一、本文介绍
本文给大家带来的改进机制是Damo-YOLO的RepGFPN(重参数化泛化特征金字塔网络),利用其优化YOLOv8的Neck部分,可以在不影响计算量的同时大幅度涨点(亲测在小目标和大目标检测的数据集上效果均表现良好涨点幅度超级高!)。RepGFPN不同于以往提出的改进模块,其更像是一种结构一种思想(一种处理事情的方法),RepGFPN相对于BiFPN和之前的FPN均有一定程度上的优化效果。
适用检测目标:所有的目标检测均有一定的提点
推荐指数:⭐⭐⭐⭐⭐
专栏回顾:YOLOv8改进系列专栏——本专栏持续复习各种顶会内容——科研必备
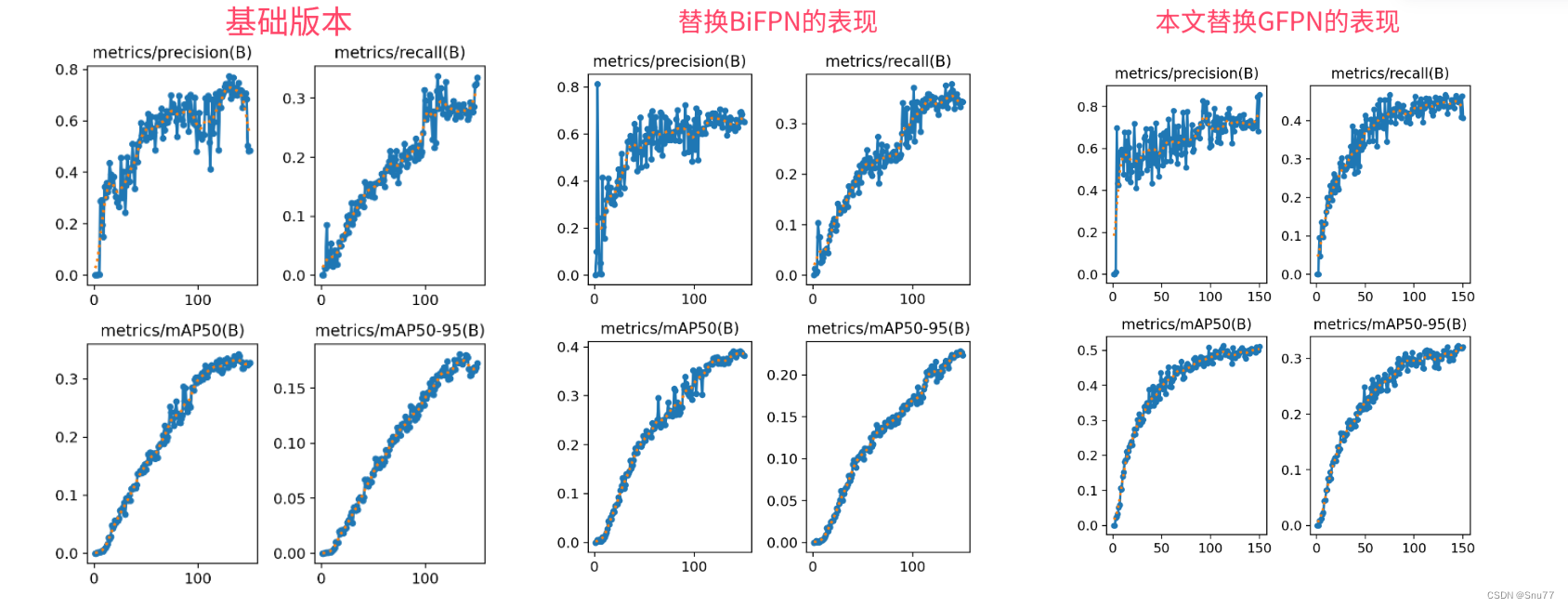
效果回顾展示->
图片分析->在我的数据集上大家可以看到mAP50大概增长了0.12左右这个涨点幅度是非常的高了以及,同时该模块是有二次创新的机会的,后期我会在接下来的文章进行二次创新,希望大家能够尽早关注我的专栏。
目录
一、本文介绍
二、GFPN的框架原理
编辑
三、GFPN的核心代码
四、手把手教你添加GFPN
4.1 修改一
4.2 修改二
五、GFPN的yaml文件
六、成功运行的截图
六、本文总结
二、GFPN的框架原理

官方论文地址: 官方论文地址
官方代码地址: 官方代码地址

RepGFPN(重参数化泛化特征金字塔网络)是DAMO-YOLO框架中用于实时目标检测的新方法。其主要主要原理是:RepGFPN改善了用于目标检测的特征金字塔网络(FPN)的概念,更高效地融合多尺度特征,对于捕捉高层语义和低层空间细节至关重要。
其主要改进机制包括->
- 不同尺度通道:它为不同尺度的特征图采用不同的通道维度,优化了计算资源下的性能。
- 优化的皇后融合机制:该方法通过修改的皇后融合机制增强了特征交互,通过去除额外的上采样操作减少延迟。
- 整合CSPNet和ELAN:它结合了CSPNet和高效层聚合网络(ELAN)以及重参数化,改善了特征融合,而不显著增加计算需求。
总结:RepGFPN更像是一种结构一种思想,其中的模块我们是可以用其它的机制替换的。
下面的图片是Damo-YOLO的网络结构图,其中我用红框标出来的部分就是RepGFPN的路径聚合图。

根据图片我们来说一下GFPN(重参数化特征金字塔网络):作为“颈部(也就是YOLOv8中的neck),用于优化和融合高层语义和低层空间特征。
在左上角的融合块(Fusion Block)中,我们可以看到反复出现的结构单元,它们由多个1x1卷积,一个3x3卷积组成,这些卷积后面通常跟着批量归一化(BN)和激活函数(Act)。这个复合结构在训练时和推理时有所不同,这是通过“简化Rep 3x3”结构来实现的,它在训练时使用3x3卷积,而在推理时则简化为1x1卷积,以提高效率(现在很多结构都使用在何种思想训练时候用复杂的模块,推理时换为简单的模块,这在大家自己的改进中也可以是一种思想)。
三、GFPN的核心代码
下面的代码是GFPN的核心代码,我们将其复制导'ultralytics/nn/modules'目录下,在其中创建一个文件,我这里起名为GFPN然后粘贴进去,其余使用方式看章节四。
import torch
import torch.nn as nn
import numpy as np
