摘要
提出了一种算法,用于生成任意尺寸卷积核的初始采样坐标。与常规卷积核相比,提出的AKConv实现了不规则卷积核的函数来提取特征,为各种变化目标提供具有任意采样形状和尺寸的卷积核,弥补了常规卷积的不足。在COCO2017和VisDrone-DET2021上进行目标检测实验,并进行了比较实验。结果表明,提出的AKConv方法在目标检测方面具有更好的性能。
在目标检测方面,本文提出的AKConv方法相比常规卷积有以下优势:
- 样本形状的灵活性:常规卷积操作具有固定的样本形状,而AKConv方法可以允许卷积具有任意形状和大小。这种灵活性使得AKConv能够更好地适应形状变化的目标,从而提高目标检测的准确性。
- 参数和计算效率:AKConv方法可以通过调整卷积的大小来减少参数数量和计算量,从而提高模型的效率和性能。相比之下,常规卷积需要更多的参数和计算资源,可能在资源有限的环境下导致模型效率降低。
- 网络性能的优化:AKConv方法可以作为一种轻量级模型替代常规卷积,从而减少模型参数和计算开销,优化网络性能。通过实验验证,使用AKConv的模型在保持性能的同时,能够减少参数和计算量,从而提高网络的效率和泛化能力。
- 扩展性:AKConv方法可以扩展到更大的内核尺寸,从而提供更多的选项来改善网络性能。这种扩展性使得AKConv能够适应不同的应用场景和需求,具有更广泛的适用性。
综上所述,本文提出的AKConv方法在目标检测方面相比常规卷积具有更高的灵活性、参数和计算效率以及网络性能优化等优势。这些优势有助于提高目标检测的准确性和效率,为计算机视觉领域的发展提供新的思路和方法。
论文:《AKConv:具有任意采样形状和任意数目参数的卷积核》
https://arxiv.org/pdf/2311.11587.pdf
基于卷积运算的神经网络在深度学习领域取得了显著的成果,但标准卷积运算存在两个固有缺陷。一方面,卷积运算被限制在一个局部窗口,不能从其他位置捕获信息,并且其采样形状是固定的;另一方面,卷积核的大小是固定为k × k的,它是一个固定的方形形状,参数的数量往往与大小成正比。很明显,在不同的数据集和不同的位置,目标的形状和大小是不同的。具有固定样本形状和正方形的卷积核不能很好地适应不断变化的目标。针对上述问题,本研究探索了可变核卷积(AKConv),它为卷积核提供了任意数量的参数和任意采样形状,为网络开销和性能之间的权衡提供了更丰富的选择。在AKConv中,我们通过一种新的坐标生成算法来定义任意大小的卷积核的初始位置。为了适应目标的变化,我们引入偏移量来调整每个位置的样本形状。此外,我们通过使用相同大小和不同初始采样形状的AKConv来探索神经网络的效果。AKConv通过不规则卷积运算完成了高效的特征提取过程,为卷积采样形状带来了更多的探索选择。在COCO2017、VOC 7+12和VisDrone-DET2021等代表性数据集上的目标检测实验充分展示了AKConv的优势。AKConv可以作为即插即用的卷积运算来替代卷积运算,提高网络性能。相关任务的代码可以在https://github.com/CV-ZhangXin/AKConv上找到。
1、引言
卷积神经网络(CNN),如ResNet [1]、DenseNet [2]和YOLO [3],已经在各种应用中展示了出色的性能,并在现代社会的许多方面引领了技术进步。它已经从自动驾驶汽车中的图像识别[4]和医疗图像分析[5]变得不可或缺,以及智能监控[6]和个性化推荐系统[7]。这些成功的网络模型在很大程度上依赖于卷积操作,有效地提取图像中的局部特征,并确保模型的复杂性。
尽管CNN在分类[8]、目标检测[9]、语义分割[10]等方面取得了许多成功,但它们仍然存在一些局限性。最值得注意的是,关于卷积样本形状和大小的选择。标准的卷积操作往往依赖于具有固定采样位置的正方形内核,例如1×1、3×3、5×5和7×7等。规则内核的采样位置是不可变形的,不能动态地响应目标形状的变化。可变形的卷积[11,12]通过偏移来增强网络性能,以灵活地调整卷积核的采样形状,从而适应目标的变化。例如,[13,14,15]利用它来对齐特征。赵等人[16]通过将其添加到YOLOv4[17]中来改进检测死鱼的有效性。杨等人[18]通过将其添加到主干网络中来改进检测牛的YOLOv8[19]。李等人[20]将可变形卷积引入到深度图像压缩任务中[21,22],以获得内容自适应的接收域。
