大家好. 几周前,我在澳大利亚 GopherCon 上发表了这个演讲[1], 但一些音/视频问题影响了效果,所以我在家重新录制了这个版本,enjoy!
这次演讲的主题是编写好的测试,但首先让我们思考一下为什么需要编写测试。为什么程序员要编写测试呢?编程相关的书籍说,测试是用来发现程序中的错误。例如这本书说“测试是对认为正常运行的程序进行有决心、系统的破坏尝试。”

确实如此,这也是程序员应该编写测试的原因。不过对今天在场的大多数人来说,这并不是(我们编写测试的)原因,因为我们不仅仅是程序员,而是软件工程师---让我告诉你我是什么意思。
我喜欢说,软件工程是当你在编程中加入时间和其他程序员时发生的事情。编程意味着让一个程序运行。你有一个问题要解决,你编写一些代码,运行它,测试它,调试它,得到你的答案,然后就完成了。这已经相当困难了,测试是这个过程的一个重要部分。但软件工程意味着在你长时间内一直使用并与其他人合作的程序中完成所有这些工作,这改变了测试的性质。

译者评注: 看来Russ Cox很喜欢讲啥是软件工程,上个演讲[Go Changes]( "Go Changes")也提到了..
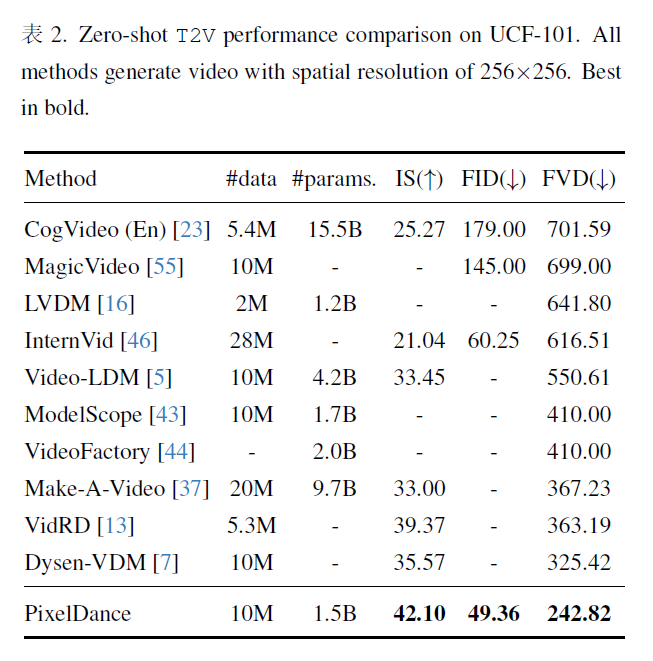
让我们先从二分查找函数的测试开始。这个函数 find 接受一个排序好的切片,一个目标值和一个比较函数,它使用二分查找来找到并返回两件事:首先是目标值如果存在的话应该出现的索引,其次是一个布尔值,表示目标值是否存在。大多数二分查找都有bug,这个也不例外。让我们来测试一下.

这是一个很好的二分查找功能的交互式测试器。你输入两个数字n和t,它会创建一个由于n个元素组成的切片,其中包含10的递增倍数. 然后在切片中搜索 T 并打印结果,并重复这个过程。这看起来可能很简单. 但有多少人通过运行并研究一段时间来测试生产代码呢?我们都这样做过。

在编程时,像这样的交互式测试器对于发现bug非常有用,尽管到目前为止,代码看起来似乎运行正常。但这样的测试器只适用于编程。如果你从事的是软件工程,这意味着需要让程序长时间运行并与其他人一起工作,这种测试器就不那么有用了。你需要的是一种 其他人每天在编写代码时都可以运行的东西,并且可以在每次提交时由计算机自动运行(译者评注: 指的就是CI吧)。手动测试你的程序只能确保它今天能工作,自动化&持续的测试则可以确保它明天和将来仍能工作,即使不太了解代码的其他人开始使用它---而且要明确的是,那个"不太了解代码的人"可能就是六个月甚至六周后的你。

(下图才)是软件工程师的测试,你可以在不清楚代码应该做什么的情况下运行它,任何同事或任何计算机都可以使用 go test 运行这个测试,并立即了解测试是否通过。相信你已经见过类似的测试了。

软件工程的理想状态是进行测试,以捕获以后可能出现的所有潜在bug。
如果你的测试满足这一理想状态,就应该放心地将代码自动部署到生产环境中,只要你的测试全部通过, 这就是人们所说的“持续部署”(Continuous Deployment)。如果你还没有这样做,如果这个想法让你感到紧张,那么值得自问为什么。要么你的测试足够好,要么不够好。如果足够好,那为什么不这样做呢?如果不够好,那就倾听审视这些"没把握"..,并弄清楚哪些测试被遗漏了.

几年前,我在开发新的Go 网站 go.dev[2] 的程序时,我们当时是手动部署该网站,而且至少每周我会做出一个在我机器上运行良好但部署到生产环境后却完全无法提供任何页面的更改---这既烦人又尴尬---解决办法是更好的测试和自动化连续部署。现在,每当有提交进入仓库,我们都会使用Cloud Build程序运行本地测试,将代码推送到新服务器,再运行一些仅在生产环境中运行的测试. 最后如果一切顺利,则将流量重定向到新服务器。
这以两种不同的方式让事情有所改进:首先,我不再造成令人尴尬的网站中断;其次,每个人都不再需要考虑部署网站了。如果他们想做出改变,例如修正一个错别字或添加一篇新博客文章,他们只需发送更改,然后对其进行审查、测试和提交,自动化流程(译者注:即CI/CD)会完成剩余的工作。

为了确信你的程序在其他人编辑时不会中断,并确信你的程序在测试全部通过时可以随时投入到生产,你需要一套非常好的测试。但一般来说,什么使测试变得好呢? 一般来说, 使测试代码变得优秀的因素与使非测试代码变得优秀的因素是一样的:努力工作、注意力和时间. 对于编写良好的测试代码,我没有任何灵丹妙药或硬性规则,就像对于编写良好的非测试代码一样. 不过,我确实收集了一些在 Go 上行之有效的技巧,我将在本次演讲中分享 20 条技巧.
Tips1. 轻松添加新的测试用例