class swish(nn.Module):
def forward(self, x):
return x * torch.sigmoid(x)
def autopad(k, p=None, d=1): # kernel, padding, dilation
"""Pad to 'same' shape outputs."""
if d > 1:
k = d * (k - 1) + 1 if isinstance(k, int) else [d * (x - 1) + 1 for x in k] # actual kernel-size
if p is None:
p = k // 2 if isinstance(k, int) else [x // 2 for x in k] # auto-pad
return p
class Conv(nn.Module):
"""Standard convolution with args(ch_in, ch_out, kernel, stride, padding, groups, dilation, activation)."""
default_act = swish() # default activation
def __init__(self, c1, c2, k=1, s=1, p=None, g=1, d=1, act=True):
"""Initialize Conv layer with given arguments including activation."""
super().__init__()
self.conv = nn.Conv2d(c1, c2, k, s, autopad(k, p, d), groups=g, dilation=d, bias=False)
self.bn = nn.BatchNorm2d(c2)
self.act = self.default_act if act is True else act if isinstance(act, nn.Module) else nn.Identity()
def forward(self, x):
"""Apply convolution, batch normalization and activation to input tensor."""
return self.act(self.bn(self.conv(x)))
def forward_fuse(self, x):
"""Perform transposed convolution of 2D data."""
return self.act(self.conv(x))
class RepConv(nn.Module):
default_act = swish() # default activation
def __init__(self, c1, c2, k=3, s=1, p=1, g=1, d=1, act=True, bn=False, deploy=False):
"""Initializes Light Convolution layer with inputs, outputs & optional activation function."""
