聚类:发掘纵向结构的某种模式信息,某些x属于相同的分布或者类别
特征学习:发掘横向结构的某种模式信息,每一行都可以看成是一种属性或特征
密度估计:发掘底层数据分布,x都是从某个未知分布p(x)采出来的,p(x)是什么,能不能估计出来
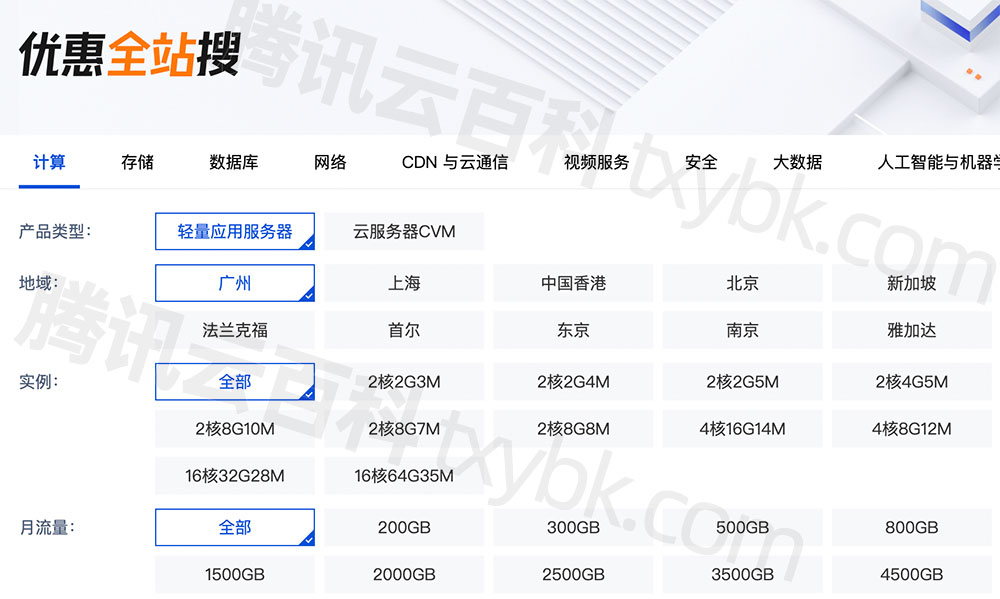
聚类

