Python 函数查询
1. 《卖火柴的小女孩》是丹麦童话故事作家安徒生的一篇童话故事,发表于1846年。主要讲了一个卖火柴的小女孩在富人阖家欢乐、举杯共庆的大年夜冻死在街头的故事。这里给出《卖火柴的小女孩》的一个网络版本文件,文件名为“小女孩.txt”。
- 问题1:在PY301-1.py文件中修改代码,对“小女孩.tx”t文件进行字符频次统计,输出频次最高的中文字符(不包含标点符号)及其频次,将输出结果保存在考生文件夹下,命名为“PY301-1.txt”。字符与频次之间采用英文冒号"."分隔,示例格式如下:
的:83- 问题2:在PY301-2.p文件中修改代码,对“小女孩.txt“文件进行字符频次统计,按照频次由高到低,输出前10个频次最高的字符,不包含回车符,字符之间无间隔,连续输出,将输出结果保存在考生文件夹下,命名为PY301-2.txt”。示例格式如下:
,的一…(后略,共10个字符)- 问题3:在PY301-3.py文件中修改代码,对"小女孩.txt"文件进行字符频次统计,将所有字符按照频次从高到低排序,字符包括中文、标点、英文等符号,但不包含空格和回车。将排序后的字符及频次输出到考生文件夹下,件名为“小女孩-频次排序.txt”。字符与频次之间采用英文冒号".“分隔,各字符之间采用英文逗号”,"分隔,参考CSV格式,最后无逗号,文件内部示例格式如下:
着:30,那:29,火:29
# PY301-1.py
fi = open("小女孩.txt","r") # 打开文件"小女孩.txt",以只读模式打开
fo = open("PY301-1.txt","w") # 打开文件"PY301-1.txt",以写入模式打开
txt = fi.read() # 读取文件中的全部内容,保存到变量txt中
d = {} # 创建一个空字典d,用来保存每个字符出现的次数
exclude = ",。!?、()【】<>《》=:+-*—“”…" # 定义一个字符串exclude,用来保存需要排除的字符
# 遍历txt中的每个字符,统计每个字符出现的次数
for word in txt:
# 如果字符在exclude中,则跳过不统计
if word in exclude:
continue
# 如果字符不在exclude中,则将该字符的出现次数加1
else:
d[word] = d.get(word,0) + 1
ls = list(d.items()) # 将字典d转换为一个列表ls,每个元素是一个元组,包含字符和出现次数两个值
ls.sort(key = lambda x:x[1],reverse = True) # 对列表ls进行排序,按照元素的第二个值(出现次数)进行**降序排序**
fo.write("{}:{}".format(ls[0][0],ls[0][1])) # 将出现次数最高的字符和对应的出现次数写入到文件"PY301-1.txt"中
fo.close() # 关闭文件"PY301-1.txt"
fi.close() # 关闭文件"小女孩.txt"
# PY301-2.py
fi = open("小女孩.txt","r") # 打开文件"小女孩.txt",以只读模式打开
fo = open("PY301-2.txt","w") # 打开文件"PY301-2.txt",以写入模式打开
txt = fi.read() # 读取文件中的全部内容,保存到变量txt中
d = {} # 创建一个空字典d,用来保存每个字符出现的次数
# 遍历txt中的每个字符,统计每个字符出现的次数
for word in txt:
# 如果字符是换行符,则跳过
if word == "\n":
continue
# 如果字符在字典d中已经存在,则将该字符的出现次数加1
if word in d:
d[word] += 1
# 如果字符在字典d中不存在,则将该字符添加到字典d中,并将出现次数初始化为1
else:
d[word] = 1
ls = list(d.items()) # 将字典d转换为一个列表ls,每个元素是一个元组,包含字符和出现次数两个值
ls.sort(key = lambda x:x[1], reverse = True) # 对列表ls进行排序,按照元素的第二个值(出现次数)进行降序排序
