微信公众号转载,关注微信公众号掌握更多技术动态

---------------------------------------------------------------
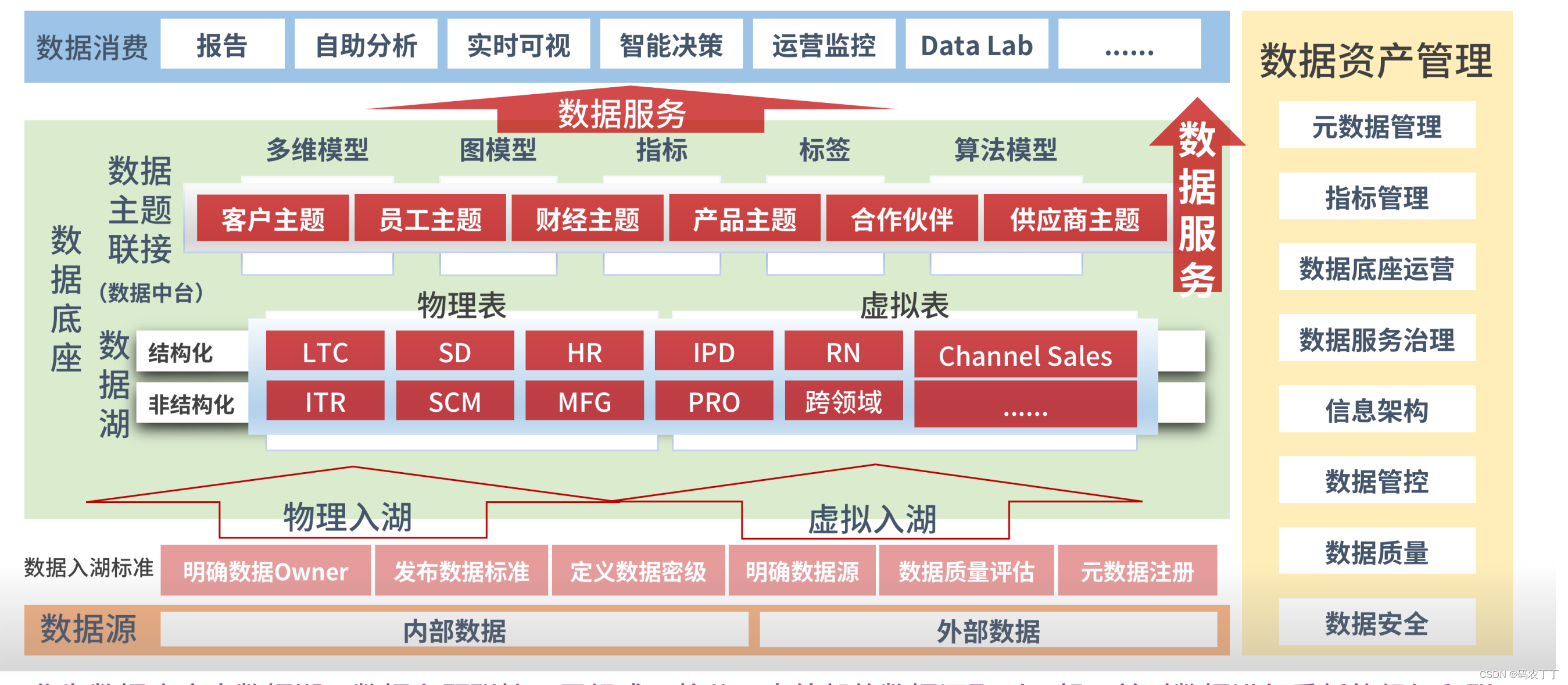
一、字符串与集合性能优化
1.String 对象的实现
在 Java 语言中,Sun 公司的工程师们对 String 对象做了大量的优化,来节约内存空间,提升 String 对象在系统中的性能。
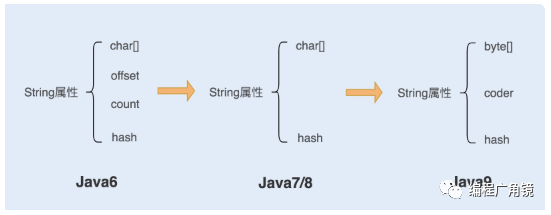
(1)在 Java6 以及之前的版本中,String对象是对 char 数组进行了封装实现的对象,主要有四个成员变量:char 数组、偏移量 offset、字符数量 count、哈希值 hash。
String 对象是通过 offset 和 count 两个属性来定位 char[] 数组,获取字符串。这么做可以高效、快速地共享数组对象,同时节省内存空间,但这种方式很有可能会导致内存泄漏。
(2)Java7/Java8,Java 对 String 类做了一些改变。String 类中不再有 offset 和 count 两个变量了。这样的好处是 String 对象占用的内存稍微少了些,同时,String.substring 方法也不再共享 char[],从而解决了使用该方法可能导致的内存泄漏问题。
(3)从 Java9 版本开始,将 char[] 字段改为了 byte[] 字段,又维护了一个新的属性 coder,它是一个编码格式的标识。
一个 char 字符占 16 位,2 个字节。这个情况下,存储单字节编码内的字符(占一个字节的字符)就显得非常浪费。JDK1.9 的 String 类为了节约内存空间,于是使用了占 8 位,1 个字节的 byte 数组来存放字符串。
而新属性 coder 的作用是,在计算字符串长度或者使用 indexOf()函数时,我们需要根据这个字段,判断如何计算字符串长度。coder 属性默认有 0 和 1 两个值,0 代表 Latin-1(单字节编码),1 代表 UTF-16。如果 String 判断字符串只包含了 Latin-1,则 coder 属性值为 0,反之则为 1。
2.String 对象的优化
(1)合理选择StringBuilder和String
①大量字符串拼接选择StringBuilder
循环体内不要使用”+”进行字符串拼接,而直接使用StringBuilder不断append
public String appendStr(String oriStr, String… appendStrs) {if (appendStrs == null || appendStrs.length == 0) {return oriStr;}for (String appendStr : appendStrs) {oriStr += appendStr;}return oriStr;
每次虚拟机碰到”+”这个操作符对字符串进行拼接的时候,会new出一个StringBuilder,然后调用append方法,最后调用toString()方法转换字符串赋值给oriStr对象,即循环多少次,就会new出多少个StringBuilder()来,这对于内存是一种浪费。(只有代码换行使用String拼接)而且创建对象的过程也会浪费时间
②少量的字符串拼接选择String
String str= "ab" + "cd" + "ef" 此时系统会自动完成优化
(2)合理String.intern 方法节省内存
①针对可能出现大量重复的字符串使用intern(国家、省市、地区)
SharedLocation sharedLocation = new SharedLocation();sharedLocation.setCity(messageInfo.getCity().intern());sharedLocation.setCountryCode(messageInfo.getCountryCode().intern());sharedLocation.setRegion(messageInfo.getCountryRegion().intern());
在字符串常量中,默认会将对象放入常量池;在字符串变量中,对象是会创建在堆内存中,同时也会在常量池中创建一个字符串对象,复制到堆内存对象中,并返回堆内存对象引用。
如果调用 intern 方法,会去查看字符串常量池中是否有等于该对象的字符串的引用,如果没有,jdk1.8只是会把首次遇到的字符串的引用添加到常量池中;如果有,就返回常量池中的字符串引用。
String a =new String("abc").intern();String b = new String("abc").intern();if(a==b) {System.out.print("a==b");}
在一开始字符串"abc"会在加载类时,在常量池中创建一个字符串对象。
创建 a 变量时,调用 new Sting() 会在堆内存中创建一个 String 对象,String 对象中的char 数组将会引用常量池中字符串。在调用 intern 方法之后,会去常量池中查找是否有等于该字符串对象的引用,有就返回引用。
创建 b 变量时,调用 new Sting() 会在堆内存中创建一个 String 对象,String 对象中的 char 数组将会引用常量池中字符串。在调用 intern 方法之后,会去常量池中查找是否有等于该字符串对象的引用,有就返回引用。
而在堆内存中的两个对象,由于没有引用指向它,将会被垃圾回收。所以 a 和 b 引用的是同一个对象。
②针对重复值少,不重复值多的字段不要使用intern
常量池的实现是类似于一个 HashTable 的实现方式,HashTable 存储的数据越大,遍历的时间复杂度就会增加。如果数据过大,会增加整个字符串常量池的负担。如果 string pool 设置太小而缓存的字符串过多,也会造成较大的性能开销。
(3)合理使用split
①避免回溯问题
除非是必须的,否则应该避免使用split,split由于支持正则表达式,使用不恰当会引起回溯问题,很可能导致 CPU 居高不下,如果确实需要频繁的调用split,可以考虑使用apache的StringUtils.split(string,char),频繁split的可以缓存结果。
用 NFA 自动机实现的比较复杂的正则表达式,在匹配过程中经常会引起回溯问题。大量的回溯会长时间地占用 CPU,从而带来系统性能开销。
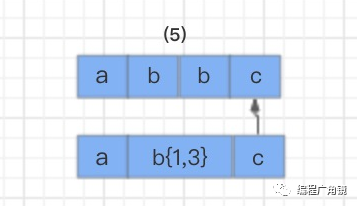
text=“abbc”regex=“ab{1,3}c”
首先,读取正则表达式第一个匹配符 a 和字符串第一个字符 a 进行比较,a 对 a,匹配。
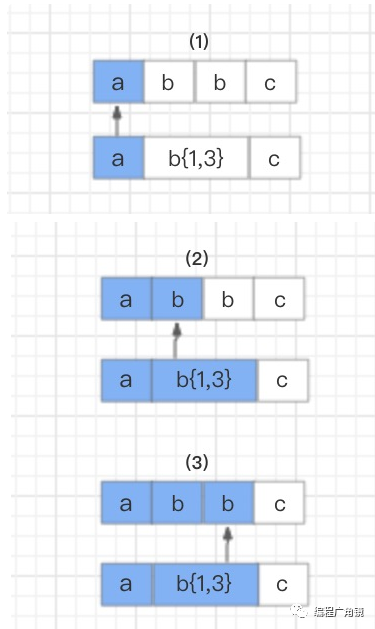
接着继续使用 b{1,3} 和字符串的第四个字符 c 进行比较,发现不匹配了,此时就会发生回溯,已经读取的字符串第四个字符 c 将被吐出去,指针回到第三个字符 b 的位置。
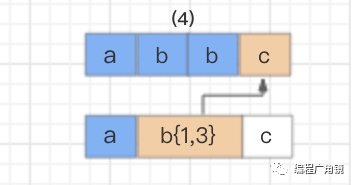
那么发生回溯以后,匹配过程怎么继续呢?程序会读取正则表达式的下一个匹配符 c,和字符串中的第四个字符 c 进行比较,结果匹配,结束。
②部分关键字(比如.[]()\| 等)需要转义
反例:
"a.ab.abc".split("."); // 结果为[]"a|ab|abc".split("|"); // 结果为["a", "|", "a", "b", "|", "a", "b", "c"]
正例:
"a.ab.abc".split("\\."); // 结果为["a", "ab", "abc"]"a|ab|abc".split("\\|"); // 结果为["a", "ab", "abc"]
(4)关于toString()方法的使用
把一个基本数据类型转为字符串,基本数据类型.toString()是最快的方式、String.valueOf(数据)次之、数据+" "最慢
String.valueOf()方法底层调用了Integer.toString()方法,但是会在调用前做空判断;
i + “”底层使用了StringBuilder实现,先用append方法拼接,再用toString()方法获取字符串;
public static void main(String[] args){int loopTime = 50000;Integer i = 0;long startTime = System.currentTimeMillis();for (int j = 0; j < loopTime; j++){String str = String.valueOf(i);}System.out.println(“String.valueOf():”+ (System.currentTimeMillis() - startTime) + “ms”);startTime = System.currentTimeMillis();for (int j = 0; j < loopTime; j++){String str = i.toString();}System.out.println(“Integer.toString():” + (System.currentTimeMillis() - startTime) + “ms”);startTime = System.currentTimeMillis();for (int j = 0; j < loopTime; j++){String str = i + “”;}System.out.println(“i + \”\”:” + (System.currentTimeMillis() - startTime) + “ms”);}
