文章目录
- 一、实验环境
- 二、实验内容
- (一)数据准备
- (二)编程环境准备
- (三)使用Hadoop API操作HDFS文件系统
- (四)使用Hadoop API + Java IO流操作HDFS文件系统
- 三、实验步骤
- (一)数据准备
- (二)编程环境准备
- 1、启动IDEA
- 2、创建Maven项目
- 3、添加项目依赖
- (1)hadoop-common (org.apache.hadoop:hadoop-common:2.7.6)
- (2)hadoop-client (org.apache.hadoop:hadoop-client:2.7.6)
- (3)hadoop-hdfs (org.apache.hadoop:hadoop-hdfs:2.7.6)
- (4)junit (junit:junit:4.10)
- (5)log4j-core (org.apache.logging.log4j:log4j-core:2.8.2)
- 4、添加资源文件
- 5、创建包
- (三)使用Hadoop API操作HDFS文件系统
- 1、获取文件系统并配置在集群上运行
- 2、创建目录
- 3、上传文件
- 4、下载文件
- 5、删除文件/目录
- 6、列出指定路径下的文件和目录
- 7、查看完整代码
- (四)使用Hadoop API + Java IO流操作HDFS文件系统
- 1、获取文件系统并配置在集群上运行
- 2、上传文件(IO流)
- 3、读取文件(IO流)
- 4、下载文件(IO流)
- 5、辅助代码
一、实验环境
- 本实验主要涉及到了4台虚拟机,其中1台虚拟机的操作系统是
ubuntu desktop,另外3台虚拟机的操作系统是centos server。
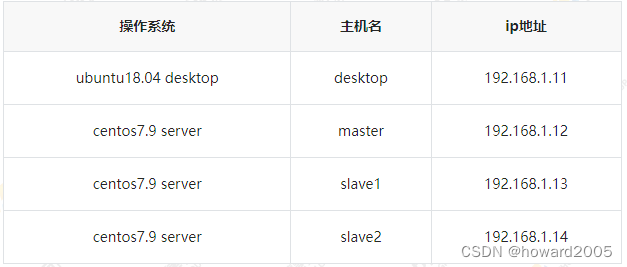
- 本实验已经搭建好了Hadoop HA的完全分布式集群

二、实验内容
- 我们将一同探讨数据处理中至关重要的一环——Hadoop文件系统(HDFS)的操作。我们将分为四个主要部分,分别是数据准备、编程环境准备、使用Hadoop API操作HDFS文件系统以及使用Hadoop API结合Java IO流进行操作。
(一)数据准备
- 在进行任何数据处理之前,充分准备好数据是至关重要的一步。这一部分将介绍数据准备的重要性,以及如何有效地准备数据以供后续处理使用。
(二)编程环境准备
- 在进行HDFS文件系统的操作之前,我们需要确保我们的编程环境已经得到了妥善的准备。这包括获取文件系统、配置集群环境等步骤,确保我们的操作能够在集群上运行。
(三)使用Hadoop API操作HDFS文件系统
- 这一部分是我们的重头戏,我们将使用Hadoop API进行各种文件系统的操作。从创建目录到上传、下载、删除文件,再到列出指定路径下的文件和目录,我们将一一演示如何使用Hadoop API轻松地完成这些操作。同时,我们也会分享一些辅助代码,使大家更好地理解和应用这些操作。
(四)使用Hadoop API + Java IO流操作HDFS文件系统
-
在这一部分,我们将进一步深入,结合Java IO流,展示如何通过IO流上传、读取和下载文件。这将为大家提供更多的灵活性和掌握文件系统操作的技能。
-
本次实验帮助大家更好地理解和应用Hadoop文件系统的操作,使大家能够在实际工作中更加得心应手。接下来,我们将深入到各个部分,让我们一同来探索这个数据处理的世界吧!
