- 🍨 本文为🔗365天深度学习训练营 中的学习记录博客
- 🍖 原作者:K同学啊 | 接辅导、项目定制
文章目录
- 前言
- 一、我的环境
- 二、代码实现与执行结果
- 1.引入库
- 2.设置GPU(如果使用的是CPU可以忽略这步)
- 3.导入数据
- 4.查看数据
- 5.加载数据
- 6.再次检查数据
- 7.配置数据集
- 8.可视化数据
- 9.构建CNN网络模型
- 10.编译模型
- 11.训练模型
- 12.模型评估
- 三、知识点详解
- 1.加载预训练的 VGG16 模型
- 2 优化器
- 2.1 梯度下降法 (Gradient Descent)
- 2.1.1 批量梯度下降法 (Batch Gradient Descent, BGD)
- 2.1.2随机梯度下降(Stochastic Gradient Descent, SGD)
- 2.2 动量优化法(Momentum)
- 2.3 自适应学习率优化算法
- 2.2.1 AdaGrad(Adaptive Gradient)
- 2.2.2 Adadelta
- 2.2.3 RMSprop
- 2.2.4 Adam(Adaptive Moment Estimation)
- 总结
前言
本文将采用CNN实现好莱坞明星识别,并用两种不同的优化器用于训练,并进行对比。简单讲述实现代码与执行结果,并浅谈涉及知识点。
关键字:加载预训练的 VGG16 模型,优化器。
一、我的环境
- 电脑系统:Windows 11
- 语言环境:python 3.8.6
- 编译器:pycharm2020.2.3
- 深度学习环境:TensorFlow 2.10.1
- 显卡:NVIDIA GeForce RTX 4070
二、代码实现与执行结果
1.引入库
from PIL import Image
import numpy as np
from pathlib import Path
import tensorflow as tf
from tensorflow.keras.layers import Dropout, Dense, BatchNormalization
from tensorflow.keras.models import Model
import matplotlib.pyplot as plt
# 支持中文
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号
import warnings
warnings.filterwarnings('ignore') # 忽略一些warning内容,无需打印
2.设置GPU(如果使用的是CPU可以忽略这步)
'''前期工作-设置GPU(如果使用的是CPU可以忽略这步)'''
# 检查GPU是否可用
print(tf.test.is_built_with_cuda())
gpus = tf.config.list_physical_devices("GPU")
print(gpus)
if gpus:
gpu0 = gpus[0] # 如果有多个GPU,仅使用第0个GPU
tf.config.experimental.set_memory_growth(gpu0, True) # 设置GPU显存用量按需使用
tf.config.set_visible_devices([gpu0], "GPU")
执行结果
True
[PhysicalDevice(name='/physical_device:GPU:0', device_type='GPU')]
3.导入数据
[好莱坞明星数据](https://pan.baidu.com/share/init?surl=C6-9ke_2fPlS2yK_TrNdpQ&pwd=czli)
'''前期工作-导入数据'''
data_dir = r"D:\DeepLearning\data\HollywoodStars"
data_dir = Path(data_dir)
4.查看数据
'''前期工作-查看数据'''
image_count = len(list(data_dir.glob('*/*.jpg')))
print("图片总数为:", image_count)
roses = list(data_dir.glob('Jennifer Lawrence/*.jpg'))
image = Image.open(str(roses[1]))
# 查看图像实例的属性
print(image.format, image.size, image.mode)
plt.imshow(image)
plt.show()
执行结果:
图片总数为: 1800
JPEG (474, 569) RGB

5.加载数据
'''数据预处理-加载数据'''
batch_size = 16
img_height = 336
img_width = 336
"""
关于image_dataset_from_directory()的详细介绍可以参考文章:https://mtyjkh.blog.csdn.net/article/details/117018789
"""
train_ds = tf.keras.preprocessing.image_dataset_from_directory(
data_dir,
validation_split=0.2,
subset="training",
seed=12,
image_size=(img_height, img_width),
batch_size=batch_size)
val_ds = tf.keras.preprocessing.image_dataset_from_directory(
data_dir,
validation_split=0.2,
subset="validation",
seed=12,
image_size=(img_height, img_width),
batch_size=batch_size)
class_names = train_ds.class_names
print(class_names)
运行结果:
Found 1800 files belonging to 17 classes.