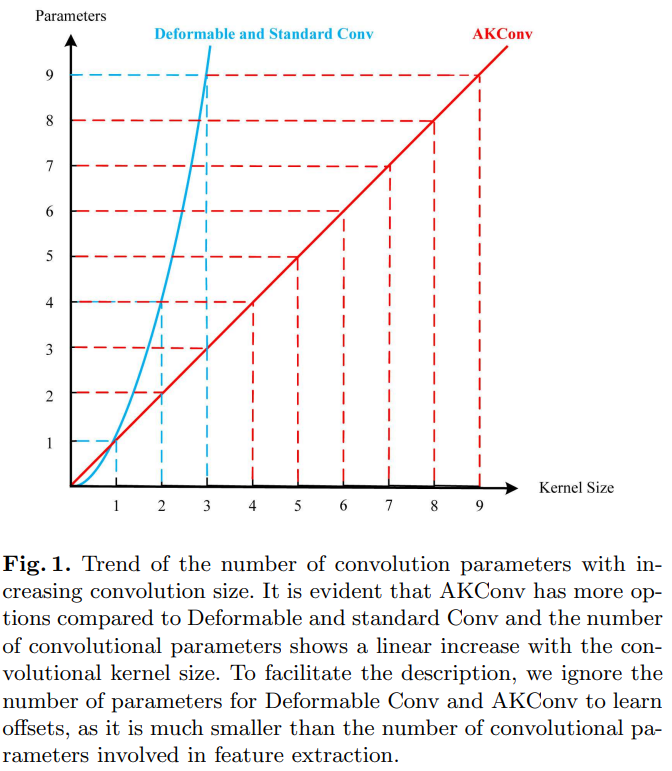
尽管上述研究已经证明了可变形卷积的优越性,但它仍然不够灵活。因为卷积核仍然局限于选择核大小,标准卷积操作和可变形卷积中的卷积核参数数量随着卷积核尺寸的增加呈现出平方增长的趋势,这对硬件环境来说不是一个友好的增长方式。因此,在对标准卷积操作和可变形卷积进行仔细分析后,我们提出了可变核卷积(AKConv)。与标准常规卷积不同,AKConv是一种新型卷积操作,可以使用任何参数数量的有效卷积核提取特征,例如(1,2,3,4,5,6,7…),这是标准卷积和可变形卷积无法实现的。AKConv可以轻松地用于替换网络中的标准卷积操作以提高网络性能。重要的是,AKConv允许卷积参数的数量呈现线性上升或下降的趋势,这对硬件环境是有利的,它可以作为轻量级模型的替代方案来减少模型参数和计算开销。其次,在具有充足资源的条件下,它为大型内核提供了更多提高网络性能的选择。图1显示了常规卷积核使参数数量呈现平方增长趋势,而AKConv仅显示线性增长趋势。与平方增长趋势相比,AKConv增长较为平缓,为卷积核的选择提供了更多选项。此外,其思想可以扩展到特定领域。因为可以根据先验知识为卷积操作创建特殊的采样形状,然后通过偏移动态地自动适应目标形状的变化。
在代表性的数据集VOC [23]、COCO2017 [24]、VisDrone-DET2021 [25]上进行的目标检测实验充分证明了AKConv的优势。总的来说,我们的贡献如下:
- 对于不同大小的卷积核,我们提出了一种算法,用于生成任意大小卷积核的初始采样坐标。
- 为了适应目标的不同变化,我们通过获得的偏移量来调整不规则卷积核的采样位置。
- 与常规卷积核相比,所提出的AKConv实现了不规则卷积核提取特征的功能,为各种变化的目标提供了具有任意采样形状和大小的卷积核,弥补了常规卷积的不足之处。
2、相关工作
近年来,许多作品从不同的角度考虑和分析标准卷积操作,并设计新型卷积操作以提高网络性能。
Li等人[26]认为,卷积核在所有空间位置共享参数会导致模型在各个空间位置上的建模能力有限,并且不能有效地捕捉空间上的长距离关系。其次,为每个输出通道使用不同的卷积核的方法实际上效率不高。因此,为了解决这些不足,他们提出了倒置卷积操作,该操作反转了卷积操作的特征以改善网络性能。Qi等人[27]基于可变形卷积提出了DSConv。从可变形卷积中学习的偏移量具有自由性,导致模型损失一小部分精细结构特征,这对于分割细长的管状结构任务构成了巨大挑战,因此他们提出了DSConv。Zhang等人[28]从新的角度理解了空间注意力机制。他们断言,空间注意力机制本质上解决了卷积操作参数字典共享的问题。但是,一些空间注意力机制,如CBAM[29]和CA[30],并未完全解决大尺寸卷积参数字典共享的问题。因此,他们提出了RFAConv。Chen等人[31]提出了动态卷积。与在每一层使用卷积核不同,动态卷积根据注意力动态聚合多个并行卷积核。动态卷积提供了更大的特征表示。Tan等人[32]认为,在CNN中,核大小经常被忽视,这可能影响网络的准确性和效率。其次,仅使用逐层卷积并不能充分利用卷积网络的全部潜力。因此,他们提出了MixConv,该操作在单个卷积中自然地混合多个核大小以改善网络性能。
尽管这些方法提高了卷积运算的性能,但它们仍然局限于常规卷积运算,不允许卷积采样形状的多种变化。相反,我们所提出的AKConv能够有效地使用具有任意数量参数和采样形状的卷积核来提取特征。
3、方法
3.1、定义初始采样位置
卷积神经网络基于卷积运算,通过规则的采样网格将特征定位到相应位置。在[11, 33, 34]中给出了 3 × 3 3 \times 3 3×3卷积运算的规则采样网格。让 R \mathrm{R} R 表示采样网格,则 R \mathrm{R} R 表示如下:
R = { ( − 1 , − 1 ) , ( − 1 , 0 ) , … , ( 0 , 1 ) , ( 1 , 1 ) } (1) R=\{(-1,-1),(-1,0), \ldots,(0,1),(1,1)\} \tag{1} R={(−1,−1),(−1,0),…,(0,1),(1,1)}(1)
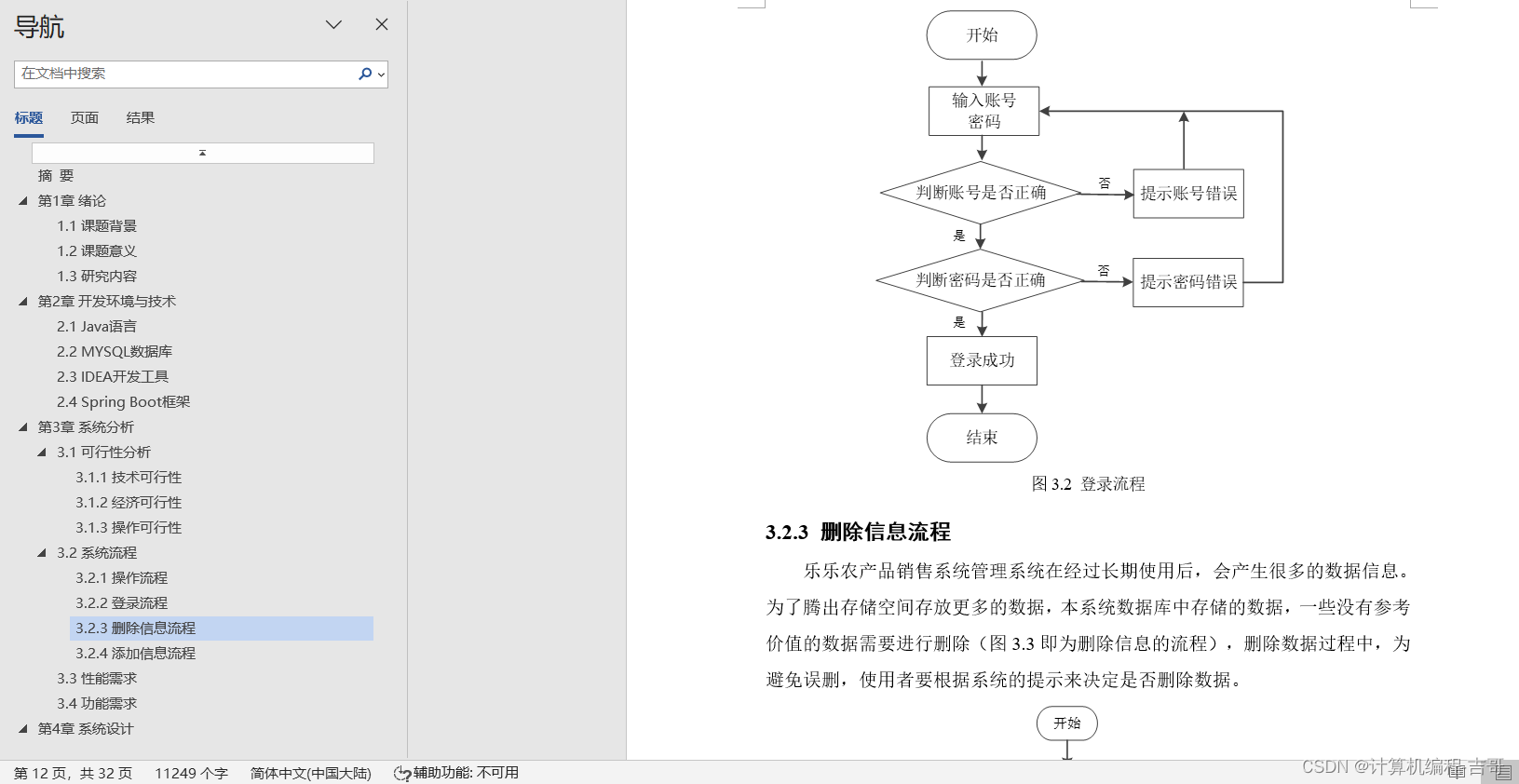
