【数学建模】《实战数学建模:例题与讲解》第十讲-时间序列预测(含Matlab代码)
- 基本概念
- 移动平均(Moving Average, MA):
- 指数平滑法(Exponential Smoothing):
- 季节性调整(Seasonal Adjustment):
- 自回归移动平均模型(ARMA):
- 自回归积分滑动平均模型(ARIMA):
- 习题8.4
- 1. 题目要求
- 2.解题过程
- 3.程序
- 4.结果
- 习题8.5
- 1. 题目要求
- 2.解题过程
- 3.程序
- 4.结果
- 习题8.6
- 1. 题目要求
- 2.解题过程
- 3.程序
- 4.结果
本系列侧重于例题实战与讲解,希望能够在例题中理解相应技巧。文章开头相关基础知识只是进行简单回顾,读者可以搭配课本或其他博客了解相应章节,然后进入本文例题实战,效果更佳。
如果这篇文章对你有帮助,欢迎点赞与收藏~

基本概念
时间序列预测是一种预测方法,它通过将观察对象按照时间顺序排列,构成一个所谓的“时间序列”。通过分析这些时间序列过去的变化规律,可以推断未来的可能变化、趋势和规律。这种方法实际上是一种回归模型,其基本原理有两个方面:一是承认事物发展的延续性,即通过分析过去时间序列的数据来预测事物的发展趋势;二是考虑到偶然因素的影响所带来的随机性。为了减少随机波动的影响,需要利用历史数据进行统计分析,并对数据进行适当处理以进行趋势预测。
时间序列预测法的优点在于其简单易行,易于掌握,能够充分利用原时间序列的数据,计算速度快,并且对模型参数具有动态确定的能力。此外,精度较高,特别是当采用组合时间序列或将时间序列与其他模型组合时,其效果更佳。然而,这种方法也有其局限性,主要是不能反映事物的内在联系,无法分析两个因素之间的相关关系,更适用于短期而非长期预测。
时间序列预测法在各个领域都有广泛的应用,如在金融市场分析、气象预测、工业生产和库存管理等领域。在实际应用中,时间序列预测通常涉及到多种技术和方法,如移动平均、指数平滑法、季节性调整、自回归移动平均模型(ARMA)、自回归积分滑动平均模型(ARIMA)等。这些技术各有特点,适用于不同类型的数据和不同的预测需求。
移动平均(Moving Average, MA):
特点: 简单、直观。
原理: 根据一定数量的连续过去数据点的平均值来预测未来的值。它有助于平滑时间序列中的短期波动,并突出长期趋势。
适用性: 最适合没有明显趋势和季节性的数据。
指数平滑法(Exponential Smoothing):
特点: 对最近的观测值给予更多的权重。
原理: 这种方法给过去的观测值赋予指数递减的权重,最近的数据点有更大的权重。简单指数平滑适用于没有趋势和季节性的数据,而双重和三重指数平滑法可以处理趋势和季节性。
适用性: 适用于具有或不具有趋势和季节性的数据。
季节性调整(Seasonal Adjustment):
特点: 专注于季节性因素。
原理: 通过消除季节性波动来更清晰地识别趋势。这通常是通过识别并调整那些周期性重复出现的模式来完成的。
适用性: 对于具有明显季节性模式的数据特别有效。
自回归移动平均模型(ARMA):
特点: 结合自回归(AR)和移动平均(MA)。
原理: AR部分利用过去值之间的关系,而MA部分则建模时间序列的误差项。这种模型假设时间序列是平稳的(即均值、方差和协方差不随时间变化)。
适用性: 适合处理平稳的时间序列。
自回归积分滑动平均模型(ARIMA):
特点: ARMA模型的扩展,可以处理非平稳数据。
原理: 结合差分(使非平稳数据平稳)的概念与ARMA模型。它通过一定次数的差分,将非平稳时间序列转化为平稳时间序列。
适用性: 可以处理非平稳时间序列,适合广泛类型的时间序列数据。
习题8.4
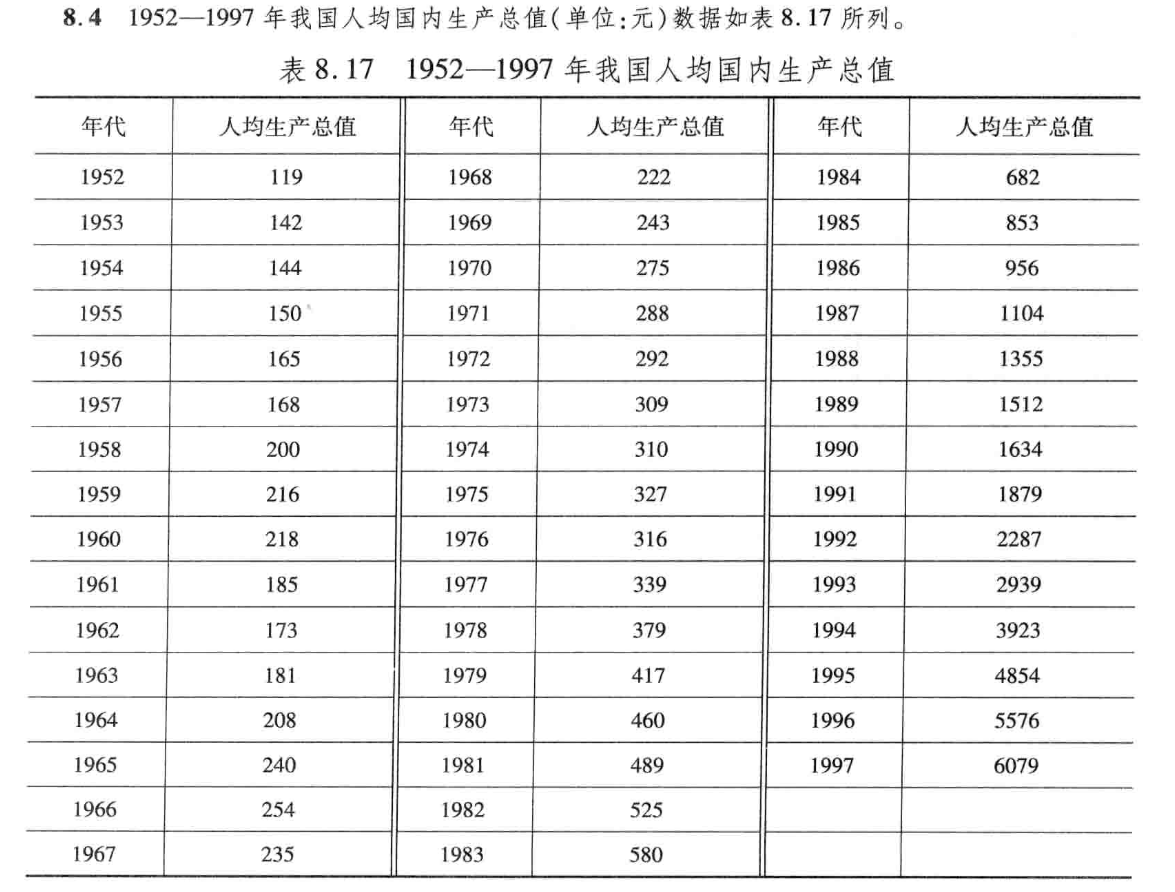
1. 题目要求

2.解题过程
解:
原始数据序列: x t {x_t} xt ,一阶差分变换后的序列为: y t y_t yt 。
(1)通过下文中程序的运行,我们可以从运行结果中得到
y
t
=
1.253
y
t
−
1
−
0.3522
y
t
−
2
+
ε
t
+
0.5022
ε
t
−
1
y_t = 1.253y_{t-1} - 0.3522y_{t-2} + \varepsilon_{t} + 0.5022 \varepsilon_{t-1}
yt=1.253yt−1−0.3522yt−2+εt+0.5022εt−1
(2)根据下文的运算结果得到未来10年的预测值分别为::
6419.44740352031
6668.77039934881
6861.19145947359
7014.42501092823
7138.60914121919
7240.20495400936
7323.73568451267
7392.59199500092
7449.42827658915
7496.37548147182
6419.44740352031 \\ 6668.77039934881\\ 6861.19145947359\\ 7014.42501092823\\ 7138.60914121919\\ 7240.20495400936\\ 7323.73568451267\\ 7392.59199500092\\ 7449.42827658915\\ 7496.37548147182
6419.447403520316668.770399348816861.191459473597014.425010928237138.609141219197240.204954009367323.735684512677392.591995000927449.428276589157496.37548147182
3.程序
求解的MATLAB程序如下:
clc, clear
format long g
% 定义列向量 xt,其中包含了原始数据的时间序列。
xt = [119, 142, 144, 150, 165, 168, 200, ...