这是最重要的建议,因为如果添加新的测试用例不容易,你就不会去做。Go在这方面已经有所帮助,我们专门设计Go测试,使其非常容易编写。

在包测试的级别上,这已经很好了,但在特定的包中,还可以做得更好。 我相信你知道表驱动测试。我们鼓励表驱动测试,因为它使添加新的测试用例变得非常容易。

下面是我们之前看到的一个例子。假设我们只有一个测试用例,并且想测试一个新的情况,我们根本不需要编写任何新的代码,只需添加一行新的数据。如果目标是让添加新测试变得容易,那么对于像这样的简单函数来说,向表中添加一行就足够了。不过,这确实提出了一个问题,我们应该添加哪些case?
这引出了下一个建议,即
Tips2 使用测试覆盖率 来 查找未经测试的代码

毕竟,测试无法发现未运行(未被覆盖到)的代码中的错误。
Go内置了对测试覆盖率的支持,下面是它的使用方式。 通过运行go test -coverprofile xxx.out生成覆盖率文件,然后运行go tool cover在浏览器中查看。

通过上图,可以发现我们的测试用例并不是很好,实际的二分查找代码是红色的,表示完全未经测试。
下一步是查看未经测试的代码,并考虑什么样的测试会使这些代码行运行。经过仔细检查,我们只测试了一个空切片,所以让我们添加一个切片不为空的case。现在我们可以再次运行(获取)覆盖率(的命令),这次我将使用编写的一个名为"uncover"的小命令行程序来读取覆盖率文件。

"uncover"会打印出未被测试覆盖的代码行,虽然它不能提供像Web视图那样的整体图像,但它可以让你停留在shell窗口中(查看)。"uncover"向我们展示了只有一行代码没有被测试执行,这是移动到切片的后半部分的那一行,这是合理的,因为我们的目标是切片的第一个元素。

让我们再添加一个测试,搜索最后一个元素。当我们运行测试时,它通过了,现在我们有100%的覆盖率,很好,我们完成了吗?
没有,这引出了下一个建议
Tips3: 覆盖率不能替代思考

覆盖率对于指出你可能忘记测试的代码片段 非常有用,但机械工具无法替代 实际思考困难的输入是什么、代码中的微妙之处, 以及它可能如何崩溃。
即使测试覆盖率达到100%,代码仍然可能存在bug,而这段代码确实有问题。这个建议同样适用于由覆盖率驱动的模糊测试,模糊测试只是试图通过探索更多代码"路径"来增加覆盖率。模糊测试也确实非常有帮助,但它也不能替代思考。

那么这里有什么遗漏呢?需要注意的一件事是,唯一找不到目标的测试用例 有一个空的输入切片,我们应该检查是否在带有值的切片中找到目标(情况),具体而言,我们应该检查目标小于所有值、大于所有值以及位于值中间时的情况。

所以让我们再添加三个新的测试用例。请注意,如果你认为你的代码可能无法正确处理某种情况,则添加一个新的测试用例应该尽可能简单,否则你可能会被诱惑不去费心。如果太困难,你可能不会这么做。
你还可以看到我们如何开始列举这个函数可能出错的所有重要方式,这些测试限制了所有未来的开发,以确保二分查找至少能够正常工作。
当我们运行这些测试时,它们会失败,返回的索引i是正确的,但指示是否找到目标的布尔值是错误的。那么让我们看看代码,return语句中的布尔表达式是错误的,它只检查索引是否在范围内,它还需要检查该索引处的值是否等于目标值,所以我们可以在这里进行修改(突出显示的部分),现在测试通过了,我们对测试覆盖感到非常满意,也认真思考过了。
我们还能做什么呢?
Tips4: 编写详尽的测试

如果可能的话,测试函数的每一个可能的输入。现在这可能不现实,但通常你可以在某些约束下测试达到特定大小的所有输入。

这是二分查找的详尽测试,我们首先创建一个包含10个元素的切片,具体为奇数1,3,5一直到19,然后考虑该切片的所有可能的长度前缀,对于每个前缀,我们考虑该前缀所有可能的目标,从0(小于切片中所有值)到长度的两倍(大于切片中的所有值)。
这将彻底测试每个可能的搜索路径,通过每个可能大小的切片,直到我们的长度为10的限制。但现在我们怎么知道答案是什么?
我们可以根据测试用例的具体情况进行一些数学计算,但有一种更好、更通用的方式,那就是编写一个与真实实现不同的参考实现。理想情况下,参考实现应该是显然正确的,但它可以是与真实实现方法不同的任何方法,通常这将是一种更简单、更慢的方法,因为如果它更简单和更快,你就会将其用作真正的实现。
在本例中,参考实现被称为slowFind,该测试检查slowFind和find的答案是否一致,由于输入很小,slowFind可以是一个简单的线性搜索(译者评注: 即 暴力遍历)。

这种生成一定大小的所有可能输入(即 入参), 然后与简单参考实现 进行结果比较的方式非常强大。其中一个重要的作用是涵盖所有基本的极端边界情况,比如零元素切片、一个元素的切片、奇数长度切片、偶数长度切片、两倍长度的幂长的切片等。
在大多数程序中,大多数bug都可以通过较小输入(即 入参)来复现,因此测试所有小输入是非常有效的。

结果表明,这个详尽的测试通过了,我们的想法相当不错。如果详尽测试失败,那意味着find和slowFind不一致,因此至少有一个是有bug的,但我们不知道是哪一个。添加一个对slowFind的直接测试 很容易,因为我们已经有一个测试数据表,这也是表驱动测试的另一个好处,表可以用于测试多个实现。
Tips5: 将测试用例与测试逻辑分开

在表驱动测试中,测试用例位于表中,处理它们的循环是测试逻辑,正如我们刚刚看到的那样,将它们分开可以让你在多个上下文中使用相同的测试用例。
那么现在我们已经完成了二分查找/二分搜索了吗?
事实证明,还有一个bug,这引出了建议六
Tips6: 寻找特殊情况

即使我们对所有小case进行了详尽的测试,仍然可能存在潜藏的bug。
现在代码还剩下一个bug。你可以暂停视频看一看,有人找到了吗?

