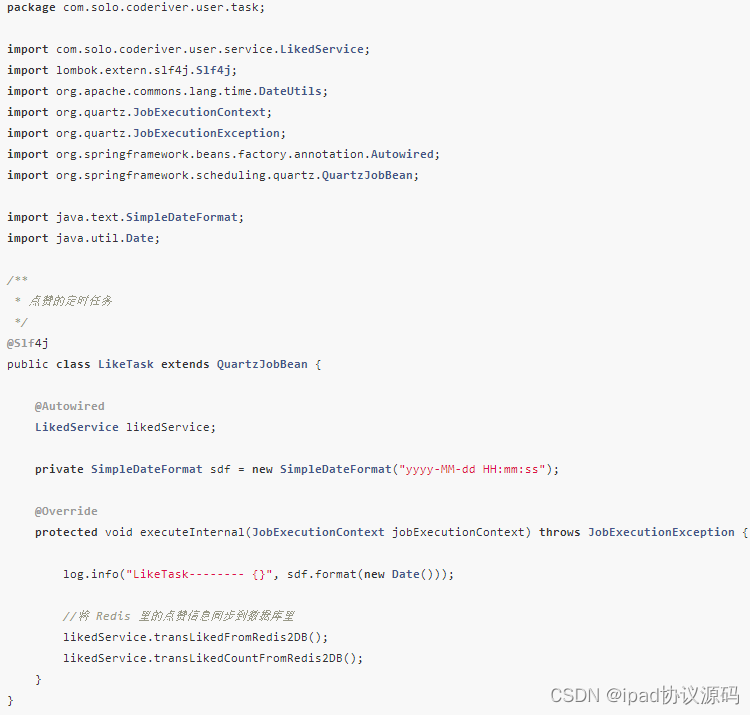
Kafka 日志详解
Apache Kafka日志存储在物理磁盘上各种数据的集合,日志按照topic分区进行文件组织,每一个分区日志由一个或者多个文件组成。生产者发送的消息被顺序追加到日志文件的末尾。

如上图所述,Kafka主题被划分为3个分区。在Kafka中,分区是一个逻辑工作单元,其中记录被顺序附加分区上 (kafka只能保证分区消息的有序性,而不能保证消息的全局有序性)。但是分区不是存储单元,分区进一步划分为Segment - 段,这些段是文件系统上的实际文件。为了获得更好的性能和可维护性,可以创建多个段,而不是从一个巨大的分区中读取,消费者现在可以更快地从较小的段文件中读取。创建具有分区名称的目录,并将该分区的所有段作为各种文件进行维护。图中 topic主题分为3个分区
- Partition 0 - 目前有三个segment文件段组成,Segment0、Segment1已经写满,目前Segment 2处于活跃状态
- Partition 1
- Partition 2
Segment
文件说明
|── my-topic-0
├── 00000000000000000000.index
├── 00000000000000000000.log
├── 00000000000000000000.timeindex
├── 00000000000000001007.index
├── 00000000000000001007.log
├── 00000000000000001007.snapshot
├── 00000000000000001007.timeindex
文件说明:
- **.log 文件 - 此文件包含实际记录,并将记录保持到特定偏移量,文件名描述了添加到此文件的起始偏移量
- .index 文件 - ** 索引文件,记录偏移量映射到 .log 文件的字节偏移量,此映射用于从任何特定偏移量读取记录
- **.timeindex 文件- 时间戳索引文件,此文件包含时间戳到记录偏移量的映射,该映射使用.index文件在内部映射到记录的字节偏移量。这有助于从特定时间戳访问记录
- .snapshot 文件 - 包含用于避免重复记录序列ID的生产者快照。出现Leader选举时使用,避免出现数据重复
数据长度
之前提到过,log文件的文件名表示该文件的起始偏移量。那么从上面的文件我们可以分析出,第一个日志段00000000000000000000.log包含从偏移量0到偏移量1006的记录。原因是下一个段00000000000000001007.log具有从偏移量1007开始的记录,这称为活动段。