216, 218, 185, 173, 181, 208, 240, 254, ...
235, 222, 243, 275, 288, 292, 309, 310, 327, ...
316, 339, 379, 417, 460, 489, 525, 580, 682, ...
853, 956, 1104, 1355, 1512, 1634, 1879, ...
2287, 2939, 3923, 4854, 5576, 6079]';
% 进行一阶差分变换,即计算 xt 中相邻元素之间的差值,生成一个新的列向量 yt
% 一阶差分变换可以将非平稳时间序列转换为平稳时间序列。
yt = diff(xt);
% 拟合arma模型
m = armax(yt, [2, 1])
% armax函数接受两个参数:时间序列数据和模型阶数[p,q],其中p是自回归项的数量,q是滞后误差项的数量
% 计算yt的10期预测值
ythat = forecast(m, yt, 10);
% 计算原始数据的10期预测值
% 这一行代码用于计算原始数据 xt 的预测值
% xt(end)表示原始数据的最后一个观测值,cumsum(ythat)表示将ythat中每个元素累加得到的新的列向量
xthat = xt(end) + cumsum(ythat)
4.结果
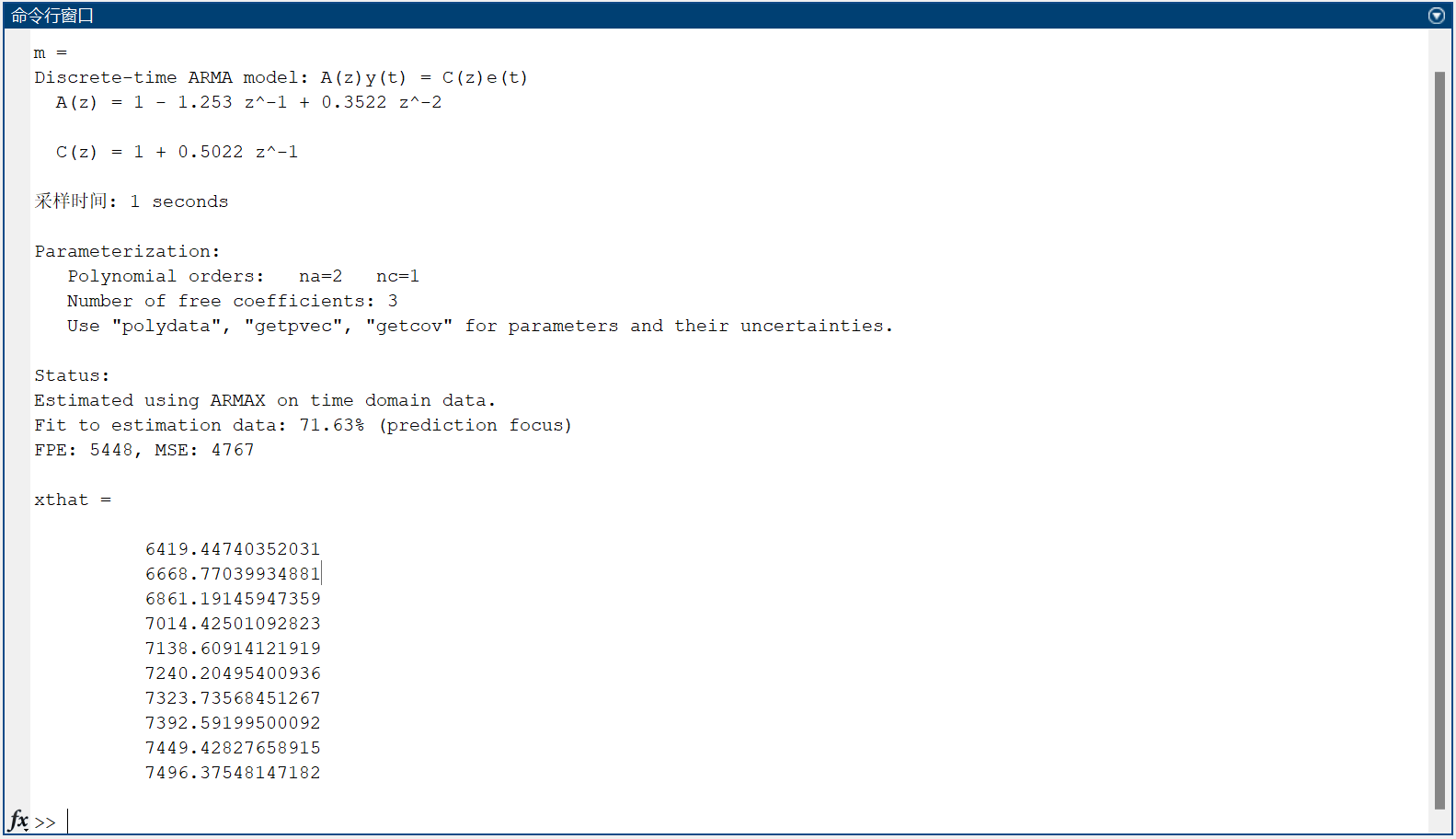
(1)我们可以从运行结果中得到
y
t
=
1.253
y
t
−
1
−
0.3522