三、实验步骤
(一)数据准备
- 在
desktop节点打开终端
- 切换到
/opt目录
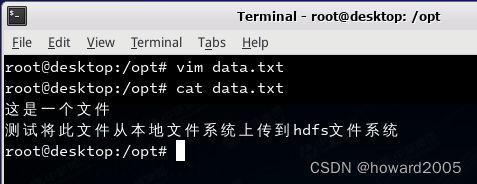
- 创建数据文件
data.txt
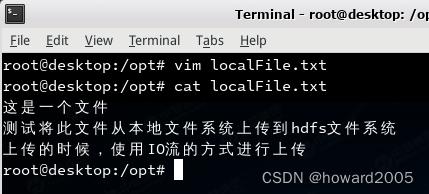
- 创建数据文件
localFile.txt
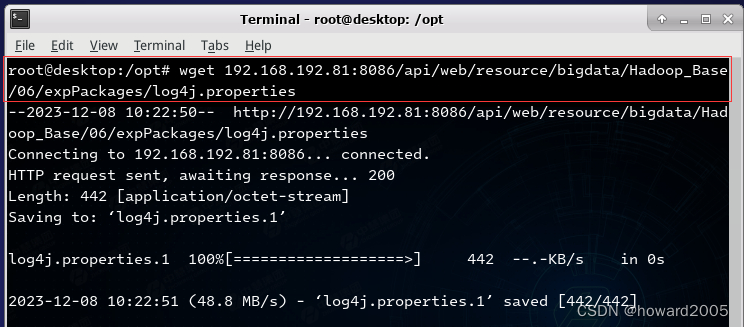
- 下载日志属性文件,执行命令:
wget 192.168.192.81:8086/api/web/resource/bigdata/Hadoop_Base/06/expPackages/log4j.properties
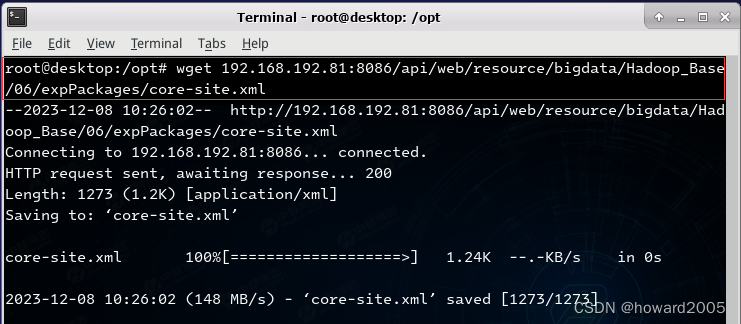
- 下载Hadoop核心配置文件
core-site.xml,执行命令:wget 192.168.192.81:8086/api/web/resource/bigdata/Hadoop_Base/06/expPackages/core-site.xml
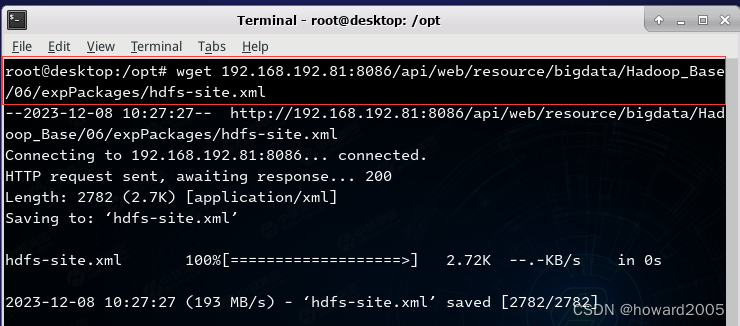
- 下载Hadoop分布式文件系统配置文件
hdfs-site.xml,执行命令:wget 192.168.192.81:8086/api/web/resource/bigdata/Hadoop_Base/06/expPackages/hdfs-site.xml
(二)编程环境准备
1、启动IDEA
-
在desktop节点上启动IDEA
-
勾选用户协议
-
单击【Continue】按钮
2、创建Maven项目
- 单击欢迎窗口中的【New Project】按钮,在左边栏里选择【Maven】类型
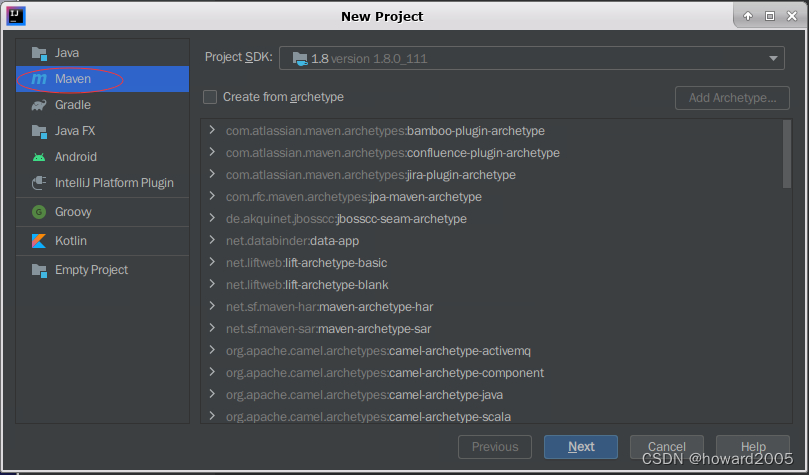
- 单击【Next】按钮,在对话框里设置项目名称、位置、组标识和构件标识
