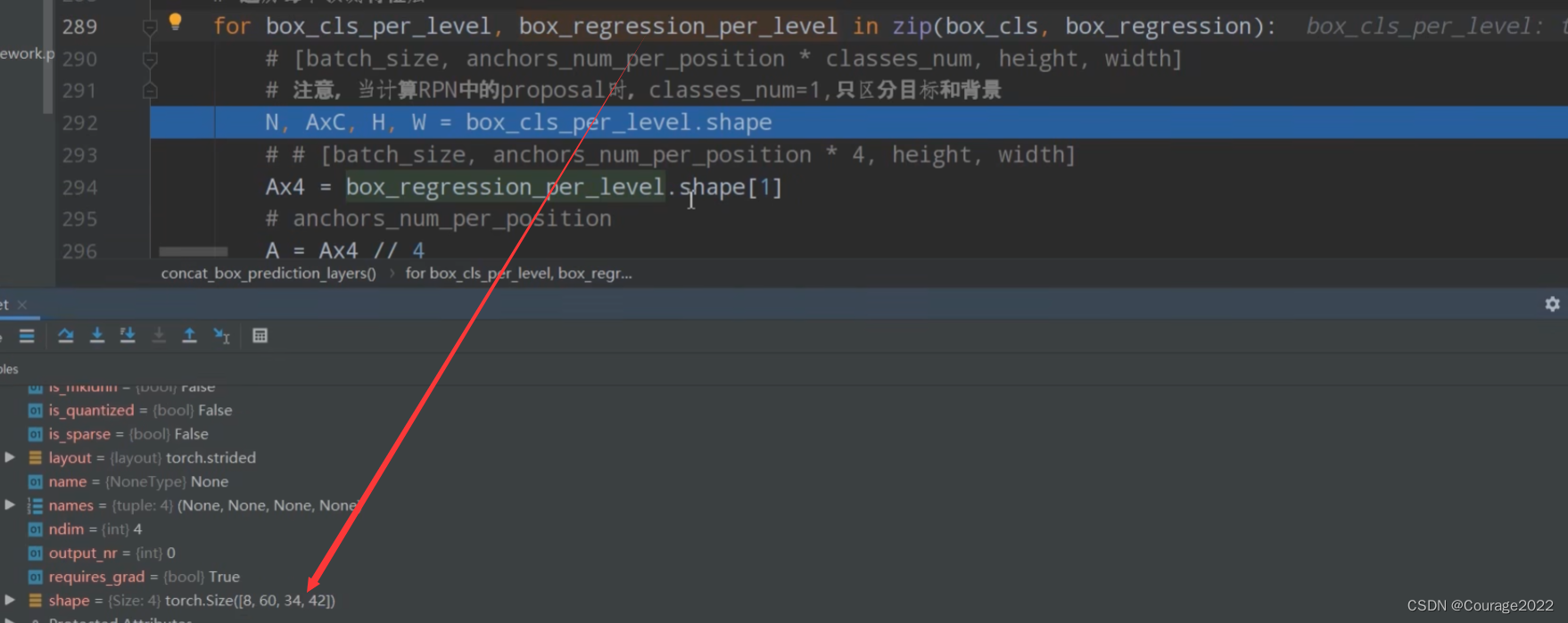
def concat_box_prediction_layers(box_cls, box_regression): # type: (List[Tensor], List[Tensor]) -> Tuple[Tensor, Tensor] """ shape 8(batch) 15(每个预测特征层有多少个anchor 5scanle 3 ratio) 34(高) 42(宽度) shape 8 60(在每个cell中参数个数 每个anchor需要四个参数 15*4) 34 42 对box_cla和box_regression两个list中的每个预测特征层的预测信息 的tensor排列顺序以及shape进行调整 -> [N, -1, C] Args: box_cls: 每个预测特征层上的预测目标概率 box_regression: 每个预测特征层上的预测目标bboxes regression参数 Returns: """ #目标分数 box_cls_flattened = [] #bndbox参数 box_regression_flattened = [] # 遍历每个预测特征层 for box_cls_per_level, box_regression_per_level in zip(box_cls, box_regression): # [batch_size, anchors_num_per_position * classes_num, height, width] # 注意,当计算RPN中的proposal时,classes_num=1,只区分目标和背景 #anchor个数 A*C(anchor * classes)这里classes=1只需要预测anchor是前景还是背景 N, AxC, H, W = box_cls_per_level.shape #对应这60 15*4 # # [batch_size, anchors_num_per_position * 4, height, width] Ax4 = box_regression_per_level.shape[1] # anchors_num_per_position A = Ax4 // 4 # classes_num C = AxC // A #N=8 A=15 C=1 H=34 W=42 # [N, -1, C] box_cls_per_level = permute_and_flatten(box_cls_per_level, N, A, C, H, W) box_cls_flattened.append(box_cls_per_level) #8 21420 1 # [N, -1, C] box_regression_per_level = permute_and_flatten(box_regression_per_level, N, A, 4, H, W) box_regression_flattened.append(box_regression_per_level) #8 21420 4 #在维度1 21420上进行拼接,将多个预测特征层上的数进行拼接 从第0到倒数第二个维度为止进行zhnaping box_cls = torch.cat(box_cls_flattened, dim=1).flatten(0, -2) # start_dim, end_dim 171360 1 box_regression = torch.cat(box_regression_flattened, dim=1).reshape(-1, 4) #171360 4 #8 21420 1 8 21420 4 return box_cls, box_regression我们先建立两个空列表存储目标分数box_cls_flattened和bndbox参数