但是,采样网格是规则的,而AKConv的目标是不规则形状的卷积核。因此,为了让不规则卷积核具有采样网格,我们创建了任意大小卷积的算法来生成卷积核的初始采样坐标 P_{n}。首先,我们生成规则的采样网格,然后创建剩余采样点的不规则网格,最后将它们拼接起来以生成整个采样网格。伪代码如下算法1所示。

如图2所示,它显示了任意大小卷积的初始采样坐标的生成。规则卷积的采样网格以点 (0,0) 为中心。而不规则卷积没有许多尺寸的中心,为了适应所使用的卷积尺寸,我们在算法中将左上角点 (0,0) 设置为采样原点。
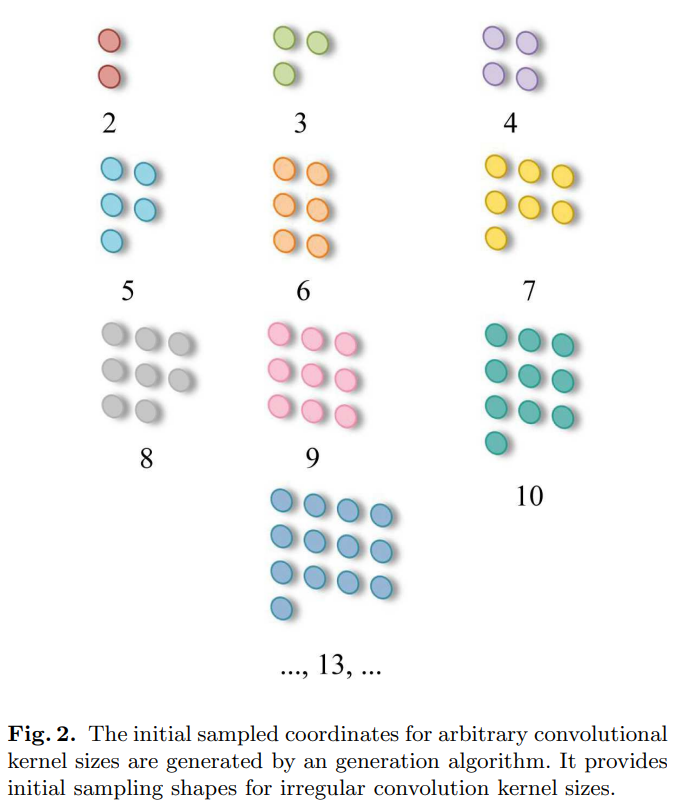
定义了不规则卷积的初始坐标 P_{n} 后,在位置 P_{0} 处的相应卷积操作可以定义如下:
Conv
(
P
0
)
=
∑
w
×
(
P
0
+
P
n
)
(2)
\operatorname{Conv}\left(P_{0}\right)=\sum w \times\left(P_{0}+P_{n}\right) \tag{2}
Conv(P0)=∑w×(P0+Pn)(2)
这里,w 表示卷积参数。然而,不规则卷积操作是不可能实现的,因为不规则采样坐标无法与相应大小的卷积操作相匹配,例如大小为 5、7 和 13 的卷积。巧妙的是,我们提出的 AKConv 实现了这一点。
3.2、可变卷积操作
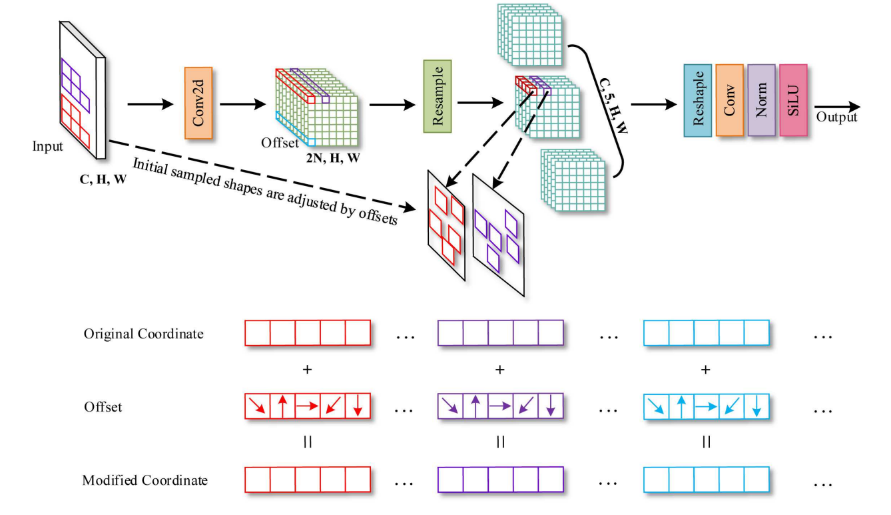
很明显,标准卷积的采样位置是固定的,这导致卷积只能提取当前窗口的局部信息,而无法捕捉其他位置的信息。可变形卷积通过卷积操作学习偏移量来调整初始规则模式的采样网格。该方法在一定程度上弥补了卷积操作的缺点。然而,标准卷积和可变形卷积都是规则的采样网格,不允许具有任意数量参数的卷积核。此外,随着卷积核大小的增加,它们的卷积参数数量趋于平方增长,这对硬件环境并不友好。因此,我们提出了一个新型的可变卷积操作(AKConv)。如图3所示,它展示了大小为5的AKConv的整体结构。
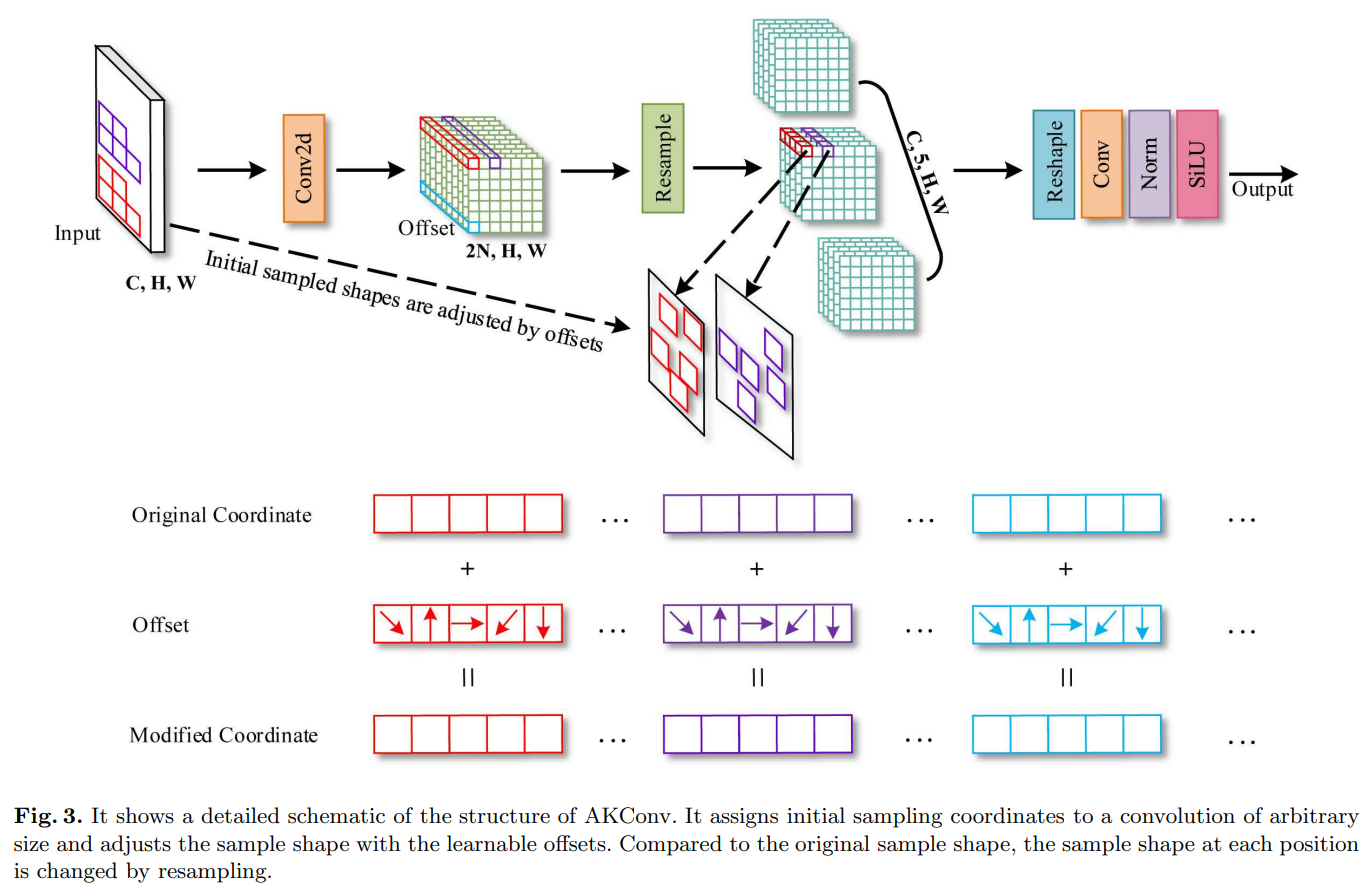
类似于可变形卷积,在AKConv中,相应核的偏移量首先通过卷积运算获得,其具有维度 ( B , 2 N , H , W ) (\mathrm{B}, 2 \mathrm{~N}, \mathrm{H}, \mathrm{W}) (B,2 N,H,W),其中 N \mathrm{N} N 是卷积核大小。以图3为例, N = 5 \mathrm{N}=5 N=5。然后通过将偏移量和原始坐标相加得到修改后的坐标 ( P 0 + P n ) (P_{0}+P_{n}) (P0+Pn)。最后通过插值和重新采样得到相应位置的特征。提取不规则卷积核采样位置的特征是困难的。为了解决这个问题,我们发现经过深入思考后有很多方法来解决这个问题。在可变形卷积[11]和RFAConv[28]中,他们在空间维度上堆叠了 3 × 3 3 \times 3 3×3 卷积特征。然后使用步长为3的卷积操作来提取特征。然而,这种方法针对的是方形采样形状。因此,可以将特征堆叠在行上或列上,以使用列卷积或行卷积提取与不规则采样形状相对应的特征。提取的特征将使用适当大小和步长的卷积核。此外,我们可以将特征转换为四个维度 ( C , N , H , W ) (\mathrm{C}, \mathrm{N}, \mathrm{H}, \mathrm{W}) (C,N,H,W) ,然后使用步长和卷积大小为 (N, 1,1) 的Conv3d来提取特征。当然,我们还可以将特征堆叠在通道维度上,以 ( C N , H , W ) (\mathrm{CN}, \mathrm{H}, \mathrm{W}) (CN,H,W),然后使用 1 × 1 1 \times 1 1×1 卷积将维度减少到 ( C , H , W ) (\mathrm{C}, \mathrm{H}, \mathrm{W}) (C,H,W)。因此,上述所有方法都可以提取与不规则采样形状相对应的特征。只需要重新调整特征的形状并使用相应的卷积操作即可。因此,在图3中,“Reshape”和“Conv”的最终表示可以是上述任何一种方法。此外,为了清楚地展示AKConv的过程,在图3中进行重新采样后,我们将与卷积相对应的特征维度放在了第三个维度。但在代码实现时,它位于最后一个维度。
