KEDA以事件驱动的方式实现Kubernetes Pod的动态自动扩容机制,以满足不同的负载需求,从而提高应用可伸缩性和弹性。原文: Dynamic Scaling with Kubernetes Event-driven Autoscaling (KEDA)

Kubernetes是容器编排平台的事实标准,已经彻底改变了部署和管理应用的方式。对应用进行有效扩容的关键挑战之一是确保基础设施适应工作负载的动态需求,这就是Kubernetes pod autoscaling发挥作用的地方,可以根据预定义指标自动调整pod数量。虽然Kubernetes提供了内置的自动缩放功能,但Kubernetes事件驱动自动缩放(KEDA, Kubernetes Event-driven Autoscaling)项目提供了更强大的解决方案来增强和扩展自动缩放功能。本文将探讨Kubernetes和KEDA中内置自动缩放的区别,重点介绍KEDA的优缺点,并提供真实用例来展示其潜力。
Kubernetes内置自动缩放
Kubernetes提供了一种称为水平Pod自动缩放(HPA,Horizontal Pod Autoscaler)的本地自动缩放机制。HPA可以定义指标(例如CPU利用率或基于指标服务器的自定义指标),从而让Kubernetes根据指定阈值自动调整pod副本数量。这种内置解决方案适用于许多场景,但在事件驱动的工作负载或基于自定义指标的扩展方面存在局限性。
Kubernetes事件驱动自动缩放(KEDA,Kubernetes Event-driven Autoscaling)
KEDA(Kubernetes事件驱动自动缩放)项目,是一个开源项目,将Kubernetes的自动缩放功能扩展到更广泛的工作负载。KEDA充当事件源(如消息队列或流平台)与Kubernetes之间的桥梁,支持基于事件驱动触发器的自动扩容。利用KEDA,可以实时扩展应用pod,对传入事件做出反应并优化资源利用率。
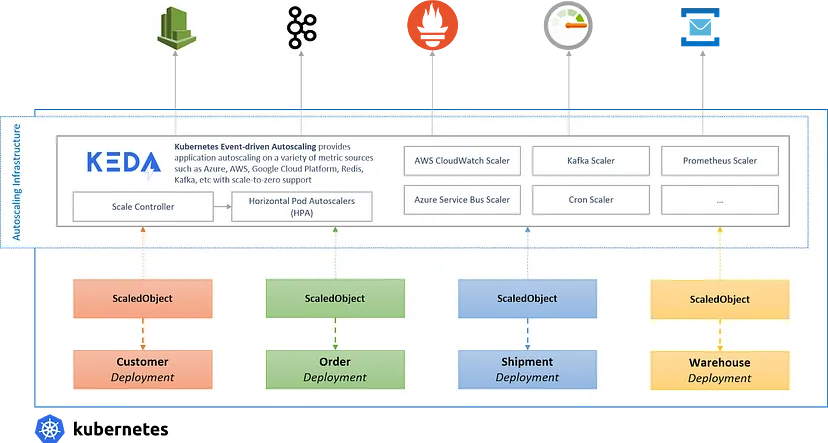
KEDA优缺点
与Kubernetes内置的自动缩放功能相比,KEDA有如下优势:
-
事件驱动扩容: KEDA支持基于各种事件源的自动扩容,可以处理突发工作负载或适应不可预测的需求峰值。 -
支持自定义指标: 与HPA不同,KEDA可以基于自定义指标进行扩容,从而在定义特定于应用需求的扩容触发器时提供更多灵活性。 -
资源效率: 当没有工作负载时,KEDA可以缩容到零副本,从而有效降低资源消耗和成本。 -
可扩展架构: KEDA与各种事件源无缝集成,并通过可插拔架构进行扩展,可以根据特定需求进行调整。
尽管有很多好处,但使用KEDA也有一些注意事项:
-
额外的复杂性: 集成和配置KEDA需要额外设置和管理开销,需要根据应用复杂性进行权衡。 -
学习曲线: KEDA引入了新的概念和工具,对于新的项目开发人员和运维人员来说,可能需要一些学习。
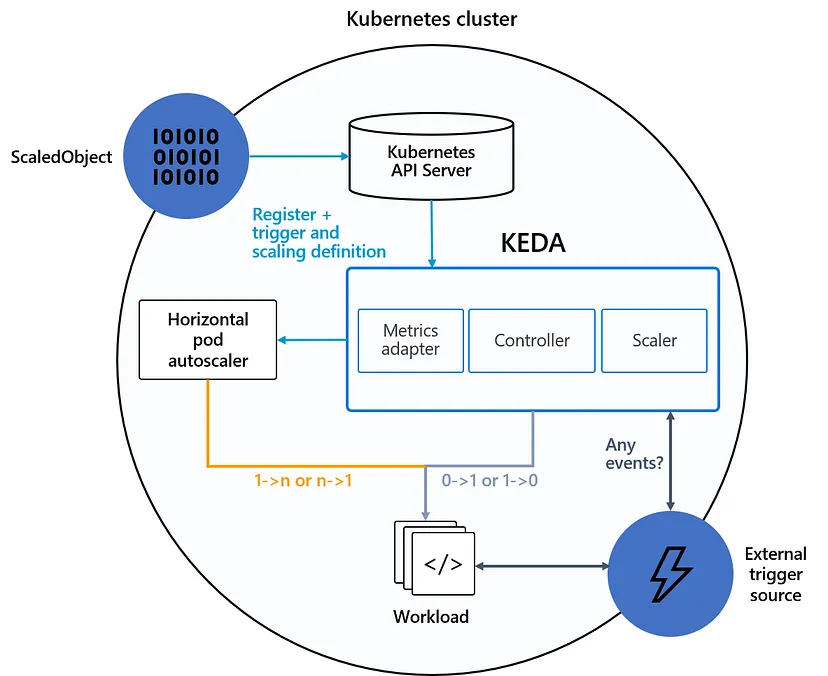
通过Helm 3安装KEDA
-
添加Helm repo
helm repo add kedacore https://kedacore.github.io/charts
-
更新Helm repo
helm repo update
-
安装 KEDAHelm chart
kubectl create namespace keda helm install keda kedacore/keda --namespace keda
用例
基于Azure服务总线队列长度的Kubernetes pod自动伸缩
在这个用例中,我们有一个微服务应用程序,负责处理来自Azure服务总线队列的消息。工作负载是偶尔发生的,根据传入流量具有不同的队列长度。我们希望动态扩展Kubernetes pod,以便通过KEDA有效的处理消息。
前置条件
-
安装了KEDA的Kubernetes集群。 -
访问队列的Azure服务总线和凭据。
步骤1: 部署示例应用程序。首先部署应用,侦听Azure服务总线队列并处理消息。我们用一个简单的Python应用程序进行演示。
# app.py
from azure.servicebus import ServiceBusClient, ServiceBusMessage
def process_message(message):
# Process the message here
print(f"Processing message: {message}")
# Configure Azure Service Bus connection string
connection_string = "your-connection-string"