Using 1440 files for training.
Found 1800 files belonging to 17 classes.
Using 360 files for validation.
['Angelina Jolie', 'Brad Pitt', 'Denzel Washington', 'Hugh Jackman', 'Jennifer Lawrence', 'Johnny Depp', 'Kate Winslet', 'Leonardo DiCaprio', 'Megan Fox', 'Natalie Portman', 'Nicole Kidman', 'Robert Downey Jr', 'Sandra Bullock', 'Scarlett Johansson', 'Tom Cruise', 'Tom Hanks', 'Will Smith']
6.再次检查数据
'''数据预处理-再次检查数据'''
# Image_batch是形状的张量(16, 336, 336, 3)。这是一批形状336x336x3的16张图片(最后一维指的是彩色通道RGB)。
# Label_batch是形状(16,)的张量,这些标签对应16张图片
for image_batch, labels_batch in train_ds:
print(image_batch.shape)
print(labels_batch.shape)
break
运行结果
(16, 336, 336, 3)
(16,)
7.配置数据集
'''数据预处理-配置数据集'''
AUTOTUNE = tf.data.AUTOTUNE
def train_preprocessing(image, label):
return (image / 255.0, label)
train_ds = (
train_ds.cache()
.shuffle(1000)
.map(train_preprocessing) # 这里可以设置预处理函数
# .batch(batch_size) # 在image_dataset_from_directory处已经设置了batch_size
.prefetch(buffer_size=AUTOTUNE)
)
val_ds = (
val_ds.cache()
.shuffle(1000)
.map(train_preprocessing) # 这里可以设置预处理函数
# .batch(batch_size) # 在image_dataset_from_directory处已经设置了batch_size
.prefetch(buffer_size=AUTOTUNE)
)
8.可视化数据
'''数据预处理-可视化数据'''
plt.figure(figsize=(10, 8)) # 图形的宽为10高为5
plt.suptitle("数据展示", fontsize=20)
for images, labels in train_ds.take(1):
for i in range(15):
plt.subplot(3, 5, i + 1)
plt.xticks([])
plt.yticks([])
plt.grid(False)
# 显示图片
plt.imshow(images[i])
# 显示标签
plt.xlabel(class_names[np.argmax(labels[i])],fontdict={'family' : 'Times New Roman', 'size':20})
plt.show()

9.构建CNN网络模型
'''构建CNN网络'''
def create_model(optimizer='adam'):
# 加载预训练模型
vgg16_base_model = tf.keras.applications.vgg16.VGG16(weights='imagenet',
include_top=False,
input_shape=(img_width, img_height, 3),
pooling='avg')
for layer in vgg16_base_model.layers:
layer.trainable = False
X = vgg16_base_model.output
X = Dense(170, activation='relu')(X)
X = BatchNormalization()(X)
X = Dropout(0.5)(X)
output = Dense(len(class_names), activation='softmax')(X)
vgg16_model = Model(inputs=vgg16_base_model.input, outputs=output)
vgg16_model.compile(optimizer=optimizer,
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
return vgg16_model
model1 = create_model(optimizer=tf.keras.optimizers.Adam())
model2 = create_model(optimizer=tf.keras.optimizers.SGD())
model2.summary()
网络结构结果如下:
Model: "model_1"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
input_2 (InputLayer) [(None, 336, 336, 3)] 0
block1_conv1 (Conv2D) (None, 336, 336, 64) 1792
block1_conv2 (Conv2D) (None, 336, 336, 64) 36928
block1_pool (MaxPooling2D) (None, 168, 168, 64) 0
block2_conv1 (Conv2D) (None, 168, 168, 128) 73856
block2_conv2 (Conv2D) (None, 168, 168, 128) 147584
block2_pool (MaxPooling2D) (None, 84, 84, 128) 0
block3_conv1 (Conv2D) (None, 84, 84, 256) 295168