如果你没发现, 没关系,这是一个非常特殊的情况,人们花了几十年的时间才注意到。Knuth告诉我们,尽管二分查找在1946年发布,但第一个正确无误的二分查找直到1964年才发布,但这个bug直到2006年才被发现。

这个bug是,如果切片中的元素数量非常多, 接近int的最大值,那么i + j就会溢出,因此(i+j)/2, 即切片中值的计算是错误的。这个bug在2006年, 在使用64位内存和32位int的C程序中被发现, 该程序对 包含超过10亿个条目的数组进行索引,这种特殊的组合在Go中基本不会发生 (因为在Go中,我们要求64位内存使用64位int,正是为了避免此类问题)。
但由于我们了解了这个bug,而且你永远不知道你或其他人将来会如何调整代码,最好还是避免这个bug。有两种标准方法之一可以修复这个数学溢出,稍微快一点的方法是是进行无符号除法。

假设我们现在修复了它,我们完成了吗?不,因为我们还没有编写一个测试。
Tips7:如果没有添加测试,那么就没有修复该bug

这在两个不同的方面都是正确的.
第一种方式是编程方式. 如果你没有测试它,则该错误甚至可能无法修复. 这可能听起来很愚蠢,但是这种情况在你身上发生过多少次? --- 有人告诉你一个错误. 你立即知道修复方法是什么. 你进行更改并告诉他们已修复. 他们回来后说不,它还是坏了. 编写测试可以让你避免尴尬. 你可以说,好吧,很抱歉我没有修复你的bug,但我确实修复了一个bug,我会再看一下这个bug.
第二种方式是软件工程方式,即 时间和其他程序员的方式. 错误不是随机的, 在任何给定的程序中,某些错误比其他错误更有容易发生。因此,如果你犯了一次错误,你或其他人将来可能会再犯。没有测试来阻止它们,bug就会再次出现。即使测试用例很难写,但事实上在这种情况下通常更值得去做的。

为了测试这种情况,一种可能是编写一个仅在32位系统上运行的测试, 并对2 GB的unit8进行二分搜索。然而,这需要大量的内存,并且我们现在几乎没有32位系统(的机器)了。
在这种情况下,有一个更巧妙的办法,因为通常是为了测试难以发现的错误,我们可以创建一个空结构体切片,无论有多长, 都不会占用内存。此测试在MaxInt 空结构体切片上调用Find,寻找一个空结构体作为目标,但随后传入的比较函数始终返回-1,要求(claiming)切片元素小于目标。这将使二分查找检查切片中越来越大的索引,这就是我们达到溢出的方式。
因此,如果我们撤消我们的修复并运行此测试,测试就会失败,而使用我们的修复,测试就会通过。现在bug已经被修复。
Tips8: 并非所有内容都适合放在表格中

这个特殊情况并不适合表格,但这没关系.
很多东西确实可以放在一张表格中, 这是我最喜欢的测试表之一,来自fmt.Printf测试。每一行都是一个printf格式,一个值的和预期的字符串。

实际的表格太大,无法放在一张幻灯片上,但这里有部分行。通过阅读该表,你就会开始看到哪些是明显的错误修复(issue xxx).

请记住Tips7,如果你没有添加测试,就没有修复bug. 该表使得添加每个测试都很简单,并且添加它们可以确保这些bug永远不会再次出现。
表格是将测试用例与测试逻辑分开的一种方法, 并且可以轻松添加新的测试用例。但有时你有太多的测试,甚至避免编写Go语法的开销也是有意义的。

例如,(上图)这是strconv包中的一个测试文件,用于测试字符串和浮点数之间的转换. 你可能认为为此输入编写解析器的工作量太大,但一旦你知道如何操作,它就不是什么工作了,并且能够定义测试迷你语言被证明是非常有用的。
我将快速演示解析器,以表明它并不复杂没太多内容。

我们读取文件,然后将其拆分为几行. 对于每一行,我们都会计算错误消息的行号.
切片元素0是第1行,我们截断该行末尾的任何注释,如果该行为空,我们跳过它。
到目前为止,这是相当标准的样板。现在好的部分来了,我们将该行拆分成多个字段,并提取出四个字段,然后根据类型字段进行float32或float64数学转换。

myatof64基本上是strconv.ParseFloat64,只不过它处理十进制p格式.让我们可以按照我复制的方式编写测试用例.

最后,如果结果不是我们想要的,会打印错误。这很像是表驱动测试,只是我们解析文件而不是遍历表格。它不适合放在一个幻灯片上,但开发时确实可以放在一个屏幕上(译者注: 这后半句未解其意)。
Tips9. 测试用例可以位于测试数据文件中

测试用例可以在测试数据文件中,不必位于你的源代码中。

再举一个例子, Go正则表达式包 包含一些从AT&T POSIX正则表达式库复制的测试数据文件。我不会详细介绍,但很感激他们选择为该库使用文件驱动的测试,因为这意味着我可以为Go复用测试数据文件。这是另一种特别格式(ad-hoc),但它易于解析和编辑。
Tips10.与其他实现进行比较

与AT&T正则表达式的测试用例进行比较有助于确保Go的包以完全相同的方式处理各种极端情况。我们还将Go的包与C++ RE2库进行了比较, 为了避免需要编译C++代码,我们采用了一种方式,将所有测试用例记录到文件,然后在Go中将该文件作为测试数据传入。

在文件中存储测试用例的另一种方法,是使用一对文件,一个用于输入,一个用于输出。为了实现go test -json,有一个名为test2json的程序,它读取测试输出并将其转换为JSON输出。
测试数据是文件对:测试输出和JSON输出。这是最短的文件。测试输出位于顶部,这是test2json的输入,并且应该在底部生成JSON输出。

