前端面试题库 (面试必备) 推荐:★★★★★
地址:前端面试题库
JavaScript基础知识
JavaScript有哪些数据类型,它们的区别?
Number(数字): 用于表示数值,可以是整数或浮点数。例如:42、3.14。String(字符串): 用于表示文本数据,可以用单引号、双引号或反引号括起来。例如:"Hello"、'World'、"JavaScript"。Boolean(布尔): 用于表示逻辑值,只有两个可能的值:true和false。Undefined(未定义): 表示变量声明了但没有赋值,或者访问不存在的属性时返回的值。Null(空值): 表示一个空值或者不存在的对象。Symbol(符号): 是ES6引入的一种数据类型,用于创建唯一的、不可变的值,通常用于对象属性的唯一标识符。BigInt(大整数): 也是ES11引入的一种数据类型,用于表示任意精度的整数,可以处理超出Number类型表示范围的整数。- 除了基本数据类型,JavaScript还有一种复杂数据类型:
Object(对象): 用于表示复杂数据结构,可以包含多个键值对,每个键值对都是属性名和对应的值组成。
这些数据类型之间的区别在于它们的值特点、存储方式和操作方式。例如,Number和String类型可以进行数学运算和字符串操作,Boolean类型用于逻辑判断,Object类型用于组织和存储数据等。理解这些数据类型的特点,有助于编写更清晰、可维护的JavaScript代码。
数据类型检测的方式有哪些?
typeof操作符:例如typeof 42; // "number"instanceof操作符:例如let arr = []; arr instanceof Array; // trueObject.prototype.toString.call()方法:例如Object.prototype.toString.call("Hello"); // "[object String]"constructor方法:例如console.log(('str').constructor === String); // trueArray.isArray()方法:该方法用于判断是否为数组Array.isArray([]); // true
null和undefined区别是什么?
undefined:
undefined 表示一个声明了但没有被赋值的变量,或者访问一个不存在的属性或变量时返回的值。
当声明一个变量但未初始化时,它的值默认为 undefined。
函数没有返回值时,默认返回 undefined。
在代码中,不要主动将变量赋值为 undefined,而应该让它自然成为未赋值状态。null:
null 表示一个明确的、空的值,表示此处应该有一个值,但是当前还没有。它是一个赋值操作,表示将变量设置为空值。
null 通常用来显示地表示变量被清空了,或者某个属性被清空了。
在代码中,可以使用 null 来显式地指示变量或属性为空。
数据类型之间转换规则是什么?
其他值转字符串
- Null 和 Undefined 类型 ,null 转换为 "null",undefined 转换为 "undefined",
- Boolean 类型,true 转换为 "true",false 转换为 "false"。
- Number 类型的值直接转换,不过那些极小和极大的数字会使用指数形式。
- Symbol 类型的值直接转换,但是只允许显式强制类型转换,使用隐式强制类型转换会产生错误。
- 对普通对象来说,除非自行定义 toString() 方法,否则会调用 toString()
(Object.prototype.toString())来返回内部属性 [[Class]] 的值,如"[object Object]"。如果对象有自己的 toString() 方法,字符串化时就会调用该方法并使用其返回值。
其他值转数字
- Undefined 类型的值转换为 NaN。
- Null 类型的值转换为 0。
- Boolean 类型的值,true 转换为 1,false 转换为 0。
- String 类型的值转换如同使用 Number() 函数进行转换,如果包含非数字值则转换为 NaN,空字符串为 0。
- Symbol 类型的值不能转换为数字,会报错。
- 对象(包括数组)会首先被转换为相应的基本类型值,如果返回的是非数字的基本类型值,则再遵循以上规则将其强制转换为数字。
其他值转布尔
以下这些是假值: • undefined • null • false • +0、-0 和 NaN • ""
显式、隐式类型转换区别是什么?
JavaScript 中的类型转换分为显式类型转换(Explicit Type Conversion,也称为类型转换或类型强制转换)和隐式类型转换(Implicit Type Conversion,也称为类型转换或类型强制转换)。显式类型转换:
显式类型转换是通过代码明确地使用一些函数或操作符来将一个数据类型转换为另一个数据类型。这种转换是由开发人员手动进行的,以满足特定的需求。例如:
let num = 42;
let str = String(num); // 显式地将数字转换为字符串
let bool = Boolean(str); // 显式地将字符串转换为布尔值
隐式类型转换:
隐式类型转换是在操作过程中自动发生的,JavaScript 在需要不同类型的值时,会根据规则自动执行类型转换。这种转换不需要显式的开发人员干预,JavaScript 引擎会自动处理。例如:
let num = 42;
let str = num + ""; // 隐式地将数字转换为字符串
let bool = !num; // 隐式地将数字转换为布尔值
区别:
- 操作方式:
显式类型转换是由开发人员明确地编写代码来执行的,使用特定的函数或操作符。
隐式类型转换是在表达式求值过程中自动执行的,由 JavaScript 引擎根据表达式的操作和数据类型进行推断。
- 可控性:
显式类型转换可以让开发人员在需要的时候有更精确的控制,确保类型转换的结果符合预期。
隐式类型转换是自动发生的,有时可能导致意外的结果,需要开发人员注意避免潜在的问题。
- 代码可读性:
显式类型转换通常会使代码更加清晰,因为它明确地表达了开发人员的意图。
隐式类型转换可能会让代码更加简洁,但有时可能降低代码的可读性,需要注意平衡。
什么是JavaScript的包装类型?
JavaScript 的包装类型是指基本数据类型(例如 number、string、boolean)在一些特定场景下会被自动转换为对应的包装对象,从而可以使用对象的方法和属性。这种自动转换是临时性的,仅在需要调用对象方法或属性时发生,操作完成后又会自动转换回基本数据类型。这种特性可以让基本数据类型在某些情况下表现得像对象。
JavaScript 中的包装类型包括:
- Number 对应于基本数据类型 number
- String 对应于基本数据类型 string
- Boolean 对应于基本数据类型 boolean
举例说明:
let num = 42;
let str = "Hello";
let bool = true;
console.log(typeof num); // "number"
console.log(typeof str); // "string"
console.log(typeof bool); // "boolean"
// 使用包装类型的方法和属性
let numObj = new Number(num);
console.log(numObj.toFixed(2)); // 调用 Number 对象的 toFixed() 方法
let strObj = new String(str);
console.log(strObj.length); // 调用 String 对象的 length 属性
let boolObj = new Boolean(bool);
console.log(boolObj.valueOf()); // 调用 Boolean 对象的 valueOf() 方法
前端面试题库 (面试必备) 推荐:★★★★★
地址:前端面试题库
JavaScript有哪些内置对象?
JavaScript 提供了许多内置对象,这些对象在语言中默认可用,无需额外导入或加载。以下是一些常见的 JavaScript 内置对象:
- Object:通用对象,所有其他对象都从它派生。
- Array:用于创建数组,存储一组有序的值。
- String:用于处理字符串,提供字符串操作的方法。
- Number:用于处理数字,提供数学操作的方法。
- Boolean:表示布尔值 true 或 false。
- Function:用于定义函数,函数是 JavaScript 的基本构建块之一。
- Date:用于处理日期和时间。
- RegExp:用于进行正则表达式匹配。
- Math:提供数学相关的常量和函数,例如三角函数、对数函数等。
- JSON:用于解析和序列化 JSON 数据。
- Map:表示键值对的集合,支持任意数据类型作为键。
- Set:表示一组唯一的值,不允许重复。
- Promise:用于处理异步操作,支持处理成功和失败状态。
- Symbol:表示唯一标识符,通常用于对象属性的键。
- ArrayBuffer:表示二进制数据的缓冲区,用于处理底层二进制数据。
- TypedArray:基于 ArrayBuffer 的一组特定数据类型的数组,例如 Int8Array、Float64Array 等。
- WeakMap:类似于 Map,但对于键的引用不会阻止垃圾回收。
- Set:表示一组唯一值的集合。
- WeakSet:类似于 Set,但对于值的引用不会阻止垃圾回收。
这只是内置对象的一部分。每个内置对象都有自己的方法和属性,用于特定的操作和功能。了解这些内置对象和它们的用法,对于编写 JavaScript 代码非常有帮助。
new操作符实际做了哪些事情?
new 操作符用于创建一个实例对象,它执行了以下步骤:
- 创建一个新的空对象:new 操作符首先会创建一个新的空对象。
- 设置对象的原型链接:新创建的对象的 [[Prototype]](隐式原型)被设置为构造函数的 prototype 属性。
- 将构造函数的上下文设置为新对象:在调用构造函数时,将 this 关键字绑定到新创建的对象,使构造函数内部的代码可以操作新对象。
- 执行构造函数的代码:构造函数内部的代码被执行,可能会在新对象上设置属性和方法。
- 如果构造函数没有返回对象,则返回新对象:如果构造函数没有显式返回一个对象,则 new 操作符会自动返回新创建的对象;如果构造函数返回一个非对象的值,则不会影响返回结果。
以下是一个使用 new 操作符创建对象的示例:
// 构造函数
function Person(name, age) {
this.name = name;
this.age = age;
}
// 使用 new 操作符创建实例对象
let person1 = new Person("Alice", 30);
let person2 = new Person("Bob", 25);
console.log(person1.name); // Alice
console.log(person2.age); // 25
在这个示例中,new 操作符创建了两个 Person 的实例对象,分别是 person1 和 person2。在构造函数中,this 指向了这两个实例对象,使得构造函数可以在实例对象上设置属性。prototype 属性用于设置实例对象的原型链接,从而可以让实例对象通过原型链访问构造函数的原型中的属性和方法。
Map,Object,weakMap有什么区别?