block3_conv2 (Conv2D) (None, 84, 84, 256) 590080
block3_conv3 (Conv2D) (None, 84, 84, 256) 590080
block3_pool (MaxPooling2D) (None, 42, 42, 256) 0
block4_conv1 (Conv2D) (None, 42, 42, 512) 1180160
block4_conv2 (Conv2D) (None, 42, 42, 512) 2359808
block4_conv3 (Conv2D) (None, 42, 42, 512) 2359808
block4_pool (MaxPooling2D) (None, 21, 21, 512) 0
block5_conv1 (Conv2D) (None, 21, 21, 512) 2359808
block5_conv2 (Conv2D) (None, 21, 21, 512) 2359808
block5_conv3 (Conv2D) (None, 21, 21, 512) 2359808
block5_pool (MaxPooling2D) (None, 10, 10, 512) 0
global_average_pooling2d_1 (None, 512) 0
(GlobalAveragePooling2D)
dense_2 (Dense) (None, 170) 87210
batch_normalization_1 (Batc (None, 170) 680
hNormalization)
dropout_1 (Dropout) (None, 170) 0
dense_3 (Dense) (None, 17) 2907
=================================================================
Total params: 14,805,485
Trainable params: 90,457
Non-trainable params: 14,715,028
_________________________________________________________________
10.编译模型
# 设置初始学习率
initial_learning_rate = 1e-4
lr_schedule = tf.keras.optimizers.schedules.ExponentialDecay(
initial_learning_rate,
decay_steps=60, # 敲黑板!!!这里是指 steps,不是指epochs
decay_rate=0.96, # lr经过一次衰减就会变成 decay_rate*lr
staircase=True)
# 将指数衰减学习率送入优化器
optimizer = tf.keras.optimizers.Adam(learning_rate=lr_schedule)
model.compile(optimizer=optimizer,
loss=tf.keras.losses.CategoricalCrossentropy(from_logits=True),
metrics=['accuracy'])
11.训练模型
'''训练模型'''
NO_EPOCHS = 50
history_model1 = model1.fit(train_ds, epochs=NO_EPOCHS, verbose=1, validation_data=val_ds)
history_model2 = model2.fit(train_ds, epochs=NO_EPOCHS, verbose=1, validation_data=val_ds)
训练记录如下:
Epoch 1/50
90/90 [==============================] - 13s 99ms/step - loss: 2.7601 - accuracy: 0.1764 - val_loss: 2.7506 - val_accuracy: 0.1250
Epoch 2/50
90/90 [==============================] - 8s 86ms/step - loss: 2.0679 - accuracy: 0.3285 - val_loss: 2.4926 - val_accuracy: 0.2111
Epoch 3/50
90/90 [==============================] - 8s 86ms/step - loss: 1.7437 - accuracy: 0.4410 - val_loss: 2.2004 - val_accuracy: 0.3639
......
Epoch 49/50
90/90 [==============================] - 8s 86ms/step - loss: 0.1929 - accuracy: 0.9354 - val_loss: 2.8650 - val_accuracy: 0.4972
Epoch 50/50
90/90 [==============================] - 8s 86ms/step - loss: 0.1694 - accuracy: 0.9458 - val_loss: 2.7593 - val_accuracy: 0.4694
Epoch 1/50
90/90 [==============================] - 8s 87ms/step - loss: 3.0367 - accuracy: 0.1090 - val_loss: 2.7868 - val_accuracy: 0.1250
Epoch 2/50
90/90 [==============================] - 8s 86ms/step - loss: 2.5409 - accuracy: 0.1979 - val_loss: 2.6385 - val_accuracy: 0.1056
Epoch 3/50
90/90 [==============================] - 8s 86ms/step - loss: 2.2875 - accuracy: 0.2847 - val_loss: 2.4560 - val_accuracy: 0.2167
......