当前活跃的Segment段文件是唯一可用于读取和写入的文件,而用户可以使用其他日志段(非活动)读取数据。当活动段变满(由log.segment.bytes配置,默认为1 GB)或配置的时间(log.roll.hours或log.roll.ms,默认为7天)过去时,该段将被滚动。这意味着活动段将以只读模式关闭并重新打开,并且将以读写模式创建新的段文件(活动段)。
log.roll.hours
Segment 日志保留的时间配置,单位为小时,默认168小时,即7天。
| Type: | int |
|---|---|
| Default: | 168 |
| Valid Values: | [1,…] |
| Importance: | high |
| Update Mode: | read-only |
在生产环境中,该参数需要结合业务实际情况进行合理配置,否则就会出现磁盘爆满的问题。
我之前的工作经验中出现过此类问题,由于生产者产生数据频率较快,在2-3天之内就已经将500G的硬盘占满,但是kafka默认保留7天日志,导致数据没有及时清理,从而导致磁盘占满的问题。后面经过权衡,配置了48小时,之后再没有出现暴磁盘的现象。
位移索引
索引有助于消费者从任何指定偏移量或使用任何时间范围读取数据。如前所述,.index文件包含一个索引,该索引将逻辑偏移量映射到.log文件中记录的字节偏移量。您可能希望每个记录都可以使用此映射,但它不能以这种方式工作 。
如何在索引文件中生成新的索引项由log.index.interval.bytes参数定义,默认值为4096字节。这意味着在日志中每添加4096个字节后,就会向索引文件中添加一个索引项。假设生产者向Kafka主题发送消息,占100字节。在这种情况下,在日志文件中每追加41条记录(41*100=4100字节)后,将向.index文件中添加一个新的索引项。

消费者从指定偏移量位置读取数据的,步骤大致如下:
- 根据topic名称搜索.index文件。例如,如果偏移量为1191,将搜索其名称值小于1191的索引文件。索引文件的命名约定与日志文件相同(这一点非常重要)
- 在.index文件中搜索请求的偏移量所在的索引项
- 使用映射的字节偏移量访问**.log**文件,并开始使用该字节偏移量的记录
时间索引
消费者可能还希望从特定的时间戳读取记录。这就是使用到.timeindex索引文件。它维护一个时间戳和偏移量映射(映射到.index文件中的索引项),映射到.log文件中的实际字节偏移量。