# 将出现次数最高的前10个字符写入到文件"PY301-2.txt"中
for i in range(10):
fo.write(ls[i][0])
fi.close() # 关闭文件"小女孩.txt"
fo.close() # 关闭文件"PY301-2.txt"
# PY301-3.py
fi = open("小女孩.txt","r") # 以只读模式打开名为 "小女孩.txt" 的文件
fo = open("PY301-2.txt","w") # 以写入模式打开名为 "PY301-2.txt" 的文件
txt = fi.read() # 读取文件中的文本内容
d = {} # 创建一个空字典
# 遍历文本中的每个字符并将其添加到字典中,如果字符已经在字典中,则将其数量加1
for word in txt:
d[word] = d.get(word, 0) + 1
# 删除字典中的空格和换行符
del d[" "]
del d["\n"]
ls = list(d.items()) # 将字典转换为列表
ls.sort(key = lambda x:x[1], reverse = True) # 按照值(也就是词频)从大到小排序
# 将列表中的每个元素转换为字符串,格式为 "字符:词频"
for i in range(len(ls)):
ls[i] = "{}:{}".format(ls[i][0],ls[i][1])
# 将列表中的所有元素用逗号连接成一个字符串,并将其写入文件中
fo.write(",".join(ls))
# 关闭文件
fi.close()
fo.close()
items()
描述:Python 字典(Dictionary) items() 函数以列表返回可遍历的(键, 值) 元组数组。
items()方法语法:dict.items()
list(seq)
描述:list() 方法用于将元组转换为列表。
list()方法语法:list( seq )
get(key, default=None)
描述:Python 字典(Dictionary) get() 函数返回指定键的值,如果值不在字典中返回默认值。
get()方法语法:dict.get(key, default=None)
2. 法定节假日是根据各国、各名族的风俗习惯或纪念要求,由国家法律统一规定的用以进行庆祝及度假的休息时间。法定节假日制度是国家政治、经济、文化制度的重要反映,涉及经济社会的多个方面,涉及广大人民群众的切身未法定节假日的休假安排,为居民出行购物和休闲提供了时间上的便利,为拉动内需、促进经济增长做出了积极益。贡献。给出一个2018年的节假日的放假日期CSV文件,内容示例如下:
| 序号 | 节假日名称 | 开始月日 | 结束月日 |
|---|---|---|---|
| 1 | 元旦 | 1230 | 0101 |
| 2 | 春节 | 0215 | 0221 |
| 3 | 清明节 | 0405 | 0407 |
| 4 | 劳动节 | 0501 | 0503 |
| 5 | 端午节 | 0616 | 0618 |
以第1行为例,1230表示12月30日,0101表示1月1日。
问题1:在PY301-1.py文件中修改代码,读入CSV文件中数据,获得用户输入。根据用户输入的节假日名称,输出此节假日的假期范围。
参考输入和输出示例格式如下:
请输入节假日名称(例如,春节):春节
春节的假期位于0215-0221之间问题2:在PY301-2.py文件中修改代码,读入CSV文件中数据,获得用户输入。用户键盘输入一组范围是1~7的整数作为序号,序号间采用空格分隔,以回车结束。屏幕输出这些序号对应的节假日的名称、假期范围,每个节假日的信息一行。本次屏幕显示完成后,重新回到输入序号的状态。
参考输入和输出示例格式如下:
请输入节假日序号:1 5
元旦(1) 假期是12月30日至01月01日之间
端午节(5)假期是06月16日至06月18日之间
请输入节假日序号:问题3:在问题2的基础上,在PY301-3.py文件中修改代码,对键盘输入的每个序号做合法性处理。如果输的数字不合法,请输出”输入节假日编号有误!",继续输出后续信息,然后重新回到输入序号的状态。
参考输入和输出示例格式如下:
请输入节假日序号:5 14 11
端午节(5)假期是06月16日至06月18日之间
输入节假日编号有误!
输入节假日编号有误!