Map、Object 和 WeakMap 都是 JavaScript 中用于存储键值对的数据结构,但它们之间有一些区别:Object:
- Object 是 JavaScript 中最基本的数据结构之一,用于存储键值对,其中键必须是字符串或符号。
- Object 对象的属性没有特定的顺序,属性的访问速度较快。
- Object 可以用于创建自定义的数据结构和对象,是最常用的数据类型之一。
Map:
- Map 是一种新的数据结构,引入于 ECMAScript 6,用于存储任意类型的键值对。
- Map 中的键可以是任意数据类型,包括基本数据类型和对象引用。
- Map 中的键值对是有序的,插入顺序决定了键值对的遍历顺序。
- Map 支持迭代器,可以使用 for...of 循环遍历键值对。
- Map 通常在需要更灵活的键类型、有序键值对以及更好的迭代支持时使用。
WeakMap:
- WeakMap 也是引入于 ECMAScript 6,类似于 Map,但有一些不同之处。
- WeakMap 的键必须是对象,值可以是任意数据类型。
- WeakMap 中的键是弱引用,不会阻止对象被垃圾回收,从而避免了内存泄漏的风险。
- WeakMap 不支持迭代器,无法直接遍历键值对。
- WeakMap 通常用于需要将数据与某些对象关联起来,但又不希望阻止对象被回收的情况。
总结区别:
- Object 是基本的键值对存储结构,键是字符串或符号。
- Map 是通用的键值对存储结构,键可以是任意数据类型,支持有序遍历。
- WeakMap 是一种键值对存储结构,键是对象,具有弱引用特性,不阻止对象被回收。
选择使用哪种数据结构取决于你的需求,例如键的类型、键值对的顺序以及内存管理等。
应用场景:Object 的应用场景:
- 创建自定义对象:Object 可以用于创建自定义的对象,用于表示特定类型的数据。
- 作为简单的映射:在一些简单的情况下,Object 可以用作简单的键值映射。
// 创建自定义对象
const person = {
name: "Alice",
age: 30,
}
// 简单的映射
const colorMap = {
red: "#FF0000",
green: "#00FF00",
blue: "#0000FF",
}
Map 的应用场景:
- 存储复杂键值对:Map 可以用于存储任意类型的键值对,例如存储函数、对象等。
- 维护插入顺序:Map 中的键值对是有序的,可以用于实现记录操作顺序的日志。
- 避免命名冲突:Map 中的键不受命名空间的限制,可以用于避免不同模块之间的命名冲突。
// 存储用户数据
const userMap = new Map();
const user1 = { name: "Alice", age: 30 };
const user2 = { name: "Bob", age: 25 };
userMap.set(user1, "User data for Alice");
userMap.set(user2, "User data for Bob");
// 记录操作顺序
const logMap = new Map();
logMap.set("1", "First action");
logMap.set("2", "Second action");
logMap.set("3", "Third action");
// 避免命名冲突
const moduleAMap = new Map();
const moduleBMap = new Map();
moduleAMap.set("data", "Module A data");
moduleBMap.set("data", "Module B data");
WeakMap 的应用场景:
- 私有数据存储:WeakMap 可以用于存储对象的私有数据,因为键是弱引用,不会阻止对象被垃圾回收。
- 元数据存储:WeakMap 可以用于存储对象的元数据,这些元数据不会影响对象的生命周期。
// 私有数据存储
const privateDataMap = new WeakMap();
class MyClass {
constructor() {
privateDataMap.set(this, { privateValue: 42 });
}
getPrivateValue() {
return privateDataMap.get(this).privateValue;
}
}
// 元数据存储
const metadataMap = new WeakMap();
function trackMetadata(obj, metadata) {
metadataMap.set(obj, metadata);
}
什么是类数组,如何转换成真正的数组?
类数组(Array-like)是一种类似于数组的对象,它具有一些数组的特性,例如有一系列的数字索引和 length 属性,但它并不是真正的数组,缺少数组的方法和属性。
常见的类数组包括函数的 arguments 对象、DOM 元素列表(如 NodeList)、字符串等。虽然类数组在某些情况下可以像数组一样被访问和操作,但由于缺少数组的方法,有时可能需要将其转换为真正的数组。
以下是如何将类数组转换为真正的数组的几种方法:使用 Array.from():
Array.from() 方法可以从类数组对象或可迭代对象创建一个新的数组。它将类数组的值复制到一个新的数组中,并返回这个新数组。
// 类数组对象
function convertToArray() {
const argsArray = Array.from(arguments);
console.log(Array.isArray(argsArray)); // true
return argsArray;
}
convertToArray(1, 2, 3); // [1, 2, 3]
使用 Array.prototype.slice.call():
slice() 方法可以用于截取数组的一部分,当将 slice() 应用于类数组对象时,可以将其转换为真正的数组。
// 类数组对象
const nodeList = document.querySelectorAll("p");
const nodeListArray = Array.prototype.slice.call(nodeList);
console.log(Array.isArray(nodeListArray)); // true
使用扩展运算符:
扩展运算符可以将一个可迭代对象转换为多个参数,然后通过 Array.from() 或直接使用 [] 创建新数组。
// 类数组对象
const nodeList = document.querySelectorAll("p");
const nodeListArray = [...nodeList];
console.log(Array.isArray(nodeListArray)); // true
使用 concat() 方法:
通过将类数组对象与一个空数组(或其他数组)连接,可以创建一个新数组,实现类数组转换。
// 类数组对象
const nodeList = document.querySelectorAll("p");
const nodeListArray = [].concat(nodeList);
console.log(Array.isArray(nodeListArray)); // true
前端面试题库 (面试必备) 推荐:★★★★★
地址:前端面试题库
操作数组有哪些方法?
javaScript 数组有许多原生的方法,用于对数组进行操作、遍历、修改等。以下是一些常见的数组原生方法:
- push(item1, item2, ...):向数组末尾添加一个或多个元素,并返回新数组的长度。
- pop():移除并返回数组的最后一个元素。
- unshift(item1, item2, ...):向数组开头添加一个或多个元素,并返回新数组的长度。
- shift():移除并返回数组的第一个元素。
- concat(array1, array2, ...):合并多个数组或值,返回一个新的合并后的数组。
- slice(start, end):截取数组的一部分,返回一个新数组,不修改原数组。
- splice(start, deleteCount, item1, item2, ...):从数组中删除、插入或替换元素,修改原数组,并返回被删除的元素组成的数组。
- join(separator):将数组的所有元素转换为字符串,使用指定的分隔符连接。
- indexOf(item, fromIndex):查找指定元素在数组中首次出现的位置,返回索引值,如果不存在则返回 -1。
- lastIndexOf(item, fromIndex):查找指定元素在数组中最后一次出现的位置,返回索引值,如果不存在则返回 -1。
- forEach(callback(item, index, array)):遍历数组的每个元素,执行回调函数。
- map(callback(item, index, array)):创建一个新数组,其中的元素是对原数组每个元素执行回调函数的结果。
- filter(callback(item, index, array)):创建一个新数组,包含满足回调函数条件的元素。
- reduce(callback(accumulator, item, index, array), initialValue):从左到右依次处理数组的元素,将结果累积为单个值。
- reduceRight(callback(accumulator, item, index, array), initialValue):从右到左依次处理数组的元素,将结果累积为单个值。
- some(callback(item, index, array)):检测数组中是否有至少一个元素满足回调函数条件,返回布尔值。
- every(callback(item, index, array)):检测数组中的所有元素是否都满足回调函数条件,返回布尔值。
- find(callback(item, index, array)):返回数组中第一个满足回调函数条件的元素。
- findIndex(callback(item, index, array)):返回数组中第一个满足回调函数条件的元素的索引,如果不存在则返回 -1。
- sort(compareFunction(a, b)):对数组元素进行排序,可传入比较函数用于指定排序规则。
- reverse():反转数组的元素顺序,修改原数组。
- fill(value, start, end):将数组的一部分元素替换为指定的值,修改原数组。
- includes(item, fromIndex):检测数组是否包含指定元素,返回布尔值。
- isArray(obj):检测一个对象是否为数组,返回布尔值。
常见的DOM操作有哪些?
DOM(Document Object Model)操作是指通过 JavaScript 对网页中的 HTML 元素和内容进行增删改查的操作。以下是一些常见的 DOM 操作以及相应的示例:获取元素:
- getElementById(id):根据元素的 id 获取元素。
- getElementsByClassName(className):根据类名获取一组元素。
- getElementsByTagName(tagName):根据标签名获取一组元素。
- querySelector(selector):根据选择器获取第一个匹配的元素。
- querySelectorAll(selector):根据选择器获取所有匹配的元素。
// 获取元素并修改其内容
let heading = document.getElementById("myHeading");
heading.textContent = "Hello, DOM!";
创建和插入元素:
- createElement(tagName):创建一个新的元素节点。
- appendChild(node):将一个节点添加为另一个节点的子节点。
- insertBefore(newNode, referenceNode):在指定节点之前插入一个新节点。
// 创建并插入新元素
let newParagraph = document.createElement("p");
newParagraph.textContent = "This is a new paragraph.";
document.body.appendChild(newParagraph);
修改元素属性和样式:
- setAttribute(name, value):设置元素的属性值。
- getAttribute(name):获取元素的属性值。
- style.property = value:设置元素的样式属性。
// 修改元素的属性和样式
let image = document.getElementById("myImage");
image.setAttribute("src", "new-image.jpg");
image.style.width = "200px";
移除元素:
removeChild(node):从父节点中移除指定的子节点。
// 移除元素
let paragraphToRemove = document.getElementById("paragraphToRemove");
paragraphToRemove.parentNode.removeChild(paragraphToRemove);
事件处理:
- addEventListener(eventType, callback):为元素添加事件监听器。
- removeEventListener(eventType, callback):移除元素的事件监听器。
// 添加事件监听器
let button = document.getElementById("myButton");
button.addEventListener("click", function() {
alert("Button clicked!");
});
for...in和for...of有什么区别?
for...in 和 for...of 都是用于迭代(遍历)数据结构中的元素,但它们在使用方式和应用场景上有一些区别。for...in 循环:
- 用于遍历对象的可枚举属性。
- 返回的是属性名(键名)。
- 可能会遍历到对象原型链上的属性。
- 不适合遍历数组或类数组对象,因为会遍历到额外的非数字索引属性和原型链上的属性。
const obj = { a: 1, b: 2, c: 3 };
for (const key in obj) {
console.log(key); // 输出:a, b, c
}
for...of 循环:
- 用于遍历可迭代对象(如数组、字符串、Set、Map 等)的值。
- 返回的是集合中的值,而不是属性名。
- 不会遍历对象的属性,只能遍历实际值。
- 可以直接遍历数组等数据结构,适合循环迭代。
const arr = [1, 2, 3];
for (const value of arr) {
console.log(value); // 输出:1, 2, 3
}
区别总结:
- for...in 遍历对象属性,返回属性名。
- for...of 遍历可迭代对象的值,返回实际值。
- for...in 可能会遍历到原型链上的属性,适合遍历对象属性。
- for...of 不会遍历原型链上的属性,适合遍历实际值。
常见的位运算符有哪些?其计算规则是什么?
