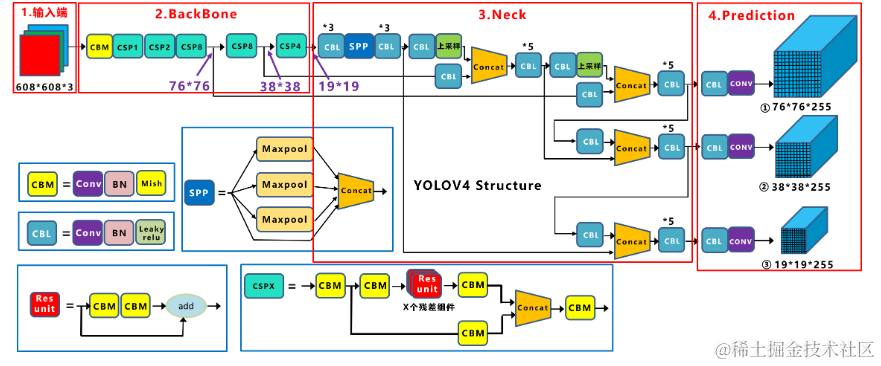
Course2-Week4-决策树
文章目录
- Course2-Week4-决策树
- 1. 决策树的直观理解
- 2. 构建单个决策树
- 2.1 熵和信息增益
- 2.2 构建决策树——二元输入特征
- 2.3 构建决策树——多元输入特征
- 2.4 构建决策树——连续的输入特征
- 2.5 构建回归树——连续的输出结果(选修)
- 2.6 代码实现-递归构建单个决策树
- 3. 决策树集合
- 3.1 使用决策树集合
- 3.2 袋装决策树
- 3.3 随机森林
- 3.4 XGBoost算法
- 3.5 何时使用决策树
- 笔记主要参考B站视频“(强推|双字)2022吴恩达机器学习Deeplearning.ai课程”。
- 该课程在Course上的页面:Machine Learning 专项课程
- 课程资料:“UP主提供资料(Github)”、或者“我的下载(百度网盘)”。
- 本篇笔记对应课程 Course2-Week4(下图中深紫色)。

1. 决策树的直观理解
“神经网络”和“决策树/决策树集合”都被广泛应用于很多商业应用,并且在各类机器学习比赛中也取得了很好的成绩。但相比于“神经网络”,“决策树/决策树集合”却并没有在学术界引起很多关注。本周就来介绍“决策树/决策树集合”这个非常强大的工具。
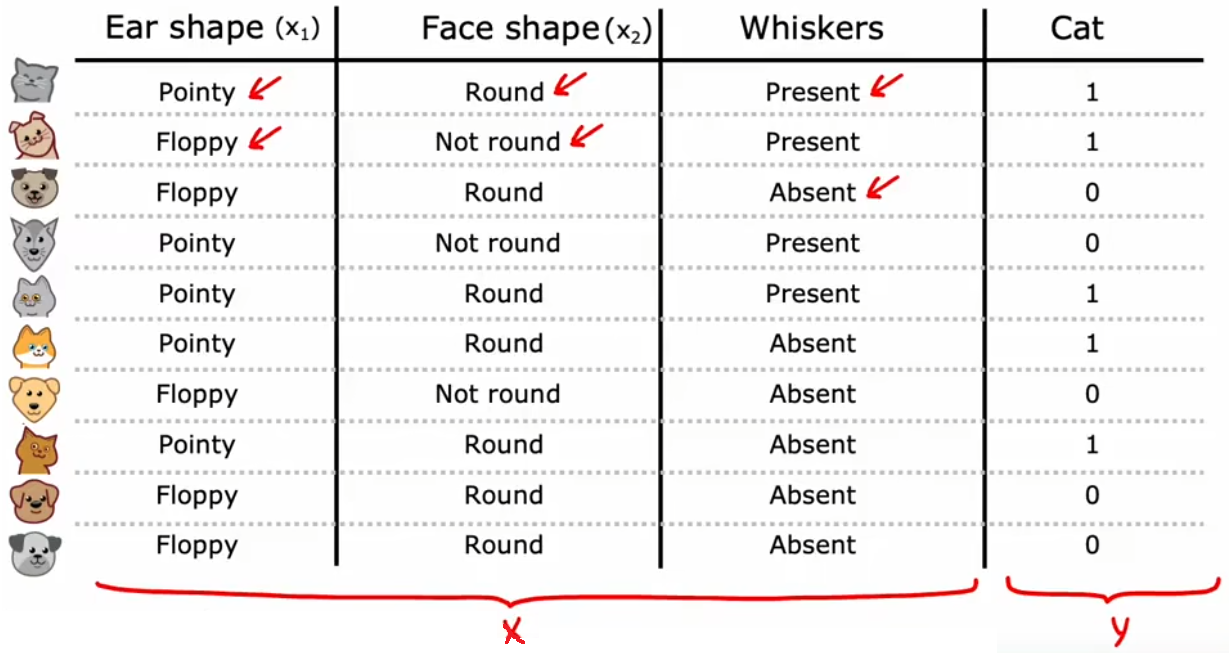
【问题1】“识别猫”:二元分类,对于给定的特征,判断是否为猫。
- 输入特征:“耳朵形状”、“脸型”、“胡须”。
- 输出:是否为猫。
- 默认数据集:三个“二元输入特征”,对应一个“二元输出结果”。
“决策树(decision tree)”采用“二叉树”的结构,从根节点(root node)开始,不断地进行一系列判断,最终到达叶子节点(leaf node),也就是预测结果。上面的“识别猫”问题将贯穿本周,用于帮助我们理解“决策树”中的概念。比如针对“识别猫”的数据集,我们可以构建如下所示的“决策树”,此时有一个新的输入,就可以按照该“决策树”进行推理:

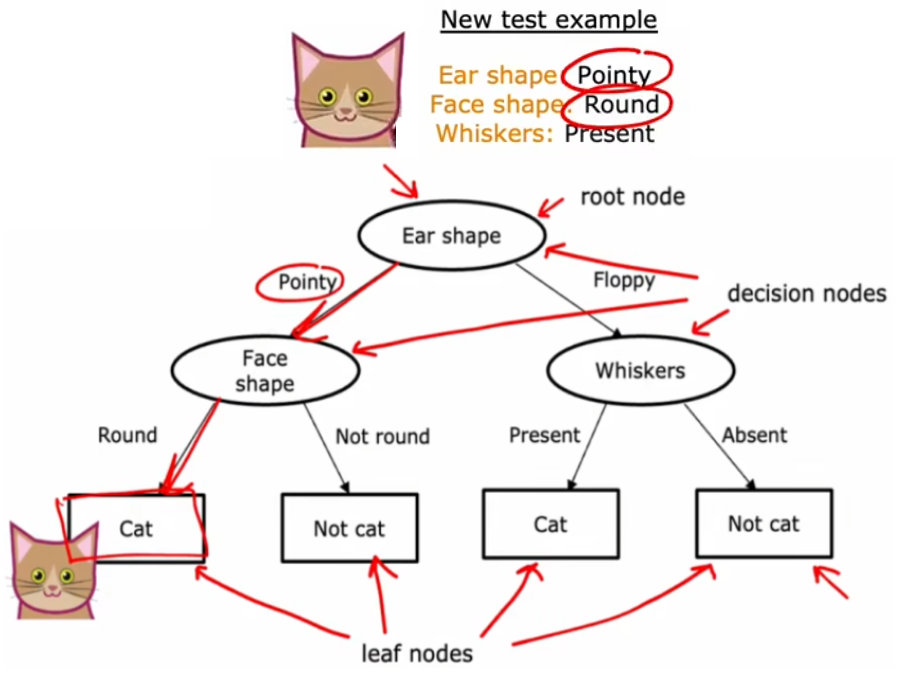
- 节点(node):树中的任何一个点都称为“节点”,也就是上图中所有的椭圆或矩形。
- 根节点(root node):最顶部的节点,也就是最顶部的椭圆,
- 决策节点(decision node):除了根节点外所有的椭圆,
- 叶子节点(leaf node):最下面一层的所有矩形。
- 深度(depth):从根节点到到达最下层的叶子节点,所经过的节点数。上图深度为2。
可以看到按照“决策树”的判断过程,这个新的输入最终被预测为猫,符合预期。但显然,对于当前给定的训练集,若没有其他约束条件的话,上述问题的决策树显然不止一种,如下图:
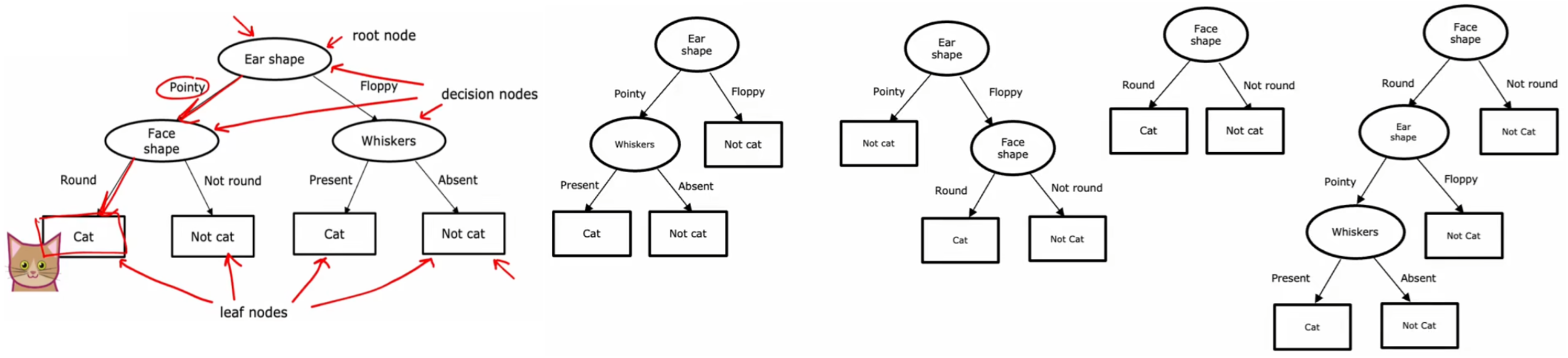
在上述这些不同的决策树当中,某些性能很好、某些性能很差。所以“决策树学习算法”就是,在所有可能的决策树中,找出当前数据集所对应的性能最好的决策树模型。下面是我们需要考虑的两条准则:
- 如何选择在每个节点使用什么特征进行拆分?
- 希望拆分后,能尽可能的区分不同的结果 y y y,理想状态就是所有子集都各自是不同种类 y y y 的集合。也就是拆分后,希望尽可能的减少信息的“不确定度”。比如在图2-4-1中,由于使用“Ear shape”进行拆分可以使“猫”尽量集中于同一个子集中,“不确定度”最小,所以选择其为根节点。后面会介绍如何计算这种“不确定度”。
- 什么时候停止拆分?
- 子集被完全区分,如上图2-4-1。
- 达到设置的最大深度。
- 降低的“不确定度”低于某个阈值。
- 当前节点的子集大小低于某个阈值(某个数)。
注1:树不应太深、太大,否则有过拟合的风险。
注2:第二节会详细介绍构建“决策树”的步骤。
本节 Quiz:
Based on the decision tree shown in the lecture, if an animal has floppy ears, a round face shape and has whiskers, does the model predict that it’s a cat or not a cat?
√ Cat
× Not a cat
Take a decision tree learning to classify between spam and non-spam email. There are 20 training examples at the root note, comprising 10 spam and 10 non-spam emails. If the algorithm can choose from among four features, resulting in four corresponding splits, which would it choose (i.e., which has highest purity)?
× Left split: 5of 10 emails are spam. Right split: 5 of 10 emails are spam.
× Left split: 2 of2 emails are spam. Right split: 8 of 18 emails are spam.
× Left split: 7 of 8 emails are spam. Right split: 3 of 12 emails are spam.
√ Left split: 10 of 10 emails are spam. Right split: 0 of 10 emails are spam.
2. 构建单个决策树
2.1 熵和信息增益
熵(杂质)
前面提到希望每次在节点进行拆分时,都尽可能的降低信息的“不确定度”,也就是尽可能提升信息的“纯度(purity)”。这个“不确定度”使用“熵(entropy)”来进行计算,下面是“熵”的计算公式和曲线。由于“熵”的物理意义就是“信息的不确定度/不纯的程度”,所以机器学习中又喜欢称“熵”为“杂质(impurity)”。这些都只是花里胡哨的名字而已,只需要记住:
- “熵”就是“杂质”,表示信息的混乱程度,也就是“不纯”的程度。
注:逻辑回归中的“二元交叉熵损失函数”就来自于“熵”的计算。
Entropy: H ( P ) = − ∑ a l l i p i l o g 2 ( p i ) ⟹ 二元分类 H ( p 1 ) = − p 1 l o g 2 ( p 1 ) − ( 1 − p 1 ) l o g 2 ( 1 − p 1 ) \begin{aligned} \text{Entropy:} \quad H(P) = -\sum_{all\;i}p_ilog_2(p_i) \overset{二元分类}{\Longrightarrow} H(p_1) = -p_1log_2(p_1) - (1-p_1)log_2(1-p_1) \end{aligned} Entropy:H(P)=−alli∑pilog2(pi)⟹二元分类H(p1)=−p1log2(p1)−(1−p1)log2(1−p1)

注意,除了“熵”之外,还有其他方法来衡量“信息不纯的程度”,比如开源软件包中会提供“Gini指数”。它表示从数据集中随机选择两个样本,其类别标签不一致的概率,下面是其计算公式。但是为了首先掌握决策树的构建过程,而不是让过多的琐碎的概念困扰,本课程我们就只用“熵”来表示信息的“不纯度”。
Gini index:
G
(
P
)
=
1
−
∑
a
l
l
i
p
i
2
⟹
二元分类
G
(
p
1
)
=
1
−
p
1
2
−
(
1
−
p
1
)
2
=
2
p
1
(
1
−
p
1
)
\text{Gini index:} \quad G(P) = 1 -\sum_{all\;i}p_i^2 \overset{二元分类}{\Longrightarrow} G(p_1) = 1- p_1^2 - (1-p_1)^2 = 2p_1(1-p_1)
Gini index:G(P)=1−alli∑pi2⟹二元分类G(p1)=1−p12−(1−p1)2=2p1(1−p1)
信息增益
每次拆分都应最大程度的减少信息的不确定度,也就是“熵”,而减少的“熵”的大小则被称为“信息增益”。通信人表示,这些又双叒叕是花里胡哨的名字,只要记住 “信息增益”就是拆分前后减少的不确定度。注意拆分后信息的不确定度,应该为两分支的熵的加权平均,权值就是 拆分后各分支的子集大小 占 拆分前的集合大小 的比例。下面给出计算公式:
Information Gain = H ( p 1 root ) − ( w left H ( p 1 left ) + w right H ( p 1 right ) ) \text{Information Gain} = H(p_1^{\text{root}}) - \left(w^{\text{left}} H(p_1^{\text{left}}) + w^{\text{right}} H(p_1^{\text{right}})\right) Information Gain=H(p1root)−(wleftH(p1left)+wrightH(p1right))
- H ( p 1 root ) H(p_1^{\text{root}}) H(p1root):拆分前的不确定度。
- w left w^{\text{left}} wleft:拆分后,左分支的集合大小。
- w right w^{\text{right}} wright:拆分后,右分支的集合大小。
- H ( p 1 left ) H(p_1^{\text{left}}) H(p1left):拆分后,左分支的不确定度。
- H ( p 1 right ) H(p_1^{\text{right}}) H(p1right):拆分后,右分支的不确定度。
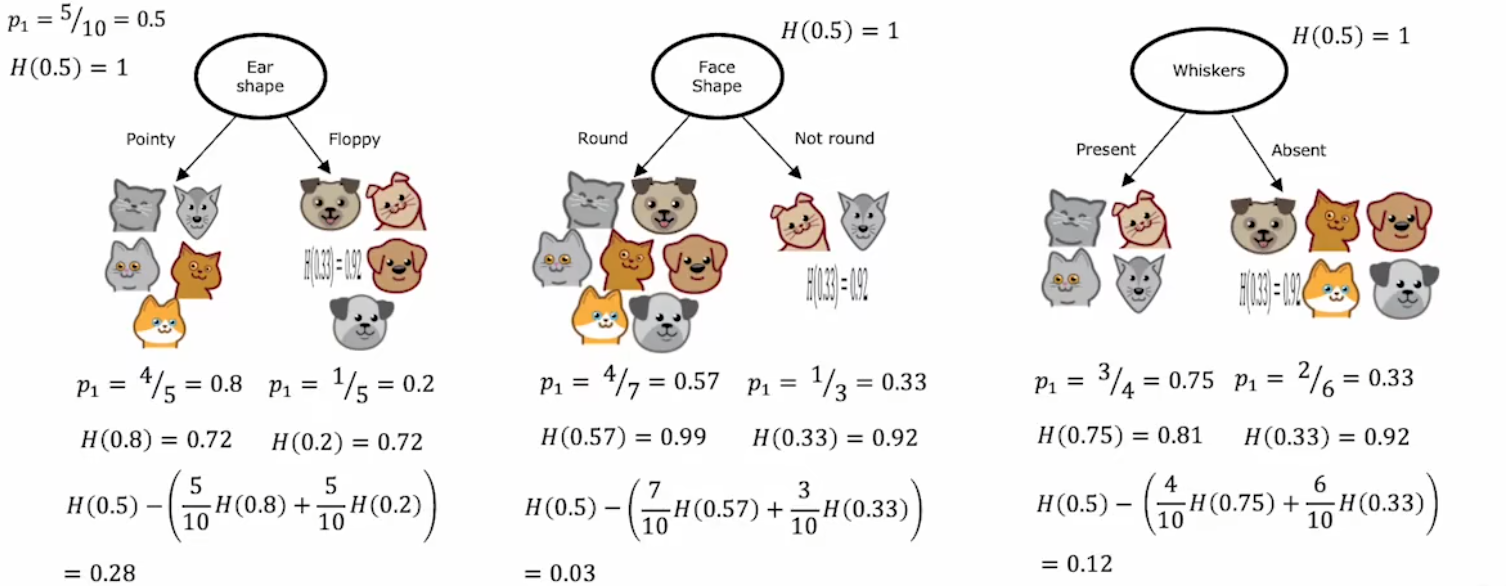
显然,在三种“二元输入特征”中,“Ear shape”的“信息增益”最大,所以选为根节点。
2.2 构建决策树——二元输入特征
构建(二元输入特征)决策树的过程:
- 在根节点,找出最大的“信息增益”所对应的特征,作为拆分标准。
- 创建左右分支,各自找出剩余特征中“信息增益”最大的,作为各自的拆分标准。
- 不断向下进行拆分,直到:
- “熵”为0,也就是完全分类。
- 达到预设的最大深度。可以使用“验证集”选择最合适的深度。
- 所有剩余特征的“信息增益”都低于某个阈值。
- 子集的大小低于某个阈值(某个数)。
注1:停止拆分是为了保证树不会变的太大、太笨重,进而降低过拟合的风险。
注2:上述算法可以使用“递归”。
注3:在构建过程中,左右分支可能会选取相同的特征。

2.3 构建决策树——多元输入特征
若想针对“多元输入特征”构建决策树,可能会有如下针对“二元输入特征”决策树的改进思路:
- 创建多分支【不推荐】。整体思路和前面一样,只不过某些节点可能是多分支,但由于每个输入特征的可选种类不一定相同,这种方法会增加计算难度和代码量。
- 将“多元特征”转换成“独热码(One-hot)”【推荐】:不仅可以继续使用之前二元特征的决策树思路,甚至也可以转换成神经网络的训练模式。
注:由于每个样本的码字中只有一个“1”,所以称之为“独热码”。
比如下面的“耳朵形状(Ear shape)”有三种可能取值“尖的(Pointy)”、“松软的(Floppy)”、“椭圆形的(Oval)”,将其转换成独热码后,相当于将1个“三元输入特征”转化成3个“二元输入特征”,于是我们只需要对训练集进行一小步预处理,即可复用上述“二元输入特征”的思路:

2.4 构建决策树——连续的输入特征
和上一小节类似,也是将“连续输入特征”转换成“二元输入特征”,然后继续进行构建。但不同的是,“多元特征”只需在最开始进行预处理,而在没被当前所在分支使用前,“连续输入特征”需要在每个节点都进行一次计算。具体来说,就是选择一个阈值,依照该阈值对当前节点的集合进行拆分,可以使“信息增益”最大,不同节点所计算的阈值可能不同。于是,就可以将“连续输入特征”转换成判断大小的“二元输入特征”。比如在“识别猫”问题中,引入“重量”这一连续取值的输入特征,由于选取“9”作为阈值可以使“信息增益”最大,于是便将“重量”这一“连续输入特征”,转换成“是否小于等于9磅?”这个“二元输入特征”:

2.5 构建回归树——连续的输出结果(选修)
本小节将“决策树(decision trees)”算法推广到“回归树(regression trees)”,也就是将“决策树”的预测结果扩展到连续的取值。和之前的“拆分后尽可能减少信息的不确定度”类似,“回归树”使用“方差(variance)”来衡量信息的不确定度。于是,拆分后的方差为左右两分支的方差的加权平均,权值也是 左右分支的子集大小 占 拆分前集合大小 的比例。相应的“信息增益”为:
Information gain = V ( s root ) − ( w left V ( s left ) + w right V ( s right ) ) \text{Information gain} = V(s^{\text{root}}) - \left(w^{\text{left}} V(s^{\text{left}}) + w^{\text{right}} V(s^{\text{right}})\right) Information gain=V(sroot)−(wleftV(sleft)+wrightV(sright))
- V ( s root ) V(s^{\text{root}}) V(sroot):拆分前的集合数据的方差。
- w left w^{\text{left}} wleft:拆分后,左分支的集合大小。
- w right w^{\text{right}} wright:拆分后,右分支的集合大小。
- V ( s left ) V(s^{\text{left}}) V(sleft):拆分后,左分支的集合数据的方差。
- V ( s right ) V(s^{\text{right}}) V(sright):拆分后,右分支的集合数据的方差。
注:通信人表示,“信息增益”只是一个泛在的概念,虽然上述定义和2.1节不同,但物理意义相通。
回到“识别猫”问题,现在将“重量”作为需要预测的结果(如下左图)。于是,在每次进行拆分时,就使用“方差”来计算“信息增益”,并选择“信息增益”最大的特征作为当前节点的拆分标准。最后达到终止拆分条件,“决策树”构建完成时,直接使用最终分类的均值作为以后的预测值:
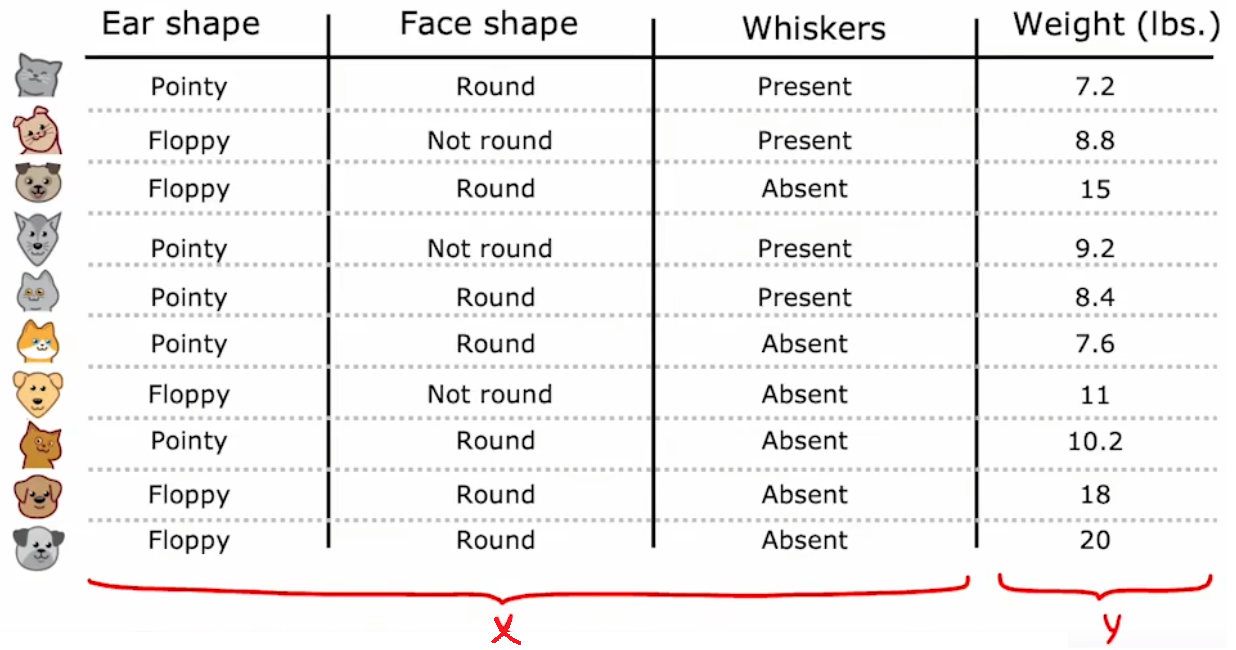
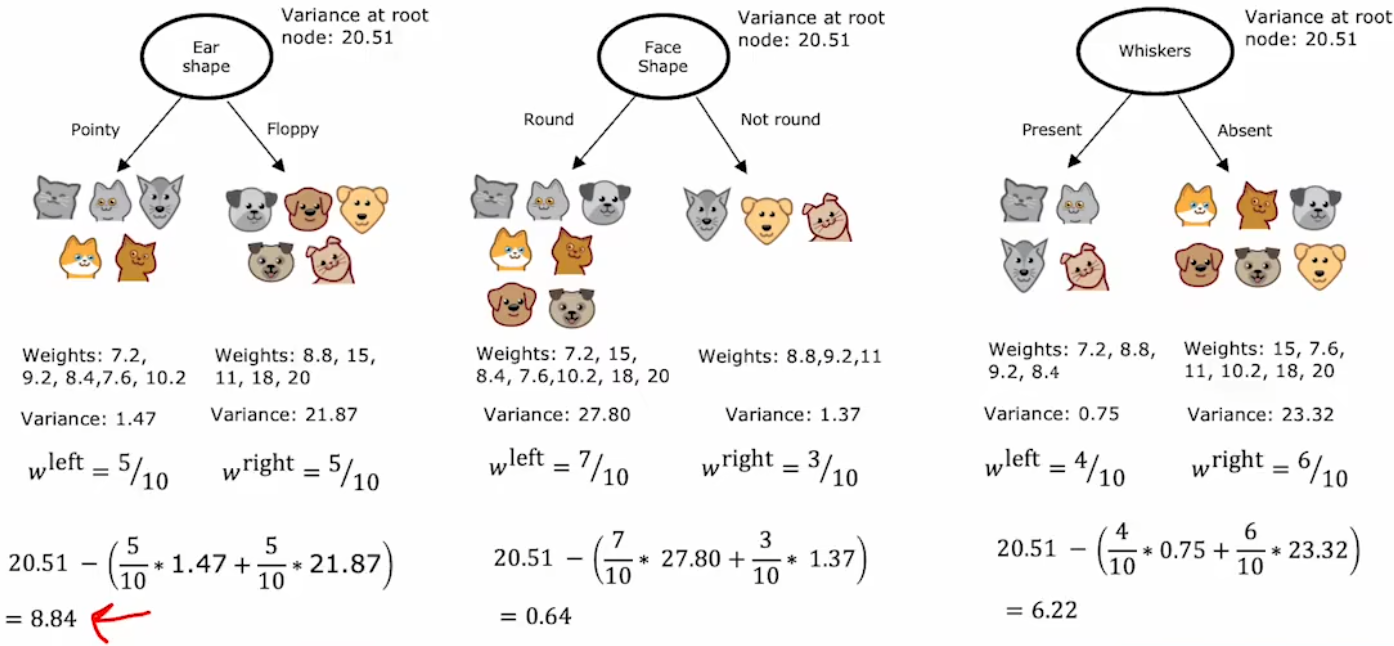
2.6 代码实现-递归构建单个决策树
最后一个小节来使用代码构建单个决策树。注意本练习完全手敲实现前面几节的原理,不调用任何封装好的机器学习库函数,问题要求和代码结构如下:
问题要求:根据下表2-4-1所给出的数据集,构建一个决策树,判断蘑菇是否可以食用。
代码结构:
- 函数1:计算01序列的熵
- 函数2:按照给定特征分割,返回左右子节点的列表
- 函数3:计算信息增益
- 函数4:找到信息增益最大的特征
- 函数5:递归的构建决策树
- 主函数:定义训练集,然后直接调用“函数5”,观察其打印输出的决策树结构。
注1:主函数中还有上述5个子函数的测试代码,在下面代码中被注释,但是代码运行结果中有其正确的测试输出。
注2:本实验来自本周的练习“C2_W4_Decision_Tree_with_Markdown”。
注3:不可将本实验作为实际的可食用蘑菇鉴别标准!!!
| Cap Color 伞盖颜色 | Stalk Shape 茎秆形状 | Solitary 独株? | Edible 可食用? |
|---|---|---|---|
| Brown | Tapering | Yes | 1 |
| Brown | Enlarging | Yes | 1 |
| Brown | Enlarging | No | 0 |
| Brown | Enlarging | No | 0 |
| Brown | Tapering | Yes | 1 |
| Red | Tapering | Yes | 0 |
| Red | Enlarging | No | 0 |
| Brown | Enlarging | Yes | 1 |
| Red | Tapering | No | 1 |
| Brown | Enlarging | No | 0 |
下面是Python代码和打印输出的结果:
import numpy as np
#################################################################################
# 函数1:计算01序列的熵
def compute_entropy(y):
"""
Computes the entropy for
Args:
y (ndarray): Numpy array indicating whether each example at a node is
edible (`1`) or poisonous (`0`)
Returns:
entropy (float): Entropy at that node
"""
# 排除特殊情况
if(len(y)==0):
return 0.0
# 正常计算
p1 = y.sum()/y.size
# print(p1)
if(p1==0 or p1==1):
return 0.0
else:
entropy = -p1*np.log2(p1)-(1-p1)*np.log2(1-p1)
return entropy
#################################################################################
# 函数2:按照给定特征分割,返回左右子节点的列表
def split_dataset(X, node_indices, feature):
"""
Splits the data at the given node into left and right branches
Args:
X (ndarray): Data matrix of shape(n_samples, n_features)
node_indices (ndarray): List containing the active indices. I.e, the samples being considered at this step.
feature (int): Index of feature to split on
Returns:
left_indices (ndarray): Indices with feature value == 1
right_indices (ndarray): Indices with feature value == 0
"""
# 定义列表
left_indices = []
right_indices = []
# 按照给定特征分割
for i in node_indices:
if(X[i][feature]):
left_indices.append(i)
else:
right_indices.append(i)
# 返回左右列表
return left_indices, right_indices
#################################################################################
# 函数3:计算信息增益
def compute_information_gain(X, y, node_indices, feature):
"""
Compute the information of splitting the node on a given feature
Args:
X (ndarray): Data matrix of shape(n_samples, n_features)
y (array like): list or ndarray with n_samples containing the target variable
node_indices (ndarray): List containing the active indices. I.e, the samples being considered in this step.
feature (int): Index of feature to split on
Returns:
cost (float): Cost computed
"""
# 排除意外情况
if(len(node_indices)==0):
return 0.0
# Split dataset
left_indices, right_indices = split_dataset(X, node_indices, feature)
# root entropy
H_root = compute_entropy(y[node_indices])
# Weights
w_left = len(left_indices) / len(node_indices)
w_right = len(right_indices) / len(node_indices)
# Weighted entropy
H_left = compute_entropy(y[left_indices])
H_right = compute_entropy(y[right_indices])
#Information gain
information_gain = H_root - (w_left*H_left + w_right*H_right)
return information_gain
#################################################################################
# 函数4:找到信息增益最大的特征
def get_best_split(X, y, node_indices):
"""
Returns the optimal feature and threshold value to split the node data
Args:
X (ndarray): Data matrix of shape(n_samples, n_features)
y (array like): list or ndarray with n_samples containing the target variable
node_indices (ndarray): List containing the active indices. I.e, the samples being considered in this step.
Returns:
best_feature (int): The index of the best feature to split
"""
best_feature = -1 # 最佳的拆分特征
info_gain = np.array([]) # 所有剩余特征的信息增益
num_features = X.shape[1] # 特征总数
# 遍历计算所有特征对应的信息增益
for i in range(num_features):
info_gain = np.append(info_gain, compute_information_gain(X, y, node_indices, i))
# 找到最大的信息增益并返回
if(info_gain.max() != 0):
best_feature = info_gain.argmax()
return best_feature
#################################################################################
# 函数5:递归的构建决策树
def build_tree_recursive(X, y, node_indices, branch_name, max_depth, current_depth):
"""
Build a tree using the recursive algorithm that split the dataset into 2 subgroups at each node.
This function just prints the tree.
Args:
X (ndarray): Data matrix of shape(n_samples, n_features)
y (array like): list or ndarray with n_samples containing the target variable
node_indices (ndarray): List containing the active indices. I.e, the samples being considered in this step.
branch_name (string): Name of the branch. ['Root', 'Left', 'Right']
max_depth (int): Max depth of the resulting tree.
current_depth (int): Current depth. Parameter used during recursive call.
"""
# Maximum depth reached - stop splitting
if current_depth == max_depth:
formatting = " "*current_depth + "-"*current_depth
print(formatting, "%s leaf node with indices" % branch_name, node_indices)
return
# Otherwise, get best split and split the data
# Get the best feature and threshold at this node
best_feature = get_best_split(X, y, node_indices)
tree = []
tree.append((current_depth, branch_name, best_feature, node_indices))
formatting = "-"*current_depth
print("%s Depth %d, %s: Split on feature: %d" % (formatting, current_depth, branch_name, best_feature))
# Split the dataset at the best feature
left_indices, right_indices = split_dataset(X, node_indices, best_feature)
# continue splitting the left and the right child. Increment current depth
build_tree_recursive(X, y, left_indices, "Left", max_depth, current_depth+1)
build_tree_recursive(X, y, right_indices, "Right", max_depth, current_depth+1)
####################################主函数######################################
# 定义训练集
X_train = np.array([[1,1,1],[1,0,1],[1,0,0],[1,0,0],[1,1,1],[0,1,1],[0,0,0],[1,0,1],[0,1,0],[1,0,0]])
y_train = np.array([1,1,0,0,1,0,0,1,1,0])
# print ('The shape of X_train is:', X_train.shape)
# print ('The shape of y_train is: ', y_train.shape)
# print ('Number of training examples (m):', len(X_train))
# 有效样本的索引
root_indices = [0, 1, 2, 3, 4, 5, 6, 7, 8, 9] # 全部包括则表示全有效
# 递归构建决策树
build_tree_recursive(X_train, y_train, root_indices, "Root", max_depth=2, current_depth=0)
# # 测试函数:计算熵
# print("\n测试函数:计算熵")
# print("Entropy at root node: ", compute_entropy(y_train))
# # 测试函数:给定特征拆分
# print("\n测试函数:给定特征拆分")
# feature = 0
# left_indices, right_indices = split_dataset(X_train, root_indices, feature)
# print("Left indices: ", left_indices)
# print("Right indices: ", right_indices)
# # 测试函数:给定特征,计算信息增益
# print("\n测试函数:给定特征,计算信息增益")
# info_gain0 = compute_information_gain(X_train, y_train, root_indices, feature=0)
# print("Information Gain from splitting the root on brown cap: ", info_gain0)
# info_gain1 = compute_information_gain(X_train, y_train, root_indices, feature=1)
# print("Information Gain from splitting the root on tapering stalk shape: ", info_gain1)
# info_gain2 = compute_information_gain(X_train, y_train, root_indices, feature=2)
# print("Information Gain from splitting the root on solitary: ", info_gain2)
# # 测试函数:计算信息增益最大的特征
# print("\n测试函数:计算信息增益最大的特征")
# best_feature = get_best_split(X_train, y_train, root_indices)
# print("Best feature to split on: %d" % best_feature)
Depth 0, Root: Split on feature: 2
- Depth 1, Left: Split on feature: 0
-- Left leaf node with indices [0, 1, 4, 7]
-- Right leaf node with indices [5]
- Depth 1, Right: Split on feature: 1
-- Left leaf node with indices [8]
-- Right leaf node with indices [2, 3, 6, 9]
测试函数:计算熵
Entropy at root node: 1.0
测试函数:给定特征拆分
Left indices: [0, 1, 2, 3, 4, 7, 9]
Right indices: [5, 6, 8]
测试函数:给定特征,计算信息增益
Information Gain from splitting the root on brown cap: 0.034851554559677034
Information Gain from splitting the root on tapering stalk shape: 0.12451124978365313
Information Gain from splitting the root on solitary: 0.2780719051126377
测试函数:计算信息增益最大的特征
Best feature to split on: 2
本节 Quiz:
At a given node of a decision tree, , 6 of 10 examples are cats and 4 of 10 are not cats. Which expression calculates the entropy H ( p 1 ) H(p_1) H(p1) of this group of 10 animals?
× − ( 0.6 ) l o g 2 ( 0.6 ) − ( 1 − 0.4 ) l o g 2 ( 1 − 0.4 ) -(0.6)log_2(0.6)-(1-0.4)log_2(1-0.4) −(0.6)log2(0.6)−(1−0.4)log2(1−0.4)
× ( 0.6 ) l o g 2 ( 0.6 ) + ( 0.4 ) l o g 2 ( 0.4 ) (0.6)log_2(0.6)+(0.4)log_2(0.4) (0.6)log2(0.6)+(0.4)log2(0.4)
× ( 0.6 ) l o g 2 ( 0.6 ) + ( 1 − 0.4 ) l o g 2 ( 1 − 0.4 ) (0.6)log_2(0.6)+(1-0.4)log_2(1-0.4) (0.6)log2(0.6)+(1−0.4)log2(1−0.4)
√ − ( 0.6 ) l o g 2 ( 0.6 ) − ( 0.4 ) l o g 2 ( 0.4 ) -(0.6)log_2(0.6)-(0.4)log_2(0.4) −(0.6)log2(0.6)−(0.4)log2(0.4)Before a split, the entropy of a group of 5 cats and 5 non-cats is H ( 5 10 ) H(\frac{5}{10}) H(105). After splitting on a particular feature, group of 7 animals (4 of which are cats) has an entropy of H ( 4 7 ) H (\frac{4}{7}) H(74). The other group of 3 animals (1 is a cat) and has an entropy of H ( 1 3 ) H(\frac{1}{3}) H(31). What is the expression for information gain?
× H ( 0.5 ) − ( 7 ∗ H ( 4 7 ) + 3 ∗ H ( 1 3 ) ) H(0.5)-(7*H(\frac{4}{7})+3*H(\frac{1}{3})) H(0.5)−(7∗H(74)+3∗H(31))
√ H ( 0.5 ) − ( 7 10 H ( 4 7 ) + 3 10 H ( 1 3 ) ) H(0.5)-(\frac{7}{10}H(\frac{4}{7})+\frac{3}{10}H(\frac{1}{3})) H(0.5)−(107H(74)+103H(31))
× H ( 0.5 ) − ( H ( 4 7 ) + H ( 1 3 ) ) H(0.5)-(H(\frac{4}{7})+ H(\frac{1}{3})) H(0.5)−(H(74)+H(31))
× H ( 0.5 ) − ( 4 7 H ( 4 7 ) + 1 3 H ( 1 3 ) H(0.5)-(\frac{4}{7}H(\frac{4}{7})+\frac{1}{3}H(\frac{1}{3}) H(0.5)−(74H(74)+31H(31)To represent 3 possible values for the ear shape, you can define 3 features for ear shape: pointy ears, floppy ears, oval ears. For an animal whose ears are not pointy, not floppy, but are oval, how can you represent this information as a feature vector?
× [1,1,0]
× [1,0,0]
× [0,1,0]
√ [0,0,1]For a continuous valued feature (such as weight of the animal), there are 10 animals in the dataset. According to the lecture, what is the recommended way to find the best split for that feature?
× Use a one-hot encoding to turn the feature into a discrete feature vector of 0’s and 1’s, then apply the algorithm we had discussed for discrete features.
√ Choose the 9 mid-points between the 10 examples as possible splits, and find the split that gives the highest information gain.
× Try every value spaced at regular intervals (e.g. 8, 8.5, 9, 9.5, 10, etc.) and find the split that gives the highest information gain.
× Use gradient descent to find the value of the split threshold that gives the highest information gain.Which of these are commonly used criteria to decide to stop splitting? (Choose two.)
√ When the number of examples in a node is below a threshold.
× When a node is 50% one class and 50% another class (highest possible value of entropy).
√ When the tree has reached a maximum depth.
× When the information gain from additional splits is too large.
3. 决策树集合
上一节已经详细的讨论了如何构建单个“决策树”。事实上,如果训练很多“决策树”组成“决策树集合(dicision tree ensemble)”,那么会得到更准确、更稳定的预测结果。下面就来介绍几种构建“决策树集合”的方法。
3.1 使用决策树集合
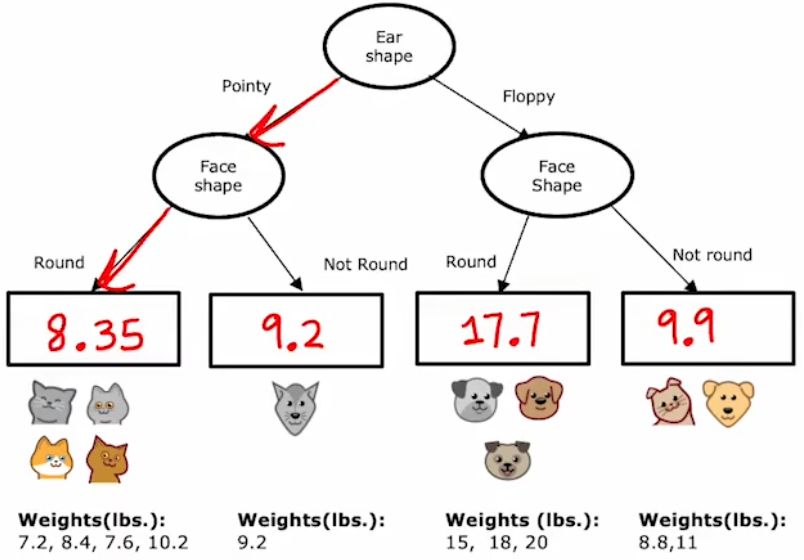
使用单个决策树完成任务时,有一个很大的缺点:单个决策树对于训练集的微小变化非常敏感。比如下图中,只是替换了训练集中的单个样本,就导致训练出完全不一样的决策树:
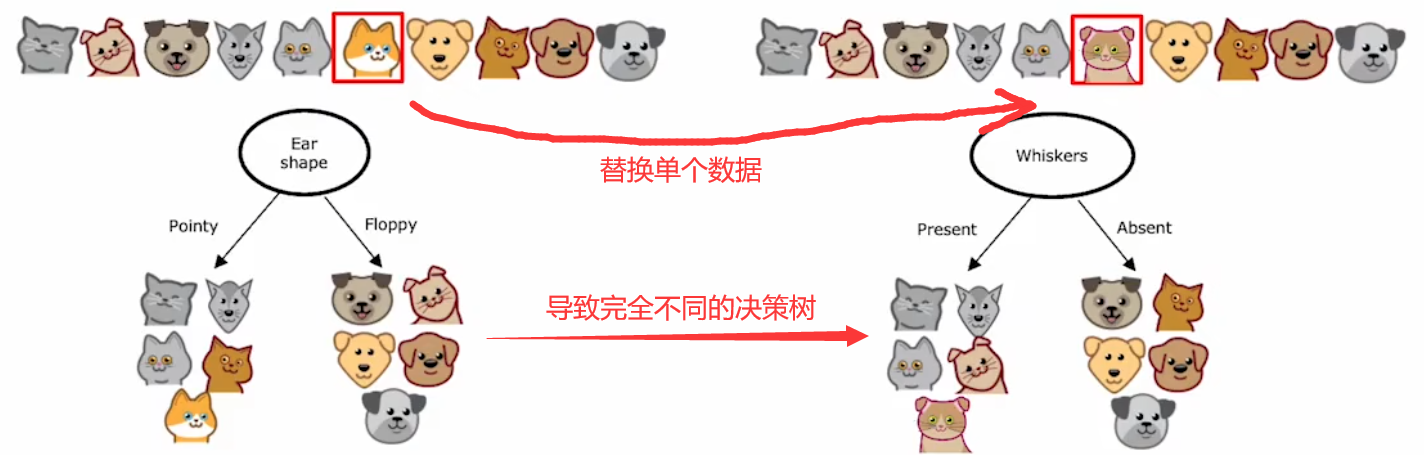
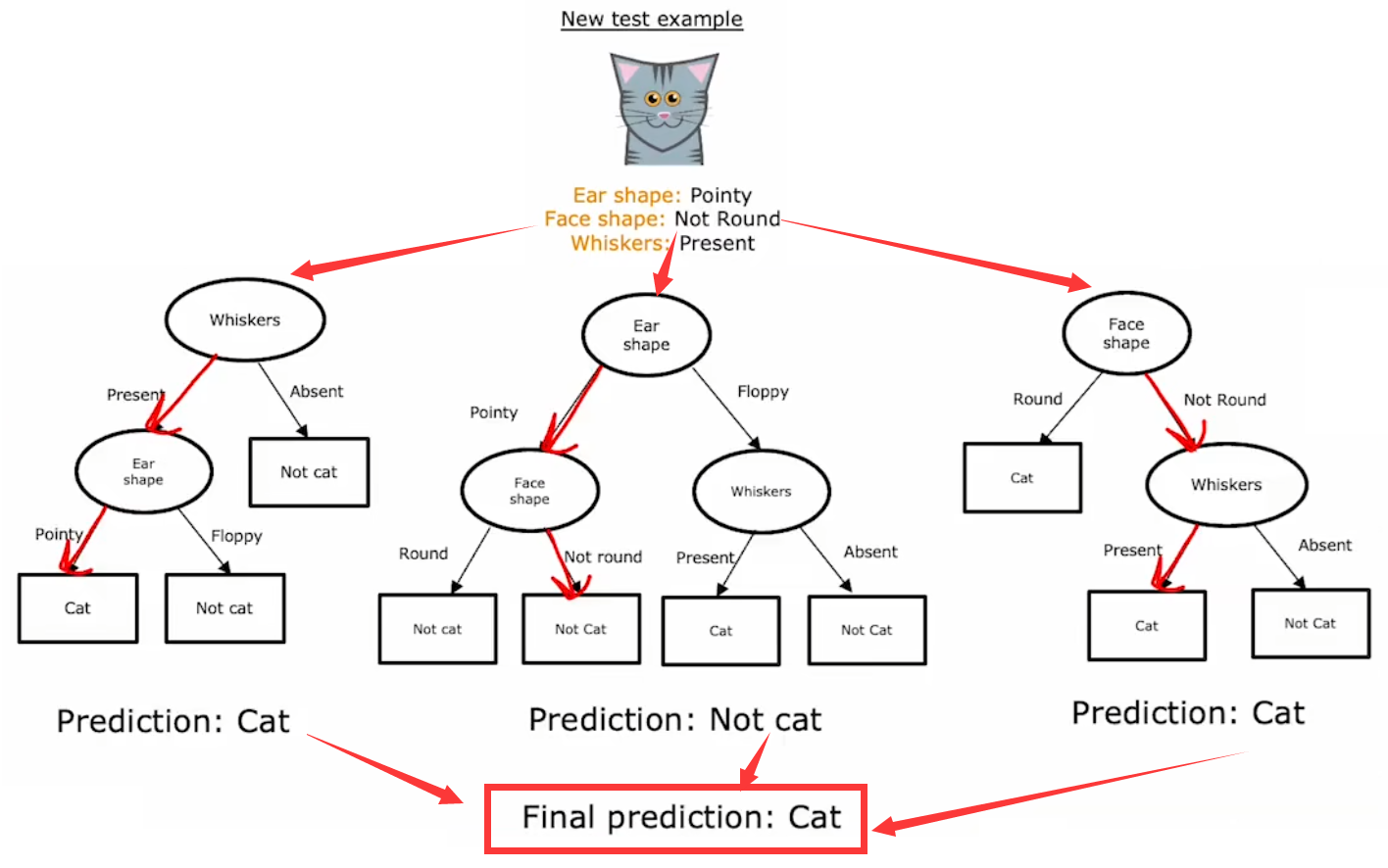
对于一个新的输入,不同的决策树很可能会有不同的预测结果。于是为了使算法更强壮,我们就需要创建不同的训练集,构建出不同的决策树组成“决策树集合(dicision tree ensemble)”。对于新的输入,使用这个“决策树集合”对所有输出结果进行投票,选择最有可能的结果,于是就可以降低算法对于单个决策树的依赖程度,也就可以降低了对于数据的敏感程度:
下面三小节就来介绍三种常见的构建“决策树集合”的方法,主要区别在于单个决策树的训练集选择策略不同。
3.2 袋装决策树
最简单的构建不同训练集的方法,就是“有放回抽样(sampling with replacement)”。假设原始训练集大小为 m m m,每次训练前都随机地有放回抽取 m m m 次样本,作为本次的训练集:
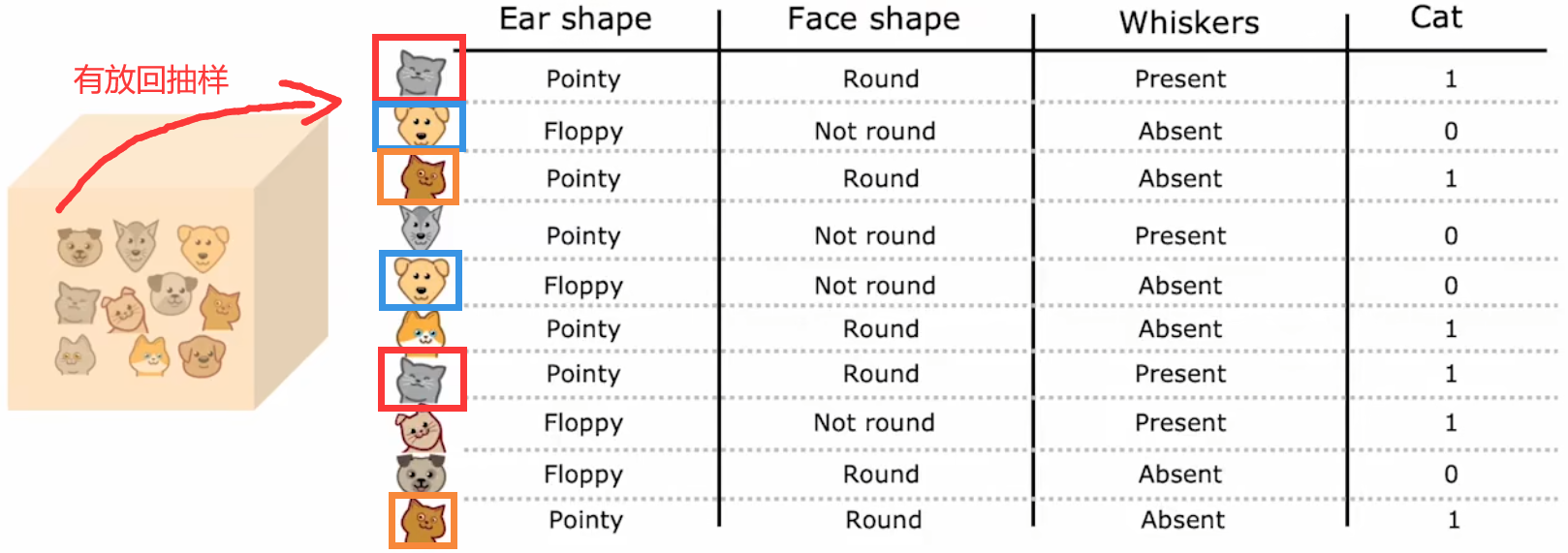
于是我们便可以创建出,有微小不同的多个训练集。注意到,单次的抽取结果中,可以有重复的样本。上面这种方法就称为“袋装决策树(bagged decision tree)”:
“袋装决策树”创建方法:
- 假设原始训练集大小为 m m m,并且“决策树集合”的大小为 B B B (bag),于是
for b = 1 to B: 1. 从原始训练集有放回抽取m次,形成本次训练集。 2. 然后使用该训练集训练单个决策树。注: B B B 一般取64~128,选取更大的 B B B 可能会提升算法性能,但当 B B B 超过100后就不会有太大的性能增益。
3.3 随机森林
“袋装决策树”有个缺点,就是很多决策树在根节点或者根节点附近的区域都非常相似。于是为了避免这个问题,在上述“袋装决策树”的基础上,训练单个决策树时,对于每个节点都会从
n
n
n 个特征中随机选取
k
k
k 个特征组成子集,然后在这个子集中选取最大的“信息增益”(
k
<
n
k<n
k<n)。一般来说,都会取
k
=
n
k=\sqrt{n}
k=n。于是,每次的训练集都是随机选取的,单个决策树的每个节点特征都是从随机选取的子集中选取的,这便称为“随机森林(random forest)”。
正是这些由“随机选取”产生的微小变动组合在一起,使得“随机森林”比单个决策树更加健壮,于是训练集的任何微小变化都不会对随机森林的输出有太大的影响。
“随机森林”创建方法:
- 假设原始训练集大小为 m m m、特征总数为 n n n、“决策树集合”的大小为 B B B (bag),于是
for b = 1 to B: 1. 从原始训练集有放回抽取m次,形成本次训练集。 2. 然后使用该训练集训练单个决策树。 选择单个节点拆分标准时,随机选取k个特征进行计算。注1: B B B 一般取64~128,选取更大的 B B B 可能会提升算法性能,但当 B B B 超过100后就不会有太大的性能增益。
注2:一般取 k = n k=\sqrt{n} k=n。
【轻松一刻】Where does a machine learning engineer go camping? Answer: In a random forest.
3.4 XGBoost算法
下面介绍比“随机森林(Random forest)”更强的算法——梯度提升树(Gradient boost tree)。每次抽取新的训练集时,都以更高概率选择上一次决策树训练出错的样本。这就是“增强(boosting)”的含义,类似于“刻意练习”。具体的增加多少概率的数学过程是非常复杂的,本课程不过多讨论,会用就行。“XGBoost(eXtreme Gradient Boosting, 极限梯度提升算法)”就是“梯度提升树”的一种,下面是其特点:
- XGBoost已经集成好开源库,调用简单。
- 非常快速和高效。
- 内置了选择单次训练集的方法,所以无需手动为每次训练生成训练集。
- 对于“拆分标准”、“停止拆分标准”有很好的默认选项。
- 内置了正则化防止过拟合。
- 机器学习竞赛中表现出色,如Kaggle。“XGBoost”和“深度学习”算法是在竞赛表现优异的两大算法。
多年以来,研究人员提出了很多构建决策树、选取决策树样本的方法。迄今为止,构建决策树集合最常用的方法就是“XGBoost算法”。它运行速度快、开源、易于使用,在很多机器学习比赛、商业应用中广泛使用。XGBoost的内部实现原理非常复杂,所以大家都是直接调用封装好的XGBoost库:
# 分类问题
from xgboost import XGBClassfier
model = XGBClassfier()
model.fit(X_train, y_train)
y_pred = model.predict(X_test)
# 回归问题
from xgboost import XGBRegressor
model = XGBRegressor()
model.fit(X_train, y_train)
y_pred = model.predict(X_test)
3.5 何时使用决策树
本周最后一小节来总结一下“决策树/决策树集合”、“神经网络”各自的适用场景:
决策树/决策树集合:
- 适用于“结构化数据”,如“房价预测”问题。不建议处理“非结构化数据”,如“图像”、“视频”、“音频”、“文本”等。并且可以处理分类问题、回归问题。
- 训练速度非常快。
- 对于人类来说更容易理解,比如小型的决策树可以直接打印出来查看决策过程。
- 缺点是一次只能训练一个决策树,且不支持传统的迁移学习。
神经网络:
- 适合处理所有类型的数据,无论是“结构化数据”还是“非结构化数据”,或者是两者的混合数据。也可以处理分类问题、回归问题。
- 训练速度较慢。
- 使用迁移学习可以快速完成“预训练”。
- 可连接性好。几个神经网络可以很容易的串联或并联在一起,组成一个更大的模型进行训练。
注1:老师建议训练“决策树”时直接调用XGBoost库,尽管可能会需要更多的运算资源,但是非常快捷、准确。
注2:“结构化数据”指的是那些可以使用电子表格表示的数据。
本节 Quiz:
For the random forest, how do you build each individual tree so that they are not all identical to each other?
× Train the algorithm multiple times on the same training set. This will naturally result in different trees.
× Sample the training data without replacement.
× If you are training B B B trees, train each one on 1 / B 1/B 1/B of the training set, so each tree is trained on a distinct set of examples.
√ Sample the training data with replacement.You are choosing between a decision tree and a neural network for a classification task where the input x x x is a 100x100 resolution image. Which would you choose?
√ A neural network, because the input is unstructured data and neural networks typically work better with unstructured data.
× A neural network, because the input is structured data and neural networks typically work better with structured data.
× A decision tree, because the input is unstructured and decision trees typically work better with unstructured data.
× A decision tree, because the input is structured data and decision trees typically work better with structured data.What does sampling with replacement refer to?
× It refers to using a new sample of data that we use to permanently overwrite (that is, to replace) the original data.
√ Drawing a sequence of examples where, when picking the next example, first replacing all previously drawn examples into the set we are picking from.
× Drawing a sequence of examples where, when picking the next example, first remove all previously drawn examples from the set we are picking from.
× It refers to a process of making an identical copy of the training set.