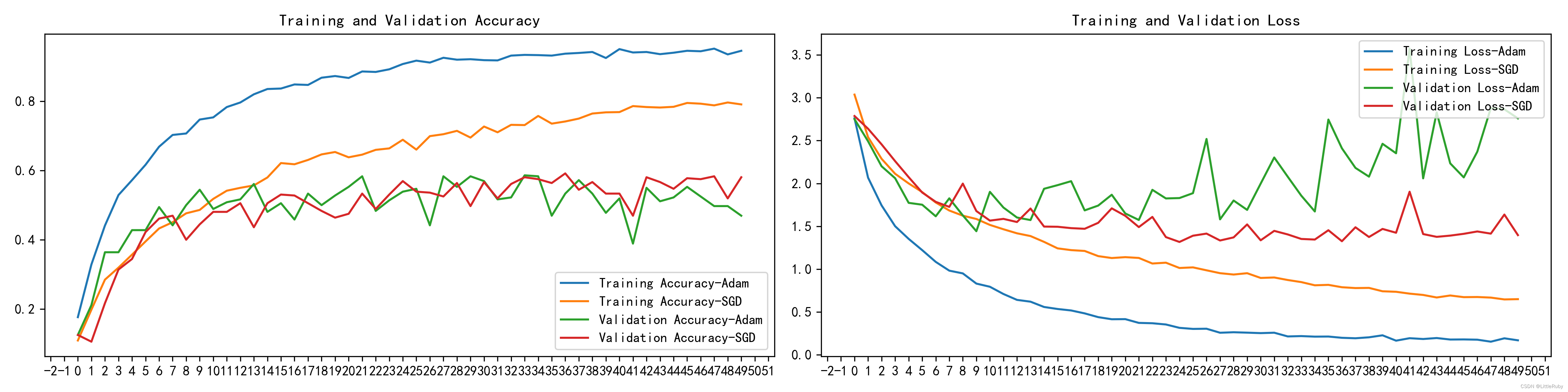
12.模型评估
'''模型评估'''
from matplotlib.ticker import MultipleLocator
plt.rcParams['savefig.dpi'] = 300 # 图片像素
plt.rcParams['figure.dpi'] = 300 # 分辨率
acc1 = history_model1.history['accuracy']
acc2 = history_model2.history['accuracy']
val_acc1 = history_model1.history['val_accuracy']
val_acc2 = history_model2.history['val_accuracy']
loss1 = history_model1.history['loss']
loss2 = history_model2.history['loss']
val_loss1 = history_model1.history['val_loss']
val_loss2 = history_model2.history['val_loss']
epochs_range = range(len(acc1))
plt.figure(figsize=(16, 4))
plt.subplot(1, 2, 1)
plt.plot(epochs_range, acc1, label='Training Accuracy-Adam')
plt.plot(epochs_range, acc2, label='Training Accuracy-SGD')
plt.plot(epochs_range, val_acc1, label='Validation Accuracy-Adam')
plt.plot(epochs_range, val_acc2, label='Validation Accuracy-SGD')
plt.legend(loc='lower right')
plt.title('Training and Validation Accuracy')
# 设置刻度间隔,x轴每1一个刻度
ax = plt.gca()
ax.xaxis.set_major_locator(MultipleLocator(1))
plt.subplot(1, 2, 2)
plt.plot(epochs_range, loss1, label='Training Loss-Adam')
plt.plot(epochs_range, loss2, label='Training Loss-SGD')
plt.plot(epochs_range, val_loss1, label='Validation Loss-Adam')
plt.plot(epochs_range, val_loss2, label='Validation Loss-SGD')
plt.legend(loc='upper right')
plt.title('Training and Validation Loss')
# 设置刻度间隔,x轴每1一个刻度
ax = plt.gca()
ax.xaxis.set_major_locator(MultipleLocator(1))
plt.show()
def test_accuracy_report(model):
score = model.evaluate(val_ds, verbose=0)
print('Loss function: %s, accuracy:' % score[0], score[1])
test_accuracy_report(model1)
test_accuracy_report(model2)
Loss function: 2.759303092956543, accuracy: 0.4694444537162781
Loss function: 1.3968818187713623, accuracy: 0.5805555582046509
