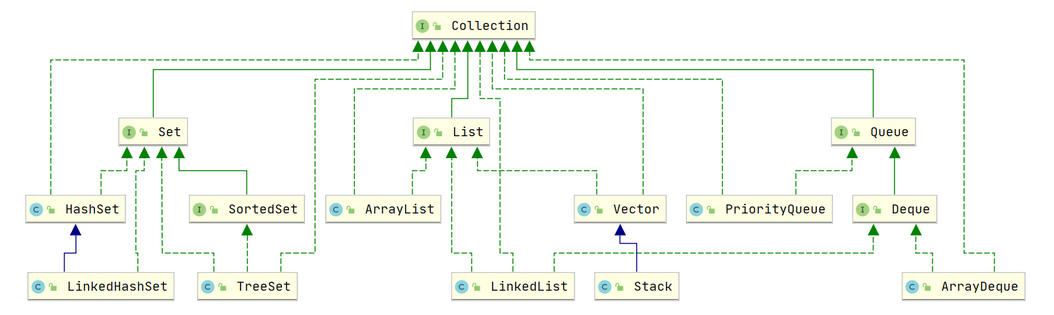
Java集合概述
从集合特点角度出发,Java集合可分为映射集、和单元素集合。如下图所示,单元素集合类图如下:
- collection包 : 工具单元素集合我们又可以分为,存储不可重复元素的
Set集合,可顺序存储重复元素的List,以及FIFO的Queue。
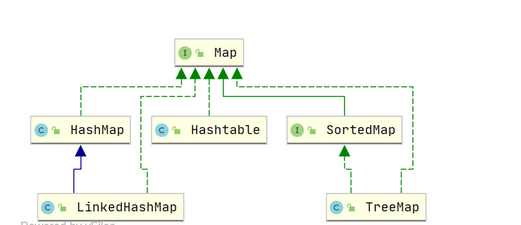
- 映射集合(Map接口下的类):另一大类就是映射集,他的特点就是每一个元素都是由键值对组成,我们可以通过
key找到对应的value,类图如下,集合具体详情笔者会在后文阐述。
List集合
list即顺序表,它是按照插入顺序存储的,元素可以重复。从底层结构角度,顺序表还可以分为以下两种:
- ArrayList :
ArrayList实现顺序表的选用的底层结构为数组,以下便是笔者从list源码找到的list底层存储元素的变量
transient Object[] elementData;
- LinkedList : 顺序链表底层是
双向链表,由一个个节点构成,节点有双指针,分别指向前驱节点和后继节点。
private static class Node<E> {
E item;
// 指向后继节点
Node<E> next;
//指向前驱节点
Node<E> prev;
Node(Node<E> prev, E element, Node<E> next) {
this.item = element;
this.next = next;
this.prev = prev;
}
}
- Vector:底层同样使用的是数组,
vector现在基本不用了,这里仅仅做个了解,它底层用的也是数组。
protected Object[] elementData;
List集合常见面试题
ArrayList容量是10,给它添加一个元素会发生什么?
我们不妨看看这样一段代码,可以看到我们将集合容量设置为10,第11次添加元素时,由于list底层使用的数组已满,会进行动态扩容,这个动态扩容说白了就是创建一个更大的容器将原本的元素拷贝过去,我们不妨基于下面的代码进行debug一下
ArrayList<Integer> arrayList=new ArrayList<>(10);
for (int i = 0; i < 10; i++) {
arrayList.add(i);
}
arrayList.add(10);
add源码如下,可以看到在添加元素前会对容量进行判断
public boolean add(E e) {
//判断本次插入位置是否大于容量
ensureCapacityInternal(size + 1);
elementData[size++] = e;
return true;
}
步入ensureCapacityInternal,会看到它调用ensureExplicitCapacity,它的逻辑就是判断当前插入元素后的最小容量是否大于数组容量,如果大于的话会直接调用动态扩容方法grow。
private void ensureExplicitCapacity(int minCapacity) {
modCount++;
//如果插入的元素位置大于数组位置,则会进行动态扩容
if (minCapacity - elementData.length > 0)
grow(minCapacity);
}
可以看到扩容的逻辑很简单创建一个新容器大小为原来的1.5倍,将原数组元素拷贝到新容器中
private void grow(int minCapacity) {
// overflow-conscious code
int oldCapacity = elementData.length;
//创建一个新容器大小为原来的1.5倍
int newCapacity = oldCapacity + (oldCapacity >> 1);
....略去细节
//将原数组元素拷贝到新容器中
elementData = Arrays.copyOf(elementData, newCapacity);
}
针对动态扩容导致的性能问题,你有什么解决办法嘛?