请输入节假日序号:
# PY301-1.py
fi = open("PY301-vacations.csv","r")
ls = []
for line in fi:
ls.append(line.strip("\n").split(","))
fi.close()
s = input("请输入节假日名称:")
for line in ls:
if s == line[1]:
print("{}的假期位于{}-{}之间".format(line[1],line[2],line[3]))
# PY301-2.py
fi = open("PY301-vacations.csv","r")
ls = []
for line in fi:
ls.append(line.strip("\n").split(","))
s = input("请输入节假日序号").split(" ")
while True:
for i in s:
for line in ls:
if i == line[0]:
print("{}({})的假期位于{}月{}日至{}月{}日之间".format(line[1],line[0],line[2][0] + line[2][1],line[2][2] + line[2][3],line[3][0] + line[3][1],line[3][2] + line[3][3]))
s = input("请输入节假日序号:").split(" ")
# PY301-3.py
fi=open("PY301-vacations.csv","r")
ls = []
for line in fi:
ls.append(line.strip("\n").split(","))
s = input("请输入节假日序号:").split(" ")#由于可以输入多个节假日的序号,所以需要进行逐个的遍历访问,所以通过split()函数来存放在列表中进行方便访问
while s != "":
for i in s:
flag = false
for line in ls:
if i == line[0]:
print("{}({})假期是{}月{}日至{}月{}日之间".format(line[1],line[0],line[2][0] + line[2][1],line[2][2] + line[2][3],line[3][0] + line[3][1],line[3][2] + line[3][3]))
flag = True
if flag == false:
print("输入节假日编号有误!")
s = input("请输入节假日序号:").split(" ")
strip([chars]):删除字符串开头和末尾的空格或指定字符。
join(seq):以指定字符串作为分隔符,将 se 中所有的元素(的字符串表示)合并为一个新的字符串
sort()函数:用于对原列表进行排序,如果指定参数,则使用比较函数指定的比较函数


3. 《论语》是儒家学派的经典著作之一,主要记录了孔子及其弟子言行。这里给出了一个网络版本的 《论语》,文件名称为“论语.txt”,其内容采用逐句“原文”与“逐句”注释相结合的形式组织,通过【原文】标记《论语》原文内容,通过【注释】标记《论语》注释内容,具体文件格式框架请 参考“论语.txt”文件。
- 问题1: 在PY301-1.py文件中修改代码,提取“论语.txt”文件中的原文内容,输出保存为文件 “论语-原文txt”。具体要求:仅保留“论语txt”文件中所有【原文】标签下面的内容,不保留标签,并去掉每行行首空格及行尾空格,无空行。原文小括号及内部数字是源文件中注释项的标记,请保留。
- 问题2:在PY302-2.py文件中修改代码,对“论语-原文.txt”文件进一步提纯,去掉每行文字中所有小括号及内部数字,保存为“论语-提纯原文.txt”文件。
#PY301-1
fi = open("论语.txt","r")
fo = open("论语-原文.txt","w")
flag = False
for line in fi:
if "【原文】" in line:
flag = true
continue
if flag == True:
fo.write(line.lstrip())
fi.close()
fo.close()
#PY302-2
fi = open("论语-原文.txt","r")
fo = open("论语-提取原文.txt","w")
for line in fi:
if i in range(1,23):
line = line.replace("({})".format(i),"")
fo.wirte(line)
fi.close()
fo.close()
4. 下面所示为一套由公司职员随身佩戴的位置传感器采集的数据,文件名称为“sensor.txt”,其内容示例如下:
2016/5/31 0:05,vawelon001,1,1
2016/5/31 0:20,earpa001,1,1
2016/5/31 2:26,earpa001,1,6
…(略)
第一列是传感器获取数据的时间,第二列是传感器的编号,第三列是传感器所在的楼层,第四列是传感器所在的位置区域编号。
- 问题1:在PY301-1. py文件中修改代码,读入sensor. txt文件中的数据,提取出传感器编号为earpa001的所有数据,将结果输出保存到“earpa001. txt”文件。输出文件格式要求:原数据文件中的每行记录写入新文件中,行尾无空格,无空行。参考格式如下:
2016/5/31 7:11, earpa001,2,4
2016/5/31 8:02, earpa001,3,4
2016/5/31 9:22, earpa001,3,4
…(略)- 问题2(10分):在PY301-2.py文件中修改代码,读入“earpa001.txt”文件中的数据,统计earpa001对应的职员在各楼层和区域出现的次数,保存到“earpa001 count.txt”文件,每条记录一行,位置信息和出现的次数之间用英文半角逗号隔开,行尾无空格,无空行。
参考格式如下:
1-1,5
1-4,3
fi = open("sensor.txt","r")
fo = open("earpa001.txt","w")
txt = fi.readlines()
for line in txt:
ls = line.strip("\n").split(",")
if 'earpa001' in ls:
fo.write("{},{},{},{}\n".format(ls[0],ls[1].ls[2],ls[3]))
fi.close()
fo.close()
fi = open("earpa001.txt","r") # # 打开名为"earpa001.txt"的文件,以只读模式读取文件内容,将其赋值给变量fi