# Create a Service Bus client
service_bus_client = ServiceBusClient.from_connection_string(connection_string)
# Create a receiver to listen to the queue
receiver = service_bus_client.get_queue_receiver(queue_name="your-queue-name")
# Start receiving and processing messages
with receiver:
for message in receiver:
process_message(message)
message.complete() # Mark the message as completed after processing
将上述代码部署为Kubernetes中的容器化应用程序。
步骤2: 配置KEDA支持自动缩放。为了使KEDA能够监控队列长度并触发自动缩放,需要创建ScaledObject并进行相应部署。
# scaledobject.yaml
apiVersion: keda.k8s.io/v1alpha1
kind: ScaledObject
metadata:
name: queue-scaler
spec:
scaleTargetRef:
deploymentName: your-deployment-name
triggers:
- type: azure-servicebus
metadata:
connection: "your-connection-string"
queueName: "your-queue-name"
name: queue-length-trigger
queueLength: "5" # Scale when the queue length is greater than or equal to 5
# deployment.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: your-deployment-name
spec:
replicas: 1 # Initial number of replicas
template:
spec:
containers:
- name: your-container-name
image: your-container-image
将上述YAML文件应用到Kubernetes集群,以创建ScaledObject和部署。
步骤3: 现在,当消息到达Azure服务总线队列时,KEDA将监控队列长度并根据定义的阈值触发自动缩放(在本例中,阈值为队列长度大于或等于5)。
可以通过监控部署的副本数量来观察自动伸缩:
kubectl get deployment your-deployment-name
当队列长度超过定义的阈值时,KEDA将自动扩展副本数量以处理增加的工作负载。一旦队列长度减少,KEDA将相应的减少副本,从而优化资源利用率。
这个用例演示了KEDA如何根据Azure服务总线队列的长度自动扩展Kubernetes pod。通过利用KEDA的可扩展性和事件驱动的扩展功能,可以确保有效的资源利用和对不同工作负载的响应。示例说明了KEDA在基于自定义指标动态调整pod数量方面的强大功能,使其成为一种有价值的扩展工具。
结论
Kubernetes pod自动伸缩是有效管理动态工作负载的基本特性。Kubernetes通过HPA提供了内置的自动缩放功能,KEDA为事件驱动缩放和自定义指标提供了强大扩展。通过将KEDA整合到Kubernetes集群中,可以释放实时自动扩展的潜力,使应用程序能够无缝适应不断变化的需求。虽然KEDA引入了额外的复杂性,但有助于提高应用集群的资源效率、可扩展性和可伸缩性。
- END -你好,我是俞凡,在Motorola做过研发,现在在Mavenir做技术工作,对通信、网络、后端架构、云原生、DevOps、CICD、区块链、AI等技术始终保持着浓厚的兴趣,平时喜欢阅读、思考,相信持续学习、终身成长,欢迎一起交流学习。为了方便大家以后能第一时间看到文章,请朋友们关注公众号"DeepNoMind",并设个星标吧,如果能一键三连(转发、点赞、在看),则能给我带来更多的支持和动力,激励我持续写下去,和大家共同成长进步!
本文由 mdnice 多平台发布






![[UNILM]论文实现:Unified Language Model Pre-training for Natural Language.........](https://img-blog.csdnimg.cn/direct/bdb2bfeb4c9b41ada63ef02eb2e2200c.png)