下面是实现,展示从文件中读取测试数据的习惯用法。
我们首先使用filepath.Glob查找所有测试数据。如果失败或找不到任何内容,我们会抛出fatal。
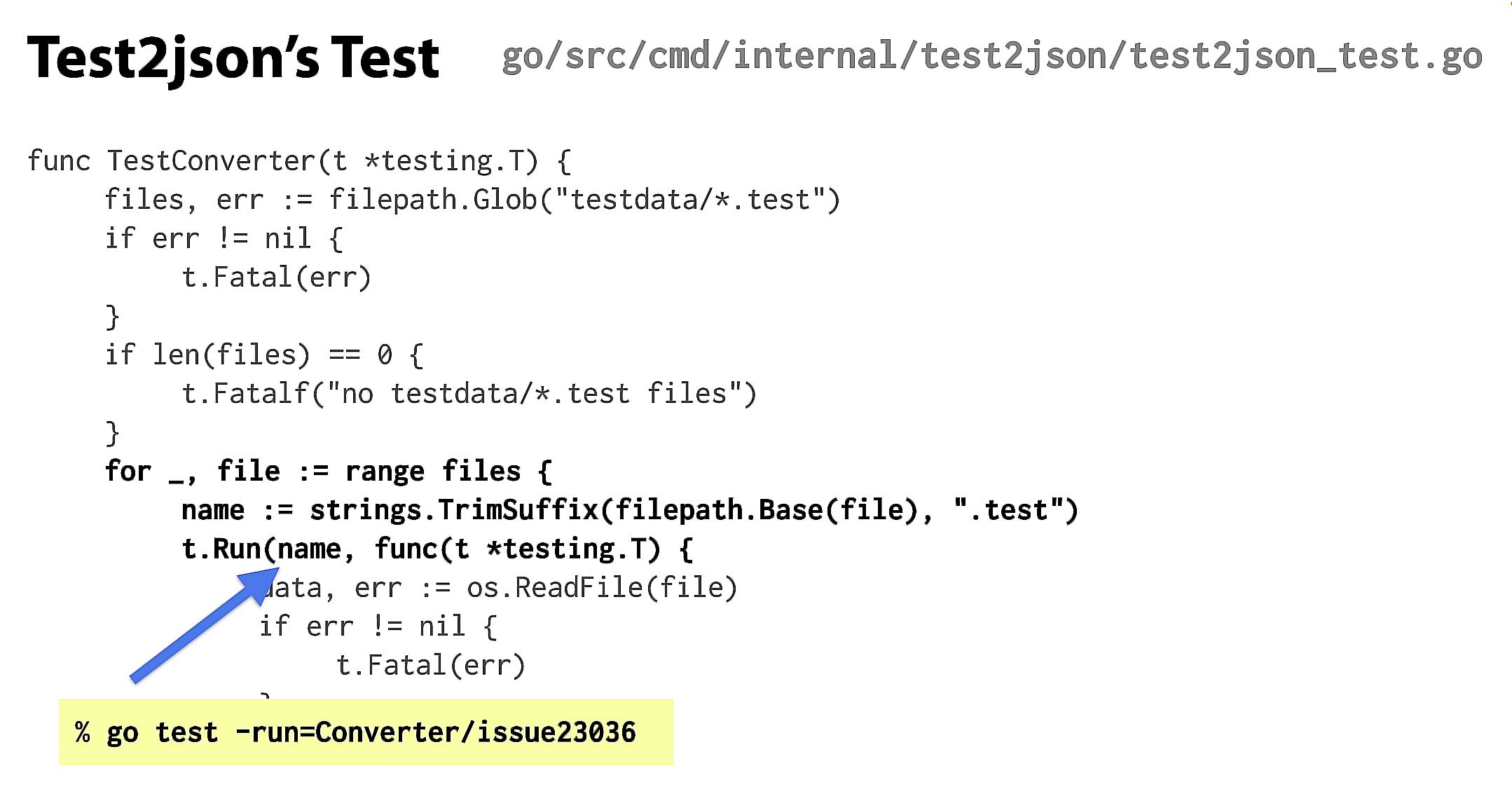
否则,我们将循环遍历所有文件。对于每一个,我们通过使用基本文件名(不带testdata/目录名,也不带文件后缀)来创建一个子测试名称。然后我们用该名称运行一个子测试。
如果你的测试用例足够复杂,每个文件都有一个,那么为每个文件创建自己的子测试几乎总是有意义的. 这样,当某个文件失败时,你可以使用go test -run运行该特定文件。
对于实际的测试用例,我们只需读取文件,运行转换器,并检查结果是否匹配。

为了进行检查,我一开始使用bytes.Equal,但随着时间的推移,编写一个自定义diffJSON来解析两个JSON结果并打印实际不同之处, 变得很值得。
Tips11.使测试失败可读

回顾一下,我们已经通过二分搜索看到了这一点。

我想我们都同意粉色部分并不是一个好的失败(提示信息)。但是,在黄色框中有两个细节使这些失败变得特别好。
首先,我们检查单个if语句中的两个返回值,然后在简洁的单行中打印完整的输入和输出。
其次,我们不会因为第一次失败而停止。我们调用t.Error而不是t.Fatal,以便运行更多的case。
结合起来,这两个选择让我们能够看到每个故障的完整详细信息,并在多个故障中寻找模式。
回到test2json,以下是其测试失败的原因。它会计算哪些事件不同并清晰地标记它们。

重要的一点是,在你第一次编写测试时,不必编写这种复杂的代码。bytes.Equal很好地开始并专注于代码。
但是,随着失败变得更加微妙,当你注意到自己花费了太多时间来阅读失败输出时,这是一个很好的信号,需要花一些时间使它们更具可读性。
此外,如果确切的输出发生变化并且你需要更正所有测试数据文件,那么更新这些类型的测试可能会有点烦人。
Tips12. 如果答案可能发生变化,请编写代码来更新它们


通常的方法是向测试添加 -update 标志。
这是 test2json 的更新代码。该测试定义了一个新标志 -update。当该标志为true时,测试会将计算出的答案写入答案文件,而不是调用 diffJSON。
现在,当我们有意更改 JSON 格式时,go test -update 会更正所有答案。你还可以使用像git diff这样的版本控制工具来检查更改,如果看起来不正确,则将其取消。
继续讨论测试文件的主题,有时将测试用例分成多个文件会很烦人。如果我今天写这个测试,我不会这样做。
Tips13. 使用 txtar 进行多文件测试用例

Txtar是我们几年前设计的一种新的存档格式,专门用于解决多文件测试用例的问题。Go解析器位于golang.org/x/tools/txtar,我还发现了用Ruby、Rust和Swift编写的解析器。
Txtar的设计有三个目标:

首先,足够简单,可以手动创建、编辑和阅读。
其次,能够存储文本文件树,因为我们需要它来执行go命令。
第三,在git历史记录和代码审查中进行很好的区分。
非目标包括成为完全通用的存档格式、存储二进制数据、存储文件模式、存储符号链接等特殊文件等。这些都不是目标,因为存档文件格式往往会变得任意复杂,而复杂性与第一个目标直接矛盾。
这些目标和非目标导致了一种非常简单的格式。下面是一个示例:

txtar文件以注释开头,在本例中为“Here are some pleasures”。然后,通常有零个或多个文件,每个文件都由--空格 文件名 空格 -- 形式的一行引入。该存档有两个单行文件:hello和g'day。这就是整个格式。没有转义、没有引用、不支持二进制数据、没有符号链接、没有可能的语法错误,也没有复杂性。

