目标检测锚框
最开始呢,我们需要先介绍一下框,先学会一下怎么画框
导入所需要的包
from PIL import Image
import d2lzh_pytorch as d2l
import numpy as np
import math
import torch
展示一下本次实验我们用到的图像,猫狗
d2l.set_figsize()
img = Image.open("catdog.png")
d2l.plt.imshow(img);

之后我们就可以在图中画框了,我们需要知道的是框的左上角和右下角坐标,注意,图像的左上角是原点。
知道了框左上角和右下角坐标,定义一个函数来画框
#使用边界框boundding box来描述目标位置,由矩形左上角坐标和右下角坐标
dog_bbox, cat_bbox = [20,15,137,516], [133, 43, 222, 158] # 随便设的
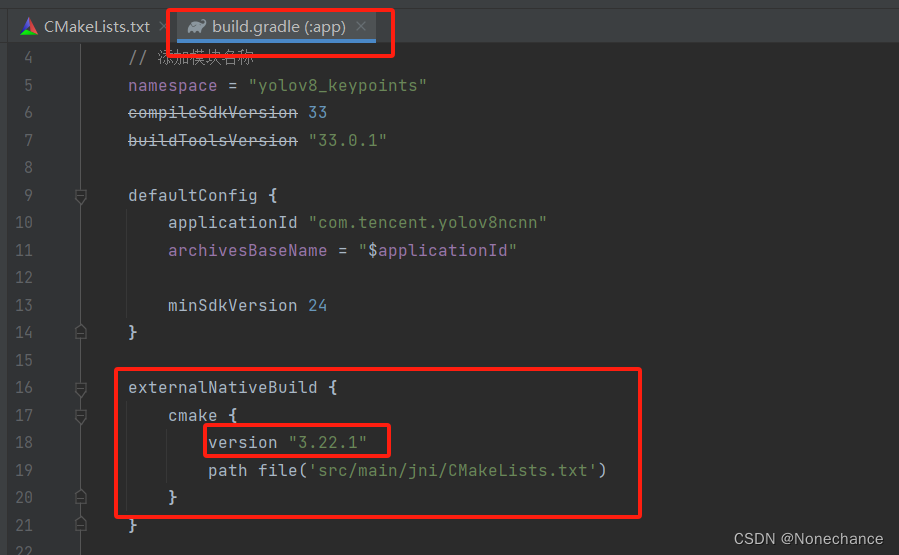
# 画出来
def bbox_to_rect(bbox, color):
return d2l.plt.Rectangle(
xy=(bbox[0], bbox[1]), width=bbox[2]-bbox[0], height=bbox[3]-bbox[1],
fill=False, edgecolor = color, linewidth=2)
fig = d2l.plt.imshow(img)
fig.axes.add_patch(bbox_to_rect(dog_bbox, 'blue'))
fig.axes.add_patch(bbox_to_rect(cat_bbox, 'red'))
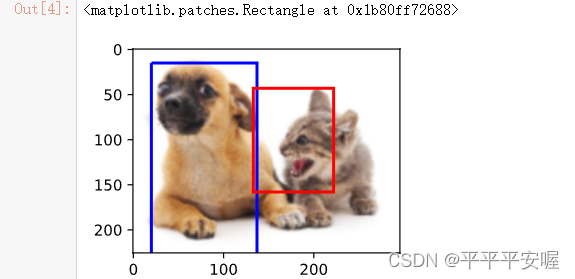
以上就是框的基本概念,应该还是很简单的,接下来我们需要知道什么是锚框
假设输入图像高为h,宽为w,我们分别以每个像素为中心生成不同形状的锚框,设锚框的大小为s,宽高比为r>0,锚框的宽和高为
w
s
r
ws\sqrt{r}
wsr,
h
s
1
r
hs\frac{1}{\sqrt{r}}
hsr1。
下面我们假设分别设定好了一组
s
1
,
s
2
,
…
,
s
n
s_1,s_2,\dots,s_n
s1,s2,…,sn和
r
1
,
r
2
…
,
r
m
r_1,r_2\dots,r_m
r1,r2…,rm,如果以每个像素为中心都使用所有大小和宽高比的组合,一共会得到whmn个锚框,计算复杂度有点高,因此,我们通常只考虑对包含
s
1
s_1
s1和
r
1
r_1
r1的大小和宽高比组合感兴趣,即
(
s
1
,
r
1
)
,
(
s
1
,
r
2
)
,
⋯
,
(
s
1
,
r
m
)
,
(
s
2
,
r
1
)
,
⋯
,
(
s
n
,
r
1
)
(s_1,r_1),(s_1,r_2),\cdots,(s_1,r_m),(s_2,r_1),\cdots,(s_n,r_1)
(s1,r1),(s1,r2),⋯,(s1,rm),(s2,r1),⋯,(sn,r1)
这样的话,对于每个像素点,我们就有n+m-1个锚框,总体整个图像有wh(n+m-1)个锚框
以下代码可以生成以上说的锚框,注意一下,此代码中的生成锚框的中心是以每个像素点的左上角为中心,如果需要像素点的中心为中心的话,在shifts_x和shifts_y加上1/w/2,1/h/2就好了,再往下就没有关于这方面的注意了,因为框的在的位置都是自己指定的。
# 本函数已经保存在d2lzh_pytorch包中方便使用
d2l.set_figsize()
img = Image.open("catdog.png")
w, h = img.size
def MultiBoxPrior(feature_map, sizes=[0.75, 0.5, 0.25], ratios=[1, 2, 0.5]):