在RFAConv和Deformable Conv之后,我们将重采样的特征按列方向进行叠加,然后使用大小为(N, 1),步长为(N, 1)的行卷积。因此,AKConv可以很好地完成不规则卷积特征提取过程。AKConv通过不规则卷积完成特征提取过程,可以根据偏移量灵活调整样本形状,为卷积采样形状带来更多的探索选择。与标准卷积和可变形卷积不同,它们受到正则卷积核思想的限制。
3.3、扩展AKConv
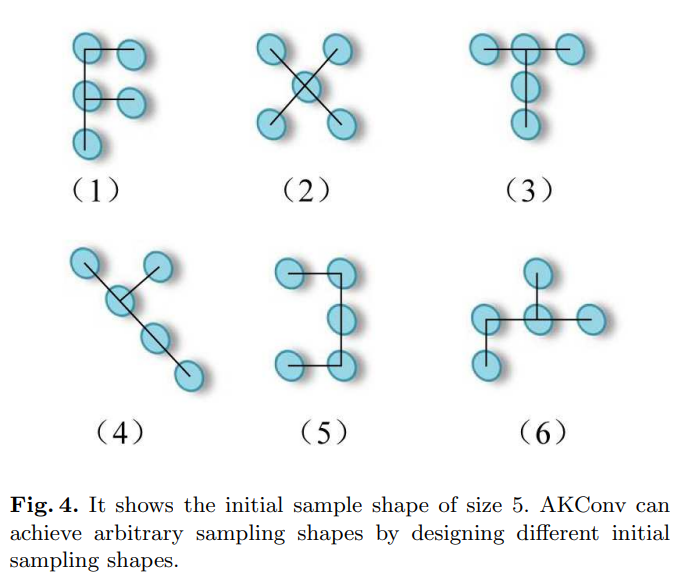
我们认为AKConv的设计是一种新颖的设计,它完成了从不规则和任意采样形状卷积核中提取特征的壮举。即使没有使用可变形卷积中的偏移量思想,AKConv仍然可以使卷积核形状多样化。因为AKConv可以对初始坐标进行重新采样以呈现出各种变化。如图4所示,我们为大小为5的卷积设计了各种初始采样形状。在图4中,我们只展示了大小为5的一些示例。但是,AKConv的大小可以是任意的,因此随着大小的增加,AKConv的初始卷积采样形状变得更加丰富,甚至无限。鉴于目标形状因数据集而异,设计对应于采样形状的卷积操作至关重要。AKConv通过根据相位特化域设计具有相应形状的卷积操作而充分实现。它也可以类似于可变形卷积,通过添加一个可学习的偏移量来动态适应目标的变化。对于特定任务,卷积核初始采样位置的设计是重要的,因为它是一种先验知识。正如Qi等人[27]提出的那样,他们为细长管状结构分割任务提出了具有相应形状的采样坐标,但他们的形状选择仅适用于细长管状结构。
4、实验
为了验证AKConv的优势,我们分别在先进的YOLOv5 [35]、YOLOv7 [36]和YOLOv8 [19]上进行了丰富的目标检测实验。实验中所有的模型都是基于RTX3090进行训练的。为了验证AKConv的优势,我们在代表性的COCO2017、VOC 7+12和VisDroneDET2021数据集上进行了相关实验。
4.1、在COCO2017上的目标检测实验
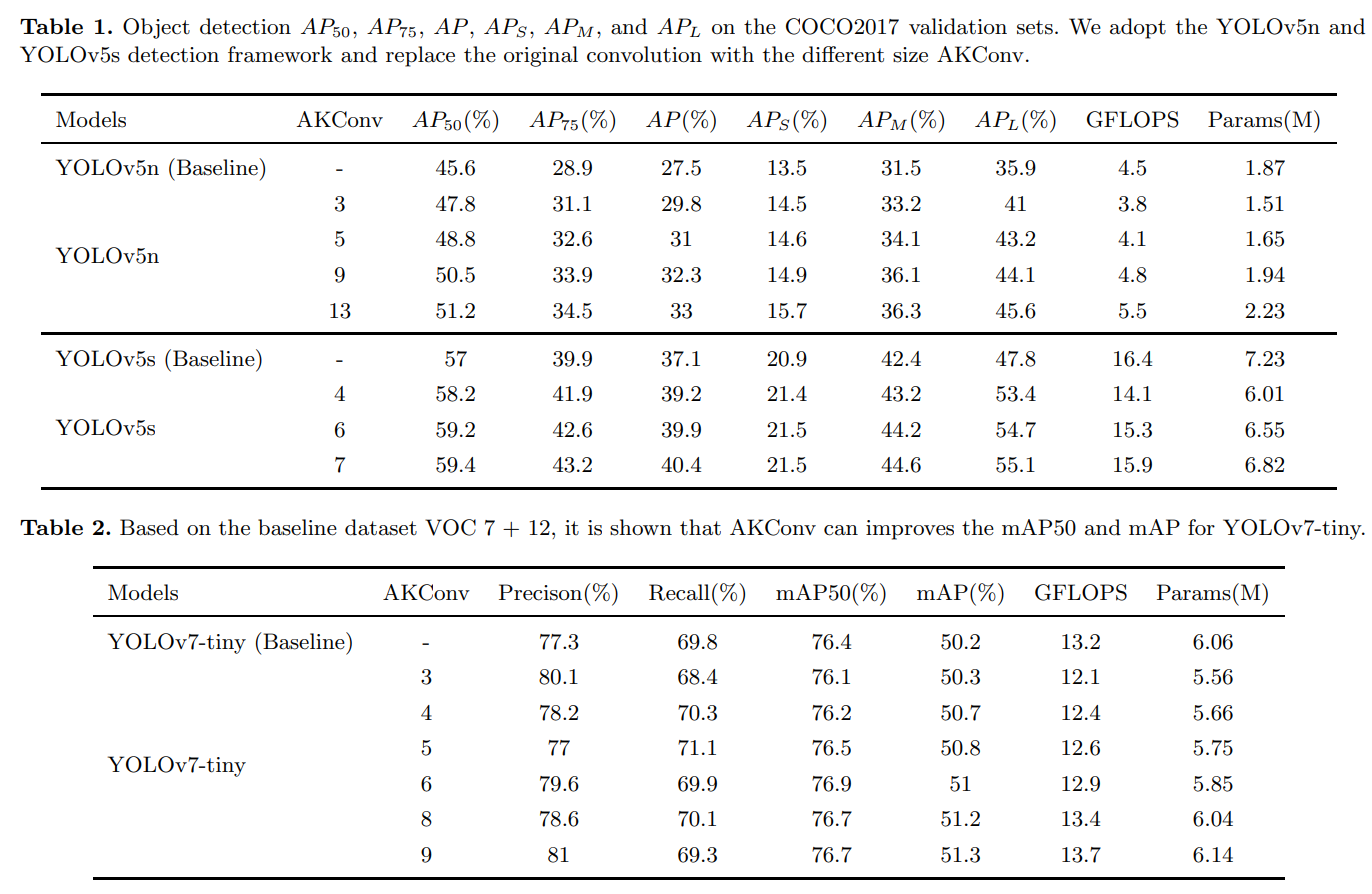
COCO2017包括训练集(118287张图片)和验证集(5000张图片),涵盖了80个目标类别。它已成为计算机视觉研究领域,尤其是目标检测领域的一项标准数据集。我们选择YOLOv5n和YOLOv5s作为基准模型,它们是目标检测领域的先进模型。然后,使用不同大小的AKConv来替换YOLOv5n和YOLOv5s的卷积操作。替换的细节与[28]中的目标检测实验相同。在实验中,除了epoch和batch-size参数外,默认使用网络的参数。在batch size为32的情况下,我们对每个模型训练了300个epochs。遵循以前的工作,我们报告了AP50、AP75、AP、APs、APm和APl。此外,我们还分别报告了使用大小为5、4、6、7、9和13的AKConv在YOLOv5n和YOLOv5s上的目标检测结果。如表1所示,YOLOv5的检测精度随着卷积核尺寸的增加而逐渐提高,但模型所需的参数数量和计算量也逐渐增加。与标准卷积操作相比,AKConv显著提高了YOLOv5在COCO2017上的目标检测性能。可以看出,当AKConv的大小为5时,它不仅使模型所需的参数数量和计算量减少,而且显著提高了YOLOv5n的AP50、AP75和AP,均提高了三个百分点,这是非常出色的。AKConv提高了基线模型的APs、APm和APl,但很明显,与小、中物体相比,AKConv显著提高了大物体的检测精度。我们断言,AKConv使用偏移量更好地适应大物体的形状。
4.2、在VOC 7+12上的目标检测实验
为了进一步验证我们的方法,我们在VOC 7+12数据集上进行了实验,该数据集是VOC2007和VOC2012的组合,包括16551个训练集和4952个验证集,涵盖20个目标类别。为了测试AKConv在不同架构上的泛化能力,我们选择了YOLOv7-tiny作为基准模型。由于YOLOv7和YOLOv5采用不同的架构,因此可以比较不同架构设置的AKConv的性能。在YOLOv7-tiny中,我们使用不同大小的AKConv来替换标准卷积操作。替换的细节遵循[28]中的工作。所有模型的超参数设置与前一节中的一致。如表2所示,随着AKConv大小的增加,网络的检测精度逐渐提高,而模型的参数数量和计算量也逐渐增加。这些实验进一步证实了AKConv的优势。