这是testdata中计算差异的包的实际用途:在这种情况下,注释对人们很有用,可以记录正在测试的内容。然后在此测试中,每个案例都是两个文件,后面跟着它们的差异。
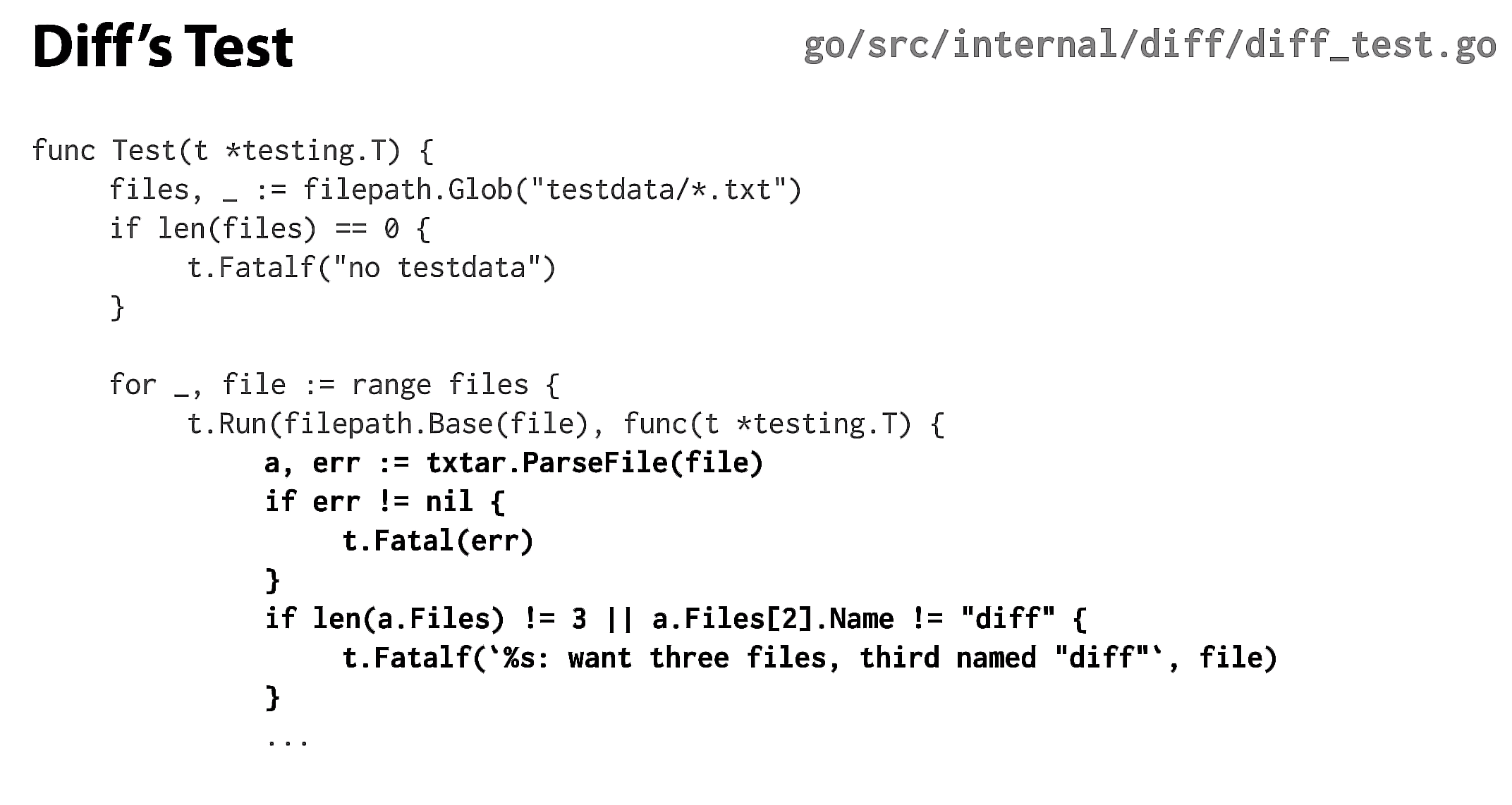
使用txtar文件几乎和编写它们一样简单。这是我们正在查看的diff包的测试。这是通常的基于文件的循环,但我们在文件上调用txtar.ParseFile。然后我们坚持认为存档包含三个文件,第三个文件名为diff。然后我们比较两个输入文件并检查结果是否与预期的差异相符。这就是整个测试。


你可能已经注意到,文件数据在使用之前会“干净”地传递给此函数。Clean允许我们为此测试添加一些特定于diff的扩展,而不会使txtar格式本身变得复杂。

第一个扩展处理以空格结尾的行,这确实发生在差异中。许多编辑器希望删除这些尾随空格,因此测试允许在txtar数据行末尾放置 。在此示例中,标记的行需要以单个空格结尾。

此外,txtar坚持文件中的每一行都以换行符结尾,但我们想在不以换行符结尾的文件上测试diff的行为。因此,测试允许末尾有字面上的^D。Clean会删除^D及其后面的换行符。在这种情况下,“新”文件最终没有最后的换行符,diff会正确报告该换行符。
因此,尽管txtar非常简单,你也可以轻松地将自己的格式调整分层。当然,记录这些内容很重要,以便接下来参与测试的人员能够理解它们。
Tips14. 对现有的格式进行注释,以创建测试迷你语言