y
t
−
2
+
ε
t
+
0.5022
ε
t
−
1
y_t = 1.253y_{t-1} - 0.3522y_{t-2} + \varepsilon_{t} + 0.5022 \varepsilon_{t-1}
yt=1.253yt−1−0.3522yt−2+εt+0.5022εt−1
(2)未来10年的预测值分别为::
6419.44740352031
6668.77039934881
6861.19145947359
7014.42501092823
7138.60914121919
7240.20495400936
7323.73568451267
7392.59199500092
7449.42827658915
7496.37548147182
6419.44740352031 \\ 6668.77039934881\\ 6861.19145947359\\ 7014.42501092823\\ 7138.60914121919\\ 7240.20495400936\\ 7323.73568451267\\ 7392.59199500092\\ 7449.42827658915\\ 7496.37548147182
6419.447403520316668.770399348816861.191459473597014.425010928237138.609141219197240.204954009367323.735684512677392.591995000927449.428276589157496.37548147182
习题8.5
1. 题目要求
2.解题过程
解:
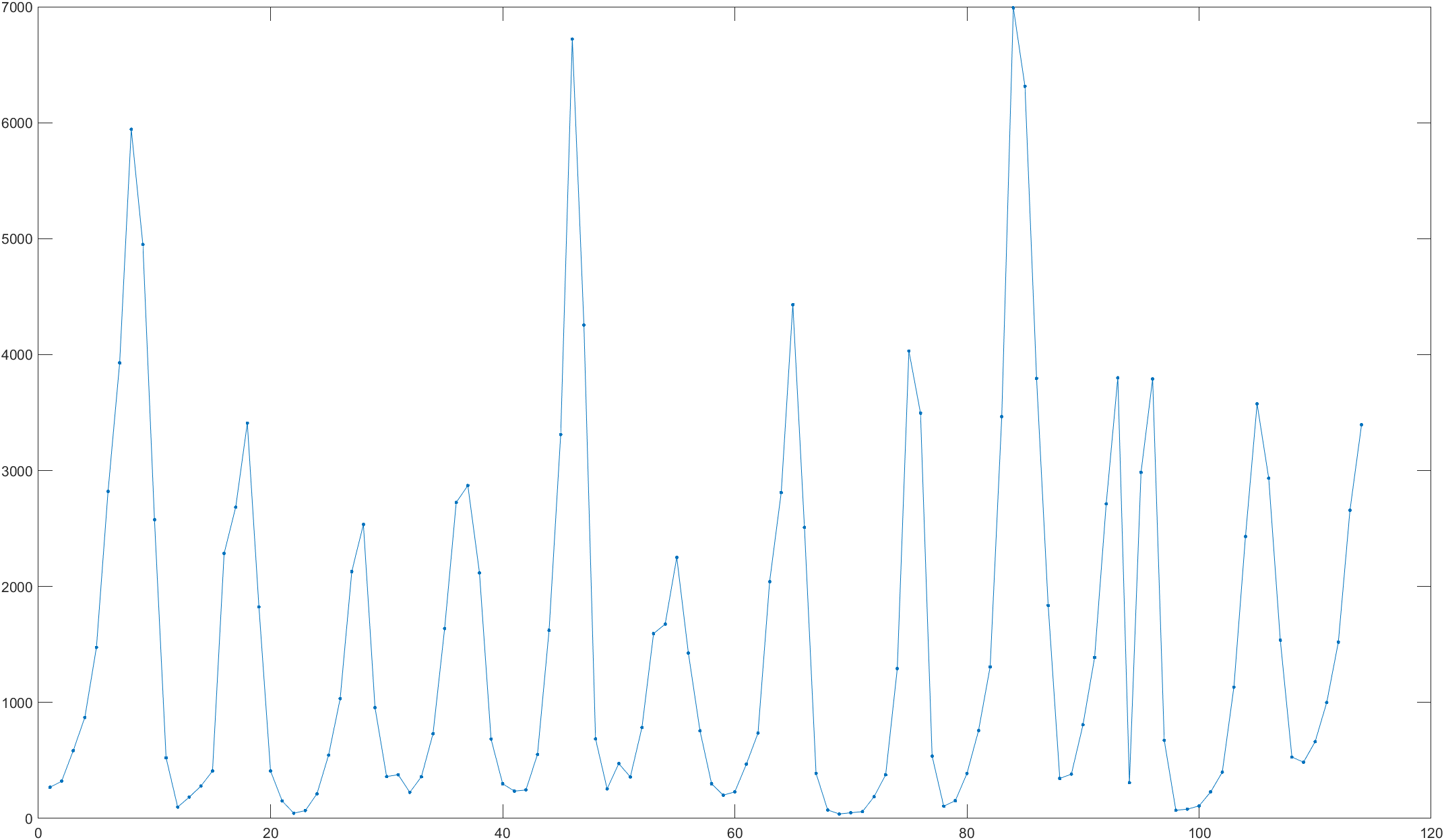
(1)序列时序图
记原始序列为 { x t {x_t} xt} ,序列时序图如下图所示,时序图显示该序列大致具有12个周期变化,周期的长度为9或10年,下面使用周期 T=10行计算。
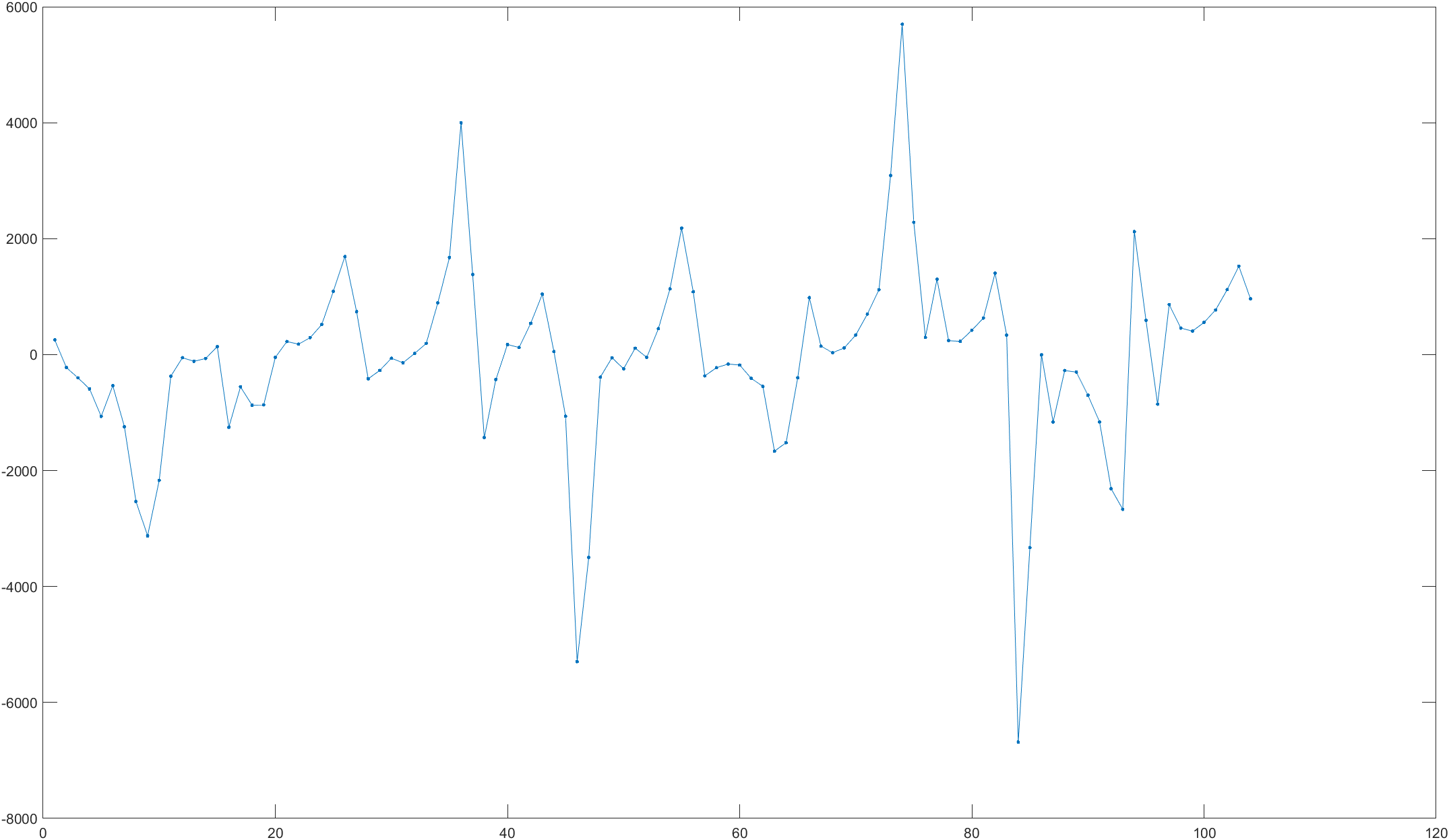
(2)差分平稳
对原序列做10步差分,消除季节趋势,得到序列 { y t y_t yt} ,其中, y t = x t + 10 − x t y_t = x_{t+10}-x_t yt=xt+10−xt,差分后序列图如下图所示。时序图显示差分后序列基本平稳了。
(3)模型拟合
根据差分后序列的自相关和偏自相关的性质,尝试拟合ARMA模型,拟合的ARMA (1,10) 模型较理想,并且通过了白噪声检验,说明低阶的ARMA模型不适合拟合这个序列。
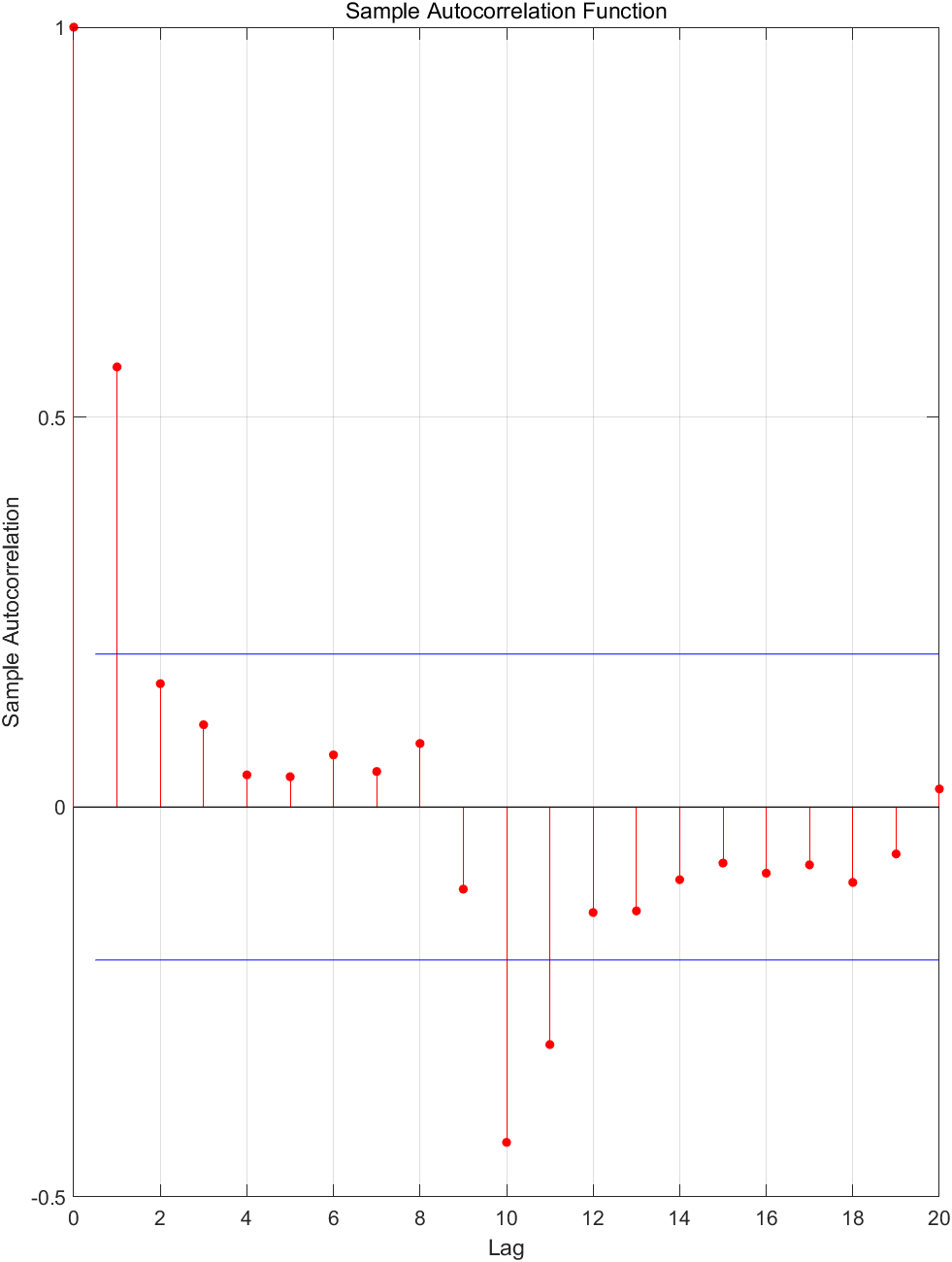
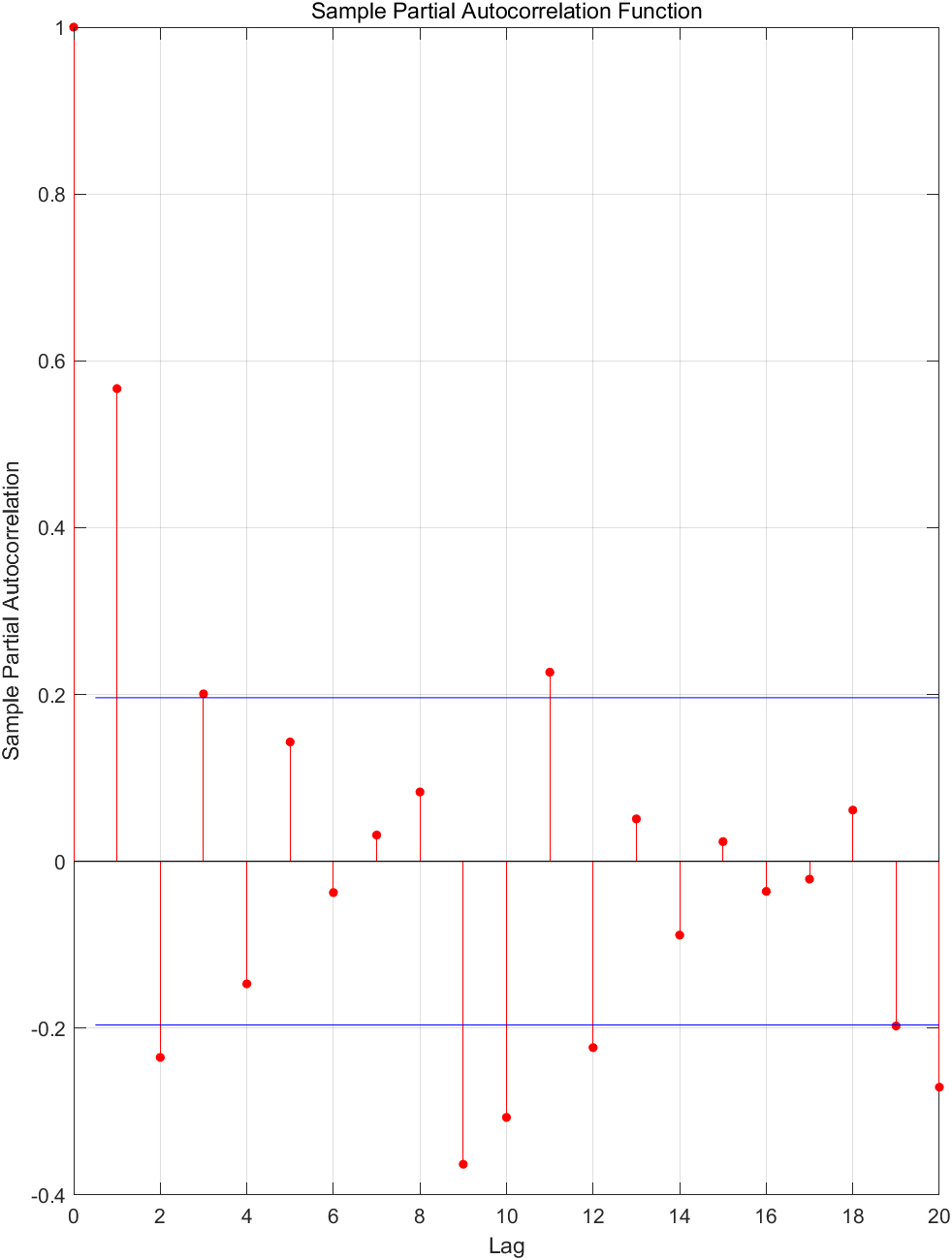
(4)
求预测值。求得下两个年度的预测值为4310和3674。
3.程序
求解的MATLAB程序如下:
clc, clear
format long g
a = [269, 321, 585, 871, 1475, 2821, 3928, 5943, 4950, ...