fo = open("earpa001_count.txt","w") # # 打开名为"earpa001_count.txt"的文件,以写入模式打开文件,将其赋值给变量fo
d = {} # 创建一个空字典,用于存储每个区域的数量统计结果
for line in fi: # 遍历文件fi中的每一行
split_data = line.strip("\n").split(",") # 使用strip方法去除每行末尾的换行符,并使用split方法以逗号为分隔符将每行内容分割成一个列表
floor_and_area = split_data[-2] + " -" + split_data[-1] # 将该行内容中倒数第二个元素和最后一个元素拼接成一个字符串,用于表示该行内容所属的区域
if floor_and_area in d: # 如果该区域已经在字典d中,则将该区域对应的值加1
d[floor_and_area] += 1 # 如果该区域不在字典d中,则将该区域添加到字典d中,并将其对应的值设置为1
else:
d[floor_and_area] = 1
ls = list(d.items()) # 将字典d转换为列表,并按照列表中元素的第二个元素(即数量统计结果)从大到小排序
ls.sort(key = lambda x:x[1], reverse = True) # 该语句用于排序
# 遍历排序后的列表,并将每个区域的数量统计结果写入文件fo中
for i in range(len(ls)):
fo.write('{},{}\n'.format(ls[i][0],ls[i][1]))
# 关闭文件fi和fo
fi.close()
fo.close()
5. 《傲慢与偏见》是史上震撼人心的“世界文学十部最佳小说之一”。第一章的内容由考生文件夹下文件arrogant.txt给出
- 问题1:编写程序,统计该篇文章的英文字符数(不统计换行符),字符与出现次数之间用英文冒号“:”分隔。
- 问题2:在问题1的前提下,将得到的字符次数记行排序,并将排名前10的常用字符保存在"arrogant-sort.txt"文件中。
# PY301-1
fi = open("arrogant.txt","r")
fo = open("PY301-1.txt","w")
txt = fi.read()
d = {}
for s in txt:
d[s] = d.get(s,0) + 1
del d["\n"]
ls = list(d.items())
for i in range(len(ls)):
fo.write("{}:{}\n".format(ls[i][0],ls[i][1]))
fi.close()
fo.close()
# PY301-2
fi = open("arrogant.txt","r")
fo = open("arrogant-sort.txt","w")
txt = fi.read()
d = {}
for s in txt:
d[s] = d.get(s,0) + 1
del d["\n"]
ls = list(d.items())
ls.sort(key = lambda x:x[1],reverse = True)
for i in range(10):
fo.write("{}:{}\n".format(ls[i][0],ls[i][1]))
fi.close()
fo.close()
6. Score.csv文件中存储的是一个学生在第一季度同一学科对应的月考成绩,求出每一门学科在三个月中的平均成绩,将结果输出在考生文件夹。
fi = open("score.csv","r")
fo = open("avg-score.txt","w")
ls = []
x = []
sum = 0
for row in fi:
ls.append(row.strip("\n").split(","))
for line in ls[1:]:
for i in line[1:]:
sum = int(i) + sum
avg = sum / 3
x.append(avg)
sum = 0
fo.write("语文:{:.2f}\n数学:{:.2f}\n英语:{:.2f}\n物理:{:.2f}\n科学:{:.2f}".format(x[0],x[1],x[2],x[3],x[4]))
fi.close()
fo.close()
7. 马和骆驼都是哺乳动物的一种,它们都有四只脚,体型也差不多大,作为现实世界中的一个类生物,我们将在这里为它们编写属于它们各自的类。
- 问题1:在PY301-1py 文件中修改代码,代码中编写了一个马(Home)的类,在这个类中马有三个属性,分别是年龄(age)、品种(category)和性别(gender)。在每创建一个马的对象时,我们需要为其指定它的年龄、品种和性别。该类中还编写一个get_deseriptive ()方法,能够打印出马的这三个属性。每一匹马都有自己的最快速度,所以类中有一个speed() 方法可以打印出马的最快速度值。并且在马的生命过程中,它的速度一直在变,类中还有一个update_speed()方法用来更新马当前的最快速度值。
例如:一匹12岁的阿拉伯公马,在草原上奔跑的速度为50km/h,要求调用get_descriptive()和update_speed()方法,将输出的结果保存在考生文件夹下,文件命名为“PY301-1.txt”。- 问题2:在PY301-2.py文件中修改代码,该代码编写了一个骆驼类(Camel),这个类继承自上一个文件中的马类但是不对马类中的属性和方法进行操作。因为每个骆驼的驼峰数量不一致,我们在类中添加驼峰数目这个新属性,并且添加一个打印出骆驼驼峰数量的方法。
例如:一个双峰驼20岁的母骆驼以每小时40千米的速度奔跑在沙漠中,调用父类的方法和Camel类本身的方法将结果保存在“PY301-2.txt"中。
# PY301-1
fo = open("PY301-1.txt","w")
class Horse ():
def _init_(self, category, gender, age):
self.cataegory = category
self.gender = gender
self.age = age
self.horse_speed = 0
def get_descriptive(self):
info = 'this horse is' + str(self.age) + 'years old,' + 'its category is' + self.category + ',' + 'its gender is’ + self.gender + '.'
fo.write(info + "\n")
def update_speed(self,new_speed):
self.horse_speed = new_speed
fo.write('the speed of this horse is' + str(self.horse_speed) + "km/h.\n")
horse = Horse("Arab","male","12")
horse.get_descriptive()
horse.update_speed(50)
fo.close()
# PY301-2
fo = open("PY301-2.txt","w")
class Horse():
def _init_(self, category, gender, age):
self.cataegory = category
self.gender = gender
self.age = age
self.horse_speed = 0
def get_descriptive(self):
info = 'this horse is' + str(self.age) + 'years old,' + 'its category is' + self.category + ',' + 'its gender is’ + self.gender + '.'
fo.write(info + "\n")
def update_speed(self,new_speed):
self.horse_speed = new_speed
fo.write('the speed of this horse is' + str(self.horse_speed) + "km/h.\n")
class Camel(Horse):
def _init_(self, category, gender, age):
super()._init_(category, gender, age)
self.hump_size = 2
def describe_hump_size(self):
fo.write('this camel has' + str(self.hump_size) + 'hump.')
camel = Camel("Double hump","female","20")
camel.get_descriptive()
camel.update_speed(40)
camel.describe_hump_size()
fo.close()
8. 凯撒密码是一种非常古老的加密算法,相传当年凯撒大帝行军打仗时为了保证自己的命令不被敌军知道,它采用了替换方法对信息中的每一个英文字符循环替换为字母序列该字符后面第三个字符:即循环后三位,对应关系如下:
原文:A B C D E FG H I J K L M N O P Q R S T U V W X Y Z
密文:D E F G H I J K L M N O P Q R S T U V W X Y Z A B C
原文字符P,其密文字符C满足如下条件:
C=(P+3)mod 26
解密方法反之,满足:
P=(C-3)mod 26
凯撒密码的加密算法程序首先接受用户输入的文本,然后对字母a-z和字母A-Z按照密码算法进行转换,同时输出。其他非英文字母原样输出。
intxt = input("请输入明文:")
for p in intxt:
if "a" < p < "z":
print(chr(ord("a") + (ord(p) - ord("a") + 3) % 26), end = "")
elif "A" < p < "Z":
print(chr(ord("A") + (ord(p) - ord("A") + 3) % 26), end = "")
else:
print(p, end = "")
9. 李白,字太白,号青莲居士,又号“谪仙人”,是唐代伟大的浪漫主义诗人,被后世誉为“诗仙”。考生文件夹下有一个“关山月.txt”文件,内容如下:
明月出天山,苍茫云海间。长风几万里,吹度玉门关。汉下白登道,胡窥青海湾。由来征战地,不见有人还。成客望边邑,思归多苦颜。高楼当此夜,叹息未应闲。
- 问题1:这是一段由标点符号分隔的文本,请编写程序,以“。”句号为分隔,将这段文本转换为诗词风格,输出到文件“关山月-诗歌.txt”中。
- 问题2:把问题1生成的“关山月-诗歌.xt”文件,以每行为单位,保留标点符号为原顺序和位置,输出全文的反转形式。将文件保存在考生文件夹下并命名为“关山月-反转.txt”。输出的形式如下:
高楼当此夜,叹息未应闲。
戍客望边邑,思归多苦颜。
由来征战地,不见有人还。
汉下白登道,胡窥青海湾。
长风几万里,吹度玉门关。
明月出天山,苍茫云海间。
fi = open("关山月.txt","r")
fo = open("关山月-诗歌.txt","w")
txt = fi.read()
ls = txt.split("。")
fo.write("。\n".join(ls))
fi.close()
fo.close()
join(seg):以指定字符串作为分隔符,将seq中所有的元素(的字符串表示)合并为一个新的字符串
fi = open("关山月-诗歌.txt","r")
fo = open("关山月-反转.txt","w")