如图索引,根据时间戳读取数据,比根据位移读取数据要复杂一些,多经历了一个数据查找的步骤。
指定读取
现在写两个按照指定位移/时间戳读取消息的demo。
位移读取
public class OffsetConsumer {
public static void main(String[] args) {
String bootstrapServers = "127.0.0.1:9092";
String topic = "topic_t40";
// create consumer configs
Properties properties = new Properties();
properties.setProperty(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, bootstrapServers);
properties.setProperty(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
properties.setProperty(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
properties.setProperty(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG, "earliest");
// create consumer
KafkaConsumer<String, String> consumer = new KafkaConsumer<String, String>(properties);
// assign
TopicPartition partitionToReadFrom = new TopicPartition(topic, 0);
long offsetToReadFrom = 200L;
consumer.assign(Arrays.asList(partitionToReadFrom));
// seek to offset 200
consumer.seek(partitionToReadFrom, offsetToReadFrom);
boolean keepOnReading = true;
// poll for new data
while(keepOnReading){
ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(100));
for (ConsumerRecord<String, String> record : records){
System.out.println("Message received " + record.value() + ", partition " + record.partition() + ", offset=" + record.offset());
}
}
}
}
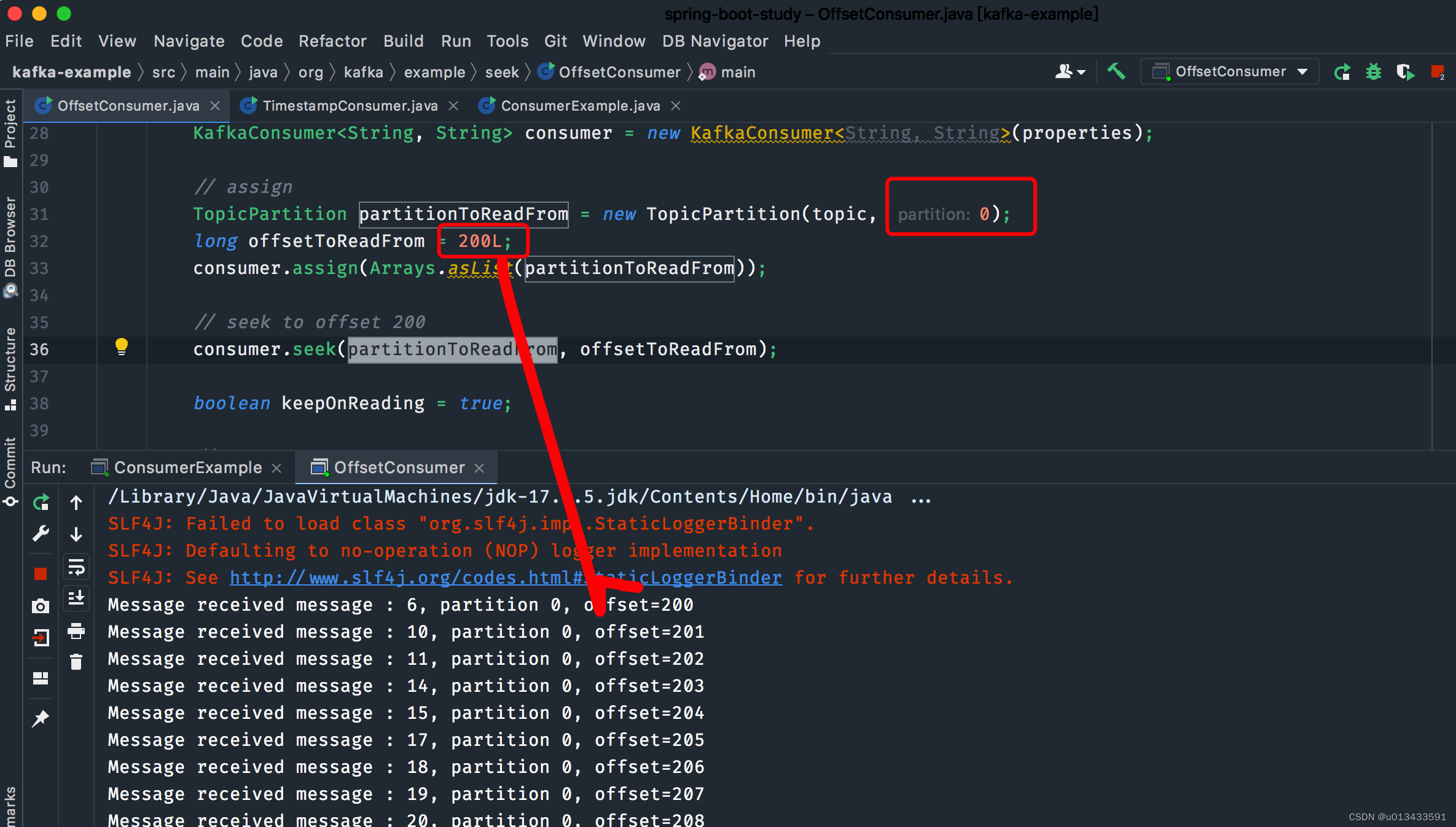
如上图所示,指定读取分区0,从偏移量200开始读取数据
时间戳读取
public class TimestampConsumer {
public static void main(String[] args) throws Exception{
String topicName = "topic_t40";
Properties props = new Properties();
props.put("bootstrap.servers", "localhost:9092");
props.put(ConsumerConfig.GROUP_ID_CONFIG, "app_hp1");
props.put("client.id", "client_01");
props.put("enable.auto.commit", true);
props.put(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG, "latest");
props.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
props.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
KafkaConsumer<String, String> consumer = new KafkaConsumer<>(props);
List<PartitionInfo> partitions = consumer.partitionsFor(topicName);
List<TopicPartition> topicPartitionList = partitions
.stream()
.map(info -> new TopicPartition(topicName, info.partition()))
.collect(Collectors.toList());
consumer.assign(topicPartitionList);
Map<TopicPartition, Long> partitionTimestampMap = topicPartitionList.stream()
.collect(Collectors.toMap(tp -> tp, tp -> 1672239981330L));
Map<TopicPartition, OffsetAndTimestamp> partitionOffsetMap = consumer.offsetsForTimes(partitionTimestampMap);
// Force the consumer to seek for those offsets
partitionOffsetMap.forEach((tp, offsetAndTimestamp) -> consumer.seek(tp, offsetAndTimestamp.offset()));
boolean keepOnReading = true;
while(keepOnReading){
ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(100));
for (ConsumerRecord<String, String> record : records){
System.out.println("Message received " + record.value() + ", partition " + record.partition() + ", offset=" + record.offset() + ", timestamp=" + record.timestamp());
}
}
}
}

如上图所示,打印出来的消息时间都大于指定时间。











![buuctf-misc-[GKCTF 2021]你知道apng吗1](https://img-blog.csdnimg.cn/a53b4ede82b24bc4ac9e0e219518f4b2.png)