三、知识点详解
1.加载预训练的 VGG16 模型
def create_model(optimizer='adam'):
# 加载预训练模型
vgg16_base_model = tf.keras.applications.vgg16.VGG16(weights='imagenet',
include_top=False,
input_shape=(img_width, img_height, 3),
pooling='avg')
for layer in vgg16_base_model.layers:
layer.trainable = False
X = vgg16_base_model.output
X = Dense(170, activation='relu')(X)
X = BatchNormalization()(X)
X = Dropout(0.5)(X)
output = Dense(len(class_names), activation='softmax')(X)
vgg16_model = Model(inputs=vgg16_base_model.input, outputs=output)
vgg16_model.compile(optimizer=optimizer,
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
return vgg16_model
model1 = create_model(optimizer=tf.keras.optimizers.Adam())
model2 = create_model(optimizer=tf.keras.optimizers.SGD())
model2.summary()
定义了一个名为 create_model 的函数,该函数接受一个参数 optimizer(默认为 ‘adam’)。函数内部首先使用 tf.keras.applications.vgg16.VGG16 加载了预训练的 VGG16 模型,其中 weights = ‘imagenet’ 表示使用 ImageNet 数据集的预训练权重,include_top = False 表示不包含顶层的全连接层,input_shape 设置输入图像的形状,pooling = ‘avg’ 表示使用平均池化。
然后,对 VGG16 模型的所有层进行循环遍历,将每一层的 trainable 属性设置为 False,即冻结预训练参数,使它们在训练过程中保持不变。
接下来,将 VGG16 模型的输出作为输入,并经过一系列的神经网络层进行特征提取和分类。首先是全连接层 Dense(170, activation = ‘relu’),然后是批归一化层 BatchNormalization(),最后是丢弃层 Dropout(0.5),用于防止过拟合。
最后一层是输出层 Dense(len(class_names), activation = ‘softmax’),其中 len(class_names) 是类别的数量,根据具体情况进行设置,激活函数使用 softmax。
接下来,使用 Model 函数创建了一个新的模型 vgg16_model,指定了输入和输出。这里的 vgg16_base_model.input 表示 VGG16 模型的输入,output 表示上述神经网络层的输出。
然后,使用 compile 方法编译了模型,指定了优化器、损失函数和评估指标。优化器根据传入的参数进行选择,如果没有指定,默认为 Adam 优化器。损失函数使用稀疏分类交叉熵,评估指标为准确率。
最后,函数返回创建的模型。
接下来,通过调用 create_model 函数分别创建了两个模型 model1 和 model2,分别使用了 Adam 优化器和 SGD 优化器。最后调用 model2.summary() 打印了 model2 的模型摘要信息。
参考链接:深度学习-第T11周——优化器对比实验
2 优化器
优化器是一种算法,它在模型优化过程中,动态地调整梯度的大小和方向,使模型能够收敛到更好的位置,或者用更快的速度进行收敛。