txt = fi.readlines()
txt.reverse()
for row in txt:
fo.write(row)
fi.close()
fo.close()
10. 设计一个猜字母的程序,程序随机给出26个小写字母中的一个,答题者输入猜测的字母,若输入的不是26个小写字母,让用户重新输入;若字母在答案之前或之后,程序给出相应正确提示;若答错5(含)次,则答题失败并退出游戏,若回答正确,程序输出回答次数并退出游戏。
import random
letter_list = ['a', 'b', 'c', 'd', 'e', 'f','g',
'h', 'i', 'j', 'k', 'l','m', 'n',
'o', 'p', 'q', 'r', 's', 't',
'u', 'v', 'w', 'x', 'y', 'z']
letter = letter_list[random.randint(0, 25)]
count = 0
while True:
letter_input = input("请输入26个小写英文字母中的任一个:")
count += 1
if letter_input not in letter_list:
print("请重新输入字母")
else:
if count >= 5:
print("猜测超过5次,答题失败")
break
else:
if letter_input == letter:
print("恭喜你答对了,总共猜了{}次".format(count))
elif letter_input > letter:
print("你输入的字母排在该字母之后")
elif letter_input < letter:
print("你输入的字母排在该字母之前")
else:
print("未知错误")
11. 某班学生评选一等奖学金,学生的10门主干课成绩存在考生文件夹下文件score.txt中,每行为一个学生的信息,分别记录了学生学号、姓名以及10门课成绩,格式如下:
1820161043 郑珉稿 68 66 83 77 56 73 61 69 66 78
1820161044 沈红伟 91 70 81 91 96 80 78 91 89 94
…
从这些学生中选出奖学金候选人,条件是:①总成绩排名在前10名;②全部课程及格(成绩大于等于60)。
- 问题1:给出按总成绩从高到低排序的前10名学生名单,并写入文candidate0.txt,每行记录一个学生的信息,分别为学生学号、姓名以及10门课成绩。补充考生文件夹下文件PY301-1.py,完成这一功能。
- 问题2:读取文件candidate0.txt,从中选出候选人,并将学号和姓名写入文件candidatetxt格式如下:
1010112161722 张三
1010112161728 李四
补充考生文件夹下文件PY301-2.py完成这一功能。
L = [] #L中的元素是学生原始成绩和总成绩
fo = open("score.txt","r")
fi = open("candidate0.txt","w")
lines = fo.readlines()
for line in lines:
line = line.strip()
student = line.split(' ')
sum = 0
for i in range(1,11):
sum += int(student[-i])
student.append(str(sum))
L.append(student)
L.sort(key = lambda x:x[-1],reverse = True) #按学生总成绩从大到小排序
for i in range(10):
fi.write(" ".join(L[i][:-1]) + "\n")
fo.close()
fi.close()
fo = open("candidate0.txt","r")
fi = open("candidate.txt","w")
L = [] # 存储候选人
lines = fo.readlines()
for line in lines:
line = line.strip()
student = line.split(' ')
for i in student[-10:]:
if int(i) < 60:
break;
else:
L.append(student[:2])
for i in L:
fi.write(" ".join(i) + "\n")#此时每个i本身就是列表
fi.close()
fo.close()
12. 《三国演义》是中国古典四大名著之一,曹操是其中主要人物,考生文件夹下文件data.txt给出《三国演义》简介
- 问题1:请编写程序,用Pthon语言中文分词第三方库iieba对文件datatxt进行分词,并将结果写入文件out.txt,每行一个词,例如:
内容简介
编辑
整个
故事
在
东汉
…
在考生文件夹下给出了程序框架文件PY301-1.py,补充代码完成程序。- 问题2:对文件out.txt进行分析,打印输出曹操出现次数。在考生文件夹下给出了程序框架文件PY301-2.py,补充代码完成程序。
import jieba
f = open('data.txt','r')