4.3、在VisDrone-DET2021上的目标检测实验
为了再次验证AKConv具有很强的泛化能力,我们基于VisDrone-DET2021数据集进行了相关的目标检测实验。VisDrone-DET2021是一个具有挑战性的数据集,由无人机在不同环境、天气和光照条件下拍摄而成。它是中国最大的无人机航拍图像数据集之一,涵盖范围最广。训练集数量为6471个,验证集数量为548个。与第4.1节一样,我们选择YOLOv5n作为基准模型,使用AKConv来替换网络中的卷积操作。实验中,将batchsize设置为16,以方便探索更大的卷积尺寸,而所有其他超参数设置与之前相同。如表3所示,很明显,基于不同大小的AKConv可以用作轻量级选项,以减少参数数量和计算量,并提高网络性能。实验中,当AKConv的大小设置为3时,与基准模型相比,模型的检测性能下降,但相应的参数数量和计算开销要小得多。此外,我们可以逐渐调整AKConv的大小来探索网络性能的变化。AKConv为网络带来了更丰富的选项。
4.4、比较实验
与可变形的Conv [11]不同,AKConv提供了更丰富的网络选择。AKConv弥补了可变形Conv的不足,可变形Conv只使用常规卷积操作,而AKConv可以使用常规和非常规卷积操作。当AKConv的大小设置为K的平方时,AKConv变成可变形的Conv。此外,DSConv [27]还使用偏移量来调整采样形状,但其采样形状是为管状目标设计的,并且采样形状的变化是有限的。为了对比AKConv、可变形Conv和DSConv的优点,我们在YOLOv5s和YOLOv5n的基础上在COCO2017和VOC 7+12上进行实验。如表4和表5所示。当卷积核参数的数量为9时(即标准的3 3卷积),可以看出AKConv和可变形Conv的性能相同。因为当卷积核大小规则时,AKConv就是可变形Conv。但是,我们之前提到过,可变形Conv没有探索非常规的卷积核大小。因此,不能实现参数数量为5和11的卷积操作。在设计AKConv时,我们没有对输入特征进行零填充。然而,在可变形Conv中使用了填充。因此,为了公平比较,在AKConv中我们也对输入特征进行零填充。实验表明,在AKConv中零填充有助于网络提高性能。由于DSConv是专为特定的管状形状设计的,因此可以看出其在COCO2017和VOC 7+12上的检测性能并不明显。在实现DSConv时,[27]将特征向行或列扩展,并最终使用列卷积或列卷积来提取与我们的方法相似的特征。因此,他们的方法也可以实现参数为2、3、4、5、6、7等的卷积操作。在同一规模下,我们也进行了比较实验。因为DSConv没有完成下采样方法,在实验中,我们使用AKConv和DSConv来替代YOLOv5n中的C3中的3 × 3卷积。实验结果如表4和表5所示。AKConv优于DSConv,因为DSConv不是为了提高任意大小的卷积核的性能而设计的,而是为了探索特定形状的目标。相比之下,AKConv提供了丰富的卷积核选择和探索选项,可以有效提高网络性能。
4.5、探索初始采样形状
如前所述,AKConv可以通过使用任意大小和任意采样形状来提取特征。为了探索AKConv与不同的初始采样形状在网络上的效果,我们在COCO2017和VisDrone-DET2021上分别进行了实验。在COCO2017上,我们在批量大小为32和每个周期为100的情况下进行了实验。在VisDrone-DET2021上,我们在批量大小为16和每个周期为300的情况下进行了实验。所有其他超参数都是网络默认值。在COCO2017中,我们选择YOLOv8n进行实验。如表6所示,AKConv仍然可以提高网络的检测精度。YOLOv8和YOLOv5的网络结构相似。区别在于C3和C2f的设计。可以看出,与在YOLOv5中添加AKConv相比,在YOLOv8中添加AKConv的性能提升不如YOLOv5。我们认为,在相同大小下,YOLOv8需要的参数比YOLOv5多,因此更多的参数可以提供更好的特征信息,就像AKConv一样。因此,随着AKConv的加入,YOLOv8的提升不如YOLOv5明显。此外,在相同大小下,我们在COCO2017上测试了不同初始采样形状对网络性能的影响。很明显,在不同的初始样本下,网络获得的检测精度的波动并不大。这得益于COCO2017的大量数据可以灵活地调整偏移量。但这并不意味着网络在所有初始采样坐标下获得的检测精度没有显著差异。为了再次探索AKConv与不同初始形状对网络的影响,我们在基于YOLOv5n的实验中探索了大小为5的AKConv以及不同的初始样本在VisDrone-DET2021上的效果。从表7中可以看出,网络在不同的初始样本下具有不同的检测精度。因此,具有不同初始采样形状的AKConv对网络性能有影响。此外,对于特定的网络和数据集,探索具有适当初始采样形状的AKConv以改善网络性能是很重要的。