我们可以提前调用ensureCapacity顶下最终容量一次性完成动态扩容提高程序执行性能。
@Test
public void listCapacityTest2() {
int size = 1000_0000;
ArrayList<Integer> list = new ArrayList<>(1);
long start = System.currentTimeMillis();
for (int i = 0; i < size; i++) {
list.add(i);
}
long end = System.currentTimeMillis();
System.out.println("无显示扩容,完成时间:" + (end - start));
ArrayList<Integer> list2 = new ArrayList<>(1);
start = System.currentTimeMillis();
list2.ensureCapacity(size);
for (int i = 0; i < size; i++) {
list.add(i);
}
end = System.currentTimeMillis();
System.out.println("显示扩容,完成时间:" + (end - start));
}
输出结果
@Test
public void listCapacityTest2() {
int size = 1000_0000;
ArrayList<Integer> list = new ArrayList<>(1);
long start = System.currentTimeMillis();
for (int i = 0; i < size; i++) {
list.add(i);
}
long end = System.currentTimeMillis();
System.out.println("无显示扩容,完成时间:" + (end - start));
ArrayList<Integer> list2 = new ArrayList<>(1);
start = System.currentTimeMillis();
list2.ensureCapacity(size);
for (int i = 0; i < size; i++) {
list.add(i);
}
end = System.currentTimeMillis();
System.out.println("显示扩容,完成时间:" + (end - start));
}
ArrayList和LinkedList性能差异
- 先来看看头插法的性能差距
@Test
public void addFirstTest() {
int size = 10_0000;
List<Integer> arrayList = new ArrayList<>();
List<Integer> linkedList = new LinkedList<>();
long start = System.currentTimeMillis();
for (int i = 0; i < size; i++) {
arrayList.add(0, i);
}
long end = System.currentTimeMillis();
System.out.println("arrayList头插时长:" + (end - start));
start = System.currentTimeMillis();
for (int i = 0; i < size; i++) {
linkedList.add(0, i);
}
end = System.currentTimeMillis();
System.out.println("linkedList 头插时长:" + (end - start));
start = System.currentTimeMillis();
for (int i = 0; i < size; i++) {
((LinkedList<Integer>) linkedList).addFirst(i);
}
end = System.currentTimeMillis();
System.out.println("linkedList 头插时长:" + (end - start));
}
输出结果如下,可以看出linkedList 自带的addFirst性能最佳。原因也很简单,链表头插直接拼接一个元素就好了,不想arraylist那样需要将整个数组元素往后挪,而且arraylist的动态扩容机制还会进一步增加工作时长。
/**
* 输出结果
*
* arrayList头插时长:1061
* linkedList 头插时长:5
* linkedList 头插时长:4
*/
- 尾插法的性能比较,同理我们也写下下面这段代码
@Test
public void addLastTest() {
int size = 10_0000;
List<Integer> arrayList = new ArrayList<>();
List<Integer> linkedList = new LinkedList<>();
long start = System.currentTimeMillis();
for (int i = 0; i < size; i++) {
arrayList.add(i, i);
}
long end = System.currentTimeMillis();
System.out.println("arrayList 尾插时长:" + (end - start));
start = System.currentTimeMillis();
for (int i = 0; i < size; i++) {
linkedList.add(i, i);
}
end = System.currentTimeMillis();
System.out.println("linkedList 尾插时长:" + (end - start));