2.1 梯度下降法 (Gradient Descent)
我们可以把模型的参数空间想象成是一个曲面,曲面的高度是整体上模型预测值与真实值的误差。我们的目的就是找到整个曲面的最低点,这样我们其实就找到了模型参数的最优点。梯度下降法是最基本的优化算法之一,它让参数朝着梯度下降最大的方向去变化。
假设模型参数为
θ
\theta
θ,损失函数为
J
(
θ
)
J(\theta)
J(θ) ,损失函数
J
(
θ
)
J(\theta)
J(θ) 关于参数
θ
\theta
θ 的偏导数,也就是梯度为
∇
t
J
(
θ
)
\nabla_tJ(\theta)
∇tJ(θ) ,学习率为
α
\alpha
α ,则使用梯度下降法更新参数的公式为:
θ
t
+
1
=
θ
t
−
α
⋅
∇
t
J
(
θ
)
\theta_{t+1}=\theta_t-\alpha\cdot\nabla_tJ(\theta)
θt+1=θt−α⋅∇tJ(θ)
梯度下降算法中,沿着梯度的方向不断减小模型参数,从而最小化损失函数。基本策略可以理解为”在你目光所及的范围内,不断寻找最陡最快的路径下山“

算法缺点:
- 训练速度慢:每走一步都要计算调整下一步的方向,下山的速度变慢。在应用于大型数据集中,每输入一个样本都要更新一次参数,且每次迭代都要遍历所有的样本。会使得训练过程及其缓慢,需要花费很长时间才能得到收敛解。
- 容易陷入局部最优解:由于是在有限视距内寻找下山的方向。当陷入平坦的洼地,会误以为到达了山地的最低点,从而不会继续往下走。
真正在使用时,主要是经过改进的以下三类方法,区别在于每次参数更新时计算的样本数据量不同:
- 批量梯度下降法(BGD, Batch Gradient Descent)
- 随机梯度下降法(SGD, Stochastic Gradient Descent)
- 小批量梯度下降法(Mini-batch Gradient Descent)
2.1.1 批量梯度下降法 (Batch Gradient Descent, BGD)
第一种很天然的想法是批量梯度下降法BGD(Batch Gradient Descent),其实就是每次用全量的数据对参数进行梯度下降。
假设训练样本总数为n,样本为 {(x1,y1), … (xn, yn)} ,模型参数为
θ
\theta
θ,损失函数为
J
(
θ
)
J(\theta)
J(θ) ,损失函数
J
(
θ
)
J(\theta)
J(θ) 关于参数
θ
\theta
θ 的偏导数,也就是梯度为
∇
t
J
(
θ
)
\nabla_tJ(\theta)
∇tJ(θ) ,学习率为
α
\alpha
α ,则使用BGD更新参数为:
θ
t
+
1
=
θ
t
−
α
t
⋅
∑
i
=
1
n
∇
t
J
i
(
θ
,
x
i
,
y
i
)
\theta_{t+1}=\theta_t-\alpha_t\cdot\sum_{i=1}^n\nabla_tJ_i(\theta,x^i,y^i)
θt+1=θt−αt⋅i=1∑n∇tJi(θ,xi,yi)
由上式可以看出,每进行一次参数更新,需要计算整个数据样本集,因此导致批量梯度下降法的速度会比较慢,尤其是数据集非常大的情况下,收敛速度就会非常慢,但是由于每次的下降方向为总体平均梯度,它可能得到的会是一个全局最优解。
2.1.2随机梯度下降(Stochastic Gradient Descent, SGD)
随机梯度下降法,不像BGD每一次参数更新,需要计算整个数据样本集的梯度,而是每次参数更新时,仅仅选取一个样本(xi, yi)计算其梯度,参数更新公式为
θ
t
+
1
=
θ
t
−
α
⋅
∇
t
J
i
(
θ
,
x
i
,
y
i
)
\theta_{t+1}=\theta_t-\alpha\cdot\nabla_tJ_i(\theta,x^i,y^i)
θt+1=θt−α⋅∇tJi(θ,xi,yi)
SGD训练速度很快,即使在样本量很大的情况下,可能只需要其中一部分样本就能迭代到最优解,由于每次迭代并不是都向着整体最优化方向,导致梯度下降的波动非常大(如下图),更容易从一个局部最优跳到另一个局部最优,准确度下降。