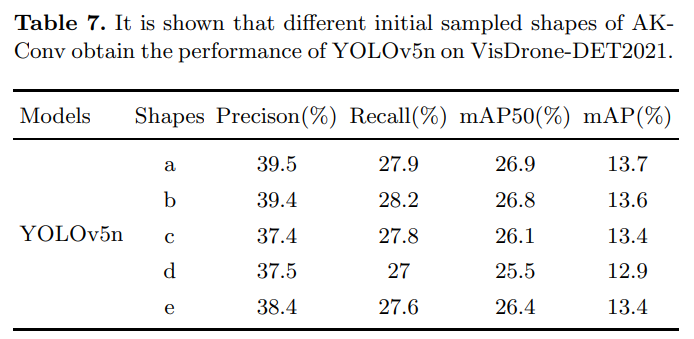
5、分析讨论
我们在之前的实验中初步观察了大小为5的AKConv在不同采样位置下YOLOv5n的检测性能。可以清楚地注意到,网络在具有不同初始采样形状时表现不同。这表明偏移量的调整能力也是有限的。为了衡量每个给定位置的偏移量的变化,我们给出了平均偏移量的定义,定义如下:
A
O
=
(
∑
i
2
N
∣
O
f
f
set
i
∣
)
/
(
2
N
)
(3)
A O=\left(\sum_{i}^{2 N}\left|O f f \operatorname{set}_{i}\right|\right) /(2 N) \tag{3}
AO=(i∑2N∣Offseti∣)/(2N)(3)
AO(平均偏移量)是通过将偏移量相加并取平均值来衡量每个位置采样点的平均变化程度。为了观察偏移量的变化,我们选择了训练好的网络,并选择了AKConv的最后一层来分析偏移量的整体变化趋势。为了进行分析,我们随机选择了VisDrone-DET2021中的四张图像,然后可视化了大小为5的初始不同采样位置的AKConv。如图5所示,我们可视化了每个采样位置的偏移量的变化程度。图5中不同的颜色表示训练后不同初始样本在每个采样位置的偏移量的变化。线条的颜色对应于中间的初始采样形状。图5中不同的初始样本形状对应于表7中的初始样本形状。可以得出结论,图5中蓝色和红色的初始样本形状的变化较小。这意味着红色和蓝色的初始样本比其他初始样本更适合此数据集。如表7中的实验所示,与红色和蓝色相对应的初始采样形状获得了更好的检测精度。所有实验都证明了AKConv能够给网络带来显著的性能改进。与可变形的Conv不同,AKConv具有基于大小的灵活性来扩展网络性能。在所有实验中,我们广泛探索了大小为5的AKConv。因为在用大量数据训练COCO2017时,我们发现将AKConv的大小设置为5时,训练速度与原始模型相差不大。此外,随着AKConv大小的增加,训练时间逐渐增加。在COCO2017、VOC 7+12和VisDrone-DET2021的实验中,将AKConv的大小设置为5在网络中取得了良好的结果。当然,探索其他大小的AKConv是可能的,因为显示线性增长和任意采样形状的参数数量为AKConv的探索带来了丰富的选择。AKConv可以实现任意大小和任意样本的卷积操作,并可以通过偏移量自动调整样本形状以适应目标变化。所有实验都证明,AKConv提高了网络性能,并为网络开销和性能之间的权衡提供了更丰富的选择。
6、结论
显然,在现实生活和计算机视觉领域中,物体的形状存在各种变化。卷积运算的固定样本形状无法适应这些变化。尽管可变形的Conv可以通过偏移量的调整灵活改变卷积的样本形状,但它仍然存在局限性。因此,我们提出了AKConv,它真正实现了允许卷积具有任意样本形状和大小,为卷积核的选择提供了多样性。此外,对于不同的领域,我们可以设计特定的初始采样坐标形状来满足实际需求。虽然在本论文中,我们仅针对大小为5的AKConv设计了多种采样坐标形状。但是,AKConv的灵活性在于它可以针对任何采样核大小来提取信息。因此,未来我们希望针对特定任务探索适当大小和采样形状的AKConv,这将对后续任务产生推动力。
RT-DERT官方测试结果
Class Images Instances Box(P R mAP50 mAP50-95): 100%|██████████| 15/15 [00:02<00:00, 5.36it/s]
all 230 1412 0.882 0.907 0.93 0.667
c17 230 131 0.945 0.926 0.986 0.794
c5 230 68 0.857 0.881 0.949 0.783
