背景
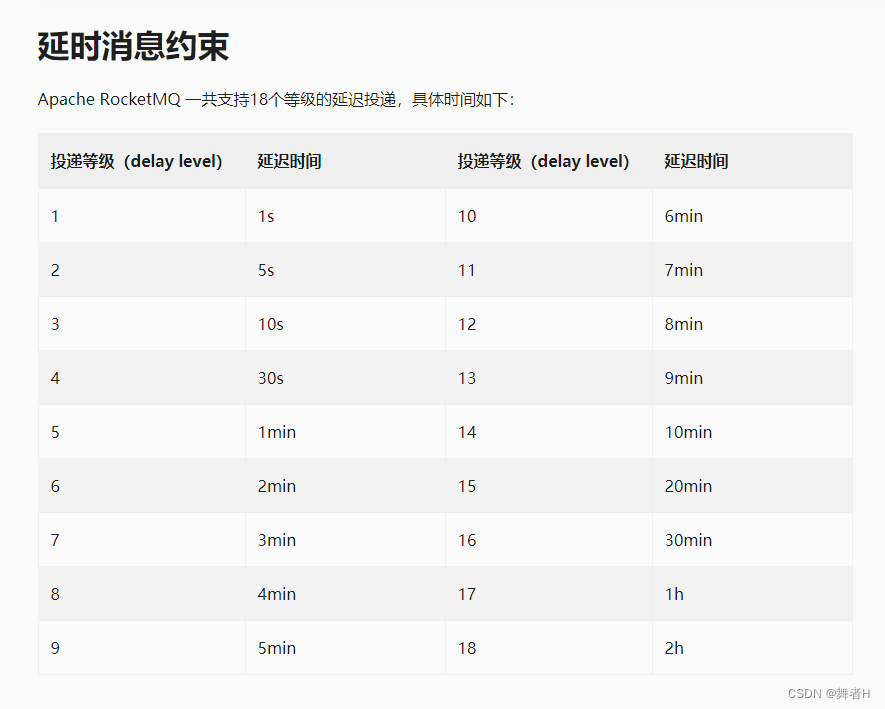
公司所用消息队列为RoucketMQ,版本为4.x。最近公司有业务需要,将某个处理延迟到第二天的白天再进行。由于4.x版本队列,默认延时时间是按等级来延时的,默认有18个等级,如下图:
默认的延时等级,无法满足延时任意时间的需要,所以现有的实现方式,是采用:延时队列+时间轮。延时队列可以延时指定等级的时间,当剩余时间小于1min时,再封装成定时任务,投递给netty中的时间轮来处理。然而当延时时间超过2H时,单次的延时队列已无法满足(默认最高2H),此时现有方案是递归的方式,继续延迟(当然也可以增加延时等级,减少递归次数)。实现方案如下图(以延时1.5H为例):

在已有的延时业务下,通常都是短时间延迟,2H之内,所以以上方案未出现较大问题。
发现问题
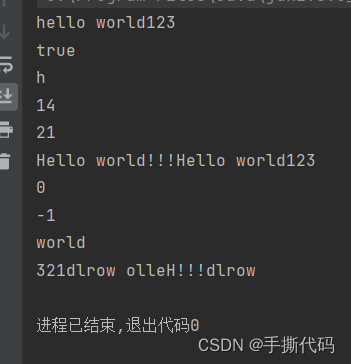
最近新增了业务需求,要求延时到第二天,例如延时20H,继续使用了上述方案,但后继续通过MQ的Console发现,延时队列的消息积压非常严重,数量远超出业务数量。然后开始通过ELK查看消息的消费日志,发现UUID标识的唯一消息,重复消费较严重,如下图:

排查问题
图中只是重复消费的一部分,实际重复消费很严重,单条消息被重复消费了上万次(还好是在测试环境,生产不敢想象【狗头】)。
然后,就准备从重复消费入手,未何会重复消费这么多次呢,查看mq的消费重试次数
RetryTimesSendFailed=2,意思是第一次消费未返回成功的话(未消费成功的原因有多种,可以另外查阅),会再进行两次重试,那就是会进行一次消费最多消费3次。
通过上述延时方案图发现,当延时2H后,剩余时间仍超过60S时,会递归再进行延时2H,以此类推,那么问题就来了:如果以此延时重复消费3次,那么递归一次,原本重复的每次再重复3次,就是重复3*3=9次;第二次递归,就是重复3*3*3=27次;第三次递归就是3*3*3*3=81次……。随着递归次数增加,重复消费次数指数级增长,想想就阔怕。
通过上图的日志图,每个时间点的重复消费次数:1、3、9、27……也验证了上述的推理。
解决问题
那既然找到了上述重复消费的原因,我们也可以针对性的采取一些措施来应对,以下是想到一些初步举措,后续可能结合具体情况再做优化;
- 如果消息消费的可靠性不是要求特别高,或者有其他补偿机制,最快速的方式,直接配置RetryTimesSendFailed=0,这样就没有重试,因而也就没有重复消费,即使递归延时也不影响。
- 通常情况下,可能不方便关闭重试,那就可以在消费时,进行幂等控制。这样即使进行重复消费,也只有一条消息正常消费执行。
- 如果只是采取第2条的话,由于递归次数没变,可能还是会存在一定数量的重复消费。我们可以扩展MQ默认的延时等级,比如增加5H/10H/20H/40H的延时等级,这样可以减少递归延时的重试次数,进而减少重复消费次数。
- 如果运维层面支持的话,我们也可以将RocketMQ升级为5.x版本,这个版本是支持任务时间的延时的,所以就不用自行扩展通过递归的方式来延时了。
思考总结
通过上述分析,这次出现的重复消费的问题,还是挺严重,但幸好还是在测试环境,发生在了生产,估计都得提桶跑路了。通过上述问题排查,也总结了一些日常要注意的地方:
- 使用消息队列时,考虑可能出现的常见问题:重复消费,消息积压、消息丢失等;充分测试确保不会出现上述问题;
- 慎重使用递归、死循环;我们相信正常流程执行的话,递归和死循环是不会有大问题的;但根据墨菲定律,虽然意外情况概率小,但仍可能出现。所以使用递归、死循环时,一定要慎重,考虑各种意外场景,且考虑中断策略。
- 测试要覆盖实际业务场景,像上述问题,如果测试为了快速验证测试结果,只是延时了几分钟,那么递归延迟就不会触发,问题也不会再测试环境暴露。所以测试要全面,保证覆盖实际的业务场景
- 技术层面,我们需要重复理解学习所用的技术栈,如果不能知其所以然,那么一些容易出问题的地方,可能就会被我们所忽略,进而导致更大的问题。