2577, 523, 98, 184, 279, 409, 2285, 2685, 3409, 1824, ...
409, 151, 45, 68, 213, 546, 1033, 2129, 2536, 957, ...
361, 377, 225, 360, 731, 1638, 2725, 2871, 2119, 684, ...
299, 236, 245, 552, 1623, 3311, 6721, 4254, 687, 255, ...
473, 358, 784, 1594, 1676, 2251, 1426, 756, 299, 201, ...
229, 469, 736, 2042, 2811, 4431, 2511, 389, 73, 39, 49, ...
59, 188, 377, 1292, 4031, 3495, 537, 105, 153, 387, 758, ...
1307, 3465, 6991, 6313, 3794, 1836, 345, 382, 808, ...
1388, 2713, 3800, 309, 2985, 3790, 674, 71, 80, 108, ...
229, 399, 1132, 2432, 3575, 2935, 1537, 529, 485, 662, ...
1000, 1520, 2657, 3396]';
n = length(a);
% 用MATLAB的plot函数绘制a的图像
plot(a, '.-')
% 使用for循环遍历从第11个到最后一个数据元素,并对前10个数据元素和当前数据元素进行差分计算得到一个新的列向量b
for i = 11:n
b(i-10) = a(i) - a(i-10); % 进行季节差分变换
end
b = b';
figure, plot(b, '.-')
% 计算b的自相关性和偏自相关性
figure, subplot(121), autocorr(b)
subplot(122), parcorr(b)
% 对b序列进行模型拟合
cs = armax(b, [1, 10]); % 拟合模型
figure, myres = resid(cs, b); % 计算残差向量并画出残差的自相关函数图
% 拟合模型的残差向量myres
[h, p, st] = lbqtest(myres.outputdata, 'lags', [6, 12, 18]); % 进行LBQ检验
% 注意,上面outputdata一定要加上,不然会报错
bhat = forecast(cs, b, 2); % 计算b的2期预测值
ahat = a(end-9:end-8) + bhat % 求原始序列的2期预测值
4.结果

后两个年度的预测值为4310和3674
习题8.6
1. 题目要求
2.解题过程
解:
(1)对所给时间序列建模
首先对此序列进行观察分析。下图为数据曲线图:
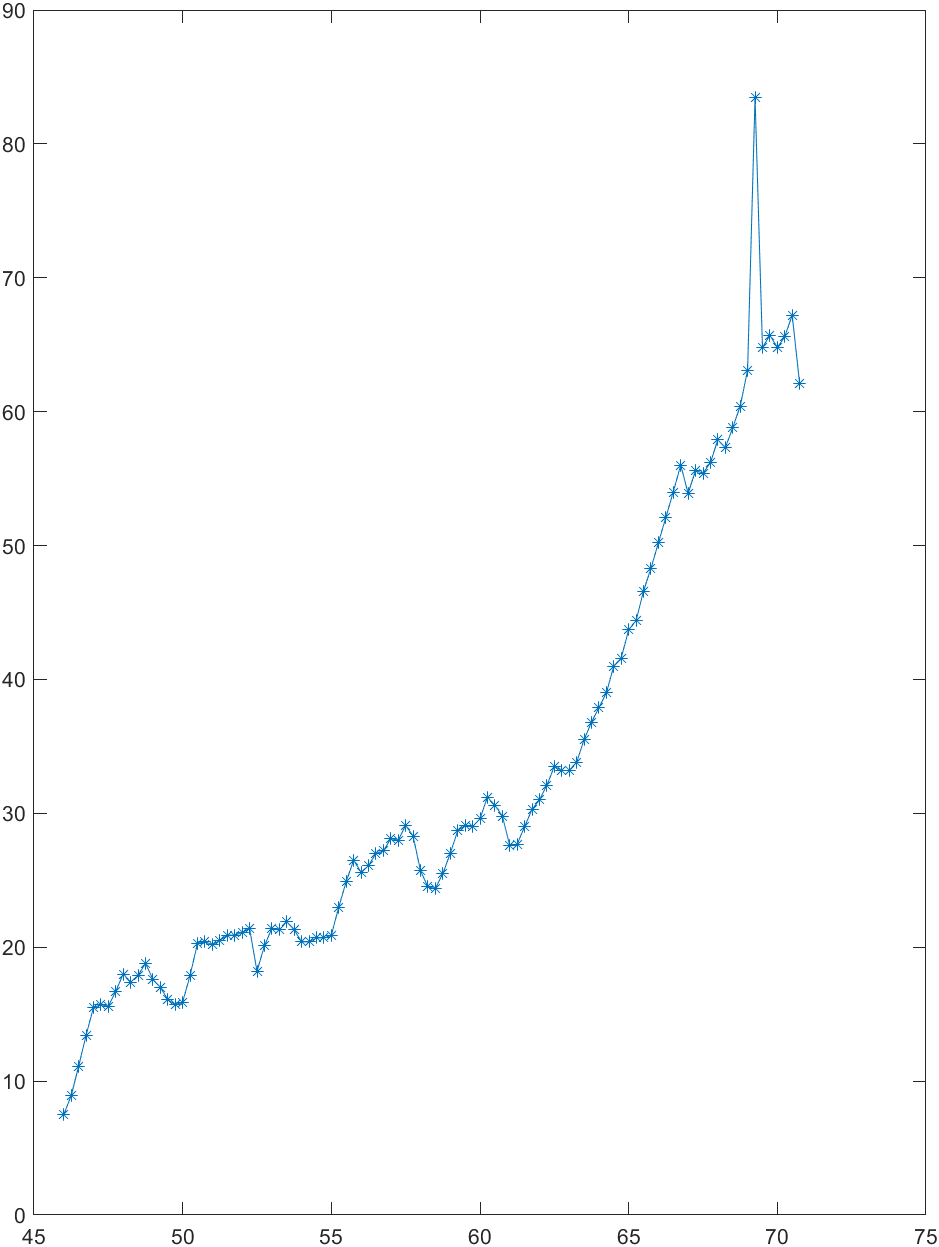
可以看出具有指数上升趋势,因此,对确定性部分先拟合一个指数增长模型,即
X
t
=
μ
t
+
Y
t
,
μ
t
=
R
1
e
r
1
t
X_t = \mu_t + Y_t, \mu_t = R_1e^{r_1t}
Xt=μt+Yt,μt=R1er1t
这里各季节依次编号为
t
=
1
,
2
,
…
,
100
t = 1,2,\dots,100
t=1,2,…,100。
然后确定性趋势的拟合。为了能用线性最小二乘法估计参数
R
1
R_1
R1和
r
1
r_1
r1,
μ
t
=
R
1
e
r
1
t
\mu_t = R_1 e^{r_1t}
μt=R1er1t两边取对数,得:
ln
μ
t
=
ln
R
1
+
r
1
t
\ln \mu_t = \ln R_1 + r_1t
lnμt=lnR1+r1t
利用观测数据求得
R
^
1
=
12.6385
,
r
^
1
\hat{R}_1 = 12.6385,\hat{r}_1
R^1=12.6385,r^1 = 0.0162。剩余平方和为1683.5371。剩余序列
Y
t
Y_t
Yt如下图所示,可以认为是平稳的:
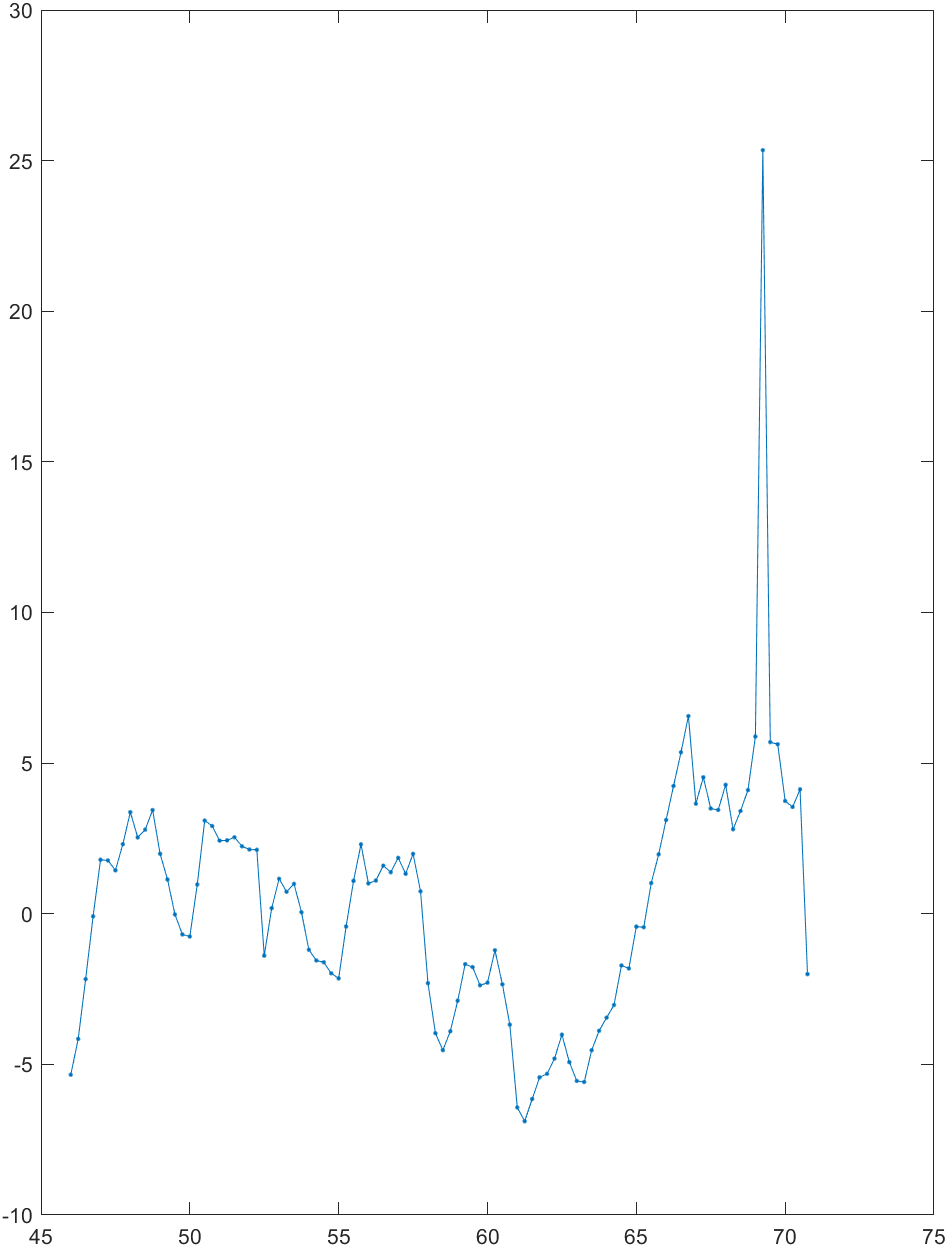
对剩余序列拟合ARMA模型。 Y t Y_t Yt自相关与偏自相关如下图所示:
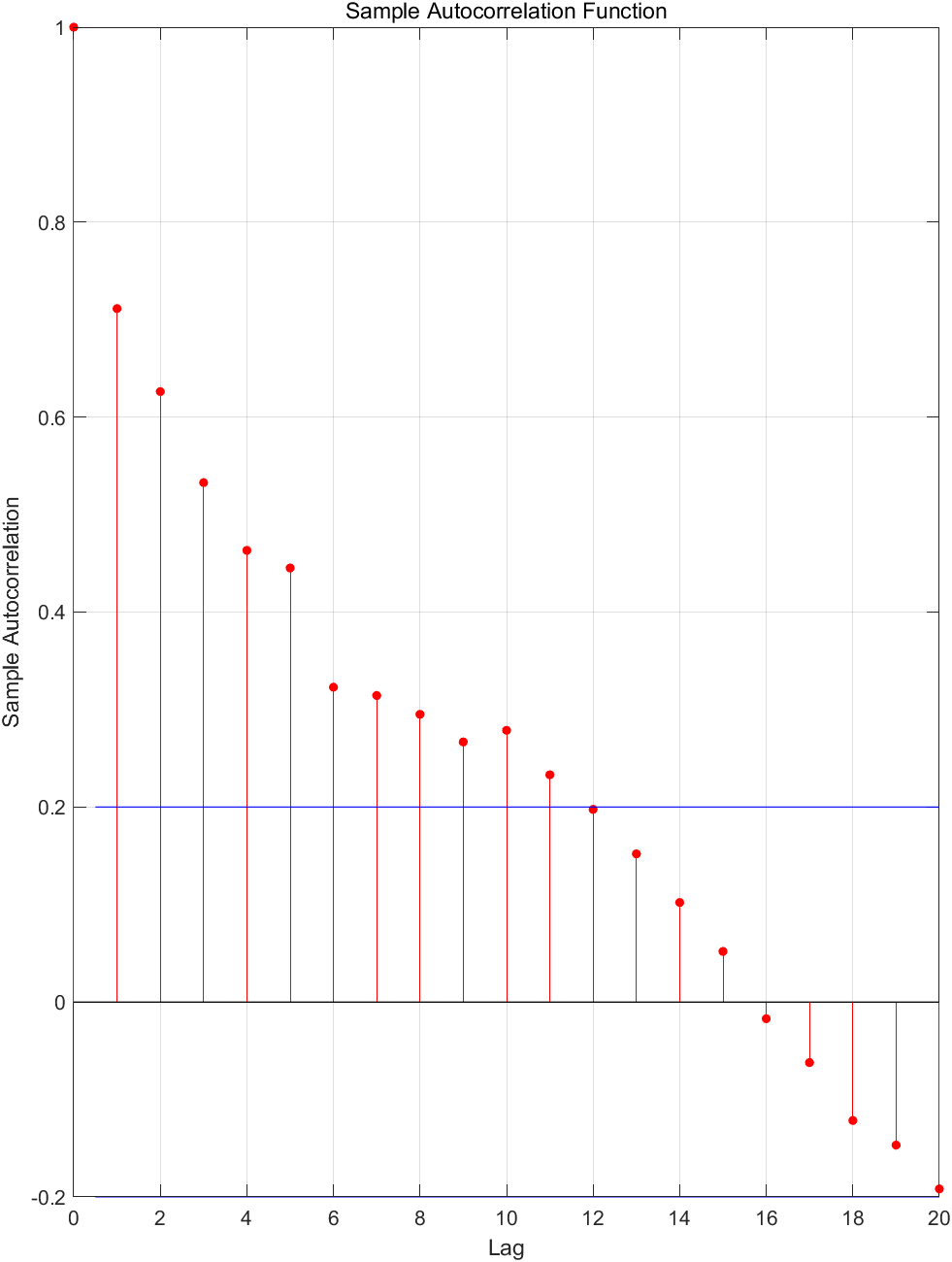
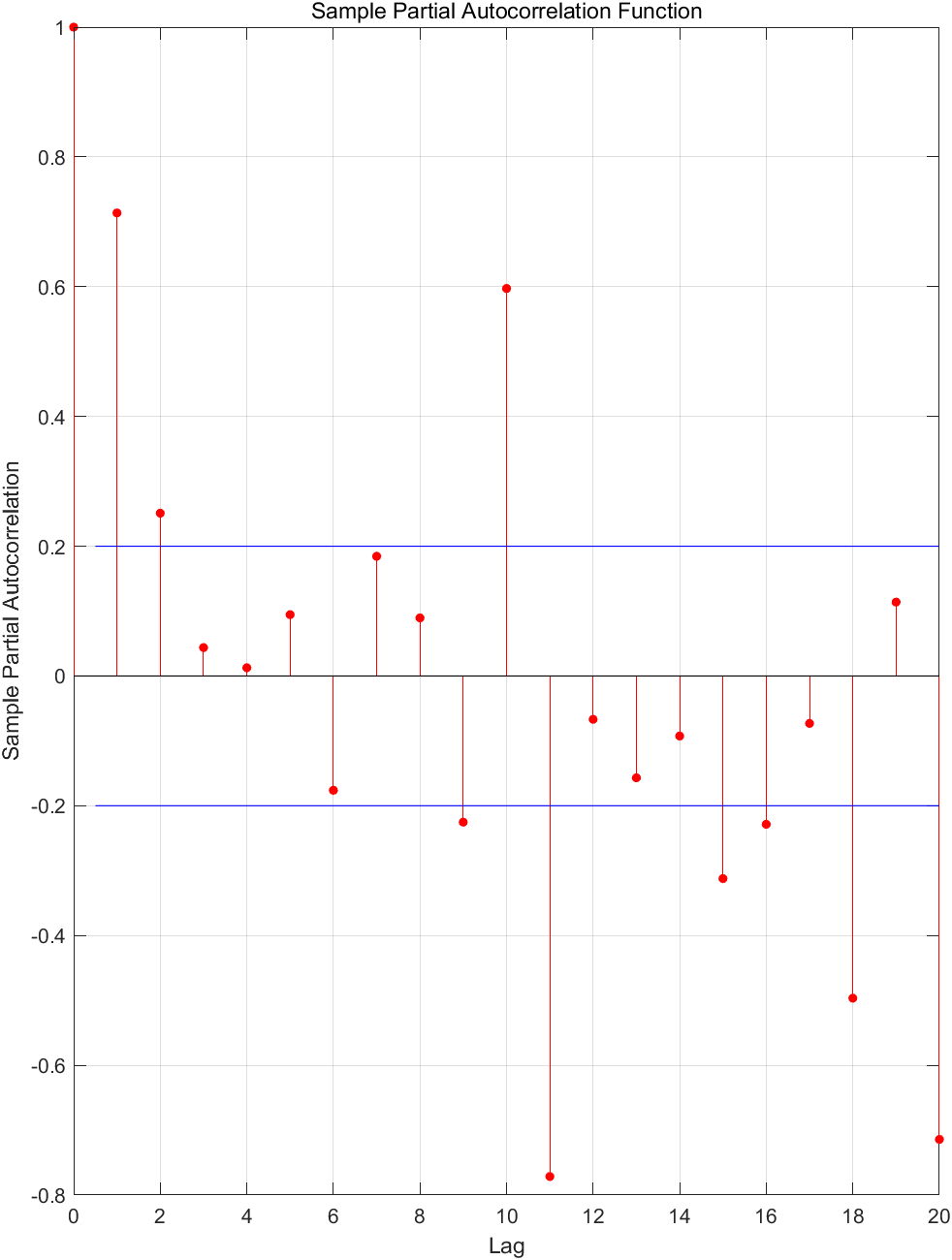
可初步断定 Y t Y_t Yt的适应模型为AR模型,逐增加AR模型阶数进行拟合,其残差方差图如下图所示:
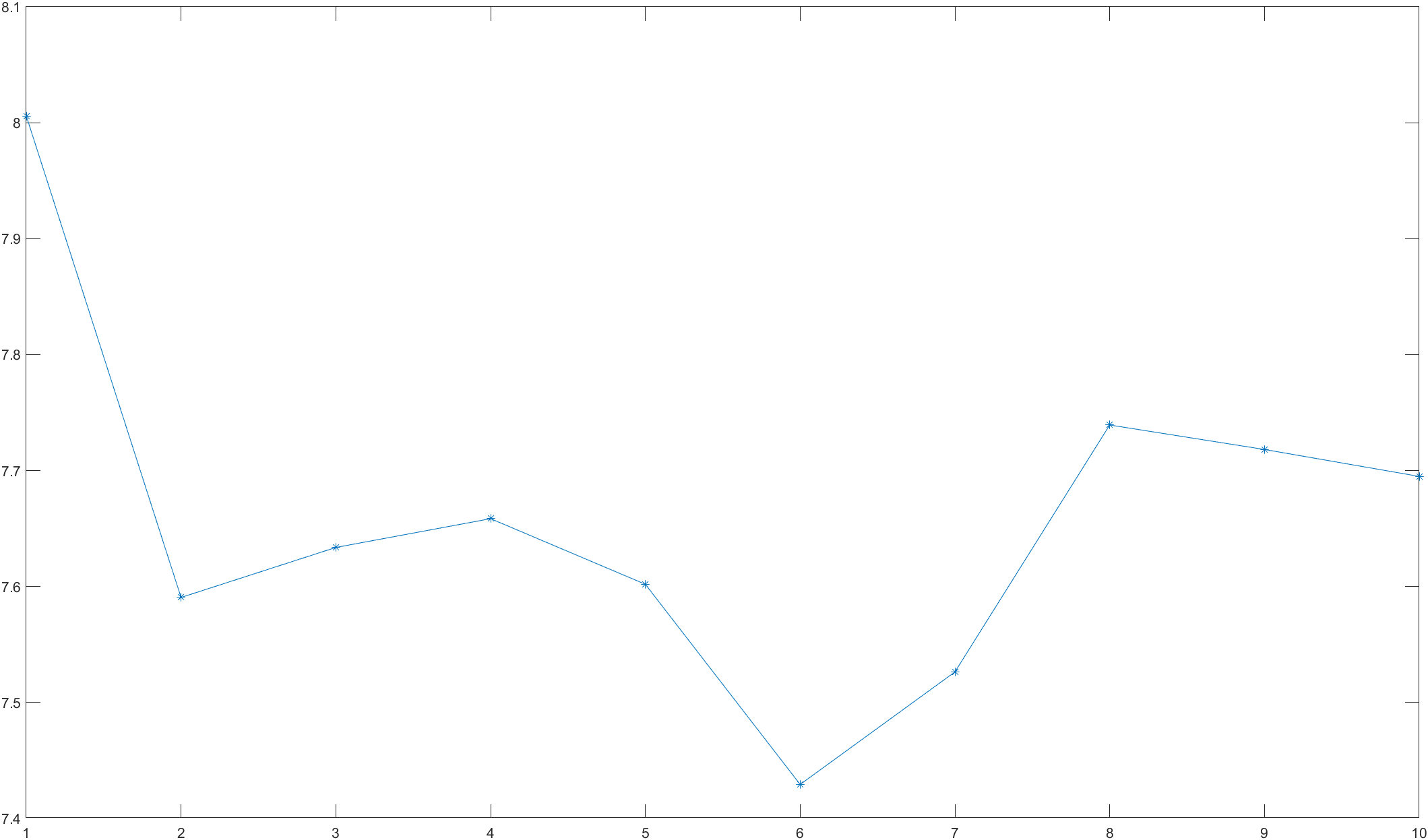
因此,合适的模型为AR (2),即
Y
t
=
φ
1
Y
t
−
1
+
φ
2
Y
t
−
2
+
a
t
Y_t = \varphi_1Y_{t-1}+\varphi_2Y_{t-2} + a_t
Yt=φ1Yt−1+φ2Yt−2+at
参数估计为
φ
^
1
=
0.5451
,
φ
^
2
=
0.2478
\hat{\varphi}_1 = 0.5451,\hat{\varphi}_2 = 0.2478
φ^1=0.5451,φ^2=0.2478。
建立组合模型。最后要以已估计出来的
R
1
,
r
1
,
φ
1
,
φ
2
R_1,r_1,\varphi_1,\varphi_2
R1,r1,φ1,φ2的值为初始值用非线性最小二乘法对模型参数进行整体估计,模型整体可写为
X
t
=
μ
t
+
Y
t
=
R
1
e
r
1
t
+
φ
1
(
X
t
−
1
−
R
1
e
r
1
(
t
−
1
)
)
+
φ
2
(
X
t
−
2
)
−
R
1
e
r
1
(
t
−
2
)
+
a
t
X_t = \mu_t + Y_t = R_1e^{r_1t} + \varphi_1(X_{t-1}-R_1e^{r_1(t-1)} )+\varphi_2(X_{t-2})-R_1e^{r_1(t-2)}+a_t
Xt=μt+Yt=R1er1t+φ1(Xt−1−R1er1(t−1))+φ2(Xt−2)−R1er1(t−2)+at
最终的参数整体估计为
R
^
1
=
12.1089
,
r
^
1
=
0.017
,
φ
^
1
=
0.517
,
φ
^
2
=
0.2397
\hat{R}_1=12.1089,\hat{r}_1=0.017,\hat{\varphi}_1 = 0.517, \hat{\varphi}_2 = 0.2397
R^1=12.1089,r^1=0.017,φ^1=0.517,φ^2=0.2397
残差平方和为739.4402。
(2)
对所给的时间序列进行两年(8个季度)的预报。用所建的模型以1970年第4几度即t = 100为原点进行预测,结果如下表所示。
| l | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 |
|---|---|---|---|---|---|---|---|---|---|
| t+l | t | t+1 | t+2 | t+3 | t+4 | t+5 | t+6 | t+7 | t+8 |
| X ^ t ( l ) \hat{X}_t(l) X^t(l) | 62.1 | 65.8298 | 66.8384 | 68.562 | 70.0083 | 71.4879 | 72.9238 | 74.3507 | 75.768 |
3.程序
(1)
求解的MATLAB程序如下:
clc, clear
% 将数据按照每年的每个季度依次写入
a = [7.5, 8.9, 11.1, 13.4, 15.5, 15.7, 15.6, 16.7, 18, 17.4, 17.9, ...
18.8, 17.6, 17, 16.1, 15.7, 15.9, 17.9, 20.3, 20.4, 20.2, 20.5, ...
20.9, 20.9, 21.1, 21.4, 18.2, 20.1, 21.4, 21.3, 21.9, 21.3, ...
20.4, 20.4, 20.7, 20.7, 20.9, 23, 24.9, 26.5, 25.6, 26.1, 27, ...
27.2, 28.1, 28, 29.1, 28.3, 25.7, 24.5, 24.4, 25.5, 27, 28.7, ...
29.1, 29, 29.6, 31.2, 30.6, 29.8, 27.6, 27.7, 29, 30.3, 31, 32.1, ...
33.5, 33.2, 33.2, 33.8, 35.5, 36.8, 37.9, 39, 41, 41.6, 43.7, ...
44.4, 46.6, 48.3, 50.2, 52.1, 54, 56, 53.9, 55.6, 55.4, 56.2, ...
57.9, 57.3, 58.8, 60.4, 63.1, 83.5, 64.8, 65.7, 64.8, 65.6, 67.2, 62.1]';
n = length(a);
t0 = [46:1 / 4:71 - 1 / 4];
t = [1:100]';
xishu = [ones(n, 1), t];
cs = xishu \ log(a)
cs(1) = exp(cs(1))
ahat = cs(1) * exp(cs(2)*t);
cha = a - ahat
res = sum(cha.^2)
subplot(121), plot(t0, a, '*-')
subplot(122), plot(t0, cha, '.-')
figure, subplot(121), autocorr(cha)
subplot(122), parcorr(cha)
for i = 1:10
cs2 = ar(cha, i);
cha2 = resid(cs2, cha);
myvar(i) = sum(cha2.outputdata.^2) / (100 - i);
end
figure, plot(myvar, '*-')
(2)
求解的MATLAB程序如下:
clc, clear
% 定义一个函数句柄 xt,它的输入参数是一个向量 cs 和一个矩阵 x。
% x 矩阵的第一列是 a 向量的第二个元素到倒数第二个元素,第二列是 a 向量的第一个元素到倒数第三个元素,
% 第三列是一个列向量,它包含数字3到100
% 这些数字将用于预测未来的季度。
% 函数的输出是一个向量,表示用于预测季度的预测值。
xt = @(cs, x)cs(1) * (exp(cs(2)*x(:, 3)) - cs(3) * exp(cs(2)*(x(:, 3) - 1)) - ...
cs(4) * exp(cs(2)*(x(:, 3) - 2))) + cs(3) * x(:, 1) + cs(4) * x(:, 2);
cs0 = [12.6385, 0.0162, 0.5451, 0.2478]';
% 将数据按照每年的每个季度依次写入
a = [7.5, 8.9, 11.1, 13.4, 15.5, 15.7, 15.6, 16.7, 18, 17.4, 17.9, ...
18.8, 17.6, 17, 16.1, 15.7, 15.9, 17.9, 20.3, 20.4, 20.2, 20.5, ...
20.9, 20.9, 21.1, 21.4, 18.2, 20.1, 21.4, 21.3, 21.9, 21.3, ...
20.4, 20.4, 20.7, 20.7, 20.9, 23, 24.9, 26.5, 25.6, 26.1, 27, ...
27.2, 28.1, 28, 29.1, 28.3, 25.7, 24.5, 24.4, 25.5, 27, 28.7, ...
29.1, 29, 29.6, 31.2, 30.6, 29.8, 27.6, 27.7, 29, 30.3, 31, 32.1, ...
33.5, 33.2, 33.2, 33.8, 35.5, 36.8, 37.9, 39, 41, 41.6, 43.7, ...
44.4, 46.6, 48.3, 50.2, 52.1, 54, 56, 53.9, 55.6, 55.4, 56.2, ...
57.9, 57.3, 58.8, 60.4, 63.1, 83.5, 64.8, 65.7, 64.8, 65.6, 67.2, 62.1]';
% 创建一个矩阵 x,包含3列,用于作为函数 xt 的输入参数
% 第一列是 a 向量的第二个元素到倒数第二个元素,第二列是 a 向量的第一个元素到倒数第三个元素,
% 第三列是一个列向量,它包含数字3到100,这些数字将用于预测未来的季度
x = [a(2:end-1), a(1:end-2), [3:100]'];
cs = lsqcurvefit(xt, cs0, x, a(3:end))
res = a(3:end) - xt(cs, x);
Q = sum(res.^2)
autocorr(res)
xhat = a;
for j = 101:108
xhat(j) = cs(1) * (exp(cs(2)*j) - cs(3) * exp(cs(2)*(j - 1)) - ...
cs(4) * exp(cs(2)*(j - 2))) + cs(3) * xhat(j-1) + cs(4) * xhat(j-2);
end
xhat101_108 = xhat(101:108)
4.结果
(1)结果见上文解题过程
(2)

| l | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 |
|---|---|---|---|---|---|---|---|---|---|
| t+l | t | t+1 | t+2 | t+3 | t+4 | t+5 | t+6 | t+7 | t+8 |
| X ^ t ( l ) \hat{X}_t(l) X^t(l) | 62.1 | 65.8298 | 66.8384 | 68.562 | 70.0083 | 71.4879 | 72.9238 | 74.3507 | 75.768 |
如果这篇文章对你有帮助,欢迎点赞与收藏~