helicopter 230 43 0.951 0.907 0.954 0.573
c130 230 85 0.985 0.976 0.983 0.658
f16 230 57 0.827 0.924 0.925 0.631
b2 230 2 0.963 1 0.995 0.553
other 230 86 0.86 0.788 0.884 0.464
b52 230 70 0.889 0.943 0.942 0.779
kc10 230 62 0.971 0.984 0.985 0.82
command 230 40 1 0.958 0.995 0.759
f15 230 123 0.952 0.968 0.99 0.688
kc135 230 91 0.976 0.911 0.941 0.662
a10 230 27 0.892 0.914 0.907 0.419
b1 230 20 0.749 0.95 0.936 0.614
aew 230 25 0.921 0.938 0.95 0.739
f22 230 17 0.891 0.965 0.99 0.703
p3 230 105 1 0.945 0.967 0.768
p8 230 1 0.798 1 0.995 0.647
f35 230 32 0.903 0.872 0.951 0.496
f18 230 125 0.946 0.944 0.95 0.78
v22 230 41 0.983 0.927 0.99 0.645
su-27 230 31 0.924 0.968 0.992 0.833
il-38 230 27 0.986 0.926 0.981 0.736
tu-134 230 1 0.794 1 0.995 0.895
su-33 230 2 0 0 0 0
an-70 230 2 0.861 1 0.995 0.796
tu-22 230 98 0.996 0.969 0.994 0.788
Speed: 0.3ms preprocess, 5.3ms inference, 0.0ms loss, 0.5ms postprocess per image
改进方法
从官方的源码中得到AKConv的源码,对源码做一些校正,代码如下:
import torch
import torch.nn as nn
import torch.nn.functional as F
import math
import einops
class AKConv(nn.Module):
def __init__(self, inc, outc, num_param, stride=1, bias=None):
super(AKConv, self).__init__()
self.num_param = num_param
self.stride = stride
self.conv = nn.Sequential(nn.Conv2d(inc, outc, kernel_size=(num_param, 1), stride=(num_param, 1), bias=bias)
,nn.BatchNorm2d(outc)
,nn.SiLU()) # the conv adds the BN and SiLU to compare original Conv in YOLOv5.
self.p_conv = nn.Conv2d(inc, 2 * num_param, kernel_size=3, padding=1, stride=stride)
nn.init.constant_(self.p_conv.weight, 0)
self.p_conv.register_full_backward_hook(self._set_lr)
@staticmethod
def _set_lr(module, grad_input, grad_output):
grad_input = (grad_input[i] * 0.1 for i in range(len(grad_input)))
grad_output = (grad_output[i] * 0.1 for i in range(len(grad_output)))
def forward(self, x):