super().__init__()
assert k == 3 and p == 1
self.g = g
self.c1 = c1
self.c2 = c2
self.act = self.default_act if act is True else act if isinstance(act, nn.Module) else nn.Identity()
self.bn = nn.BatchNorm2d(num_features=c1) if bn and c2 == c1 and s == 1 else None
self.conv1 = Conv(c1, c2, k, s, p=p, g=g, act=False)
self.conv2 = Conv(c1, c2, 1, s, p=(p - k // 2), g=g, act=False)
def forward_fuse(self, x):
"""Forward process."""
return self.act(self.conv(x))
def forward(self, x):
"""Forward process."""
id_out = 0 if self.bn is None else self.bn(x)
return self.act(self.conv1(x) + self.conv2(x) + id_out)
def get_equivalent_kernel_bias(self):
"""Returns equivalent kernel and bias by adding 3x3 kernel, 1x1 kernel and identity kernel with their biases."""
kernel3x3, bias3x3 = self._fuse_bn_tensor(self.conv1)
kernel1x1, bias1x1 = self._fuse_bn_tensor(self.conv2)
kernelid, biasid = self._fuse_bn_tensor(self.bn)
return kernel3x3 + self._pad_1x1_to_3x3_tensor(kernel1x1) + kernelid, bias3x3 + bias1x1 + biasid
def _pad_1x1_to_3x3_tensor(self, kernel1x1):
"""Pads a 1x1 tensor to a 3x3 tensor."""
if kernel1x1 is None:
return 0
else:
return torch.nn.functional.pad(kernel1x1, [1, 1, 1, 1])
def _fuse_bn_tensor(self, branch):
"""Generates appropriate kernels and biases for convolution by fusing branches of the neural network."""
if branch is None:
return 0, 0
if isinstance(branch, Conv):
kernel = branch.conv.weight
running_mean = branch.bn.running_mean
running_var = branch.bn.running_var
gamma = branch.bn.weight
beta = branch.bn.bias
eps = branch.bn.eps
elif isinstance(branch, nn.BatchNorm2d):
if not hasattr(self, 'id_tensor'):
input_dim = self.c1 // self.g
kernel_value = np.zeros((self.c1, input_dim, 3, 3), dtype=np.float32)
for i in range(self.c1):
kernel_value[i, i % input_dim, 1, 1] = 1
self.id_tensor = torch.from_numpy(kernel_value).to(branch.weight.device)
kernel = self.id_tensor
running_mean = branch.running_mean
running_var = branch.running_var
gamma = branch.weight
beta = branch.bias
eps = branch.eps
std = (running_var + eps).sqrt()
t = (gamma / std).reshape(-1, 1, 1, 1)
return kernel * t, beta - running_mean * gamma / std
def fuse_convs(self):
"""Combines two convolution layers into a single layer and removes unused attributes from the class."""
if hasattr(self, 'conv'):
return
kernel, bias = self.get_equivalent_kernel_bias()
self.conv = nn.Conv2d(in_channels=self.conv1.conv.in_channels,
out_channels=self.conv1.conv.out_channels,
