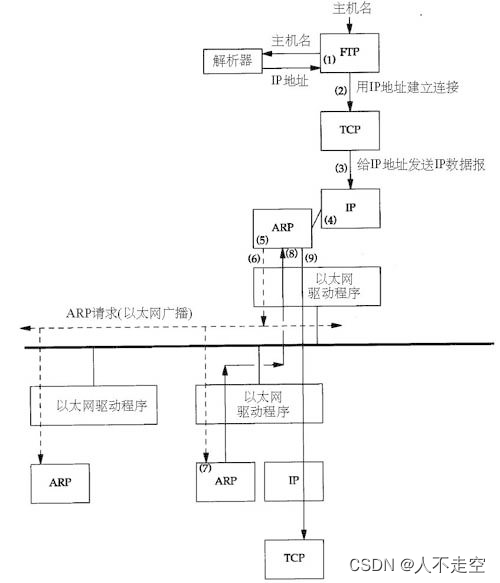
Faster R-CNN pytorch源码血细胞检测实战(二)数据增强
文章目录
- Faster R-CNN pytorch源码血细胞检测实战(二)数据增强
- 1. 资源&参考
- 2. 数据增强
- 2.1 代码运行
- 2.2 文件存放
- 3 数据集划分
- 4. 训练&测试
- 5. 总结
1. 资源&参考
Faster R-CNN pytorch版源码调试过程参考:Faster R-CNN pytorch源码血细胞检测实战(详细版)
数据增强源码参考:voc数据集对有标签的数据集数据增强
其它参考:
imgaug使用文档
2. 数据增强
在Faster R-CNN pytorch源码血细胞检测实战(详细版)的基础上,我们完成了对Faster RCNN pytorch版代码的运行,并且基于公共血细胞数据集实现了对多血细胞的检测。现在,在前文的基础上,我们对数据进行增强,并基于增强后的数据对Faster RCNN进行训练,进而测试应用数据增强技术后的训练模型的检测精度。
2.1 代码运行
数据增强源码参考了这篇voc数据集对有标签的数据集数据增强,如下所示:
'''
Author: CodingWZP
Email: codingwzp@gmail.com
Date: 2021-08-06 10:51:35
LastEditTime: 2021-08-09 10:53:43
Description: Image augmentation with label.
'''
import xml.etree.ElementTree as ET
import os
import imgaug as ia
import numpy as np
import shutil
from tqdm import tqdm
from PIL import Image
from imgaug import augmenters as iaa
ia.seed(1)
def read_xml_annotation(root, image_id):
in_file = open(os.path.join(root, image_id))
tree = ET.parse(in_file)
root = tree.getroot()
bndboxlist = []
for object in root.findall('object'): # 找到root节点下的所有country节点
bndbox = object.find('bndbox') # 子节点下节点rank的值
xmin = int(bndbox.find('xmin').text)
xmax = int(bndbox.find('xmax').text)
ymin = int(bndbox.find('ymin').text)
ymax = int(bndbox.find('ymax').text)
# print(xmin,ymin,xmax,ymax)
bndboxlist.append([xmin, ymin, xmax, ymax])
# print(bndboxlist)
bndbox = root.find('object').find('bndbox')
return bndboxlist
def change_xml_list_annotation(root, image_id, new_target, saveroot, id):
in_file = open(os.path.join(root, str(image_id) + '.xml')) # 这里root分别由两个意思
tree = ET.parse(in_file)
# 修改增强后的xml文件中的filename
elem = tree.find('filename')
elem.text = (str(id) + '.jpg')
xmlroot = tree.getroot()
# 修改增强后的xml文件中的path
elem = tree.find('path')
if elem != None:
elem.text = (saveroot + str(id) + '.jpg')
index = 0
for object in xmlroot.findall('object'): # 找到root节点下的所有country节点
bndbox = object.find('bndbox') # 子节点下节点rank的值
# xmin = int(bndbox.find('xmin').text)
# xmax = int(bndbox.find('xmax').text)
# ymin = int(bndbox.find('ymin').text)
# ymax = int(bndbox.find('ymax').text)
new_xmin = new_target[index][0]
new_ymin = new_target[index][1]
new_xmax = new_target[index][2]
new_ymax = new_target[index][3]
xmin = bndbox.find('xmin')
xmin.text = str(new_xmin)
ymin = bndbox.find('ymin')
ymin.text = str(new_ymin)
xmax = bndbox.find('xmax')
xmax.text = str(new_xmax)
ymax = bndbox.find('ymax')
ymax.text = str(new_ymax)
index = index + 1
tree.write(os.path.join(saveroot, str(id + '.xml')))
def mkdir(path):
# 去除首位空格
path = path.strip()
# 去除尾部 \ 符号
path = path.rstrip("\\")
# 判断路径是否存在
# 存在 True
# 不存在 False
isExists = os.path.exists(path)
# 判断结果
if not isExists:
# 如果不存在则创建目录
# 创建目录操作函数
os.makedirs(path)
print(path + ' 创建成功')