# N is num_param.
offset = self.p_conv(x)
dtype = offset.data.type()
N = offset.size(1) // 2
# (b, 2N, h, w)
p = self._get_p(offset, dtype)
# (b, h, w, 2N)
p = p.contiguous().permute(0, 2, 3, 1)
q_lt = p.detach().floor()
q_rb = q_lt + 1
q_lt = torch.cat([torch.clamp(q_lt[..., :N], 0, x.size(2) - 1), torch.clamp(q_lt[..., N:], 0, x.size(3) - 1)],
dim=-1).long()
q_rb = torch.cat([torch.clamp(q_rb[..., :N], 0, x.size(2) - 1), torch.clamp(q_rb[..., N:], 0, x.size(3) - 1)],
dim=-1).long()
q_lb = torch.cat([q_lt[..., :N], q_rb[..., N:]], dim=-1)
q_rt = torch.cat([q_rb[..., :N], q_lt[..., N:]], dim=-1)
# clip p
p = torch.cat([torch.clamp(p[..., :N], 0, x.size(2) - 1), torch.clamp(p[..., N:], 0, x.size(3) - 1)], dim=-1)
# bilinear kernel (b, h, w, N)
g_lt = (1 + (q_lt[..., :N].type_as(p) - p[..., :N])) * (1 + (q_lt[..., N:].type_as(p) - p[..., N:]))
g_rb = (1 - (q_rb[..., :N].type_as(p) - p[..., :N])) * (1 - (q_rb[..., N:].type_as(p) - p[..., N:]))
g_lb = (1 + (q_lb[..., :N].type_as(p) - p[..., :N])) * (1 - (q_lb[..., N:].type_as(p) - p[..., N:]))
g_rt = (1 - (q_rt[..., :N].type_as(p) - p[..., :N])) * (1 + (q_rt[..., N:].type_as(p) - p[..., N:]))
# resampling the features based on the modified coordinates.
x_q_lt = self._get_x_q(x, q_lt, N)
x_q_rb = self._get_x_q(x, q_rb, N)
x_q_lb = self._get_x_q(x, q_lb, N)
x_q_rt = self._get_x_q(x, q_rt, N)
# bilinear
x_offset = g_lt.unsqueeze(dim=1) * x_q_lt + \
g_rb.unsqueeze(dim=1) * x_q_rb + \
g_lb.unsqueeze(dim=1) * x_q_lb + \
g_rt.unsqueeze(dim=1) * x_q_rt
x_offset = self._reshape_x_offset(x_offset, self.num_param)
out = self.conv(x_offset)
return out
# generating the inital sampled shapes for the AKConv with different sizes.
def _get_p_n(self, N, dtype):
base_int = round(math.sqrt(self.num_param))
row_number = self.num_param // base_int
mod_number = self.num_param % base_int
p_n_x ,p_n_y = torch.meshgrid(
torch.arange(0, row_number),
torch.arange(0 ,base_int))
p_n_x = torch.flatten(p_n_x)
p_n_y = torch.flatten(p_n_y)
if mod_number > 0:
mod_p_n_x ,mod_p_n_y = torch.meshgrid(
torch.arange(row_number ,row_number +1),
torch.arange(0 ,mod_number))
mod_p_n_x = torch.flatten(mod_p_n_x)
mod_p_n_y = torch.flatten(mod_p_n_y)
p_n_x ,p_n_y = torch.cat((p_n_x ,mod_p_n_x)) ,torch.cat((p_n_y ,mod_p_n_y))
p_n = torch.cat([p_n_x ,p_n_y], 0)
p_n = p_n.view(1, 2 * N, 1, 1).type(dtype)
return p_n
# no zero-padding
def _get_p_0(self, h, w, N, dtype):
p_0_x, p_0_y = torch.meshgrid(
torch.arange(0, h * self.stride, self.stride),
torch.arange(0, w * self.stride, self.stride))
p_0_x = torch.flatten(p_0_x).view(1, 1, h, w).repeat(1, N, 1, 1)
p_0_y = torch.flatten(p_0_y).view(1, 1, h, w).repeat(1, N, 1, 1)
p_0 = torch.cat([p_0_x, p_0_y], 1).type(dtype)
return p_0
def _get_p(self, offset, dtype):
N, h, w = offset.size(1) // 2, offset.size(2), offset.size(3)
# (1, 2N, 1, 1)
p_n = self._get_p_n(N, dtype)
# (1, 2N, h, w)
p_0 = self._get_p_0(h, w, N, dtype)
p = p_0 + p_n + offset
return p
def _get_x_q(self, x, q, N):
b, h, w, _ = q.size()
padded_w = x.size(3)
c = x.size(1)
# (b, c, h*w)
x = x.contiguous().view(b, c, -1)
# (b, h, w, N)
index = q[..., :N] * padded_w + q[..., N:] # offset_x*w + offset_y
# (b, c, h*w*N)
index = index.contiguous().unsqueeze(dim=1).expand(-1, c, -1, -1, -1).contiguous().view(b, c, -1)
x_offset = x.gather(dim=-1, index=index).contiguous().view(b, c, h, w, N)
return x_offset
# Stacking resampled features in the row direction.
@staticmethod
def _reshape_x_offset(x_offset, num_param):
b, c, h, w, n = x_offset.size()
x_offset = einops.rearrange(x_offset, 'b c h w n -> b c (h n) w')
return x_offset
AKConv第二个参数是卷积核的大小,可以设置为:3、4、5、6、7、8、9、10、11等,不再限制为奇数。不过过大的卷积核会占用很大的显存。
测试结果
Class Images Instances Box(P R mAP50 mAP50-95): 100%|██████████| 15/15 [00:04<00:00, 3.72it/s]
all 230 1412 0.902 0.937 0.951 0.688
c17 230 131 0.95 0.969 0.989 0.79
c5 230 68 0.881 0.853 0.885 0.734
helicopter 230 43 0.928 0.902 0.961 0.6
c130 230 85 0.956 0.976 0.975 0.667
f16 230 57 0.945 0.906 0.94 0.647
b2 230 2 0.601 1 0.995 0.539
other 230 86 0.88 0.851 0.871 0.435
b52 230 70 0.958 0.929 0.925 0.768
kc10 230 62 0.948 0.984 0.986 0.806
command 230 40 0.956 1 0.995 0.805
f15 230 123 0.903 0.987 0.988 0.683
kc135 230 91 0.895 0.934 0.942 0.681
a10 230 27 0.793 0.741 0.694 0.324
b1 230 20 0.984 0.95 0.948 0.625
aew 230 25 0.873 1 0.992 0.8
f22 230 17 0.934 1 0.989 0.7
p3 230 105 0.979 0.952 0.967 0.752
p8 230 1 0.77 1 0.995 0.716
f35 230 32 0.878 0.938 0.938 0.51
f18 230 125 0.938 0.984 0.983 0.8
v22 230 41 0.949 0.976 0.992 0.656
su-27 230 31 0.915 1 0.993 0.826
il-38 230 27 0.931 0.992 0.993 0.756
tu-134 230 1 0.825 1 0.995 0.796
su-33 230 2 1 0.5 0.75 0.6
an-70 230 2 0.844 1 0.995 0.796
tu-22 230 98 0.939 0.98 0.991 0.762
还是有涨点的!
总结
本文尝试使用最新的卷积AKConv改进RT-DERT,从实验的结果来看还是不错的。大家可以在自己的数据集上做尝试。
代码和PDF版本的文章链接: