进程地址空间与进程控制
文章目录
- 进程地址空间与进程控制
- 1. 进程地址空间
- 1.1 进程地址空间的引入
- 1.1 进程地址空间的特点
- 1.2 页表
- 1.3 C/C++的地址
- 1.4 进程地址空间 + 页表的优势
- 2. 进程控制
- 2.1 进程创建
- 2.1.1 写时拷贝
- 2.2 进程终止
- 2.2.1 进程退出码
- 2.2.2 异常信号码
- 2.2.3 errno
- 2.2.4 总结
- 2.3 进程等待
- 2.3.1 wait()
- 2.3.2 形参*status
- 2.3.3 waitpid()
本章思维导图:
 注:本章思维导图对应的
注:本章思维导图对应的
.xmind和
.png文件都已同步导入至
资源
1. 进程地址空间
1.1 进程地址空间的引入
以前我们可能看过如下图类似的不同数据的地址分布图:
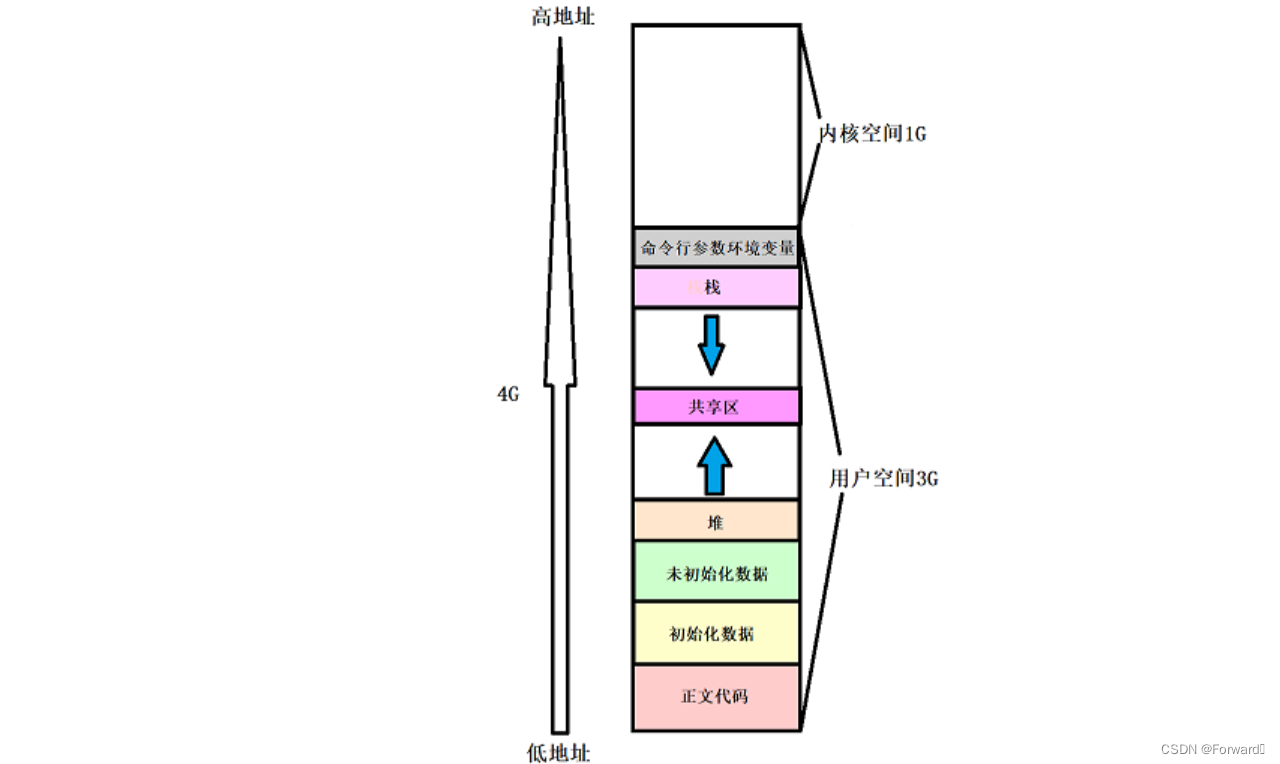
我们可以通过打印部分数据的地址来验证上图的正确性:
#include <stdio.h> int a; int b = 1; void Func(){}; int main() { printf("main = %p\n", main); printf("Func = %p\n", Func); printf("&a = %p\n", &a); printf("&b = %p\n", &b); return 0; }output:
main = 0x40050e Func = 0x400507 &a = 0x601034 &b = 0x60102c即地址:
正文代码 < 初始化数据 < 未初始化数据
示例二:
#include <stdio.h> #include <stdlib.h> int main() { int a[2]; int A[2]; int* b = (int*)malloc(sizeof(int) * 2); int* B = (int*)malloc(sizeof(int) * 2); for (int i = 0; i < 2; i++) printf("a[%d] = %p\n", i, &a[i]); printf("\n"); for (int i = 0; i < 2; i++) printf("b[%d] = %p\n", i, &b[i]); printf("\n"); for (int i = 0; i < 2; i++) printf("A[%d] = %p\n", i, &A[i]); printf("\n"); for (int i = 0; i < 2; i++) printf("B[%d] = %p\n", i, &B[i]); return 0; }output:
a[0] = 0x7ffd9342fc38 a[1] = 0x7ffd9342fc3c b[0] = 0x1944010 b[1] = 0x1944014 A[0] = 0x7ffd9342fc30 A[1] = 0x7ffd9342fc34 B[0] = 0x1944030 B[1] = 0x1944034可以得出两个结论:
- 栈空间地址高于堆空间
- 栈空间的地址是从高到低减小的,堆空间的地址是从低到高增大的
示例三:
重点来了
#include <stdio.h> #include <stdlib.h> #include <sys/types.h> #include <unistd.h> int main() { pid_t id = fork(); //利用系统调用fork()创建一个子进程 int num = 10; if (id == 0) { num = 0; printf("子进程,num = %d, address = %p\n", num, &num); exit(-1); } printf("父进程,num = %d, adderss = %p\n", num, &num); return 0; }output:
父进程,num = 10, adderss = 0x7ffca5330fb8 子进程,num = 0, address = 0x7ffca5330fb8大家应该发现了两个奇怪的现象:
- 拥有相同名字的变量
num,为什么可以同时拥有两个不同的值10和0呢?- 假设父进程的
num和子进程的num不同,那么两个不同的变量为什么可以有相同的地址0x7ffca5330fb8
对于第一个问题,我们首先给出结论:父进程的num和子进程的num确实不是同一个变量。我们将在进程控制一节进行详细的说明
对于第二个问题:
- 首先我们应该清楚,每一个变量都对应着一块独一无二的内存地址(物理内存)。换句话说,对于物理内存,不同变量的地址是绝对不同的
- 因此,对于示例三两个不同的变量却有相同地址的情况,我们可以得出结论:用
%p打印出的地址绝对不是物理地址 - 不是物理地址,那是什么?这种地址就是我们这一节要讨论的虚拟地址。
- 我们最上面放出的图不是物理内存,而是进程地址空间

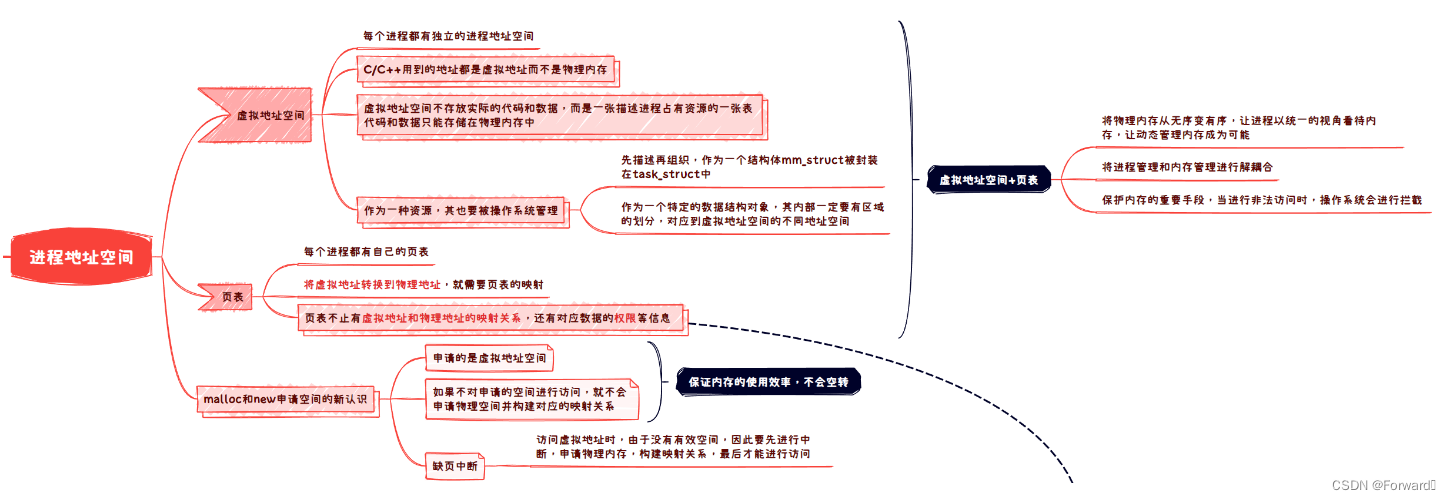
1.1 进程地址空间的特点
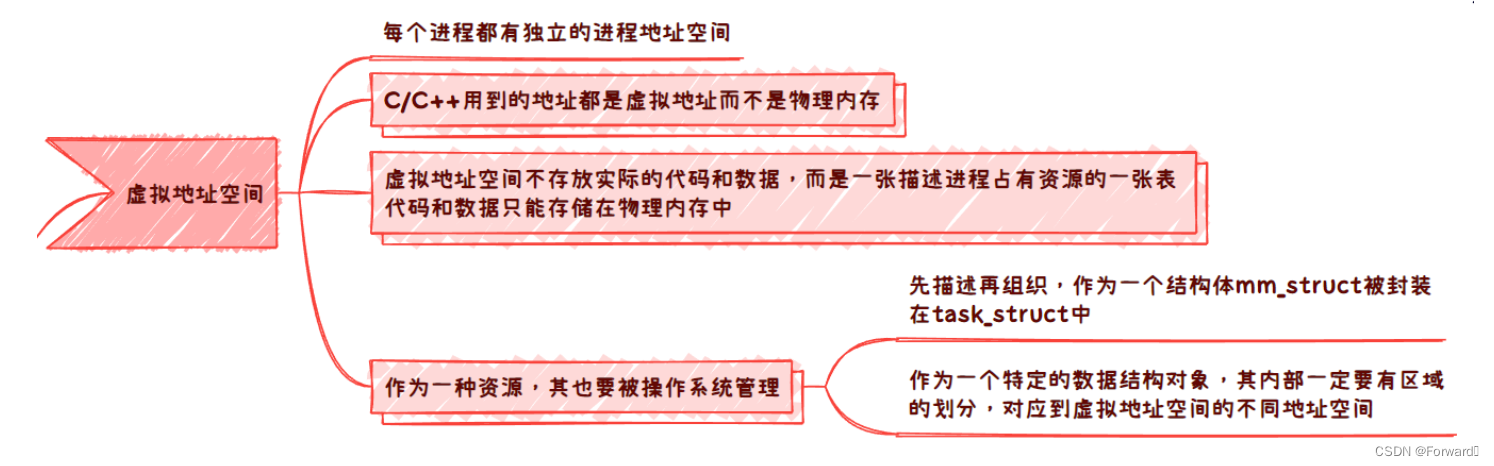
- Linux中,每个进程都认为自己独占内存,因此每个进程都有一个地址空间,也就是进程地址空间,在32位系统中,这块地址空间的大小为整个内存的大小即4GB(232bit)
- 进程地址空间并不是真正的内存,因此并不会真正存储代码和数据,可以认为他只是一张描述进程占有资源的一张表。进程的代码和数据实际上还是存储在物理内存中
- 进程地址空间也是一种资源,因此也要被操作系统管理。
- 如何管理?先描述再组织,因此描述进程地址空间的各种信息都被组织在了一个结构体
mm_struct中,而mm_struct同时作为描述一个进程的信息,其会被封装在进程的task_struct中 - 同时,为了对应到上图各种地址的分布,
mm_struct中一定有区域的划分,即用变量记录了各个区域的起始地址和结束地址
- 如何管理?先描述再组织,因此描述进程地址空间的各种信息都被组织在了一个结构体
现在问题来了:
既然虚拟地址并不存放代码和数据,那我们是通过什么来找到一个虚拟地址对应的物理地址呢?
答案是页表
1.2 页表

- 每个进程都有独自的进程地址空间,那自然也要有独自的页表
- 页表存放着虚拟地址和物理地址的映射关系,这样,虚拟地址就可以通过页表的映射来找到对应的物理内存
- 页表不仅有虚拟地址和物理地址的关系,同时还记录着对应数据的权限信息。
- 例如,为什么字符串常量不能修改?就是因为其存放的虚拟地址区域在页表的权限为只读,因此当要对这块空间进行写操作时,操作系统就会根据页表的权限终止对物理内存的映射,也就无法改变常量的内容了。
1.3 C/C++的地址
在引入部分的示例三中,我们通过%p打印出的地址实际上是虚拟地址,实际上C/C++用到的地址全都是虚拟地址
既然如此,那我们便会对malloc和new动态开辟内存有更深入的理解:
malloc、new申请的空间实际上都是虚拟地址的空间,一开始并没有实际申请物理内存- 当要对开辟的空间进行写操作时,就会进行缺页中断:
- 由于虚拟地址并不会实际存放代码和数据,因此首先要先申请物理内存的空间并通过页表构建映射关系,最后才能进行写入
这样做有两个好处:
- 可以提高
malloc、new申请空间的效率(一开始并不要申请物理内存并构建映射关系)- 可以防止空转,节省资源,提高空间利用率(申请的空间可能并不会使用)
1.4 进程地址空间 + 页表的优势

将物理内存从无序变有序,让进程以统一的视角看待内存。并让动态管理内存成为可能
- 物理内存通常由多个内存块组成,其并没有固定的顺序;而虚拟地址是连续且有序的进程地址空间,因此可以通过页表的映射关系,让物理内存从无序变有序
- 进程可以通过虚拟地址空间+页表这种方式统一看待内存
- 由于虚拟地址空间是连续且有序的,因此也可以很方便的开辟并释放空间,并通过页表的映射实现动态内存管理,并提高内存利用率:
- 当要动态开辟数据时,可以通过页表映射到一块空闲的内存区域
- 当释放掉一块动态开辟的空间后,可以将这块空间重新映射到其他进程的虚拟地址空间
将进程管理和内存管理进行解耦合
虚拟地址空间并不存放实际的代码和数据,因此可以在不改变代码和数据的前提下动态管理内存
是保护内存的重要手段
- 由于页表存储着相关数据的权限信息,因此当要进行非法访问时,操作系统会根据这个权限直接终止
- 如果进程都是在物理内存直接开辟,那么当进行内存的动态开辟时,可能会和其相邻的进程空间产生影响,导致进程的不连续
2. 进程控制
2.1 进程创建
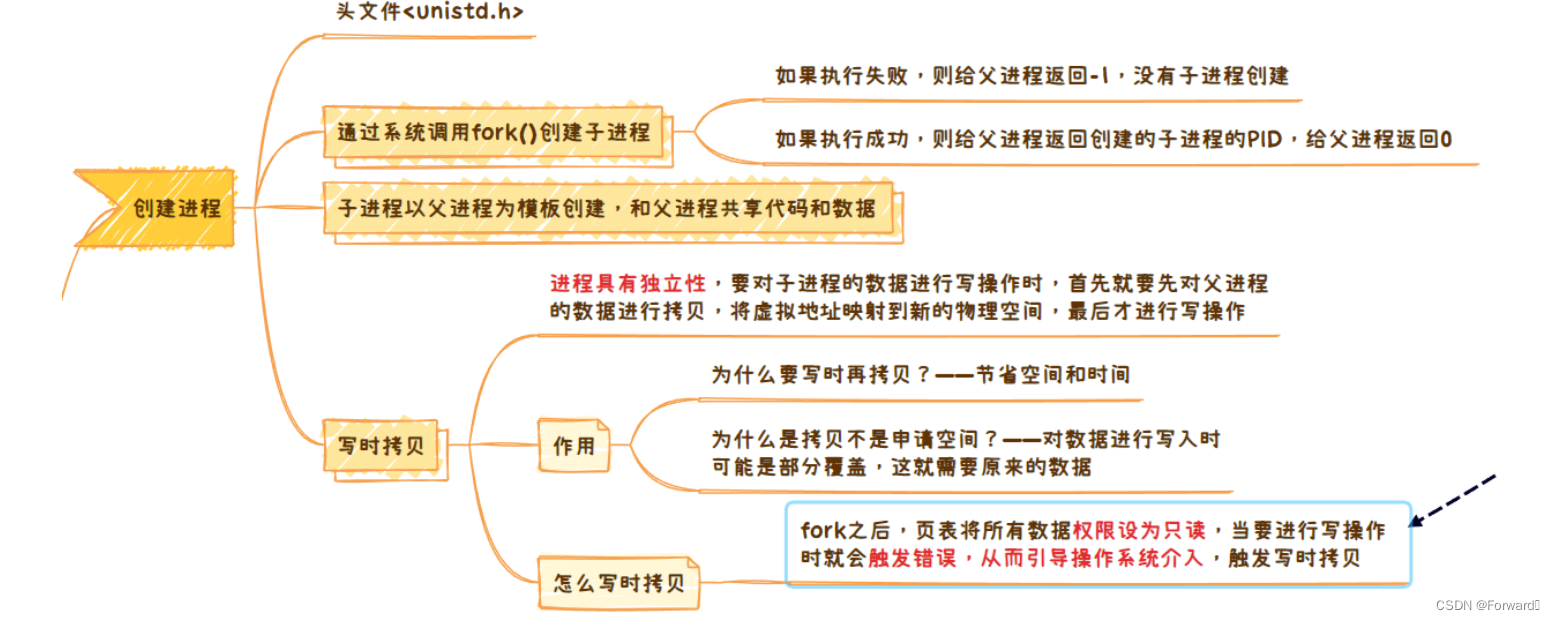
需要包含头文件
<unistd.h>
Linux通过**系统调用forK()**创建子进程
函数原型:
pid_t fork(void);
- 该函数没有形参
- 返回类型
pid_t实际上就是短整形short。- 如果创建子进程成功,那就给子进程返回0,给父进程返回子进程的`PID
- 如果子进程创建失败,那么就会给父进程返回-1
子进程以父进程为模板创建,和父进程共享代码和数据。如图所示:
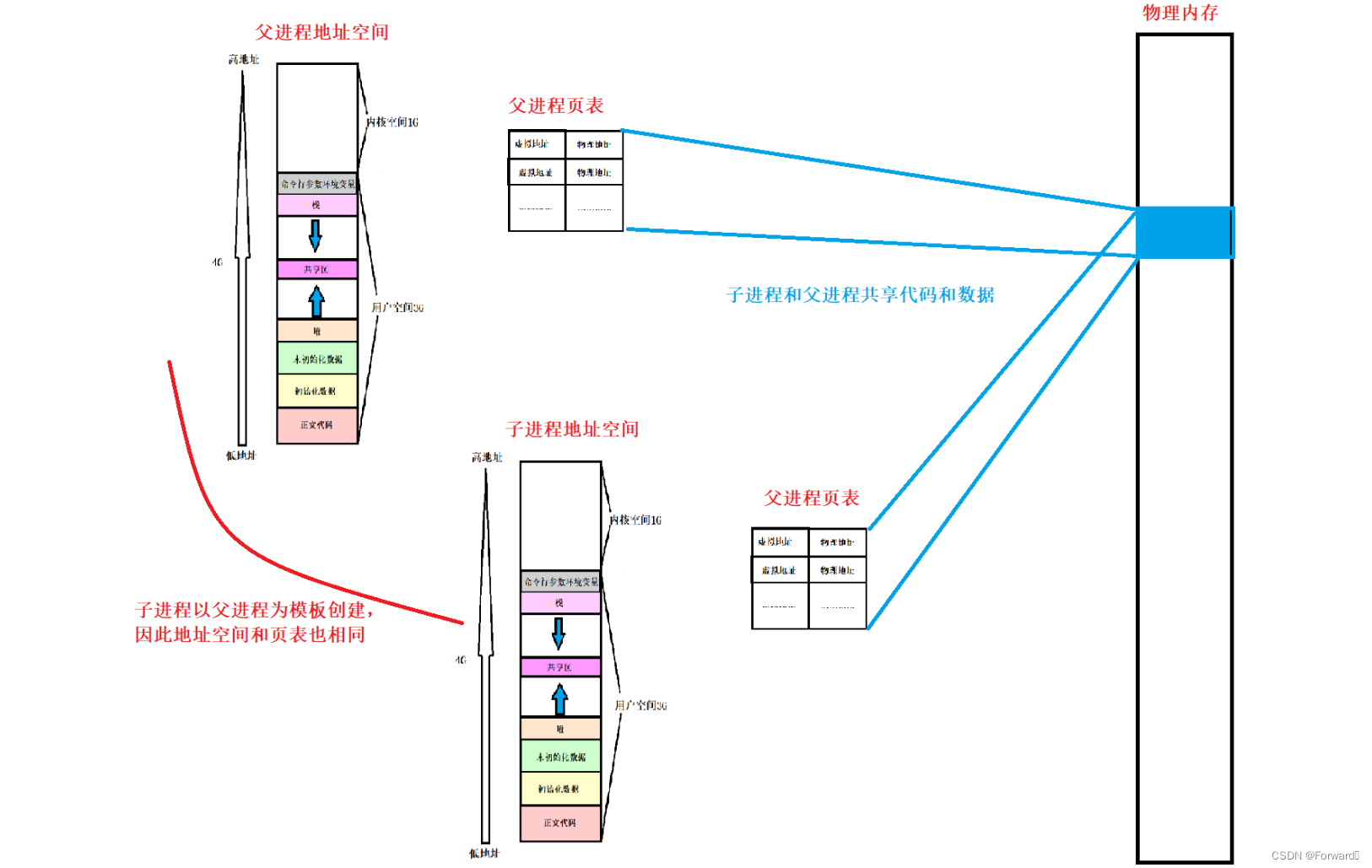
知道了这一点后,我们就可以回答一个问题:
为什么fork()函数可以有两个返回值呢,或者说为什么它可以return两次?
这是因为:
fork()是一个创建子进程的函数,因此在它的函数体内**return之前,他就已经产生了子进程**- 而子进程和父进程共享代码和数据,因此
return这一条语句也就会分别对父进程和子进程执行- 所以,
fork()看起来可以return两次,实际上时父进程return了一次,子进程return了一次
我们也可以用一份示例代码来验证上面说到的结论:
#include <unistd.h>
#include <stdio.h>
#include <sys/types.h>
int main()
{
pid_t id = fork();
if (id == 0)
{
while (1)
{
printf("I am child process\n");
sleep(1);
}
}
while (1)
{
printf("I am father process\n");
sleep(1);
}
return 0;
}
运行效果:

可以发现,子进程和父进程是同时运行的
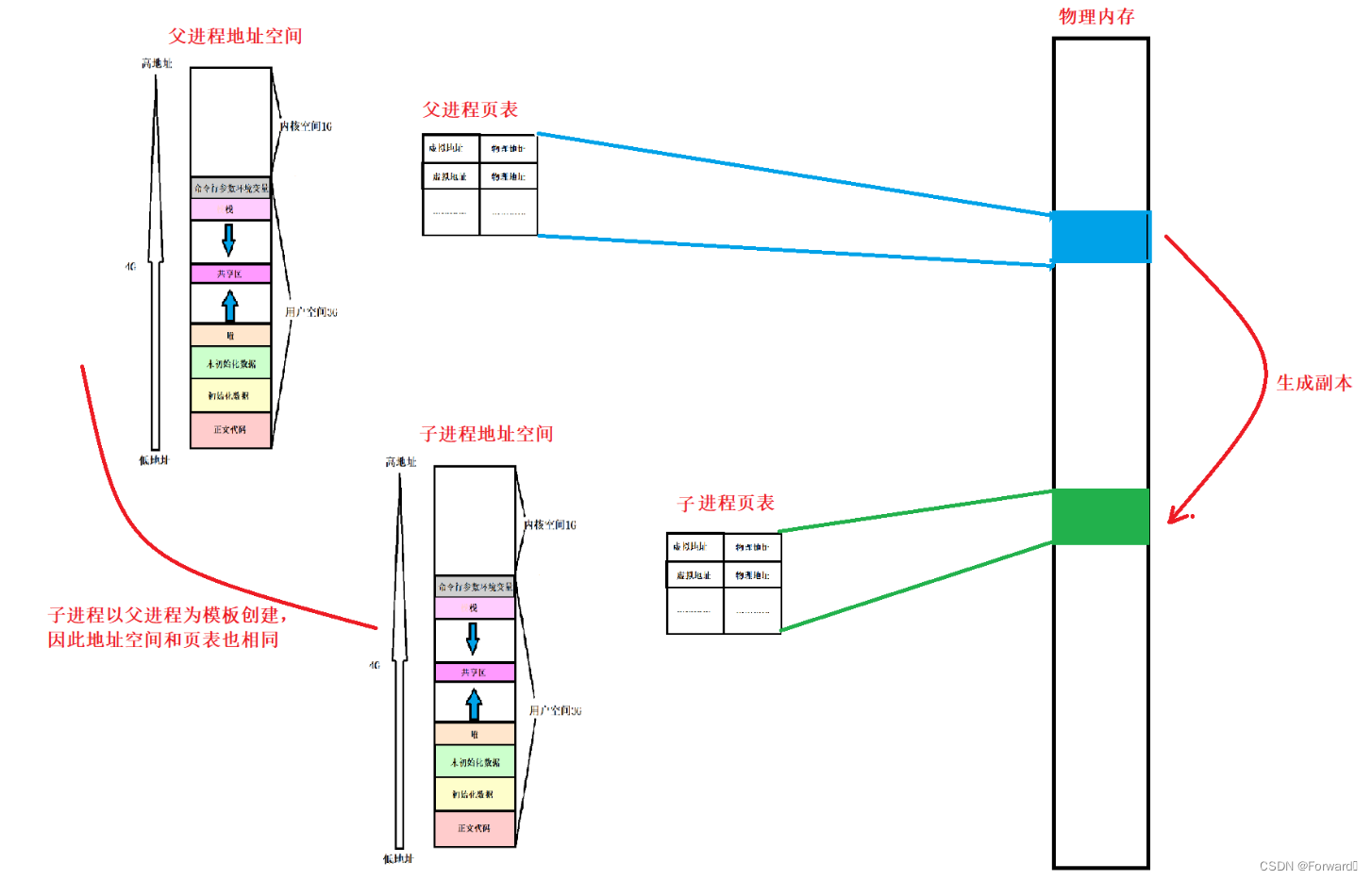
2.1.1 写时拷贝
当子进程或者父进程要向存储的数据进行写操作时,由于进程具有独立性并且进程创建时子进程和父进程共享代码和数据,因此为了让子进程和父进程的数据不会相互影响,就会触发写时拷贝
写时拷贝:
- 即为在写的时候拷贝数据
- 当要向子进程和父进程共享的数据进行写入时,会先对这份数据进行一次拷贝,并通过页表映射到新的空间,生成一个副本,最后再对这个副本进行写操作
- 这样,就可以确保子进程和父进程的数据不会相互影响,从而确保了进程的独立性
如图所示:
这时小伙伴就有几个疑问了:
为什么要在写的时候才拷贝呢?为什么不直接拷贝呢?
- 应该清楚,虽然子进程和父进程共享代码和数据,但是我们并不一定会会对这些数据进行写操作
- 因此,只在写的时候才拷贝可以有效地节省空间以及创建进程的时间
为什么是拷贝,而不是申请一块一样大小的内存?
- 就拿对数组这种数据进行写操作来说,假设我们只改变数组某一个下标的元素,而不是改变整个数组
- 那么如果只是申请一块空间,就不能知道其他未修改部分的内容
- 因此考虑到只是对数据做部分覆盖(修改)的情况,必须对源数据进行拷贝,生成一个副本
写时拷贝的原理是什么?
当子进程被创建完成后,页表会将父子进程共享的代码和数据的权限设置为只读。
当对这些数据进行写操作时,就会触发错误,从而引导操作系统的介入,触发写时拷贝
这样,我们就算对写时拷贝有了一个较为清楚的认识,同样我们也能回答当初遗留的问题:
代码pid_t id = fork()的id为什么可以有两个值?
- 前面就已经说过,
fork()在return前(也就是id接收返回值前)就已经创建了子进程,因此id就已经是父子进程共享的数据- 当要对
id进行写操作时,就会触发写时拷贝,就会生成一个副本id- 因此,父子进程就会同时拥有变量名相同但是实际的物理地址不同的变量
id- 所以看起来
id有两个值,实际上就是父进程的id有一个值,子进程的id有一个值
2.2 进程终止
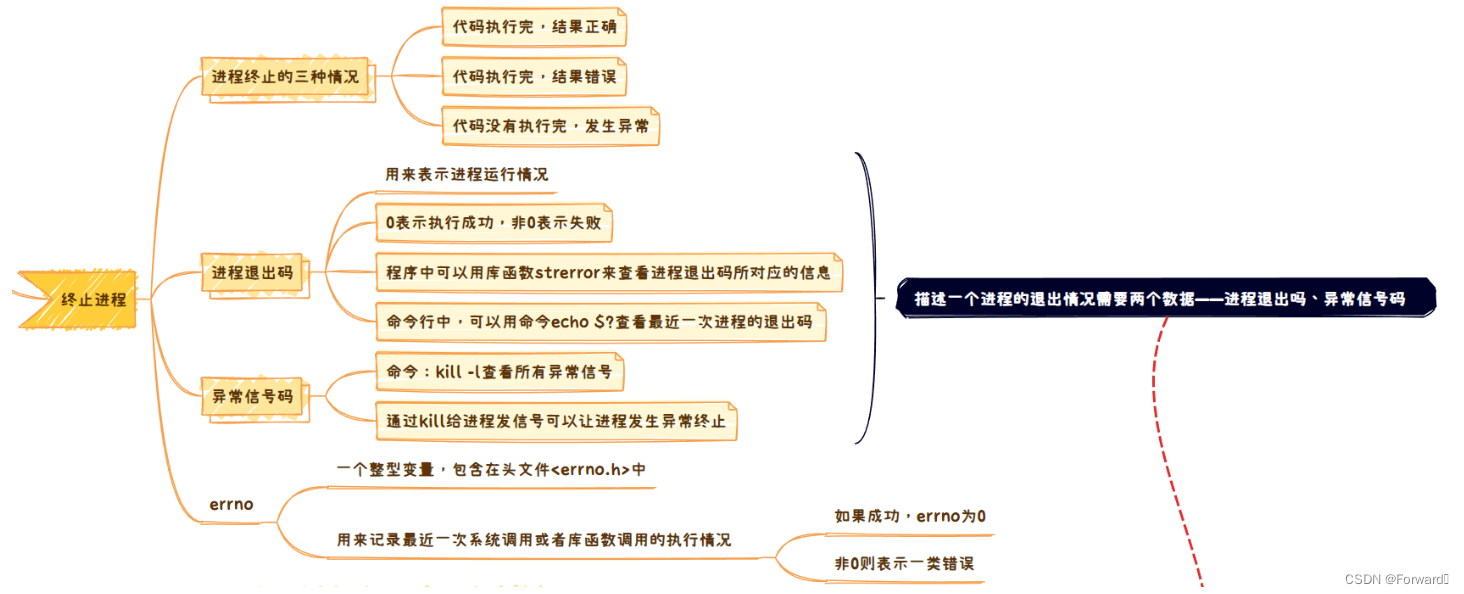
首先需要清楚,进程终止有且只有三种情况:
- 代码执行完,且结果正确
- 代码执行完,且结果错误
- 代码未执行完,发生异常
2.2.1 进程退出码
进程退出码用来描述代码执行完,结果的正确情况
例如:
int main() {return 0;}
里面的return 0中的0就是进程退出码。
- 对于进程退出码,0代表执行成功,非0代表执行失败
- 每一个进程退出码实际上都对应着一个具体的执行情况,我们可以用库函数
strerror进行查看- 头文件
<string.h> - 函数原型:
char *strerror(int errnum);
- 头文件
示例代码:
#include <unistd.h>
#include <stdio.h>
#include <sys/types.h>
#include <string.h>
int main()
{
int i;
for (i = 0; i < 200; i++)
printf("%d: %s\n", i, strerror(i));
return 0;
}
output:

可以看到,在Linux系统中,一共有134中进程退出码
在命令行中,我们也可以通过命令来得到最近一次进程的错误返回码
echo &?

2.2.2 异常信号码
异常信号码用来描述代码为执行完,出现异常的情况
我们可以用命令查看所有的异常信号码以及对应的信息
kill -l

我们也可以用命令向指定的进程发送信号:
kill -num PID
2.2.3 errno
errno是一个是一个整形变量,使用时需要包含头文件<errno.h>
errno可以用来记录最近一次系统调用或者库函数的执行情况,如果成功,errno为0,否则为对应的错误码- 每一次系统调用或库函数调用都会刷新一次
errno
例如:
#include <stdio.h>
#include <errno.h>
#include <string.h>
#include <stdlib.h>
int main()
{
FILE* fp = fopen("data.txt", "r"); //data.txt为一个不能存在的文件
if (NULL == fp)
{
printf("%s\n", strerror(errno));
exit(-1);
}
return 0;
}
output:
No such file or directory
2.2.4 总结
通过上面的讲解,我们知道,要知道代码是否出异常,就需要知道它的异常信号码,要知道它的运行结果是否正确,就需要他的进程退出码。因此,如果想要知道一个进程的执行情况,就一定需要两个整数:进程退出码和异常信号码
2.3 进程等待
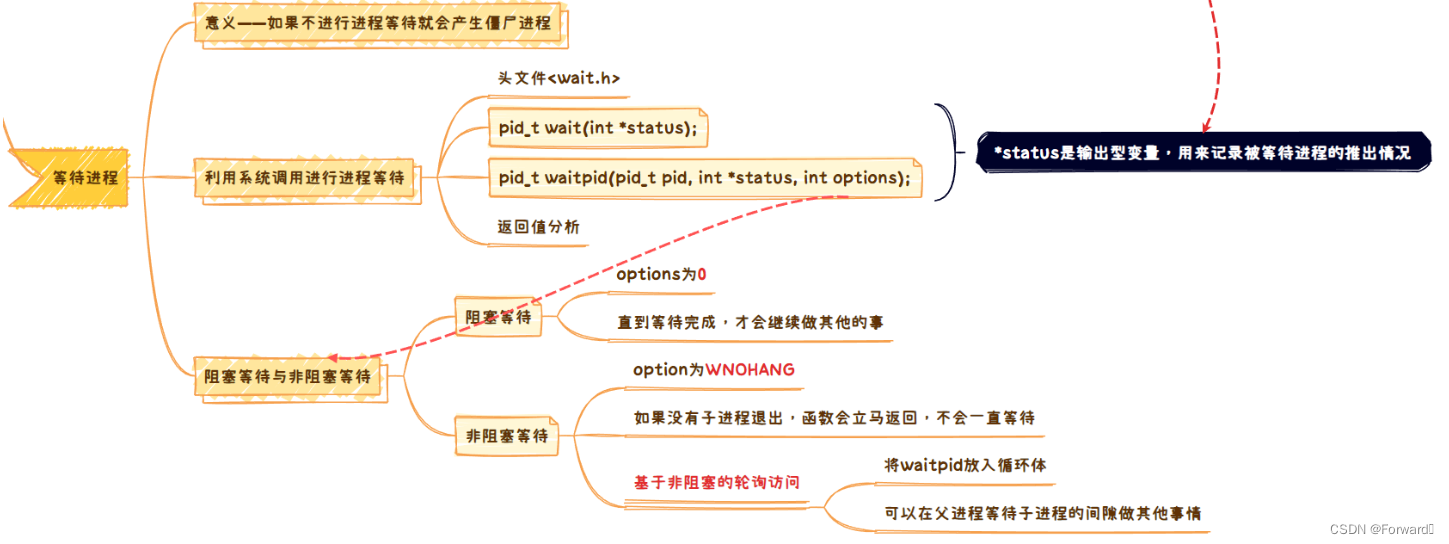
我们之前提到过:
如果子进程先于父进程退出,但是父进程没有等待子进程,拿走它留下的资源,那么这个子进程就会变成僵尸进程。从而造成内存泄露等不良后果。
所以在子进程退出后,我们必须进行进程的等待。如何等待?我们可以利用系统调用wait()和waitpid()。下面进行详细的说明:
要调用这两个系统调用,需要包含头文件:
<sys/wait.h>和<sys/types.h>
先来看wait()
2.3.1 wait()
pid_t wait(int *status);
wait()会暂停调用进程(父进程)的执行,直到其任意一个子进程终止。换句话说就是:只有等待到任意一个子进程终止,父进程才会继续工作- 如果成功,则返回被等待的子进程的
PID;否则返回-1 *status为一个输出型参数。用来表示被等待的子进程的执行情况,如果不关心可以设置为NULL。
实例:
#include <stdio.h>
#include <stdlib.h>
#include <sys/types.h>
#include <sys/wait.h>
#include <unistd.h>
int main()
{
pid_t id = fork();
if (id == 0)
{
int cnt = 5;
while (cnt--)
{
printf("I am child process, PID = %d\n", getpid());
sleep(1);
}
printf("child process exit\n");
exit(-1);
}
sleep(5);
printf("father will wait child 5 seconds later\n");
sleep(5);
wait(NULL);
printf("wait sucess!!!\n");
while(1);
return 0;
}
效果:

2.3.2 形参*status
我们前面说过,*status是一个输出型参数,表示被等待子进程的执行状态,如果我们不关心,可以设置为NULL
但是如果我们要关心呢?简单,用一个整型变量接收即可。
例如:
#include <stdio.h>
#include <stdlib.h>
#include <sys/types.h>
#include <sys/wait.h>
#include <unistd.h>
int main()
{
pid_t id = fork();
if (id == 0)
{
exit(-1);
}
int status = 0;
wait(&status);
printf("status = %d\n", status);
return 0;
}
output:
status = 65280
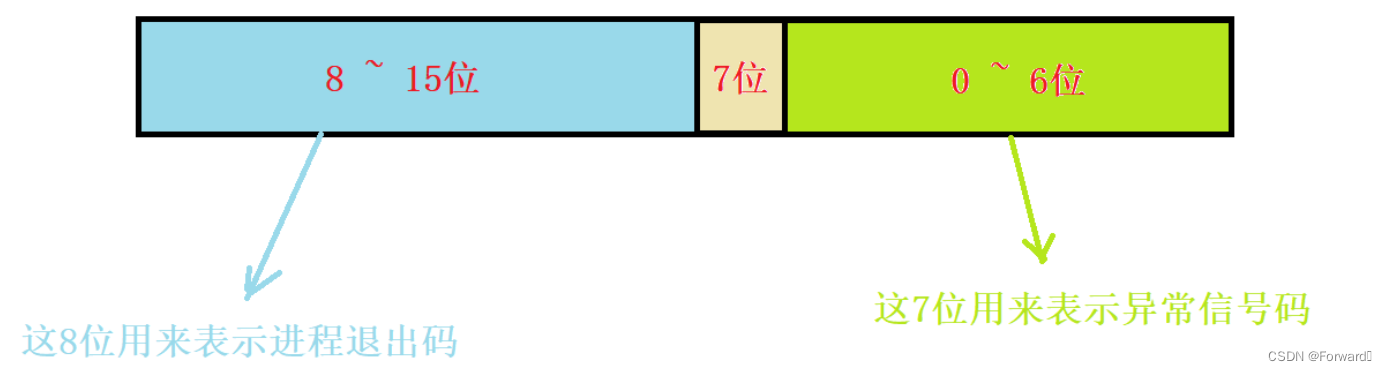
这时,有小伙伴就纳闷了:65280这个数是什么意思,我们要怎么分析这个数呢?
我们前面提到过,如果想要准确地描述一个进程的执行状态,必须要两个这个整数:进程退出码和异常信号码
因此,既然
status可以表示一个进程的执行状态,那它也一定包含了这两个数的信息。
- 实际上,作为一个
32位的int型数据,它的每一位都被赋予了特定的信息,我们应该将其当作一个位图来看待:
- 因此,我们就可以利用位运算来提取一个进程的退出码和信号码:
exit_code = (status >> 8) & 0xff; sign_code = status & 0x7f
例如对于上面的
status = 65280这种情况,65280的二进制形式为:1111 1111 0000 0000。我们取它的前8位:1111 1111,将其转换为原码:1000 0001也就是子进程的退出码-1了同样,如果子进程被信号所杀,我们也可以得到对应的异常信号码:
#include <stdio.h> #include <stdlib.h> #include <sys/types.h> #include <sys/wait.h> #include <unistd.h> int main() { pid_t id = fork(); if (id == 0) { while(1); exit(-1); } int status = 0; wait(&status); printf("status = %d, exit_code = %d, sign_code = %d\n", status, (status >> 8) & 0xff, status & 0x7f); return 0; }效果:

有些小伙伴可能会觉得要获取一个进程的退出码和信号码每次都要写一个位运算会很麻烦。所以我们也可以用系统定义的宏来完成:
WIFEXITED(status); //如果进程正常退出,就返回true
WEXITSTATUS(status); //代表进程的退出码
WIFSIGNALED(status); //如果进程由信号终止,就返回true
WTERMSIG(status); //代表进程的信号码
例如:
#include <stdio.h>
#include <stdlib.h>
#include <sys/types.h>
#include <sys/wait.h>
#include <unistd.h>
int main()
{
pid_t id = fork();
if (id == 0)
{
exit(1);
}
int status = 0;
wait(&status);
if (WIFEXITED(status))
printf("exit_code = %d\n", WEXITSTATUS(status));
if (WIFSIGNALED(status))
printf("sign_code = %d\n", WTERMSIG(status));
return 0;
}
output:
exit_code = 1
2.3.3 waitpid()
pid_t waitpid(pid_t pid, int *status, int options);
关于pid我们讨论两种情况:
pid == -1:表示等待任何一个子进程pid > 0:表示等待PID == pid的子进程
status和上面说的一样,这里不再赘述
关于options这里也讨论两种情况:
options == 0。此时,waitpid(-1, NULL, 0)就和wait(NULL)完全等价。在这种情况下,父进程会进行阻塞等待,如果一直没有子进程退出,那就会一直等待下去。options == WNOHANG。在这种情况下,父进程就会进行非阻塞等待,即如果在调用该系统调用的时候,如果没有子进程退出,就会立即返回,而不会被卡住。如果是这种情况,waitpid()的返回值也有以下三种情况:- 返回值大于0,表示等待成功
- 返回值等于0,表示没有子进程退出
- 返回值等于-1,表示发生错误
所以,我们可以利用waitpid的非阻塞等待方式进行基于非阻塞的轮询访问:
我们可以将系统调用
waitpid()放入循环体中,不断进行对子进程的等待,同时也可以在等待的间隙做父进程需要做的事情例如:
#include <stdio.h> #include <stdlib.h> #include <sys/types.h> #include <sys/wait.h> #include <unistd.h> typedef void(*func)(); func task[3]; void Func1() {printf("Func1\n");} void Func2() {printf("Func2\n");} void Func3() {printf("Func3\n");} void taskInit() { task[0] = Func1; task[1] = Func2; task[2] = Func3; } void excuteTask() { for (int i = 0; i < 3; i++) task[i](); } int main() { taskInit(); pid_t id = fork(); if (id == 0) { int cnt = 5; while (cnt--) { printf("I am child process, PID = %d\n", getpid()); sleep(1); } printf("child process exit\n"); exit(1); } while (1) { if (waitpid(id, NULL, WNOHANG) > 0) { printf("wait success\n"); break; } excuteTask(); sleep(1); } return 0; }效果:






![[多线程]线程池](https://img-blog.csdnimg.cn/direct/ace478d3bf1c4884b0baca6ed360a009.png)