前言
聚类算法又叫做”无监督分类“,目标是通过对无标记训练样本来揭示数据的内在性质及 规律,为进一步的数据分析提供基础。
Kmeans
作为聚类算法的典型代表,Kmeans可以说是最简单的聚类算法,没有之一,那她是怎么完成聚类的呢?
- 算法接受参数k
- 给定样本集 D = { x 1 , x 2 , . . . , x n } D=\{x_1,x_2,...,x_n\} D={x1,x2,...,xn}
- 随机选点k个中心(质心)
- 遍历样本集,先取距离最近的质心,从而根据质心分解样本集D簇划分 C = { C 1 , C 2 , . . . , C k } C=\{C_1,C_2,...,C_k\} C={C1,C2,...,Ck}
- 最小化平方误差

- 利用簇中均值等方法更新该簇类的中心k个;
- 重覆4-6的步骤,直至E不再更新
Kmeans中用的是欧式距离
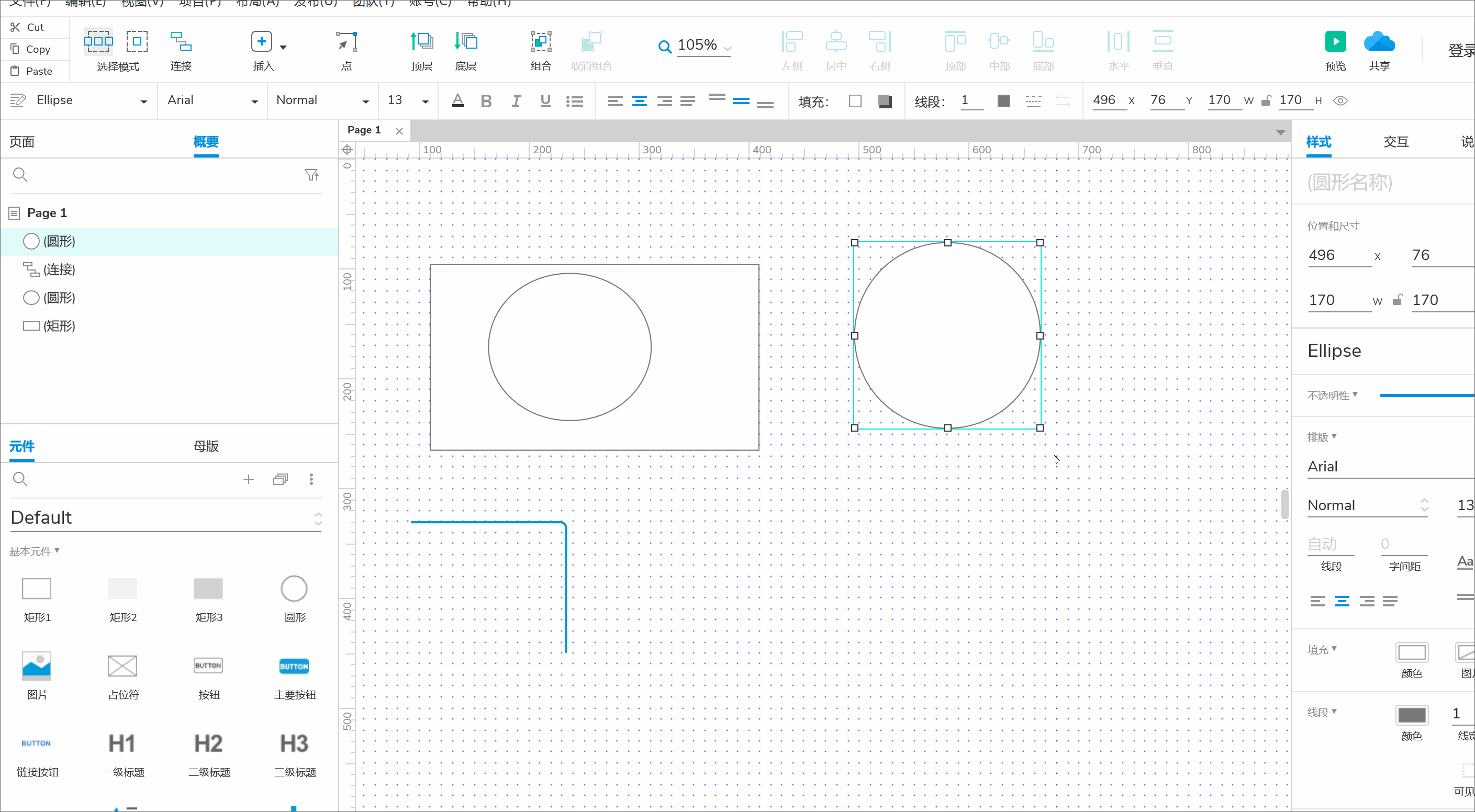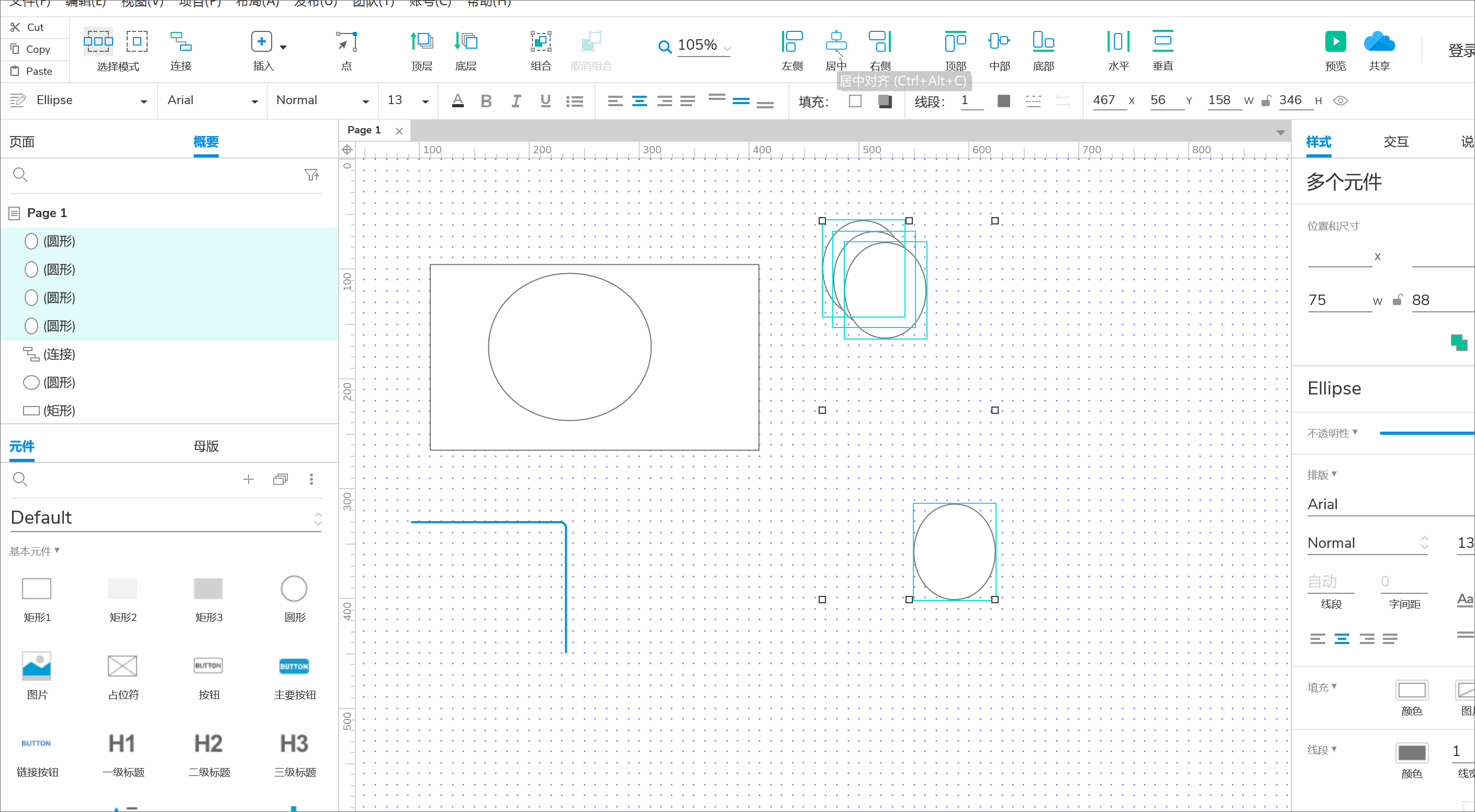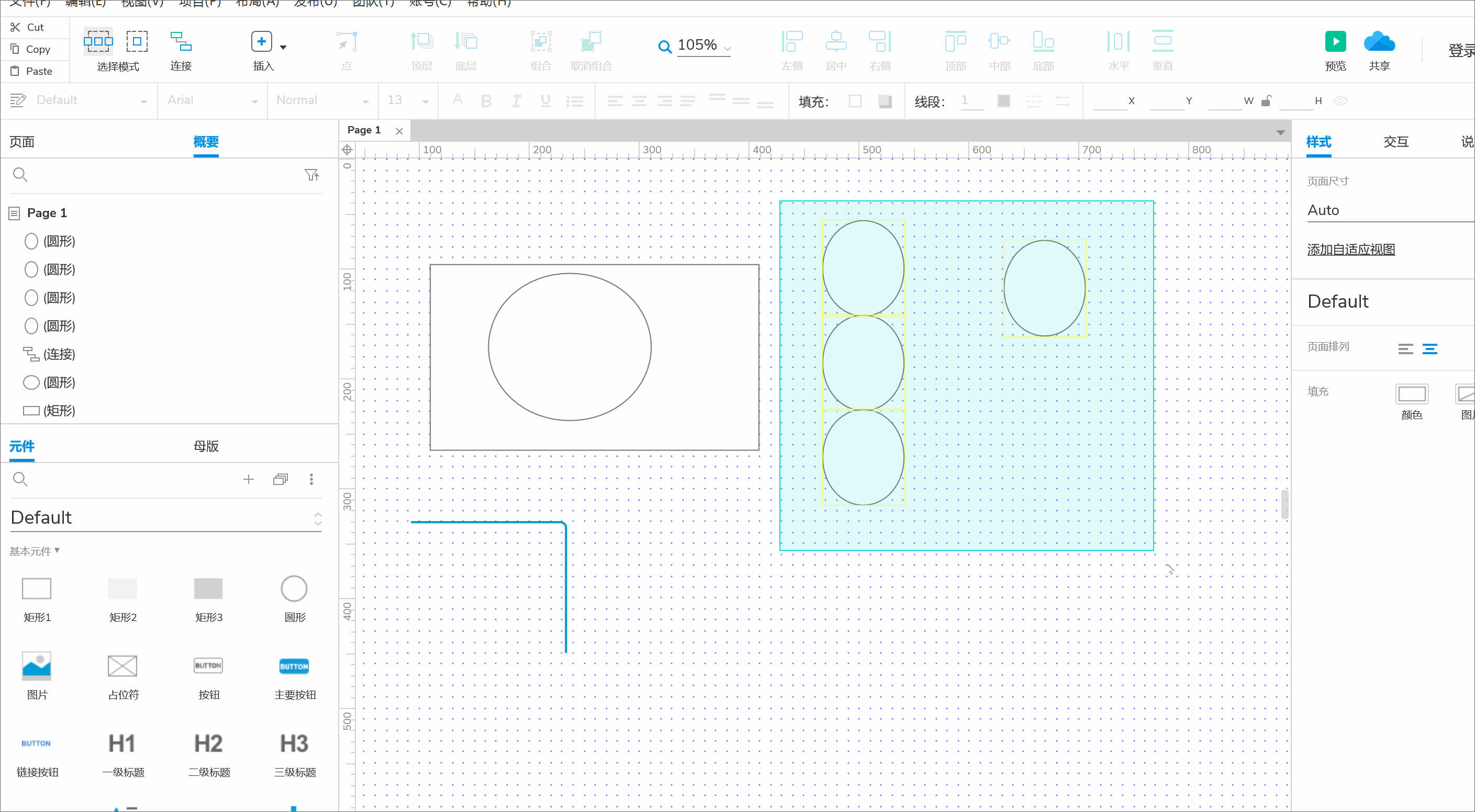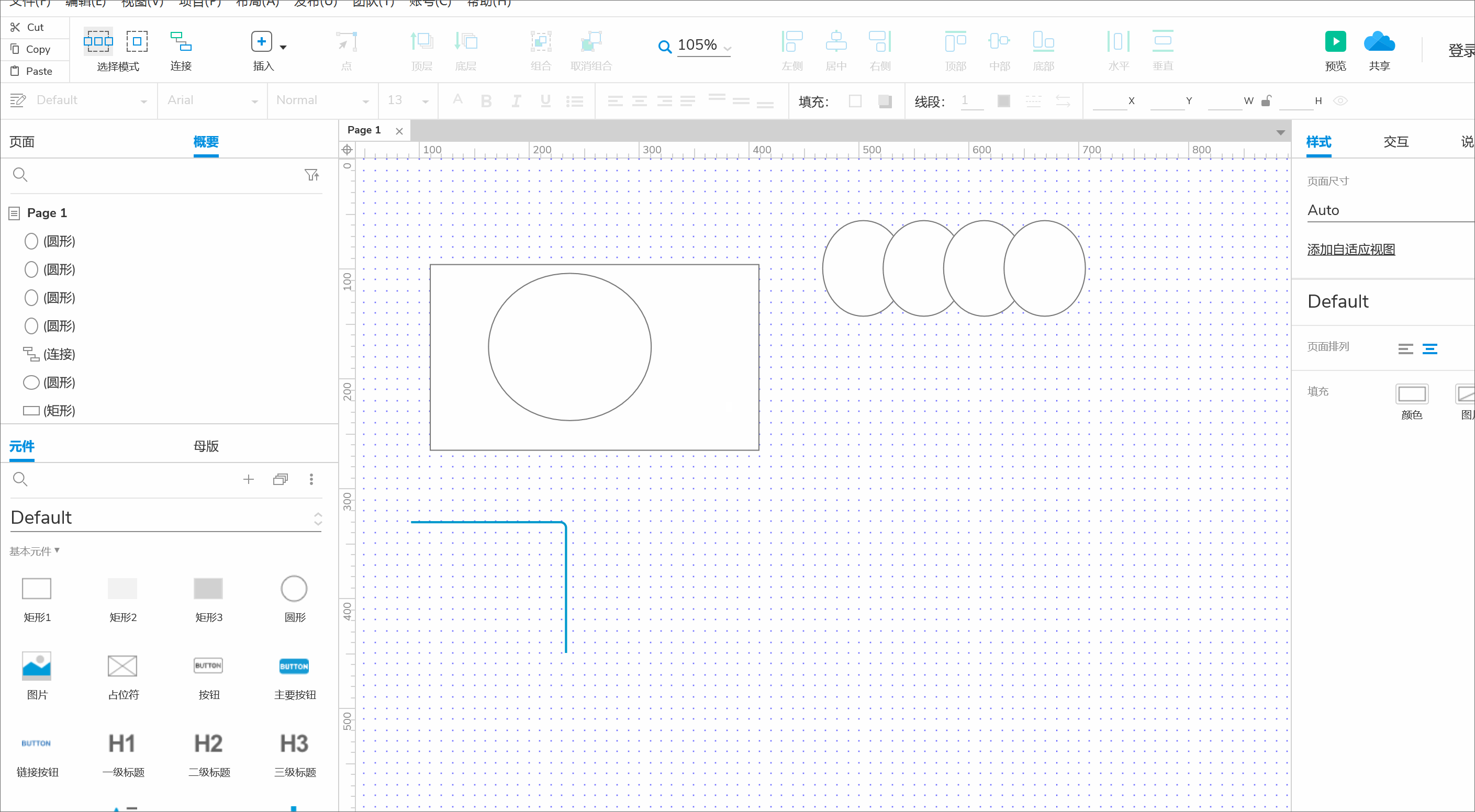
kmeans的计算过程
- 现在有4组数据,每组数据有2个维度,对其进行聚类分为2类,将其可视化一下。

- 通过比较,将其进行归类。并使用平均法更新中心位置。

- 再次计算每个点与更新后的位置中心的距离,直到上一次的类别标记无变化,即可停止
import matplotlib.pyplot as plt
from sklearn.cluster import KMeans
from sklearn.datasets import make_blobs
## 创建数据集
X, _ = make_blobs(n_samples=10000, centers=2, random_state=0)
## kmeans超参数值列表
n_clusters_list = [4, 8, 16]
# 图的框架
fig, axs = plt.subplots(
1, len(n_clusters_list), figsize=(12, 5)
)
axs = axs.T
for j, n_clusters in enumerate(n_clusters_list):
## 创建模型
algo = KMeans(n_clusters=n_clusters, random_state=random_state, n_init=3)
algo.fit(X)
centers = algo.cluster_centers_
axs[j].scatter(X[:, 0], X[:, 1], s=10, c=algo.labels_)
## 画质心
axs[j].scatter(centers[:, 0], centers[:, 1], c="r", s=20)
axs[j].set_title(f"{n_clusters} clusters")
for ax in axs.flat:
ax.label_outer()
ax.set_xticks([])
ax.set_yticks([])
plt.show()
聚类算法用于降维
K-Means聚类最重要的应用之一是非结构数据(图像,声音)上的矢量量化(VQ)。非结构化数据往往占用比较多的储存空间,文件本身也会比较大,运算非常缓慢,我们希望能够在保证数据质量的前提下,尽量地缩小非结构化数据的大小,或者简化非结构化数据的结构。
- 一组40个样本的数据,分别含有40组不同的信息(x1,x2)。
- 将代表所有样本点聚成4类,找出四个质心.这些点和他们所属的质心非常相似,因此他们所承载的信息就约等于他们所在的簇的质心所承载的信息。
- 使用每个样本所在的簇的质心来覆盖原有的样本,有点类似四舍五入的感觉,类似于用1来代替0.9和0.8。
这样,40个样本带有的40种取值,就被我们压缩了4组取值,虽然样本量还是40个,但是这40个样本所带的取值其实只有4个,就是分出来的四个簇的质心。查看官方用例
主要参考
《机器学习理论(十三)Kmeans聚类》