前言
大家都知道在大模型时代,数据有多么重要,质量多高都不过分!甚至直接决定着最终的效果。
尤其做SFT,模型框架基本不用改(事实上也改不动),如何做一份符合自己场景高质量的SFT数据成了唯一且核心的工作。
之前笔者已经写过几篇来强调数据的重要性以及业界如何自动做数据的文章,比较有参考性,感兴趣的小伙伴可以穿梭:
《大模型时代下数据的重要性》:https://zhuanlan.zhihu.com/p/639207933
《大模型SFT微调指令数据的生成》:https://zhuanlan.zhihu.com/p/650596719
《怎么更好的训练一个会数学推理的LLM大模型呢?》:https://zhuanlan.zhihu.com/p/656665345
今天再给大家带来三篇如何自动筛选高质量数据的文章以及穿插在中间的笔者自己的一些讨论。
总的来说这些paper都是做SFT数据比较有参考意义的,大家可以收藏反复琢磨研究进而抽象理论。
MoDS: Model-oriented Data Selection for Instruction Tuning
论文地址:https://arxiv.org/pdf/2311.15653.pdf
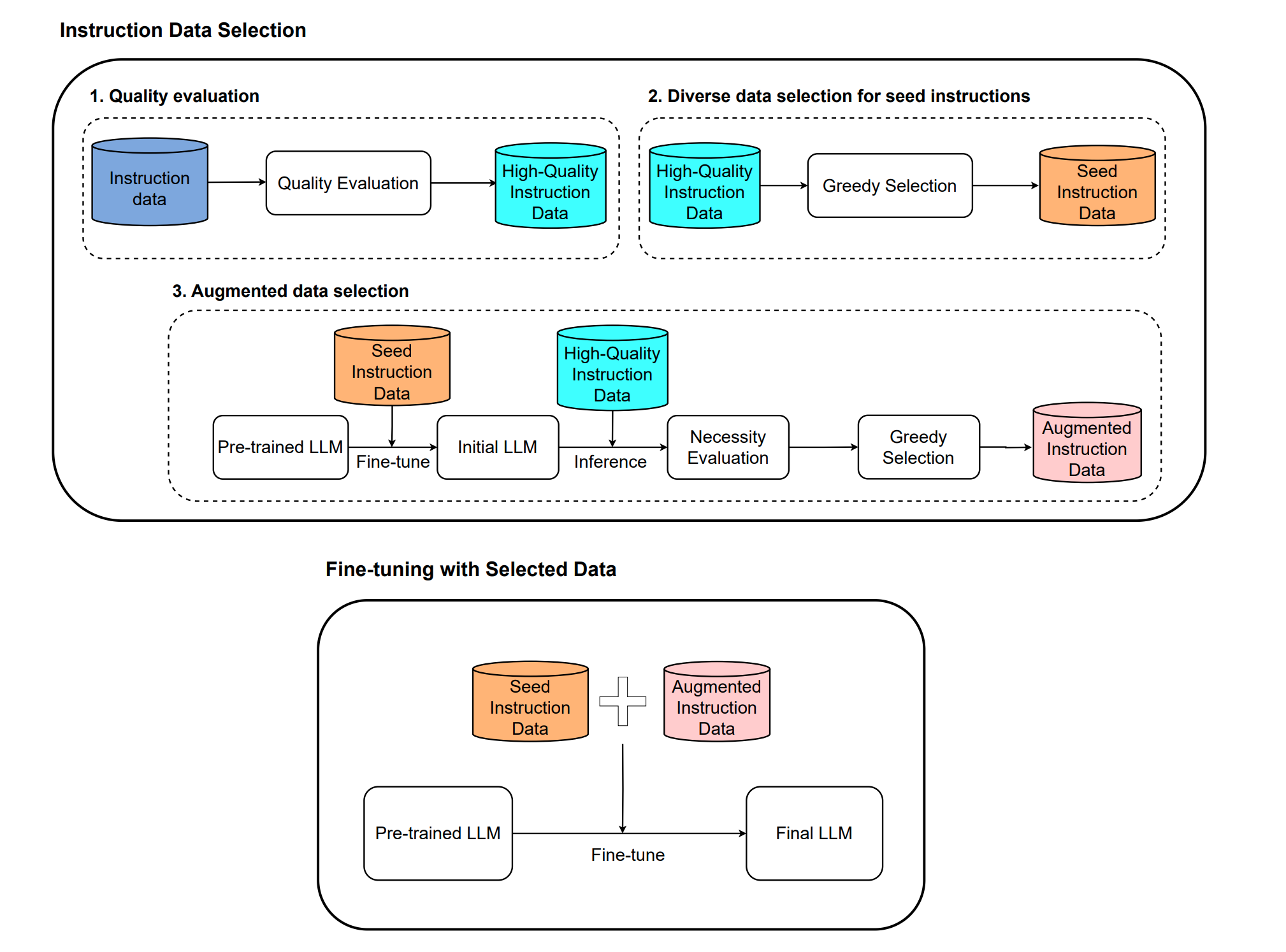
注意这篇文章的出发点是在给定一个LLM的前提下,如何筛选出适合当前给定这个LLM的高质量数据,也就是说高质量是和模型深度绑定的,这也是比较trick的做法。适合自己的才是最好的,对于不同的模型想要学好,可能需要的数据是不完全一样的。
(1)标准
为了更具体量化什么是“高质量”,作者归纳了下面三个方面:
(a)质量: 高质量的prompt以及对应的高质量response可以很好的让模型学会遵循指令。
(b)覆盖率: prompt的多样性,越多样性越好
(c)必要性: 同一条prompt对不同基座模型的重要度和必要性是不一样的,如果一条prompt对于基座来说已经很好的输出response了,也就是说模型已经很好的遵循prompt了,不需要再训练了,相反则是模型需要的。
其中必要性这里是非常重要的,这也是为啥有一个很强的基座只需要很少很少的SFT数据就行了,大部分都能cover,而一个比较差的基座模型对很多prompt都天然不理解,也就需要海量的SFT数据来弥补自身天然的缺陷。总的来说前期不努力,后期就要努力,前期努力了后期也就会省事很多。
(2)具体筛选做法
好了,言归正传,既然定义好了上面三个维度,下面作者就逐个针对性的进行筛选
- (a)Quality Evaluation
这部分主要就是基于模型打分筛选出高质量的SFT数据,具体的作者使用的模型是OpenAssistant/reward-model-deberta-v3-large-v2
链接为https://huggingface.co/OpenAssistant/reward-model-deberta-v3-large-v2/tree/main
部分打分case如下:
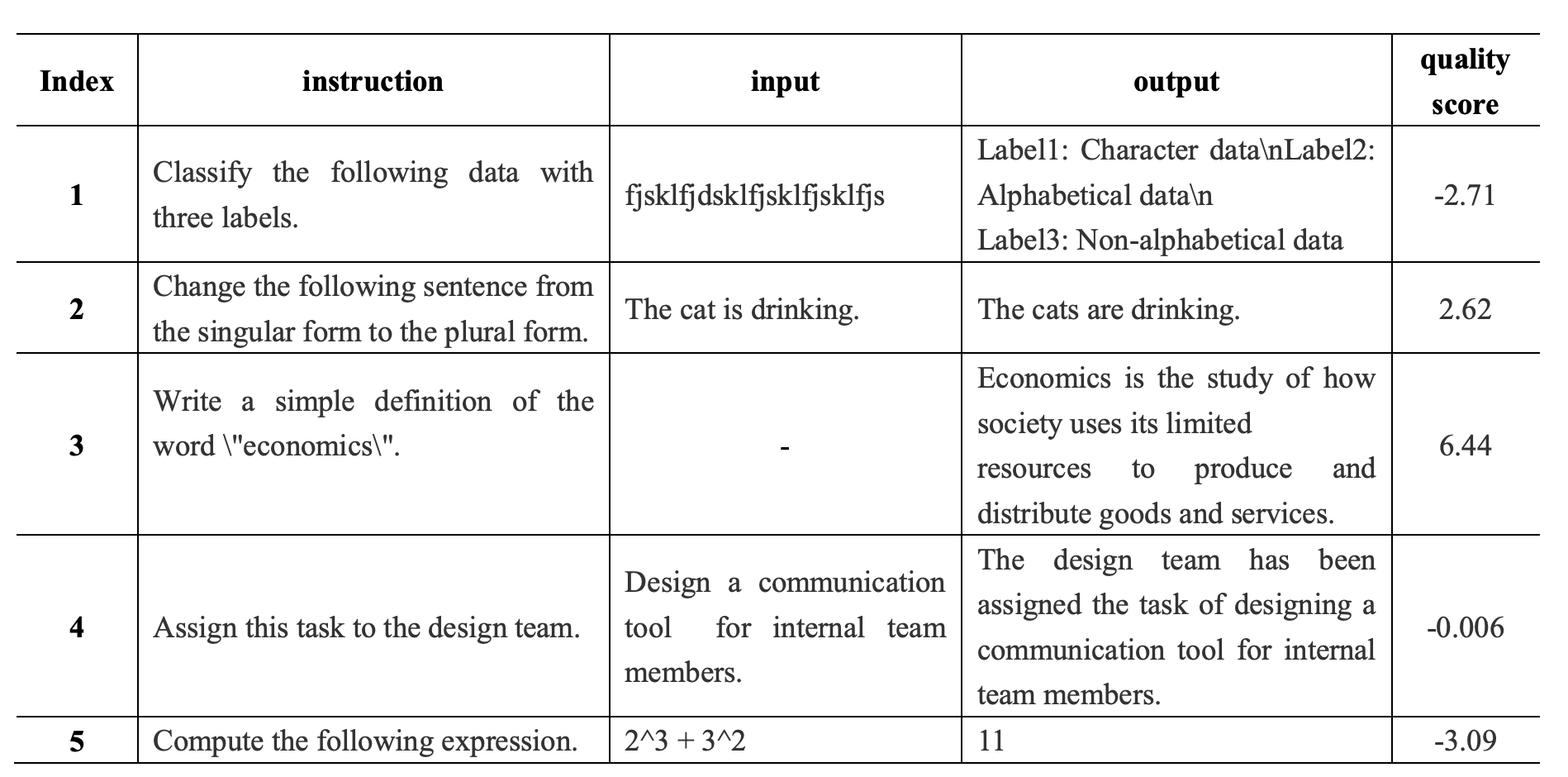
分数越高认为质量越高,最终是会选取一个门限值作为过滤。最终过滤得到High-Quality Instruction Data
不过笔者认为想要一个好的打分模型是非常难的,类似PPO中的reward model, 纠结什么是好?一份高质量的训练reward model的数据本身也是一个难题,而且reward model本身也不应该太小,应该和待最终训练的SFT模型规模大小相等甚至更大才能保证是“老师”给“学生”打分,一个好的reward model也是LLM的核心壁垒,甚至笔者认为,如果有一个好的打分模型就有了LLM的半壁江山,可以用来做评估、筛选数据等等用处,现在大家基本还是用GPT4来打分。
如果想训练某一个垂直方向的reward model,还可以针对性的准备样本,因为什么是“好”比较明确定义比如安全、比如做对题。如果想做一个通用的reward model,这件事本身难度就非常高甚至目前就不可行,因为通用的“好”到底是什么本身就很难定义,太多标准和维度了,就算你定义了几个标准,把他认为是通用的了,甚至包含想了很多很多维度,但是终究还是不能包含全部,总会有遗漏,更不用说该这么具体落地准备样本了,比较难。
- (b)Diverse Data Selection for Seed Instrucitons
经过上面过滤,可以得到一份高质量的SFT数据即High-Quality Instruction Data,本节的目的就是在这份高质量SFT数据集中继续过滤出一个子集,该子集的多样性要足够好,能表征整个数据集。
作者具体采用的手段就是k-Center Greedy算法

核心做法就是首先选一个初始点,然后每次迭代都选取离当前中心集合最远的点,最终得到一份Seed Instruction Data
- (c) Augmented Data Selection
正如前面考虑的必要性,Seed Instruction Data中的每条prompt对模型来说不一定都是需要的,同样被Diverse Data Selection for Seed Instrucitons阶段过滤掉的样本也不一定是模型不需要的。
为此作者先用Seed Instruction Data训练了一下模型,然后用该模型去对High-Quality Instruction Data中的prompt进行推理得到response,然后同样用reward-model-deberta-v3-large-v2去打分筛选出得分低的那些样本,这些样本就是模型处理不好的,言外之意就是模型需要的样本,作者把这部分新筛选出了的样本叫做 augmented dataset
(3)训练模型和结果
作者使用Seed Instruction Data + augmented dataset 来训练模型,具体的作者选用的初始数据是Alpaca、HC3、alpaca-evol-instruct等等混合而成,最终得到一份量级为214526的数据集。
测试集的选取的也是来着Self-instruct、LIMA等多个知名开源数据集。最终的打分借助的是GPT4打分。
作者训练的是Llama2,结果如下:
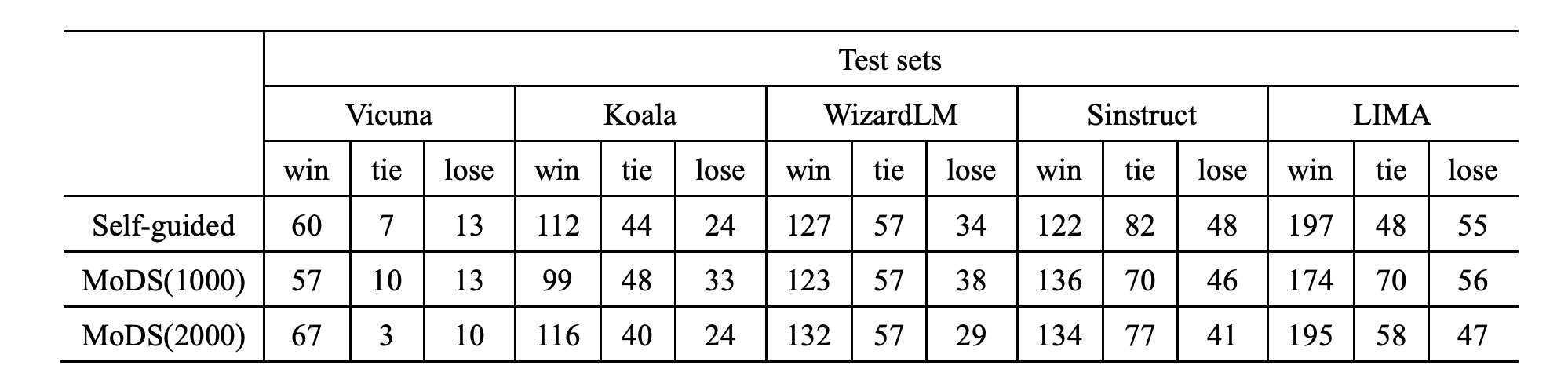
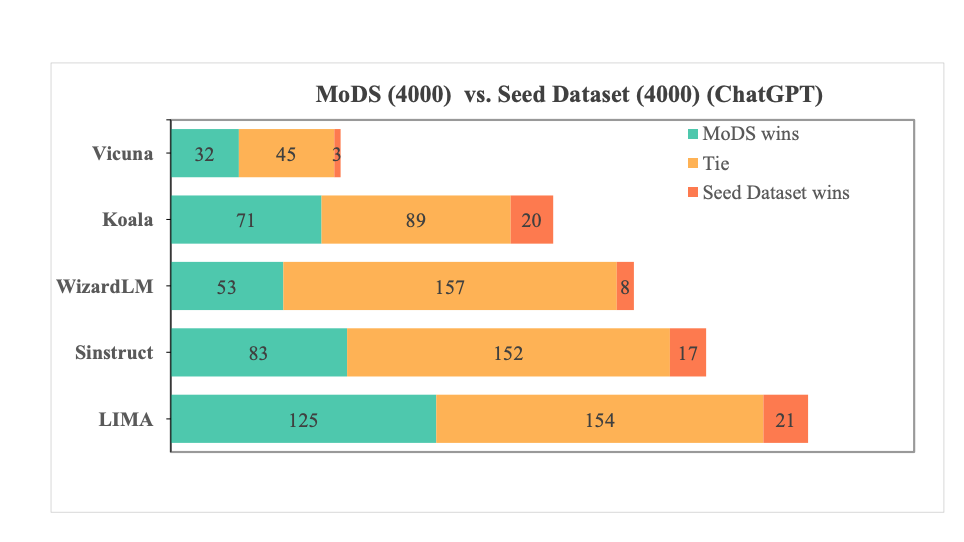
最终筛选过后的4k数据就能达到不错的效果。
Active Instruction Tuning: Improving Cross-Task Generalization by Training on Prompt Sensitive Tasks
论文地址:https://arxiv.org/pdf/2311.00288.pdf
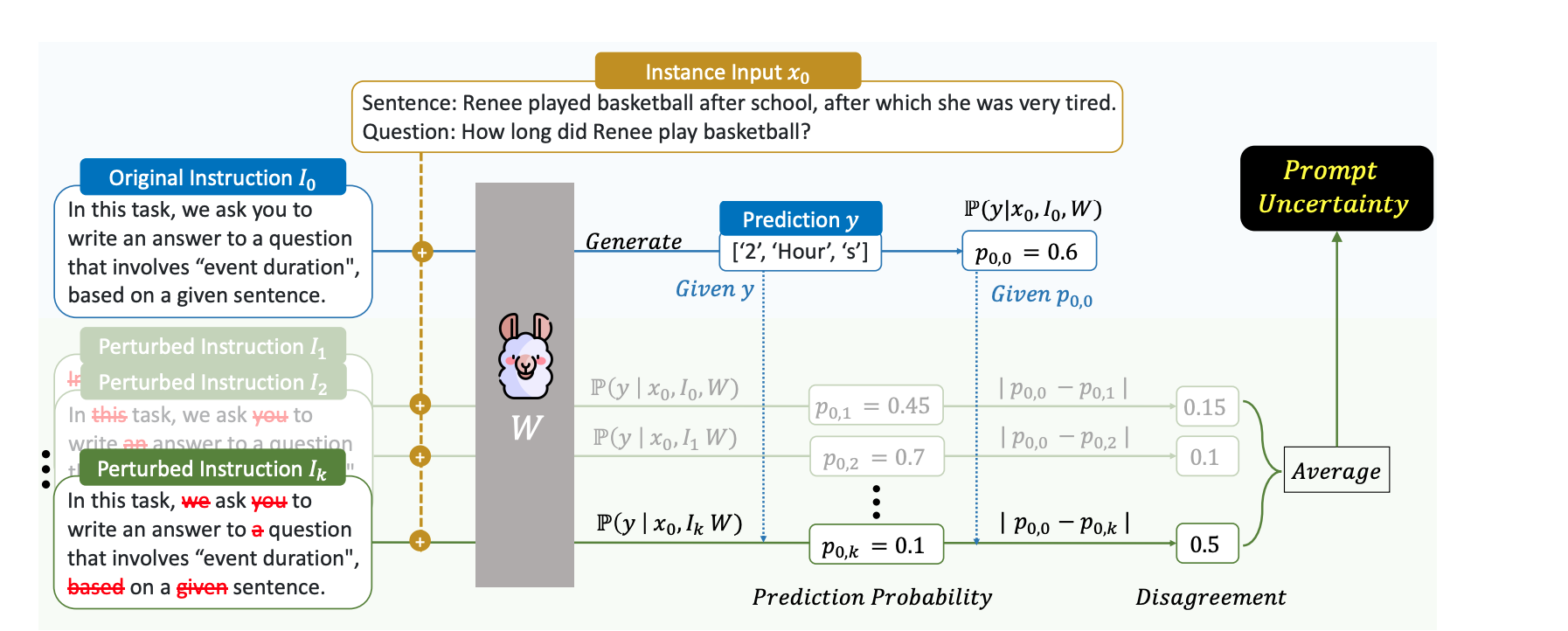
这篇论文是从任务这一粒度(本质也是样本)来出发的即,怎么更好的选择一个新任务来提高模型泛化性。
论文的具体做法是提出了一个Prompt Uncertainty概念,假设有一个原始样本对<prompt, response>,然后对prompt做一些扰动得到promot_v1,其中promot_v1还是要保留大部分prompt语义,然后将prompt和promot_v1分别传给模型,分别拿到response的输出,计算得到两者之间的likelihood值,该值即为Prompt Uncertainty。
这里的扰动作者采用的是随机drop掉部分单词。
作者的理论假设是:从上下文学习的鲁棒性角度来看,如果模型不能稳定地将任务指令映射到特定的潜在概念(response),那么它对相应任务的泛化能力是有限的。为了刻画量化这一假设,作者将其反映在对指令扰动的敏感性上,即假设在不确定prompt的任务上训练模型将提高其将prompt与特定潜在概念(任务)相关联的能力,从而在未见prompt的情况下获得更好的零样本性能。
作者将Prompt Uncertainty高的作为困难样本来进行active学习,为了说明当前方法的有效性,设计了三个baseline:Random Sampling即随机抽样任务、High Perplexity即在response上面高困惑度的任务、Low Perplexity即在response上面低困惑度的任务。
实验结果如下:可以看到当前方法是最好的。
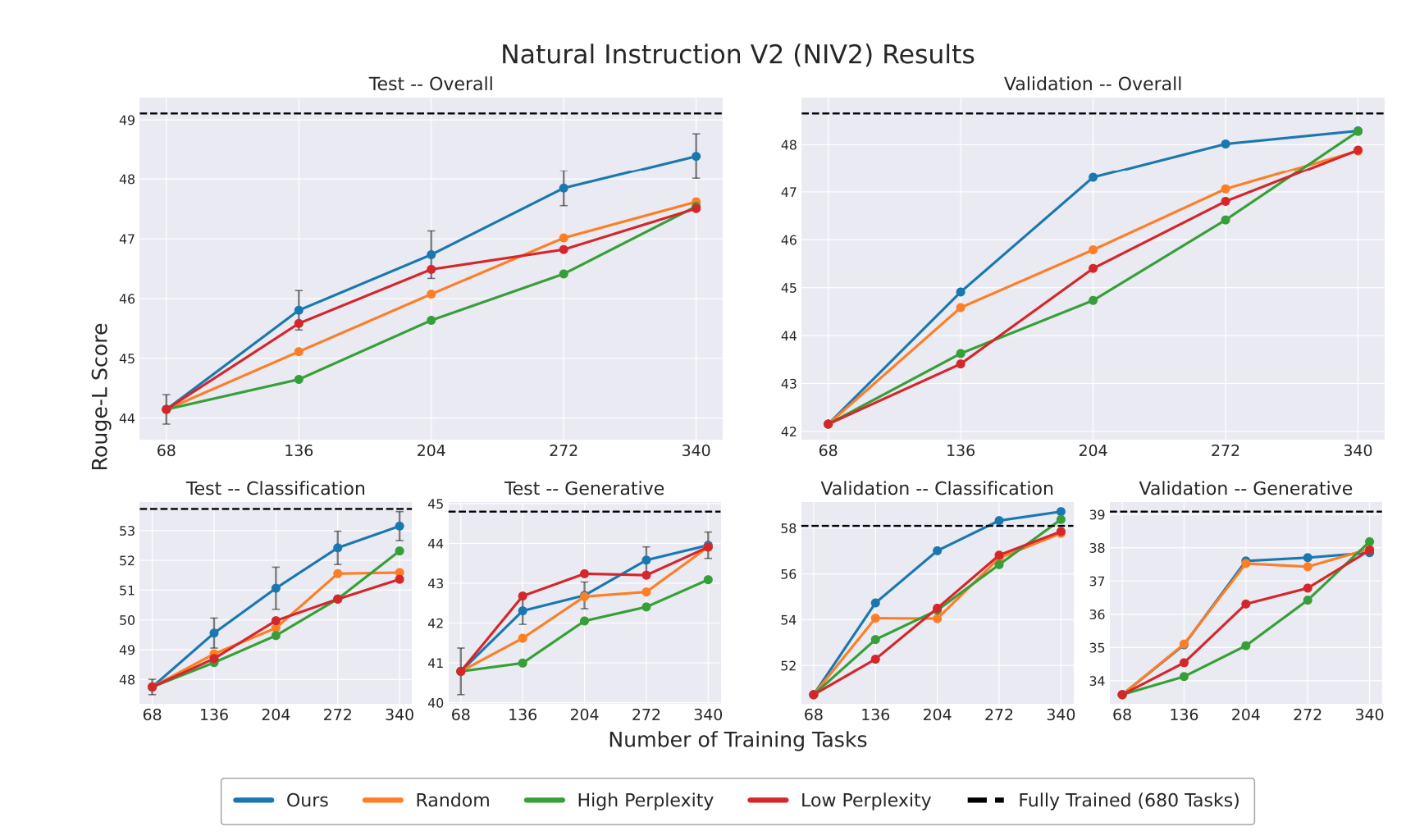
除了Prompt Uncertainty,作者进一步算了Prediction Probability即模型对自己预测response的自信度。Prompt Uncertainty代表的是模型将一个prompt映射到特定概念的一致性,表明模型对任务的模糊性;Prompt Uncertainty表示模型执行任务的自信程度。有了这两个概念,作者将任务大概分为三类Easy、Difficult、Ambigous:
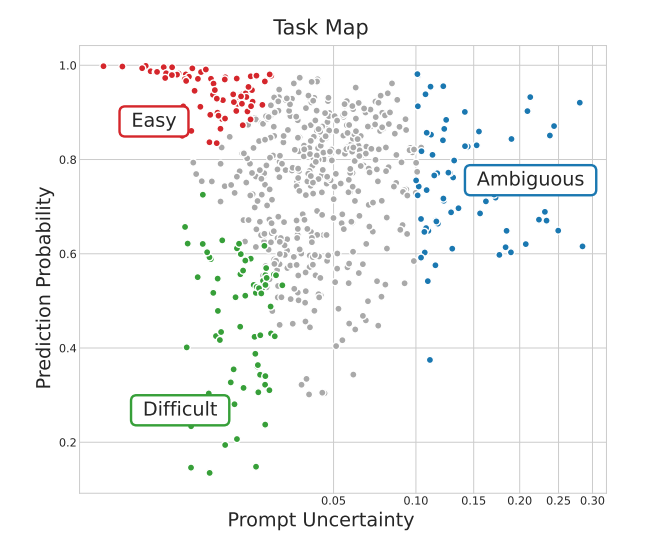
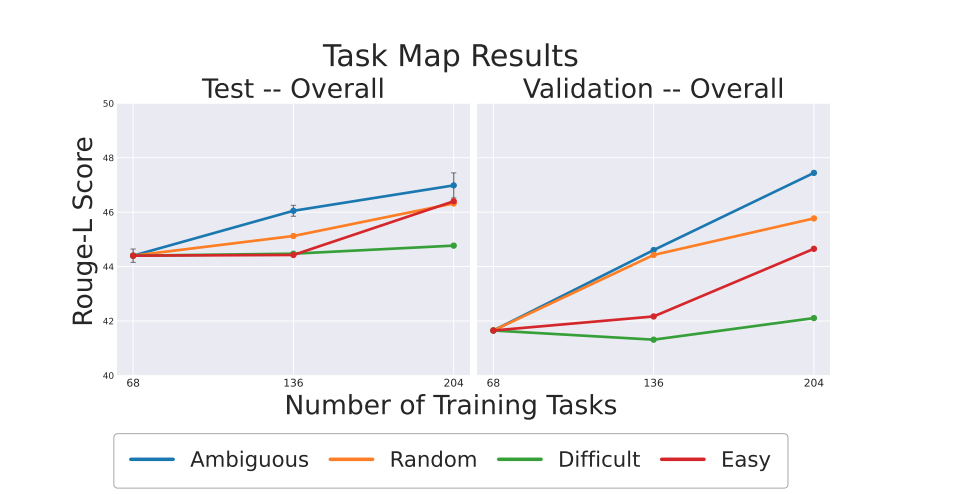
可以看到在Ambigous任务上可以有效的提高模型性能,而Easy、Difficult还不如随机抽取,特别是多加一些Easy任务还可以提高点,但是Difficult任务是没啥用的,作者认为这是因为Difficult太难了没法学。
说到这里不禁让笔者想到了WizardLM系列论文,他的核心是不断的进化出困难样本,而且很有效,本质原因就是既有简单样本又有困难样本,模型可以学到两者之间的diff也即有点对比学习的逻辑在里面,只学简单或者只学困难样本都是不行的,混在一起可能更好,甚至先学简单的,再学难的也可以尝试。话说这里的Ambigous样本是不是也有点混于简单和困难样本中间的味道呢?大家可以多想想,哈哈。
From Quantity to Quality: Boosting LLM Performance with Self-Guided Data Selection for Instruction Tuning
论文链接:https://arxiv.org/pdf/2308.12032.pdf
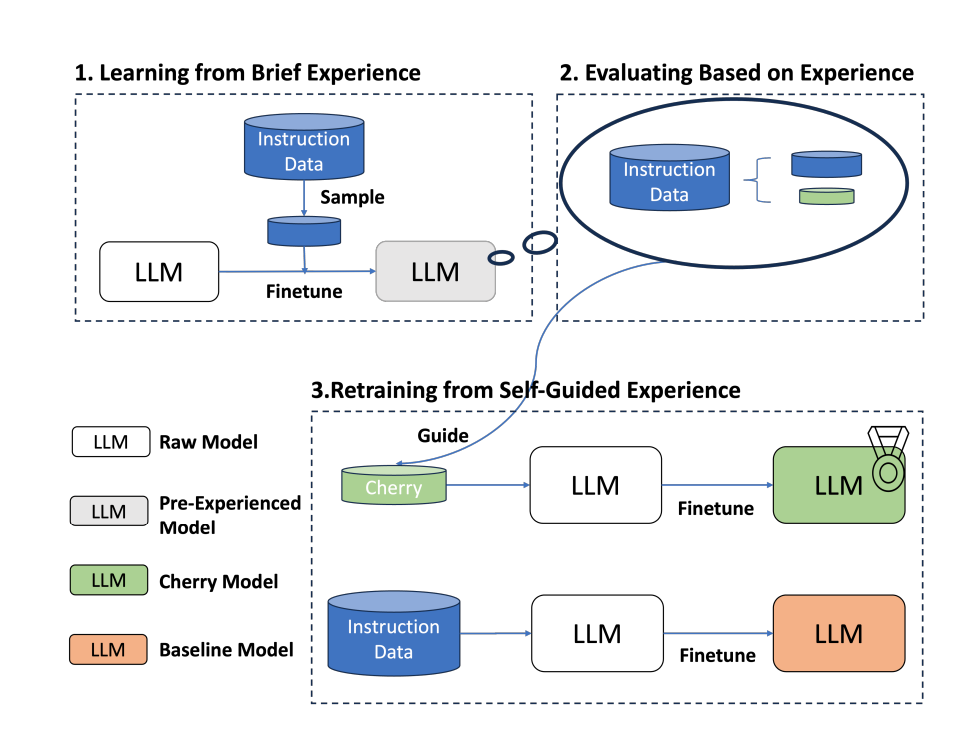
本篇论文提出了一个IFD指标来筛选过滤数据,成功的实现了只使用10%的原始数据便可达到不错效果,并且实验在Alpaca和WizardLM两个知名开源数据集上都得到了验证。
(1)方法
具体的论文是通过如下三步来实现:
- Learning from Brief Experience
这一步主要目的就是先训练得到一个能够遵循基本指令的模型。具体做法就是将我们所有的SFT数据聚类,论文是聚了100个簇,然后从每个簇中心选10个代表样本,使用这些样本去训练基座模型(LLaMA )得到一个初版的SFT,具体的论文中给这个模型起名为brief pre-experienced model。
- Evaluating Based on Experience
用第一步的模型便可以得到Conditioned Answer Score
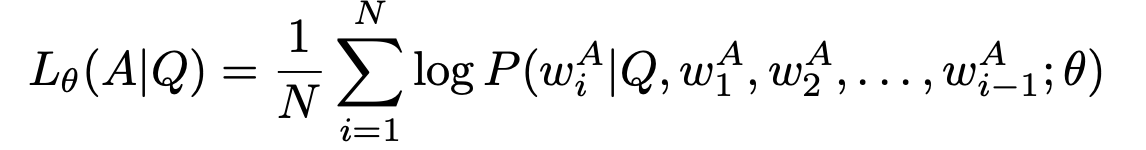
可以看到其实该指标反应了在给定prompt的前提下,模型能够在多大程度上生成正确的response。
但是Conditioned Answer Score分越高并不一定真真就意味着越是困难样本(对模型来说),因为有可能response答案本身就很难(可以这么理解:即使模型很理解prompt了,也get到prompt的目的了,但就是因为缺乏知识,回答不上来),所以作者又计算了一个指标:
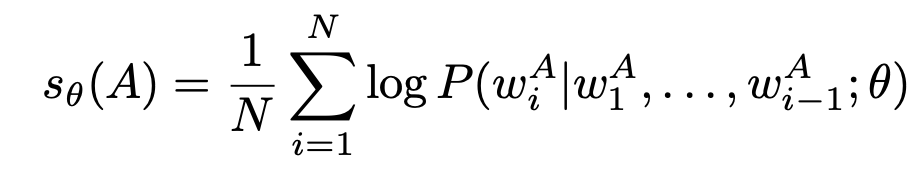
即衡量response答案本身的难度。
基于上面两个指标,便可得到本篇论文提出的核心量化指标IFD:

IFD的物理含义是prompt对于模型来说的困难度,该指标已在一定程度上消除了response答案本身的影响。
- Retraining from Self-Guided Experience
这部分就很简单了,就是批量跑得到每个样本的IFD得分,然后选取较高得分(prompt困难样本)的样本,paper中称为cherry samples,用其重新训练模型。
(2)实验
作者在Alpaca和WizardLM都进行了实验,经过过滤漏斗分别是5%、10%

可以看到效果要好于使用全部样本。
同时作者进一步按照能力项拆开看各部分的影响

最终观察到的现象是在数学、代码、复杂任务上都会有性能损失,但在其他任务上都会有提高(这里也侧面反映出对于数学,代码等比较复杂的理科领域还是需要保证数据量级的,这也是一条咱们可以借鉴的宝贵经验。)
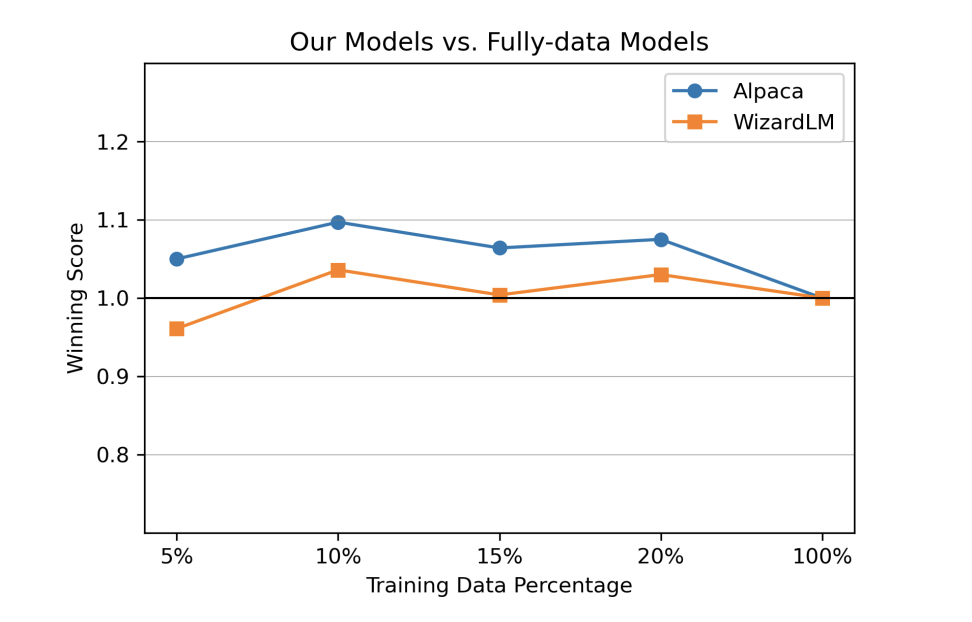
同时论文也做了不断加数据量看性能的变化,可以看到随机量级增大,模型的性能并没有带来限制的提升,甚至出现了下降,也侧面说明了IFD的重要性
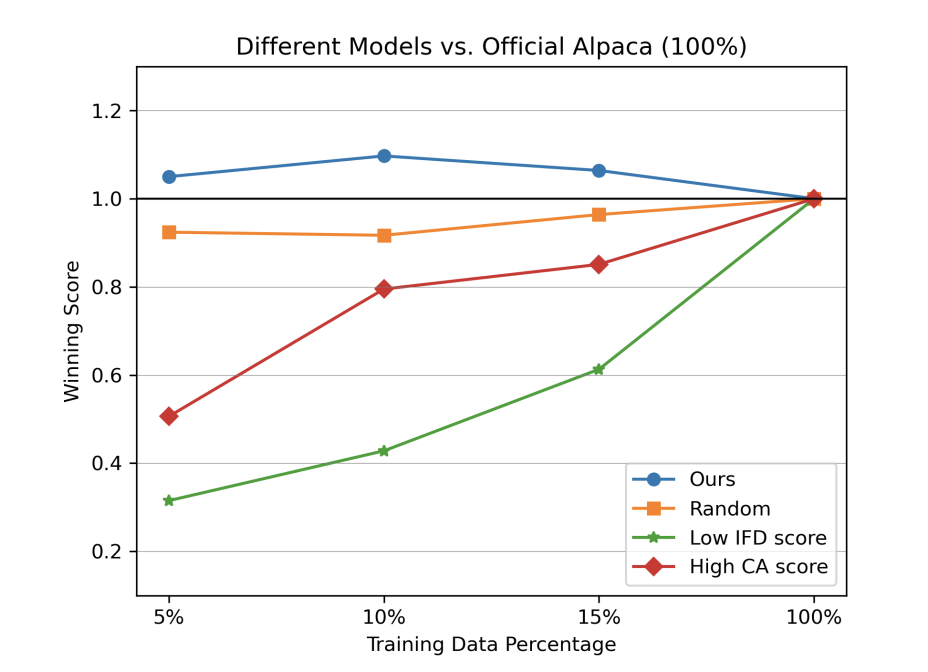
为了进一步说明,论文又对比了几个baseline,一个是取低IFD分的(LOW IFD score),一个是取高Conditioned Answer Score(High CA),一个是随机取,通过LOW IFD score进一步佐证了IFD的有效性。

同时作者也对brief pre-experienced model做了消融,也即需要多少样本来训练brief pre-experienced model,可以看到当增加到300时有了一个显著的提升,但是再继续增加时没有带来特别明显受益,即进一步增加样本数量并不能使模型的性能更好。
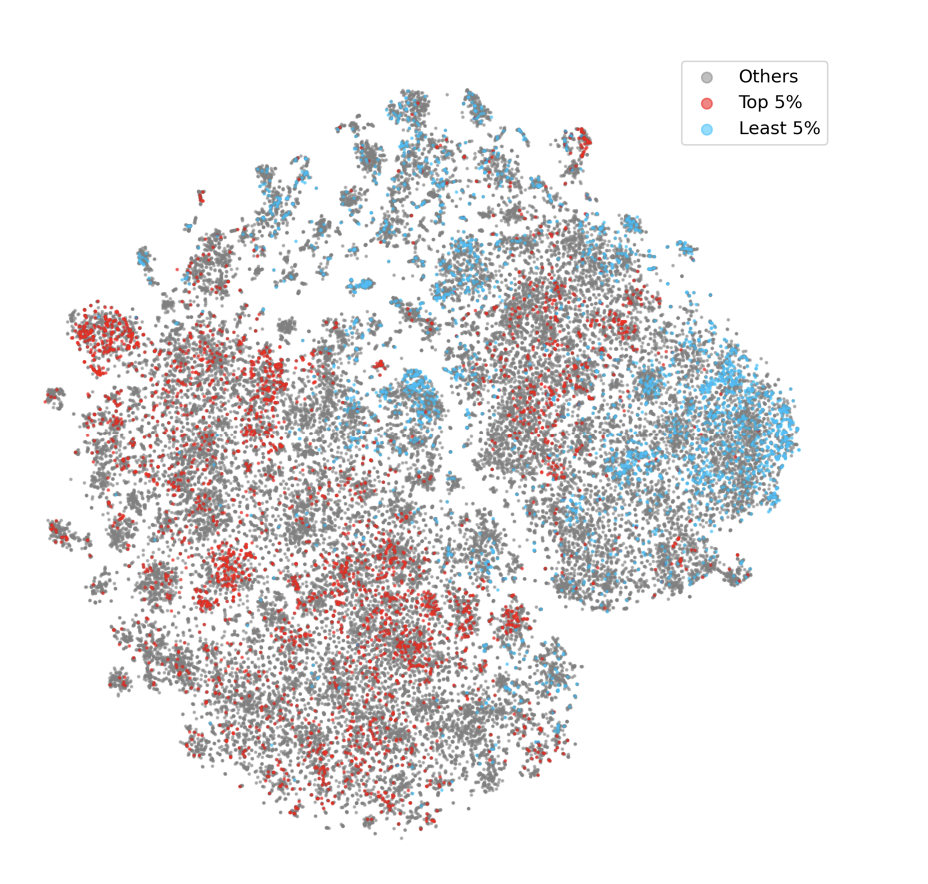
作者进一步进行了可视化分析,红蓝分别代表高低IFD分,可以看到两者具有明显界限,为了更深入的观察,作者使用了K-means(K=100)进行聚类,并关注了10个代表性的聚类簇,其中一半与前5%的样本有显著重叠,另一半与最后5%的样本有显著重叠。低IFD分数样本主导的聚类簇基本是基础任务,如编辑标点符号、单词或句子,而高IFD分数的聚类簇是更深入、更复杂的任务如讲故事或阐明现象。作者认为这些深入的任务对于对齐大型语言模型至关重要。
总结
(1)数据广义的好坏(脱离模型)也即对于所有模型来说他都是坏样本或者好样本,这个筛选可以基于一些先验知识又或者reward model来做,这本质是和待训练模型是异步的。同时训练一个reward model尤其是通用的reward model是一件不易的事情。
(2)基于待训练模型进行筛选是一个不错的出发点,毕竟适合不适合自己只有自己最清楚,当前样本也只有当前模型认为重要才是真真的重要。那该怎么具体量化“重要”这一概念,无非就是两个角度:一个是prompt,一个是response。更具体来说就是一个二维象限。衡量的角度也有很多比如loss,不确定性等等,本质都是利用了生成token的概率,然后进行抽象组合,找到一个有效点加以区分样本。
(3)当前的方法目标都是减量,但是减量后基本上都是维持和原来一样的效果,当然IFD有一些提升的趋势(和用全量相比),如果你已经有资源甚至是已经在全量数据上训练过了又或者全量一把梭哈的代价也不大,这种情况下再做减量的性价比就要衡量一下了,因为做半天减量,最多也是保持和现在一样的效果(已经拿到了当前效果模型),除非期望减量能带来进一步效果的提升或为了后续迭代效率。
(4)除了上面介绍的方法,应该还会有更加抽象理论的方法将其统一,进行全面合理的解释,如果找到那是非常幸运的。
关注
欢迎关注,下期再见啦~
知乎,csdn,github,微信公众号







![[ 蓝桥杯Web真题 ]-组课神器](https://img-blog.csdnimg.cn/direct/c760d682770341768ffe2da6f01ba10e.gif)