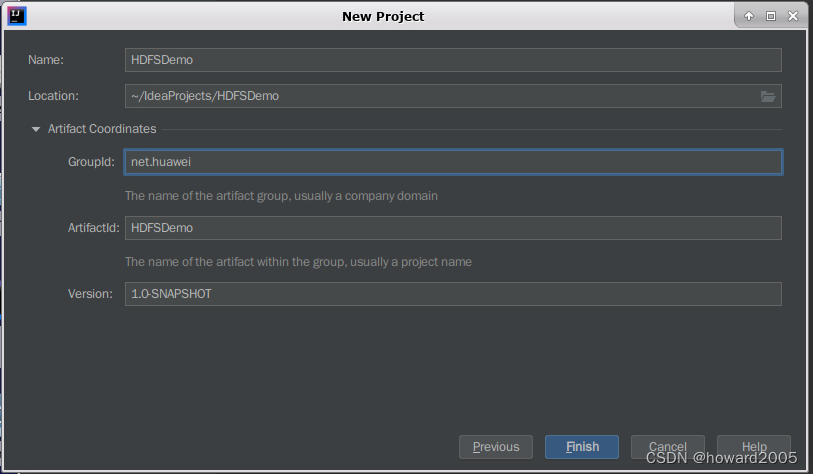
- 单击【Finish】按钮,在弹出的【Tip of the Day】消息框里勾选【Don’t show tips】复选框
- 单击【Close】按钮,看到一个空的Maven项目
3、添加项目依赖
- 在
pom.xml文件里添加相关依赖
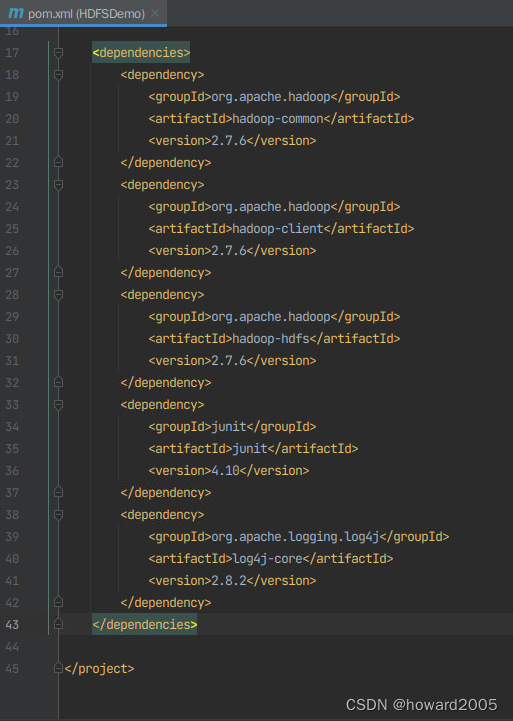
<dependencies>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>2.7.6</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>2.7.6</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-hdfs</artifactId>
<version>2.7.6</version>
</dependency>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.10</version>
</dependency>
<dependency>
<groupId>org.apache.logging.log4j</groupId>
<artifactId>log4j-core</artifactId>
<version>2.8.2</version>
</dependency>
</dependencies>
(1)hadoop-common (org.apache.hadoop:hadoop-common:2.7.6)
- 作用: 提供Hadoop的通用库和工具,包括文件系统操作、配置管理等。
- 详细说明: 这是Hadoop的核心库,包含了许多通用的类和工具,用于支持Hadoop分布式文件系统(HDFS)和分布式计算。
(2)hadoop-client (org.apache.hadoop:hadoop-client:2.7.6)