运行结果为:
String.valueOf():11ms
Integer.toString():5ms
i + “”:25ms
(5)使用 Apache Commons StringUtils.Replace 而不是 String.replace
一般来说,String.replace 方法可以正常工作,并且效率很高,尤其是在你使用 Java 9 的情况下。但是,如果你的应用程序需要大量的替换操作,并且没有更新到最新的 Java 版本,那么检查更快和更有效的替代品依然是有必要的。有一种候选方案是 Apache Commons Lang 的 StringUtils.replace 方法。
// replace thistest.replace(“test”, “simple test”);// with thisStringUtils.replace(test, “test”, “simple test”);
3.集合性能优化
(1)尽量初始ArrayList的大小
如果能估计到待添加的内容长度,为底层以数组方式实现的集合、工具类指定初始长度。比如ArrayList、StringBuilder、StringBuffer、HashMap、HashSet等等,以StringBuilder为例:
-
StringBuilder() 默认分配16个字符的空间
-
StringBuilder(int size) 默认分配size个字符的空间
-
StringBuilder(String str) 默认分配16个字符+str.length()个字符空间
可以通过类(这里指的不仅仅是上面的StringBuilder)的构造函数来设定它的初始化容量,这样可以明显地提升性能。
比如StringBuilder,length表示当前的StringBuilder能保持的字符数量。因为当StringBuilder达到最大容量的时候,它会将自身容量增加到当前的2倍再加2,无论何时只要StringBuilder达到它的最大容量,它就不得不创建一个新的字符数组然后将旧的字符数组内容拷贝到新字符数组中——这是十分耗费性能的一个操作。
但是,注意,像HashMap这种是以数组+链表实现的集合,别把初始大小和你估计的大小设置得一样,因为一个table上只连接一个对象的可能性几乎为0。初始大小建议设置为2的N次幂,如果能估计到有2000个元素,设置成new HashMap(128)、new HashMap(256)都可以。
(2) 公用的集合类中不使用的数据一定要及时remove掉
如果一个集合类是公用的(也就是说不是方法里面的属性),那么这个集合里面的元素是不会自动释放的,因为始终有引用指向它们。
所以,如果公用集合里面的某些数据不使用而不去remove掉它们,那么将会造成这个公用集合不断增大,使得系统有内存泄露的隐患。
(3)ArrayList进行优化
trimToSize() 减少无用的集合空间
ensureCapacity() 减少数组扩容所需的时间
subList() 进行集合中数据的批量删除
(4)arrayList和linkedList的选择
推荐使用arrayList,只有在特定情况下才可以使用linkedList
(5)hashMap的优化
当查询操作较为频繁时,我们可以适当地减少加载因子;如果对内存利用率要求比较 高,我可以适当的增加加载因子。
(6)contains方法使用:使用HashSet替换ArrayList
Set()的contain时间复杂度是O(1),而List.contain的时间复杂度是O(n)。
①ArrayList得contains实现
contains()方法调用了indexOf()方法,该方法通过遍历数据和比较元素的方式来判断是否存在给定元素。当ArrayList中存放的元素非常多时,这种实现方式来判断效率将非常低。
public boolean contains(Object o) {return indexOf(o) >= 0;}
②HashSet得contains实现
containsKey()方法调用getEntry()方法。在该方法中,首先根据key计算hash值,然后从HashMap中取出该hash值对应的链表(链表的元素个数将很少),再通过变量该链表判断是否存在给定值。这种实现方式效率将比ArrayList的实现方法效率高非常多。
public boolean contains(Object o) {return map.containsKey(o);}
4.Stream性能优化
多核 CPU 服务器配置环境下,对比长度 100 的 int 数组的性能;
多核 CPU 服务器配置环境下,对比长度 1.00E+8 的 int 数组的性能;
多核 CPU 服务器配置环境下,对比长度 1.00E+8 对象数组过滤分组的性能;
单核 CPU 服务器配置环境下,对比长度 1.00E+8 对象数组过滤分组的性能。
常规的迭代<stream 并行迭代="" <stream="" 串行迭代<="" span="">
Stream 并行迭代 < 常规的迭代<stream 串行迭代<="" span="">
Stream 并行迭代 < 常规的迭代<stream 串行迭代<="" span="">
常规的迭代<stream 串行迭代="" <stream="" 并行迭代<="" span="">
在循环迭代次数较少的情况下,常规的迭代方式性能反而更好;在单核 CPU 服务器配置环境中,也是常规迭代方式更有优势;而在大数据循环迭代中,如果服务器是多核 CPU 的情况下,Stream 的并行迭代优势明显。
5.变量性能调优
(1)尽可能使用基本类型
避免任何开销并提高应用程序性能的另一种简便快速的方法是使用基本类型而不是其包装类。所以,最好使用 int 而不是 Integer ,是 double 而不是 Double 。这将使得你的 JVM 将值存储在堆栈而不是堆中,以减少内存消耗,并更有效地处理它。
避免引用类型和基础类型之间无谓的拆装箱操作,请尽量保持一致,自动装箱发生太频繁,会非常严重消耗性能。
(2)尽量避免大整数和小数
大整数和小数尤其是后者因其精确性而受欢迎,但这是有代价的。大整数和小数比一个简单的 long 型或 double 型需要更多的内存,并会显著减慢所有的运算。所以,如果你需要额外的精度,或者如果你的数字超出一个较长的范围,最好要三思。这可能是你需要更改并解决性能问题的唯一方法,尤其是在实现数学算法时。
(3)已经获取到的值,尽量传递,不要重新计算
public Response dealRequest(Request request){UserInfo userInfo = userInfoDao.selectUserByUserId(request.getUserId);if(Objects.isNull(request)){return ;}insertUserVip(request.getUserId);}private int insertUserVip(String userId){//又查了一次UserInfo userInfo = userInfoDao.selectUserByUserId(request.getUserId);//插入用户vip流水insertUserVipFlow(userInfo);....}
6.if条件
// 当使用&&时,应将常不满足条件的判断放在前面// 比如isUserVip经常为false,只要判断isUserVip就可以避免后续判断if(isUserVip && isFirstLogin){sendMsgNotify();}
二、IO与网络性能优化
I/O 的速度要比内存速度慢,尤其在大数据时代背景下,I/O 的性能问题更是尤为突出,I/O 读写已经成为很多应用场景下的系统性能瓶颈。
1.传统IO问题及优化
(1)传统 I/O 的性能问题
①多次内存复制
在传统 I/O 中,我们可以通过 InputStream 从源数据中读取数据流输入到缓冲区里,通过 OutputStream 将数据输出到外部设备(包括磁盘、网络)。
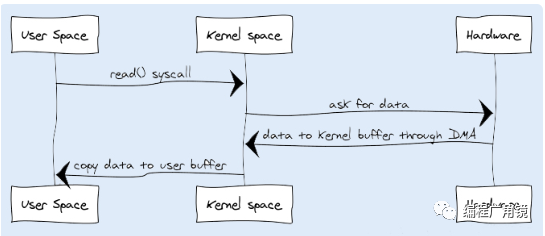
-
JVM 会发出 read() 系统调用,并通过 read 系统调用向内核发起读请求;
-
内核向硬件发送读指令,并等待读就绪;
-
内核把将要读取的数据复制到指向的内核缓存中;
-
操作系统内核将数据复制到用户空间缓冲区,然后 read 系统调用返回。
在这个过程中,数据先从外部设备复制到内核空间,再从内核空间复制到用户空间,这就发生了两次内存复制操作。这种操作会导致不必要的数据拷贝和上下文切换,从而降低 I/O 的性能。
②阻塞
在传统 I/O 中,InputStream 的 read() 是一个 while 循环操作,它会一直等待数据读取,直到数据就绪才会返回。如果没有数据就绪,这个读取操作将会一直被挂起,用户线程将会处于阻塞状态。
在少量连接请求的情况下,使用这种方式没有问题,响应速度也很高。但在发生大量连接请求时,就需要创建大量监听线程,这时如果线程没有数据就绪就会被挂起,然后进入阻塞状态。一旦发生线程阻塞,这些线程将会不断地抢夺 CPU 资源,从而导致大量的 CPU 上下文切换,增加系统的性能开销。