box_regression_flattened的信息。遍历每个预测特征层,我们通过zip(box_cls, box_regression)方法同时遍历 box_cls和 box_regression 变量,即逐层的遍历针对每个预测特征层所生成的目标分数及边界框回归参数,因为我们只有一个预测特征层因此我们只会遍历一次。
我们看一下box_cls_per_level这个变量的shape:
用N, AxC, H, W = box_cls_per_level.shape 接收:
N : batch
A×C :anchor的个数 (anchor=15 * classes=1)因为只需预测前景或背景C=1
H,W : 特征矩阵的高度和宽度
我们看一下box_regression_per_level这个变量的shape:
box_regression_per_level.shape[1]索引为1的地方对应着60,对应着A×4。
这样我们得到了N=8 A=15 C=1 H=34 W=42这些参数,我们通过permute_and_flatten方法对参数进行展平处理(2.1.4节)
box_cls_per_level

box_regression_per_level
存放入目标分数列表box_cls_flattened和bndbox参数列表box_regression_flattened中:
最后我们在维度1上进行拼接:将多个预测特征层上的信息进行拼接。
返回这两个tensor信息给调用函数。
2.1.4 permute_and_flatten
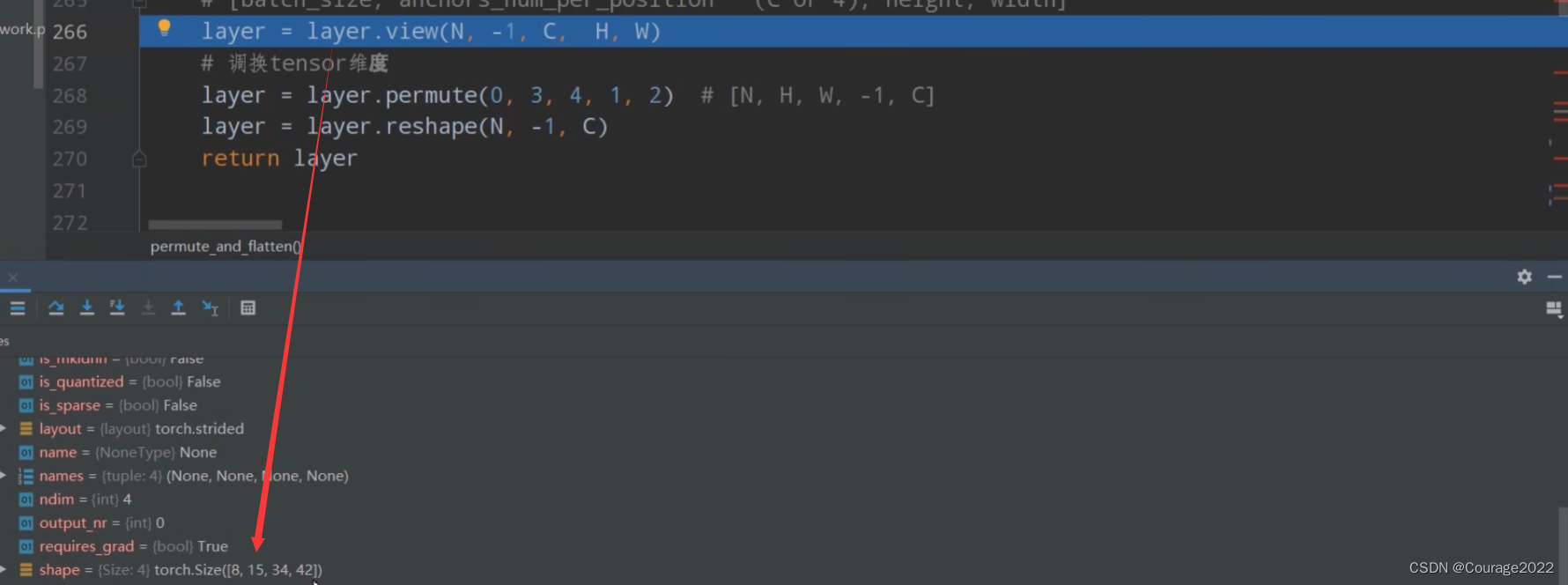
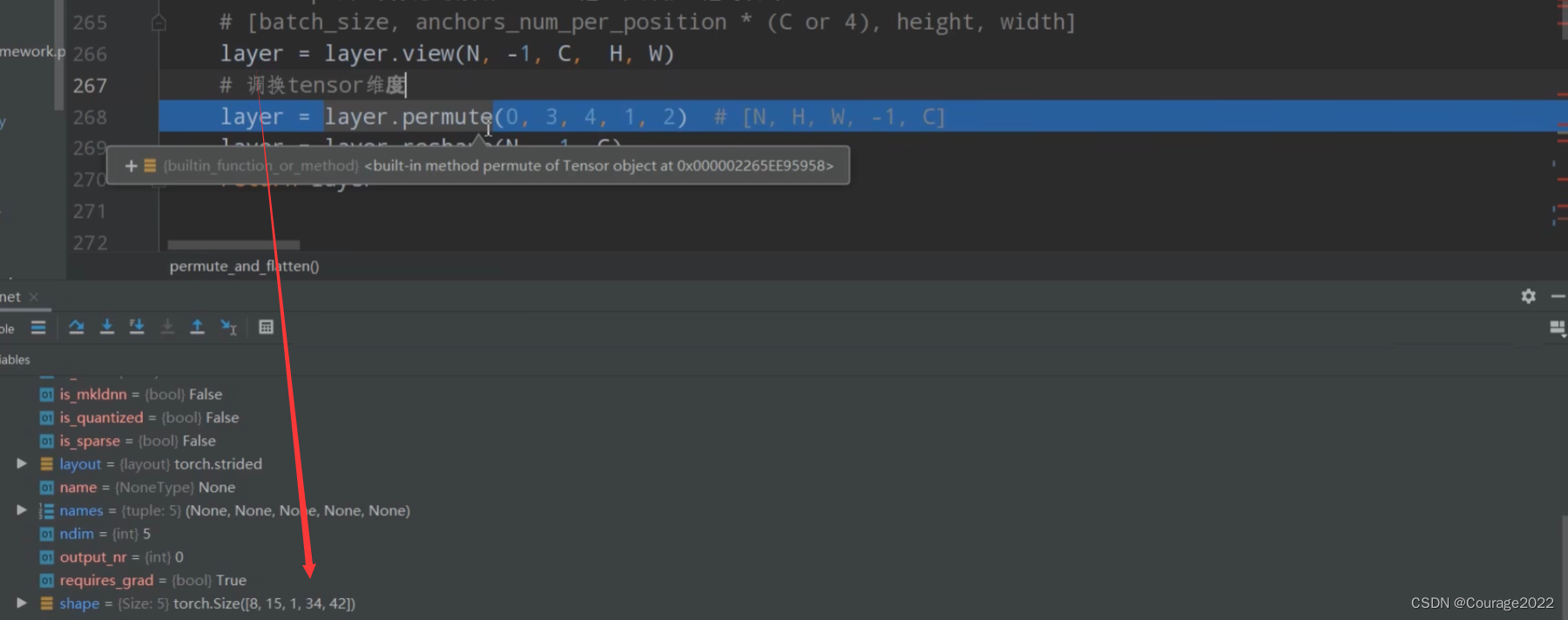
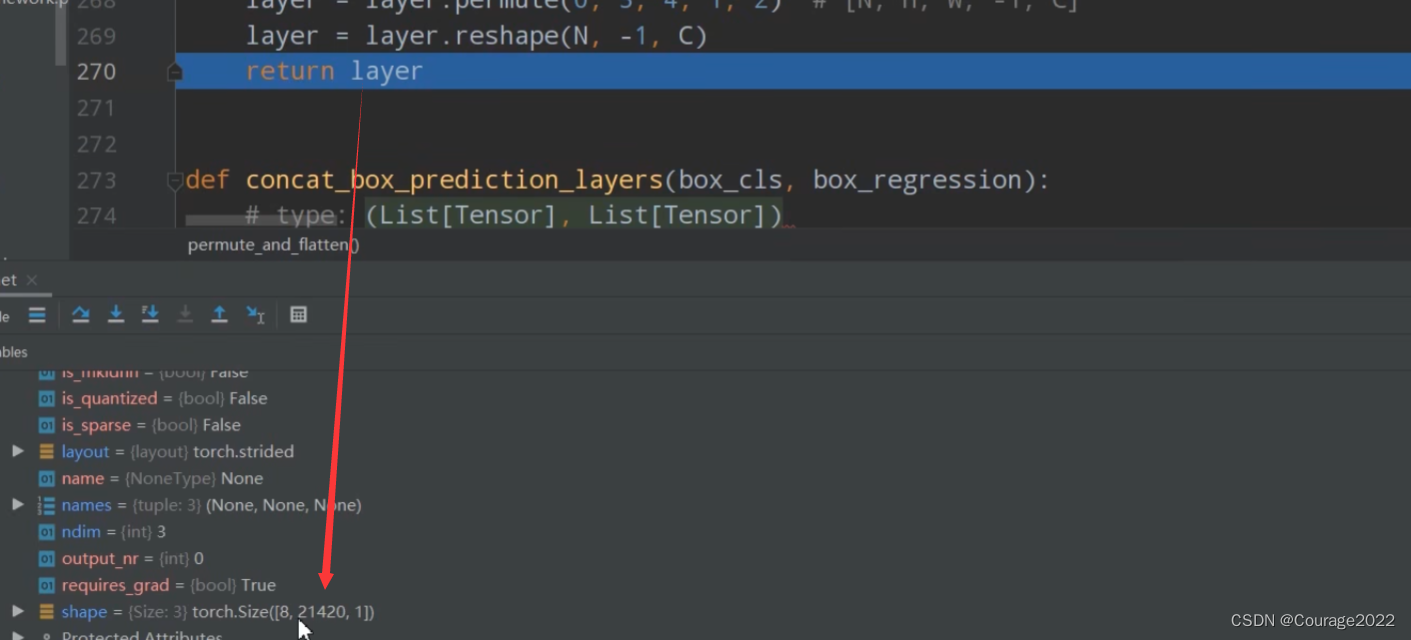
#N=8 A=15 C=1 H=34 W=42 #传进来的是每一层的数据 def permute_and_flatten(layer, N, A, C, H, W): # type: (Tensor, int, int, int, int, int) -> Tensor """ 调整tensor顺序,并进行reshape Args: layer: 预测特征层上预测的目标概率或bboxes regression参数 N: batch_size A: anchors_num_per_position C: classes_num or 4(bbox coordinate) H: height W: width Returns: layer: 调整tensor顺序,并reshape后的结果[N, -1, C] """ # view和reshape功能是一样的,先展平所有元素在按照给定shape排列 # view函数只能用于内存中连续存储的tensor,permute等操作会使tensor在内存中变得不再连续,此时就不能再调用view函数 # reshape则不需要依赖目标tensor是否在内存中是连续的 # [batch_size, anchors_num_per_position * (C or 4), height, width] #之前的layer 8 15 34 42 #之后的layer 8 15 1 34 42 layer = layer.view(N, -1, C, H, W) # 调换tensor维度 layer = layer.permute(0, 3, 4, 1, 2) # [N, H, W, -1, C] layer = layer.reshape(N, -1, C) # 8 21420 1 return layer
通过view之后,得到如下:
用permute函数和reshape调整维度信息:我们看一下最终得到的tensor的样子:
这里是针对box_cls_per_level进行输入运算的,8代表batch_size,21420对应着所有anchors的个数,1代表着分数。
针对box_regression_per_level进行输入运算的,shape则是8*21420*4。
2.1.5 filter_proposals
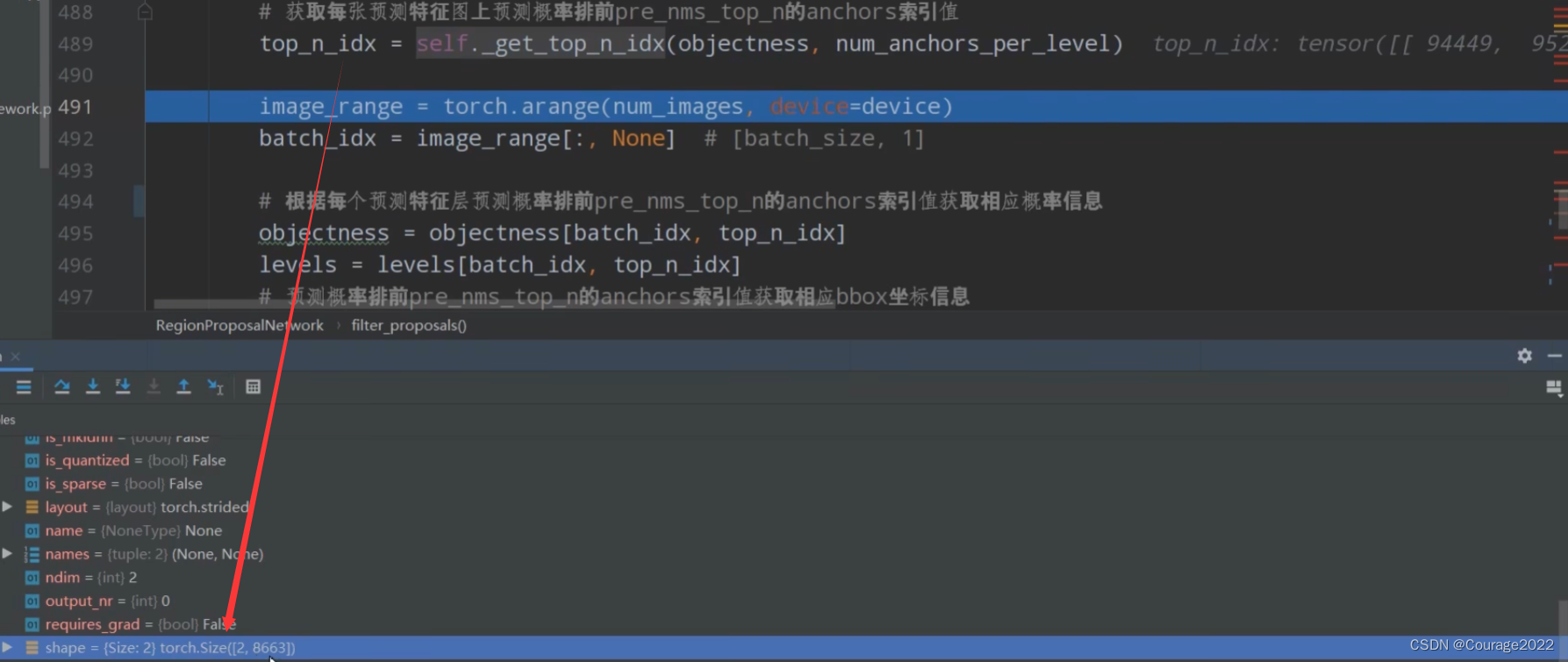
def filter_proposals(self, proposals, objectness, image_shapes, num_anchors_per_level): # type: (Tensor, Tensor, List[Tuple[int, int]], List[int]) -> Tuple[List[Tensor], List[Tensor]] """ 筛除小boxes框,nms处理,根据预测概率获取前post_nms_top_n个目标 Args: proposals: 预测的bbox坐标 objectness: 预测的目标概率 image_shapes: batch中每张图片的size信息 num_anchors_per_level: 每个预测特征层上预测anchors的数目 Returns: """ #8 num_images = proposals.shape[0] device = proposals.device # do not backprop throught objectness #我们输出的proposal是要输出给fastrcnn部分的,对于fastrcnn部分 proposal是输入参数,不是模型计算得到的中间变量 #可以理解为一个叶子节点 且required_grad=false #丢弃梯度信息 只获得数值信息 #155040 objectness = objectness.detach() #8 19380 objectness = objectness.reshape(num_images, -1) # Returns a tensor of size size filled with fill_value # levels负责记录分隔不同预测特征层上的anchors索引信息 #因为我们只有一层预测特征层 num_anchors_per_level是个列表 因此它只有一个值19380 #idx是预测特征层的索引,n是该预测特征层的个数 #torch.full 如何使用:参数n是要制定生成的tensor的一个shape,idx是用什么值填充tensor #因此这里我们的idx=0 n=19380 #levels是一个全0列表 levels = [torch.full((n, ), idx, dtype=torch.int64, device=device) for idx, n in enumerate(num_anchors_per_level)] levels = torch.cat(levels, 0) #区分哪些anchor在哪层 将其shape变成objectness # Expand this tensor to the same size as objectness levels = levels.reshape(1, -1).expand_as(objectness) # select top_n boxes independently per level before applying nms # 获取每张预测特征图上预测概率排前pre_nms_top_n的anchors索引值 # 最终得到的是每张图片的topk的索引值 【8 * x】 top_n_idx = self._get_top_n_idx(objectness, num_anchors_per_level) #num_images = batchsize = 【01234567】 image_range = torch.arange(num_images, device=device) #shape为【8,1】 batch_idx = image_range[:, None] # [batch_size, 1] # 根据每个预测特征层预测概率排前pre_nms_top_n的proposals索引值获取相应概率信息 objectness = objectness[batch_idx, top_n_idx] levels = levels[batch_idx, top_n_idx] # 预测概率排前pre_nms_top_n的anchors索引值获取相应bbox坐标信息 proposals = proposals[batch_idx, top_n_idx] objectness_prob = torch.sigmoid(objectness) final_boxes = [] final_scores = [] # 遍历每张图像的相关预测信息 proposal是坐标 for boxes, scores, lvl, img_shape in zip(proposals, objectness_prob, levels, image_shapes): # 调整预测的boxes信息,将越界的坐标调整到图片边界上 boxes = box_ops.clip_boxes_to_image(boxes, img_shape) #删除proposal中的小目标 # 返回boxes满足宽,高都大于min_size的索引 keep = box_ops.remove_small_boxes(boxes, self.min_size) boxes, scores, lvl = boxes[keep], scores[keep], lvl[keep] # 移除小概率boxes,参考下面这个链接 # https://github.com/pytorch/vision/pull/3205 keep = torch.where(torch.ge(scores, self.score_thresh))[0] # ge: >= boxes, scores, lvl = boxes[keep], scores[keep], lvl[keep] # non-maximum suppression, independently done per level keep = box_ops.batched_nms(boxes, scores, lvl, self.nms_thresh) # keep only topk scoring predictions keep = keep[: self.post_nms_top_n()] boxes, scores = boxes[keep], scores[keep] final_boxes.append(boxes) final_scores.append(scores) return final_boxes, final_scores筛除小boxes框,nms处理,根据预测概率获取前post_nms_top_n个目标。
传入的参数:
@proposals :经过anchors和回归预测处理后的边界框
@objectness :预测的目标概率
@image_shapes :batch中每张图片的size信息
@num_anchors_per_level :每个预测特征层上预测anchors的数目
num_images获取图片的数量(8)。
由于我们进行完这个函数处理后筛选后的proposal是要给fastrcnn部分的,对于fastrcnn部分proposal是输入参数不是模型计算得到的中间变量,可以理解为是叶子节点且required_grad = False。
reshape之后objectness的shape变成了
, 和proposal的shape差不多了。
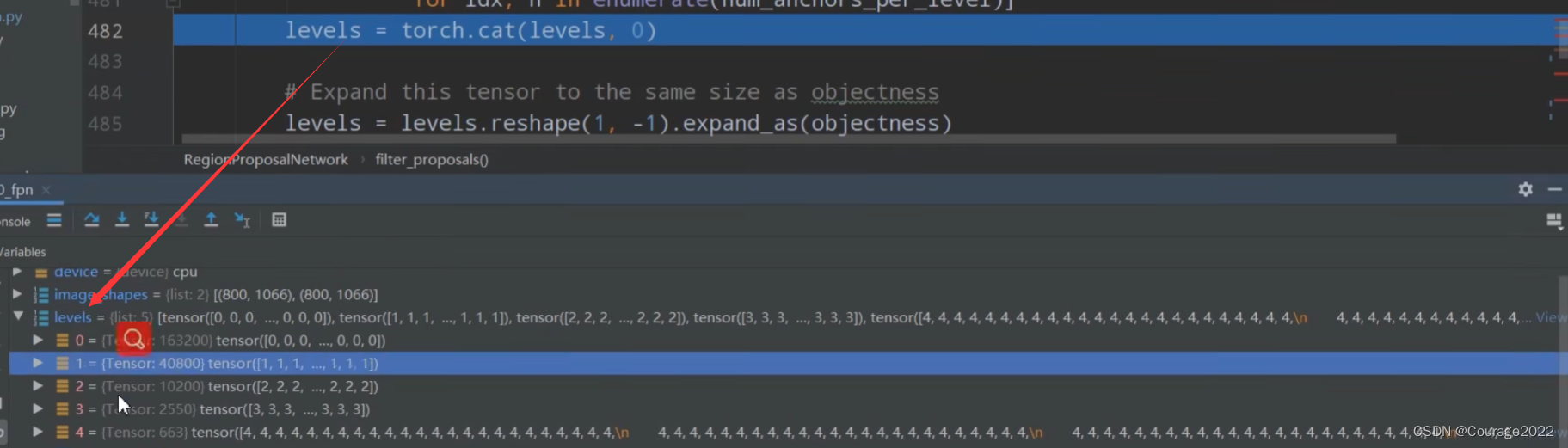
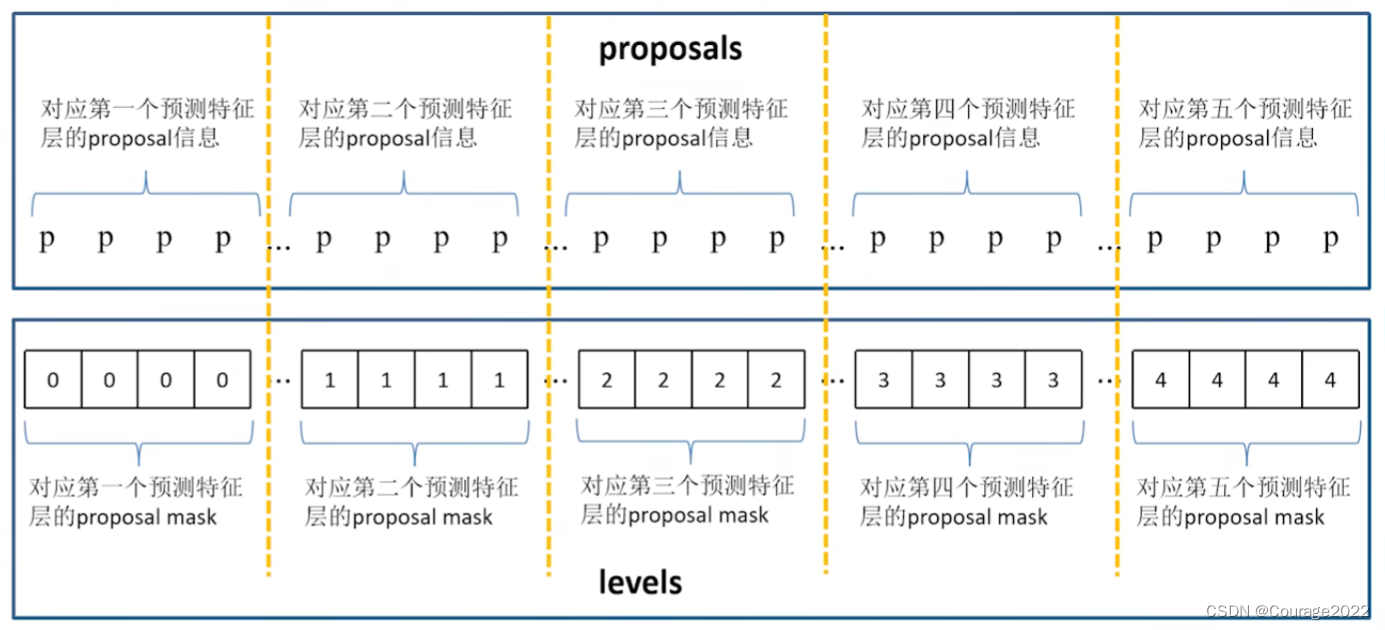
#因为我们只有一层预测特征层 num_anchors_per_level是个列表 因此它只有一个值21420 #idx是预测特征层的索引,n是该预测特征层anchor的个数 #torch.full 如何使用:参数n是要制定生成的tensor的一个shape,idx是用什么值填充tensor #因此这里我们的idx=0 n=21420 #levels是一个全0列表 levels = [torch.full((n, ), idx, dtype=torch.int64, device=device) for idx, n in enumerate(num_anchors_per_level)] levels = torch.cat(levels, 0)这里的level只有一维,它有21420个元素,它的元素都为0。
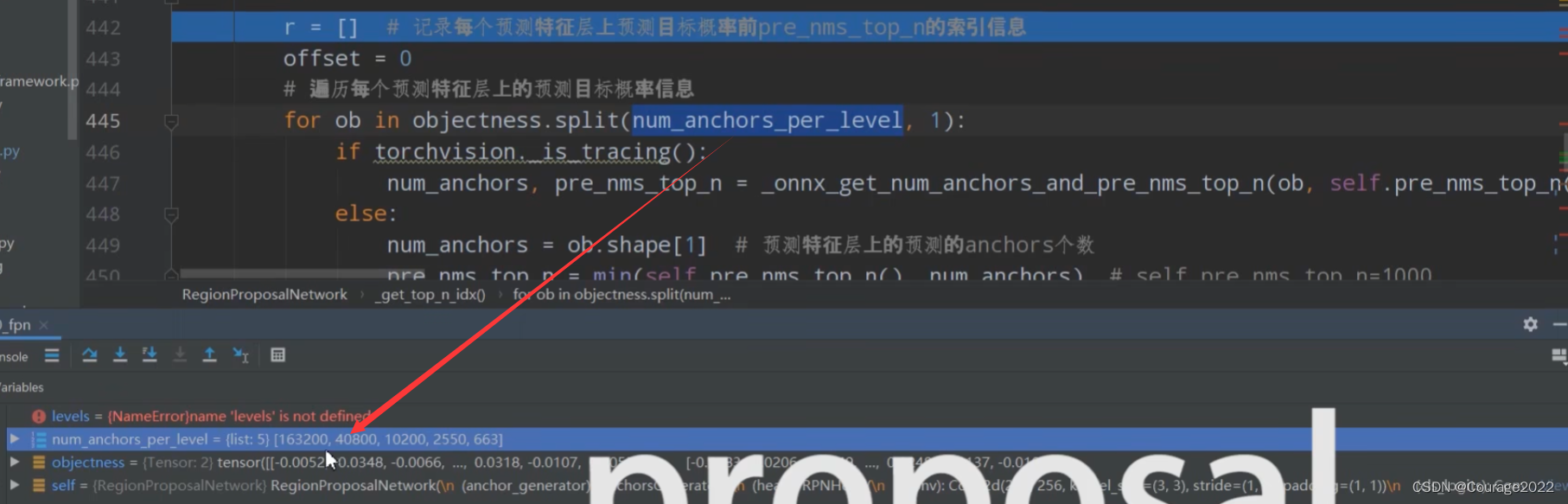
如果有多层预测特征层呢?就会生成多个tensor,我们在train_res50_fpn.py进行断点调试!
我们看到levels有五个元素,对应着每个预测特征层tensor的索引信息,我们看到第一层预测特征层有163200个anchor,第二层有40800个anchor....同样第一层是000,第二层是111,.....。我们将levels用cat拼接到一起后,是一个一维tensor,里面是000...111...222。那这有什么意义呢?记录anchor在哪一个特征层!
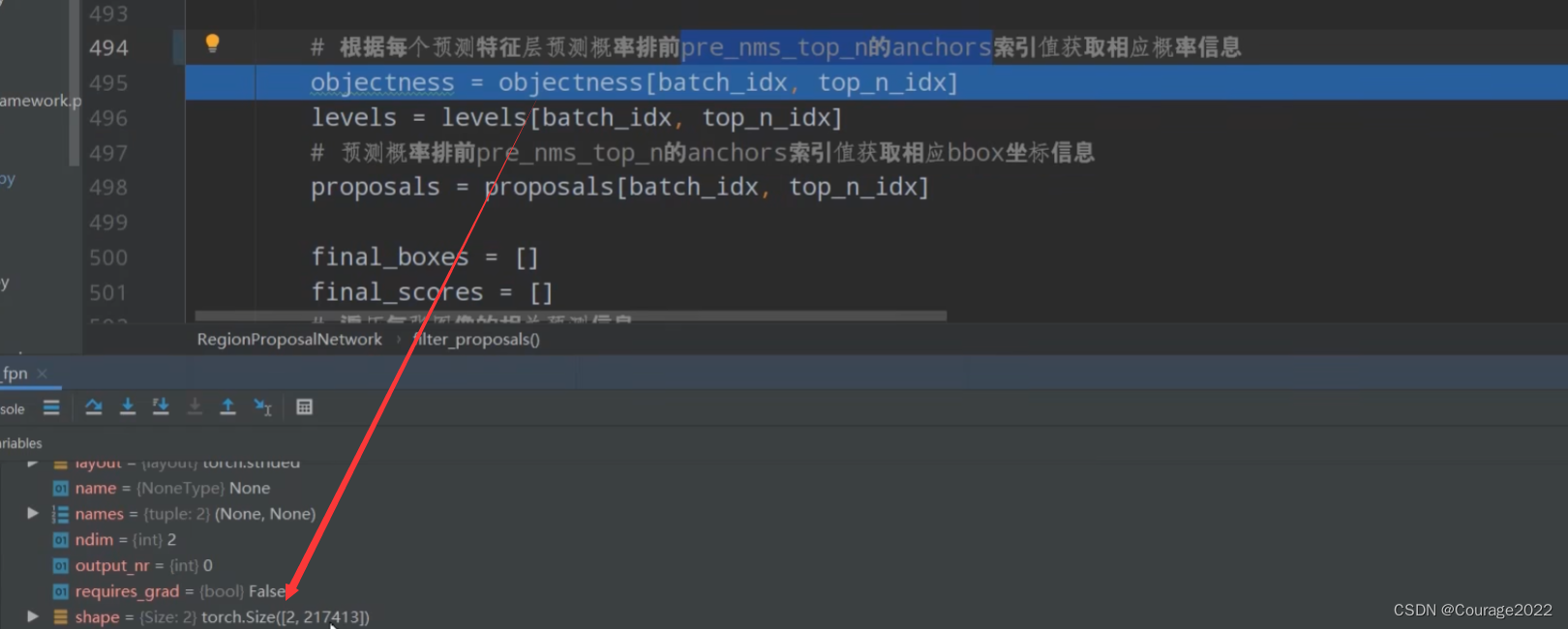
在train_res50_fpn.py这个脚本中,我们看看proposal这个变量:
我们的batchsize=2的,因此第一维是2, 后面是217413个proposal的anchor,我们有五个预测特征层,我们不知道哪些anchor在哪层,因此这就是levels变量的意义!
再将levels变量进行reshape处理:
#区分哪些anchor在哪层 将其shape变成objectness levels = levels.reshape(1, -1).expand_as(objectness)
处理之前levels就有一个维度217413,reshape之后第一个维度是1,第二个维度是推理得到的。现在的levels是
。再将其通过expand_as方法将其tensor的shape向objectness的shape对齐。最终得到的shape是
。
利用_get_top_n_idx方法获取每张预测特征图上预测概率排前pre_nms_top_n的anchors索引值。(2.1.6节)
# 获取每张预测特征图上预测概率排前pre_nms_top_n的anchors索引值 # 最终得到的是每张图片的topk的索引值 【8 * x】 top_n_idx = self._get_top_n_idx(objectness, num_anchors_per_level)
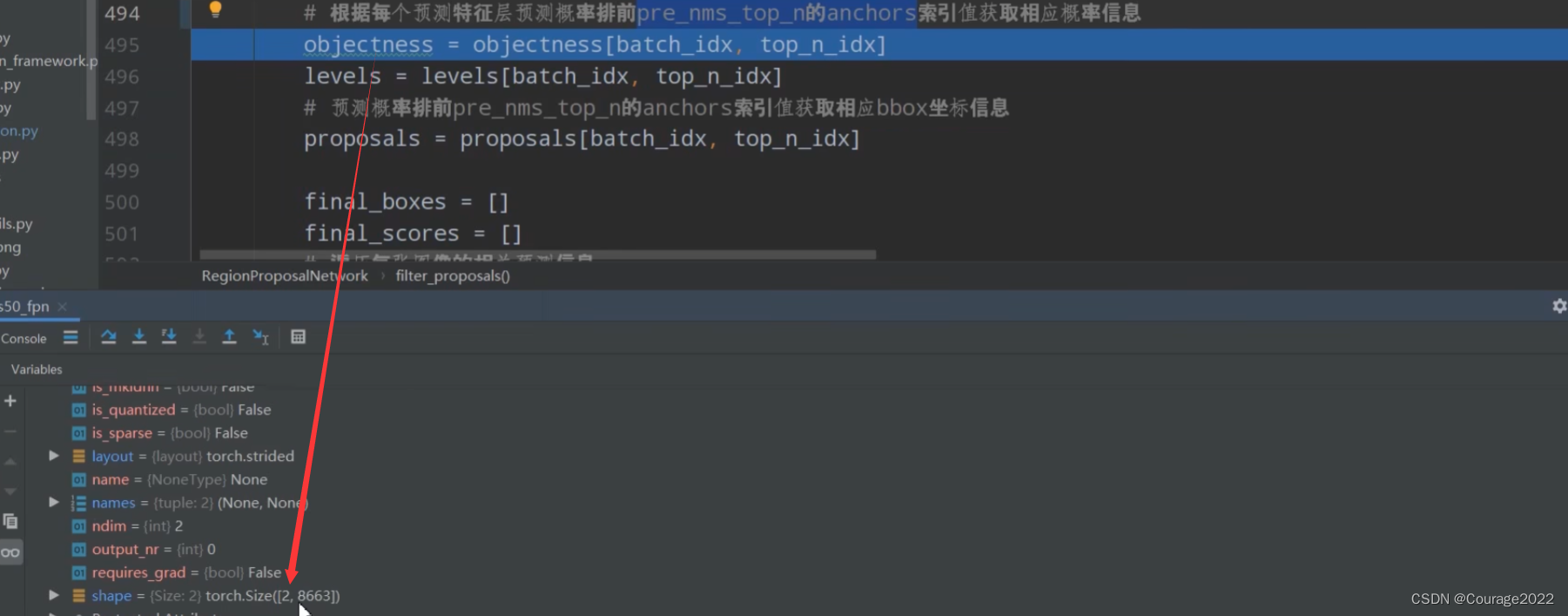
经过top_n_idx方法后,每张图片只有8663个proposal了。
#num_images = batchsize = 【01234567】 image_range = torch.arange(num_images, device=device) #shape为【8,1】 batch_idx = image_range[:, None] # [batch_size, 1]根据每个预测特征层预测概率排前pre_nms_top_n的proposals索引值获取相应概率信息
# 根据每个预测特征层预测概率排前pre_nms_top_n的proposals索引值获取相应概率信息 objectness = objectness[batch_idx, top_n_idx] levels = levels[batch_idx, top_n_idx] # 预测概率排前pre_nms_top_n的anchors索引值获取相应bbox坐标信息 proposals = proposals[batch_idx, top_n_idx]排序之前的objectness:
排序之后的objectness:
最后遍历每张图片的信息获取过滤之后的proposal信息:
过滤掉不符合条件的proposal。
最终得到过滤后的final_boxes, final_scores。


2.1.6 _get_top_n_idx
def _get_top_n_idx(self, objectness, num_anchors_per_level): # type: (Tensor, List[int]) -> Tensor """ 获取每张预测特征图上预测概率排前pre_nms_top_n的anchors索引值 Args: objectness: Tensor(每张图像的预测目标概率信息 ) num_anchors_per_level: List(每个预测特征层上的预测的anchors个数) Returns: """ r = [] # 记录每个预测特征层上预测目标概率前pre_nms_top_n的索引信息 offset = 0 # 遍历每个预测特征层上的预测目标概率信息 #第二个参数的1代表是在哪个维度上进行split分割,num_anchors_per_level为指定的维度上以多长进行分割 #num_anchors_per_level存储的是每个预测特征层proposal的个数 list5 163200 40800 10200 2550 663 for ob in objectness.split(num_anchors_per_level, 1): if torchvision._is_tracing(): num_anchors, pre_nms_top_n = _onnx_get_num_anchors_and_pre_nms_top_n(ob, self.pre_nms_top_n()) else: num_anchors = ob.shape[1] # 预测特征层上的预测的anchors个数 163200 pre_nms_top_n = min(self.pre_nms_top_n(), num_anchors) # Returns the k largest elements of the given input tensor along a given dimension #在维度1上获取前pre_nms_top_n个元素的索引 163200 _, top_n_idx = ob.topk(pre_nms_top_n, dim=1) r.append(top_n_idx + offset) offset += num_anchors return torch.cat(r, dim=1) #r是一个列表@objectness :预测的目标概率
@num_anchors_per_level :每个预测特征层上的预测的anchors个数
我们用列表r 记录每个预测特征层上预测目标概率前pre_nms_top_n的索引信息。
遍历每个预测特征层上的预测目标概率信息,第二个参数的1代表是在哪个维度上进行split分割,num_anchors_per_level存放每个预测特征层proposal的个数,也是指定的维度上以多长进行分割。
也就是将objectness以每层预测特征层的个数进行分割。
理解offset += num_anchors。
在proposal中将所有的anchor拼接在一起,假设由三个预测特征层组成,第一个预测特征层有9个proposal...,topk是针对每个预测特征层求索引,第一个预测特征层的索引不用加offset,对于第二个预测特征层的top1是第二个2格子如下图,那么它的索引为(9+3)。
top_n_idx是索引信息,对应着某一预测特征层前pre_nms_top_n分数的索引。
经过top_n_idx方法后,每张图片只有8663个proposal了。
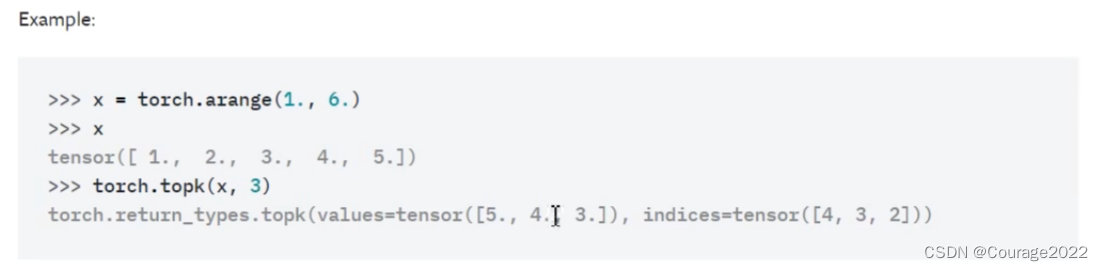
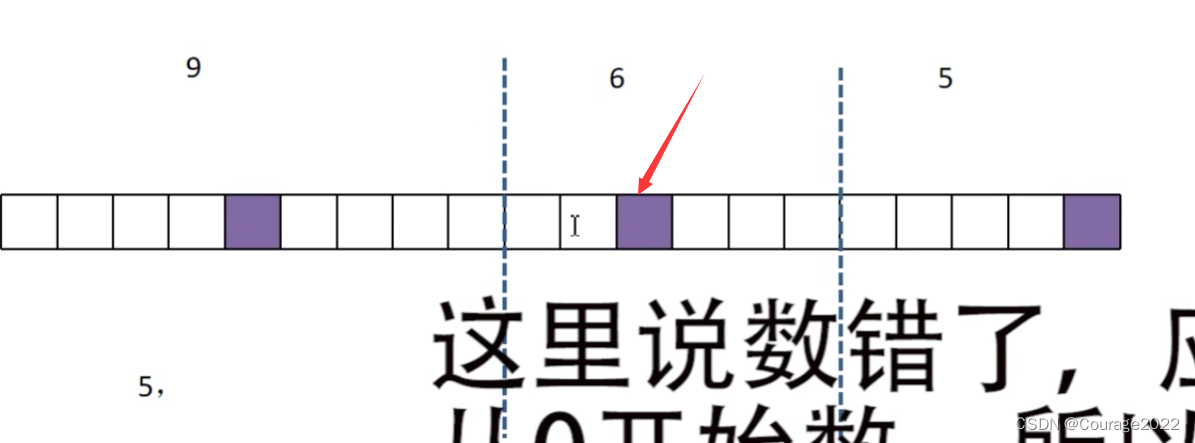
2.2 BoxCoder类(det_utils.py)
2.2.1 decode
#传进来的参数 pred_box_deltas 预测边界框体的回归参数 anchors 框体位置 def decode(self, rel_codes, boxes): # type: (Tensor, List[Tensor]) -> Tensor """ Args: rel_codes: bbox regression parameters boxes: anchors/proposals Returns: """ assert isinstance(boxes, (list, tuple)) assert isinstance(rel_codes, torch.Tensor) #获取每张图片生成的box的数目 #boxes格式: 八张图片 每一个tensor都是21420的 有四个值,每一个的size[0]是【21420,4】 boxes_per_image = [b.size(0) for b in boxes] #拼接 【155040,4】 concat_boxes = torch.cat(boxes, dim=0) box_sum = 0 for val in boxes_per_image: box_sum += val # 将预测的bbox回归参数应用到对应anchors上得到预测bbox的坐标 pred_boxes = self.decode_single( rel_codes, concat_boxes ) # 防止pred_boxes为空时导致reshape报错 if box_sum > 0: pred_boxes = pred_boxes.reshape(box_sum, -1, 4) #155040*1*4 return pred_boxes传入的参数:
pred_bbox_deltas :
的tensor,存储着预测的边界框回归参数。
anchors :
的tensor,存储着生成的anchor信息。
遍历每张图片生成的box数量boxes_per_image,八张图片,每一个tensor都是21420的 有四个值,每一个的size[0]是
。
我们对boxes(anchors)进行拼接,拼接完成后是
现在我们的rel_codes(预测的边界框回归参数)和concat_boxes(存储的生成的anchors信息)维度都是
我们将它们传入decode_single函数,将预测的bbox(rel_codes)回归参数应用到对应anchors上(concat_boxes)得到预测bbox的坐标。(2.2.2节)
最终得到的pred_boxes的shape是
最终返回给上层函数的proposal的坐标的shape是
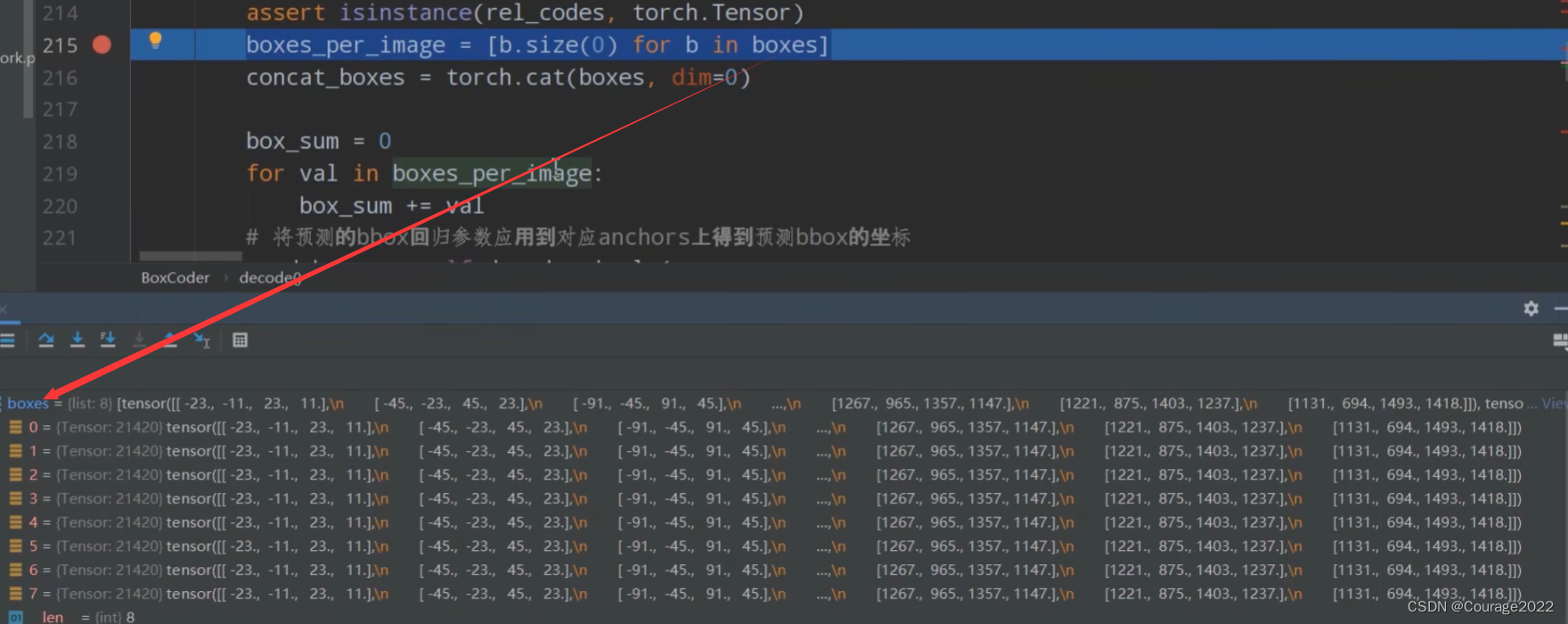

2.2.2 decode_single
#rel_codes回归 boxes anchor def decode_single(self, rel_codes, boxes): """ From a set of original boxes and encoded relative box offsets, get the decoded boxes. Arguments: rel_codes (Tensor): encoded boxes (bbox regression parameters) boxes (Tensor): reference boxes (anchors/proposals) """ boxes = boxes.to(rel_codes.dtype) # xmin, ymin, xmax, ymax # xmax xmin widths = boxes[:, 2] - boxes[:, 0] # anchor/proposal宽度 # ymax ymin heights = boxes[:, 3] - boxes[:, 1] # anchor/proposal高度 # xmin (xmax-xmin)/2 ctr_x = boxes[:, 0] + 0.5 * widths # anchor/proposal中心x坐标 ctr_y = boxes[:, 1] + 0.5 * heights # anchor/proposal中心y坐标 wx, wy, ww, wh = self.weights # RPN中为[1,1,1,1], fastrcnn中为[10,10,5,5] 平衡系数/超参数 dx = rel_codes[:, 0::4] / wx # 预测anchors/proposals的中心坐标x回归参数 dy = rel_codes[:, 1::4] / wy # 预测anchors/proposals的中心坐标y回归参数 dw = rel_codes[:, 2::4] / ww # 预测anchors/proposals的宽度回归参数 dh = rel_codes[:, 3::4] / wh # 预测anchors/proposals的高度回归参数 #设置最大值 # limit max value, prevent sending too large values into torch.exp() # self.bbox_xform_clip=math.log(1000. / 16) 4.135 dw = torch.clamp(dw, max=self.bbox_xform_clip) dh = torch.clamp(dh, max=self.bbox_xform_clip) #将预测的bbox回归参数应用到对应anchors上得到预测bbox的坐标 pred_ctr_x = dx * widths[:, None] + ctr_x[:, None] pred_ctr_y = dy * heights[:, None] + ctr_y[:, None] pred_w = torch.exp(dw) * widths[:, None] pred_h = torch.exp(dh) * heights[:, None] # xmin pred_boxes1 = pred_ctr_x - torch.tensor(0.5, dtype=pred_ctr_x.dtype, device=pred_w.device) * pred_w # ymin pred_boxes2 = pred_ctr_y - torch.tensor(0.5, dtype=pred_ctr_y.dtype, device=pred_h.device) * pred_h # xmax pred_boxes3 = pred_ctr_x + torch.tensor(0.5, dtype=pred_ctr_x.dtype, device=pred_w.device) * pred_w # ymax pred_boxes4 = pred_ctr_y + torch.tensor(0.5, dtype=pred_ctr_y.dtype, device=pred_h.device) * pred_h #pred_boxes1 的格式为1555040*1 pred_boxes = torch.stack((pred_boxes1, pred_boxes2, pred_boxes3, pred_boxes4), dim=2).flatten(1) return pred_boxes输入的参数:
rel_codes(预测的边界框回归参数) 维度是
boxes(存储的生成的anchors信息)维度是
取得anchor的宽度、高度、中心x坐标、中心y坐标。
取得预测坐标的宽度、高度、中心x坐标、中心y坐标。
对dw,dh设置一个上限防止指数爆炸。
将预测值运用到我们的anchor中:
#将预测的bbox回归参数应用到对应anchors上得到预测bbox的坐标 pred_ctr_x = dx * widths[:, None] + ctr_x[:, None] pred_ctr_y = dy * heights[:, None] + ctr_y[:, None] pred_w = torch.exp(dw) * widths[:, None] pred_h = torch.exp(dh) * heights[:, None]
这里的
对应的就是最终的proposal坐标。
就是我们刚刚预测得到的回归参数,
对应的是anchor的信息,因此想得到我们的
宽度和高度:
最后利用这些信息转换成xmin、xmax、ymin、ymax信息:
# xmin pred_boxes1 = pred_ctr_x - torch.tensor(0.5, dtype=pred_ctr_x.dtype, device=pred_w.device) * pred_w # ymin pred_boxes2 = pred_ctr_y - torch.tensor(0.5, dtype=pred_ctr_y.dtype, device=pred_h.device) * pred_h # xmax pred_boxes3 = pred_ctr_x + torch.tensor(0.5, dtype=pred_ctr_x.dtype, device=pred_w.device) * pred_w # ymax pred_boxes4 = pred_ctr_y + torch.tensor(0.5, dtype=pred_ctr_y.dtype, device=pred_h.device) * pred_h看一下它们的shape:pred_boxes1、pred_boxes2...的shape都是
我们通过stack方法进行拼接,最终得到的pred_box的维度为:
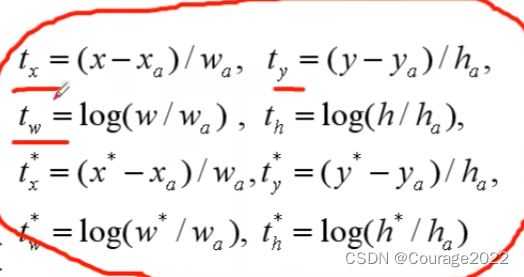

2.2.3 限制shape
def clip_boxes_to_image(boxes, size): # type: (Tensor, Tuple[int, int]) -> Tensor """ Clip boxes so that they lie inside an image of size `size`. 裁剪预测的boxes信息,将越界的坐标调整到图片边界上 Arguments: boxes (Tensor[N, 4]): boxes in (x1, y1, x2, y2) format size (Tuple[height, width]): size of the image Returns: clipped_boxes (Tensor[N, 4]) """ dim = boxes.dim() boxes_x = boxes[..., 0::2] # x1, x2 boxes_y = boxes[..., 1::2] # y1, y2 height, width = size if torchvision._is_tracing(): boxes_x = torch.max(boxes_x, torch.tensor(0, dtype=boxes.dtype, device=boxes.device)) boxes_x = torch.min(boxes_x, torch.tensor(width, dtype=boxes.dtype, device=boxes.device)) boxes_y = torch.max(boxes_y, torch.tensor(0, dtype=boxes.dtype, device=boxes.device)) boxes_y = torch.min(boxes_y, torch.tensor(height, dtype=boxes.dtype, device=boxes.device)) else: boxes_x = boxes_x.clamp(min=0, max=width) # 限制x坐标范围在[0,width]之间 boxes_y = boxes_y.clamp(min=0, max=height) # 限制y坐标范围在[0,height]之间 clipped_boxes = torch.stack((boxes_x, boxes_y), dim=dim) return clipped_boxes.reshape(boxes.shape)
2.2.4 删除小目标remove_small_boxes
def remove_small_boxes(boxes, min_size): # type: (Tensor, float) -> Tensor """ Remove boxes which contains at least one side smaller than min_size. 移除宽高小于指定阈值的索引 Arguments: boxes (Tensor[N, 4]): boxes in (x1, y1, x2, y2) format min_size (float): minimum size Returns: keep (Tensor[K]): indices of the boxes that have both sides larger than min_size """ ws, hs = boxes[:, 2] - boxes[:, 0], boxes[:, 3] - boxes[:, 1] # 预测boxes的宽和高 # keep = (ws >= min_size) & (hs >= min_size) # 当满足宽,高都大于给定阈值时为True keep = torch.logical_and(torch.ge(ws, min_size), torch.ge(hs, min_size)) # nonzero(): Returns a tensor containing the indices of all non-zero elements of input # keep = keep.nonzero().squeeze(1) keep = torch.where(keep)[0] return keep
xmax-xmin得到我们的proposal的宽度, ymax-ymin得到我们的proposal的高度。
我们要满足宽度高度均满足给定的最小值。
2.2.5 batched_nms
def batched_nms(boxes, scores, idxs, iou_threshold): # type: (Tensor, Tensor, Tensor, float) -> Tensor """ Performs non-maximum suppression in a batched fashion. Each index value correspond to a category, and NMS will not be applied between elements of different categories. Parameters ---------- boxes : Tensor[N, 4] boxes where NMS will be performed. They are expected to be in (x1, y1, x2, y2) format scores : Tensor[N] scores for each one of the boxes idxs : Tensor[N] indices of the categories for each one of the boxes. iou_threshold : float discards all overlapping boxes with IoU < iou_threshold Returns ------- keep : Tensor int64 tensor with the indices of the elements that have been kept by NMS, sorted in decreasing order of scores """ if boxes.numel() == 0: return torch.empty((0,), dtype=torch.int64, device=boxes.device) # strategy: in order to perform NMS independently per class. # we add an offset to all the boxes. The offset is dependent # only on the class idx, and is large enough so that boxes # from different classes do not overlap # 获取所有boxes中最大的坐标值(xmin, ymin, xmax, ymax) max_coordinate = boxes.max() # to(): Performs Tensor dtype and/or device conversion # 为每一个类别/每一层生成一个很大的偏移量 # 这里的to只是让生成tensor的dytpe和device与boxes保持一致 offsets = idxs.to(boxes) * (max_coordinate + 1) # boxes加上对应层的偏移量后,保证不同类别/层之间boxes不会有重合的现象 boxes_for_nms = boxes + offsets[:, None] keep = nms(boxes_for_nms, scores, iou_threshold) return keep


![2023新年祝福代码[css动画特效]](https://img-blog.csdnimg.cn/46d30533ba1f4facaa594a390b6f57c7.png)