- 作用: 提供Hadoop的客户端库,支持与Hadoop集群进行交互。
- 详细说明: 包含Hadoop客户端的相关类,用于在应用程序中与Hadoop集群通信,提交作业等。
(3)hadoop-hdfs (org.apache.hadoop:hadoop-hdfs:2.7.6)
- 作用: 提供Hadoop分布式文件系统(HDFS)的支持。
- 详细说明: 包含了HDFS相关的类,用于进行文件系统的读写操作,支持分布式存储和文件管理。
(4)junit (junit:junit:4.10)
- 作用: 提供Java单元测试的支持。
- 详细说明: JUnit是一个广泛用于Java项目的测试框架,用于编写和运行单元测试。
(5)log4j-core (org.apache.logging.log4j:log4j-core:2.8.2)
-
作用: 提供Log4j日志框架的核心功能。
-详细说明: Log4j是一个用于Java应用程序的灵活的日志框架,log4j-core包含了其核心的日志处理功能。 -
中慧教学实训平台提供了文件的上传和下载功能
-
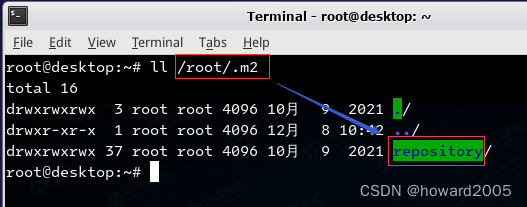
CentOS上Maven项目本地仓库默认位置(
用户主目录/.m2/repository)
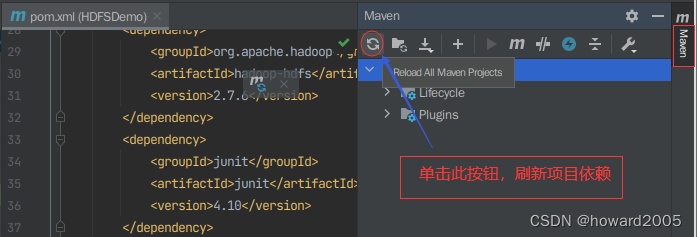
-
刷新项目依赖
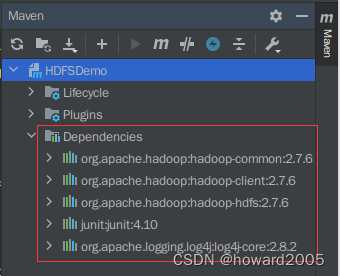
-
刷新之后,多一个
Dependencies项
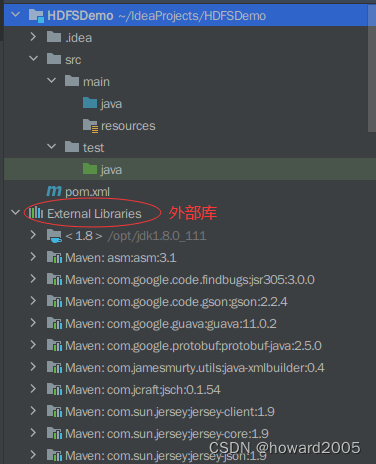
-
查看项目依赖的外部库(External Libraries)
4、添加资源文件
- 将
/opt目录里的core-site.xml、hdfs-site.xml、log4j.properties文件拷贝到项目的resources目录

