参考了两篇文章
K-Means及K-Means++算法Python源码实现-CSDN博客
使用K-means算法进行聚类分析_kmeans聚类分析结果怎么看-CSDN博客
# 定义kmeans类
from copy import deepcopy
from sklearn.datasets import make_blobs
import numpy as np
import matplotlib.pyplot as plt
class kMeans():
def __init__(self, input_data, k=3, max_epnoch=100):
"""
:param input_data: 一个numpy数组 为样本特征数值型数据集
:param k: 分成几组,整数
:max_epnoch: 最大迭代次数
"""
self.data = input_data
self.k = k
self.max_epnoch = max_epnoch
self.capacity = len(input_data)
self.centers = [] # 用于保存族的质心
self.clusters = np.zeros(self.capacity) # 用于保存数据所属的族
def get_init_clustcen(self):
# 随机初始化聚类中心
# k值合理性检验
if self.k < 1 or self.k > self.capacity:
raise Exception('k值输入错误')
# 打乱样本 取前k个
indexs = np.arange(self.capacity)
np.random.shuffle(indexs)
# indexs[:self.k] 取前k个index
# 这样就随机取k个样本作为组质心
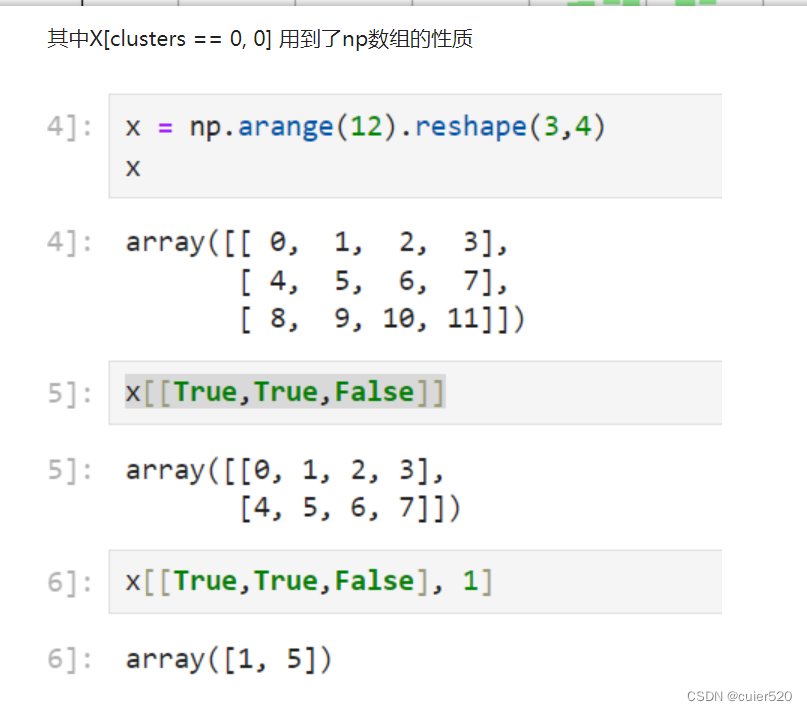
self.centers = self.data[indexs[:self.k],:] # data[nums,:]注意这种切片方式必须要data是np数组才可以
return
def get_distance(self, data1, data2):
# 计算同列的数据的欧式距离 diff相减时用到了广播机制
diff = data1 - data2
return np.sum(np.power(diff, 2), axis= 1)**0.5 # 按列进行求和
# np.argmax得到np数组中最小值的索引
def cluster_pross(self):
# 用来保存聚类中心的旧值,一开始初始化为0
old_center = np.zeros(self.centers.shape)
# 迭代标识符,记录新旧聚类中心的距离
distance_flag = self.get_distance(old_center, self.centers)
# 若聚类中心不再变化或者达到迭代次数 则退出 否则才执行循环
while np.sum(distance_flag) != 0 and self.max_epnoch:
# 1. 计算每个样本点所属的族
for i in range(self.capacity):
# 样本与各族的距离(样本与各族的列是相同的 因此可调用前面准备的函数)
distance_i = self.get_distance(self.data[i], self.centers)
# 获得当前样本点与族最近的那个族的索引
cluster_i = np.argmin(distance_i)
# 记录当前样本点所属的聚类中心
self.clusters[i] = cluster_i
# 2. 更新聚类中心
# 记录之前的聚类中心
old_center = deepcopy(self.centers)
# 按照族来计算,将属于同一组的样本堆叠在一起 计算均值作为聚类中心
for i in range(self.k):
tmp = [self.data[j] for j in range(self.capacity) if self.clusters[j] == i]
# 按列计算均值,并将其存储在新的聚类中心中
self.centers[i] = np.mean(tmp, axis= 0)
# 3. 更新迭代条件的值
self.max_epnoch -= 1
distance_flag = self.get_distance(old_center, self.centers)
return self.centers, self.clusters# 实例化并作图前后对比
# 获取数据集 并用图像呈现
X, _ = make_blobs(n_samples=150, n_features=2, centers=3, cluster_std=0.5, random_state=0)
plt.scatter(X[:,0], X[:,1], c='r', marker='o') # 将white改为其他的颜色
plt.grid()
plt.show()
# 实例化一个聚类对象
kmeans_X = kMeans(X)
# 随机初始化聚类中心
kmeans_X.get_init_clustcen()
# 进行聚类 并接结果 为了作图 返回的是聚类中心数据 和 对应样本i的所属聚类
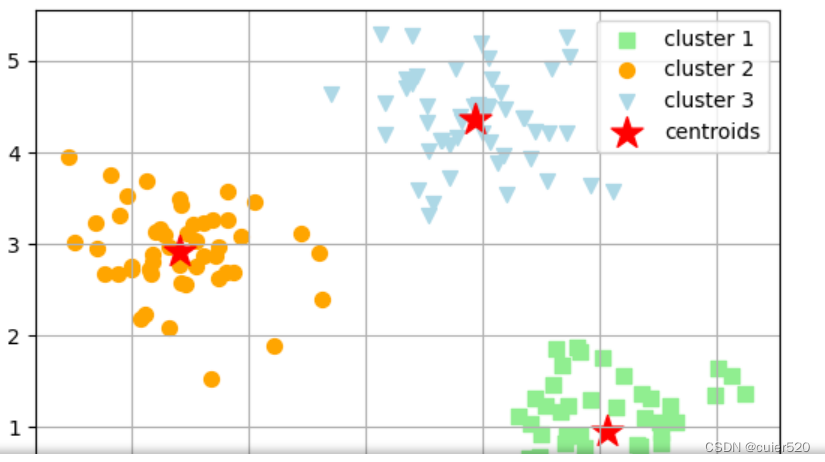
centers, clusters = kmeans_X.cluster_pross() # 其中 centers(k,n_features) cluters(n_samples, 1)
# 可视化聚类结果
plt.scatter(X[clusters == 0, 0], X[clusters == 0, 1], s=50, c='lightgreen', marker='s', label='cluster 1')
plt.scatter(X[clusters == 1, 0], X[clusters == 1, 1], s=50, c='orange', marker='o', label='cluster 2')
plt.scatter(X[clusters == 2, 0], X[clusters == 2, 1], s=50, c='lightblue', marker='v', label='cluster 3')
plt.scatter(centers[:,0], centers[:,1], s=250, c='red', marker='*', label='centroids')
plt.legend()
plt.grid()
plt.show()