前言
OpenAI的创始人之一,大神Andrej Karpthy刚在微软Build 2023开发者大会上做了专题演讲:State of GPT(GPT的现状)。
他详细介绍了如何从GPT基础模型一直训练出ChatGPT这样的助手模型(assistant model)。作者不曾在其他公开视频里看过类似的内容,这或许是OpenAI官方第一次详细阐述其大模型内部原理和RLHF训练细节。
难能可贵的是,Andrej不仅深入了细节, 还高屋建瓴的抽象了大模型实现中的诸多概念,牛人的洞察就是不一样。
比如,Andrej非常形象的把当前LLM大语言模型比喻为人类思考模式的系统一(快系统),这是相对于反应慢但具有更长线推理的系统二(慢系统)而言。这只是演讲里诸多闪光点的其中一个。
并且,Andrej真的有当导师的潜力,把非常技术的内容讲得深入浅出,而又异常透彻。这个演讲完全可以让非专业人士也能理解,并且,认真看完演讲后会有一种醍醐灌顶的感觉。
本次演讲的精校完整中文版视频的B站传送门: https://www.bilibili.com/video/BV1ts4y1T7UH
他将整个报告分为了两个部分,分别是GPT是如何训练的,以及该如何用GPT。
GPT是如何训练

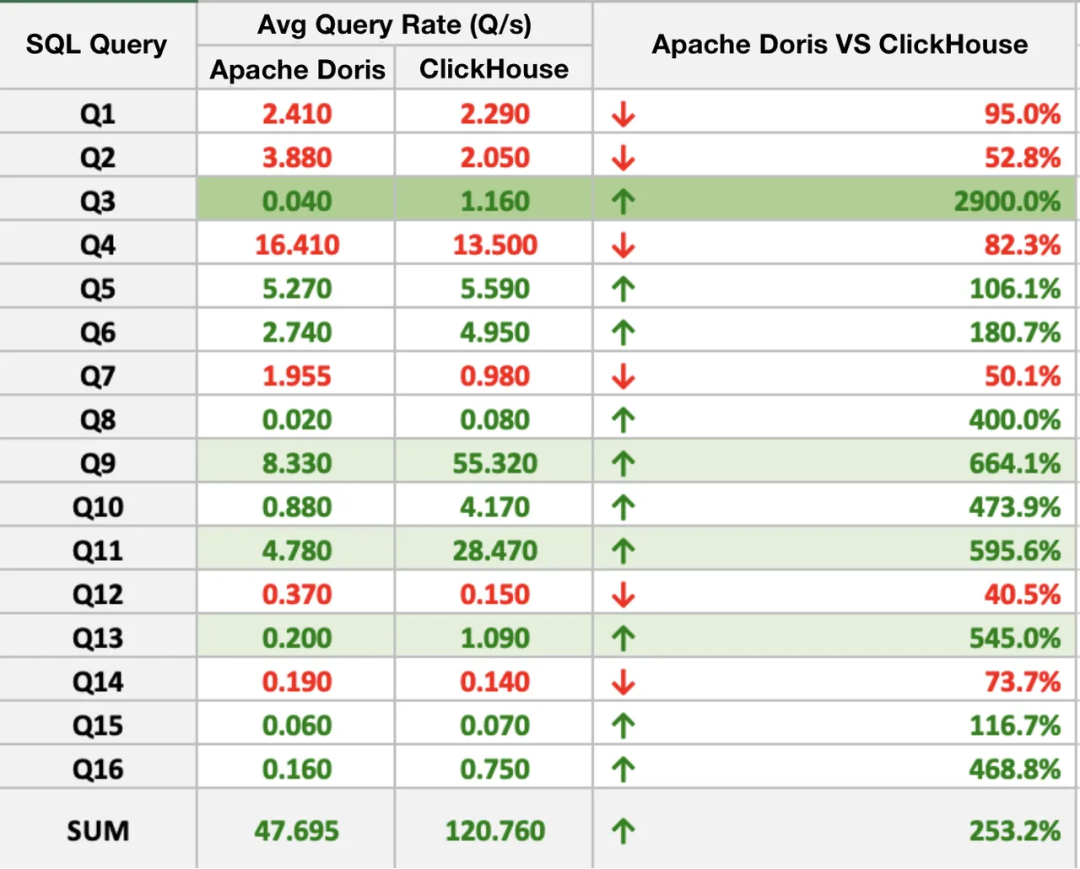
这节的主要内容其实都是围绕着这个图中的概念来的,从左边开始到右边描述了gpt在训练过程中的4个阶段,通常来说是四个阶段预训练(Pretraining),有监督的微调(Supervised Finetuning),奖励建模(Reward Modeling)和强化学习(Reinforcement Learning),这几个阶段通常是依次进行,每个阶段都有不同的数据集。
这里从第一个阶段:预训练阶段开始说起,这个阶段使用大量的文本对模型进行预训练,消耗了99%的训练资源,需要数千GPU训练几个月(其他几个阶段只用了1%资源,一般是数个gpu训练几天就可以)。
预训练阶段
这个阶段首先需要准备大量的数据,下图是引用了llama中使用了哪些数据。

可以大致看到进入这些集合的数据集的种类,我们有common crawl这只是一个网络爬取,C4也是common crawl,然后还有一些高质量的数据集。例如,GitHub、维基百科、书籍、ArXiv论文存档、StackExchange问答网站等。这些都混合在一起,然后根据给定的比例进行采样,形成 GPT 神经网络的训练集。
下载完这些数据之后,并不能直接使用他们进行训练,计算机是无法识别的,需要首先做一下tokenization,将单词转化为token,这个过程如下图所示,最后的结果是每一个单词(或单词的一部分)都会被一个数字编号所代替,所有单词会形成一个词典,数字编号就是词典中的序号。