注释现有格式,例如将 $ 和 ^D 添加到 txtar,这是一个强大的工具。
以下是注释现有格式的另一个例子。

这是对Go类型检查器的测试。这是一个普通的Go输入文件,但预期的类型错误已经添加到/* */错误注释中。我们使用/*注释,以便我们可以将它们准确地放置在应该报告错误的位置。该测试运行类型检查器并检查它是否在预期位置生成预期消息,并且不会生成任何意外消息。
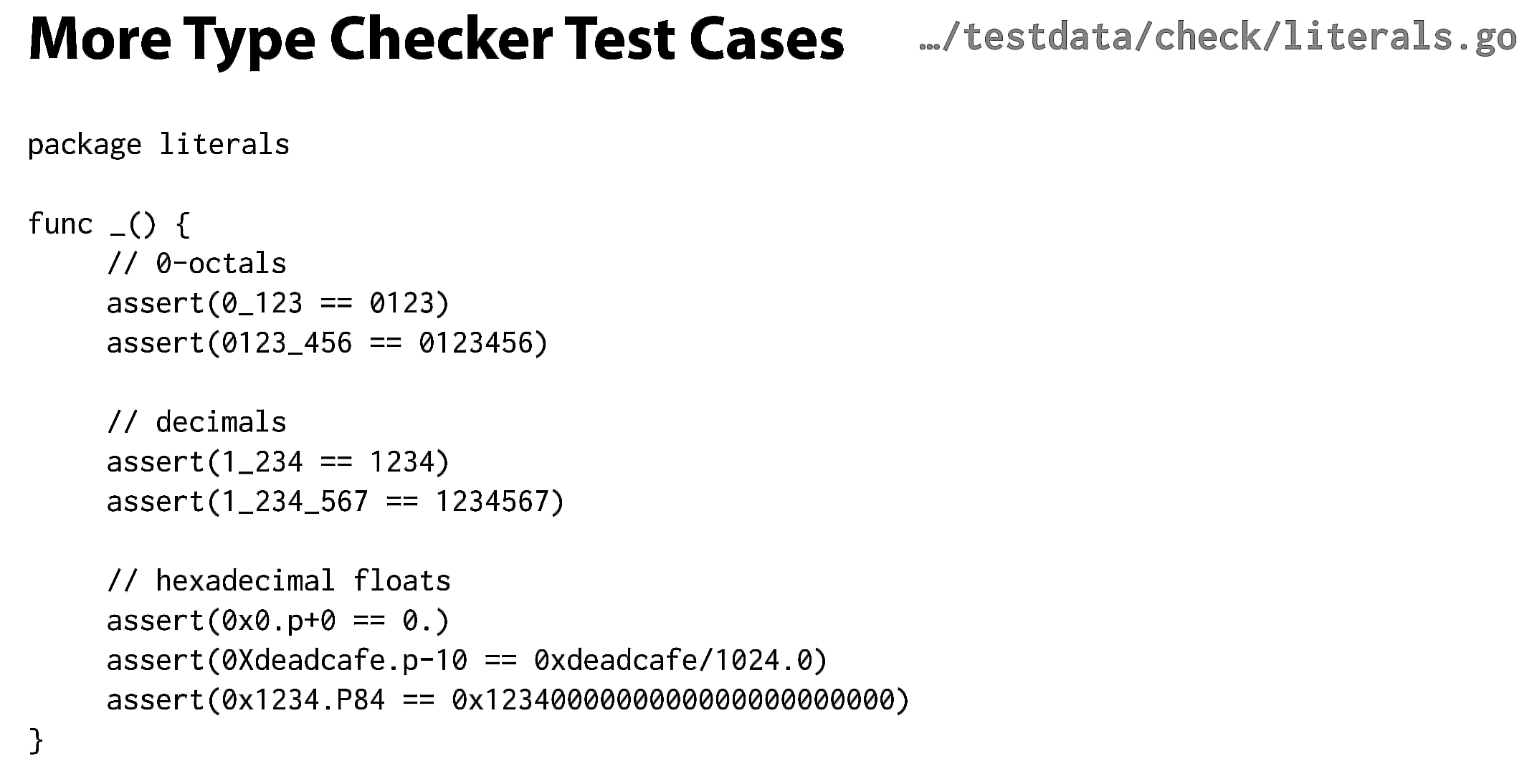
这是类型检查器的另一个例子。在此测试中,我们在通常的Go语法之上添加了一个assert注释。这使我们可以编写常量算术的测试,就像这个例子一样。类型检查器已经在计算每个常量表达式的布尔值,因此检查assert实际上只是检查常量是否已计算为true。
这里是另一个带注释的格式的例子。Ivy是一款交互式计算器。你输入程序(通常是简单的表达式),它会打印出答案。测试用例是这样的文件:

未缩进的行是Ivy输入,缩进的行是对Ivy在该点打印的输出的注释。这不仅使编写新测试用例变得非常容易,而且这些带注释的格式扩展了现有的解析器(parsers)和打印机(printers)。
有时从头开始编写自己的解析器和打印机会更有帮助。毕竟,大多数测试涉及创建或检查数据,而当你可以以方便的形式处理数据时,这些测试总是更加令人愉快。
Tips15. 编写parsers(解析器)和 printers(打印机)来简化测试

这些parsers和printers 不仅仅用于测试数据文件中的独立脚本,也可以在常规的Go代码中使用。
以下是运行deps.dev代码的测试片段。此测试设置一些数据库表行。它调用一个使用数据库的函数并正在进行测试。然后它检查数据库是否包含预期结果。Insert和Want调用使用专门为这些测试编写的数据库内容的迷你语言。解析器就像看起来一样简单:它将输入分割成行,然后将每行分割成字段。第一行给出列名称。就是这样。这些字符串中的确切间距并不重要,但如果它们全部对齐,当然看起来会很好。

因此,为了支持此测试,deps.dev团队还专门为这些测试编写了代码格式化程序。

它使用Go标准库来解析测试源文件, 然后它会遍历Go语法树来查找对Insert或Want的调用。它提取字符串参数并将它们解析到表中。然后,它将表重新打印回字符串,将字符串重新插入语法树中,并将语法树重新打印回Go源代码。这只是gofmt的扩展版本,使用与gofmt相同的软件包。我不会向你展示它,但代码并不多。

parsers和printers花了一些时间来编写。但现在每次有人编写测试时,测试都会变得更容易编写。每次测试失败或需要更新时,调试都会变得更加容易。如果你从事软件工程,收益会随着程序员的数量和项目的生命周期而变化。对于deps.dev,花在parsers和printers上的时间已经节省了很多倍。也许更重要的是,因为测试更容易编写,你可能会编写更多测试,从而产生更高质量的代码。
Tips16. 代码质量受到测试质量的限制

如果你无法编写高质量的测试,你就不会编写足够的测试,并且最终也不会得到高质量的代码。
现在,我想向你展示我曾经做过的一些最高质量的测试,即go命令的测试。这些汇集了我们迄今为止看到的许多想法。