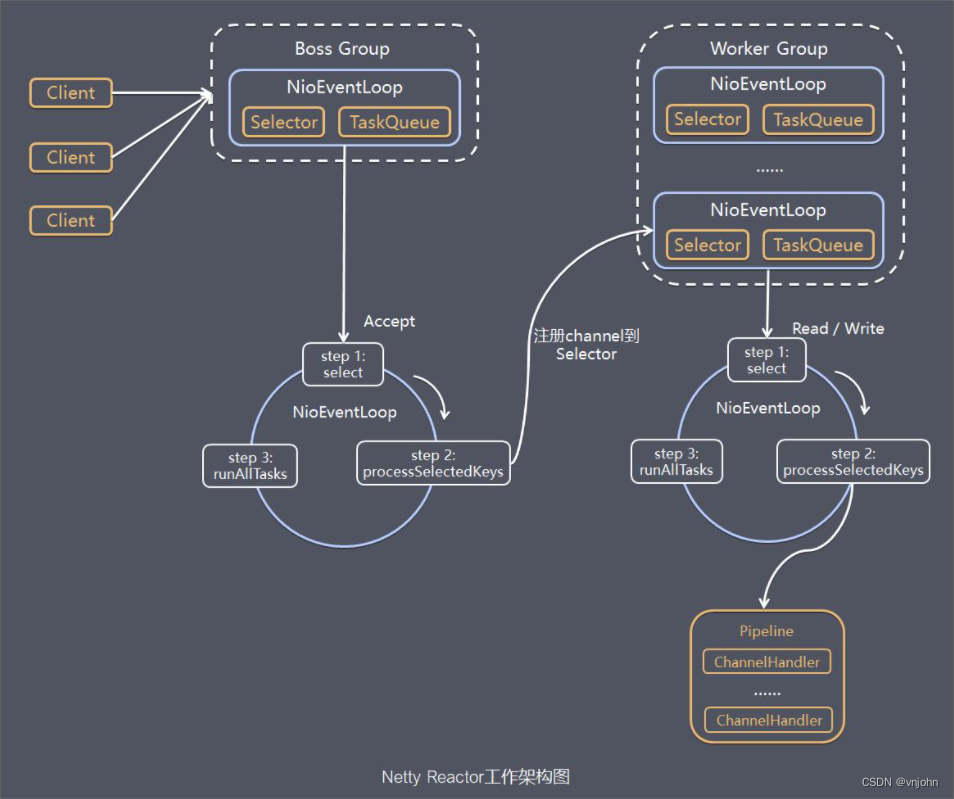
样本间距离


C是指C簇
常见聚类任务

常见聚类方法

聚类效果评估
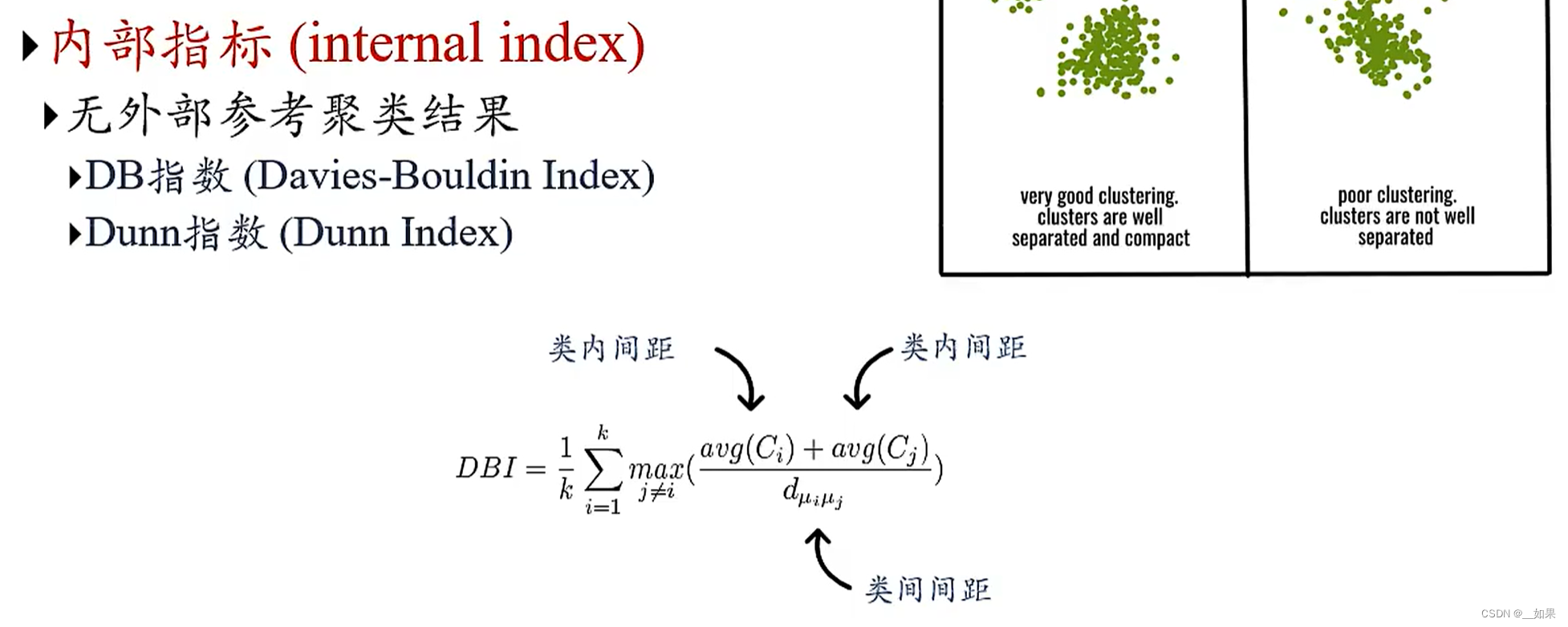
外部指标

内部指标
当我们没有办法参考正确的分类,我们怎么评判聚类的好坏?
最核心的思想还是类内相似度高,类间相似度低

聚类:发掘纵向结构的某种模式信息,某些x属于相同的分布或者类别
特征学习:发掘横向结构的某种模式信息,每一行都可以看成是一种属性或特征
密度估计:发掘底层数据分布,x都是从某个未知分布p(x)采出来的,p(x)是什么,能不能估计出来
C是指C簇
当我们没有办法参考正确的分类,我们怎么评判聚类的好坏?
最核心的思想还是类内相似度高,类间相似度低
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如若转载,请注明出处:http://www.coloradmin.cn/o/1315982.html
如若内容造成侵权/违法违规/事实不符,请联系多彩编程网进行投诉反馈,一经查实,立即删除!