(2)优化 I/O
在 JDK 1.4 中原来的 I/O 包和 NIO 已经很好地集成了。 java.io.* 已经以 NIO 为基础重新实现了,所以现在它可以利用 NIO 的一些特性。例如, java.io.* 包中的一些类包含以块的形式读写数据的方法,这使得即使在更面向流的系统中,处理速度也会更快。
可以看到,1.4后的IO经过了集成。所以NIO的好处,集中在其他特性上,而非速度:
-
分散与聚集读取
-
文件锁定功能
-
网络异步IO
2.序列化与反序列化
当前大部分后端服务都是基于微服务架构实现的。服务按照业务划分被拆分,实现了服务的解耦,但同时也带来了新的问题,不同业务之间通信需要通过接口实现调用。两个服务之间要共享一个数据对象,就需要从对象转换成二进制流,通过网络传输,传送到对方服务,再转换回对象,供服务方法调用。这个编码和解码过程我们称之为序列化与反序列化。
在大量并发请求的情况下,如果序列化的速度慢,会导致请求响应时间增加;而序列化后的传输数据体积大,会导致网络吞吐量下降。所以一个优秀的序列化框架可以提高系统的整体性能。
减少序列化(避免RPC),如果无法减少替换java序列化的方法
(1)java序列化的实现原理
Java 提供了一种序列化机制,这种机制能够将一个对象序列化为二进制形式(字节数组),用于写入磁盘或输出到网络,同时也能从网络或磁盘中读取字节数组,反序列化成对象,在程序中使用。JDK 提供的两个输入、输出流对象 ObjectInputStream 和 ObjectOutputStream,它们只能对实现了 Serializable 接口的类的对象进行反序列化和序列化。
具体实现序列化的是 writeObject 和 readObject,通常这两个方法是默认的,当然也可以在实现 Serializable 接口的类中对其进行重写,定制一套属于自己的序列化与反序列化机制。
另外,Java 序列化的类中还定义了两个重写方法:writeReplace() 和 readResolve(),前者是用来在序列化之前替换序列化对象的,后者是用来在反序列化之后对返回对象进行处理的。
(2)Java 序列化的缺陷
①无法跨语言
现在的系统设计越来越多元化,很多系统都使用了多种语言来编写应用程序。而 Java 序列化目前只适用基于 Java 语言实现的框架,其它语言大部分都没有使用 Java 的序列化框架,也没有实现 Java 序列化这套协议。因此,如果是两个基于不同语言编写的应用程序相互通信,则无法实现两个应用服务之间传输对象的序列化与反序列化。
②易被攻击
对象是通过在 ObjectInputStream 上调用 readObject() 方法进行反序列化的,这个方法其实是一个神奇的构造器,它可以将类路径上几乎所有实现了 Serializable 接口的对象都实例化。这也就意味着,在反序列化字节流的过程中,该方法可以执行任意类型的代码,这是非常危险的。
对于需要长时间进行反序列化的对象,不需要执行任何代码,也可以发起一次攻击。攻击者可以创建循环对象链,然后将序列化后的对象传输到程序中反序列化,这种情况会导致 hashCode 方法被调用次数呈次方爆发式增长, 从而引发栈溢出异常。例如下面这个案例就可以很好地说明。
Set root = new HashSet();Set s1 = root;Set s2 = new HashSet();for (int i = 0; i < 100; i++) {Set t1 = new HashSet();Set t2 = new HashSet();t1.add("foo"); // 使 t2 不等于 t1s1.add(t1);s1.add(t2);s2.add(t1);s2.add(t2);s1 = t1;s2 = t2;}
后续解决方案
很多序列化协议都制定了一套数据结构来保存和获取对象。例如,JSON 序列化、ProtocolBuf 等,它们只支持一些基本类型和数组数据类型,这样可以避免反序列化创建一些不确定的实例。虽然它们的设计简单,但足以满足当前大部分系统的数据传输需求。
可以通过反序列化对象白名单来控制反序列化对象,可以重写 resolveClass 方法,并在该方法中校验对象名字。
@Overrideprotected Class resolveClass(ObjectStreamClass desc) throws IOException,ClassNotFoundException {if (!desc.getName().equals(Bicycle.class.getName())) {throw new InvalidClassException("Unauthorized deserialization attempt", desc.getName());}return super.resolveClass(desc);}
③序列化后的流太大
序列化后的二进制流大小能体现序列化的性能。序列化后的二进制数组越大,占用的存储空间就越多,存储硬件的成本就越高。如果我们是进行网络传输,则占用的带宽就更多,这时就会影响到系统的吞吐量。
Java 序列化实现的二进制编码完成的二进制数组大小,比 ByteBuffer 实现的二进制编码完成的二进制数组大小要大上几倍。因此,Java 序列后的流会变大,最终会影响到系统的吞吐量。
User user = new User();user.setUserName("test");user.setPassword("test");ByteArrayOutputStream os =new ByteArrayOutputStream();ObjectOutputStream out = new ObjectOutputStream(os);out.writeObject(user);byte[] testByte = os.toByteArray();System.out.print("ObjectOutputStream 字节编码长度:" + testByte.length + "\n");
ByteBuffer byteBuffer = ByteBuffer.allocate( 2048);byte[] userName = user.getUserName().getBytes();byte[] password = user.getPassword().getBytes();byteBuffer.putInt(userName.length);byteBuffer.put(userName);byteBuffer.putInt(password.length);byteBuffer.put(password);byteBuffer.flip();byte[] bytes = new byte[byteBuffer.remaining()];System.out.print("ByteBuffer 字节编码长度:" + bytes.length+ "\n");
ObjectOutputStream 字节编码长度:99
ByteBuffer 字节编码长度:16
④序列化性能太差
序列化的速度也是体现序列化性能的重要指标,如果序列化的速度慢,就会影响网络通信的效率,从而增加系统的响应时间。Java 序列化中的编码耗时要比 ByteBuffer 长很多
User user = new User();user.setUserName("test");user.setPassword("test");long startTime = System.currentTimeMillis();for(int i=0; i<1000; i++) {ByteArrayOutputStream os =new ByteArrayOutputStream();ObjectOutputStream out = new ObjectOutputStream(os);out.writeObject(user);out.flush();out.close();byte[] testByte = os.toByteArray();os.close();}long endTime = System.currentTimeMillis();System.out.print("ObjectOutputStream 序列化时间:" + (endTime - startTime) + "\n");
long startTime1 = System.currentTimeMillis();for(int i=0; i<1000; i++) {ByteBuffer byteBuffer = ByteBuffer.allocate( 2048);byte[] userName = user.getUserName().getBytes();byte[] password = user.getPassword().getBytes();byteBuffer.putInt(userName.length);byteBuffer.put(userName);byteBuffer.putInt(password.length);byteBuffer.put(password);byteBuffer.flip();byte[] bytes = new byte[byteBuffer.remaining()];}long endTime1 = System.currentTimeMillis();System.out.print("ByteBuffer 序列化时间:" + (endTime1 - startTime1)+ "\n");
