Prometheus 算是一个全能型选手,原生支持容器监控,当然监控传统应用也不是吃干饭的,所以就是容器和非容器他都支持,所有的监控系统都具备这个流程,数据采集→数据处理→数据存储→数据展示→告警,本文就是针对 Prometheus 展开的,所以先看看 Prometheus 概述
Prometheus 概述
先来看一下 Prometheus 是个啥
Prometheus 是什么
中文名普罗米修斯,最初在 SoundCloud 上构建的监控系统,自 2012 年成为社区开源项目,用户非常活跃的开发人员和用户社区,2016 年加入 CNCF,成为继 kubernetes 之后的第二个托管项目,官方网站
Prometheus 特点
- 多维数据模型:由度量名称和键值对标识的时间序列数据
- PromSQL: — 种灵活的查询语言,可以利用多维数据完成复杂的查询
- 不依赖分布式存储,单个服务器节点可直接工作
- 基于 HTTP 的 pull 方式釆集时间序列数据
- 推送时间序列数据通过 PushGateway 组件支持
- 通过服务发现或静态配罝发现目标
- 多种图形模式及仪表盘支持 (grafana)
Prometheus 组成与架构
来看一张图,官方扒到的
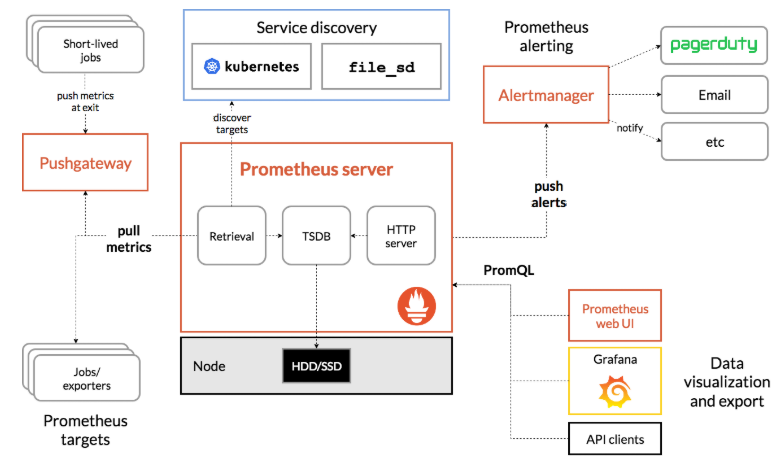
| 名称 | 说明 |
| Prometheus Server | 收集指标和存储时间序列数据,并提供查询接口 |
| Push Gateway | 短期存储指标数据,主要用于临时性任务 |
| Exporters | 采集已有的三方服务监控指标并暴露 metrics |
| Alertmanager | 告警 |
| Web UI | 简单的 WEB 控制台 |
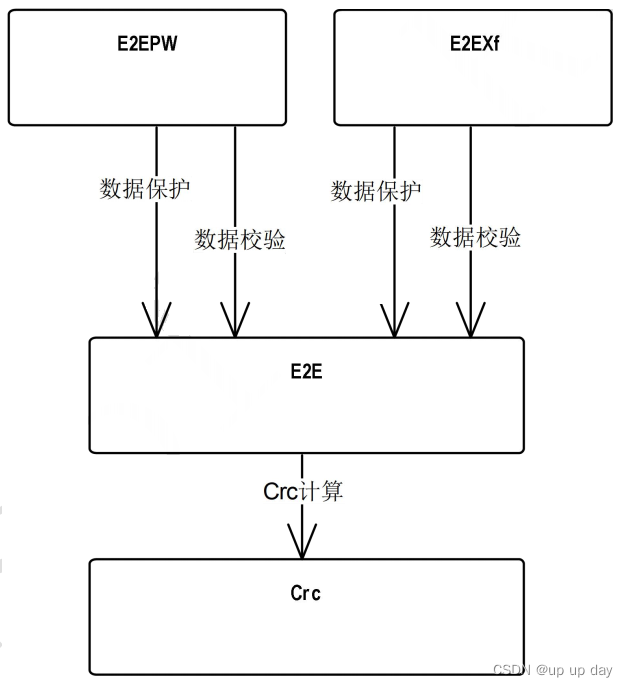
集成了数据的采集,处理,存储,展示,告警一系列流程都已经具备了
数据模型
Prometheus 将所有数据存储为时间序列,具有相同度量名称以及标签属于同个指标,也就是说 Prometheus 从数据源拿到数据之后都会存到内置的 TSDB 中,这里存储的就是时间序列数据,它存储的数据会有一个度量名称,譬如你现在监控一个 nginx,首先你要给他起个名字,这个名称也就是度量名,还会有 N 个标签,你可以理解名称为表名,标签为字段,所以,每个时间序列都由度量标准名称和一组键值对 (也称为标签) 唯一标识。
时间序列的格式是这样的,
<metricename> {<labelname>=<labelvalue>,...}
# metrice name 指的就是度量标准名称,label name 也就是标签名,这个标签可以有多个,例子
jvm_memory_max_bytes{area="heap",id="Eden Space",}指的就是度量标准名称,label name 也就是标签名,这个标签可以有多个,例子
jvm_memory_max_bytes{area="heap",id="Eden Space",}
这个度量名称为 jvm_memory_max_bytes,后面是两个标签,和他们各对应的值,当然你还可以继续指定标签,你指定的标签越多查询的维度就越多。
指标类型
看表格吧
| 类型名称 | 说明 |
| Counter | 递增计数器,适合收集接口请求次数 |
| Guage | 可以任意变化的数值,适用 CPU 使用率 |
| Histogram | 对一段时间内数据进行采集,并对有所数值求和于统计数量 |
| Summary | 与 Histogram 类型类似 |
任务和实例展开目录
实例指的就是你可以抓取的目标target,这个会在 Prometheus 配置文件中体现,任务是具有相同目标的实例集合,你可以理解为是一个组(比如,订单服务多台实例机器,可以放入一个任务里,分多个实例target抓取),一会写配置文件的时候会详细解析,下面开始安装 Prometheus。
Prometheus 部署
我们借助docker来安装,新建目录docker-monitor,在里面创建文件docker-compose.yml,内容如下:
version: "3"
services:
prometheus:
image: prom/prometheus:v2.4.3
container_name: 'prometheus'
volumes:
- ./prometheus/:/etc/prometheus/ #映射prometheus的配置文件
- /etc/localtime:/etc/localtime:ro #同步容器与宿主机的时间,这个非常重要,如果时间不一致,会导致prometheus抓不到数据
ports:
- '9090:9090'监控web应用性能指标
在docker-monitor目录下新增prometheus目录,在里面创建prometheus配置文件prometheus.yml,内容如下:
global: #全局配置
scrape_interval: 15s #全局定时任务抓取性能数据间隔
scrape_configs: #抓取性能数据任务配置
- job_name: 'tulingmall-order' #抓取订单服务性能指标数据任务,一个job下可以配置多个抓紧的targets,比如订单服务多个实例机器
scrape_interval: 10s #每10s抓取一次
metrics_path: '/actuator/prometheus' #抓取的数据url
static_configs:
- targets: ['192.168.31.60:8844'] #抓取的服务器地址
labels:
application: 'tulingmall-order-label' #抓取任务标签
- job_name: 'prometheus' #抓取prometheus自身性能指标数据任务
scrape_interval: 5s
static_configs:
- targets: ['localhost:9090']在docker-monitor目录下执行如下命令启动prometheus
docker-compose up -在浏览器访问prometheus:http://192.168.31.60:9090,如下图所示:
点击Status下拉,选中Targets,界面如下:
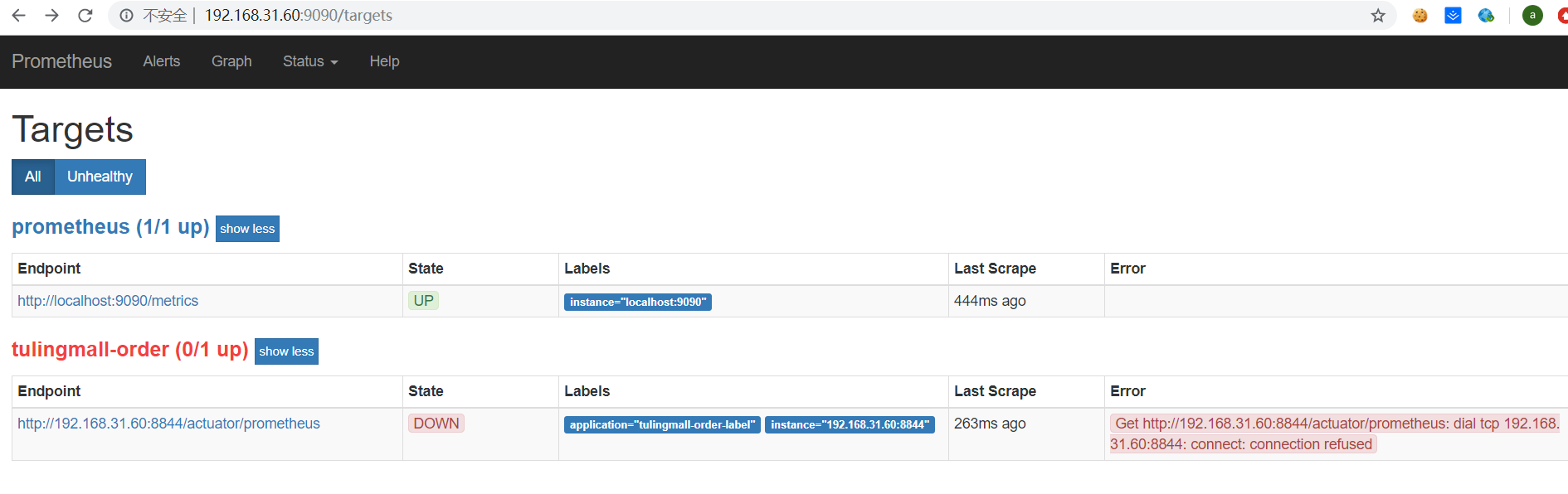
这里显示了在prometheus里配置的两个抓取任务,不过tulingmall-order任务是失败的,state是down,接下来我们需要配置下tulingmall-order服务才能让prometheus抓取数据。
首先需要在tulingmall-order服务下增加pom依赖,如下:
<!-- 开启springboot的应用监控 -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-actuator</artifactId>
</dependency>
<!-- 增加prometheus整合 -->
<dependency>
<groupId>io.micrometer</groupId>
<artifactId>micrometer-registry-prometheus</artifactId>
</dependency>还需要在tulingmall-order服务的配置文件里增加开启springboot admin监控的配置,如下:
management: #开启SpringBoot Admin的监控
endpoints:
promethus:
enable: true
web:
exposure:
include: '*'
endpoint:
health:
show-details: always重启tulingmall-order服务,刷新prometheus页面,如下所示:
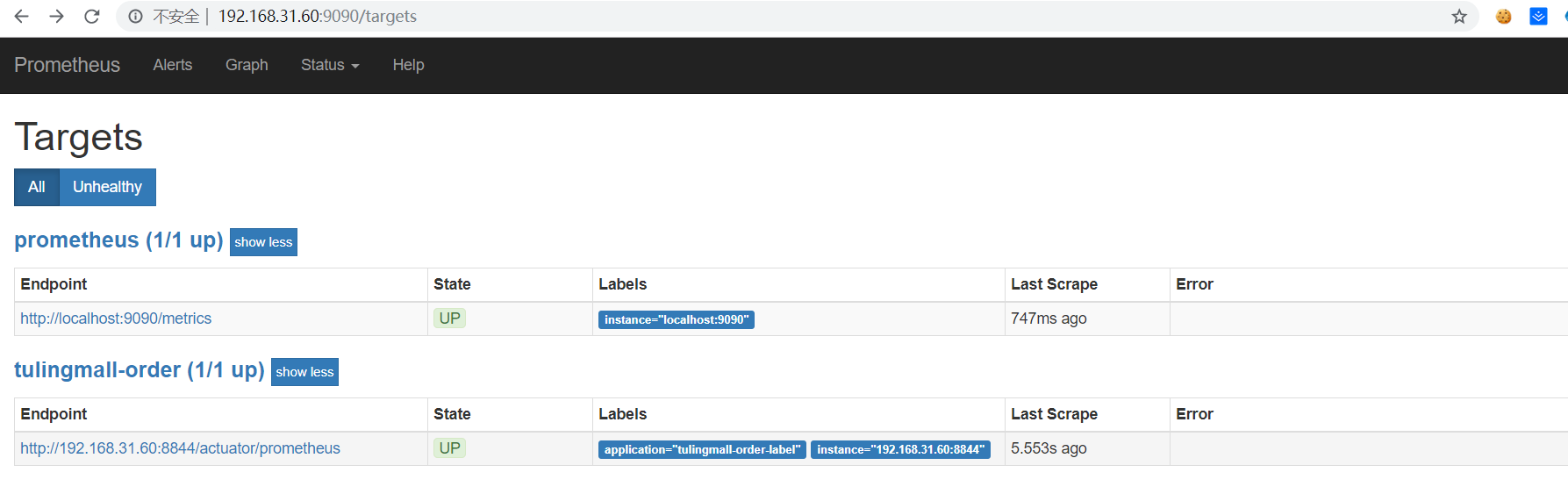
点击tulingmall-order下面的prometheus链接:http://192.168.31.60:8844/actuator/prometheus,会打开order服务对外暴露的性能指标数据,如下图:
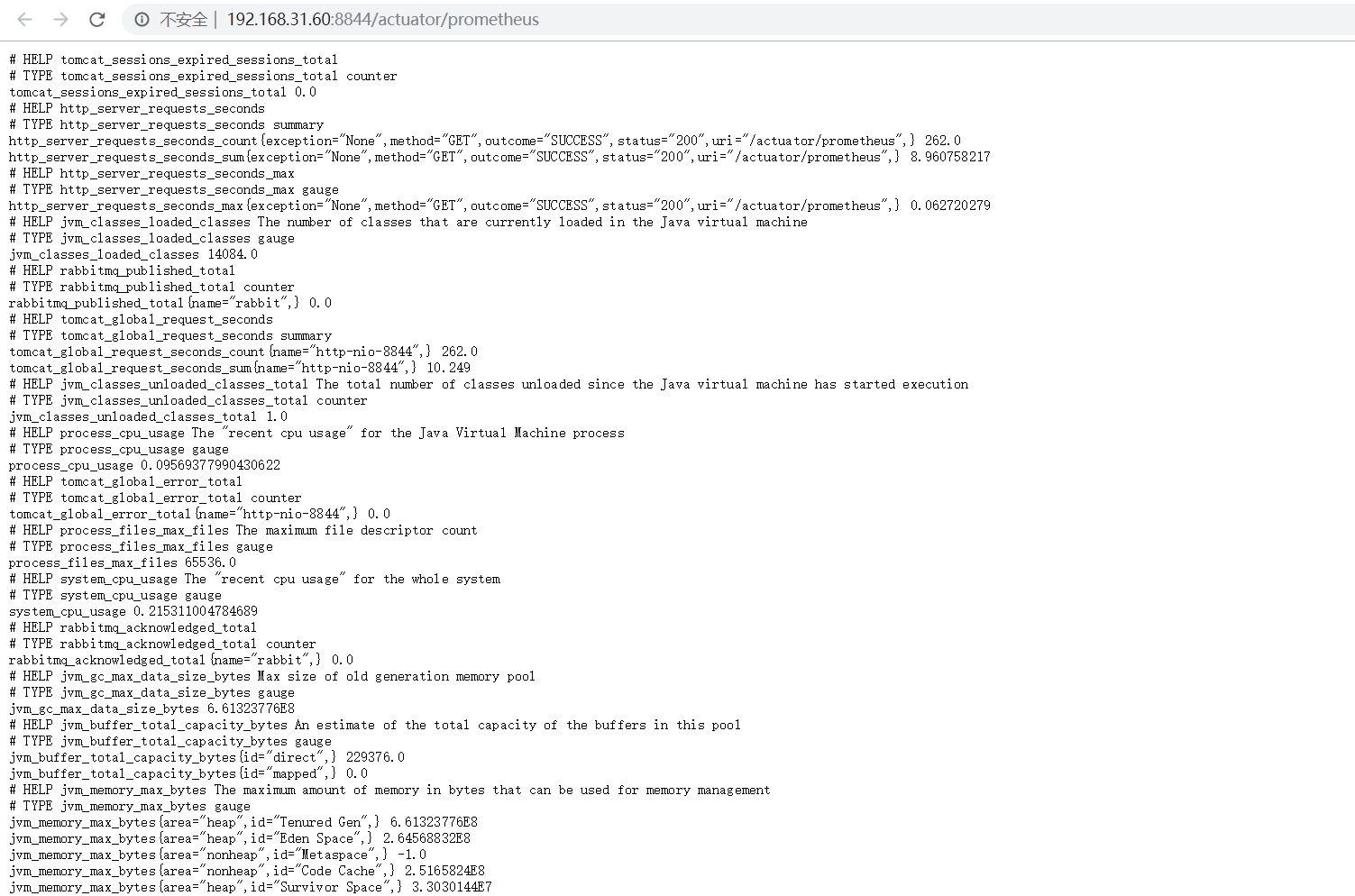
拿其中一个指标举例:jvm_threads_states_threads{state="runnable",} 13.0,这代表jvm_threads_states_threads这个度量指标,其中state等于runnable的数据有13条
点prometheus页面的Graph链接,进入指标查询页面可以查询相关指标,如下:
将度量指标输入查询框,点击Execute按钮,如下:
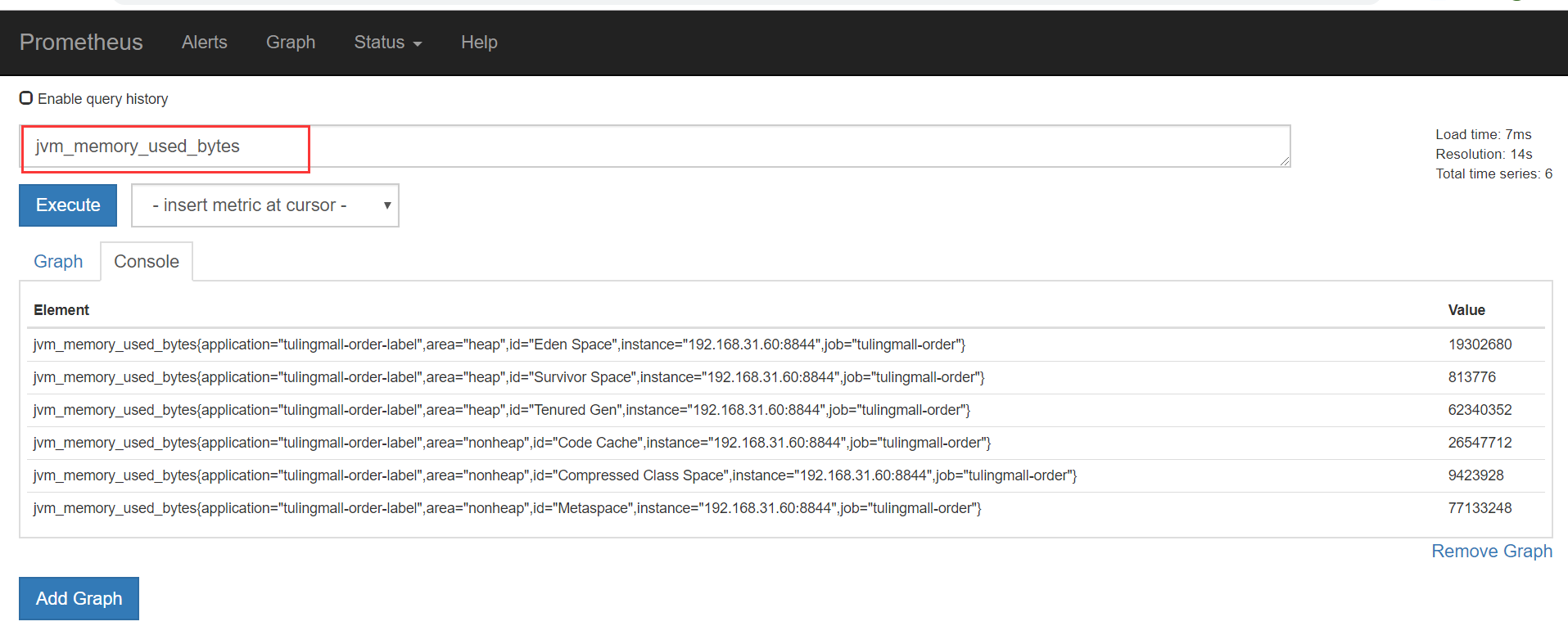
点击Execute按钮下的Graph链接可以查看指标对应的图标,如下:
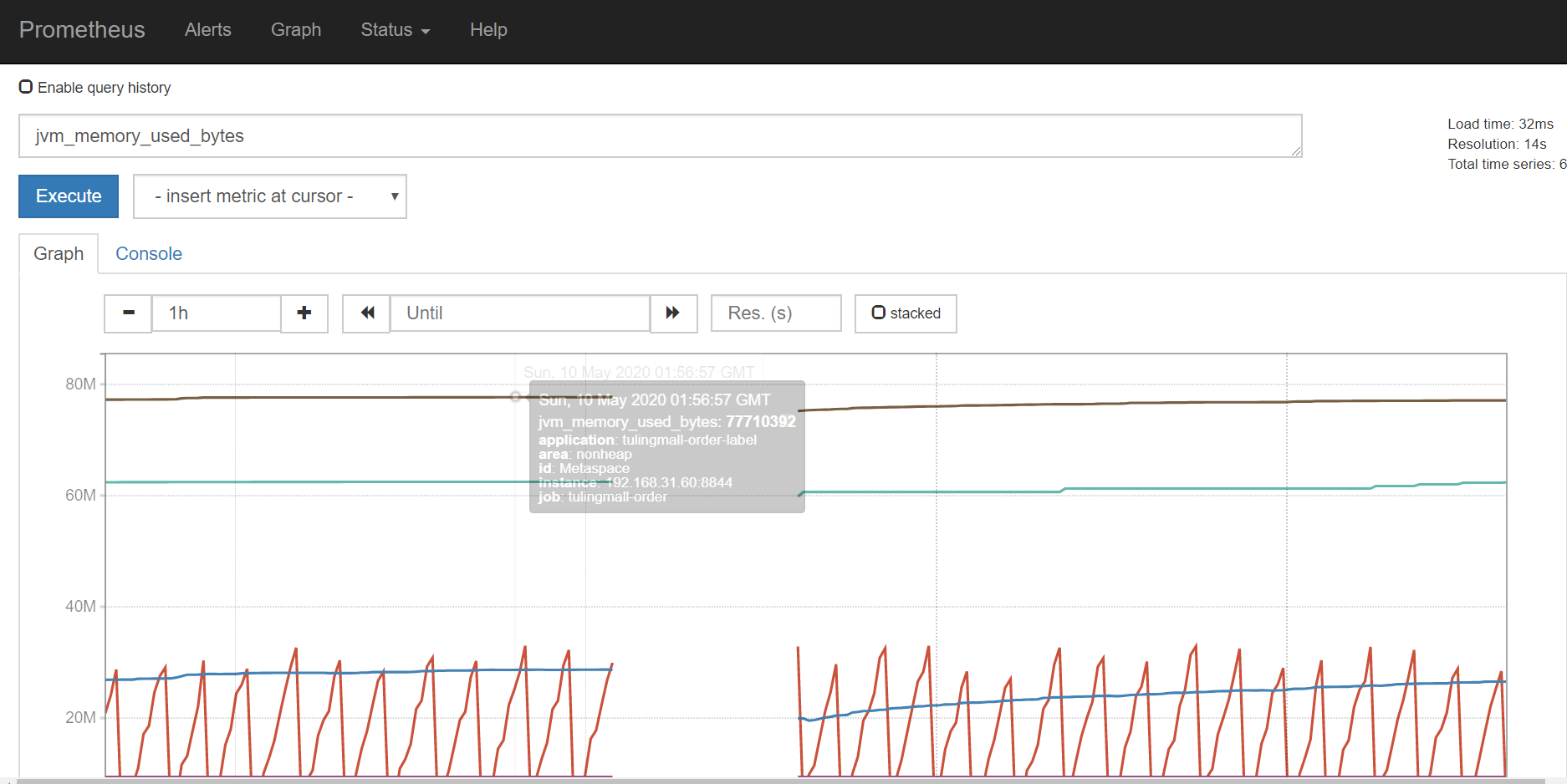
以上是prometheus自带的指标查询界面,但是太简陋,一般我们都是使用grafana图形展示工具配合prometheus一起使用
Grafana 部署
先用docker来安装下grafana,在上面的docker-compose.yml文件里加入grafana的安装配置,如下所示:
version: "3"
services:
prometheus:
image: prom/prometheus:v2.4.3
container_name: 'prometheus'
volumes:
- ./prometheus/:/etc/prometheus/ #映射prometheus的配置文件
- /etc/localtime:/etc/localtime:ro #同步容器与宿主机的时间,这个非常重要,如果时间不一致,会导致prometheus抓不到数据
ports:
- '9090:9090'
grafana:
image: grafana/grafana:5.2.4
container_name: 'grafana'
ports:
- '3000:3000'
volumes:
- ./grafana/config/grafana.ini:/etc/grafana/grafana.ini #grafana报警邮件配置
- ./grafana/provisioning/:/etc/grafana/provisioning/ #配置grafana的prometheus数据源
- /etc/localtime:/etc/localtime:ro
env_file:
- ./grafana/config.monitoring #grafana登录配置
depends_on:
- prometheus #grafana需要在prometheus之后启动在docker-monitor目录下新增grafana目录,在里面创建文件config.monitoring,内容如下:
GF_SECURITY_ADMIN_PASSWORD=password #grafana管理界面的登录用户密码,用户名是admin
GF_USERS_ALLOW_SIGN_UP=false #grafana管理界面是否允许注册,默认不允许在grafana目录下创建目录provisioning,在里面创建datasources目录,在datasources目录里新建文件datasource.yml,内容如下:
# config file version
apiVersion: 1
deleteDatasources: #如果之前存在name为Prometheus,orgId为1的数据源先删除
- name: Prometheus
orgId: 1
datasources: #配置Prometheus的数据源
- name: Prometheus
type: prometheus
access: proxy
orgId: 1
url: http://prometheus:9090 #在相同的docker compose下,可以直接用prometheus服务名直接访问
basicAuth: false
isDefault: true
version: 1
editable: true在grafana目录下创建目录config,在里面创建文件grafana.ini,内容如下:
#################################### SMTP / Emailing ##########################
# 配置邮件服务器
[smtp]
enabled = true
# 发件服务器
host = smtp.qq.com:465
# smtp账号
user = 285763097@qq.com
# smtp 授权码
password = test123
# 发信邮箱
from_address = 285763097@qq.com
# 发信人
from_name = memory用docker compose启动grafana,访问grafana页面:http://192.168.31.60:3000,用户名为admin,密码为password,如下:

登录进去首页如下:
点击左边的加号并import一个我们事先准备好的可视化指标文件web-dashboard.json(网上可以找现成的)
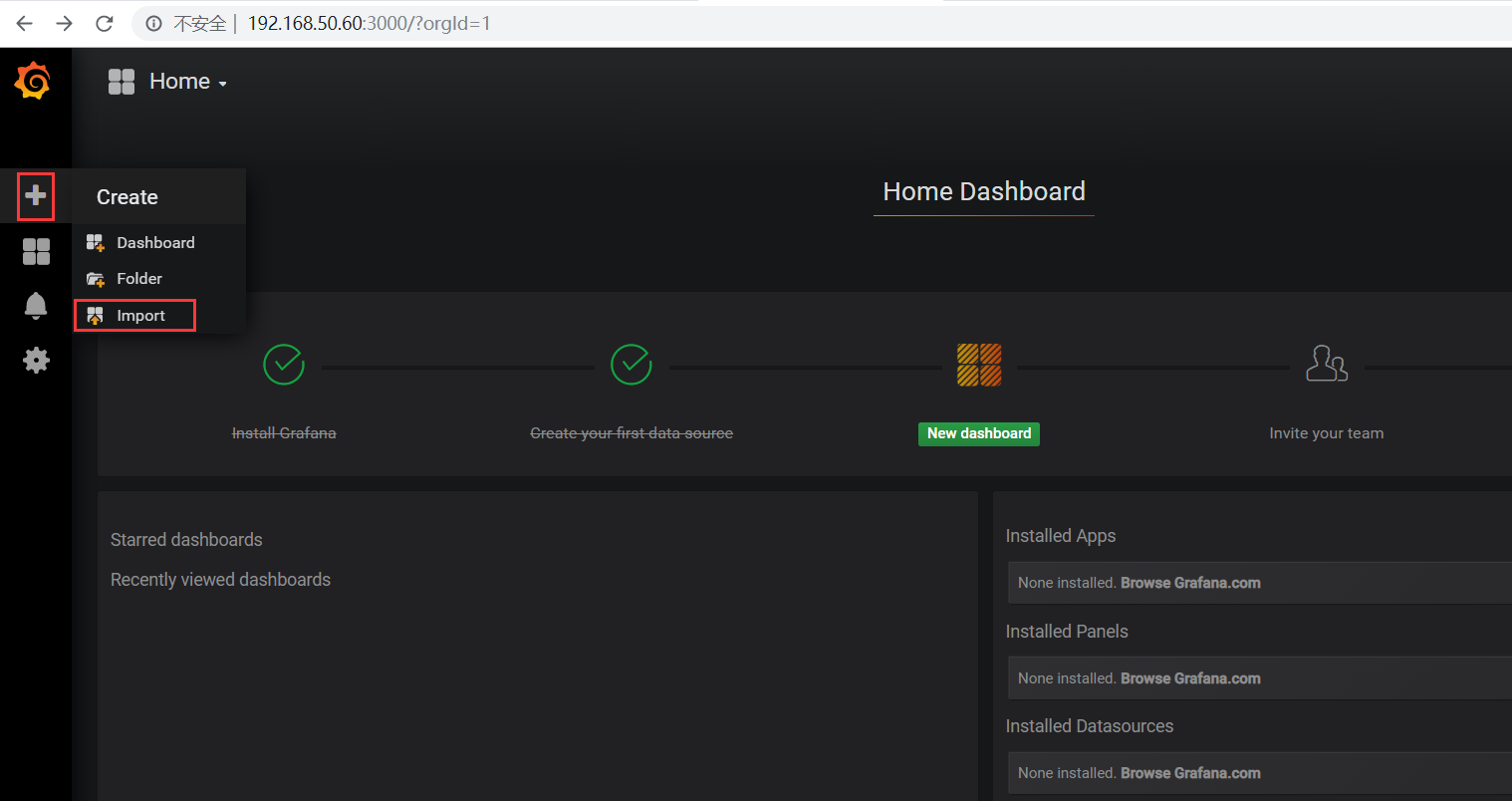
导入web-dashboard.json后在页面上选择Prometheus,点击import按钮之后页面显示如下(有可能没有任何数据):
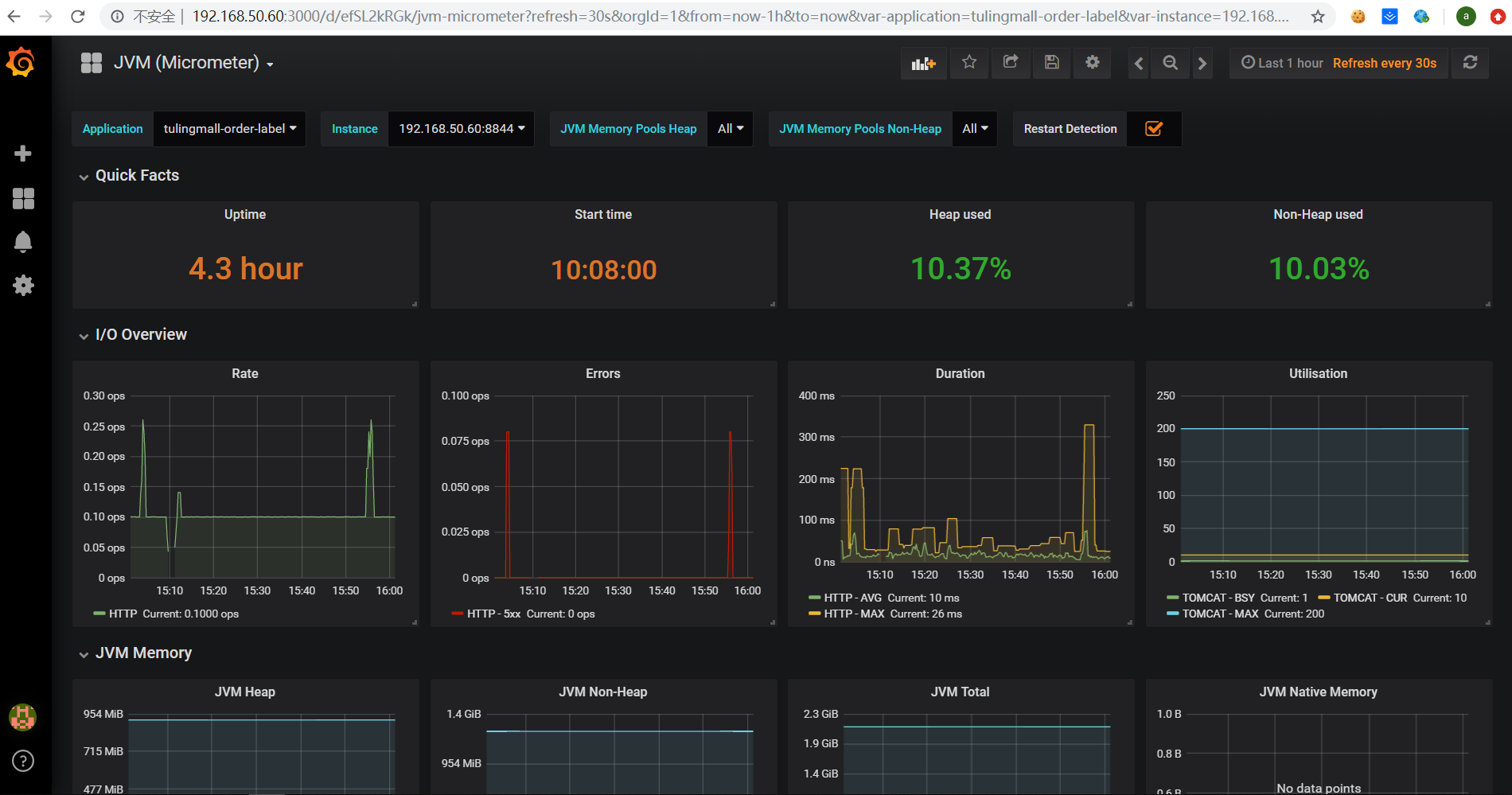
写一个监控指标报警示例,比如系统报错5XX达到一定程度就报警发邮件通知:
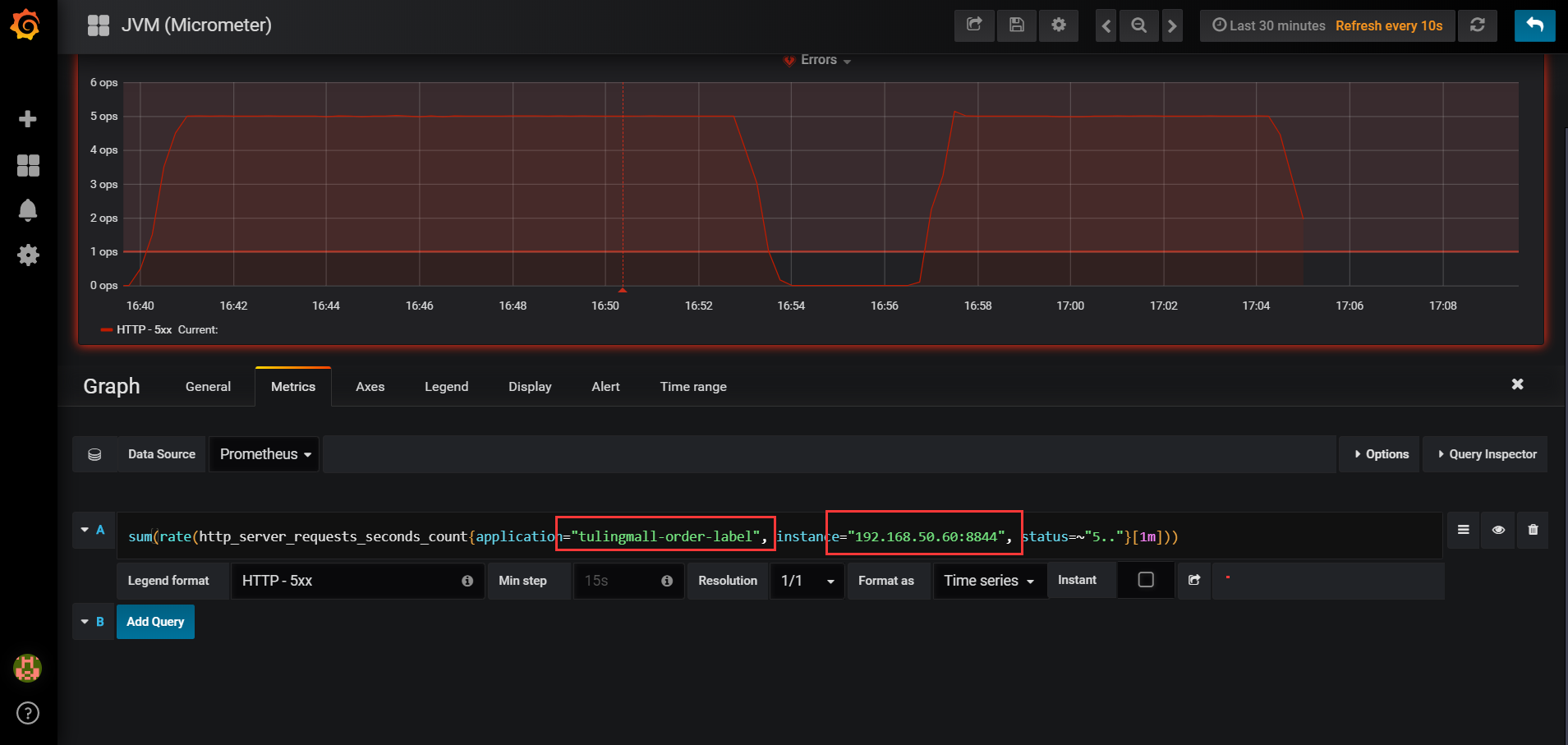
点击Errors面板选择Edit,进入到Errors指标的详细面板,如下:
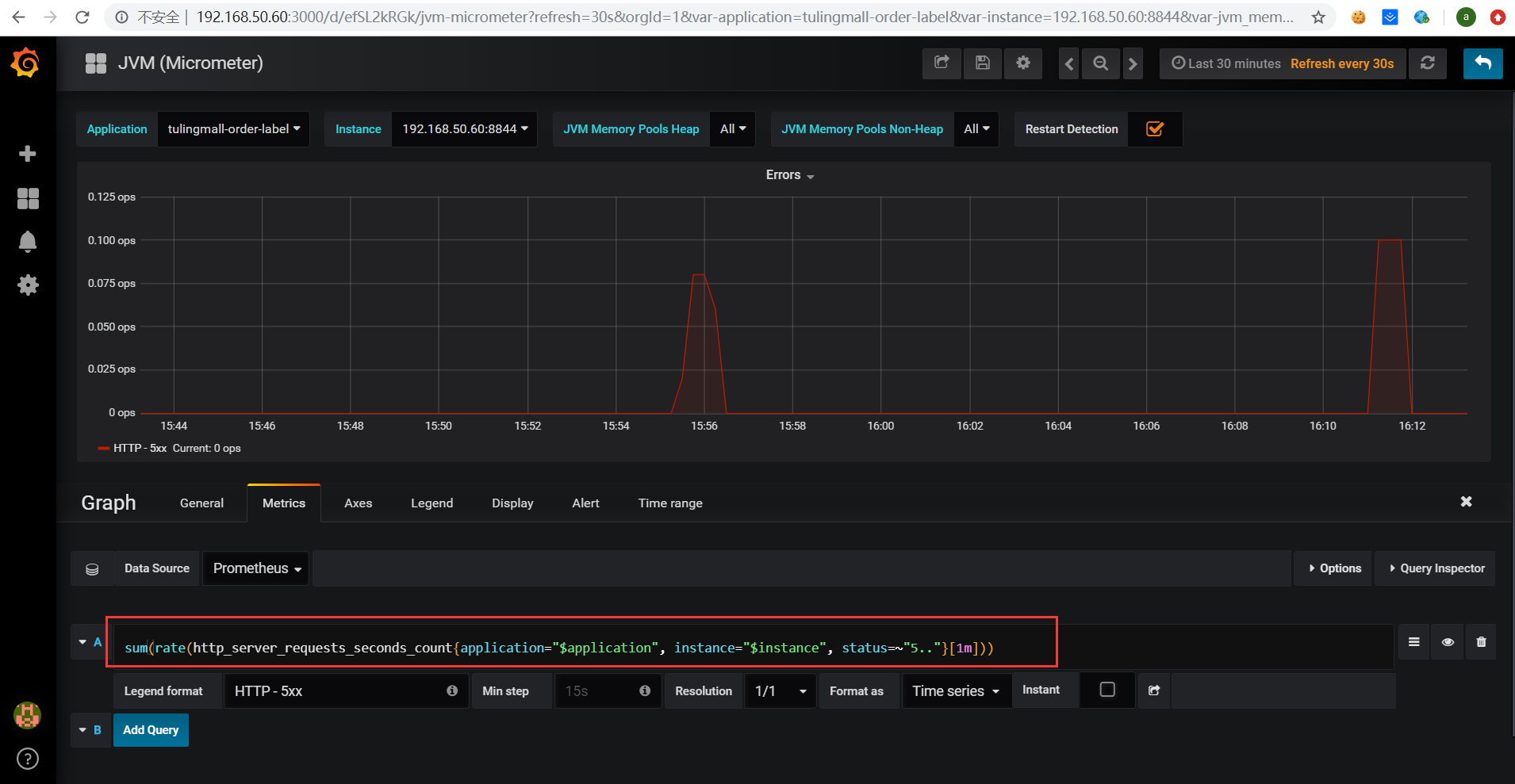
点击下图所示新增报警渠道:
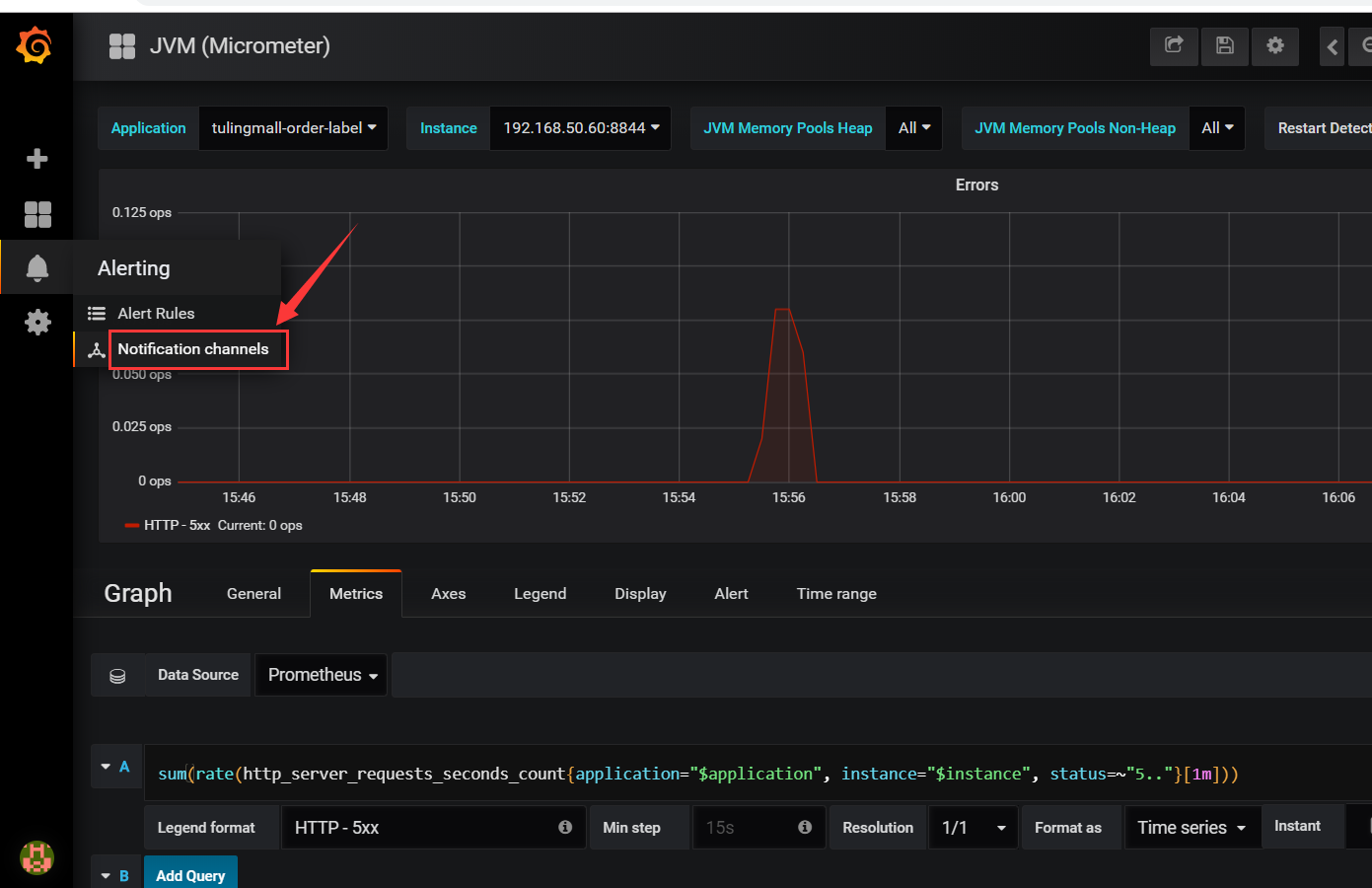
然后选择邮件报警,也可以选择webhook方式配置一个报警通知的http调用接口,这个可以间接实现所有的通知方式,如下:
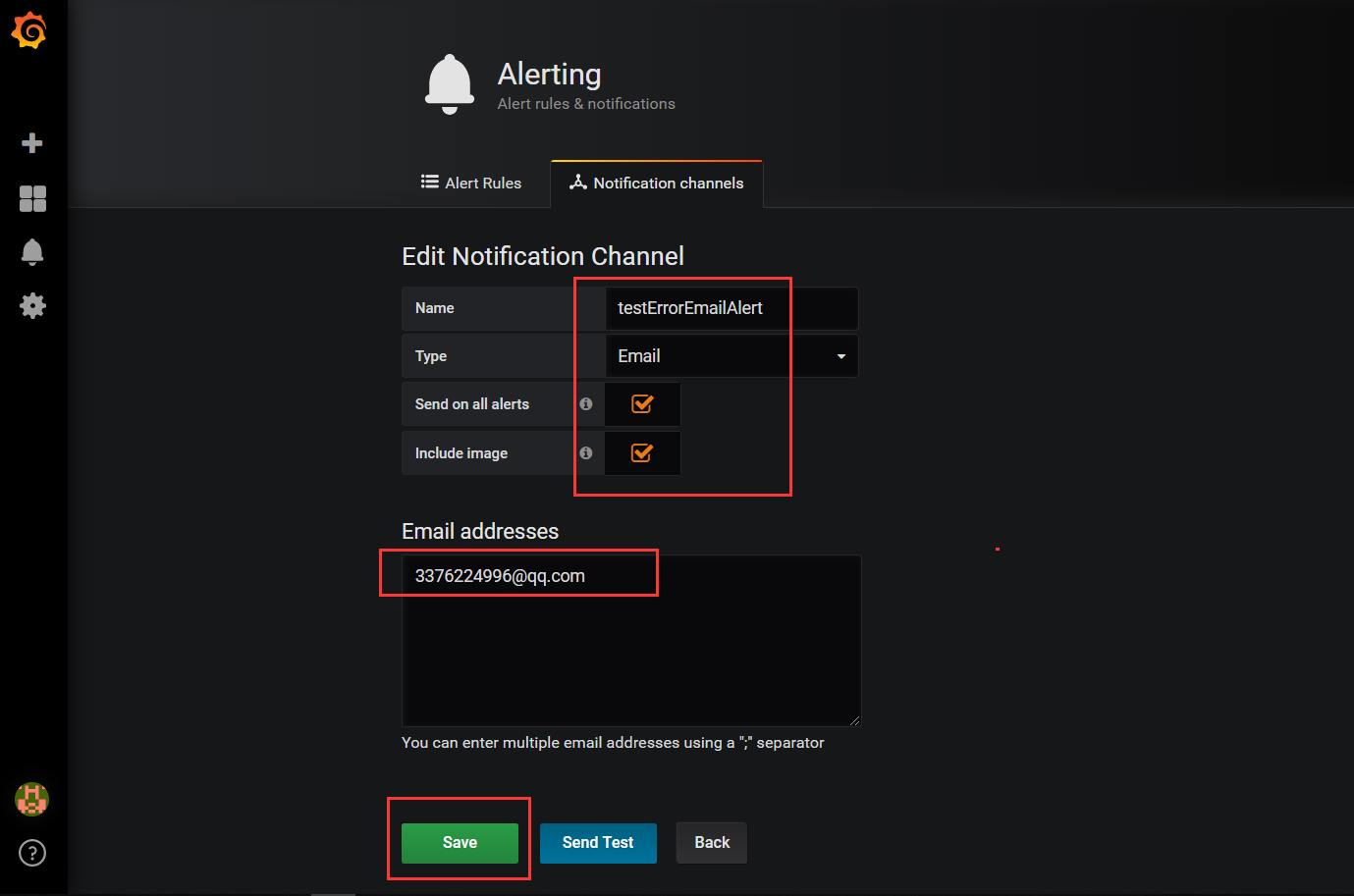
最后点击save按钮保存
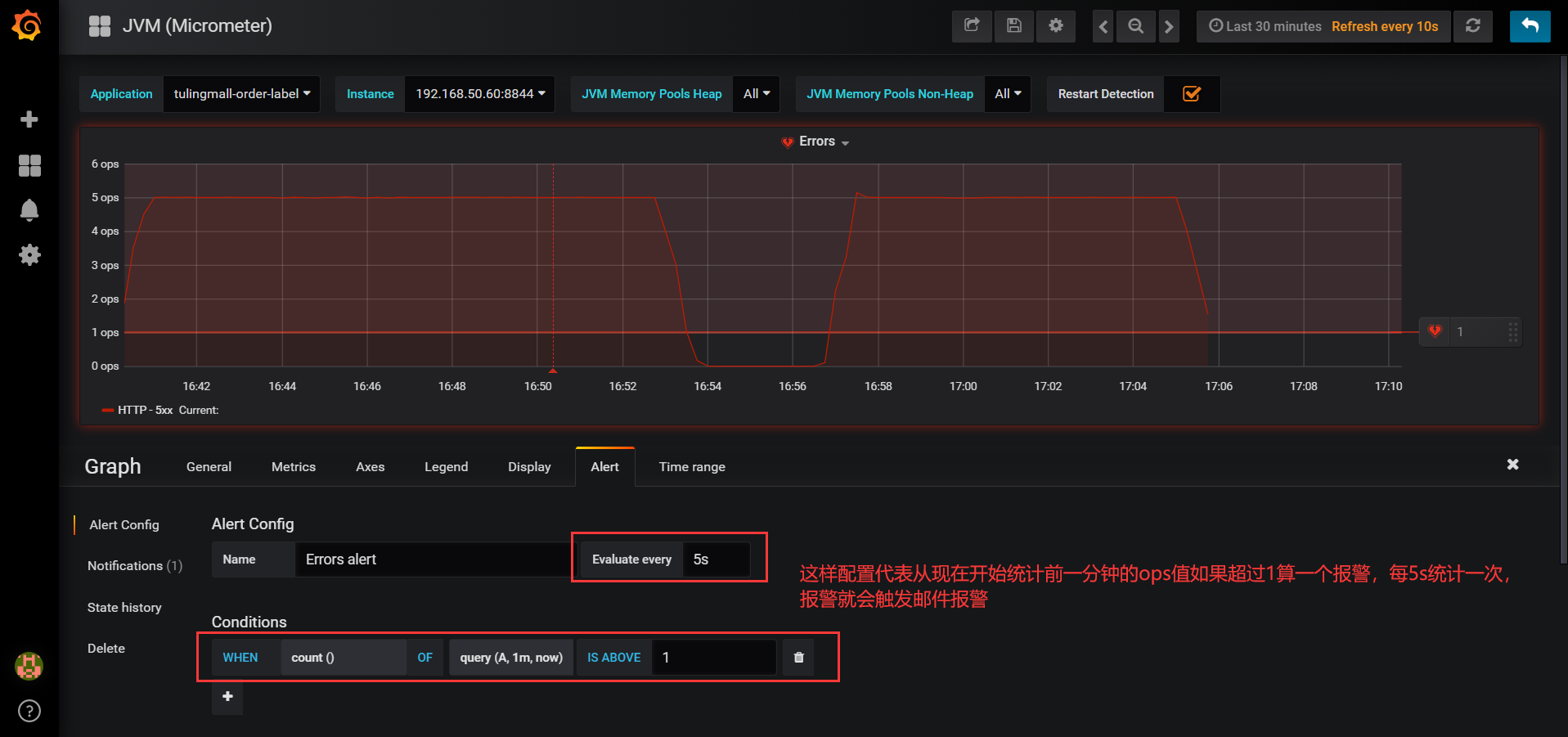
进入Errors详细页面,配置alert报警,有如下几个地方需要配置,如图所示:
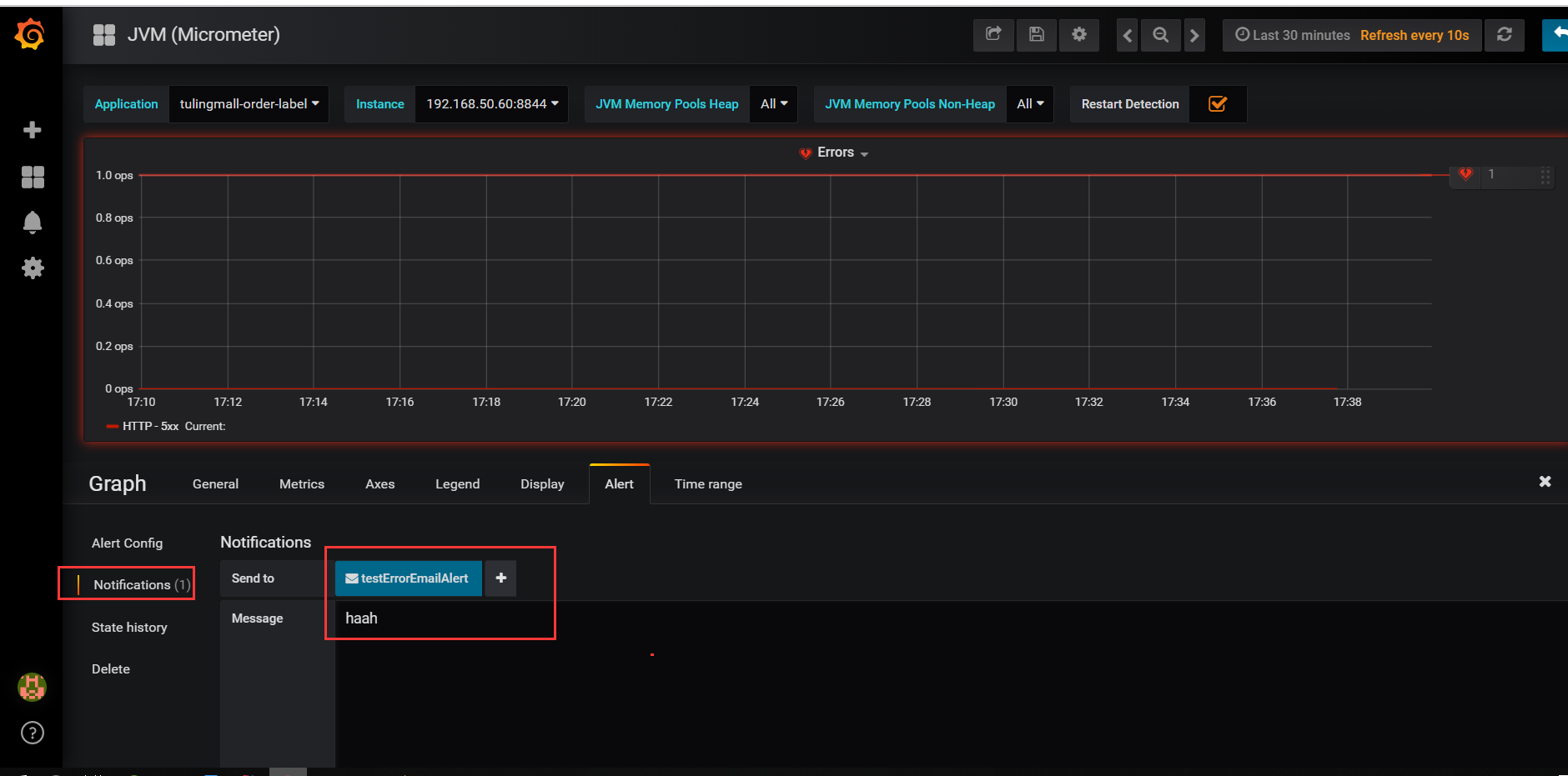
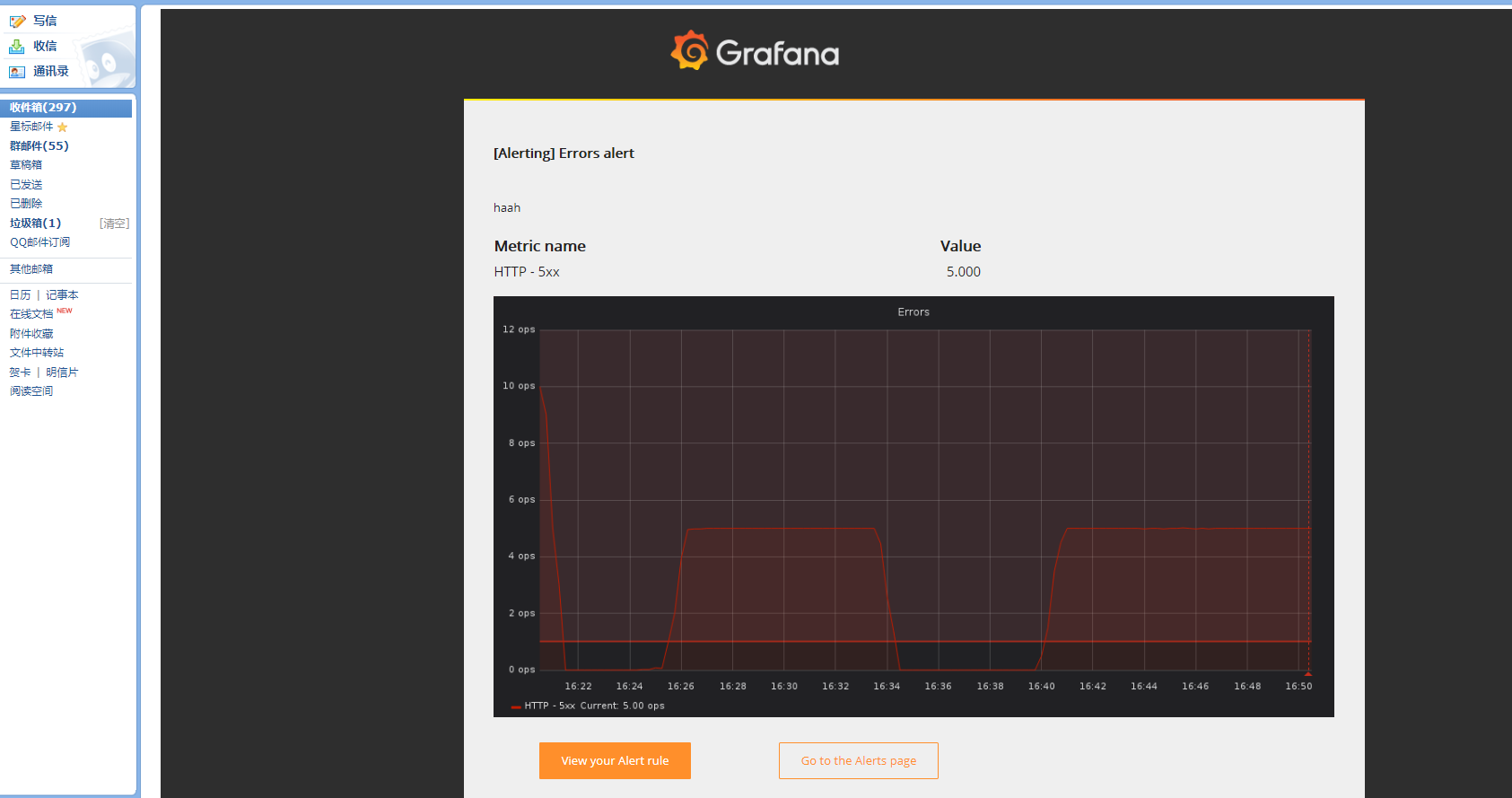
报警邮件如下所示:
监控Mysql性能指标
1、下载mysql客户端的exporter镜像
docker pull prom/mysqld-exporter2、启动监控的数据库连接,容器创建的时候需要指定
docker run -d -p 9104:9104 -e DATA_SOURCE_NAME="root:password@(mysql服务器ip:3306)/databaseName" prom/mysqld-exporter3、在prometheus.yml文件末尾追加如下配置:
- job_name: 'mysql' scrape_interval: 5s static_configs: - targets: ['192.168.50.60:9104'] labels: instance: mysql4、重新启动Prometheus镜像,查看Prometheus是否启动完成,访问:http://服务器ip:9090
docker-compose up --force-recreate -d5、导入Prometheus模板,添加mysql-dashboard.json格式模板,更多模板下载地址:
Dashboards | Grafana Labs
GitHub - percona/grafana-dashboards: PMM dashboards for database monitoring
监控Redis性能指标
1、下载redis客户端的exporter镜像
docker pull oliver006/redis_exporter2、启动监控的数据库连接,容器创建的时候需要指定
docker run -d -p 9121:9121 oliver006/redis_exporter --redis.addr redis://redis连接IP:63793、在prometheus.yml文件末尾追加如下配置:
- job_name: 'redis'
scrape_interval: 5s
static_configs:
- targets: ['192.168.50.60:9121']
labels:
instance: redis4、重新启动Prometheus镜像,查看Prometheus是否启动完成,访问:http://服务器ip:9090
docker-compose up --force-recreate -d5、导入Prometheus模板,添加redis-dashboard.json格式模板
监控Linux服务器性能指标
1、下载linux监控的exporter镜像
docker pull prom/node-exporter2、启动监控的数据库连接,容器创建的时候需要指定
docker run -d -p 9100:9100 prom/node-exporter3、在prometheus.yml文件末尾追加如下配置:
- job_name: linux
scrape_interval: 10s
static_configs:
- targets: ['IP地址1:9100']
labels:
instance: linux-1
- targets: ['IP地址2:9100']
labels:
instance: linux-2
- job_name: linux
scrape_interval: 10s
static_configs:
- targets: ['192.168.65.160:9100']
labels:
instance: linux-160
- targets: ['192.168.65.203:9100']
labels:
instance: linux-203
- targets: ['192.168.65.210:9100']
labels:
instance: linux-210
- targets: ['192.168.65.42:9100']
labels:
instance: linux-424、重新启动Prometheus镜像,查看Prometheus是否启动完成,访问:http://服务器ip:9090
docker-compose up --force-recreate -d5、导入Prometheus模板,Dashboards | Grafana Labs在这里去找自己想要的面板json导入。