接下来开始准备一个transformer的模型,Andrej以GPT3和LLaMA作为例子如下图
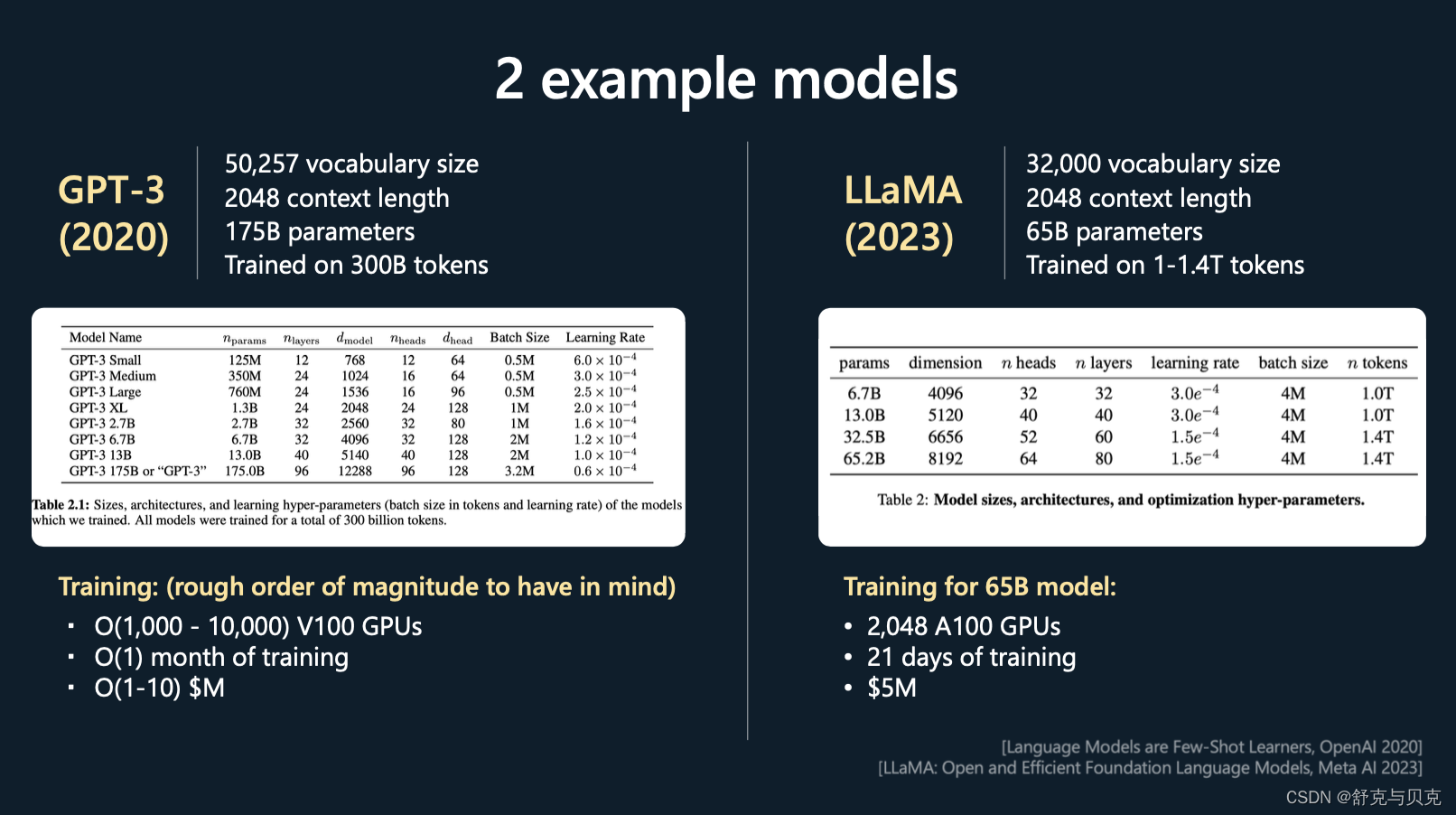
这里针对几个超参数进行一下描述:
- vocabulary size:表示上一张图中筹备的词典有多少个
- context length:表示训练时一次性能输入的文本的长度是多少,意味着超过这个长度就无法记忆了
- parameter:表示transformer的参数数量
- Trained on XXX tokens:表示训练时一共看过多少token,可以认为是训练iteration * context length * batch size
这些大致是在进行预训练时要处理的数量级:词汇量通常是几万个标记。上下文长度通常是 2,000、4,000,现在甚至是 100,000,这决定了 GPT 在尝试预测序列中的下一个整数时将查看的最大整数数。
你可以看到,Llama 的参数数量大概是 650 亿。现在,尽管与 GPT3 的 1750 亿个参数相比,Llama 只有 65 个 B 参数,但 Llama 是一个明显更强大的模型,直观地说,这是因为该模型的训练时间明显更长,训练了1.4 万亿标记而不是 3000 亿标记。所以你不应该仅仅通过模型包含的参数数量来判断模型的能力。
这里我展示了一些粗略的超参数表,这些超参数通常用于指定 Transformer 神经网络。比如头的数量,尺寸大小,层数等等。
在底部,展示了一些训练超参数。例如,为了训练 65 B 模型,Meta 使用了 2,000 个 GPU,大约训练了 21 天,大约花费了数百万美元。
现在,当我们实际进行预训练时&#