按位与(&):
计算规则:对两个操作数的每个对应位执行逻辑 AND 操作,结果中的每个位都取决于两个操作数的对应位是否都为 1。
示例:a & b 返回一个值,其中每个位都是 a 和 b 对应位的 AND 结果。按位或(|):
计算规则:对两个操作数的每个对应位执行逻辑 OR 操作,结果中的每个位都取决于两个操作数的对应位是否有至少一个为 1。
示例:a | b 返回一个值,其中每个位都是 a 和 b 对应位的 OR 结果。按位异或(^):
计算规则:对两个操作数的每个对应位执行逻辑 XOR 操作,结果中的每个位都取决于两个操作数的对应位是否不同。
示例:a ^ b 返回一个值,其中每个位都是 a 和 b 对应位的 XOR 结果。按位非(~):
计算规则:对操作数的每个位执行逻辑 NOT 操作,即对每个位取反,1 变为 0,0 变为 1。
示例:~a 返回一个值,其中每个位都是 a 每个位取反的结果。左移(<<):
计算规则:将操作数的二进制位向左移动指定的位数,右侧用 0 填充。
示例:a << b 返回一个值,其中 a 的二进制位向左移动 b 位。右移(>>):
计算规则:将操作数的二进制位向右移动指定的位数,左侧用符号位的值填充。
示例:a >> b 返回一个值,其中 a 的二进制位向右移动 b 位。无符号右移(>>>):
计算规则:将操作数的二进制位向右移动指定的位数,左侧用 0 填充。
示例:a >>> b 返回一个值,其中 a 的二进制位向右移动 b 位,左侧用 0 填充。
解释性语言和编译型语言的区别是什么?
解释性语言和编译型语言是两种不同的编程语言类型,它们的主要区别在于代码的执行方式和编译过程:
解释性语言:
- 执行方式:解释性语言的代码在运行时逐行被解释器翻译成机器代码,然后立即执行。代码是一边翻译一边执行,不需要先进行显式的编译过程。
- 执行效率:由于每次运行都需要进行解释,解释性语言通常比较慢。解释性语言更注重开发速度和动态性,适用于一些快速原型开发和脚本编写场景。
- 跨平台性:解释性语言的代码通常可以在不同平台上直接运行,不需要重新编译。
- 例子:
Python、JavaScript、Ruby、PHP是一些常见的解释性语言。
编译型语言:
- 编译过程:编译型语言的代码需要在运行之前先通过编译器进行一次完整的编译,将源代码翻译成目标平台的机器代码。这个编译过程产生一个可执行文件,运行时不需要再次编译。
- 执行效率:由于代码已经编译成机器代码,编译型语言的执行速度通常较快。适合开发需要高性能的应用程序。
- 跨平台性:编译型语言的代码需要为每个不同的目标平台进行编译,因此需要重新编译适应不同的操作系统和硬件。
- 例子:
C、C++、Rust、Go是一些常见的编译型语言。
总结区别:
- 解释性语言在运行时逐行解释并执行代码,执行速度较慢,适合开发快速原型和脚本。
- 编译型语言在运行之前先编译成机器代码,执行速度较快,适合开发需要高性能的应用。
- 解释性语言跨平台性较好,无需重新编译。
- 编译型语言需要为每个平台重新编译,较难实现跨平台。
JavaScript高级知识
什么是原型,原型链?
JavaScript 中的原型(prototype)和原型链(prototype chain)是理解对象和继承机制的关键概念。原型(prototype):
每个 JavaScript 对象都有一个关联的原型对象,它是一个普通对象,包含一些共享的属性和方法。当你访问对象的属性或方法时,如果对象本身没有这个属性或方法,JavaScript 引擎会沿着对象的原型链去查找。对象可以通过 prototype 属性来访问它的原型对象。原型链(prototype chain):
原型链是由一系列连接的原型对象组成的链。当访问对象的属性或方法时,如果对象本身没有找到,引擎会沿着原型链向上查找,直到找到该属性或方法或者到达原型链的顶端(Object.prototype)。这样的搜索路径就构成了原型链。
例如:
class Person {
constructor(name, age) {
this.name = name
this.age = age
}
sayHello() {
console.log('hello')
}
}
const person = new Person('John', 20)
console.log(Person.prototype)
console.log(person.__proto__)
const person2 = Object.create(person)
console.log(person2.__proto__.__proto__)
person2.sayHello()
执行结果如下
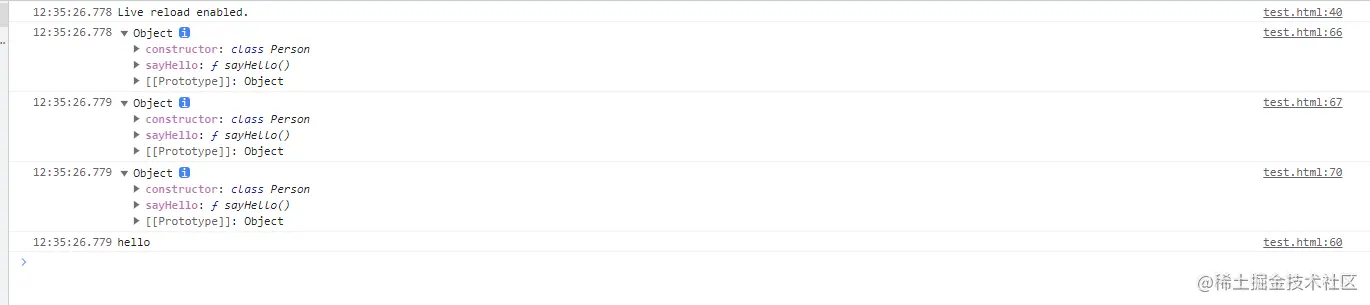
这里的Person类就存在自己的原型prototype,prototype是一个对象,拥有Person的constructor和sayHello方法
使用Person创建出一个实例person此时person上并没有sayHello方法,但是person的__proto__指向Person的prototype,当在当前对象上找不到sayHello方法时,js就会沿着__proto__的指向向上寻找
后面我们用Object.create(person)方法创建一个对象person2,此时该对象是空对象,但是该对象的__proto__指向person,而person的__proto__又指向Person的prototype,因此person2也可以调用sayHello方法
这种沿着__proto__指向一致向上寻找,便形成一个原型链,需要注意的时原型链的最顶端都是null
前端面试题库 (面试必备) 推荐:★★★★★
地址:前端面试题库
什么是闭包,有什么作用?
闭包是一种在函数内部创建的函数,它可以访问其包含函数(外部函数)的变量和参数,即使外部函数已经执行完毕。换句话说,闭包是一个函数加上该函数创建时所能访问的作用域,它可以"捕获"这个作用域中的变量,并在函数执行后继续保持对这些变量的访问能力。
闭包通常由以下两个主要部分组成:
- 内部函数(嵌套函数):在外部函数内部定义的函数,形成了闭包。
- 外部函数的作用域:内部函数可以访问和"捕获"外部函数的作用域中的变量和参数。
闭包的作用:
保护数据:通过闭包,可以将一些数据限制在函数的作用域内,避免全局污染,只暴露必要的接口。保存状态:闭包可以用于保存函数执行过程中的状态,例如计数器、缓存等,使得状态在函数调用之间得以保持。实现模块化:通过闭包,可以实现类似于模块的封装,将一组相关的功能组织在一起,避免命名冲突和变量泄露。实现回调和异步操作:JavaScript 中的回调函数和异步操作通常需要使用闭包来捕获外部函数的状态和数据。创建私有变量:通过闭包可以模拟私有变量,使得只有内部函数能够访问和修改某些数据。
以下是一个闭包的简单示例:
function outerFunction() {
let outerVariable = "I am from outer function";
function innerFunction() {
console.log(outerVariable); // 内部函数访问了外部函数的变量
}
return innerFunction; // 返回内部函数作为闭包
}
let closure = outerFunction(); // 调用外部函数,返回内部函数
closure(); // 调用内部函数,输出 "I am from outer function"
在这个例子中,innerFunction 是一个闭包,它可以访问外部函数 outerFunction 中的变量 outerVariable。当我们调用外部函数并将其返回的内部函数赋值给 closure 变量后,closure 成为了一个保存了 outerVariable 的闭包,可以在之后的调用中继续访问这个变量。
JavaScript中的作用域是什么,有什么作用?
JavaScript 中的作用域(scope)是指变量和函数在代码中可访问的范围。作用域规定了在何处以及如何查找变量。作用域的概念在 JavaScript 中是非常重要的,因为它影响着变量的可见性和生命周期。
作用域的类型:
全局作用域:在代码的最外层定义的变量和函数,可以在代码的任何位置被访问,称为全局作用域。局部作用域:在函数内部定义的变量和函数,只能在函数内部被访问,称为局部作用域(也称为函数作用域)。
作用域的作用:
隔离变量:作用域可以将变量限制在特定的代码块或函数内部,防止变量之间发生命名冲突。封装和信息隐藏:通过使用函数作用域,可以将一些变量隐藏在函数内部,避免了外部代码直接访问和修改这些变量,实现了信息隐藏和封装。变量的生命周期:作用域也影响了变量的生命周期,变量在进入作用域时被创建,在离开作用域时被销毁。这有助于内存管理和垃圾回收。
// 全局作用域
let globalVariable = "I am global";
function myFunction() {
// 局部作用域
let localVariable = "I am local";
console.log(localVariable); // 可以访问局部变量
console.log(globalVariable); // 可以访问全局变量
}
console.log(globalVariable); // 可以在全局范围内访问
// console.log(localVariable); // 无法在全局范围内访问局部变量
在这个示例中,globalVariable 是一个全局变量,可以在代码的任何地方访问。localVariable 是在函数内部定义的局部变量,只能在函数内部访问。
作用域帮助我们组织代码、封装功能、限制变量的可见性,并且有助于避免命名冲突,使得代码更加模块化和可维护。
如何理解JavaScript中的执行上下文?