kernel_size=self.conv1.conv.kernel_size,
stride=self.conv1.conv.stride,
padding=self.conv1.conv.padding,
dilation=self.conv1.conv.dilation,
groups=self.conv1.conv.groups,
bias=True).requires_grad_(False)
self.conv.weight.data = kernel
self.conv.bias.data = bias
for para in self.parameters():
para.detach_()
self.__delattr__('conv1')
self.__delattr__('conv2')
if hasattr(self, 'nm'):
self.__delattr__('nm')
if hasattr(self, 'bn'):
self.__delattr__('bn')
if hasattr(self, 'id_tensor'):
self.__delattr__('id_tensor')
class BasicBlock_3x3_Reverse(nn.Module):
def __init__(self,
ch_in,
ch_hidden_ratio,
ch_out,
shortcut=True):
super(BasicBlock_3x3_Reverse, self).__init__()
assert ch_in == ch_out
ch_hidden = int(ch_in * ch_hidden_ratio)
self.conv1 = Conv(ch_hidden, ch_out, 3, s=1)
self.conv2 = RepConv(ch_in, ch_hidden, 3, s=1)
self.shortcut = shortcut
def forward(self, x):
y = self.conv2(x)
y = self.conv1(y)
if self.shortcut:
return x + y
else:
return y
class SPP(nn.Module):
def __init__(
self,
ch_in,
ch_out,
k,
pool_size
):
super(SPP, self).__init__()
self.pool = []
for i, size in enumerate(pool_size):
pool = nn.MaxPool2d(kernel_size=size,
stride=1,
padding=size // 2,
ceil_mode=False)
self.add_module('pool{}'.format(i), pool)
self.pool.append(pool)
self.conv = Conv(ch_in, ch_out, k)
def forward(self, x):
outs = [x]
for pool in self.pool:
outs.append(pool(x))
y = torch.cat(outs, axis=1)
y = self.conv(y)
return y
class CSPStage(nn.Module):
def __init__(self,
ch_in,
ch_out,
n,
block_fn='BasicBlock_3x3_Reverse',
ch_hidden_ratio=1.0,
act='silu',
spp=False):
super(CSPStage, self).__init__()
split_ratio = 2
ch_first = int(ch_out // split_ratio)
ch_mid = int(ch_out - ch_first)
self.conv1 = Conv(ch_in, ch_first, 1)
self.conv2 = Conv(ch_in, ch_mid, 1)
self.convs = nn.Sequential()
next_ch_in = ch_mid
for i in range(n):
if block_fn == 'BasicBlock_3x3_Reverse':
self.convs.add_module(
str(i),
BasicBlock_3x3_Reverse(next_ch_in,
ch_hidden_ratio,
ch_mid,
shortcut=True))
else:
raise NotImplementedError
if i == (n - 1) // 2 and spp:
self.convs.add_module('spp', SPP(ch_mid * 4, ch_mid, 1, [5, 9, 13]))
next_ch_in = ch_mid
self.conv3 = Conv(ch_mid * n + ch_first, ch_out, 1)
def forward(self, x):
y1 = self.conv1(x)
y2 = self.conv2(x)
mid_out = [y1]
for conv in self.convs:
y2 = conv(y2)
mid_out.append(y2)
y = torch.cat(mid_out, axis=1)
y = self.conv3(y)
return y
四、手把手教你添加GFPN
上一节我们给出了GFPN的核心代码,这一节会教大家如何添加GFPN其实,GFPN的添加方式,和C2f是一模一样的,非常简单只需要修改几处即可。
同时给大家推荐我其它位置的修改教程的链接,当然你只使用本文的基础用本文的修改教程即可。