start = System.currentTimeMillis();
for (int i = 0; i < size; i++) {
((LinkedList<Integer>) linkedList).addLast(i);
}
end = System.currentTimeMillis();
System.out.println("linkedList 尾插时长:" + (end - start));
}
输出结果,可以看到还是链表稍快一些,为什么arraylist这里性能也还不错呢?原因也很简单,无需为了插入一个节点维护其他位置。
/**
*输出结果
* arrayList 尾插时长:6
* linkedList 尾插时长:5
* linkedList 尾插时长:3
*/
- 随机插入:为了公平实验,笔者将
list初始化工作都放在计时之外,避免arrayList动态扩容的时间影响最终实验结果
@Test
public void randAddTest() {
int size = 100_0000;
ArrayList arrayList = new ArrayList(size);
add(size, arrayList, "arrayList");
long start = System.currentTimeMillis();
for (int i = 0; i < 1000; i++) {
arrayList.add(50_0000, 1);
}
long end = System.currentTimeMillis();
System.out.println("arrayList randAdd :" + (end - start));
LinkedList linkedList = new LinkedList();
add(size, linkedList, "linkedList");
start = System.currentTimeMillis();
for (int i = 0; i < 1000; i++) {
linkedList.add(50_0000, 1);
}
end = System.currentTimeMillis();
System.out.println("linkedList randAdd :" + (end - start));
}
从输出结果来看,随机插入也是arrayList性能较好,原因也很简单,arraylist随机访问速度远远快与linklist
arrayList插入元素时间 18
arrayList randAdd :179
linkedList插入元素时间 105
linkedList randAdd :5353
ArrayList 和 Vector 区别了解嘛?
这个问题我们可以从以下几个维度分析:
- 底层数据结构:两者底层存储都是采用数组,我们可以从他们的源码了解这一点
ArrayList存储用的是new Object[initialCapacity];
public ArrayList(int initialCapacity) {
if (initialCapacity > 0) {
this.elementData = new Object[initialCapacity];
} else if (initialCapacity == 0) {
this.elementData = EMPTY_ELEMENTDATA;
} else {
throw new IllegalArgumentException("Illegal Capacity: "+
initialCapacity);
}
}
Vector底层存储元素用的是 new Object[initialCapacity];
public Vector(int initialCapacity, int capacityIncrement) {
super();
if (initialCapacity < 0)
throw new IllegalArgumentException("Illegal Capacity: "+
initialCapacity);
this.elementData = new Object[initialCapacity];
this.capacityIncrement = capacityIncrement;
}
- 线程安全性:
Vector为线程安全类,ArrayList线程不安全,如下所示我们使用ArrayList进行多线程插入出现的索引越界问题。
@Test
public void listAddTest2() throws InterruptedException {
List<Integer> list = new ArrayList<>();
Thread t1 = new Thread(() -> {
for (int i = 0; i < 1000; i++) {
list.add(i);
}
});
Thread t2 = new Thread(() -> {
for (int i = 0; i < 1000; i++) {
list.add(i);
}
});
t1.start();
t2.start();
t1.join();
t2.join();
Thread.sleep(5000);
System.out.println(list.size());
/**
* java.lang.ArrayIndexOutOfBoundsException: 70
* at java.util.ArrayList.add(ArrayList.java:463)
* at com.guide.collection.CollectionTest.lambda$listAddTest2$3(CollectionTest.java:290)
* at java.lang.Thread.run(Thread.java:748)
* 71
*/
}
Vector 线程安全代码示例
@Test
public void listAddTest() throws InterruptedException{
List<Integer> list = new Vector<>();
Thread t1 = new Thread(() -> {
for (int i = 0; i < 1000; i++) {
list.add(i);
}
});
Thread t2 = new Thread(() -> {
for (int i = 0; i < 1000; i++) {
list.add(i);
}
});
t1.start();
t2.start();
t1.join();
t2.join();
Thread.sleep(5000);
System.out.println(list.size());//2000
}
原因很简单,vector的add方法有加synchronized 关键字
public synchronized boolean add(E e) {
modCount++;
ensureCapacityHelper(elementCount + 1);
elementData[elementCount++] = e;
return true;
}
ArrayList 与 LinkedList 的区别
-
底层存储结构:
ArrayList底层使用的是数组,LinkedList底层使用的是链表 -
线程安全性:两者都是线程不安全,因为add方法都没有任何关于线程安全的处理。
-
随机访问性:虽然两者都支持随机访问,但是链表随机访问不太高效。感兴趣的读者可以使用下面这段代码分别使用
100w数据量的数组或者链表get数据就会发现,ArrayList随机访问速度远远高于LinkedList。
@Test
public void arrTest() {
int size = 100_0000;
List<Integer> arrayList = new ArrayList<>();
List<Integer> linkedList = new LinkedList<>();
add(size, arrayList, "arrayList");
// 要维护节点关系和创建节点耗时略长
/**
* void linkLast(E e) {
* final Node<E> l = last;
* final Node<E> newNode = new Node<>(l, e, null);
* last = newNode;
* if (l == null)
* first = newNode;
* else
* l.next = newNode;
* size++;
* modCount++;
* }
*/
add(size, linkedList, "linkedList");
/**
* 输出结果
* arrayList插入元素时间 52
* linkedList插入元素时间 86
*/
get(size, arrayList, "arrayList");
/**
* Node<E> node(int index) {
* // assert isElementIndex(index);
*
* if (index < (size >> 1)) {
* Node<E> x = first;
* for (int i = 0; i < index; i++)
* x = x.next;
* return x;
* } else {
* Node<E> x = last;
* for (int i = size - 1; i > index; i--)
* x = x.prev;
* return x;
* }
* }
*/
get(size, linkedList, "linkedList");
}
private void get(int size, List<Integer> list, String arrType) {
long start = System.currentTimeMillis();
for (int i = 0; i < size; i++) {
list.get(i);
}
long end = System.currentTimeMillis();
System.out.println(arrType + "获取元素时间 " + (end - start));
}
private void add(int size, List<Integer> list, String arrType) {
long start = System.currentTimeMillis();
for (int i = 0; i < size; i++) {
list.add(i);
}
long end = System.currentTimeMillis();
System.out.println(arrType + "插入元素时间 " + (end - start));
}
输出结果
arrayList插入元素时间 44
linkedList插入元素时间 89
arrayList获取元素时间 5
linkedList获取元素时间 1214464
可以看到链表添加时间和访问时间都远远大于数组,原因也很简单,之所以随机访问时间长是因为底层使用的是链表,所以无法做到直接的随机存取。
而插入时间长是因为需要插入节点时要遍历位置且维护前驱后继节点的关系。
/**
* Links e as last element.
*/
void linkLast(E e) {
final Node<E> l = last;
final Node<E> newNode = new Node<>(l, e, null);
last = newNode;
if (l == null)
first = newNode;
else
l.next = newNode;
size++;
modCount++;
}
- 内存空间占用:
ArrayList的空 间浪费主要体现在在List列表的结尾会预留一定的容量空间,而LinkedList的空间花费则体现在它的每一个元素都需要消耗比ArrayList更多的空间(因为要存放直接后继和直接前驱以及数据)。
ArrayList 的扩容机制了解过嘛?
Java的ArrayList 底层默认数组大小为10,的动态扩容机制即ArrayList 确保元素正确存放的关键,了解核心逻辑以及如何基于该机制提高元素存储效率也是很重要的,感兴趣的读者可以看看读者编写的这篇博客:
Java数据结构与算法(动态数组ArrayList和LinkList小结)
尽管从上面来看两者各有千秋,但是设计者认为若无必要,都使用用Arraylist即可。
Set集合
Set集元素不可重复,存储也不会按照插入顺序排序。适合存储那些需要去重的场景。set大概有两种:
- HashSet:
HashSet要求数据唯一,但是存储是无序的,所以基于面向对象思想复用原则,Java设计者就通过聚合关系封装HashMap,基于HashMap的key实现了HashSet。
从源码我们就可以看到HashSet的add方法就是通过HashMap的put方法实现存储唯一元素(key作为set的值,value统一使用PRESENT这个object对象)
public boolean add(E e) {
// 底层逻辑是插入时发现这个元素有的话就不插入直接返回集合中的值,反之插入成功返回null,所以判断添加成功的代码才长下面这样
return map.put(e, PRESENT)==null;
}
-
LinkedHashSet:
LinkedHashSet即通过聚合封装LinkedHashMap实现的。` -
TreeSet:
TreeSet底层也是TreeMap,一种基于红黑树实现的有序树。关于红黑树可以参考笔者之前写过的这篇文章:
数据结构与算法之红黑树小结
public TreeSet() {
this(new TreeMap<E,Object>());
}
Map集合
Map即映射集,适合存储键值对类型的元素,key不可重复,value可重复,我们可以更具key找到对应的value。
HashMap(重点)
JDK1.8的HashMap默认是由数组+链表组成,通过key值hash选择合适的数组索引位置,当冲突时使用拉链法解决冲突。当链表长度大于8且数组长度大于64的情况下,链表会变成红黑树,减少元素搜索时间。(注意若长度小于64链表长度大于8只会进行数组扩容)
LinkedHashMap
LinkedHashMap继承自HashMap,他在HashMap基础上增加双向链表,由于LinkedHashMap维护了一个双向链表来记录数据插入的顺序,因此在迭代遍历生成的迭代器的时候,是按照双向链表的路径进行遍历的,所以遍历速度远远快于HashMap,具体可以查阅笔者写的这篇文章:
Java集合LinkedHashMap小结
Hashtable简介
数组+链表组成的,数组是 Hashtable 的主体,链表则是主要为了解决哈希冲突而存在的。
Set和Map常见面试题
HashMap 和 Hashtable 的区别(重点)
- 从线程安全角度:
HashMap线程不安全、Hashtable线程安全。 - 从底层数据结构角度:
HashMap初始情况是数组+链表,特定情况下会变数组+红黑树,Hashtable则是数组,核心源码:private transient Entry<?,?>[] table;。 - 从保存数值角度:
HashMap允许null键或null值,但是只允许一个。 - 从初始容量角度考虑:
HashMap默认16,扩容都是基于当前容量*2。Hashtable默认的初始大小为11,之后每次扩充,容量变为原来的2n+1。 - 从性能角度考虑:
Hashtable每次添加都会上synchronized锁,所以性能很差。
HashMap 和 HashSet有什么区别
HashSet 聚合了HashMap ,通俗来说就是将HashMap 的key作为自己的值存储来使用。
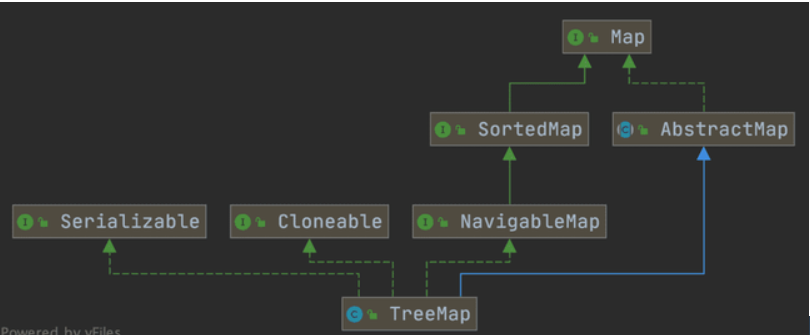
HashMap 和 TreeMap 有什么区别
类图如下,TreeMap 底层是有序树,所以对于需要查找最大值或者最小值等场景,TreeMap 相比HashMap更有优势。因为他继承了NavigableMap接口和SortedMap 接口。
如下源码所示,我们需要拿最大值或者最小值可以用这种方式或者最大值或者最小值
@Test
public void treeMapTest(){
TreeMap<Integer,Object> treeMap=new TreeMap<>();
treeMap.put(3213,"231");
treeMap.put(434,"231");
treeMap.put(432,"231");
treeMap.put(2,"231");
treeMap.put(432,"231");
treeMap.put(31,"231");
System.out.println(treeMap.toString());
System.out.println(treeMap.firstKey());
System.out.println(treeMap.lastEntry());
/**
* 输出结果
*
* {2=231, 31=231, 432=231, 434=231, 3213=231}
* 2
* 3213=231
*/
}
HashSet 实现去重插入的底层工作机制了解嘛?
当你把对象加入HashSet时,HashSet 会先计算对象的hashcode值来判断对象加入的位置,同时也会与其他加入的对象的hashcode 值作比较,如果没有相符的 hashcode,HashSet 会认为对象没有重复出现,直接允许插入了。但是如果发现有相同 hashcode 值的对象,这时会调用equals()方法来检查 hashcode 相等的对象是否真的相同。如果两者相同,HashSet就会将其直接覆盖返回插入前的值。
对此我们不妨基于下面这样一段代码进行debug了解一下究竟
HashSet<String> set=new HashSet<>();
set.add("1");
set.add("1");
而通过源码我们也能看出,底层就是调用HashMap的put方法,若返回空则说明这个key没添加过
public boolean add(E e) {
return map.put(e, PRESENT)==null;
}
map.put底层返回值的核心逻辑是基于hashMap的源码如下,可以看到hashset将onlyIfAbsent设置为false,若插入成功返回null,反之则会将用新值将旧值进行覆盖,返回oldValue
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i;
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
//通过哈希计算新元素要插入的位置有没有元素
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);
else {//走到这里则说明新元素的位置有元素插入了
Node<K,V> e; K k;
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
//完全相等用用新元素直接去覆盖旧的元素
e = p;
//下面两种情况则说明只是计算的位置一样,所以就将新节点挂到后面去
else if (p instanceof TreeNode)
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
else {
for (int binCount = 0; ; ++binCount) {
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
break;
}
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
//如果e不为空说明当前位置之前有过元素,将新值覆盖旧的值并返回旧值
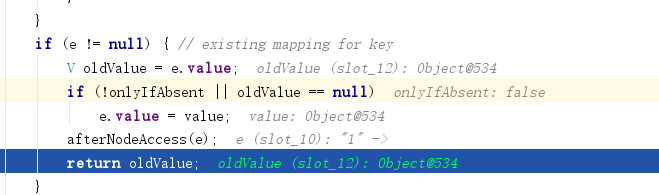
if (e != null) {
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e);
return oldValue;
}
}
++modCount;
if (++size > threshold)
resize();
afterNodeInsertion(evict);
return null;
}
如下图所示,第2次add就会返回上次add的value,只不过对于hashSet而言返回的就是private static final Object PRESENT = new Object();全局不可变对象而已。
能不能从底层数据结构比较 HashSet、LinkedHashSet 和 TreeSet 使用场景、不同之处
-
HashSet:可在不要求元素有序但唯一的场景。
-
LinkedHashSet:可用于要求元素唯一、插入或者访问有序性的场景,或者
FIFO的场景。 -
TreeSet:要求支持有序性且按照自定义要求进行排序的元素不可重复的场景。
更多关于HashMap的知识
Java集合hashMap小结
更多ConcurrentHashMap
Java并发容器小结
优先队列PriorityQueue
关于优先队列的文章,笔者已将该文章投稿给了Javaguide,感兴趣的读者可以参考一下这篇文章:
https://github.com/Snailclimb/JavaGuide/blob/main/docs/java/collection/priorityqueue-source-code.md
Java集合使用以及工具类小结
Java集合使用以及工具类小结
一些常见的笔试题
以下代码分别输出多少?
List a=new ArrayList<String>();
a.add(null);
a.add(null);
a.add(null);
System.out.println(a.size());//3
Map map=new HashMap();
map.put("a",null);
map.put("a",null);
map.put("a",null);
System.out.println(map.size());//1
参考文献
Java集合常见面试题总结(上)
ArrayList源码&扩容机制分析