这是一个简单但真实的go命令测试。这是一个txtar输入,带有单个文件hello.go。存档注释是用简单的一次一行命令语言编写的脚本。
在脚本中,env设置一个环境变量来关闭Go Modules。#号引入了注释。go运行go命令,该命令又应该运行helo world。该程序应该将hello world打印到标准错误。stderr命令检查上一个命令打印的标准错误是否与正则表达式匹配。因此,此测试运行go run hello.go并检查它是否将hello world打印到标准错误。
这是另一个真实的测试。

请注意底部的a.go是一个无效程序,因为它正在导入一个空字符串。感叹号在第一行开头是一个NOT运算符。! go list a.go 意味着go list a.go应该失败。
下一行,! stdout . ,表示标准输出上不应该有正则表达式的匹配,这意味着根本不应该打印任何文本。
接下来,标准错误应该包含无效的导入路径消息。
最后,不应该发生panic。
Tips17. 脚本可以进行良好的测试

这些脚本使添加新测试用例变得非常容易。
这是我们最小的测试:两行。
最近在我破坏了为未知命令打印的错误消息后,我添加了这个(测试用例)

我们总共有超过700多个这样的脚本测试,(长度)从2行到500多行不等。

这些测试脚本取代了更传统的测试脚手架(scaffold)。这张幻灯片显示了它所取代的脚本翻译背后的真实测试之一(This slide shows one of the real tests it replaced, behind the script translation).
细节并不重要,只需注意脚本写起来更加简单易懂。
Tips18:尝试使用 rsc.io/script 来获取你自己的基于脚本的测试用例

自从我们创建go脚本测试以来已经大约五年了(It has been about five years since we created the go script tests),我们对特定的脚本引擎感到非常满意。
Bryan Mills[3] 花费了大量时间为其开发了一个出色的 API。我在 11 月初将其发布在 rsc.io/script[4] 上,以供导入。
现在我说“尝试”,是因为这个项目还相对较新,讽刺的是它自身的测试还不够充分,毕竟作为一个可导入的包,它的历史只有几周。尽管如此,你仍然可能会发现它非常有用。
随着我们积累更多的经验,我们可能会把它移到一个更正式的地方。如果你尝试使用它,请与我分享你的进展。

们提取脚本引擎的动机是为了在 Go 命令测试的不同部分中重复使用它。这个脚本用于准备一个 Git 仓库,其中包含我们在常规 Go 命令脚本测试期间要导入的模块。你会看到它设置了一些环境变量,执行了实际的 git init,设置时间,并运行更多的 git 命令来将 hello world 文件添加到仓库中,然后验证我们是否得到了预期的仓库结构。这再次提醒我,测试并不是一开始就是这样的,这引出了下一个技巧。
Tips19:随着时间的推移改进你的测试

最初,我们并没有这些存储库脚本。我们手动创建了小型测试仓库,并将它们托管在 GitHub、Bitbucket 以及其他依赖于我们所需版本控制系统的服务器上。这种方法虽然可行,但如果任何服务器出现故障,测试就会失败。
最终,我们投入时间构建了自己的云服务器,可以为每个版本控制系统提供仓库。现在,我们手动创建仓库,将它们打包,然后复制到服务器上。
这种方法更好,因为现在只依赖于一台服务器来完成我们的测试,但有时也会出现网络问题。另一个问题是测试仓库本身不受版本控制,且与使用它们的测试相距甚远。
作为测试的一部分,基于脚本的版本完全在本地构建并提供这些存储库,现在可以轻松地查找、更改和审视存储库描述。这是一个庞大的基础设施,但它也测试了大量的代码。如果你的代码只有 10 行,你可能不需要数千行的测试框架。但是,如果你有十万行代码(就像 Go 命令一样),那么几千行甚至一万行的测试代码会使测试变得更加有效,这几乎可以肯定是一个值得的投资。
Tips20:以持续部署为目标

可能出于(公司)政策原因,你不能在每次通过所有测试的提交上真正部署代码,但无论如何都应以此为目标。正如我在演讲开始时提到的,对持续部署的任何疑虑都是有用的小提醒,告诉你哪些部分需要更好的测试。更好测试的关键,当然是使添加新测试变得容易。即使你从未真正 实现/启用 持续部署,以此为目标也可以帮助你保持诚实,提高测试和代码的质量。
我之前提到过,Go 网站使用持续部署。在每次提交时,我们都会运行测试,以决定最新版本的代码是否可以部署,并将流量路由到新版本。你可能不会对我们为这些测试编写了测试脚本语言感到惊讶。
下面是它们的样子:每个测试都从一个 HTTP 请求开始。这里我们获取了 go.dev 的主页面。然后是关于响应的断言。每个断言的格式都是字段、运算符、值。这里,字段是 body,运算符是 contains,值是 body 必须包含的文字文本。这个测试在检查页面是否渲染,因此它检查了基本文本和副标题。为了使编写测试变得更容易,根本没有引用:值只是运算符后面的行的其余部分。