添加教程->YOLOv8改进 | 如何在网络结构中添加注意力机制、C2f、卷积、Neck、检测头
4.1 修改一
我们找到如下文件'ultralytics/nn/tasks.py'。在其中的开头我们导入我们的模块。

4.2 修改二
我们找到parse_model的函数,在其中进行修改,大约在700行,修改如下的两处即可。
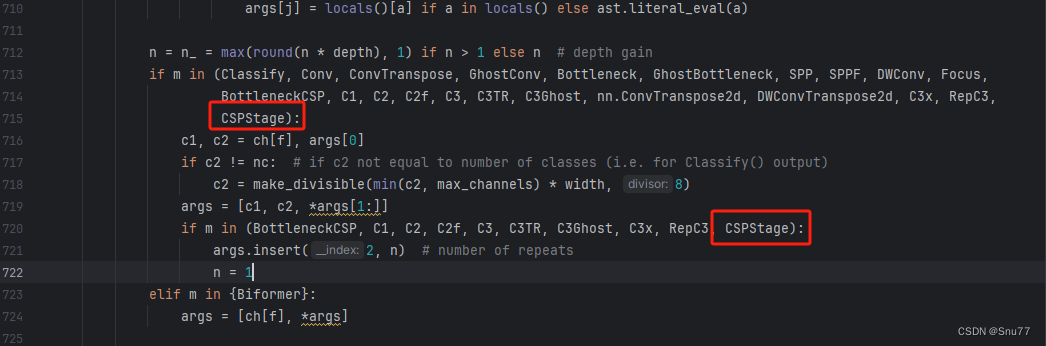
五、GFPN的yaml文件
其实最主要的是yaml文件的配置,来复现Damo-YOLO的Neck部分,大家复制粘贴我的yaml文件运行即可。
# Ultralytics YOLO 🚀, AGPL-3.0 license
# YOLOv8 object detection model with P3-P5 outputs. For Usage examples see https://docs.ultralytics.com/tasks/detect
# Parameters
nc: 80 # number of classes
scales: # model compound scaling constants, i.e. 'model=yolov8n.yaml' will call yolov8.yaml with scale 'n'
# [depth, width, max_channels]
n: [0.33, 0.25, 1024] # YOLOv8n summary: 225 layers, 3157200 parameters, 3157184 gradients, 8.9 GFLOPs
s: [0.33, 0.50, 1024] # YOLOv8s summary: 225 layers, 11166560 parameters, 11166544 gradients, 28.8 GFLOPs
m: [0.67, 0.75, 768] # YOLOv8m summary: 295 layers, 25902640 parameters, 25902624 gradients, 79.3 GFLOPs
l: [1.00, 1.00, 512] # YOLOv8l summary: 365 layers, 43691520 parameters, 43691504 gradients, 165.7 GFLOPs
x: [1.00, 1.25, 512] # YOLOv8x summary: 365 layers, 68229648 parameters, 68229632 gradients, 258.5 GFLOPs
# YOLOv8.0n backbone
backbone:
# [from, repeats, module, args]
- [-1, 1, Conv, [64, 3, 2]] # 0-P1/2
- [-1, 1, Conv, [128, 3, 2]] # 1-P2/4
- [-1, 3, C2f, [128, True]]
- [-1, 1, Conv, [256, 3, 2]] # 3-P3/8
- [-1, 6, C2f, [256, True]]
- [-1, 1, Conv, [512, 3, 2]] # 5-P4/16
- [-1, 6, C2f, [512, True]]
- [-1, 1, Conv, [1024, 3, 2]] # 7-P5/32
- [-1, 3, C2f, [1024, True]]
- [-1, 1, SPPF, [1024, 5]] # 9
# DAMO-YOLO GFPN Head
head:
- [-1, 1, Conv, [512, 1, 1]] # 10
- [6, 1, Conv, [512, 3, 2]]
- [[-1, 10], 1, Concat, [1]]
- [-1, 3, CSPStage, [512]] # 13
- [-1, 1, nn.Upsample, [None, 2, 'nearest']] #14
- [4, 1, Conv, [256, 3, 2]] # 15
- [[14, -1, 6], 1, Concat, [1]]
- [-1, 3, CSPStage, [512]] # 17
- [-1, 1, nn.Upsample, [None, 2, 'nearest']]
- [[-1, 4], 1, Concat, [1]]
- [-1, 3, CSPStage, [256]] # 20
- [-1, 1, Conv, [256, 3, 2]]
- [[-1, 17], 1, Concat, [1]]
- [-1, 3, CSPStage, [512]] # 23
- [17, 1, Conv, [256, 3, 2]] # 24
- [23, 1, Conv, [256, 3, 2]] # 25
- [[13, 24, -1], 1, Concat, [1]]
- [-1, 3, CSPStage, [1024]] # 27
- [[20, 23, 27], 1, Detect, [nc]] # Detect(P3, P4, P5)
六、成功运行的截图
下面是成功运行的截图,确保我添加的机制是可以完美运行的给大家证明。

六、本文总结
到此本文的正式分享内容就结束了,在这里给大家推荐我的YOLOv8改进有效涨点专栏,本专栏目前为新开的平均质量分98分,后期我会根据各种最新的前沿顶会进行论文复现,也会对一些老的改进机制进行补充,目前本专栏免费阅读(暂时,大家尽早关注不迷路~),如果大家觉得本文帮助到你了,订阅本专栏,关注后续更多的更新~
专栏回顾:YOLOv8改进系列专栏——本专栏持续复习各种顶会内容——科研必备