lines = f.readlines()
f.close()
f = open('out.txt','w')
for line in lines:
line = line.strip() #删除每行首尾可能出现的空格
wordList = jieba.lcut(line) #用结巴分词,对每行内容进行分词
f.writelines('\n'.join(wordList)) #将分词结果存到文件out.txt中
f.close()
import jieba
f = open('out.txt','r') #以读的方式打开文件
words = f.readlines()
f.close()
D = {}
for w in words: #词频统计
D[w[:-1]] = D.get(w[:-1],0) + 1
print("曹操出现次数为:{} ".format(D['曹操']))
join()

python之read()方法
- read()方法
read()方法,当不规定读取多少字符时,读的时文件的全部字符
2、readlines()方法
readlines(),读取所有数据,读取的所有的数据,会形成一个列表,列表的每一项就是一行数据
3、readline()方法
readline方法,读取文件一行数据,如果不关闭文件,可以一直读取
#①read()方法
f=open(r"C:\Users\Administrator\Desktop\text.txt","r",encoding="UTF-8")
print(f.read())
print(f.read(10))
f.close()
#②readlines()方法
f=open(r"C:\Users\Administrator\Desktop\text.txt","r",encoding="UTF-8")
print(f.readlines())
f.close()
#③readline()方法
f=open(r"C:\Users\Administrator\Desktop\text.txt","r",encoding="UTF-8")
print(f.readline())
print(f.readline())
f.close()

sort和sorted的区别
- sort是应用在list(也就是列表)上的方法,属于列表的成员方法;而sorted是Python内置的全局方法,可以对所有可迭代对象进行排序操作
- list的sort方法是对已存在的列表进行操作;而内建函数sorted的结果会返回一个新生成的列表,而不是在原有列表的基础上进行操作
- sort的使用方法为list.sort(),而sorted的使用方法为sorted(list)
sorted()
语法:sorted(iterable=None,key=None,reverse=False)
参数说明:
iterable:可迭代对象
key:该参数的值为一个函数,此函数只有一个参数,并且返回一个值用来进行比较。
reverse:排序规则,reverse=False 升序(默认),reverse=True 降序
sort()
sort语法:list.sort(key=None,reverse=False)
两个参数跟上面sorted的参数一样
在使用的时候要注意的是list.sort()没有返回值,也就是返回值为None。
python字典排序方法
1. 利用自定义函数lambda
说明:通过dic.items()获取由字典键名和键值(key 、value)组成的元组列表,然后通过自定义函数,获取元组的第2个元素作为排序的依据(即根据字典的键值来排序)
默认是按照升序排列(此时可省略reverse=False)
dic={'a': 4, 'b': 3, 'c': 2, 'd': 1}
sorted(dic.items(), key=lambda x: x[1],reverse=False)
sorted(dic.items(), key=lambda x: x[1],reverse=True)

如果是降序排列可以把reverse设为True

2. 利用operator的方法
说明:功能是返回一个可调用对象,该对象可以使用操作__getitem__()方法从自身的操作中捕获item。如果制定了多个items,返回一个由查询值组成的元组。例如:运行f =itemgetter(2),然后调用f(r),返回r[2]。这里通过operator获得了dic.items()中的键值。注意operator是内置的包,无需安装。
dic={'a': 4, 'b': 3, 'c': 2, 'd': 1}
import operator
sorted(dic.items(), key=operator.itemgetter(1))

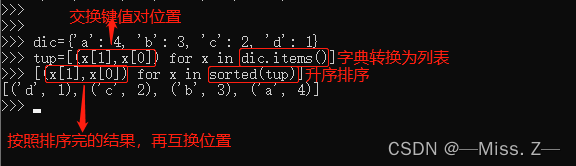
3. 列表推导式法
dic={'a': 4, 'b': 3, 'c': 2, 'd': 1}
tup=[(x[1],x[0]) for x in dic.items()]
[(x[1],x[0]) for x in sorted(tup)]
说明:用列表推导式,交换元组中元素的位置,排序后再交换回来,这种方法有点儿麻烦,但是逻辑清楚,适合新手。