优点:
- 由于每次迭代只使用了一个样本计算梯度,训练速度快,包含一定随机性,但是从期望来看,每次计算的梯度基本是正确的导数的。虽然看起来SGD波动非常大,会走很多弯路,但是对梯度的要求很低(计算梯度快),而且对于引入噪声,大量的理论和实践工作证明,只要噪声不是特别大,SGD都能很好地收敛。
- 应用大型数据集时,训练速度很快。比如每次从百万数据样本中,取几百个数据点,算一个SGD梯度,更新一下模型参数。相比于标准梯度下降法的遍历全部样本,每输入一个样本更新一次参数,要快得多
缺点:- 更新频繁,带有随机性,会造成损失函数在收敛过程中严重震荡。SGD没能单独克服局部最优解的问题(主要)
- SGD在随机选择梯度的同时会引入噪声,使得权值更新的方向不一定正确(次要)
2.2 动量优化法(Momentum)
关于动量
动量优化法引入了物理之中的概念。动量 p=mvp=mvp=mv,当一个小球从山顶滚下,速度越来越快,动量越来越大,开始加速梯度下降,当跨越了山谷,滚到对面的坡上时,速度减小,动量减小。
带动量的小球不仅可以加速梯度;还可以借着积累的动量,冲过小的山坡,以避免落入局部最优点。
动量优化法(Momentum)提出的原因
梯度下降法容易被困在局部最小的沟壑处来回震荡,可能存在曲面的另一个方向有更小的值;有时候梯度下降法收敛速度还是很慢。动量法就是为了解决这两个问题提出的
动量优化法思想
参数更新时在一定程度上保留之前更新的方向,同时又利用当前batch的梯度微调最终的更新方向,简言之就是通过积累之前的动量来 (previous_sum_of_gradient) 加速当前的梯度。
优缺点分析
- 优点:前后梯度一致的时候能够加速学习;前后梯度不一致的时候能够抑制震荡,越过局部极小值(加速收敛,减小震荡)
- 缺点:多了一个超参数,增加了计算量
2.3 自适应学习率优化算法
传统的优化算法要么将学习率设置为常数要么根据训练次数调节学习率。往往忽视了学习率其他变化的可能性。学习率对模型的性能有着显著的影响,需要采取一些策略来更新学习率,进而提高训练速度与准确率。
使用统一的全局学习率的缺点可能出现的问题
- 对于某些参数,通过算法已经优化到了极小值附近,但是有的参数仍然有着很大的梯度。
- 如果学习率太小,则梯度很大的参数会有一个很慢的收敛速度; 如果学习率太大,则已经优化得差不多的参数可能会出现不稳定的情况。
解决方案:对每个参与训练的参数设置不同的学习率,在整个学习过程中通过一些算法自动适应这些参数的学习率。
如果损失与某一指定参数的偏导的符号相同,那么学习率应该增加; 如果损失与该参数的偏导的符号不同,那么学习率应该减小。
2.2.1 AdaGrad(Adaptive Gradient)
Adagrad其实是对学习率进行了一个约束,对于经常更新的参数,我们已经积累了大量关于它的知识,不希望被单个样本影响太大,希望学习速率慢一些;对于偶尔更新的参数,我们了解的信息太少,希望能从每个偶然出现的样本(稀疏特征的样本)身上多学一些,即学习速率大一些。该方法中开始使用的二阶动量,意味着“自适应学习率”优化算法时代的到来。
AdaGrad 算法,独立地适应所有模型参数的学习率,缩放每个参数反比于其所有梯度历史平均值总和的平方根。(知道这么回事就好,基本不用它~)
● 具有损失函数最大梯度的参数相应地有个快速下降的学习率 ● 而具有小梯度的参数在学习率上有相对较小的下降。优点:自适应的学习率,无需人工调节
缺点:
- 仍需要手工设置一个全局学习率 η, 如果 η 设置过大的话,会使 regularizer 过于敏感,对梯度的调节太大
- 中后期,分母上梯度累加的平方和会越来越大,使得参数更新量趋近于0,使得训练提前结束,无法学习
2.2.2 Adadelta
由于AdaGrad调整学习率变化过于激进,我们考虑一个改变二阶动量计算方法的策略:不累积全部历史梯度,而只关注过去一段时间窗口的下降梯度,即Adadelta只累加固定大小的项,并且也不直接存储这些项,仅仅是近似计算对应的平均值(指数移动平均值),这就避免了二阶动量持续累积、导致训练过程提前结束的问题了。
优点:
- 不依赖全局learning rate
- 训练初中期,加速效果不错,很快
缺点: 训练后期,反复在局部最小值附近抖动
2.2.3 RMSprop
RMSprop 和 Adadelta 都是为了解决 AdaGrad 学习率急剧下降问题的,但是RMSProp算法修改了AdaGrad的梯度平方和累加为指数加权的移动平均。
指数加权平均,旨在消除梯度下降中的摆动,与Momentum的效果一样,某一维度的导数比较大,则指数加权平均就大,某一维度的导数比较小,则其指数加权平均就小,这样就保证了各维度导数都在一个量级,进而减少了摆动。
另外,指数衰减平均的方式可以淡化遥远过去的历史对当前步骤参数更新量的影响,衰减率表明的是只是最近的梯度平方有意义,而很久以前的梯度基本上会被遗忘
优点:
- RMSprop算是Adagrad的一种发展,和Adadelta的变体,效果趋于二者之间
- 适合处理非平稳目标(包括季节性和周期性)——对于RNN效果很好
缺点:其实RMSprop依然依赖于全局学习率 η
2.2.4 Adam(Adaptive Moment Estimation)
Adam 结合了前面方法的一阶动量和二阶动量,是前述方法的集大成者。
优点:
- Adam梯度经过偏置校正后,每一次迭代学习率都有一个固定范围,使得参数比较平稳。
- 结合了Adagrad善于处理稀疏梯度和RMSprop善于处理非平稳目标的优点
- 为不同的参数计算不同的自适应学习率
- 节省了训练集时间、训练成本
缺点: Adam 使用动量的滑动平均,可能会随着训练数据变化而抖动比较剧烈,在online场景可能波动较大,在广告场景往往效果不如 AdaGrad
Adam那么棒,为什么还对SGD念念不忘
举个栗子。很多年以前,摄影离普罗大众非常遥远。十年前,傻瓜相机开始风靡,游客几乎人手一个。智能手机出现以后,摄影更是走进千家万户,手机随手一拍,前后两千万,照亮你的美(咦,这是什么乱七八糟的)。但是专业摄影师还是喜欢用单反,孜孜不倦地调光圈、快门、ISO、白平衡……一堆自拍党从不care的名词。技术的进步,使得傻瓜式操作就可以得到不错的效果,但是在特定的场景下,要拍出最好的效果,依然需要深入地理解光线、理解结构、理解器材。
更深入的内容,可以通过文末的参考文献进入了解。
1)TensorFlow2调用
函数原型:
keras.optimizers.Adam(lr=0.001, beta_1=0.9, beta_2=0.999, epsilon=None, decay=0.0, amsgrad=False)
📍官网地址:https://www.tensorflow.org/api_docs/python/tf/keras/optimizers/Adam
参数详解:
- lr: float >= 0. 学习率。
- beta_1: float, 0 < beta < 1. 通常接近于 1。
- beta_2: float, 0 < beta < 1. 通常接近于 1。
- epsilon: float >= 0. 模糊因子. 若为 None, 默认为 K.epsilon()。
- decay: float >= 0. 每次参数更新后学习率衰减值。
- amsgrad: boolean. 是否应用此算法的 AMSGrad 变种,来自论文 “On the Convergence of Adam and Beyond”。
调用示例:
# 设置优化器
opt = tf.keras.optimizers.Adam(learning_rate=0.001, decay=0.0)
model.compile(optimizer=opt,
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=['accuracy'])
参考文献
An overview of gradient descent optimization algorithms
Adam那么棒,为什么还对SGD念念不忘 (2)—— Adam的两宗罪
总结
通过本次的学习,了解了预加载模型的用法,了解了多种优化器。