执行上下文(Execution Context)是 JavaScript 中一个重要的概念,它是代码在执行过程中的环境,包含了当前代码执行所需的所有信息,如变量、函数、作用域等。每当 JavaScript 代码运行时,都会创建一个新的执行上下文。理解执行上下文对于理解代码的执行流程和作用域非常关键。
执行上下文可以分为三种类型:
全局执行上下文:整个脚本的最外层环境,在代码执行之前被创建。在浏览器中,全局执行上下文通常是 window 对象。函数执行上下文:每次调用函数时,都会创建一个新的函数执行上下文,用于管理函数内部的变量、参数和执行流程。Eval 函数执行上下文:使用 eval 函数执行的代码会在一个特殊的执行上下文中运行。
执行上下文包含的重要信息:
变量环境(Variable Environment):包含了变量和函数声明,以及外部环境的引用。在函数执行上下文中,这部分称为函数的“作用域链”。词法环境(Lexical Environment):类似于变量环境,但是在函数执行上下文中,它会随着函数嵌套的改变而变化,支持闭包。this 值:指向当前执行上下文的上下文对象。外部引用:指向包含当前执行上下文的外部执行上下文。
执行上下文的生命周期:
创建阶段:在进入代码块之前,执行上下文会被创建。这时会创建变量对象(VO),初始化函数参数、变量和函数声明。执行阶段:在进入代码块时,代码会按顺序执行。在这个阶段,变量赋值和函数调用等操作会被执行。销毁阶段:执行完代码后,执行上下文会被销毁,函数的局部变量等会被释放。
示例:
function greet(name) {
var message = "Hello, " + name;
console.log(message);
}
greet("Alice"); // 调用函数,创建函数执行上下文
在这个示例中,当调用 greet("Alice") 时,会创建一个新的函数执行上下文用于执行 greet 函数内部的代码。这个执行上下文包含了 name 参数和 message 变量,以及其他所需的信息。一旦函数执行完毕,这个执行上下文将会被销毁。
什么是Ajax,如何实现一个简单的Ajax请求
Ajax(Asynchronous JavaScript and XML) 是一种用于在不刷新整个页面的情况下,通过 JavaScript 在后台与服务器进行数据交换的技术。通过 Ajax,可以实现异步加载数据、动态更新页面内容,从而提升用户体验。
Ajax 的工作流程:
- 创建 XMLHttpRequest 对象:通过 JavaScript 创建一个 XMLHttpRequest 对象,用于在后台与服务器进行通信。
- 发送请求:使用 XMLHttpRequest 对象发送请求,可以是 GET 或 POST 请求,传递参数或数据给服务器。
- 接收响应:服务器处理请求后,返回数据或响应,JavaScript 通过监听事件来获取响应数据。
- 更新页面:根据接收到的响应数据,使用 JavaScript 动态更新页面内容,而不需要刷新整个页面。
以下是一个简单的 Ajax 请求的示例,使用原生的 XMLHttpRequest 对象:
<!DOCTYPE html>
<html>
<head>
<title>Ajax Example</title>
</head>
<body>
<button id="loadButton">Load Data</button>
<div id="dataContainer"></div>
<script>
document.getElementById("loadButton").addEventListener("click", function() {
let xhr = new XMLHttpRequest();
xhr.open("GET", "https://jsonplaceholder.typicode.com/posts/1", true); // 发送 GET 请求
xhr.onreadystatechange = function() {
if (xhr.readyState === 4 && xhr.status === 200) {
let response = JSON.parse(xhr.responseText);
document.getElementById("dataContainer").textContent = response.title;
}
};
xhr.send(); // 发送请求
});
</script>
</body>
</html>
在这个示例中,点击 "Load Data" 按钮会触发一个 Ajax 请求,获取 https://jsonplaceholder.typicode.com/posts/1 地址返回的数据,并将其中的标题显示在页面上。XMLHttpRequest 对象用于创建和管理请求,onreadystatechange 事件监听响应状态的变化,readyState 表示请求状态,status 表示响应状态码,responseText 存储响应内容。
如何使用Promise封装Ajax请求
使用 Promise 封装 Ajax 请求可以让代码更具可读性和可维护性,同时还可以更好地处理异步操作的结果。以下是一个使用 Promise 封装 Ajax 请求的示例,使用原生的 XMLHttpRequest 对象:
function makeAjaxRequest(url, method) {
return new Promise(function(resolve, reject) {
let xhr = new XMLHttpRequest();
xhr.open(method, url, true);
xhr.onreadystatechange = function() {
if (xhr.readyState === 4) {
if (xhr.status === 200) {
resolve(xhr.responseText); // 请求成功,将响应数据传递给 resolve 函数
} else {
reject(new Error("Request failed with status: " + xhr.status)); // 请求失败,将错误信息传递给 reject 函数
}
}
};
xhr.send();
});
}
// 使用封装的函数
makeAjaxRequest("https://jsonplaceholder.typicode.com/posts/1", "GET")
.then(function(response) {
console.log("Response:", response);
})
.catch(function(error) {
console.error("Error:", error);
});
在这个示例中,makeAjaxRequest 函数返回一个 Promise 对象,它将一个回调函数传递给 XMLHttpRequest 的 onreadystatechange 事件处理程序。当请求完成时,如果状态码为 200,则调用 resolve 函数并传递响应数据,否则调用 reject 函数并传递错误信息。
通过使用 Promise,你可以使用 .then() 方法处理成功的响应,使用 .catch() 方法处理失败的情况,使得代码逻辑更加清晰和可控。封装了 Promise 的 Ajax 请求可以更好地管理异步操作,使得代码更具可读性和可维护性。不过需要注意的是,现代的 Web 开发中,许多人更倾向于使用基于 Promise 的库(如 axios)来进行网络请求,因为它们提供了更便捷和强大的功能。
Ajax,axios,fetch之间有什么区别
Ajax、axios 和 fetch 都是用于在前端实现网络请求的工具或技术,但它们在用法和功能上有一些区别。Ajax:
- Ajax(Asynchronous JavaScript and XML)是一种异步通信技术,使用原生的 JavaScript 和 XMLHttpRequest 对象来实现在不刷新整个页面的情况下与服务器交换数据。
- Ajax 可以用于发送各种类型的请求(GET、POST 等),并接收服务器返回的数据,然后通过 JavaScript 更新页面内容。
- 原生的 Ajax 代码较为繁琐,需要处理不同浏览器的兼容性。
axios:
- axios 是一个基于 Promise 的 HTTP 客户端,用于在浏览器和 Node.js 中发送 HTTP 请求。
- axios 提供了简洁的 API,并且处理了很多底层细节,如请求和响应的转换、拦截器、错误处理等。
- axios 可以在浏览器环境和 Node.js 环境中使用,支持请求取消和并发请求管理等功能。
fetch:
- fetch 是 Web API 中的一部分,是浏览器原生提供的一个用于发起网络请求的方法。
- fetch 提供了一种基于 Promise 的简单和现代的方式来发送请求和处理响应。
- 与 axios 不同,fetch 不会自动将请求失败(例如 HTTP 错误状态码)视为错误,需要手动检查响应状态。
区别总结:
- Ajax 是一种通信技术,主要通过 XMLHttpRequest 对象实现。
- axios 是一个第三方库,提供了基于 Promise 的 API,用于简化 HTTP 请求的处理。
- fetch 是浏览器原生提供的网络请求 API,也使用了 Promise,但处理响应状态的方式略有不同。
- axios 和 fetch 提供了更现代、更简洁的 API,且能处理一些附加功能,如拦截器、取消请求等。
JavaScript中的this是什么?
在 JavaScript 中,this 是一个特殊关键字,它在不同的上下文中指向不同的值。this 的值取决于代码在何处被调用,以及调用方式。
this 的指向可以分为以下几种情况:全局上下文中的 this:
在全局上下文(没有嵌套在任何函数内部)中,this 指向全局对象,通常在浏览器环境中是 window 对象,在 Node.js 环境中是 global 对象。函数中的 this:
- 在函数中,this 的值取决于函数是如何被调用的。常见的情况包括:
- 在函数中,直接使用 this,其值取决于函数的调用方式。
- 在函数中,作为对象的方法被调用,this 指向调用该方法的对象。
- 使用 call()、apply() 或 bind() 方法来明确指定函数执行时的 this。
箭头函数中的 this:
箭头函数没有自己的 this 值,它会继承外部函数的 this 值。箭头函数的 this 始终指向包含它的最近的非箭头函数的 this 值,即词法作用域的 this。DOM 事件处理函数中的 this:
在处理 DOM 事件时,事件处理函数的 this 默认指向触发事件的 DOM 元素。但是,如果使用箭头函数作为事件处理函数,this 将保持其外部函数的 this 值。
示例:
console.log(this); // 全局上下文中,指向全局对象(浏览器环境中是 window)
function sayHello() {
console.log(this); // 在函数中,取决于调用方式
}
const obj = {
method: function() {
console.log(this); // 在对象的方法中,指向调用方法的对象(obj)
}
};
const arrowFunction = () => {
console.log(this); // 箭头函数中,继承外部函数的 this 值
};
sayHello(); // 函数中,取决于调用方式
obj.method(); // 对象的方法中,指向调用方法的对象(obj)
arrowFunction(); // 箭头函数中,继承外部函数的 this 值
call,apply,bind函数如何使用,有何区别?
call、apply 和 bind 是 JavaScript 中用于显式设置函数执行上下文(this 值)的方法。它们的主要作用是在调用函数时,将指定的对象作为函数的上下文来执行函数。这些方法的区别在于参数传递的方式和执行时间。call 方法:
- call 方法允许你将一个对象作为参数传递给函数,并将该对象作为函数的上下文(this 值)来调用函数。
- 除了第一个参数,后续的参数是传递给函数的实际参数。
- 函数会立即执行。
示例:
function greet(name) {
console.log(`Hello, ${name}! I am ${this.name}.`);
}
const person = { name: "Alice" };
greet.call(person, "Bob"); // 输出:Hello, Bob! I am Alice.
apply 方法:
- apply 方法与 call 方法类似,但参数是以数组形式传递的。
- 函数会立即执行。
示例:
function greet(name) {
console.log(`Hello, ${name}! I am ${this.name}.`);
}
const person = { name: "Alice" };
greet.apply(person, ["Bob"]); // 输出:Hello, Bob! I am Alice.
bind 方法:
- bind 方法返回一个新函数,该新函数的上下文被绑定到指定的对象,但不会立即执行。
- 返回的新函数可以稍后被调用,调用新函数时将使用绑定的上下文。
示例:
function greet(name) {
console.log(`Hello, ${name}! I am ${this.name}.`);
}
const person = { name: "Alice" };
const boundGreet = greet.bind(person);
boundGreet("Bob"); // 输出:Hello, Bob! I am Alice.
区别总结:
- call 和 apply 是用于立即执行函数并传递参数的方法,其中 apply 接受参数的形式是数组。
- bind 是用于创建一个新函数,该函数会在稍后的调用中使用绑定的上下文。
这些方法通常用于在特定上下文中执行函数,例如在事件处理程序、回调函数或特定环境中的函数调用。
如何自己实现call,apply,bind函数?
实现 call 函数:
Function.prototype.myCall = function(context, ...args) {
context = context || window; // 如果未传入上下文,则使用全局对象
const uniqueKey = Symbol(); // 使用一个唯一的键来避免覆盖原有属性
context[uniqueKey] = this; // 将当前函数设置为上下文的属性
const result = context[uniqueKey](...args); // 调用函数并传递参数
delete context[uniqueKey]; // 删除添加的属性
return result; // 返回函数执行的结果
};
function greet(name) {
console.log(`Hello, ${name}! I am ${this.name}.`);
}
const person = { name: "Alice" };
greet.myCall(person, "Bob"); // 输出:Hello, Bob! I am Alice.
实现 apply 函数:
Function.prototype.myApply = function(context, args) {
context = context || window;
const uniqueKey = Symbol();
context[uniqueKey] = this;
const result = context[uniqueKey](...args);
delete context[uniqueKey];
return result;
};
function greet(name) {
console.log(`Hello, ${name}! I am ${this.name}.`);
}
const person = { name: "Alice" };
greet.myApply(person, ["Bob"]); // 输出:Hello, Bob! I am Alice.
实现 bind 函数:
Function.prototype.myBind = function(context, ...args1) {
const originalFunction = this;
return function(...args2) {
context = context || window;
const combinedArgs = args1.concat(args2); // 合并传入的参数
return originalFunction.apply(context, combinedArgs);
};
};
function greet(name) {
console.log(`Hello, ${name}! I am ${this.name}.`);
}
const person = { name: "Alice" };
const boundGreet = greet.myBind(person);
boundGreet("Bob"); // 输出:Hello, Bob! I am Alice.
需要注意,使用 Symbol 来确保添加到上下文中的属性不会与现有属性冲突。这只是一种简化的实现,实际的 call、apply 和 bind 方法还包括更多的错误处理和边界情况考虑。
什么是异步编程,有何作用?
异步编程是一种编程范式,用于处理在执行过程中需要等待的操作,如网络请求、文件读写、数据库查询等。在传统的同步编程中,代码会按顺序一行一行执行,如果遇到需要等待的操作,整个程序可能会被阻塞,直到操作完成。而异步编程允许程序在执行等待操作的同时继续执行其他任务,以提高程序的效率和响应性。
异步编程的作用有以下几点:
提高响应性:在等待长时间操作(如网络请求)时,程序不会被阻塞,用户仍然可以与界面交互,提升用户体验。优化资源利用:在等待 IO 操作时,CPU 不会被空闲浪费,可以继续执行其他任务,充分利用系统资源。降低延迟:在需要等待的操作完成后,程序可以立即继续执行,而不需要等待整个操作序列完成。并行处理:异步编程使得程序能够同时执行多个任务,从而更有效地利用多核处理器。
在 JavaScript 中,异步编程通常使用以下方式来实现:
回调函数:将需要在操作完成后执行的代码封装在一个回调函数中,并在操作完成后调用回调函数。Promise:通过 Promise 对象封装异步操作,并通过链式调用 .then() 方法处理操作完成后的结果。async/await:使用 async 和 await 关键字来编写更具同步风格的异步代码,使代码更易读和维护。事件监听:将需要在操作完成时执行的代码绑定到事件,当事件触发时执行相应的代码。
异步编程对于处理现代 Web 应用中的网络请求、数据库查询、文件操作等任务非常重要。它能够提高应用的性能、响应性和用户体验,同时还有助于避免程序因等待操作而阻塞。
什么是Promise,如何使用?
Promise 是 JavaScript 中处理异步操作的一种机制,它表示一个异步操作的最终完成(或失败),并可以在操作完成后进行处理。Promise 提供了一种更优雅和结构化的方式来处理回调地狱(Callback Hell),使异步代码更加可读和可维护。
一个 Promise 可以处于以下三个状态之一:
Pending(进行中):初始状态,表示异步操作正在进行中。Fulfilled(已完成):表示异步操作已成功完成,结果值可用。Rejected(已拒绝):表示异步操作失败,错误信息可用。
使用 Promise 的基本流程如下:
- 创建一个 Promise 对象,传入一个执行函数,该函数接收两个参数:resolve 和 reject。
- 在执行函数中执行异步操作,并根据操作结果调用 resolve 或 reject。
以下是一个简单的使用 Promise 的示例:
function fetchData() {
return new Promise((resolve, reject) => {
setTimeout(() => {
const data = { message: "Data fetched successfully" };
if (data) {
resolve(data); // 成功时调用 resolve 并传递数据
} else {
reject(new Error("Failed to fetch data")); // 失败时调用 reject 并传递错误信息
}
}, 1000);
});
}
// 使用 Promise
fetchData()
.then((result) => {
console.log(result.message); // 处理成功的情况
})
.catch((error) => {
console.error(error.message); // 处理失败的情况
});
在这个示例中,fetchData 函数返回一个 Promise 对象。通过 .then() 方法处理异步操作成功的情况,通过 .catch() 方法处理异步操作失败的情况。
如何自己实现一个Promise?
实现一个完整的 Promise 并不是一件简单的事情,因为 Promise 的内部需要处理异步操作的状态管理、回调函数的注册和调用、错误处理等复杂逻辑。以下是一个简化版本的 Promise 实现,用于演示其基本原理:
class MyPromise {
constructor(executor) {
this.state = "pending"; // 初始状态
this.value = undefined; // 保存异步操作的结果
this.callbacks = []; // 存储成功和失败回调
const resolve = (value) => {
if (this.state === "pending") {
this.state = "fulfilled"; // 成功状态
this.value = value;
this.callbacks.forEach(callback => callback.onFulfilled(value));
}
};
const reject = (reason) => {
if (this.state === "pending") {
this.state = "rejected"; // 失败状态
this.value = reason;
this.callbacks.forEach(callback => callback.onRejected(reason));
}
};
try {
executor(resolve, reject);
} catch (error) {
reject(error);
}
}
then(onFulfilled, onRejected) {
if (this.state === "fulfilled") {
onFulfilled(this.value);
} else if (this.state === "rejected") {
onRejected(this.value);
} else if (this.state === "pending") {
this.callbacks.push({ onFulfilled, onRejected });
}
}
}
// 使用自己实现的 Promise
const promise = new MyPromise((resolve, reject) => {
setTimeout(() => {
resolve("Promise resolved");
// reject("Promise rejected");
}, 1000);
});
promise.then(
value => console.log("Fulfilled:", value),
reason => console.error("Rejected:", reason)
);
这只是一个简化的 Promise 实现,它涵盖了 pending、fulfilled 和 rejected 状态以及 then 方法的基本逻辑。实际的 Promise 还需要考虑更多的细节,如链式调用、错误处理、异步操作的处理等。要在生产环境中使用,建议使用原生的 Promise 或第三方库来获得更完善和稳定的功能。
什么是async/await,如何使用?
async/await 是 JavaScript 中用于处理异步操作的一种现代化的语法特性。它使得异步代码的编写和理解更接近于同步代码,使得异步操作的流程更加清晰和可读。async/await 是建立在 Promise 之上的一种语法糖,用于更方便地处理 Promise 的链式调用。async:
- async 是一个关键字,用于定义一个函数,该函数返回一个 Promise 对象。
- async 函数内部可以包含 await 表达式,用于暂停函数的执行,直到 await 后的表达式完成并返回结果。
await:
- await 是一个关键字,只能在 async 函数内部使用。
- await 后面跟着一个返回 Promise 对象的表达式,该表达式可以是异步函数调用、Promise 对象等。
- 在 await 后的表达式完成之前,函数的执行会被暂停,直到 Promise 对象状态变为 fulfilled。
使用 async/await 的基本示例:
function fetchData() {
return new Promise(resolve => {
setTimeout(() => {
resolve("Data fetched successfully");
}, 1000);
});
}
async function fetchAndPrintData() {
try {
const data = await fetchData(); // 等待异步操作完成
console.log(data);
} catch (error) {
console.error("Error:", error);
}
}
fetchAndPrintData(); // 调用 async 函数
在这个示例中,fetchAndPrintData 是一个 async 函数,内部使用 await 暂停了执行,直到 fetchData 异步操作完成。使用 try/catch 来处理异步操作的结果或错误。
async/await和Promise有何区别,有何优势?
async/await 和 Promise 都是用于处理异步操作的方式,但它们在语法和使用上有一些区别,以及一些优势和劣势。
区别:语法:
- Promise 使用链式调用的方式,通过 .then() 和 .catch() 来处理异步操作的结果和错误。
- async/await 使用更类似同步代码的语法,通过 async 关键字定义异步函数,内部使用 await 暂停执行,并使用 try/catch 处理错误。
返回值:
- Promise 的 .then() 和 .catch() 方法返回的仍然是 Promise 对象,允许进行链式调用。
- async/await 中,await 后的表达式返回的是 Promise 的结果,而 async 函数本身返回的也是一个 Promise 对象。
优势:可读性:
async/await 的语法更接近同步代码,使异步操作的流程更加清晰和易读,减少了回调地狱(Callback Hell)的问题。错误处理:
在 Promise 中,错误处理需要使用 .catch() 方法,而 async/await 可以使用 try/catch 来处理错误,使得错误处理更加直观和统一。调试:
async/await 在调试时更容易跟踪代码执行流程,因为它更接近同步代码的写法。链式调用:
Promise 的链式调用对于一系列的异步操作很有用,但可能会造成代码深度嵌套,难以维护。
async/await 也可以链式调用,但代码的可读性更高,不易产生回调地狱。并发:
使用 Promise.all() 可以同时处理多个 Promise,在 async/await 中可以使用 Promise.all() 实现类似的功能。
选择使用时的考虑:
- 如果代码中已经广泛使用了 Promise,并且不打算重构,那么继续使用 Promise 可能更合适。
- 如果希望代码更易读、易于调试,并且要处理复杂的异步操作流程,那么可以考虑使用 async/await。
需要注意的是,async/await 内部仍然基于 Promise,因此它们并不是互斥的,而是可以相互配合使用的。
怎么理解JavaScript中的面向对象?
JavaScript 中的面向对象(Object-Oriented)编程是一种编程范式,它将程序的组织方式从简单的函数和数据结构转变为更加模块化和抽象化的方式。在面向对象编程中,程序被组织为一组对象,每个对象都具有属性(数据)和方法(函数),这些对象可以相互交互和协作,从而构建出更复杂的系统。
面向对象编程的主要概念包括:
类(Class):类是对象的蓝图或模板,定义了对象的属性和方法。类描述了对象的特征和行为,可以看作是一个抽象的概念。对象(Object):对象是类的实例,具有类定义的属性和方法。对象是面向对象编程中的基本单位,代表现实世界中的实体。封装(Encapsulation):封装是将数据和操作封装在一个对象中,隐藏对象的内部细节,只暴露必要的接口供外部使用。继承(Inheritance):继承是通过创建一个新的类来扩展已有的类,子类继承了父类的属性和方法,并可以添加自己的属性和方法。多态(Polymorphism):多态允许不同的类实现相同的接口或方法,并可以以相同的方式进行调用,提高了代码的灵活性和可复用性。
在 JavaScript 中,虽然它是一门基于原型的编程语言,但也支持面向对象编程。通过使用构造函数、原型链、类、继承等特性,可以在 JavaScript 中实现面向对象的编程风格。ES6 引入了更现代的类和继承语法,使得 JavaScript 的面向对象编程更加清晰和直观。
以下是一个简单的 JavaScript 面向对象编程的示例:
// 定义一个类
class Animal {
constructor(name) {
this.name = name;
}
speak() {
console.log(`${this.name} makes a sound.`);
}
}
// 定义一个子类继承自 Animal
class Dog extends Animal {
speak() {
console.log(`${this.name} barks.`);
}
}
// 创建对象并调用方法
const dog = new Dog("Buddy");
dog.speak(); // 输出:Buddy barks.
前端面试题库 (面试必备) 推荐:★★★★★
地址:前端面试题库
JavaScript中的垃圾回收机制是什么?
JavaScript 中的垃圾回收(Garbage Collection)是一种自动管理内存的机制,用于检测和回收不再使用的内存,以防止内存泄漏和资源浪费。在 JavaScript 中,开发人员不需要手动释放内存,因为垃圾回收机制会自动处理不再使用的内存对象。
JavaScript 中的垃圾回收主要基于以下两个概念:引用计数垃圾回收:
- 引用计数是一种最简单的垃圾回收机制,它通过维护每个对象的引用计数来判断对象是否可达。
- 当一个对象被引用时,它的引用计数加一;当一个对象的引用被移除时,它的引用计数减一。
- 如果一个对象的引用计数变为零,说明没有任何引用指向它,该对象不再可达,垃圾回收机制会将其回收。
标记-清除垃圾回收:
- 标记-清除是一种更高级的垃圾回收算法,通过判断对象是否可达来确定对象是否应该回收。
- 垃圾回收器首先从根对象(如全局对象、活动函数的局部变量等)开始,标记所有可达对象。
- 之后,垃圾回收器会遍历所有对象,清除没有被标记为可达的对象,将其内存回收。
需要注意的是,引用计数垃圾回收在解决循环引用(两个对象相互引用)方面存在问题,因为即使对象之间相互引用,它们的引用计数也不会变为零。而标记-清除垃圾回收则能够处理循环引用。
现代 JavaScript 引擎通常使用基于标记-清除的垃圾回收机制。例如,V8 引擎(Chrome、Node.js)采用了分代垃圾回收策略,将对象分为新生代和老生代,以更高效地进行垃圾回收。垃圾回收是一种重要的机制,它确保在代码执行期间不会出现内存泄漏问题,提高了应用的性能和稳定性。
JavaScript有哪些情况会导致内存泄漏?
JavaScript 中的内存泄漏是指程序中已不再使用的内存没有被正确释放,导致内存占用不断增加,最终可能导致应用程序的性能下降甚至崩溃。以下是一些可能导致内存泄漏的常见情况:循环引用:
当两个或多个对象彼此相互引用,而且没有其他对象引用它们,就会形成循环引用。这会阻止垃圾回收器回收这些对象,导致内存泄漏。未清理的定时器和事件监听:
如果使用 setTimeout、setInterval 或 addEventListener 注册了定时器或事件监听器,但在不再需要时未进行清理,这些定时器和监听器将继续持有对象的引用,阻止垃圾回收。闭包:
闭包可以使函数内部的变量在函数执行结束后仍然被引用,导致这些变量的内存无法释放。特别是在循环中创建闭包时,可能会导致内存泄漏。未使用的全局变量:
如果创建了全局变量,但没有及时销毁或解除引用,这些变量将继续占用内存,即使在不再需要它们的情况下也是如此。DOM 元素引用:
在 JavaScript 中,保留对 DOM 元素的引用,即使这些元素从页面中删除,也会导致内存泄漏。必须确保在不需要 DOM 元素时解除引用。大量缓存:
缓存数据和对象可以提高性能,但如果缓存不受限制地增长,会导致内存泄漏。必须定期清理缓存,删除不再需要的数据。忘记释放资源:
例如,在使用了底层资源(如数据库连接、文件句柄等)后,没有显式地关闭或释放这些资源,可能导致资源泄漏。循环引用的事件处理器:
如果在 DOM 元素上注册了事件处理器,而这些事件处理器引用了其他对象,且这些对象又引用了相同的 DOM 元素,可能会导致循环引用,阻止垃圾回收。
为了避免内存泄漏,开发者应该注意适时释放不再需要的资源、解除引用,确保定时器和事件监听器的正确清理,以及注意循环引用的情况。使用浏览器的开发者工具和内存分析工具可以帮助识别内存泄漏问题。
什么是防抖,节流函数,如何实现?
防抖(Debouncing)和节流(Throttling)是两种常用的优化技术,用于限制频繁触发的事件的执行次数,从而提升性能和用户体验。
防抖是指在事件触发后,等待一段时间(例如 200 毫秒),如果在这段时间内没有再次触发事件,那么执行相应的操作。如果在等待时间内又触发了事件,那么等待时间会被重置。节流是指在事件触发后,一段时间内只执行一次相应的操作。无论触发多少次事件,都会在每个固定的时间间隔内执行一次。
防抖的实现:
function debounce(func, delay) {
let timerId;
return function (...args) {
clearTimeout(timerId);
timerId = setTimeout(() => {
func.apply(this, args);
}, delay);
};
}
// 使用示例
const debouncedFn = debounce(() => {
console.log('Debounced function called');
}, 200);
window.addEventListener('scroll', debouncedFn);
节流的实现:
function throttle(func, delay) {
let lastTime = 0;
return function (...args) {
const currentTime = new Date().getTime();
if (currentTime - lastTime >= delay) {
func.apply(this, args);
lastTime = currentTime;
}
};
}
// 使用示例
const throttledFn = throttle(() => {
console.log('Throttled function called');
}, 200);
window.addEventListener('scroll', throttledFn);
浅拷贝,深拷贝是什么?如何实现一个深拷贝函数?
浅拷贝和深拷贝是两种不同的对象复制方式,涉及到对象的引用关系。下面分别对浅拷贝和深拷贝进行解释:
浅拷贝:在浅拷贝中,创建一个新对象,然后将原始对象的属性值复制到新对象中。如果属性值是基本类型,那么直接复制其值;如果属性值是对象或数组等引用类型,那么只是复制其引用,新对象和原始对象共享这些引用。浅拷贝只复制对象的一层属性。深拷贝:在深拷贝中,递归地复制一个对象及其嵌套的所有属性,直到所有嵌套的属性都是基本类型为止。这样创建了一个完全独立的对象副本,原始对象和新对象之间没有任何引用关系。
以下是一个简单的深拷贝函数的示例:
function deepClone(obj) {
if (obj === null || typeof obj !== 'object') {
return obj;
}
let clone = Array.isArray(obj) ? [] : {};
for (let key in obj) {
if (obj.hasOwnProperty(key)) {
clone[key] = deepClone(obj[key]);
}
}
return clone;
}
const originalObj = {
a: 1,
b: { c: 2 },
d: [3, 4]
};
const copiedObj = deepClone(originalObj);
console.log(copiedObj); // 深拷贝后的新对象
console.log(copiedObj === originalObj); // false,新对象和原始对象无关联
console.log(copiedObj.b === originalObj.b); // false,嵌套对象也是深拷贝
需要注意的是,上述深拷贝函数只是一个简单的实现示例,可能在某些特定情况下存在性能问题。在实际项目中,可以使用成熟的深拷贝工具库,如 lodash 的 cloneDeep 方法,来处理深拷贝的需求。
深拷贝如何解决循环引用的问题?
深拷贝是在创建一个对象的副本时,递归地复制其所有嵌套属性和子对象。在深拷贝过程中,如果对象存在循环引用,即某个对象引用了自身或与其他对象形成了循环引用关系,那么简单的递归拷贝可能会导致无限循环,甚至造成内存溢出。
为了解决循环引用问题,你可以在深拷贝过程中使用一些策略。以下是一种常见的方法
- 使用一个缓存对象来跟踪已经被拷贝的对象,以及它们在新对象中的引用。这可以防止无限递归。
- 在每次拷贝一个对象之前,先检查缓存对象,如果该对象已经被拷贝,则直接返回缓存中的引用,而不是递归拷贝。
下面是一个使用JavaScript实现深拷贝并解决循环引用问题的示例
function deepCopyWithCycles(obj, cache = new WeakMap()) {
if (obj === null || typeof obj !== 'object') {
return obj;
}
if (cache.has(obj)) {
return cache.get(obj);
}
if (obj instanceof Date) {
return new Date(obj);
}
if (obj instanceof RegExp) {
return new RegExp(obj);
}
const copy = Array.isArray(obj) ? [] : {};
cache.set(obj, copy);
for (const key in obj) {
if (obj.hasOwnProperty(key)) {
copy[key] = deepCopyWithCycles(obj[key], cache);
}
}
return copy;
}
const objA = {
name: 'Object A'
};
const objB = {
name: 'Object B'
};
objA.circularRef = objA;
objB.circularRef = objA;
const copiedObjA = deepCopyWithCycles(objA);
console.log(copiedObjA.name); // 输出: Object A
console.log(copiedObjA.circularRef.name); // 输出: Object A
console.log(copiedObjA.circularRef === copiedObjA); // 输出: true
console.log(copiedObjA.circularRef === copiedObjA.circularRef.circularRef); // 输出: true
在上面的示例中,deepCopyWithCycles 函数使用了一个 WeakMap 来缓存已经拷贝的对象,以及它们在新对象中的引用。这样,即使对象存在循环引用,也可以正确地处理。同时,这个函数也考虑了处理特殊类型如 Date 和 RegExp。
什么是事件委托,为什么要使用事件委托?
事件委托(Event Delegation)是一种在 Web 开发中常用的事件处理技术,它通过将事件监听器绑定到父元素而不是每个子元素上,以达到优化性能、简化代码和处理动态内容的目的。
事件委托的原理是利用了事件冒泡机制。当子元素上的事件被触发时,该事件会向上冒泡到父元素,父元素可以捕获并处理这个事件。通过在父元素上监听事件,可以捕获到子元素触发的事件,从而实现对子元素的事件处理。
事件委托的优势和原因:
减少事件监听器的数量:当页面上存在大量的子元素时,为每个子元素都绑定事件监听器会增加内存占用和性能开销。使用事件委托可以减少事件监听器的数量,只需在父元素上绑定一个监听器。动态添加的元素也能被处理:对于通过 JavaScript 动态添加到页面的元素,无需再次绑定事件监听器,因为它们是父元素的后代,事件会冒泡到父元素。性能优化:由于事件监听器较少,减少了事件冒泡的层级,可以提升页面的响应速度和性能。方便维护:在有大量相似子元素的情况下,使用事件委托可以简化代码,使代码更易维护和理解。
如何实现数组扁平化?
- 递归方法:使用递归遍历数组的每个元素,如果元素是数组,则递归处理;如果是基本类型,则添加到结果数组中。
function flattenArray(arr) {
const result = [];
for (const item of arr) {
if (Array.isArray(item)) {
result.push(...flattenArray(item));
} else {
result.push(item);
}
}
return result;
}
const nestedArray = [1, [2, 3, [4, 5]], 6];
const flattenedArray = flattenArray(nestedArray);
console.log(flattenedArray); // [1, 2, 3, 4, 5, 6]
- 使用 Array.prototype.flat 方法(ES6):flat 方法用于将嵌套的数组扁平化,可以指定扁平化的深度,默认为 1。
const nestedArray = [1, [2, 3, [4, 5]], 6];
const flattenedArray = nestedArray.flat(Infinity);
console.log(flattenedArray); // [1, 2, 3, 4, 5, 6]
- 使用 reduce 方法:使用 reduce 方法将多维数组逐一展开。
function flattenArray(arr) {
return arr.reduce((result, item) => {
return result.concat(Array.isArray(item) ? flattenArray(item) : item);
}, []);
}
const nestedArray = [1, [2, 3, [4, 5]], 6];
const flattenedArray = flattenArray(nestedArray);
console.log(flattenedArray); // [1, 2, 3, 4, 5, 6]
- 使用扩展运算符(ES6):使用扩展运算符和递归来实现数组扁平化。
function flattenArray(arr) {
return [].concat(...arr.map(item => Array.isArray(item) ? flattenArray(item) : item));
}
const nestedArray = [1, [2, 3, [4, 5]], 6];
const flattenedArray = flattenArray(nestedArray);
console.log(flattenedArray); // [1, 2, 3, 4, 5, 6]
前端面试题库 (面试必备) 推荐:★★★★★
地址:前端面试题库
什么是函数柯里化?
函数柯里化(Currying)是一种将一个接受多个参数的函数转化为一系列接受一个参数的函数的技术。通过函数柯里化,可以将一个函数的调用过程分解为一系列较小的函数调用,每个函数接受一个参数,并返回一个新的函数,直至所有参数都被收集完毕,最后返回最终结果。
函数柯里化的主要思想是,将多参数函数转化为一系列只接受一个参数的函数,这样可以在每个步骤中捕获部分参数,生成一个新的函数来处理这些参数,最终产生一个累积所有参数的结果。
function add(a) {
return function(b) {
return a + b;
};
}
const add5 = add(5); // 第一个参数 5 固定
console.log(add5(3)); // 输出 8,传入第二个参数 3
在这个示例中,add 函数接受一个参数 a,然后返回一个新的函数,这个新函数接受参数 b,并返回 a + b 的结果。通过调用 add(5),可以固定第一个参数为 5,然后返回一个接受一个参数的函数 add5。随后调用 add5(3),将参数 3 传递给 add5 函数,得到结果 8。
函数柯里化的好处包括:
- 参数复用:可以将一些参数在多个场景中复用,生成新的函数。
- 函数组合:可以更方便地将多个函数组合在一起,实现更复杂的功能。
- 延迟执行:可以在柯里化的过程中,只传递一部分参数,然后在后续调用中传递剩余参数,实现延迟执行。
什么是函数的链式调用?
函数的链式调用是指通过在函数调用的结果上连续调用其他函数,形成一个函数调用的链条。每次调用都会返回一个新的对象或值,从而允许在一个连续的调用序列中执行多个操作。链式调用在很多 JavaScript 库和框架中广泛使用,它能够使代码更具有可读性和流畅性。
链式调用的好处在于可以在一个语句中完成多个操作,从而减少了中间变量的使用,使代码更加紧凑和易于理解。这种方式尤其在操作对象或调用方法链时非常有用。
class Calculator {
constructor(value = 0) {
this.value = value;
}
add(num) {
this.value += num;
return this; // 返回实例以支持链式调用
}
subtract(num) {
this.value -= num;
return this;
}
multiply(num) {
this.value *= num;
return this;
}
divide(num) {
this.value /= num;
return this;
}
getValue() {
return this.value;
}
}
const result = new Calculator(10)
.add(5)
.multiply(2)
.subtract(3)
.divide(2)
.getValue();
console.log(result); // 输出 7,(((10 + 5) * 2 - 3) / 2)
在上述示例中,Calculator 类具有一系列的方法,每个方法都会修改实例的属性并返回实例自身,以支持链式调用。通过链式调用,可以在一行中完成一系列的数学操作,使代码更加简洁和易读。
什么是严格模式,开启严格模式有什么作用?
严格模式(Strict Mode)是一种在 JavaScript 中的一种运行模式,它使得代码在执行时遵循更严格的语法和规则,从而减少一些常见的错误,并提供更好的错误检测和调试机制。
要开启严格模式,可以在脚本的顶部或函数的内部添加以下语句:"use strict"开启严格模式有以下作用:
- 禁止使用全局变量:在严格模式下,不允许隐式地创建全局变量。如果没有通过 var、let 或 const 声明的变量被赋值,会抛出引用错误。
- 禁止删除变量:在严格模式下,使用 delete 关键字删除变量或函数会导致语法错误。
- 禁止重复的参数名:在严格模式下,函数参数不能有重复的名称,否则会导致语法错误。
- 禁止使用八进制字面量:在严格模式下,不允许使用八进制字面量(以 0 开头)。
- 禁止对只读属性赋值:在严格模式下,不允许对只读属性赋值,否则会抛出类型错误。
- 强制 this 为 undefined:在严格模式下,函数内部的 this 不会自动指向全局对象,而是为 undefined。
- 禁止使用 with 语句:在严格模式下,不允许使用 with 语句,因为它会导致代码的不确定性和难以维护性。
更严格的错误检测:严格模式提供了更严格的错误检测机制,例如对未声明的变量赋值会抛出引用错误,而非严格模式下会创建一个全局变量。
ES6新特性
前端面试题库 (面试必备) 推荐:★★★★★
地址:前端面试题库
ES6之后出现了哪些新特性?
- 箭头函数(Arrow Functions):更简洁的函数定义语法,绑定了词法作用域中的 this。
- let 和 const 关键字:引入了块级作用域的变量声明方式,let 用于声明可变变量,const 用于声明常量。
- 模板字面量(Template Literals):更方便的字符串拼接方式,支持多行字符串和嵌入表达式。
- 解构赋值(Destructuring Assignment):通过模式匹配从数组或对象中提取值并赋给变量。
- 默认参数值(Default Parameters):在函数声明时为参数提供默认值,简化函数调用。
- 扩展操作符(Spread Operator):用于数组、对象等的展开操作,可用于复制、合并等。
- 剩余参数(Rest Parameters):允许将一组参数封装成一个数组,用于处理变长参数列表。
- 类(Classes):引入类和继承的语法糖,更接近传统的面向对象编程语言。
- Promise:提供了一种更优雅的处理异步操作的方式,用于处理回调地狱。
- 模块(Modules):引入了模块化的语法,允许将代码拆分成多个文件并进行导入和导出。
- 迭代器和生成器(Iterators and Generators):迭代器用于迭代数据结构,生成器用于简化异步编程。
- Symbol:引入了一种原始数据类型,表示唯一的标识符,用于对象属性的键名。
- Map 和 Set:引入了 Map 和 Set 数据结构,提供更灵活的数据存储和查找方式。
- 数组和对象的新方法:引入了许多用于处理数组和对象的新方法,如 map、filter、find、includes 等。
- 函数的扩展:引入了箭头函数、bind、call、apply 等函数的新特性和用法。
- 模块化加载:通过 import 和 export 关键字实现模块化的代码加载。
- Proxy 和 Reflect:Proxy 对象用于创建一个拦截目标对象操作的代理,Reflect 对象提供了操作对象的方法,可以用于代替一些原生对象方法。
- Async/Await:基于 Promise 的语法糖,更方便地编写异步代码,使其更接近同步代码的写法。
- Iterator 和 for...of 循环:引入了迭代器协议和 for...of 循环,使遍历数据结构变得更加简洁和灵活。
- 函数式编程特性:引入了许多函数式编程的特性,如箭头函数、map、filter、reduce 等,使得处理数据更加方便和高效。
- 数组的方法:ES6 引入了许多新的数组方法,如 find、findIndex、some、every 等,用于更方便地处理数组数据。
- 字符串的新方法:引入了一些新的字符串方法,如 startsWith、endsWith、includes、模板字符串中的标签函数等。
- 数字的新方法:引入了一些新的数字方法,如 Number.isNaN、Number.isInteger、Number.parseFloat 等。
- Map 和 Set 的方法:Map 和 Set 数据结构也引入了一些新的方法,如 keys、values、entries 等。
- 对象的新方法:对象也引入了一些新的方法,如 Object.assign、Object.keys、Object.values、Object.entries 等。
- 模板标签函数:可以在模板字符串前使用自定义函数,对模板进行处理,用于实现字符串的定制化输出。
- 默认导出和命名导出:在模块中可以使用 export default 和 export 来定义默认导出和命名导出。
- BigInt:引入了 BigInt 数据类型,用于表示任意精度的整数。
- 函数参数的默认值:函数参数可以指定默认值,简化函数调用时的参数传递。
- 函数参数的解构赋值:函数参数可以使用解构赋值,直接从传入的对象中提取属性值。
let、const、var的区别?
作用域:
var:使用 var 声明的变量具有函数作用域,即在函数内部声明的变量在整个函数体内都可见。
let 和 const:使用 let 和 const 声明的变量具有块级作用域,即在 {} 块内声明的变量只在该块内有效。声明提升:
var:var 声明的变量会发生声明提升,即变量的声明会被提升至当前作用域的顶部,但初始化的值会保留在原位置。
let 和 const:虽然也会发生声明提升,但使用 let 和 const 声明的变量在初始化之前是不可访问的。重复声明:
var:可以重复声明同名变量,不会引发错误。
let 和 const:不能在同一个作用域内重复声明同名变量,否则会引发错误。可变性:
var 和 let:声明的变量是可变的,可以重新赋值。
const:声明的变量是常量,一旦赋值就不能再修改。全局对象属性:
var 声明的变量会成为全局对象的属性,例如在浏览器环境中是 window 的属性。
let 和 const 声明的变量不会成为全局对象的属性。临时死区:
let 和 const 声明的变量会在声明之前存在一个“临时死区”,在该区域内访问变量会引发错误。
箭头函数与普通函数的区别是什么?
语法简洁性:
- 箭头函数的语法更为简洁,可以在一些情况下省略大括号、return 关键字和参数括号。
- 普通函数的语法相对繁琐,需要使用 function 关键字、大括号和参数括号。
this 绑定:
- 箭头函数的 this 绑定是词法作用域的,它会捕获当前上下文中的 this 值,无法通过 call、apply 或 bind 改变。
- 普通函数的 this 绑定是动态的,取决于函数的调用方式和上下文。
arguments 对象:
- 箭头函数没有自己的 arguments 对象,它会继承外层作用域的 arguments 对象(如果有的话)。
- 普通函数具有自己的 arguments 对象,其中包含了函数调用时传递的参数。
构造函数:
- 箭头函数不能用作构造函数,无法通过 new 关键字实例化对象。
- 普通函数可以用作构造函数,可以通过 new 关键字实例化对象。
递归:
- 由于箭头函数没有自己的 arguments 对象和函数名称,所以递归调用时相对不方便。
- 普通函数可以更方便地进行递归调用。
-
前端面试题库 (面试必备) 推荐:★★★★★
地址:前端面试题库
命名函数表达式:
- 箭头函数不能被命名,只能使用匿名函数表达式。
- 普通函数可以被命名,也可以使用匿名函数表达式。
扩展运算符的作用及使用场景有哪些?
扩展运算符(Spread Operator)是 ES6 引入的一种语法,用于展开(拆分)可迭代对象(如数组、字符串、对象等)为独立的元素,以便在函数调用、数组字面量、对象字面量等地方使用。扩展运算符的作用和使用场景包括以下几点:
函数调用中的参数传递:扩展运算符可以用于将一个数组展开为一个函数的参数列表,这对于传递动态数量的参数非常有用。
function add(a, b, c) {
return a + b + c;
}
const numbers = [1, 2, 3];
const result = add(...numbers); // 等同于 add(1, 2, 3)
数组字面量中的元素合并:扩展运算符可以将一个数组的元素合并到另一个数组中。
const array1 = [1, 2, 3];
const array2 = [4, 5, 6];
const mergedArray = [...array1, ...array2]; // 合并为 [1, 2, 3, 4, 5, 6]
复制数组和对象:扩展运算符可以用于浅复制数组和对象,创建一个新的数组或对象,而不是引用同一个内存地址。
const originalArray = [1, 2, 3];
const copiedArray = [...originalArray]; // 创建新数组,值相同但引用不同
const originalObject = { key1: 'value1', key2: 'value2' };
const copiedObject = { ...originalObject }; // 创建新对象,值相同但引用不同
字符串转为字符数组:扩展运算符可以将字符串转换为字符数组,以便逐个访问字符。
const str = 'hello';
const chars = [...str]; // 转为字符数组 ['h', 'e', 'l', 'l', 'o']
对象字面量中的属性合并:扩展运算符可以将一个对象的属性合并到另一个对象中。
const obj1 = { a: 1, b: 2 };
const obj2 = { c: 3, d: 4 };
const mergedObject = { ...obj1, ...obj2 }; // 合并为 { a: 1, b: 2, c: 3, d: 4 }
模板字符串如何使用?
模板字符串(Template Strings)是 ES6 引入的一种字符串语法,它允许在字符串中插入变量、表达式以及换行符,使字符串的拼接和格式化更加方便。模板字符串使用反引号()来界定字符串,并在 `${}`` 内部插入表达式或变量。
const name = 'Alice';
const age = 30;
// 使用模板字符串插入变量和表达式
const greeting = `Hello, my name is ${name} and I am ${age} years old.`;
console.log(greeting);
// 输出:Hello, my name is Alice and I am 30 years old.
模板字符串还支持多行文本:
const multilineText = `
This is a multiline text
that spans across multiple lines.
It's easy to format and read.
`;
console.log(multilineText);
/*
输出:
This is a multiline text
that spans across multiple lines.
It's easy to format and read.
*/
前端面试题库 (面试必备) 推荐:★★★★★
地址:前端面试题库
Set方法有哪些应用场景?
Set 是 ES6 引入的一种数据结构,它类似于数组,但不允许有重复的值,且没有固定的索引。Set 内部的值是唯一的,不会存在重复的元素。Set 对象的方法和特性使它在许多场景下非常有用,以下是一些常见的 Set 方法的应用场景:
去重:最常见的用途就是用于去除数组中的重复元素。将数组转换为 Set,再将 Set 转换回数组,就能轻松去重。
const array = [1, 2, 2, 3, 3, 4, 5];
const uniqueArray = [...new Set(array)]; // 去重后的数组:[1, 2, 3, 4, 5]
判断元素是否存在:使用 Set 的 has 方法可以快速判断一个元素是否存在于集合中。
const set = new Set([1, 2, 3]);
console.log(set.has(2)); // true
console.log(set.has(4)); // false
交集、并集、差集等操作:通过将多个 Set 对象转换为数组,然后利用数组的方法进行交集、并集、差集等操作。
const set1 = new Set([1, 2, 3]);
const set2 = new Set([2, 3, 4]);
const intersection = [...set1].filter(item => set2.has(item)); // 交集:[2, 3]
const union = [...set1, ...set2]; // 并集:[1, 2, 3, 4]
const difference = [...set1].filter(item => !set2.has(item)); // 差集:[1]
存储任意类型的数据:Set 可以存储任意类型的数据,包括基本数据类型和对象等。
const mixedSet = new Set();
mixedSet.add(1);
mixedSet.add('hello');
mixedSet.add({ key: 'value' });
迭代:使用 for...of 循环可以迭代 Set 中的每个元素,且顺序与添加顺序一致。
const set = new Set([1, 2, 3]);
for (const item of set) {
console.log(item);
}
前端面试题库 (面试必备) 推荐:★★★★★
地址:前端面试题库
defienProperty与proxy有何作用,区别是什么?
Object.defineProperty:Object.defineProperty 是一个用于直接在一个对象上定义一个新属性或修改现有属性的方法。它允许你精确地控制属性的各种特性,如可枚举性、可配置性、可写性等。主要作用如下:
- 定义新属性或修改现有属性的特性。
- 可以通过 get 和 set 方法实现属性的自定义读取和写入操作。
- 适用于修改已有对象的属性特性。
const obj = {};
Object.defineProperty(obj, 'name', {
value: 'Alice',
writable: false, // 不可写
enumerable: true, // 可枚举
configurable: true // 可配置
});
Proxy:Proxy 是 ES6 引入的一种代理机制,用于拦截对象上的操作,提供了更强大的操作对象的能力。通过使用 Proxy,可以捕获并自定义对象的各种操作,如读取属性、写入属性、删除属性、函数调用等。主要作用如下:
- 拦截对象的各种操作,实现自定义逻辑。
- 用于创建一个代理对象,而不是直接修改现有对象
const target = { name: 'Alice' };
const handler = {
get: function(target, property) {
console.log(`Getting property ${property}`);
return target[property];
}
};
const proxy = new Proxy(target, handler);
console.log(proxy.name); // 触发 get 操作,并输出 "Getting property name"
区别:
- Object.defineProperty 只能修改现有对象的属性特性,而 Proxy 则是创建一个代理对象,可以捕获和拦截各种操作。
- Object.defineProperty 只能拦截属性的读取和写入操作,而 Proxy 可以拦截更多的操作,包括函数调用、删除属性等。
- Object.defineProperty 的适用范围更窄,主要用于修改现有对象的属性特性。Proxy 则可以在更底层、更广泛地拦截和修改对象操作。
综上所述,Object.defineProperty 和 Proxy 在功能上有一定的重叠,但 Proxy 提供了更灵活和强大的能力,适用于更广泛的对象操作需求
Object.assign和扩展运算符是浅拷贝还是深拷贝?
Object.assign 方法和扩展运算符都是进行浅拷贝(Shallow Copy),而不是深拷贝(Deep Copy)。浅拷贝是指在拷贝对象时,只拷贝对象的一层属性,而不会递归地拷贝嵌套对象的属性。拷贝后的对象和原始对象会共享嵌套对象的引用。深拷贝是指在拷贝对象时,会递归地拷贝所有嵌套对象的属性,从而创建一个完全独立的副本,两者之间没有引用关系。使用 Object.assign 进行浅拷贝:
const originalObj = { a: 1, b: { c: 2 } };
const copiedObj = Object.assign({}, originalObj);
console.log(copiedObj); // { a: 1, b: { c: 2 } }
console.log(copiedObj === originalObj); // false
console.log(copiedObj.b === originalObj.b); // true,嵌套对象的引用相同
使用扩展运算符进行浅拷贝:
const originalObj = { a: 1, b: { c: 2 } };
const copiedObj = { ...originalObj };
console.log(copiedObj); // { a: 1, b: { c: 2 } }
console.log(copiedObj === originalObj); // false
console.log(copiedObj.b === originalObj.b); // true,嵌套对象的引用相同
ES6和commonJS的导入导出有何区别?
ES6 模块:ES6 引入了一种新的模块系统,它在语言层面提供了模块的支持。ES6 模块的导入和导出使用 import 和 export 关键字。
- 导出:使用 export 关键字将某个值、变量、函数或类导出为一个模块。
// 导出单个值
export const myVariable = 42;
// 导出多个值
export { foo, bar };
- 导入:使用 import 关键字引入其他模块导出的内容。
// 导入单个值
import { myVariable } from './myModule';
// 导入多个值
import { foo, bar } from './myModule';
CommonJS:CommonJS 是一种用于服务器端 JavaScript 的模块系统,它被广泛用于 Node.js。CommonJS 使用 require 来导入模块,使用 module.exports 或 exports 来导出模块。
- 导出:使用 module.exports 或 exports 将一个值、变量、函数或类导出为一个模块。
// 导出单个值
module.exports = 42;
// 导出多个值
exports.foo = foo;
exports.bar = bar;
- 导入:使用 require 来引入其他模块导出的内容。
// 导入单个值
const myVariable = require('./myModule');
// 导入多个值
const { foo, bar } = require('./myModule');
区别:
- 编程语言层面 vs 运行时层面:ES6 模块是 JavaScript 语言规范的一部分,在语言层面提供了模块支持。而 CommonJS 是一种运行时模块系统,主要用于服务器端。
- 静态 vs 动态:ES6 模块的导入和导出在静态分析阶段就能确定,因此可以进行静态优化。而 CommonJS 的导入和导出是在运行时动态执行的。
- 浏览器环境:ES6 模块在现代浏览器中得到了支持。CommonJS 在浏览器中需要使用工具(如 Browserify 或 webpack)进行转换。
- 导入导出语法:ES6 模块使用 import 和 export,而 CommonJS 使用 require 和 module.exports。
前端面试题库 (面试必备) 推荐:★★★★★
地址:前端面试题库






![[BUUCTF 2018]Online Tool1](https://img-blog.csdnimg.cn/direct/0a8a246dcfbf4aecb86ef040eec27fab.png)