这里还有一个测试用例。由于历史原因,/about 需要重定向到 pkg.go.dev。还有另一个测试,没有什么特别的,只是检查case研究页面是否渲染,因为它是由许多其他文件合成的。
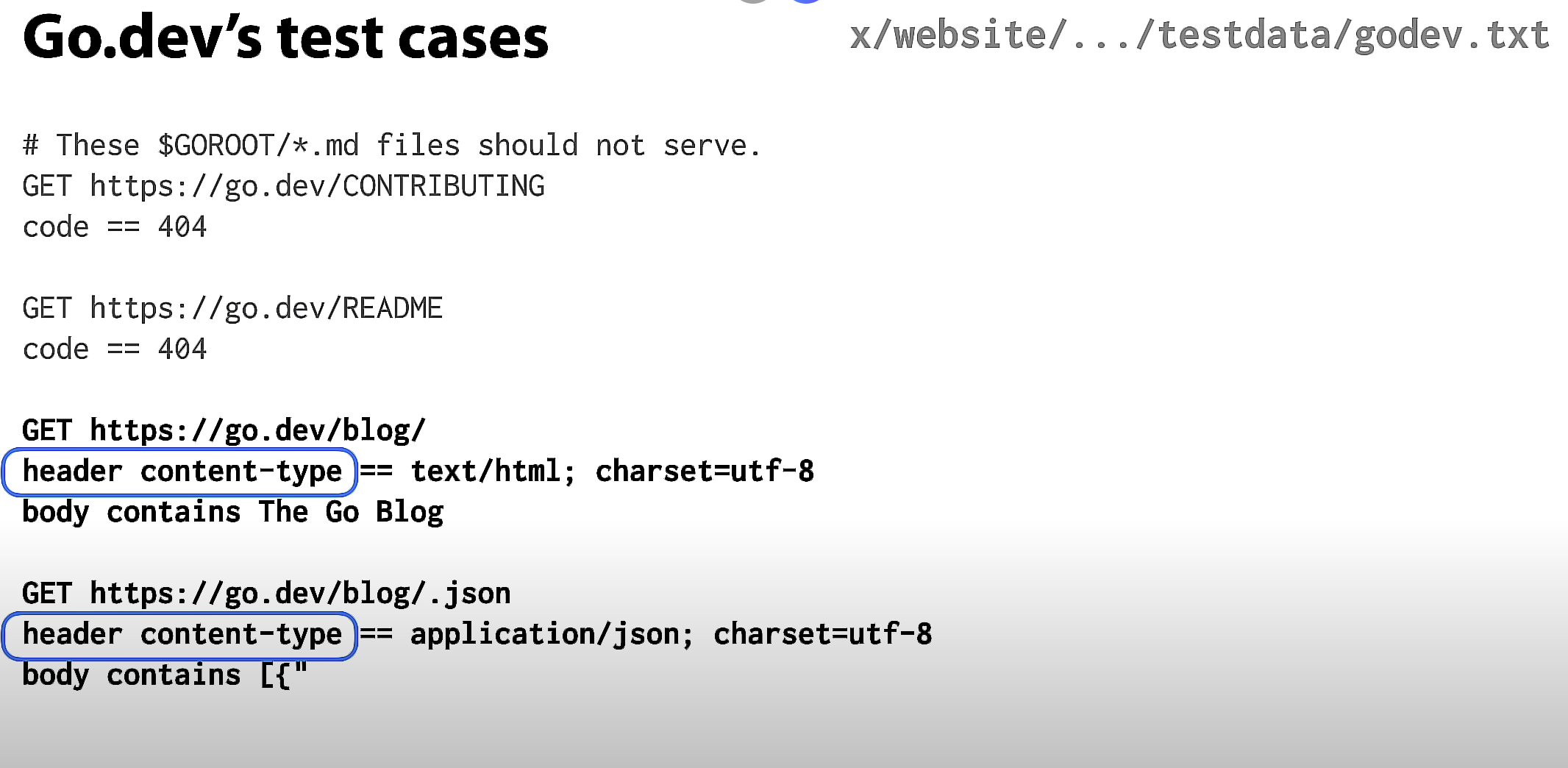
另一个可以检查的字段是 HTTP 响应代码,这里是一个错误修复。我们意外地将这些文件从 Go 仓库根目录提供,就好像它们是 Go 网站页面一样。我们希望对这些获取 404 响应。
还可以测试的另一个字段是 header foo,对于某些 foo。在这种情况下,需要为博客主页及其 JSON Feed 正确设置 header Content-Type。

(上图)这是另一个例子,这个使用正则表达式匹配运算符波形符和 \s+语法来确保页面有正确的文本,无论单词之间有多少空格。这变得有点过时了,所以我们添加了一个名为 trimbody 的新字段,即所有空格都替换为单个空格的 body。此示例还表明,值可以作为多个缩进行提供,以使多行匹配更容易。

我们还有一些无法在本地运行的测试(上图),但在将实时流量迁移到服务器之前,仍然值得在生产中运行。这里有两个例子。这些依赖于对生产playground后端的网络访问。这些用例除了 URL 之外都是相同的。
这并不是一个非常易读的测试,因为这些是我们唯一的 POST 测试。如果我们增加了更多这样的测试,我可能会花时间让它们变得更好一点,本着随着时间的推移改进你的测试的精神。但现在它们还好,并且它们有一个重要的用途。
最后,像往常一样,添加错误修复很容易。在 Issue 51989 中,某些对话完全无法渲染。因此,这个测试检查页面是否确实渲染,并包含一段独特的文本。 Issue 51989 永远不会再发生,至少不会在实时网站上发生。当然,其他的错误肯定还会出现,但这个错误已经一去不复返了,这就是进步。

这就是我能展示的所有示例,但最后还有一个想法。我相信你一定有过这样的经历:在追查一个错误时,最终发现了一段重要的代码是错误的。但不知何故,这个错误大多数时候似乎并不重要,或者被其他错误的代码片段抵消了。你可能会想:“这段代码是怎么运作的?”

如果你是代码的作者,你可能会觉得自己很幸运。如果是别人写的代码,你可能会对他们评价不高,然后也认为他们很幸运。但大多数时候,答案并不是运气。这段代码能够工作的原因几乎总是因为它有一个测试。当然,代码是错误的,但测试检查了它是否足够正确,使系统的其他部分能够正常工作,这才是重要的。

也许编写代码的人实际上是一个糟糕的程序员,但他是一个优秀的软件工程师,因为他编写了一个测试,这就是包含该代码的整个系统能够(正常)工作的原因。
我希望你从这次演讲中学到的不仅是任何给定测试的具体细节, 尽管我确实希望你能留意 小型**parsers(解析器)**和 **printers(打印机)**的良好用途。任何人都可以学会如何编写这些,有效使用它们可以成为软件工程的超能力。

最终,这些是对这些包的好的测试, 对你的包进项好的测试 可能看起来会有所不同,这也没关系。但要轻松添加新的测试用例,并确保你有良好,清晰,高质量的测试。
请记住,代码质量受到测试质量的限制,随着时间的推移,要逐步改进你的测试。你在一个项目上工作的时间越长,你的测试就应该变得越好,并以持续部署为目标,至少作为一种思维实验,来了解哪些部分还没有被充分测试。
总的来说,在编写良好的测试代码时要投入与编写良好的非测试代码一样多的思考,关注和精力,这绝对是值得的。
参考资料
这个演讲: https://research.swtch.com/testing
[2]go.dev: https://go.dev
[3]Bryan Mills: https://github.com/bcmills
[4]rsc.io/script: https://pkg.go.dev/rsc.io/script
本文由 mdnice 多平台发布