python 协程
- 协程
- 为什么需要协程?
- 协程与子线程的区别
- 协程的工作原理
- 协程的优缺点
- 协程优点
- 协程缺点
- 协程的实现
- yield 关键字
- greenlet 模块
- gevent 模块
- Pool 限制并发
协程
协程又称微线程,英文名coroutine。协程是用户态的一种轻量级线程,是由用户程序自己控制调度。基于这一原理,协程能在单线程下实现并发。我们知道进程是操作系统分配资源的基本单位,线程是CPU任务调度和执行的最小单位。线程之间的切换是由于线程A遇到了等待操作(比如I/O阻塞)或者计算时间过长,由操作系统控制切换到另一线程B。而协程在遇到阻塞的时候,通过用户程序切换到另一协程,这个切换过程由程序控制,所以对操作系统来说是无感知的。相比较来说通过程序切换,比操作系统层面的切换,开销要小的多的多。
协程是一种轻量级线程, 可以在单线程中实现“并发”操作。
协程不是计算机提供的,计算机只提供:进程、线程。协程是人工创造的一种用户态切换的微进程,使用一个线程去来回切换多个进程。
为什么需要协程?
导致Python不能充分利用多线程来实现高并发,在某些情况下使用多线程可能比单线程效率更低。
由于进程和线程的切换都要消耗时间,保存线程进程当前状态以便下次继续执行。在不怎么需要cpu的程序中,即相对于IO密集型的程序,协程相对于线程进程资源消耗更小,切换更快,更适用于IO密集型。所以Python中出现了协程
协程也是单线程的,没法利用cpu的多核,想利用cpu多核可以通过,进程+协程的方式,又或者进程+线程+协程。
因为协程中获取状态或将状态传递给协程。进程和线程都是通过CPU的调度实现不同任务的有序执行,而协程是由用户程序自己控制调度的,也没有线程切换的开销,所以执行效率极高。
协程与子线程的区别
- 子程序:子程序是按层级,按顺序调用的,如A 调B,B在执行过程中又调用了C,C执行完毕返回,B执行完毕返回,最后是A执行完毕。子程序调用通过栈实现的(调用压栈,返回出栈),一个线程执行一个子程序。子程序调用总是一个入口,一次返回,调用顺序是明确的。
- 协程:协程本质也是特殊的子程序,但与线程执行过程却有很大不同,但执行过程中,在子程序内部可中断,然后转而执行别的程序,当再次调用时,程序再接着上次运行的状态继续运行。(核心特点是可中断,状态保持,有点类似CPU的上下文切换)
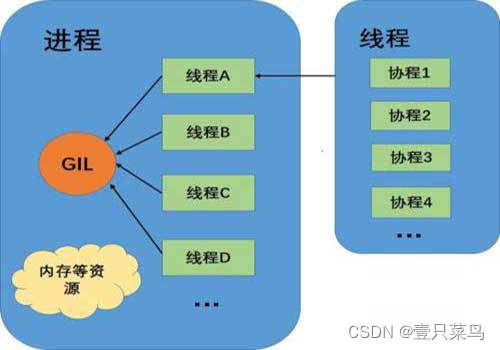
进程,线程,协程
首先,一条线程是进程中一个单一的顺序控制流,一个进程可以并发多个线程执行不同任务。协程由单一线程内部发出控制信号进行调度,而非受到操作系统管理,因此协程没有切换开销和同步锁机制,具有极高的执行效率。
线程的切换非常耗性能。但是协程的切换只是单纯的操作CPU的上下文,所以一秒钟切换个上百万次系统都抗的住。
协程的工作原理
- 协程由于由程序主动控制切换,没有线程切换的开销,所以执行效率极高。对于IO密集型任务非常适用,如果是cpu密集型,推荐多进程+协程的方式。
- 线程的切换会保存到CPU的栈里,协程拥有自己的寄存器上下文和栈,
- 协程调度切换时,将寄存器上下文和栈保存到其他地方,在切回来的时候,恢复先前保存的寄存器上下文和栈
- 协程能保留上一次调用时的状态(即所有局部状态的一个特定组合),每次过程重入时,就相当于进入上一次调用的状态
- 协程最主要的作用是在单线程的条件下实现并发的效果,但实际上还是串行的(像yield一样)
协程的作用:是在执行函数A时,可以随时中断,去执行函数B,然后中断继续执行函数A(可以自由切换)。但这一过程并不是函数调用(没有调用语句),这一整个过程看似像多线程,然而协程只有一个线程执行.
协程的主要特色
- 协程间是协同调度的,这使得并发量数万以上的时候,协程的性能是远远高于线程。
- 注意这里也是“并发”,不是“并行”。
协程的优缺点
协程优点
- 无需线程上下文切换的开销
- 无需原子操作(不会被线程调度机制打断的操作)锁定以及同步的开销
- 方便切换控制流,简化编程模型
- 适合高并发处理场景
协程缺点
- 无法利用多核资源,本质是单核的,它不能同时将单个CPU的多个核用上,协程需要和进程配合才能运行在多CPU上。可以是一个程序开启多个进程,每个进程内开启多个线程,每个线程内开启协程
- 协程指的是单个线程,多个任务一旦有一个阻塞没有切,整个线程都阻塞在原地,该线程内的其余的任务都不能执行了(可以解决)
协程的实现
协程,又称微线程,纤程,也称为用户级线程,在不开辟线程的基础上完成多任务,也就是在单线程的情况下完成多任务,多个任务按照一定顺序交替执行。通俗理解只要在def里面只看到一个yield关键字表示就是协程
为了更好使用协程来完成多任务,python中的greenlet模块对其封装,从而使得切换任务变的更加简单
gevent是对greenlet进行的封装,而greenlet又是对yield进行封装。gevent只用起一个线程,当请求发出去后 gevent就不管,永远就只有一个线程工作,谁先回来谁先处理。
为什么协程能够遇到 I/O 自动切换 ?greenlet是C语言写的一个模块,遇到 I/O 手动切换,协程有一个gevent模块,封装了greenlet模块,遇到 I/O自动切换。
Python 对协程的支持经历了多个版本:
Python2.x 对协程的支持比较有限,通过 yield 关键字支持的生成器实现了一部分协程的功能但不完全。第三方库 gevent 对协程有更好的支持。
Python3.4 中提供了 asyncio 模块。
Python3.5 中引入了 async/await 关键字。
Python3.6 中 asyncio 模块更加完善和稳定。
Python3.7 中内置了 async/await 关键字。
yield 关键字
在认识学习协程之前,首先要解一下 生成器(Generator),其本质其实是在迭代器的基础上,实现了 yield。
yield关键字通过生成器实现协程
#coding:utf-8
import time
n=0
def producer():
global n
while True:
time.sleep(1)
n+=1
print("product no.%d ball"%n, time.strftime("%X"))
yield
def consumer():
while True:
next(prd)
print("cunsum 1 ball", time.strftime("%X"))
if __name__ == "__main__":
prd = producer()
consumer()
----------------------------------
('product no.1 ball', '14:13:00')
('cunsum 1 ball', '14:13:00')
('product no.2 ball', '14:13:01')
('cunsum 1 ball', '14:13:01')
('product no.3 ball', '14:13:02')
('cunsum 1 ball', '14:13:02')
...
执行步骤解析:
- prd = producer(),第一次执行会返回一个生成器对象,而不会真正的执行该函数
- consumer(),调用并运行该函数,死循环,然后执行
next(prd)执行第一步的生成器对象 - 执行producer,死循环,输出生产包子语句,遇到yield择执行挂起并返回到consumer中继续执行上次
next()后的代码,然后次循环再次来到next() - 程序又返回到上次yield挂起的地方继续执行,依次循环执行,达到并发效果。
所以在遇到需要cpu等待的操作主动让出cpu,记住函数执行的位置,下次切换回来继续执行才能算是并发的运行,提高程序的并发效果。
协程之间执行任务按照一定顺序交替执行
greenlet 模块
为了更好使用协程来完成多任务,python中的greenlet模块对yield封装,从而使得切换任务变的更加简单
#coding:utf-8
import greenlet
import time
# 任务1
def work1():
for i in range(3):
print("work1...")
time.sleep(0.2)
# 切换到协程2里面执行对应的任务
g2.switch()
# 任务2
def work2():
for i in range(3):
print("work2...")
time.sleep(0.2)
# 切换到第一个协程执行对应的任务
g1.switch()
if __name__ == '__main__':
# 创建协程指定对应的任务
g1 = greenlet.greenlet(work1)
g2 = greenlet.greenlet(work2)
# 切换到第一个协程执行对应的任务
g1.switch()
--------------------------------------
work1...
work2...
work1...
work2...
work1...
work2...
gevent 模块
greenlet已经实现了协程,但是这个还要人工切换,这里介绍一个比greenlet更强大而且能够自动切换任务的第三方库,那就是gevent。
gevent内部封装的greenlet,其原理是当一个greenlet遇到IO(指的是input output 输入输出,比如网络、文件操作等)操作时,比如访问网络,就自动切换到其他的greenlet,等到IO操作完成,再在适当的时候切换回来继续执行。
由于IO操作非常耗时,经常使程序处于等待状态,有了gevent为我们自动切换协程,就保证总有greenlet在运行,而不是等待IO
gevent的使用
#coding:utf-8
import gevent
def work(n):
for i in range(n):
# 获取当前协程
print(gevent.getcurrent(), i)
g1 = gevent.spawn(work, 5)
g2 = gevent.spawn(work, 4)
g3 = gevent.spawn(work, 3)
g1.join()
g2.join()
g3.join()
-----------------------------
(<Greenlet at 0x2a23e88L: work(5)>, 0)
(<Greenlet at 0x2a23e88L: work(5)>, 1)
(<Greenlet at 0x2a23e88L: work(5)>, 2)
(<Greenlet at 0x2a23e88L: work(5)>, 3)
(<Greenlet at 0x2a23e88L: work(5)>, 4)
(<Greenlet at 0x2e250e0L: work(4)>, 0)
(<Greenlet at 0x2e250e0L: work(4)>, 1)
(<Greenlet at 0x2e250e0L: work(4)>, 2)
(<Greenlet at 0x2e250e0L: work(4)>, 3)
(<Greenlet at 0x2e25178L: work(3)>, 0)
(<Greenlet at 0x2e25178L: work(3)>, 1)
(<Greenlet at 0x2e25178L: work(3)>, 2)
可以看到,3个greenlet是顺序运行而不是交替运行
gevent切换执行
#coding:utf-8
import gevent
def work(n):
for i in range(n):
# 获取当前协程
print(gevent.getcurrent(), i)
#用来模拟一个耗时操作,注意不是time模块中的sleep
gevent.sleep(1)
g1 = gevent.spawn(work, 5)
g2 = gevent.spawn(work, 4)
g3 = gevent.spawn(work, 3)
g1.join()
g2.join()
g3.join()
-----------------------------
(<Greenlet at 0x2ae3e88L: work(5)>, 0)
(<Greenlet at 0x2e350e0L: work(4)>, 0)
(<Greenlet at 0x2e35178L: work(3)>, 0)
(<Greenlet at 0x2ae3e88L: work(5)>, 1)
(<Greenlet at 0x2e35178L: work(3)>, 1)
(<Greenlet at 0x2e350e0L: work(4)>, 1)
(<Greenlet at 0x2ae3e88L: work(5)>, 2)
(<Greenlet at 0x2e350e0L: work(4)>, 2)
(<Greenlet at 0x2e35178L: work(3)>, 2)
(<Greenlet at 0x2ae3e88L: work(5)>, 3)
(<Greenlet at 0x2e350e0L: work(4)>, 3)
(<Greenlet at 0x2ae3e88L: work(5)>, 4)
monkey.patch_all()
用过 gevent 的开发者都知道,在开头导入monkey.patch_all(),非常重要,会自动将 python 的一些标准模块替换成 gevent 框架,这个补丁其实存在着一些坑:
monkey.patch_all(),网上一般叫猴子补丁。如果使用了这个补丁,gevent 直接修改标准库里面大部分的阻塞式系统调用,包括 socket、ssl、threading 和 select 等模块,而变为协作式运行。有些地方使用标准库会由于打了补丁而出现奇怪的问题(比如会影响 multiprocessing 的运行)
和一些第三方库不兼容(比如不能兼容 kazoo)。若要运用到项目中,必须确保其他用到的网络库明确支持Gevent。
在实际情况中协程和进程的组合非常常见,两个结合可以大幅提升性能,但直接使用猴子补丁会导致进程运行出现问题。其实可以按以下办法解决,将 thread 置成 False,缺点是无法发挥 monkey.patch_all() 的全部性能:
monkey.patch_all(thread=False, socket=False, select=False)
#coding:utf-8
import gevent
import time
from gevent import monkey
# 打补丁,让gevent框架识别耗时操作,比如:time.sleep,网络请求延时
monkey.patch_all()
# 任务1
def work1(num):
for i in range(num):
print("work1....")
time.sleep(0.2)
# 任务1
def work2(num):
for i in range(num):
print("work2....")
time.sleep(0.2)
if __name__ == '__main__':
# 创建协程指定对应的任务
g1 = gevent.spawn(work1, 3)
g2 = gevent.spawn(work2, 3)
# 主线程等待协程执行完成以后程序再退出
g1.join()
g2.join()
--------------------------------------
work1....
work2....
work1....
work2....
work1....
work2....
对比前面"greenlet 模块"的示例,遇到耗时操作时,我们不需要手动切换协程
如果使用的协程过多,如果想启动它们就需要一个一个的去使用join()方法去阻塞主线程,这样代码会过于冗余,可以使用gevent.joinall()方法启动需要使用的协程
#coding:utf-8
import time
import gevent
def work1():
for i in range(5):
print("work1工作了{}".format(i))
gevent.sleep(1)
def work2():
for i in range(5):
print("work2工作了{}".format(i))
gevent.sleep(1)
if __name__ == '__main__':
gevent.joinall([gevent.spawn(work1), gevent.spawn(work2)]) # 参数可以为list,set或者tuple
Pool 限制并发
协程虽然是轻量级线程,但并发数达到一定量级后,会把系统的文件句柄数占光。所以需要通过 Pool 来限制并发数。
#coding:utf-8
import gevent
from gevent.pool import Pool
from gevent import monkey
monkey.patch_all()
import time,datetime
def test(tm):
time.sleep(tm)
print('时间:{}'.format(datetime.datetime.now()))
if __name__ =='__main__':
task = []
# 限制最大并发
pool = Pool(5)
# 分配100个任务,最大并发数为5
for i in range(20):
task.append(pool.spawn(test,2))
gevent.joinall(task)
----------------------------------------
时间:2023-12-13 11:33:18.082000
时间:2023-12-13 11:33:18.082000
时间:2023-12-13 11:33:18.082000
时间:2023-12-13 11:33:18.082000
时间:2023-12-13 11:33:18.082000
...
时间:2023-12-13 11:33:24.088000
时间:2023-12-13 11:33:24.088000