ObjectOutputStream 序列化时间:29
ByteBuffer 序列化时间:6
(3)解决方案
目前业内优秀的序列化框架有很多,而且大部分都避免了 Java 默认序列化的一些缺陷。例如,最近几年比较流行的 FastJson、Kryo、Protobuf、Hessian 等。我们完全可以找一种替换掉 Java 序列化,推荐使用 Protobuf 序列化框架。
3.减少编码
Java 的编码运行比较慢,这是 Java 的一大硬伤。在很多场景下,只要涉及字符串的操作 (如输入输出操作、I/O 操作)都比较耗 CPU 资源,不管它是磁盘 I/O 还是网络 I/O,因 为都需要将字符转换成字节,而这个转换必须编码。 每个字符的编码都需要查表,而这种查表的操作非常耗资源,所以减少字符到字节或者相反 的转换、减少字符编码会非常有成效。减少编码就可以大大提升性能。 那么如何才能减少编码呢?例如,网页输出是可以直接进行流输出的,即用 resp.getOutputStream() 函数写数据,把一些静态的数据提前转化成字节,等到真正往外 写的时候再直接用 OutputStream() 函数写,就可以减少静态数据的编码转换。
三、多线程性能调优——降低锁竞争
-
互斥锁能够满足各类功能性要求,特别是被锁住的代码执行时间不可控时,它通过内核执行线程切换及时释放了资源,但它的性能消耗最大。
-
如果能够确定被锁住的代码取到锁后很快就能释放,应该使用更高效的自旋锁,它特别适合基于异步编程实现的高并发服务。
-
如果能区分出读写操作,读写锁就是第一选择,它允许多个读线程同时持有读锁,提高了并发性。读写锁是有倾向性的,读优先锁很高效,但容易让写线程饿死,而写优先锁会优先服务写线程,但对读线程亲和性差一些。还有一种公平读写锁,它通过把等待锁的线程排队,以略微牺牲性能的方式,保证了某种线程不会饿死,通用性更佳。另外,读写锁既可以使用互斥锁实现,也可以使用自旋锁实现,我们应根据场景来选择合适的实现。
-
当并发访问共享资源,冲突概率非常低的时候,可以选择无锁编程。然而,一旦冲突概率上升,就不适合使用它,因为它解决冲突的重试成本非常高。
1.深入了解Synchronized同步锁的优化方法
(1)自旋锁的关闭
在锁竞争不激烈且锁占用时间非常短的场景下,自旋锁可以提高系统性能。一旦锁竞争激烈或锁占用的时间过长,自旋锁将会导致大量的线程一直处于 CAS 重试状态,占用 CPU 资源,反而会增加系统性能开销。所以自旋锁和重量级锁的使用都要结合实际场景。在高负载、高并发的场景下,我们可以通过设置 JVM 参数来关闭自旋锁,优化系统性能,示例代码如下:
-XX:-UseSpinning //参数关闭自旋锁优化(默认打开)-XX:PreBlockSpin //参数修改默认的自旋次数。JDK1.7后,去掉此参数,由jvm控制
(2)减小锁粒度
当锁对象是一个数组或队列时,集中竞争一个对象的话会非常激烈,锁也会升级为重量级锁。我们可以考虑将一个数组和队列对象拆成多个小对象,来降低锁竞争,提升并行度。
最经典的减小锁粒度的案例就是 JDK1.8 之前实现的 ConcurrentHashMap 版本。我们知道,HashTable 是基于一个数组 + 链表实现的,所以在并发读写操作集合时,存在激烈的锁资源竞争,也因此性能会存在瓶颈。而 ConcurrentHashMap 就很很巧妙地使用了分段锁 Segment 来降低锁资源竞争。
①锁分离
与传统锁不同的是,读写锁实现了锁分离,也就是说读写锁是由“读锁”和“写锁”两个锁实现的,其规则是可以共享读,但只有一个写。
这样做的好处是,在多线程读的时候,读读是不互斥的,读写是互斥的,写写是互斥的。而传统的独占锁在没有区分读写锁的时候,读写操作一般是:读读互斥、读写互斥、写写互斥。所以在读远大于写的多线程场景中,锁分离避免了在高并发读情况下的资源竞争,从而避免了上下文切换。
②锁分段
在使用锁来保证集合或者大对象原子性时,可以考虑将锁对象进一步分解。例如 ConcurrentHashMap 就使用了锁分段。
(3)减少锁的持有时间
锁的持有时间越长,就意味着有越多的线程在等待该竞争资源释放。如果是 Synchronized 同步锁资源,就不仅是带来线程间的上下文切换,还有可能会增加进程间的上下文切换。
优化前
public synchronized void mySyncMethod(){businesscode1();mutextMethod();businesscode2();}
优化后
public void mySyncMethod(){businesscode1();synchronized(this){mutextMethod();}businesscode2();}
(4)使用读写分离锁代替独占锁
使用ReadWriteLock读写分离锁可以提高系统性能, 使用读写分离 锁也是减小锁粒度的一种特殊情况. 第二条建议是能分割数据结构 实现减小锁的粒度,那么读写锁是对系统功能点的分割. 在多数情况下都允许多个线程同时读,在写的使用采用独占锁,在 读多写少的情况下,使用读写锁可以大大提高系统的并发能力
(5)粗锁化
为了保证多线程间的有效并发,会要求每个线程持有锁的时间尽 量短.但是凡事都有一个度,如果对同一个锁不断的进行请求,同步和 释放,也会消耗系统资源.如:
public void method1(){synchronized( lock ){同步代码块 1}synchronized( lock ){同步代码块 2}}
JVM 在遇到一连串不断对同一个锁进行请求和释放操作时,会把所 有的锁整合成对锁的一次请求,从而减少对锁的请求次数,这个操作叫 锁的粗化,如上一段代码会整合为:
public void method1(){synchronized( lock ){同步代码块 1同步代码块 2}}
在开发过程中,也应该有意识的在合理的场合进行锁的粗化,尤其 在循环体内请求锁时,如:
for(int i = 0 ; i< 100; i++){synchronized(lock){}}
这种情况下,意味着每次循环都需要申请锁和释放锁,所以一种更 合理的做法就是在循环外请求一次锁,如:
synchronized( lock ){for(int i = 0 ; i< 100; i++){}}
2.使用乐观锁
在读大于写的场景下,读写锁 ReentrantReadWriteLock、StampedLock 以及乐观锁的读写性能是最好的;在写大于读的场景下,乐观锁的性能是最好的,其它 4 种锁的性能则相差不多;在读和写差不多的场景下,两种读写锁以及乐观锁的性能要优于 Synchronized 和 ReentrantLock。
乐观锁虽然去除了锁操作,但是一旦发生冲突,重试的成本非常高。所以,只有在冲突概率 非常低,且加锁成本较高时,才考虑使用乐观锁。
3.减少上下文切换
(1)检测与避免
多线程的上下文切换会导致速度的损失。一般在单个逻辑比较简单,而且速度相对来非常快的情况下可以使用单线程。例如Redis,从内存中快速读取值,不用考虑 I/O 瓶颈带来的阻塞问题。而在逻辑相对来说很复杂的场景,等待时间相对较长又或者是需要大量计算的场景,建议使用多线程来提高系统的整体性能。例如,NIO 时期的文件读写操作、图像处理以及大数据分析等。
在 Linux 系统下,可以使用 Linux 内核提供的 vmstat 命令,来监视 Java 程序运行过程中系统的上下文切换频率,cs 如下图所示:
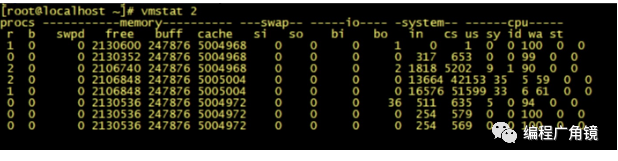
如果是监视某个应用的上下文切换,就可以使用 pidstat 命令监控指定进程的 Context Switch 上下文切换。
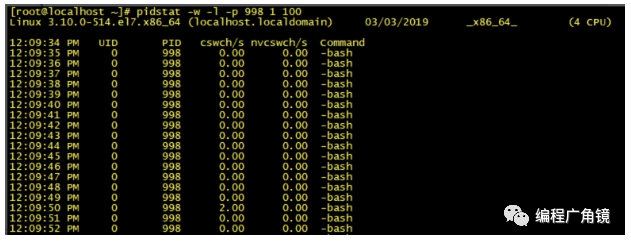
(2)wait/notify 的使用导致了较多的上下文切换
4.合理地设置线程池大小,避免创建过多线程
线程池的线程数量设置不宜过大,因为一旦线程池的工作线程总数超过系统所拥有的处理器数量,就会导致过多的上下文切换。并且服务器CPU核数有限,能够同时并发的线程数有限。
还有一种情况就是,在有些创建线程池的方法里,线程数量设置不会直接暴露给我们。比如,用 Executors.newCachedThreadPool() 创建的线程池,该线程池会复用其内部空闲的线程来处理新提交的任务,如果没有,再创建新的线程(不受 MAX_VALUE 限制),这样的线程池如果碰到大量且耗时长的任务场景,就会创建非常多的工作线程,从而导致频繁的上下文切换。因此,这类线程池就只适合处理大量且耗时短的非阻塞任务。
N核服务器,通过执行业务的单线程分析出本地计算时间为x,等待时间为y,则工作线程数(线程池线程数)设置为 N*(x+y)/x,能让CPU的利用率最大化。
一般来说,非CPU密集型的业务(加解密、压缩解压缩、搜索排序等业务是CPU密集型的业务),瓶颈都在后端数据库访问或者RPC调用,本地CPU计算的时间很少,所以设置几十或者几百个工作线程是能够提升吞吐量的。
根据实际的测试发现,减少线程等待时间对提升性能的影响没有想象得那么大,它并不是线性的提升关系。 真正对性能有影响的是 CPU 的执行时间。这也很好理解,因为 CPU 的执行真正消耗了服务器的资源。经过实际的测试,如果减少 CPU 一半的执行时间,就可以增加一倍的 QPS。 也就是说,应该致力于减少 CPU 的执行时间。
5.使用协程实现非阻塞等待——协程不适合计算密集型的场景。协程适合I/O 阻塞型
(1)如何通过切换请求实现高并发?
