接触huggingface
finetuning llama
按照https://github.com/samlhuillier/code-llama-fine-tune-notebook/tree/main中的教程一步一步了解。
pip install
!pip install git+https://github.com/huggingface/transformers.git@main bitsandbytes # we need latest transformers for this
!pip install git+https://github.com/huggingface/peft.git@4c611f4
!pip install datasets==2.10.1
import locale # colab workaround 将首选编码改为utf8
locale.getpreferredencoding = lambda: "UTF-8" # colab workaround
!pip install wandb
!pip install scipy
bitsandbytes 是 CUDA 自定义函数的轻量级包装器,特别是 8 位优化器、矩阵乘法 (LLM.int8()) 和量化函数。
wandb是一个免费的,用于记录实验数据的工具。wandb相比于tensorboard之类的工具,有更加丰富的用户管理,团队管理功能,更加方便团队协作。使用wandb首先要在网站上创建team,然后在team下创建project,然后project下会记录每个实验的详细数据。
Loading library
from datetime import datetime
import os
import sys
import torch
from peft import (
LoraConfig,
get_peft_model,
get_peft_model_state_dict,
prepare_model_for_int8_training,
set_peft_model_state_dict,
)
from transformers import AutoTokenizer, AutoModelForCausalLM, TrainingArguments, Trainer, DataCollatorForSeq2Seq
Load dataset
from datasets import load_dataset
dataset = load_dataset("b-mc2/sql-create-context", split="train")
train_dataset = dataset.train_test_split(test_size=0.1)["train"]
eval_dataset = dataset.train_test_split(test_size=0.1)["test"]
查看数据
print(train_dataset[3])
{'question': 'What was the district when the reason for change was died January 1, 1974?', 'context': 'CREATE TABLE table_1134091_4 (district VARCHAR, reason_for_change VARCHAR)', 'answer': 'SELECT district FROM table_1134091_4 WHERE reason_for_change = "Died January 1, 1974"'}
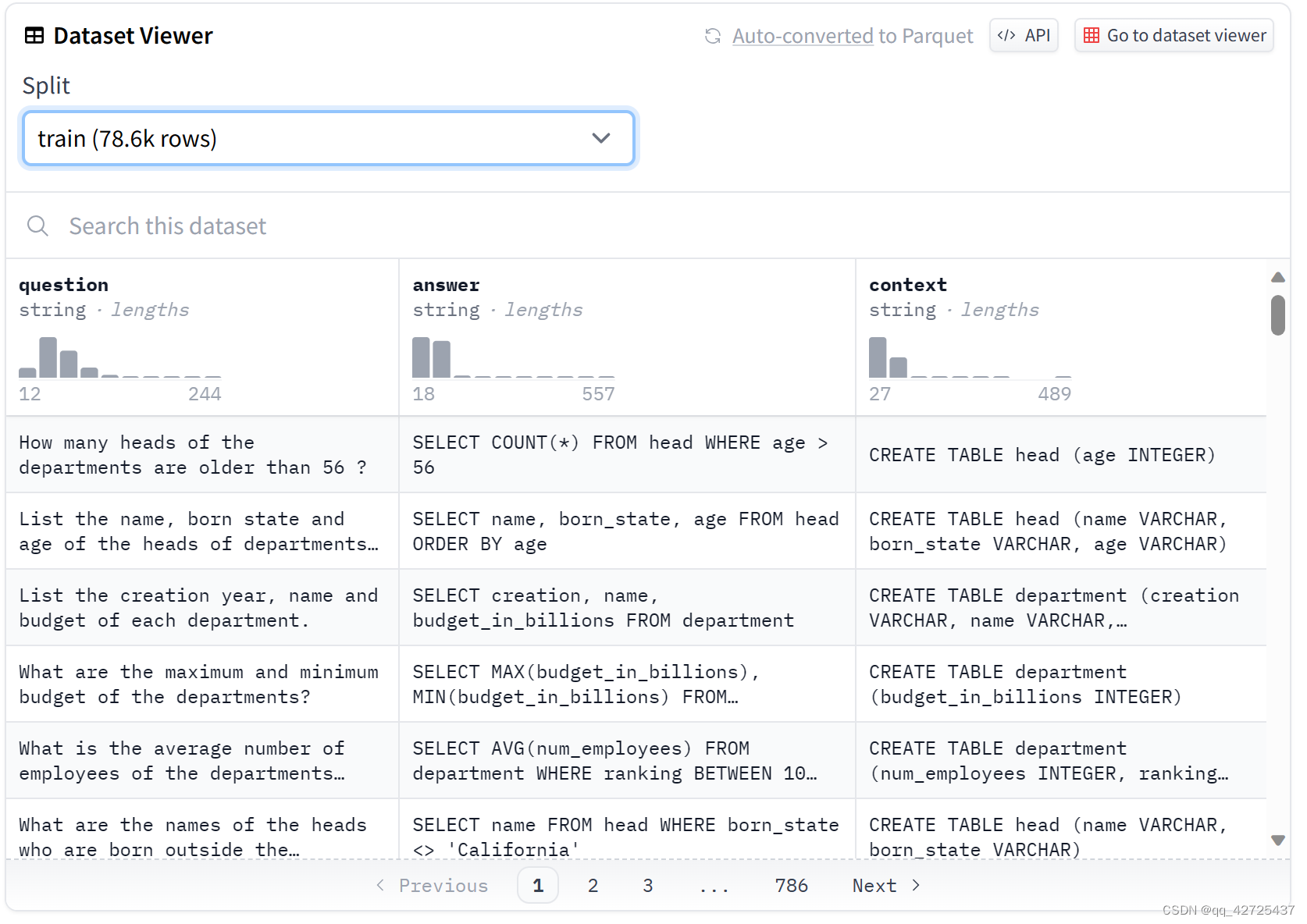
每个条目由文本“问题”、sql 表“上下文”和“答案”组成
Load model
base_model = "codellama/CodeLlama-7b-hf"
model = AutoModelForCausalLM.from_pretrained(
base_model,
load_in_8bit=True,
torch_dtype=torch.float16,
device_map="auto",
)
tokenizer = AutoTokenizer.from_pretrained("codellama/CodeLlama-7b-hf")
- load_in_8bit=True:
这个参数可能是用来指定模型加载时的数据表示方法。一般情况下,深度学习模型在内存中存储权重时会使用32位或者更高精度的浮点数(例如float32)。load_in_8bit=True可能意味着在加载模型时,将这些权重转换为8位表示,以减少内存占用。这种技术通常被称为模型量化。通过量化,可以减少模型的内存占用和提高推理速度,但可能会牺牲一些模型精度。 - torch_dtype=torch.float16:
torch_dtype参数指定了PyTorch中张量的数据类型。torch.float16表示使用半精度浮点数(16位)。与标准的32位浮点数(float32)相比,使用半精度可以减少内存和计算资源的消耗。这在特别是在具有半精度算术支持的GPU上非常有用,因为它可以显著加速模型的训练和推理过程,同时也减少了内存使用。 - device_map=“auto”:
这个参数可能与模型在不同计算设备上的分布式运行有关。在深度学习中,device_map通常用于指定模型或数据应该在哪些硬件设备上运行(如不同的GPU或CPU)。"auto"可能意味着框架将自动选择最优的设备分配策略,例如自动分配模型的不同部分到可用的GPU上,以达到最佳的运行效率。
torch_dtype=torch.float16 表示使用 float16 表示形式执行计算,即使值本身是 8 位整数。
Check base model
一个非常好的常见做法是检查模型是否已经可以完成手头的任务。
eval_prompt = """You are a powerful text-to-SQL model. Your job is to answer questions about a database. You are given a question and context regarding one or more tables.
You must output the SQL query that answers the question.
### Input:
Which Class has a Frequency MHz larger than 91.5, and a City of license of hyannis, nebraska?
### Context:
CREATE TABLE table_name_12 (class VARCHAR, frequency_mhz VARCHAR, city_of_license VARCHAR)
### Response:
"""
# {'question': 'Name the comptroller for office of prohibition', 'context': 'CREATE TABLE table_22607062_1 (comptroller VARCHAR, ticket___office VARCHAR)', 'answer': 'SELECT comptroller FROM table_22607062_1 WHERE ticket___office = "Prohibition"'}
model_input = tokenizer(eval_prompt, return_tensors="pt").to("cuda")
model.eval()
with torch.no_grad():
print(tokenizer.decode(model.generate(**model_input, max_new_tokens=100)[0], skip_special_tokens=True))
tokenizer
tokenizer.tokenize(sequence)对文本进行分词;
tokenizer.convert_tokens_to_ids(tokens)将token转变为编号;
tokenizer.decode([7993, 170, 11303, 1200, 2443, 1110, 3014])将数字转变为文本,skip_special_tokens=True跳过特殊字符;
model.genertate
max_new_tokens (int, optional) - 要生成的最大数量的tokens,忽略提示中的tokens数量。

显然是不对的。
Tokenization
tokenizer.add_eos_token = True
tokenizer.pad_token_id = 0
tokenizer.padding_side = "left"
- tokenizer.add_eos_token = True:
这行代码设置了一个标志,指示在对文本进行分词处理时自动添加一个“结束符”(End Of String, EOS)标记。在许多NLP模型中,EOS标记用来表示句子或文本输入的结束。这对于模型正确解释输入长度和结构通常是必要的,特别是在处理多句子或者需要明确句子边界的任务中。 - tokenizer.pad_token_id = 0:
这行代码指定了用于填充(padding)操作的标记的ID是0。在处理文本数据时,经常需要将不同长度的句子统一到相同的长度,这样才能被批量处理。这通常通过在短句子后面添加“填充标记”(padding token)来实现。这里设置pad_token_id为0意味着用ID为0的标记来进行这种填充操作。 - tokenizer.padding_side = “left”:
这个设置指定了填充操作是在句子的哪一边进行。"left"表示在句子的左侧添加填充标记。这意味着如果需要将句子填充到固定长度,额外的填充标记会被添加到句子开头,而不是结尾。在某些模型或任务中,改变填充的方向可能会影响模型的性能或者对输入数据的处理方式。
decoder-only模型采用 left-padding的原因是, 模型的输入是对模型输入的延续(模型的输出中会带着输入,并在输入后边补充输出),如果采用right-padding,会导致大量的[pad]token夹在模型的输入和输入之间,不利于处理结果.并且模型的输出句子的语义也被pad打乱了,输入并不直观.此外,decoder-only的模型并不需要cls等开头的token来做额外的处理,right-padding在decoder-only的模型中没有任何优势.
def tokenize(prompt):
result = tokenizer(
prompt,
truncation=True,
max_length=512,
padding=False,
return_tensors=None,
)
# "self-supervised learning" means the labels are also the inputs:
result["labels"] = result["input_ids"].copy()
return result
result[“input_ids”]比tokenizer.convert_tokens_to_ids(tokens)的结果增加了特殊的字符 [CLS] 和 [SEP]。
def generate_and_tokenize_prompt(data_point):
full_prompt =f"""You are a powerful text-to-SQL model. Your job is to answer questions about a database. You are given a question and context regarding one or more tables.
You must output the SQL query that answers the question.
### Input:
{data_point["question"]}
### Context:
{data_point["context"]}
### Response:
{data_point["answer"]}
"""
return tokenize(full_prompt)
重新格式化以提示并标记每个样本:
tokenized_train_dataset = train_dataset.map(generate_and_tokenize_prompt)
tokenized_val_dataset = eval_dataset.map(generate_and_tokenize_prompt)
Setup Lora
model.train() # put model back into training mode
model = prepare_model_for_int8_training(model)
config = LoraConfig(
r=16,
lora_alpha=16,
target_modules=[
"q_proj",
"k_proj",
"v_proj",
"o_proj",
],
lora_dropout=0.05,
bias="none",
task_type="CAUSAL_LM",
)
model = get_peft_model(model, config)
Lora
- task_type:指定任务类型。如:条件生成任务(SEQ_2_SEQ_LM),因果语言建模(CAUSAL_LM)等。
- inference_mode:是否在推理模式下使用Peft模型。
r: LoRA低秩矩阵的维数。关于秩的选择,通常,使用4,8,16即可。
lora_alpha: LoRA低秩矩阵的缩放系数,为一个常数超参,调整alpha与调整学习率类似。 - lora_dropout:LoRA 层的丢弃(dropout)率,取值范围为[0, 1)。
- target_modules:要替换为 LoRA 的模块名称列表或模块名称的正则表达式。针对不同类型的模型,模块名称不一样,因此,我们需要根据具体的模型进行设置,比如,LLaMa的默认模块名为[q_proj, v_proj],我们也可以自行指定为:[q_proj,k_proj,v_proj,o_proj]。
wandb_project = "sql-try2-coder"
if len(wandb_project) > 0:
os.environ["WANDB_PROJECT"] = wandb_project
if torch.cuda.device_count() > 1:
# keeps Trainer from trying its own DataParallelism when more than 1 gpu is available
model.is_parallelizable = True
model.model_parallel = True
Training arguments
batch_size = 32
per_device_train_batch_size = 8
gradient_accumulation_steps = batch_size // per_device_train_batch_size
output_dir = "sql-code-llama"
training_args = TrainingArguments(
per_device_train_batch_size=per_device_train_batch_size,
gradient_accumulation_steps=gradient_accumulation_steps,
warmup_steps=100,
max_steps=400,
learning_rate=3e-4,
fp16=True,
logging_steps=10,
optim="adamw_torch",
evaluation_strategy="steps", # if val_set_size > 0 else "no",
save_strategy="steps",
eval_steps=20,
save_steps=20,
output_dir=output_dir,
save_safetensors=False, # 跟github不同,因为版本不同,需要添加save_safetensors
# save_total_limit=3,
load_best_model_at_end=False,
# ddp_find_unused_parameters=False if ddp else None,
group_by_length=True, # group sequences of roughly the same length together to speed up training
report_to="wandb", # if use_wandb else "none",
run_name=f"codellama-{datetime.now().strftime('%Y-%m-%d-%H-%M')}", # if use_wandb else None,
)
trainer = Trainer(
model=model,
train_dataset=tokenized_train_dataset,
eval_dataset=tokenized_val_dataset,
args=training_args,
data_collator=DataCollatorForSeq2Seq(
tokenizer, pad_to_multiple_of=8, return_tensors="pt", padding=True
),
)
model.config.use_cache = False
old_state_dict = model.state_dict
model.state_dict = (lambda self, *_, **__: get_peft_model_state_dict(self, old_state_dict())).__get__(
model, type(model)
)
if torch.__version__ >= "2" and sys.platform != "win32":
print("compiling the model")
model = torch.compile(model)
trainer.train()
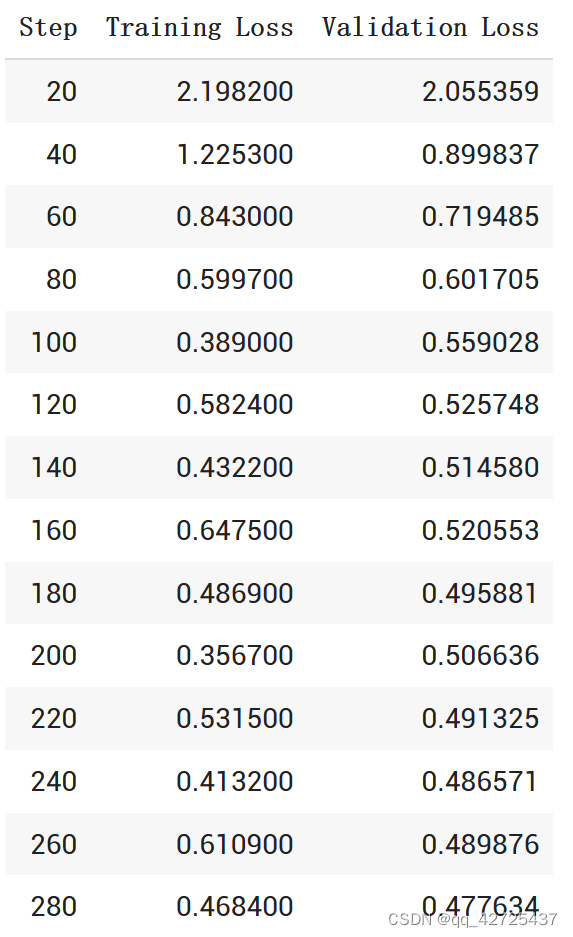
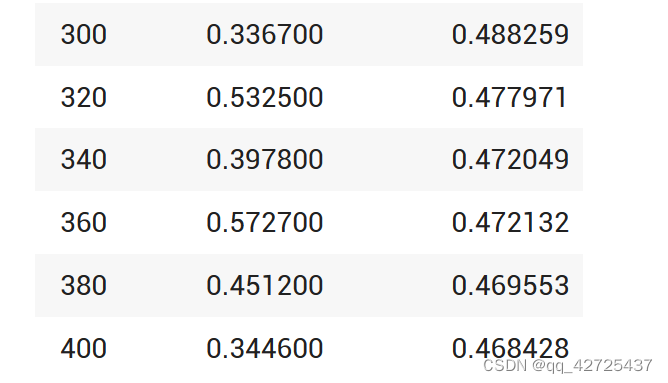

Load the final checkpoint
import torch
from transformers import AutoModelForCausalLM, BitsAndBytesConfig, AutoTokenizer
base_model = "codellama/CodeLlama-7b-hf"
model = AutoModelForCausalLM.from_pretrained(
base_model,
load_in_8bit=True,
torch_dtype=torch.float16,
device_map="auto",
)
tokenizer = AutoTokenizer.from_pretrained("codellama/CodeLlama-7b-hf")
from peft import PeftModel
model = PeftModel.from_pretrained(model, "/content/sql-code-llama/checkpoint-400")
这里需要重新启动内核,清空显存
eval_prompt = """You are a powerful text-to-SQL model. Your job is to answer questions about a database. You are given a question and context regarding one or more tables.
You must output the SQL query that answers the question.
### Input:
Which Class has a Frequency MHz larger than 91.5, and a City of license of hyannis, nebraska?
### Context:
CREATE TABLE table_name_12 (class VARCHAR, frequency_mhz VARCHAR, city_of_license VARCHAR)
### Response:
"""
model_input = tokenizer(eval_prompt, return_tensors="pt").to("cuda")
model.eval()
with torch.no_grad():
print(tokenizer.decode(model.generate(**model_input, max_new_tokens=100)[0], skip_special_tokens=True))
我的结果很差,没有改变,不知道什么原因,就当作笔记了。





![[Linux] Linux防火墙之firewalld](https://img-blog.csdnimg.cn/direct/b741142983614dc590fd2681a1d0f337.png)