# pairs 为刚刚说的组合,r记得开个根号
pairs = []
for r in ratios:
pairs.append([sizes[0], math.sqrt(r)])
for s in sizes:
pairs.append([s, math.sqrt(ratios[0])])
pairs = np.array(pairs)
ss1 = pairs[:, 0] * pairs[:, 1] # size * sqrt(r) 刚刚说的宽
ss2 = pairs[:, 0] / pairs[:, 1] # size / sqrt(r) 高
base_anchors = np.stack([-ss1, -ss2, ss1, ss2], axis=1)/2 # 按列拼接,xmin, ymin, xmax, ymax
h, w = feature_map.shape[-2:]
# 遍历每个像素点
shifts_x = np.arange(0, w)/w # 除以是为了归一化,后面会还原的
shifts_y = np.arange(0, h)/h
shift_x,shift_y = np.meshgrid(shifts_x, shifts_y)
shift_x = shift_x.reshape(-1)
shift_y = shift_y.reshape(-1)
shifts = np.stack((shift_x, shift_y, shift_x, shift_y), axis = 1) # 前两列用来定位左上角,后两列定位右下角 ps:误会了,y轴是从上往下的
anchors = shifts.reshape((-1, 1, 4)) + base_anchors.reshape((1, -1, 4))
# shifts.shape是w*h,4 base_anchors为(n+m),4 没有-1是因为没剔除,重复了也无所谓没事
# 将shift变成 w*h,1,4 base_anchors变为1*6*4 这样他们相加,根据Python的广播机制,size会变为w*h*6*4,w*h表示每个像素点,6代表锚框的个数,
# 4则分别代表每个框的左下角的xy 和右上角的xy
return torch.tensor(anchors, dtype=torch.float32).view(1, -1, 4)
X = torch.Tensor(1, 3, h, w) # 构造输入数据
Y = MultiBoxPrior(X, sizes=[0.75, 0.5, 0.25], ratios=[1, 2, 0.5])
Y.shape # torch.Size([1, 401376, 4])
# Y.shape 为(1, 锚框个数,4)
然后我们写一个绘制以某像素为中心的他的锚框函数
# 为了描绘图像以某个像素为中心的所有锚框,定义一个函数
def show_bboxes(axes, bboxes, labels=None, colors=None):
def _make_list(obj, default_values=None):
if obj is None:
obj = default_values
elif not isinstance(obj, (list, tuple)):
obj = [obj]
return obj
labels = _make_list(labels)
colors = _make_list(colors, ['b', 'g', 'r', 'm', 'c'])
for i, bbox in enumerate(bboxes):
color = colors[i % len(colors)]
rect = d2l.bbox_to_rect(bbox.detach().cpu().numpy(), color)
axes.add_patch(rect)
if labels and len(labels) > i:
text_color = 'k' if color == 'w' else 'w'
axes.text(rect.xy[0], rect.xy[1], labels[i], va='center', ha='center', fontsize=6, color=text_color, bbox=dict(facecolor=color,lw=0))
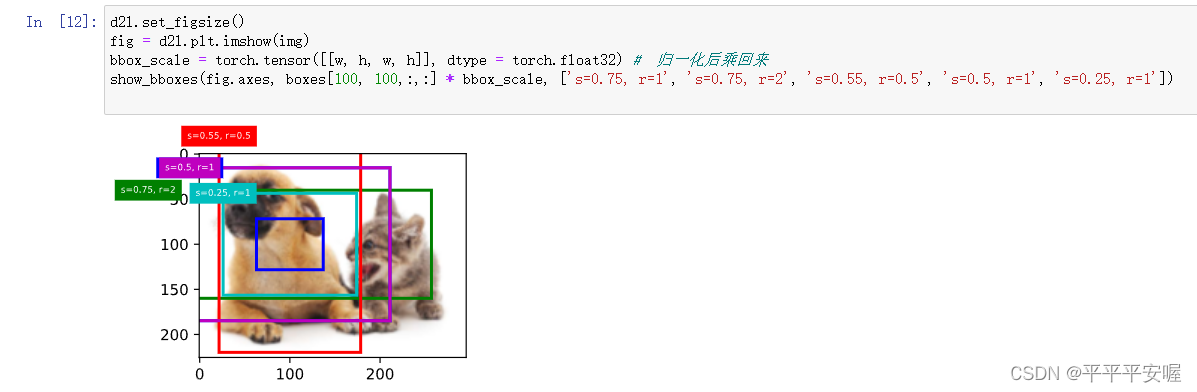
之后绘图,boxes就是把变回来原来的性质,boxes[100,100,:,:]为在像素点100,100上的所有锚框,第三个参数是锚框的索引为6是因为s和r各有三个,按理来说应该是3+3-1=5,但是函数里没有把重复的(s1,r1)组合去掉,所以就有六个(多一个也无伤大雅),第四个参数大小为4,是锚框左上角和右下角的坐标,
boxes = Y.reshape((h, w, 6, 4))
d2l.set_figsize()
fig = d2l.plt.imshow(img)
bbox_scale = torch.tensor([[w, h, w, h]], dtype = torch.float32) # 归一化后乘回来
show_bboxes(fig.axes, boxes[100, 100,:,:] * bbox_scale, ['s=0.75, r=1', 's=0.75, r=2', 's=0.55, r=0.5', 's=0.5, r=1', 's=0.25, r=1'])
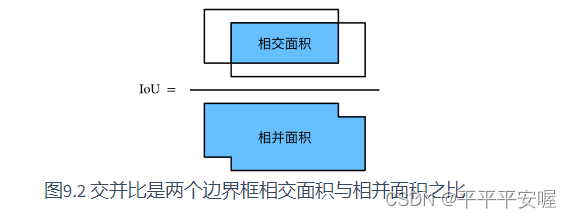
接下来介绍一下交互比,就是两个集合的交集/两个集合的并集
代码如下
# 计算交互比
def compute_intersection(set_1, set_2):
# set_1 为(n1, 4) n1 表示框的数量
# set_2 为(n2, 4) n2 表示框的数量
# return n1中的框在每个n2框中的交集,shape为(n1, n2)
# 左上角的点肯定是找max
lower_bounds = torch.max(set_1[:, :2].unsqueeze(1), set_2[:, :2].unsqueeze(0)) #set_1[:, :2].unsqueeze(1),变为(n1,1,2) 后面的变为(1,n2,2)
# 根据广播机制,n1中的每个点都会跟n2的比较,返回(n1,n2,2)
# 右下角找min
upper_bounds = torch.min(set_1[:, 2:].unsqueeze(1), set_2[:, 2:].unsqueeze(0))
intersection_dims = torch.clamp(upper_bounds - lower_bounds, min=0) # 计算宽度和高度 n1,n2,2
return intersection_dims[:, :, 0] * intersection_dims[:, :, 1]
def compute_jaccard(set_1, set_2):
intersection = compute_intersection(set_1, set_2)
areas_set_1 = (set_1[:, 2] - set_1[:, 0]) * (set_1[:, 3] - set_1[:, 1]) # n1
areas_set_2 = (set_2[:, 2] - set_2[:, 0]) * (set_2[:, 3] - set_2[:, 1]) # n2
union = areas_set_1.unsqueeze(1) + areas_set_2.unsqueeze(0) - intersection
return intersection / union
标注训练集的锚框
在训练集中,我们将每个锚框当做一个训练样本,每个锚框有两个标签,一个是锚框的类别,一个是锚框的偏移量,在目标检测时,我们首先生成多个锚框,然后为每个锚框预测类别以及偏移量,接着根据预测的偏移量调整锚框位置从而得到预测边界框,最后筛选需要输出的预测边界框。
直接借用一下动手学深度学习里的把


接下来我们给个具体的例子,。我们为读取的图像中的猫和狗定义真实边界框,其中第一个元素为类别(0为狗,1为猫),剩余4个元素分别为左上角的x和y坐标以及右下角的x和y轴坐标(值域在0到1之间)。这里通过左上角和右下角的坐标构造了5个需要标注的锚框,先画出这些锚框与真实边界框在图像中的位置。
bbox_scale = torch.tensor([w, h, w, h], dtype = torch.float32)
ground_truth = torch.tensor([[0, 0.1, 0.08, 0.52, 0.92], [1, 0.55, 0.2, 0.9, 0.88]])
anchors = torch.tensor([[0, 0.1, 0.2, 0.3], [0.15, 0.2, 0.4, 0.4],
[0.63, 0.05, 0.88, 0.98], [0.66, 0.45, 0.8, 0.8],
[0.57, 0.3, 0.92, 0.9]])
fig = d2l.plt.imshow(img)
show_bboxes(fig.axes, ground_truth[:, 1:] * bbox_scale, ['dog','cat'], 'k')
show_bboxes(fig.axes, anchors * bbox_scale, ['0', '1', '2', '3', '4'])

接下来这个函数实现锚框的标注和偏移量标注
# 实现为锚框标注类别和偏移量,将背景设为0, 1为狗,2为猫
def assign_anchor(bb, anchor, jaccard_threshold=0.5):
# bb 真实边界框 nb, 4
# anchor 待分配的anchor
# jaccard_threshold 阈值
# return (na, ) 为每个anchor分配真实bb索引,未分配为-1
na = anchor.shape[0]
nb = bb.shape[0]
jaccard = compute_jaccard(anchor, bb).detach().cpu().numpy() # shape (na, nb)
assigned_idx = np.ones(na) * -1
# 先为每个bb 分配anchor 此时不需要大于阈值
jaccard_cp = jaccard.copy()
for j in range(nb):
i = np.argmax(jaccard_cp[:, j])
assigned_idx[i] = j
jaccard_cp[i:] = float('-inf') # 赋值为负无穷,相当于去掉这一行
# 还未被分配的anchor,要满足阈值
for i in range(na):
if assigned_idx[i] == -1: # 未被分配
j = np.argmax(jaccard[i, :])
if jaccard[i, j] >= jaccard_threshold:
assigned_idx[i] = j
return torch.tensor(assigned_idx, dtype=torch.long)
def xy_to_cxcy(xy):
#将(x_min, y_min, x_max, y_max)形式的anchor转换成(center_x, center_y, w, h)形式的.
return torch.cat([(xy[:, 2:] + xy[:, :2]) / 2, # cx cy
xy[:, 2:] - xy[:, :2]], 1) # w h
def MultiBoxTarget(anchor, label):
'''
args:
anchor: torch.tensor 输入的锚框,一般是通过MultiBoxPrior生成, (1, 锚框总数,4)
label: 真实标签,(bn, 每张图片最多的真实锚框数,5)
每张图片最多的真实锚框数 或许描述为图片中最多的真实锚框数 更合适一些
第二维度中,如果给定的照片没有那么多锚框,先用-1填充,最后一维为[类别标签,四个坐标值]
每张图片最多的真实锚框数:这是一个预设的最大值,用于确保每张图片在这个批量中都有一个固定大小的空间来存储其真实锚框信息。
由于不同的图片可能有不同数量的真实锚框(例如,一张图片可能有3个物体,另一张可能有5个),所以需要设定一个最大数,
以便在批量处理时保持数据结构的一致性。
return
[bbox_offset, bbox_mask, cls_labels]
bbox_offset : 每个锚框的标注偏移量, (bn, 锚框总数*4)
bbox_mask : 形同bbox_offset,每个锚框的掩码,一一对应上面的偏移量, 负类锚框(背景)对应的掩码为0, 正类均为1
cls_labels : 每个锚框的标注类别,0为背景, 形状为(bn, 锚框总数)
'''
assert len(anchor.shape) == 3 and len(label.shape) == 3
bn = label.shape[0]
def MultiBoxTarget_one(anc, lab, eps=1e-6):
'''
MultiBoxTarget函数的辅助函数, 处理batch中的一个
Args:
anc : shape of (锚框总数, 4)
lab : shape of (真实锚框数, 5)
eps : 一个极小值,防止log 0
return
offset : (锚框总数*4)
mask (锚框总数*4, )
cls_labels : (锚框总数)
'''
an = anc.shape[0]
assigned_idx = assign_anchor(lab[:, 1:], anc) # (锚框总数
bbox_mask = ((assigned_idx >= 0).float().unsqueeze(-1)).repeat(1,4) # unsqueeze 在最后加一个维度,repeat(1,4)在第二个(刚刚加的)重复四次,变成(锚框总数,4)
cls_labels = torch.zeros(an, dtype = torch.long) # 0表示背景
assigned_bb = torch.zeros((an, 4), dtype = torch.float32) # 所有anchor对应的bb坐标
for i in range(an):
bb_idx = assigned_idx[i]
if bb_idx >= 0 : # 非背景
cls_labels[i] = lab[bb_idx, 0].long().item() + 1 # 注意+1
assigned_bb[i, :] = lab[bb_idx, 1:]
center_anc = xy_to_cxcy(anc) #(center_x, center_y, w, h)
center_assigned_bb = xy_to_cxcy(assigned_bb)
offset_xy = 10.0 * (center_assigned_bb[:, :2] - center_anc[:, :2]) / center_anc[:,2:]
offset_wh = 5.0 * torch.log(eps + center_assigned_bb[:, 2:] / center_anc[:, 2:])
offset = torch.cat([offset_xy, offset_wh], dim=1) * bbox_mask # (锚框总数, 4)
return offset.view(-1), bbox_mask.view(-1), cls_labels
batch_offset = []
batch_mask = []
batch_cls_labels = []
for b in range(bn):
offset, bbox_mask, cls_labels = MultiBoxTarget_one(anchor[0, :, :], label[b, :, :])
batch_offset.append(offset)
batch_mask.append(bbox_mask)
batch_cls_labels.append(cls_labels)
bbox_offset = torch.stack(batch_offset)
bbox_mask = torch.stack(batch_mask)
cls_labels = torch.stack(batch_cls_labels)
return bbox_offset, bbox_mask, cls_labels
进行一下测试
ground_truth = torch.tensor([[0, 0.1, 0.08, 0.52, 0.92],
[1, 0.55, 0.2, 0.9, 0.88]])
anchors = torch.tensor([[0, 0.1, 0.2, 0.3], [0.15, 0.2, 0.4, 0.4],
[0.63, 0.05, 0.88, 0.98], [0.66, 0.45, 0.8, 0.8],
[0.57, 0.3, 0.92, 0.9]])
labels = MultiBoxTarget(anchors.unsqueeze(dim=0),
ground_truth.unsqueeze(dim=0))
labels[2] # tensor([[2, 1, 2, 0, 2]]) 标签
labels[1] # tensor([[1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 0., 0., 0., 0., 1., 1., 1., 1.]]) 掩码
labels[0] # 偏移量
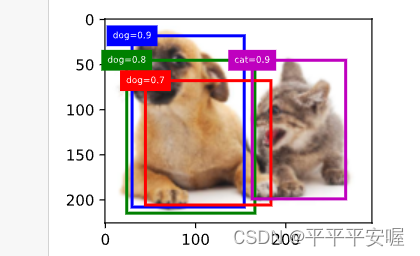
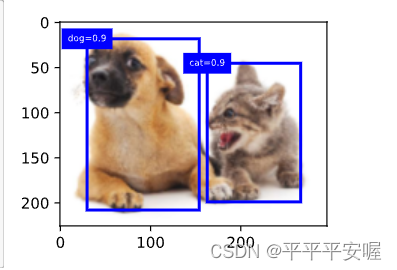
最后呢,介绍一下非极大值抑制,也就是NMS,最后输出的话我们很可能会得到很多的框,我们肯定不想看到那么多框,于是就有了NMS,原理大概是这样的,首先我们按每个框所属类别(非背景)的置信度降序排序,然后跟置信度最高的交互比超过阈值了,我们就把他去掉,依次往下类推
举个例子,先在一个图像上标几个框
# NMS
# 先假设偏移量都为0
anchors = torch.tensor([[0.1, 0.08, 0.52, 0.92], [0.08, 0.2, 0.56, 0.95],
[0.15, 0.3, 0.62, 0.91], [0.55, 0.2, 0.9, 0.88]])
offset_preds = torch.tensor([0.0] * (4 * len(anchors)))
cls_probs = torch.tensor([[0., 0., 0., 0.,], # 背景的预测概率
[0.9, 0.8, 0.7, 0.1], # 狗的预测概率
[0.1, 0.2, 0.3, 0.9]]) # 猫的预测概率
fig = d2l.plt.imshow(img)
show_bboxes(fig.axes, anchors * bbox_scale,
['dog=0.9', 'dog=0.8', 'dog=0.7', 'cat=0.9'])
然后是NMS函数的编写
# 以下函数已保存在d2lzh_pytorch包中方便以后使用
from collections import namedtuple
# 这行代码使用了 Python 的 namedtuple 函数,来定义一个命名元组 Pred_BB_Info。
# 命名元组是标准元组类型的子类,它允许元素通过名称以及位置进行访问,这使得代码更加可读和自文档化。
Pred_BB_Info = namedtuple("Pred_BB_Info", ["index", "class_id", "confidence", "xyxy"])
def non_max_suppression(bb_info_list, nms_threshold = 0.5):
'''
args:
bb_info_list:Pred_BB_Info的列表, 包括预测类别、置信度等信息
nms_threshold 阈值
return
output: Pred_BB_Info的列表, 只保留过滤后的边界框信息
'''
output = []
# 先根据置信度高低排序
sorted_bb_info_list = sorted(bb_info_list, key = lambda x:x.confidence, reverse=True)
while len(sorted_bb_info_list) != 0:
best = sorted_bb_info_list.pop(0)
output.append(best)
if len(sorted_bb_info_list) == 0:
break
bb_xyxy = []
for bb in sorted_bb_info_list:
bb_xyxy.append(bb.xyxy)
#iou = compute_jaccard(torch.tensor([best.xyxy]), torch.tensor([bb_xyxy]))[0] # (len(sorted_bb_info_list), )
iou = compute_jaccard(torch.tensor([best.xyxy]),
torch.tensor(bb_xyxy))[0] # shape: (len(sorted_bb_info_list), )
n = len(sorted_bb_info_list)
sorted_bb_info_list = [sorted_bb_info_list[i] for i in range(n) if iou[i] <= nms_threshold] # 去掉大于阈值的
return output
def MultiBoxDetection(cls_prob, loc_pred, anchor, nms_threshold = 0.5):
'''
args:
cls_prob : 经过softmax后得到各个锚框的准确率, shape(bn, 预测总类别数+1, 锚框个数)
loc_pred : 预测各个锚框的偏移量 (bn, 锚框个数*4)
anchor : (1, 锚框个数,4) MultiBoxPrior输出的默认锚框
nms_threshold:阈值
return
所有锚框的信息,shape(bn, 锚框个数, 6)
class_id, confidence, xmin,ymin,xmax,ymax
'''
assert len(cls_prob.shape) == 3 and len(loc_pred.shape) == 2 and len(anchor.shape) == 3
bn = cls_prob.shape[0]
def MultiBoxDetection_one(c_p, l_p, anc, nms_threshold=0.5):
'''
c_p (预测类别个数+1, 锚框个数)
l_p (锚框个数*4)
anc (锚框个数,4)
return
output (锚框个数, 6)
'''
pred_bb_num = c_p.shape[1]
anc = (anc + l_p.view(pred_bb_num, 4)).detach().cpu().numpy() # 加上偏移量
confidence, class_id = torch.max(c_p, 0)
confidence = confidence.detach().cpu().numpy()
class_id = class_id.detach().cpu().numpy()
# 正类label从0开始
pred_bb_info = [Pred_BB_Info(index = i, class_id = class_id[i] - 1, confidence = confidence[i], xyxy=[*anc[i]]) for i in range(pred_bb_num)]
obj_bb_idx = [bb.index for bb in non_max_suppression(pred_bb_info, nms_threshold)] # 当然也有可能选中背景
output = []
for bb in pred_bb_info:
output.append([
(bb.class_id if bb.index in obj_bb_idx else -1.0), # 选中背景也是-1
bb.confidence,
*bb.xyxy
])
return torch.tensor(output)
batch_output = []
for b in range(bn):
batch_output.append(MultiBoxDetection_one(cls_prob[b], loc_pred[b], anchor[0], nms_threshold))
return torch.stack(batch_output)
output = MultiBoxDetection(
cls_probs.unsqueeze(dim=0), offset_preds.unsqueeze(dim=0),
anchors.unsqueeze(dim=0), nms_threshold=0.5)
output

output输出是这样的,第一个元素-1表示被抑制或者是背景,0是狗1是猫,第二个元素就是概率,后面四个元素是左上角和右下角坐标
最后画图
fig = d2l.plt.imshow(img)
for i in output[0].detach().cpu().numpy():
if i[0] == -1:
continue
label = ('dog=', 'cat=')[int(i[0])] + str(i[1])
show_bboxes(fig.axes, [torch.tensor(i[2:]) * bbox_scale], label)









![[AutoSar]状态管理(二)单核 ECUM wakeup 流程——Can唤醒流程(TJA1043)](https://img-blog.csdnimg.cn/direct/04922bdc3b914028a66e4bd3a2b88463.png)