我们知道,主机上资源有限,一颗 CPU、一块磁盘、一张网卡,如何同时服务上百个请求呢?多进程模式是最初的解决方案。内核把 CPU 的执行时间切分成许多时间片(timeslice),比如 1 秒钟可以切分为 100 个 10 毫秒的时间片,每个时间片再分发给不同的进程,通常,每个进程需要多个时间片才能完成一个请求。这样,虽然微观上,比如说就这 10 毫秒时间 CPU 只能执行一个进程,但宏观上 1 秒钟执行了 100 个时间片,于是每个时间片所属进程中的请求也得到了执行,这就实现了请求的并发执行。
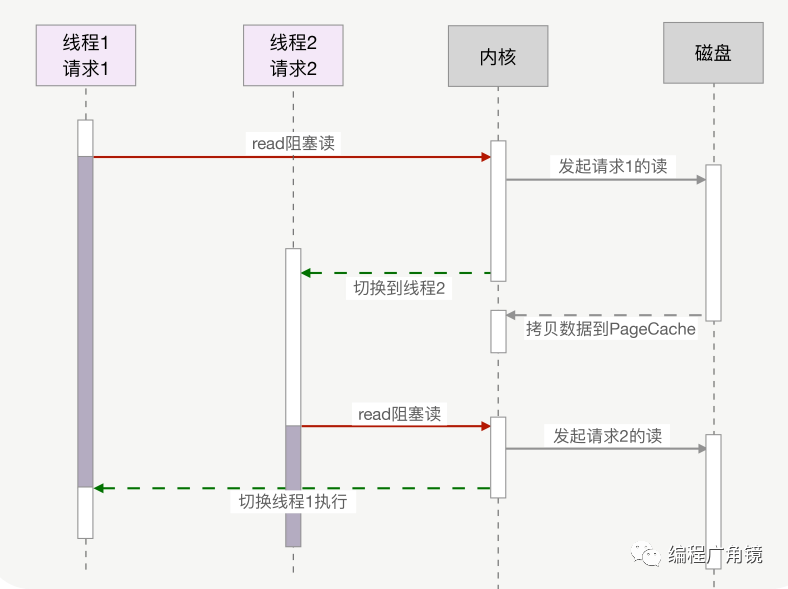
不过,每个进程的内存空间都是独立的,这样用多进程实现并发就有两个缺点:一是内核的管理成本高,二是无法简单地通过内存同步数据,很不方便。于是,多线程模式就出现了,多线程模式通过共享内存地址空间,解决了这两个问题。然而,共享地址空间虽然可以方便地共享对象,但这也导致一个问题,那就是任何一个线程出错时,进程中的所有线程会跟着一起崩溃。这也是如 Nginx 等强调稳定性的服务坚持使用多进程模式的原因。事实上,无论基于多进程还是多线程,都难以实现高并发,这由两个原因所致。首先,单个线程消耗的内存过多,比如,64 位的 Linux 为每个线程的栈分配了 8MB 的内存,还预分配了 64MB 的内存作为堆内存池。所以,我们没有足够的内存去开启几万个线程实现并发。其次,切换请求是内核通过切换线程实现的,什么时候会切换线程呢?不只时间片用尽,当调用阻塞方法时,内核为了让 CPU 充分工作,也会切换到其他线程执行。一次上下文切换的成本在几十纳秒到几微秒间,当线程繁忙且数量众多时,这些切换会消耗绝大部分的 CPU 运算能力。
下图以上一讲介绍过的磁盘 IO 为例,描述了多线程中使用阻塞方法读磁盘,2 个线程间的切换方式。
那么,怎么才能实现高并发呢?把上图中本来由内核实现的请求切换工作,交由用户态的代码来完成就可以了,异步化编程通过应用层代码实现了请求切换,降低了切换成本和内存占用空间。异步化依赖于 IO 多路复用机制,比如 Linux 的 epoll 或者 Windows 上的 iocp,同时,必须把阻塞方法更改为非阻塞方法,才能避免内核切换带来的巨大消耗。Nginx、Redis 等高性能服务都依赖异步化实现了百万量级的并发。下图描述了异步 IO 的非阻塞读和异步框架结合后,是如何切换请求的。
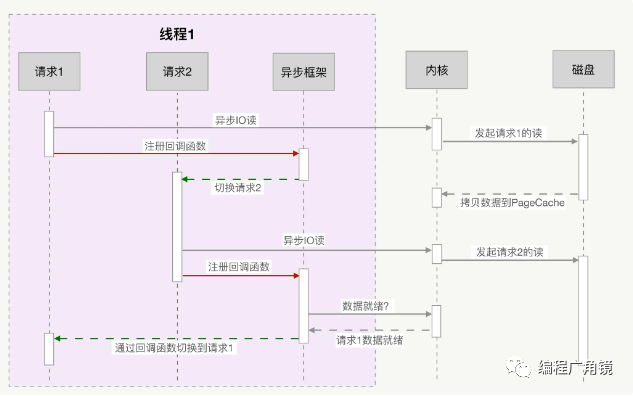
然而,写异步化代码很容易出错。因为所有阻塞函数,都需要通过非阻塞的系统调用拆分成两个函数。虽然这两个函数共同完成一个功能,但调用方式却不同。第一个函数由你显式调用,第二个函数则由多路复用机制调用。这种方式违反了软件工程的内聚性原则,函数间同步数据也更复杂。特别是条件分支众多、涉及大量系统调用时,异步化的改造工作会非常困难。有没有办法既享受到异步化带来的高并发,又可以使用阻塞函数写同步化代码呢?协程可以做到,它在异步化之上包了一层外衣,兼顾了开发效率与运行效率。
(2)协程是如何实现高并发的?
协程与异步编程相似的地方在于,它们必须使用非阻塞的系统调用与内核交互,把切换请求的权力牢牢掌握在用户态的代码中。但不同的地方在于,协程把异步化中的两段函数,封装为一个阻塞的协程函数。这个函数执行时,会使调用它的协程无感知地放弃执行权,由协程框架切换到其他就绪的协程继续执行。当这个函数的结果满足后,协程框架再选择合适的时机,切换回它所在的协程继续执行。如下图所示:
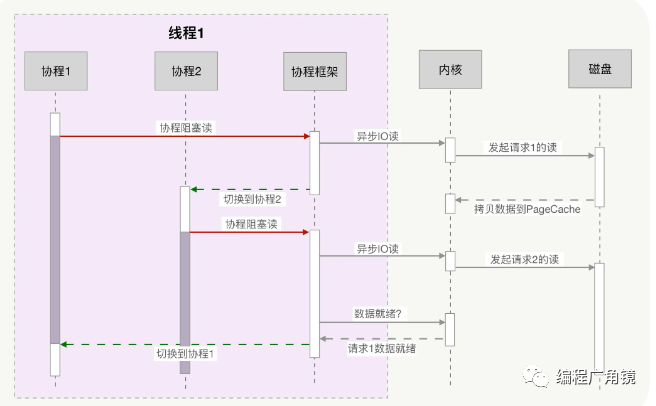
看起来非常棒,然而,异步化是通过回调函数来完成请求切换的,业务逻辑与并发实现关联在一起,很容易出错。协程不需要什么“回调函数”,它允许用户调用“阻塞的”协程方法,用同步编程方式写业务逻辑。那协程的切换是如何完成的呢?
实际上,用户态的代码切换协程,与内核切换线程的原理是一样的。内核通过管理 CPU 的寄存器来切换线程,我们以最重要的栈寄存器和指令寄存器为例,看看协程切换时如何切换程序指令与内存。每个线程有独立的栈,而栈既保留了变量的值,也保留了函数的调用关系、参数和返回值,CPU 中的栈寄存器 SP 指向了当前线程的栈,而指令寄存器 IP 保存着下一条要执行的指令地址。因此,从线程 1 切换到线程 2 时,首先要把 SP、IP 寄存器的值为线程 1 保存下来,再从内存中找出线程 2 上一次切换前保存好的寄存器值,写入 CPU 的寄存器,这样就完成了线程切换。(其他寄存器也需要管理、替换,原理与此相同,不再赘述。)协程的切换与此相同,只是把内核的工作转移到协程框架实现而已,下图是协程切换前的状态:
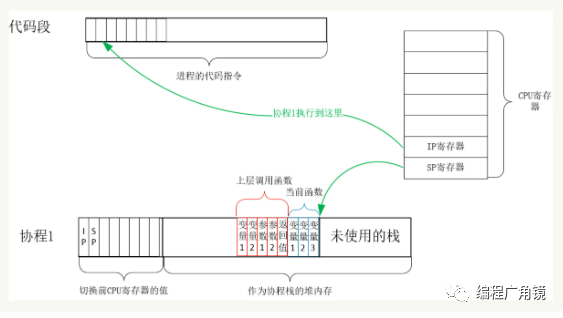
从协程 1 切换到协程 2 后的状态如下图所示:
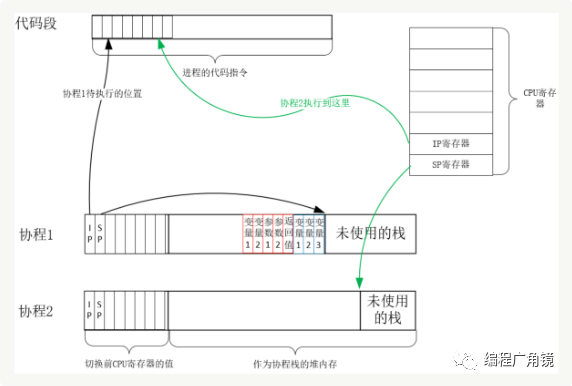
创建协程时,会从进程的堆中分配一段内存作为协程的栈。线程的栈有 8MB(太大,导致单机无法实现高并发的原因),而协程栈的大小通常只有几十 KB。而且,C 库内存池也不会为协程预分配内存,它感知不到协程的存在。这样,更低的内存占用空间为高并发提供了保证,毕竟十万并发请求,就意味着 10 万个协程。当然,栈缩小后,就尽量不要使用递归函数,也不能在栈中申请过多的内存,这是实现高并发必须付出的代价。
由此可见,协程就是用户态的线程。然而,为了保证所有切换都在用户态进行,协程必须重新封装所有的阻塞系统调用,否则,一旦协程触发了线程切换,会导致这个线程进入休眠状态,进而其上的所有协程都得不到执行。比如,普通的 sleep 函数会让当前线程休眠,由内核来唤醒线程,而协程化改造后,sleep 只会让当前协程休眠,由协程框架在指定时间后唤醒协程。再比如,线程间的互斥锁是使用信号量实现的,而信号量也会导致线程休眠,协程化改造互斥锁后,同样由框架来协调、同步各协程的执行。
所以,协程的高性能,建立在切换必须由用户态代码完成之上,这要求协程生态是完整的,要尽量覆盖常见的组件。比如 MySQL 官方提供的客户端 SDK,它使用了阻塞 socket 做网络访问,会导致线程休眠,必须用非阻塞 socket 把 SDK 改造为协程函数后,才能在协程中使用。当然,并不是所有的函数都能用协程改造。比如提到的异步 IO,它虽然是非阻塞的,但无法使用 PageCache,降低了系统吞吐量。如果使用缓存 IO 读文件,在没有命中 PageCache 时是可能发生阻塞的。这种时候,如果对性能有更高的要求,就需要把线程与协程结合起来用,把可能阻塞的操作放在线程中执行,通过生产者 / 消费者模型与协程配合工作。实际上,面对多核系统,也需要协程与线程配合工作。因为协程的载体是线程,而一个线程同一时间只能使用一颗 CPU,所以通过开启更多的线程,将所有协程分布在这些线程中,就能充分使用 CPU 资源。
除此之外,为了让协程获得更多的 CPU 时间,还可以设置所在线程的优先级,比如 Linux 下把线程的优先级设置到 -20,就可以每次获得更长的时间片。另外,为了减少 CPU 缓存失效的比例,还可以把线程绑定到某个 CPU 上,增加协程执行时命中 CPU 缓存的机率。虽然这一讲中谈到协程框架在调度协程,然而,你会发现,很多协程库只提供了创建、挂起、恢复执行等基本方法,并没有协程框架的存在,需要业务代码自行调度协程。这是因为,这些通用的协程库并不是专为服务器设计的。服务器中可以由客户端网络连接的建立,驱动着创建出协程,同时伴随着请求的结束而终止。在协程的运行条件不满足时,多路复用框架会将它挂起,并根据优先级策略选择另一个协程执行。因此,使用协程实现服务器端的高并发服务时,并不只是选择协程库,还要从其生态中找到结合 IO 多路复用的协程框架,这样可以加快开发速度。
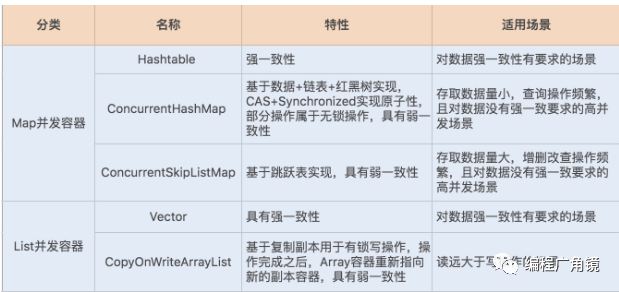
6.识别不同场景下最优容器
7.串行变并行
串行的逻辑,在没有依赖限制的情况下,可以并行执行。后端的逻辑如果需 要执行多项操作,那么如果没有依赖,或者依赖项满足的情况下,可以立即执行,而不必一 个一个挨个等待依次完成。Spring 的@Async 注解,可以比较方便地将普通的 Java 方 法调用变成异步进行的,用这种方法可以同时执行数个互不依赖的方法。
8.避免使用多线程
业务中使用多线程(有别于Tomcat这种容器中间件)是为了提高并发能力,或者是异步化业务能力。而这两种都有其他的方案来替代。比如高并发,我们可能会进行一些拆分操作,比如异步化消息队列,会使用消息队列等。尽量不使用多线程,除非是必须
四、BitSet和BitMap
1.BitSet简介
(1)什么是BitSet
可以减少大数据量的内存的消耗
BitSet类实现了一个按需增长的位向量。位Set的每一个组件都有一个boolean值。用非负的整数将BitSet的位编入索引。可以对每个编入索引的位进行测试、设置或者清除。通过逻辑与、逻辑或和逻辑异或操作,可以使用一个 BitSet修改另一个 BitSet的内容。
默认情况下,set 中所有位的初始值都是false。
每个位 set 都有一个当前大小,也就是该位 set 当前所用空间的位数。注意,这个大小与位 set 的实现有关,所以它可能随实现的不同而更改。位 set 的长度与位 set 的逻辑长度有关,并且是与实现无关而定义的。
(2)BitSet是如何存储的?
比如有一堆数字,需要存储,source[3,5,6,9]
用int就需要4*4个字节。
java.util.BitSet可以存true/false。
如果用java.util.BitSet,则会少很多,其原理是:
-
先找出数据中最大值maxvalue=9
-
声明一个BitSet bs,它的size是maxvalue+1=10
-
遍历数据source,bs[source[i]]设置成true.
最后的值是:
(0为false;1为true)
bs [0,0,0,1,0,1,1,0,0,1]
3, 5,6, 9
这样一个本来要int型需要占4字节共32位的数字现在只用了1位!
比例32:1
这样就省下了很大空间。
(3)应用场景
①统计一组大数据中没有出现过的数;
将这组数据映射到BitSet,然后遍历BitSet,对应位为0的数表示没有出现过的数据。
②对大数据进行排序;
将数据映射到BitSet,遍历BitSet得到的就是有序数据。
③在内存对大数据进行压缩存储等等。
一个GB的内存空间可以存储85亿多个数,可以有效实现数据的压缩存储,节省内存空间开销。
2.方法详解
(1)构造函数
BitSet() 创建一个新的位 set。
BitSet(int nbits) 创建一个位 set,它的初始大小足以显式表示索引范围在 0 到 nbits-1 的位。
注意:
(1)如果指定了bitset的初始化大小,那么会把他规整到一个大于或者等于这个数字的64的整倍数。比如64位,bitset的大小是1个long,而65位时,bitset大小是2个long,即128位。做这么一个规定,主要是为了内存对齐,同时避免考虑到不要处理特殊情况,简化程序。
(2)常用方法案例演示
①大数据中没出现过的数
有1千万个随机数,随机数的范围在1到1亿之间。现在要求写出一种算法,将1到1亿之间没有在随机数中的数求出来?
public class Alibaba{public static void main(String[] args){Random random=new Random();List<Integer> list=new ArrayList<>();for(int i=0;i<10000000;i++){int randomResult=random.nextInt(100000000);list.add(randomResult);}System.out.println("产生的随机数有");for(int i=0;i<list.size();i++){System.out.println(list.get(i));}BitSet bitSet=new BitSet(100000000);for(int i=0;i<10000000;i++){bitSet.set(list.get(i));}System.out.println("0~1亿不在上述随机数中有"+bitSet.size());for (int i = 0; i < 100000000; i++){if(!bitSet.get(i)){System.out.println(i);}}}}
②大数量计算素数
step1:开辟指定大小的位集空间;
step2:将所有位置true;
step3:将已知素数的倍数所对应的位置false。
public class ComputeSieve {public static void main(String[] args) {int n = 100;BitSet b = new BitSet(n + 1);int i;for(i = 2; i <= n; i++){b.set(i);}i = 2;while(i * i <= n){if(b.get(i)){int k = 2 * i;while(k <=n){b.clear(k);k += i;}}i++;}i = 0;while(i <= n){if(b.get(i)){System.out.println(i);}i++;}}}
五、让linux变得更快的代码
1.让CPU执行得更快的代码
任何代码的执行都依赖 CPU,通常,使用好 CPU 是操作系统内核的工作。然而,当我们编 写计算密集型的程序时,CPU 的执行效率就开始变得至关重要。由于 CPU 缓存由更快的 SRAM 构成(内存是由 DRAM 构成的),而且离 CPU 核心更近,如果运算时需要的输入 数据是从 CPU 缓存,而不是内存中读取时,运算速度就会快很多。
(1)CPU 的多级缓存
CPU 缓存离 CPU 核心更近,由于电子信号传输是需要时间的,所以离 CPU 核心越近,缓存的读写速度就越快。但 CPU 的空间很狭小,离 CPU 越近缓存大小受 到的限制也越大。所以,综合硬件布局、性能等因素,CPU 缓存通常分为大小不等的三级 缓存。 CPU 缓存的材质 SRAM 比内存使用的 DRAM 贵许多,所以不同于内存动辄以 GB 计算, 它的大小是以 MB 来计算的。比如在 Linux 系统上,离 CPU 最近的一级缓存是 32KB,二级缓存是 256KB,最大的三级缓存则是 20MB(Windows 系统查看缓存大小可 以用 wmic cpu 指令,或者用CPU-Z这个工具)。

CPU 都是多核心 的,每个核心都有自己的一、二级缓存,但三级缓存却是一颗 CPU 上所有核心共享的。程序执行时,会先将内存中的数据载入到共享的三级缓存中,再进入每颗核心独有的二级缓 存,最后进入最快的一级缓存,之后才会被 CPU 使用。

缓存存要比内存快很多。CPU 访问一次内存通常需要 100 个时钟周期以上,而访问一级缓存 只需要 4~5 个时钟周期,二级缓存大约 12 个时钟周期,三级缓存大约 30 个时钟周期 (对于 2GHZ 主频的 CPU 来说,一个时钟周期是 0.5 纳秒。
如果 CPU 所要操作的数据在缓存中,则直接读取,这称为缓存命中。命中缓存会带来很大 的性能提升,因此代码优化目标是提升 CPU 缓存的命中率。
当然,缓存命中率是很笼统的,具体优化时还得一分为二。比如,你在查看 CPU 缓存时会 发现有 2 个一级缓存(比如 Linux 上就是上图中的 index0 和 index1),这是因为,CPU 会区别对待指令与数据。比如,“1+1=2”这个运算,“+”就是指令,会放在一级指令缓 存中,而“1”这个输入数字,则放在一级数据缓存中。虽然在冯诺依曼计算机体系结构 中,代码指令与数据是放在一起的,但执行时却是分开进入指令缓存与数据缓存的,因此要分开来看二者的缓存命中率。
(2)提升数据缓存的命中率
for(i = 0; i < N; i+=1) {for(j = 0; j < N; j+=1) {array[i][j] = 0;}}
array[j][i]执行的时间是后者 array[i] [j]的 8 倍之多。因为二维数组 array 所占用的内存是连续的,比如若长度 N 的值为 2,那么内存中从前至后各元素的顺序是:
array[0][0],array[0][1],array[1][0],array[1][1]。如果用 array[i][j]访问数组元素,则完全与上述内存中元素顺序一致,因此访问 array[0][0] 时,缓存已经把紧随其后的 3 个元素也载入了,CPU 通过快速的缓存来读取后续 3 个元素 就可以。如果用 array[j][i]来访问,访问的顺序就是:
array[0][0],array[1][0],array[0][1],array[1][1]此时内存是跳跃访问的,如果 N 的数值很大,那么操作 array[j][i]时,是没有办法把 array[j+1][i]也读入缓存的。遇到这种遍历访问数组的情况时,按照内存布局顺序访问将会带来很大的性能提升。
(3)提升指令缓存的命中率
比如,有一个元素为 0 到 255 之间随机数字组成的数组。接下来要对它做两个操作:一是循环遍历数组,判断每个数字是否小于 128,如果小于则 把元素的值置为 0;二是将数组排序。那么,先排序再遍历速度快,还是先遍历再排序速度 快呢?
接下来要对它做两个操作:一是循环遍历数组,判断每个数字是否小于 128,如果小于则 把元素的值置为 0;二是将数组排序。那么,先排序再遍历速度快,还是先遍历再排序速度 快呢?
当代码中出现 if、switch 等语句时,意味着此时至少可以选择跳转到两段不同的指令去执 行。如果分支预测器可以预测接下来要在哪段代码执行(比如 if 还是 else 中的指令),就 可以提前把这些指令放在缓存中,CPU 执行时就会很快。当数组中的元素完全随机时,分 支预测器无法有效工作,而当 array 数组有序时,分支预测器会动态地根据历史命中数据对 未来进行预测,命中率就会非常高。
(4)提升多核 CPU 下的缓存命中率
虽然三级缓存面向所有核心,但一、二级缓存是每颗核心独享的。我们知道,即使只有一个 CPU 核心,现代分时操作系统都支持许多进程同时运行。这是因为操作系统把时间切成了 许多片,微观上各进程按时间片交替地占用 CPU,这造成宏观上看起来各程序同时在执 行。
因此,若进程 A 在时间片 1 里使用 CPU 核心 1,自然也填满了核心 1 的一、二级缓存, 当时间片 1 结束后,操作系统会让进程 A 让出 CPU,基于效率并兼顾公平的策略重新调度 CPU 核心 1,以防止某些进程饿死。如果此时 CPU 核心 1 繁忙,而 CPU 核心 2 空闲,则 进程 A 很可能会被调度到 CPU 核心 2 上运行,这样,即使我们对代码优化得再好,也只能在一个时间片内高效地使用 CPU 一、二级缓存了,下一个时间片便面临着缓存效率的问 题。 因此,操作系统提供了将进程或者线程绑定到某一颗 CPU 上运行的能力。如 Linux 上提供 了 sched_setaffinity 方法实现这一功能,其他操作系统也有类似功能的 API 可用。
当多线程同时执行密集计 算,且 CPU 缓存命中率很高时,如果将每个线程分别绑定在不同的 CPU 核心上,性能便 会获得非常可观的提升。Perf 工具也提供了 cpu-migrations 事件,它可以显示进程从不 同的 CPU 核心上迁移的次数。
2.内存池
当代码申请内存时,首先会到达应用层内存池,如果应用层内存池有足够的可用内存,就会 直接返回给业务代码,否则,它会向更底层的 C 库内存池申请内存。比如,如果你在 Apache、Nginx 等服务之上做模块开发,这些服务中就有独立的内存池。当然,Java 中 也有内存池,当通过启动参数 Xmx 指定 JVM 的堆内存为 8GB 时,就设定了 JVM 堆内存 池的大小。 你可能听说过 Google 的 TCMalloc 和 FaceBook 的 JEMalloc,它们也是 C 库内存池。 当 C 库内存池无法满足内存申请时,才会向操作系统内核申请分配内存。
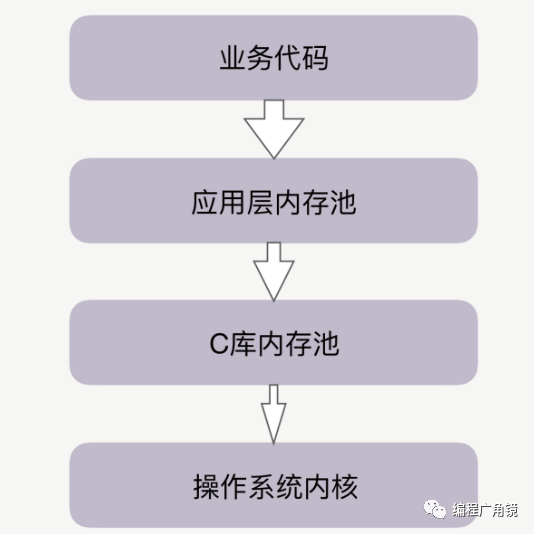
Java 已经有了应用层内存池,为什么还会受到 C 库内存池的影响 呢?这是因为,除了 JVM 负责管理的堆内存外,Java 还拥有一些堆外内存,由于它不使用 JVM 的垃圾回收机制,所以更稳定、持久,处理 IO 的速度也更快。这些堆外内存就会由 C 库内存池负责分配,这是 Java 受到 C 库内存池影响的原因。
C 库内存池影响着系 统下依赖它的所有进程。我们就以 Linux 系统的默认 C 库内存池 Ptmalloc2 来具体分析, 看看它到底对性能发挥着怎样的作用。 C 库内存池工作时,会预分配比你申请的字节数更大的空间作为内存池。比如说,当主进程 下申请 1 字节的内存时,Ptmalloc2 会预分配 132K 字节的内存(Ptmalloc2 中叫 Main Arena),应用代码再申请内存时,会从这已经申请到的 132KB 中继续分配。
当我们释放这 1 字节时,Ptmalloc2 也不会把内存归还给操作系统。Ptmalloc2 认为,与 其把这 1 字节释放给操作系统,不如先缓存着放进内存池里,仍然当作用户态内存留下 来,进程再次申请 1 字节的内存时就可以直接复用,这样速度快了很多。 你可能会想,132KB 不多呀?为什么这一讲开头提到的 Java 进程,会被分配了几个 GB 的 内存池呢?这是因为多线程与单线程的预分配策略并不相同。
当释放这 1 字节时,Ptmalloc2 也不会把内存归还给操作系统。Ptmalloc2 认为,与 其把这 1 字节释放给操作系统,不如先缓存着放进内存池里,仍然当作用户态内存留下 来,进程再次申请 1 字节的内存时就可以直接复用,这样速度快了很多。 你可能会想,132KB 不多呀?为什么这一讲开头提到的 Java 进程,会被分配了几个 GB 的 内存池呢?这是因为多线程与单线程的预分配策略并不相同。
Linux 下的 JVM 编译时默认使用了 Ptmalloc2 内存池,因此每个线 程都预分配了 64MB 的内存,这造成含有上百个 Java 线程的 JVM 多使用了 6GB 的内 存。在多数情况下,这些预分配出来的内存池,可以提升后续内存分配的性能。 然而,Java 中的 JVM 内存池已经管理了绝大部分内存,确实不能接受莫名多出来 6GB 的 内存,那该怎么办呢?有两种解决办法。
首先可以调整 Ptmalloc2 的工作方式。通过设置 MALLOC_ARENA_MAX 环境变量,可 以限制线程内存池的最大数量,当然,线程内存池的数量减少后,会影响 Ptmalloc2 分配 内存的速度。不过由于 Java 主要使用 JVM 内存池来管理对象,这点影响并不重要。 其次可以更换掉 Ptmalloc2 内存池,选择一个预分配内存更少的内存池,比如 Google 的 TCMalloc。
六、JMH
1.JMH 简介
JMH(Java Microbenchmark Harness)是用于代码微基准测试的工具套件,主要是基于方法层面的基准测试,精度可以达到纳秒级。当你定位到热点方法,希望进一步优化方法性能的时候,就可以使用 JMH 对优化的结果进行量化的分析。JMH 比较典型的应用场景如下:
-
想准确地知道某个方法需要执行多长时间,以及执行时间和输入之间的相关性
-
对比接口不同实现在给定条件下的吞吐量
-
查看多少百分比的请求在多长时间内完成
2.案例演示
下面以字符串拼接的两种方法为例子使用 JMH 做基准测试。
(1)引入依赖
加入依赖因为 JMH 是 JDK9 自带的,如果是 JDK9 之前的版本需要加入如下依赖(目前 JMH 的最新版本为
1.23):
<dependency><groupId>org.openjdk.jmh</groupId><artifactId>jmh-core</artifactId><version>1.23</version></dependency><dependency><groupId>org.openjdk.jmh</groupId><artifactId>jmh-generator-annprocess</artifactId><version>1.23</version></dependency>
(2)测试类
编写基准测试接下来,创建一个 JMH 测试类,用来判断 + 和 StringBuilder.append() 两种字符串拼接哪个耗时更短,具体代码如下所示:
@BenchmarkMode(Mode.AverageTime)@Warmup(iterations = 3, time = 1)@Measurement(iterations = 5, time = 5)@Threads(4)@Fork(1)@State(value = Scope.Benchmark)@OutputTimeUnit(TimeUnit.NANOSECONDS)public class StringConnectTest {@Param(value = {"10", "50", "100"})private int length;@Benchmarkpublic void testStringAdd(Blackhole blackhole) {String a = "";for (int i = 0; i < length; i++) {a += i;}blackhole.consume(a);}@Benchmarkpublic void testStringBuilderAdd(Blackhole blackhole) {StringBuilder sb = new StringBuilder();for (int i = 0; i < length; i++) {sb.append(i);}blackhole.consume(sb.toString());}public static void main(String[] args) throws RunnerException {Options opt = new OptionsBuilder().include(StringConnectTest.class.getSimpleName()).result("result.json").resultFormat(ResultFormatType.JSON).build();new Runner(opt).run();}}
在 main() 函数中,首先对测试用例进行配置,使用 Builder 模式配置测试,将配置参数存入 Options 对象,并使用 Options 对象构造 Runner 启动测试。另外大家可以看下官方提供的 jmh 示例 demo:
http://hg.openjdk.java.net/code-tools/jmh/file/tip/jmh-samples/src/main/java/org/openjdk/jmh/samples/
(3)执行基准测试
准备工作做好了,接下来,运行代码,等待片刻,测试结果就出来了,下面对结果做下简单说明:
# JMH version: 1.23# VM version: JDK 1.8.0_201, Java HotSpot(TM) 64-Bit Server VM, 25.201-b09# VM invoker: D:\Software\Java\jdk1.8.0_201\jre\bin\java.exe# VM options: -javaagent:D:\Software\JetBrains\IntelliJ IDEA 2019.1.3\lib\idea_rt.jar=61018:D:\Software\JetBrains\IntelliJ IDEA 2019.1.3\bin -Dfile.encoding=UTF-8# Warmup: 3 iterations, 1 s each# Measurement: 5 iterations, 5 s each# Timeout: 10 min per iteration# Threads: 4 threads, will synchronize iterations# Benchmark mode: Average time, time/op# Benchmark: com.wupx.jmh.StringConnectTest.testStringBuilderAdd# Parameters: (length = 100)
该部分为测试的基本信息,比如使用的 Java 路径,预热代码的迭代次数,测量代码的迭代次数,使用的线程数量,测试的统计单位等。
# Warmup Iteration 1: 1083.569 ±(99.9%) 393.884 ns/op# Warmup Iteration 2: 864.685 ±(99.9%) 174.120 ns/op# Warmup Iteration 3: 798.310 ±(99.9%) 121.161 ns/op
该部分为每一次热身中的性能指标,预热测试不会作为最终的统计结果。预热的目的是让 JVM 对被测代码进行足够多的优化,比如,在预热后,被测代码应该得到了充分的 JIT 编译和优化。
Iteration 1: 810.667 ±(99.9%) 51.505 ns/opIteration 2: 807.861 ±(99.9%) 13.163 ns/opIteration 3: 851.421 ±(99.9%) 33.564 ns/opIteration 4: 805.675 ±(99.9%) 33.038 ns/opIteration 5: 821.020 ±(99.9%) 66.943 ns/opResult "com.wupx.jmh.StringConnectTest.testStringBuilderAdd":819.329 ±(99.9%) 72.698 ns/op [Average](min, avg, max) = (805.675, 819.329, 851.421), stdev = 18.879CI (99.9%): [746.631, 892.027] (assumes normal distribution)Benchmark (length) Mode Cnt Score Error UnitsStringConnectTest.testStringBuilderAdd 100 avgt 5 819.329 ± 72.698 ns/op
该部分显示测量迭代的情况,每一次迭代都显示了当前的执行速率,即一个操作所花费的时间。在进行 5 次迭代后,进行统计,在本例中,length 为 100 的情况下 testStringBuilderAdd 方法的平均执行花费时间为
819.329 ns,误差为 72.698 ns。
最后的测试结果如下所示:
Benchmark (length) Mode Cnt Score Error UnitsStringConnectTest.testStringAdd 10 avgt 5 161.496 ± 17.097 ns/opStringConnectTest.testStringAdd 50 avgt 5 1854.657 ± 227.902 ns/opStringConnectTest.testStringAdd 100 avgt 5 6490.062 ± 327.626 ns/opStringConnectTest.testStringBuilderAdd 10 avgt 5 68.769 ± 4.460 ns/opStringConnectTest.testStringBuilderAdd 50 avgt 5 413.021 ± 30.950 ns/opStringConnectTest.testStringBuilderAdd 100 avgt 5 819.329 ± 72.698 ns/op
结果表明,在拼接字符次数越多的情况下,
StringBuilder.append() 的性能就更好。
(4)生成 jar 包执行
对于一些小测试,直接用上面的方式写一个 main 函数手动执行就好了。对于大型的测试,需要测试的时间比较久、线程数比较多,加上测试的服务器需要,一般要放在 Linux 服务器里去执行。JMH 官方提供了生成 jar 包的方式来执行,我们需要在 maven 里增加一个 plugin,具体配置如下:
<plugins><plugin><groupId>org.apache.maven.plugins</groupId><artifactId>maven-shade-plugin</artifactId><version>2.4.1</version><executions><execution><phase>package</phase><goals><goal>shade</goal></goals><configuration><finalName>jmh-demo</finalName><transformers><transformerimplementation="org.apache.maven.plugins.shade.resource.ManifestResourceTransformer"><mainClass>org.openjdk.jmh.Main</mainClass></transformer></transformers></configuration></execution></executions></plugin></plugins>
接着执行 maven 的命令生成可执行 jar 包并执行:
mvn clean installjava -jar target/jmh-demo.jar StringConnectTest
3.JMH 基础
@BenchmarkMode用来配置 Mode 选项,可用于类或者方法上,这个注解的 value 是一个数组,可以把几种 Mode 集合在一起执行,如:@BenchmarkMode({Mode.SampleTime, Mode.AverageTime}),还可以设置为
Mode.All,即全部执行一遍。
-
Throughput:整体吞吐量,每秒执行了多少次调用,单位为 ops/time
-
AverageTime:用的平均时间,每次操作的平均时间,单位为 time/op
-
SampleTime:随机取样,最后输出取样结果的分布
-
SingleShotTime:只运行一次,往往同时把 Warmup 次数设为 0,用于测试冷启动时的性能
-
All:上面的所有模式都执行一次
@State
通过 State 可以指定一个对象的作用范围,JMH 根据 scope 来进行实例化和共享操作。@State 可以被继承使用,如果父类定义了该注解,子类则无需定义。由于 JMH 允许多线程同时执行测试,不同的选项含义如下:
-
Scope.Benchmark:所有测试线程共享一个实例,测试有状态实例在多线程共享下的性能
-
Scope.Group:同一个线程在同一个 group 里共享实例
-
Scope.Thread:默认的 State,每个测试线程分配一个实例
@OutputTimeUnit
为统计结果的时间单位,可用于类或者方法注解
@Warmup
预热所需要配置的一些基本测试参数,可用于类或者方法上。一般前几次进行程序测试的时候都会比较慢,所以要让程序进行几轮预热,保证测试的准确性。参数如下所示:
-
iterations:预热的次数
-
time:每次预热的时间
-
timeUnit:时间的单位,默认秒
-
batchSize:批处理大小,每次操作调用几次方法
为什么需要预热?因为 JVM 的 JIT 机制的存在,如果某个函数被调用多次之后,JVM 会尝试将其编译为机器码,从而提高执行速度,所以为了让 benchmark 的结果更加接近真实情况就需要进行预热。
@Measurement实际调用方法所需要配置的一些基本测试参数,可用于类或者方法上,参数和
@Warmup 相同。
@Threads
每个进程中的测试线程,可用于类或者方法上。
@Fork
进行 fork 的次数,可用于类或者方法上。如果 fork 数是 2 的话,则 JMH 会 fork 出两个进程来进行测试。
@Param
指定某项参数的多种情况,特别适合用来测试一个函数在不同的参数输入的情况下的性能,只能作用在字段上,使用该注解必须定义 @State 注解。
在介绍完常用的注解后,让我们来看下 JMH 有哪些陷阱。
4.JMH 陷阱
在使用 JMH 的过程中,一定要避免一些陷阱。
比如 JIT 优化中的死码消除,比如以下代码:
@Benchmarkpublic void testStringAdd(Blackhole blackhole) {String a = "";for (int i = 0; i < length; i++) {a += i;}}
JVM 可能会认为变量 a 从来没有使用过,从而进行优化把整个方法内部代码移除掉,这就会影响测试结果。JMH 提供了两种方式避免这种问题,一种是将这个变量作为方法返回值 return a,一种是通过 Blackhole 的 consume 来避免 JIT 的优化消除。其他陷阱还有常量折叠与常量传播、永远不要在测试中写循环、使用 Fork 隔离多个测试方法、方法内联、伪共享与缓存行、分支预测、多线程测试等,
5.插件
JMH 插件大家还可以通过 IDEA 安装 JMH 插件使 JMH 更容易实现基准测试,在 IDEA 中点击
File->Settings...->Plugins,然后搜索 jmh,选择安装 JMH plugin:
这个插件可以让我们能够以 JUnit 相同的方式使用 JMH,主要功能如下:
-
自动生成带有 @Benchmark 的方法
-
像 JUnit 一样,运行单独的 Benchmark 方法
-
运行类中所有的 Benchmark 方法比如可以通过右键点击
Generate...,选择操作
Generate JMH benchmark 就可以生成一个带有
@Benchmark 的方法。
还有将光标移动到方法声明并调用 Run 操作就运行一个单独的 Benchmark 方法。将光标移到类名所在行,右键点击 Run 运行,该类下的所有被
@Benchmark 注解的方法都会被执行。
6.JMH 可视化
除此以外,如果你想将测试结果以图表的形式可视化,可以试下这些网站:
-
JMH Visual Chart:http://deepoove.com/jmh-visual-chart/
-
JMH Visualizer:https://jmh.morethan.io/
比如将上面测试例子结果的 json 文件导入,就可以实现可视化: