一场久违的老友对谈,一次精妙的 AI 探索碰撞。
近日,Milvus 老友汇·Arch Meetup 在上海圆满落幕。本次 Meetup 亮点颇多,不仅得到了 KubeBlocks 社区的大力支持,同时也邀请了来自网易伏羲和蚂蚁集团的资深专家,现场分享各自对于 AI 时代云原生与向量数据库的思考。

接下来,让我们快速回顾一下本次活动的主要观点:
Zilliz 资深工程师 夏琮祺 :无论是架构、新功能、性能还是可维护性,Milvus 2.3.x 都是向量数据库中的佼佼者,绝对值得一试
网易伏羲资深 AI 研发工程师 陈京来 :Milvus 在网易图文多模态场景的实践中显示,其有效地支撑了网易伏羲十亿级图文数据及应用落地
云猿生数据资深工程师 郭子昂:使用 KubeBlocks 轻松管理向量数据库 + LLM 等 AIGC 数据基础设施
蚂蚁集团工程师 徐鹏飞:使用 KCL 声明式配置语言和工具应对工程化配置策略挑战
以下为详细解读,大家可按需享用:
01.Milvus 2.3.x 新功能解读
夏琮祺从架构、新功能、性能和可维护性方面对 Milvus 2.3.x 进行了全方位的解读。

他首先提到,Milvus 2.3.x 在架构方面进行了升级,包括对异构硬件的支持(GPU Index:RAFT;ARM)、升级 QueryNode(QueryNodeV2)。夏琮祺着重介绍了 QueryNodeV2 。QueryNode 承担了整个Milvus 系统中最重要的检索服务,其稳定性、性能、扩展性对 Milvus 至关重要,但 QueryNodeV1 存在状态复杂、消息队列重复、代码结构不清晰、报错内容不直观等问题。在 QueryNodeV2 的新设计中,团队重新梳理了代码结构、将复杂的状态改为无状态的设计、移除了 delete 数据的消息队列减少了资源浪费,在后续持续的稳定性测试中,QueryNodeV2 的表现更加优异。
新功能方面,Milvus 2.3.x 上线的这些功能值得重点关注:
-
Upsert:由于 Milvus 现在还不支持 update 操作,用户需要更新向量时需要删除旧有的记录后并重新插入。在2.3版本,Milvus 提供的 Upsert 接口,保证了一个原子性的“修改”操作;
-
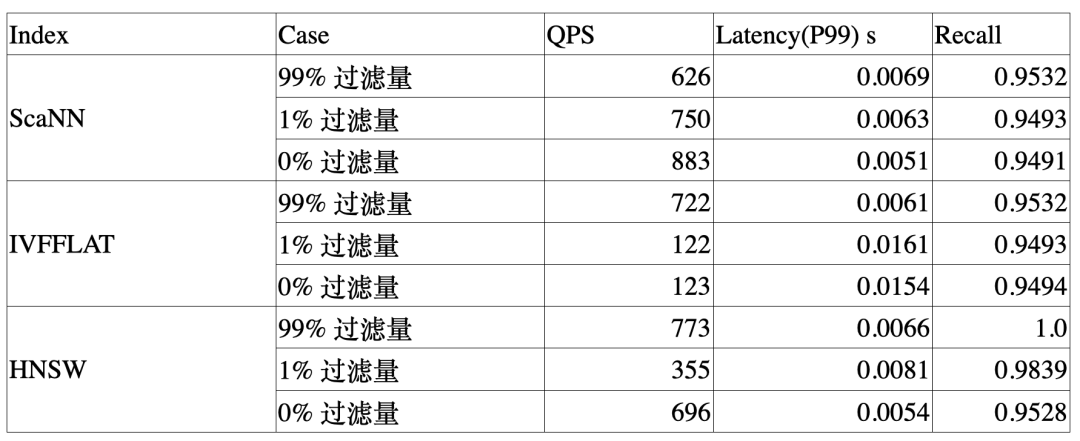
SCANN Index:Knowhere 2.0,支持了 SCANN 索引;
-
Iterator (pymilvus only):Milvus 的 Search 和 Query 都有数据上线,当用户需要查询大量乃至全量数据的时候,现存的接口无法完全满足这一需求。在 Milvus 支持 range search 后,pymilvus 通过动态调整 range 的方式模拟了一套 Iterator 接口,可以返回用户所需要的大批量数据;
-
Delete By Expression:Delete 接口,在 2.3 之前只能通过主键表达式来做删除(ID in [1, 2, 3, …])。用户想要删除一些满足条件的数据时,需要先 Query 其主键,再执行删除操作,Delete by expression 提供了 Milvus 服务端的“语法糖”,在系统内部完成了这一操作。
不止如此,Milvus 2.3.x 还支持 MMap、Growing Index、支持动态修改配置、CDC 等,大大提升了 Milvus 的整体性能和可运维性,感兴趣的同学可以查看 Milvus 2.3.x 系列文章了解详情。
02.Milvus 在网易图文多模态场景的实践
陈京来分享了“Milvus 在网易图文多模态场景的实践”。他表示,加大模型规模及提升数据质量是获得更好的人工智能效果的重要手段。
网易伏羲从事大模型的研究 5 年的时间,积累了丰富的算法和工程经验,先后打造了数十个文本和多模态预训练模型。而向量在大型语言模型中起着重要作用,例如:Embedding——基于 AI 的工具和算法,可以将非结构化的数据,如文本、图像、音频和视频等映射到低维度空间表示为 embedding。

如今,伏羲图文数据已经积累了 10 亿+ 互联网数据以及网易自有版权数据,有着大量图文检索的需求,相应地也带来了各种挑战:
-
资源占用高:占用大量的计算、存储资源
-
异构资源:GPU、CPU、SSD 等不同类型资源
-
业务类型复杂:图文多模态、NLP、用户画像等多种业务,不同业务数据规模、时延、服务质量、召回精度等不同
-
稳定性和可靠性
在此情况下,如何构建一个高性能、高可靠、异构的图文向量引擎至关重要。Milvus 架构具有云原生、存储计算分离、分布式、冗余和高可用等特点,在其助力下,网易伏羲实现了十亿级 Milvus 集群的创建。

此外,陈京来亦提到,在攻坚任务等研发框架下,伏羲启动了图文多模态领域能力的积累及应用探索。自研了支持中文场景的图文生成模型“丹青”,基于此推出了AI 绘画平台“丹青约”,而 LangChain + Milvus 可以构建丹青约绘画 Agent。
对于未来,陈京来期待用 Milvus 探索检索增强生成(RAG)以提升图文多模态模型能力,以及借助更多 Milvus+ 的能力提升图文多模态场景的应用落地。
03.KubeBlocks:轻松管理 AIGC 数据基础设施

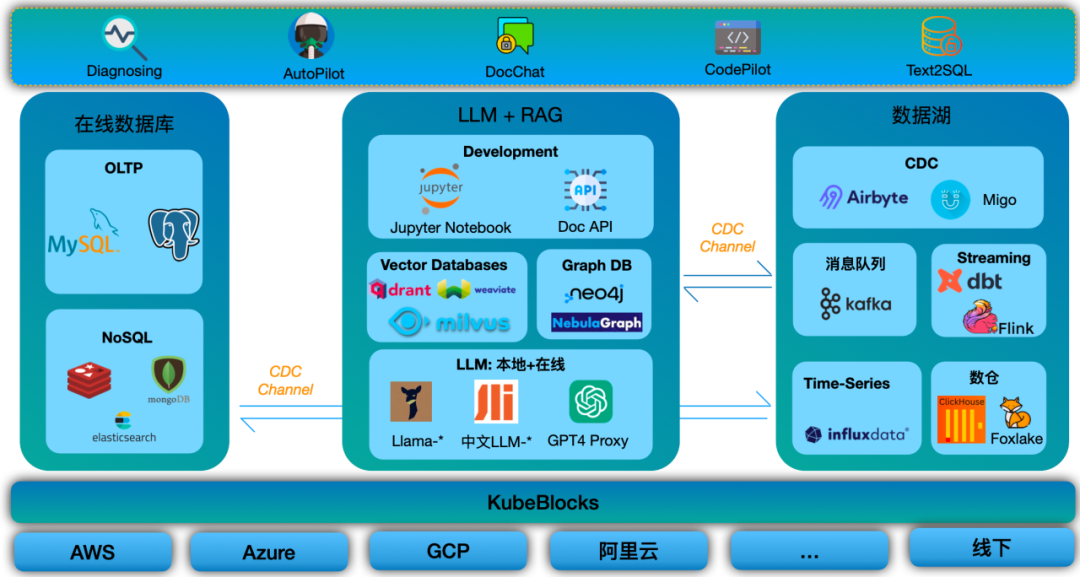
郭子昂以《KubeBlocks:轻松管理 AIGC 数据基础设施》为主题,讲解了 AI 时代背景下,KubeBlocks 的 AIGC 数据基础设施解决方案:KubeBlocks 通过提供向量数据库托管和 LLM 托管能力,帮助用户构建自己的 AI 应用,极大地降低了应用开发者的负担。
-
KubeBlocks 的数据库托管能力
KubeBlocks 作为开源管控平台,可运行和管理 K8s 上的数据库、消息队列及其他数据基础设施。基于这一特点,KubeBlocks 的解决方案采用托管向量数据库(如 Milvus)和图数据库(如NebulaGraph)的方式,实现多云和线下部署,在实现快速 day-1 集成的同时,也提供了丰富的 day-2 运维操作。
KubeBlocks 依靠其强大的集成和抽象能力,可快速实现数据库集成。郭子昂以 Milvus 为例,展示了根据 KubeBlocks 的 API 在 YAML 文件中定义 Milvus 各种特性、运维配置,轻松实现向量数据库全生命周期管理。
-
KubeBlocks 的 LLM 托管能力
KubeBlocks 具有强大的 LLMOps 能力,支持托管 LLM 及多种大模型。基于 KubeBlocks,开发者可实现 LLM 私有化部署,同时支持定制化大模型,实现行业数据的精细调整。此外,KubeBlocks 的 LLMOps 能力还支持 LLM 开发环境私有化部署、分布式部署、高性能 batching,充分适配本地开发环境和生产环境,提升 GPU 利用率。
-
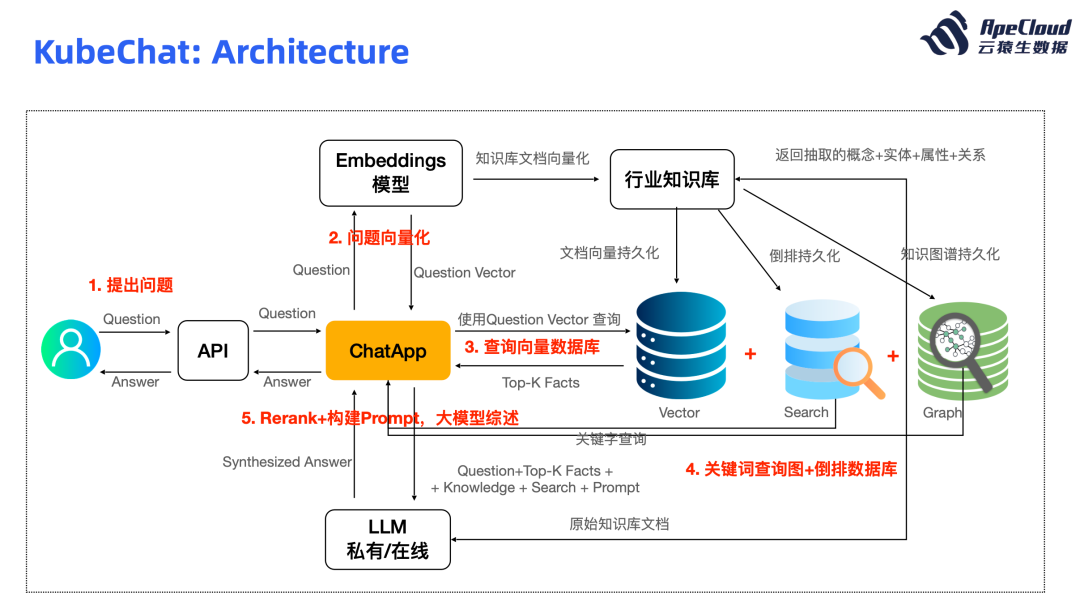
KubeChat:KubeBlocks AIGC 解决方案落地
基于上述解决方案,KubeBlocks 已成功落地 AI 应用,在 10 天时间开发出 AI 知识库应用 KubeChat,轻松应对 Embedding、向量数据库和大模型在开发 AI 应用过程中带来的各类挑战。
04.KCL 在 AI 工程配置策略场景的探索和落地使用

徐鹏飞分享了《KCL 在 AI 工程配置策略场景的探索和落地使用》。平台工程和 AI 工程的发展日益迅猛,但这也带来了问题和挑战,比如认知负担、配置/数据种类繁杂、配置/数据清洗过程易出错、效率可靠性低等。KCL 作为专用配置策略语言为配置和自动化提供了解决方案,以收敛的语言和工具集合解决领域问题近乎无限的变化和复杂性,同时兼顾表达力和易用性。
此外,KCL 以数据和模型为中心,采用开发者可以理解的声明式 Schema/配置/策略模型用于 AI 工程、云原生工程等场景。KCL 为开发人员提供了通过记录和函数语言设计将配置(config)、建模抽象(schema)、逻辑(lambda)和策略(rule)作为核心能力,具有可复用可扩展、抽象和组合能力、稳定性、高性能等特点。
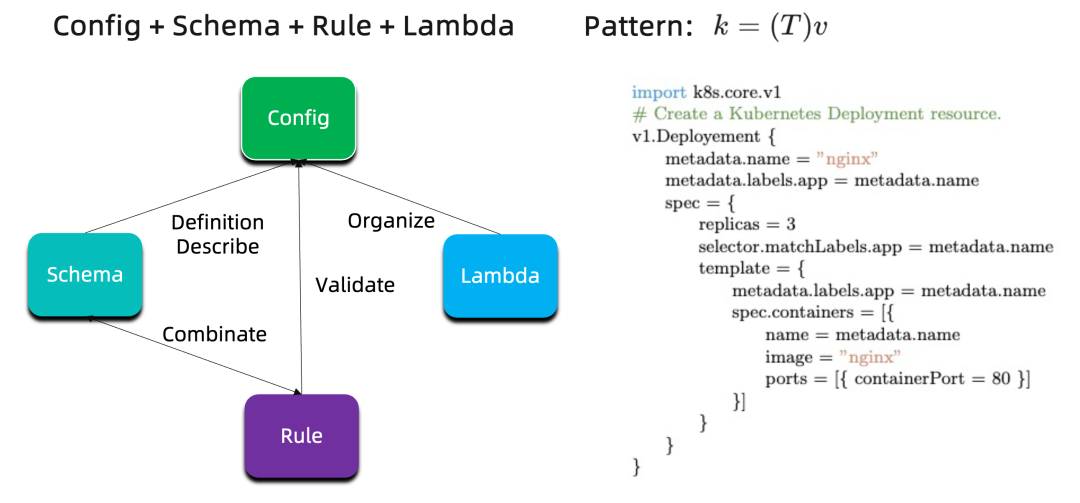
KCL 可以广泛用于表格数据集验证和转换、云原生配置验证和转换、通过抽象进行应用交付、IaC & GitOps等场景。KCL 也注重开发者体验,提供完备的 Language + Tools + IDEs + SDKs + Plugins 工具链支持,还支持模型 Registry。
彩蛋:看看模型 Registry 里出现了谁?

关注 Zilliz 微信公众号,回复关键词【老友汇上海】获取现场嘉宾 PPT。
本文由 mdnice 多平台发布












![[多线程]线程池](https://img-blog.csdnimg.cn/direct/ace478d3bf1c4884b0baca6ed360a009.png)