return True
else:
# 如果目录存在则不创建,并提示目录已存在
print(path + ' 目录已存在')
return False
if __name__ == "__main__":
IMG_DIR = "./JPEGImages/"
XML_DIR = "./Annotations/"
AUG_XML_DIR = "./AUG/Annotations/" # 存储增强后的XML文件夹路径
try:
shutil.rmtree(AUG_XML_DIR)
except FileNotFoundError as e:
a = 1
mkdir(AUG_XML_DIR)
AUG_IMG_DIR = "./AUG/JPEGImages/" # 存储增强后的影像文件夹路径
try:
shutil.rmtree(AUG_IMG_DIR)
except FileNotFoundError as e:
a = 1
mkdir(AUG_IMG_DIR)
AUGLOOP = 5 # 每张影像增强的数量
boxes_img_aug_list = []
new_bndbox = []
new_bndbox_list = []
# 影像增强
seq = iaa.Sequential([
iaa.Invert(0.5),
iaa.Fliplr(0.5), # 镜像
iaa.Multiply((1.2, 1.5)), # change brightness, doesn't affect BBs
iaa.GaussianBlur(sigma=(0, 3.0)), # iaa.GaussianBlur(0.5),
iaa.Affine(
translate_px={"x": 15, "y": 15},
scale=(0.8, 0.95),
) # translate by 40/60px on x/y axis, and scale to 50-70%, affects BBs
])
for name in tqdm(os.listdir(XML_DIR), desc='Processing'):
bndbox = read_xml_annotation(XML_DIR, name)
# 保存原xml文件
shutil.copy(os.path.join(XML_DIR, name), AUG_XML_DIR)
# 保存原图
og_img = Image.open(IMG_DIR + '/' + name[:-4] + '.jpg')
og_img.convert('RGB').save(AUG_IMG_DIR + name[:-4] + '.jpg', 'JPEG')
og_xml = open(os.path.join(XML_DIR, name))
tree = ET.parse(og_xml)
# 修改增强后的xml文件中的filename
elem = tree.find('filename')
elem.text = (name[:-4] + '.jpg')
tree.write(os.path.join(AUG_XML_DIR, name))
for epoch in range(AUGLOOP):
seq_det = seq.to_deterministic() # 保持坐标和图像同步改变,而不是随机
# 读取图片
img = Image.open(os.path.join(IMG_DIR, name[:-4] + '.jpg'))
# sp = img.size
img = np.asarray(img)
# bndbox 坐标增强
for i in range(len(bndbox)):
bbs = ia.BoundingBoxesOnImage([
ia.BoundingBox(x1=bndbox[i][0], y1=bndbox[i][1], x2=bndbox[i][2], y2=bndbox[i][3]),
], shape=img.shape)
bbs_aug = seq_det.augment_bounding_boxes([bbs])[0]
boxes_img_aug_list.append(bbs_aug)
# new_bndbox_list:[[x1,y1,x2,y2],...[],[]]
n_x1 = int(max(1, min(img.shape[1], bbs_aug.bounding_boxes[0].x1)))
n_y1 = int(max(1, min(img.shape[0], bbs_aug.bounding_boxes[0].y1)))
n_x2 = int(max(1, min(img.shape[1], bbs_aug.bounding_boxes[0].x2)))
n_y2 = int(max(1, min(img.shape[0], bbs_aug.bounding_boxes[0].y2)))
if n_x1 == 1 and n_x1 == n_x2:
n_x2 += 1
if n_y1 == 1 and n_y2 == n_y1:
n_y2 += 1
if n_x1 >= n_x2 or n_y1 >= n_y2:
print('error', name)
new_bndbox_list.append([n_x1, n_y1, n_x2, n_y2])
# 存储变化后的图片
image_aug = seq_det.augment_images([img])[0]
path = os.path.join(AUG_IMG_DIR,
str(str(name[:-4]) + '_' + str(epoch)) + '.jpg')
image_auged = bbs.draw_on_image(image_aug, size=0)
Image.fromarray(image_auged).convert('RGB').save(path)
# 存储变化后的XML
change_xml_list_annotation(XML_DIR, name[:-4], new_bndbox_list, AUG_XML_DIR,
str(name[:-4]) + '_' + str(epoch))
# print(str(str(name[:-4]) + '_' + str(epoch)) + '.jpg')
new_bndbox_list = []
print('Finish!')
建一个新的python文件,命名为img_augmentation.py,放在faster-rcnn.pytorch-pytorch-1.0\data\VOCdevkit2007\VOC2007目录下即可。
用命令python img_augmentation.py运行上述代码,会在VOC2007目录下生成一个AUG文件夹,里面存放好了JPEGImages和Annotations文件夹,如下图所示:
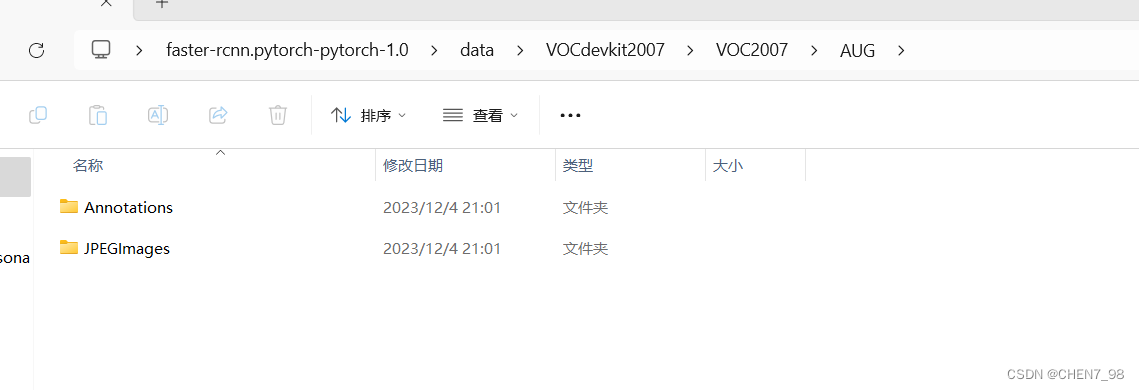
而这两个文件夹则分别存放了包括原图和增强图像在内的2184张图像(384+384×5=2184),具体生成多少张,应用怎么样的增强,可以修改上述代码来实现,这里是对每张原图生成5张增强图像。
2.2 文件存放
正常来说,应该是将增强后的图像单独存放在faster-rcnn.pytorch-pytorch-1.0\data\目录下,并写一个读取该目录的类,但是,最近没啥时间来专门coding了,所以这里为了求快,直接按照以下懒人版方法修改文件即可。
对2.1中生成的AUG文件夹,直接用该文件夹下的JPEGImages和Annotations文件夹替换faster-rcnn.pytorch-pytorch-1.0\data\VOCdevkit2007\VOC2007的JPEGImages和Annotations。
3 数据集划分
建一个新的python文件,命名为img_split.py,放在faster-rcnn.pytorch-pytorch-1.0\data\VOCdevkit2007\VOC2007目录下,代码内容如下所示:
import os
import random
path = './' # 设置path为VOC2007文件夹即可,也就是当前文件夹
trainval_percent = 0.8 # 训练+验证占80%
train_percent = 0.75 # 训练集占训练+验证的75%,也就是0.8×0.75=0.6
xmlfilepath = os.path.join(path, 'Annotations') # xml文件保存地址
txtsavepath = os.path.join(path, 'ImageSets/Main') # txt文件保存地址
total_xml = os.listdir(xmlfilepath) # 解析
original_xml = [f for f in total_xml if f.endswith('.xml') and len(os.path.splitext(f)[0].split('_')) == 2]
# print(original_xml)
num = len(original_xml)
list = range(num)
tv = int(num * trainval_percent)
tr = int(tv * train_percent)
trainval = random.sample(list, tv)
train = random.sample(trainval, tr)
ftrainval = open(os.path.join(txtsavepath, 'trainval.txt'), 'w')
ftest = open(os.path.join(txtsavepath, 'test.txt'), 'w')
ftrain = open(os.path.join(txtsavepath, 'train.txt'), 'w')
fval = open(os.path.join(txtsavepath, 'val.txt'), 'w')
# 获取所有图像文件(原始和增强)
image_files = [f.replace('.xml', '') for f in os.listdir(os.path.join(path, 'JPEGImages')) if f.endswith('.jpg')]
# 用于记录已经写入的图像名
written_images = set()
for i in list:
name = original_xml[i][:-4] # 获取原始图像的文件名,不包括扩展名
# print(name)
if i in trainval:
ftrainval.write(name + '\n')
if i in train:
ftrain.write(name + '\n')
# 找到对应的增强图像并写入训练集
for k in range(0, 5): # 假设每张图像有5次增强
augmented_name = f"{name}_{k}"
if augmented_name not in written_images:
ftrain.write(augmented_name + '\n')
written_images.add(augmented_name)
else:
fval.write(name + '\n')
else:
ftest.write(name + '\n')
ftrainval.close()
ftrain.close()
fval.close()
ftest.close()
用命令python img_split.py运行上述代码,会在faster-rcnn.pytorch-pytorch-1.0\data\VOCdevkit2007\VOC2007\ImageSets\Main\生成划分数据集的txt文件。
注意img_split.py和img_augmentation.py是对应的,可以看到我在img_augmentation.py中对每张图片都增强了5次,所以在img_split.py中也是每次读取原始图像的5个增强图像文件。
为了防止数据泄露,所以在img_split.py中,只用增强后的数据来对模型进行训练,而不用于验证和测试,可以看到在img_split.py中的这几行:
# 只有训练集中添加了增强后的图像
if i in trainval:
ftrainval.write(name + '\n')
if i in train:
ftrain.write(name + '\n')
# 找到对应的增强图像并写入训练集
for k in range(0, 5): # 假设每张图像有5次增强
augmented_name = f"{name}_{k}"
if augmented_name not in written_images:
ftrain.write(augmented_name + '\n')
written_images.add(augmented_name)
else:
fval.write(name + '\n')
else:
ftest.write(name + '\n')
4. 训练&测试
在开始训练之前,还需要把之前训练产生的模型以及cache删除掉,分别在下面三个路径下:
faster-rcnn.pytorch-pytorch-1.0\output\res101\voc_2007_test\faster_rcnn_10\
faster-rcnn.pytorch-pytorch-1.0\data\cache\
faster-rcnn.pytorch-pytorch-1.0\data\VOCdevkit2007\annotations_cache\
之后,参照Faster R-CNN pytorch源码血细胞检测实战(详细版)中即可。
5. 总结
这次代码调试过程还是让我学到了很多的,由于pytorch版Faster RCNN源码的实现和运行比较复杂,因此点到为止,只要求能成功复现实验,并且了解了怎么调参即可,代码的实现细节可以参考其它的开源仓库,据我所知好像mmdetection对Faster RCNN的实现就比较简洁,且易于运行。
![Mybatis-Plus 3.3.2 发布,新增优雅的数据安全保护姿势[MyBatis-Plus系列]](https://img-blog.csdnimg.cn/img_convert/2f2356937db21222bc8858daf57b2793.png)