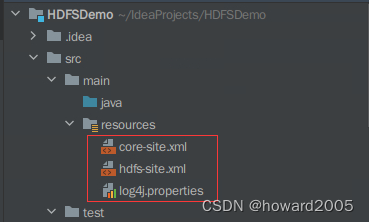
5、创建包
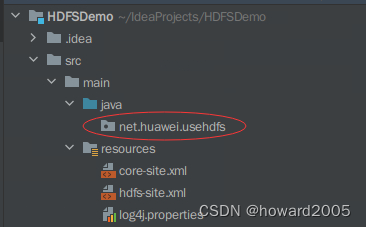
- 在
src/main/java里创建net.huawei.usehdfs包
(三)使用Hadoop API操作HDFS文件系统
1、获取文件系统并配置在集群上运行
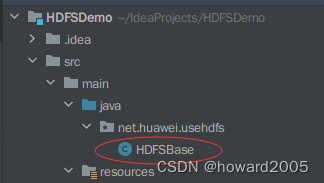
- 在
net.huawei.usehdfs包里创建HDFSBase类
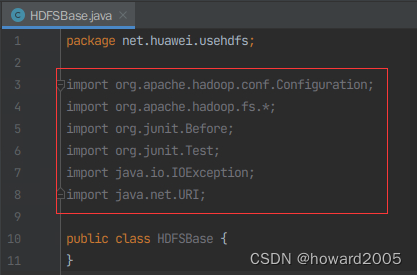
- 导入程序所需要的包
- 创建
init()方法,获取在集群上运行的文件系统
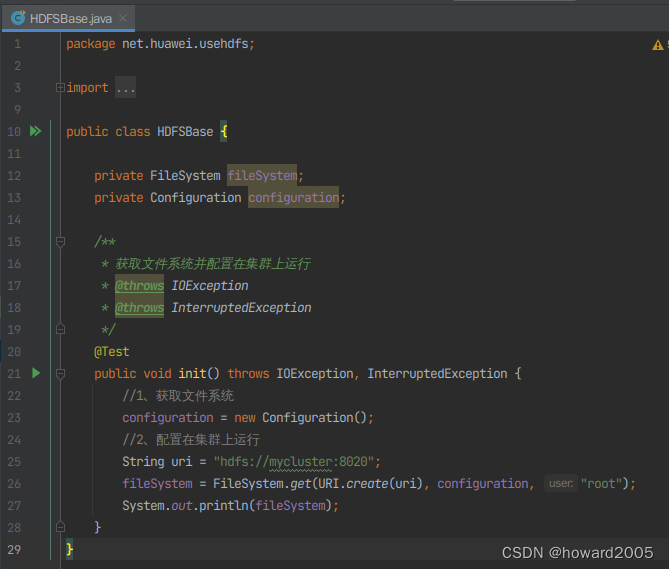
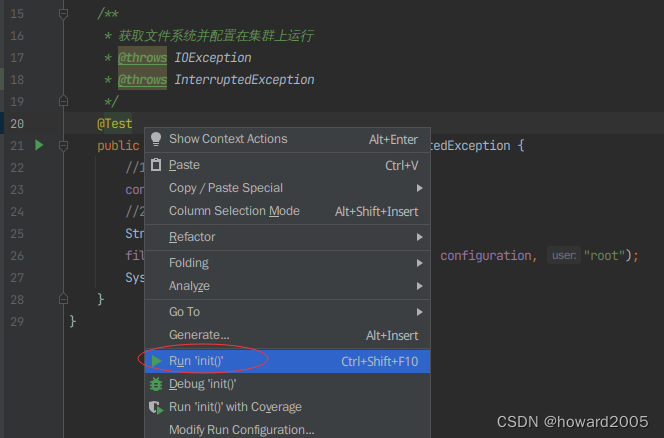
- 运行
init()方法
- 在控制台查看结果
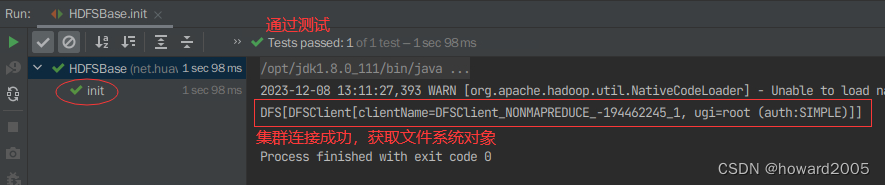
2、创建目录
- 创建
testMkdirs()方法

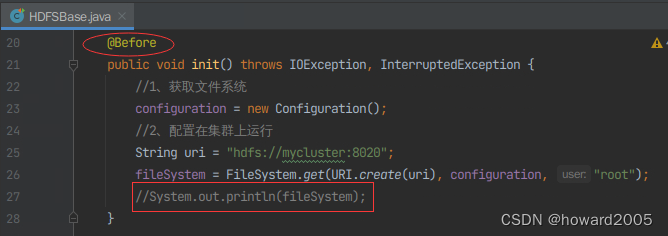
- 由于每次对于HDFS文件系统的操作都需要获取文件系统并配置在集群上运行,因此需要将上一个功能代码中的
@Test修改为@Before,并将System.out.printIn(fileSystem);语句注释掉。
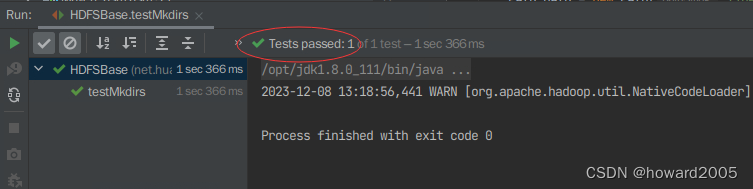
- 运行
testMkdirs()方法,查看控制台结果
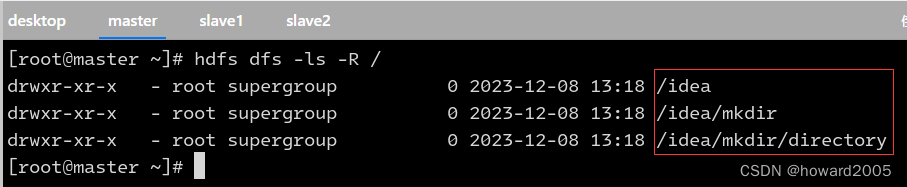
- 在Hadoop WebUI上查看创建的目录

- 利用HDFS Shell命令
hdfs dfs -ls -R /查看
3、上传文件
- 创建
testCopyFromLocal()方法
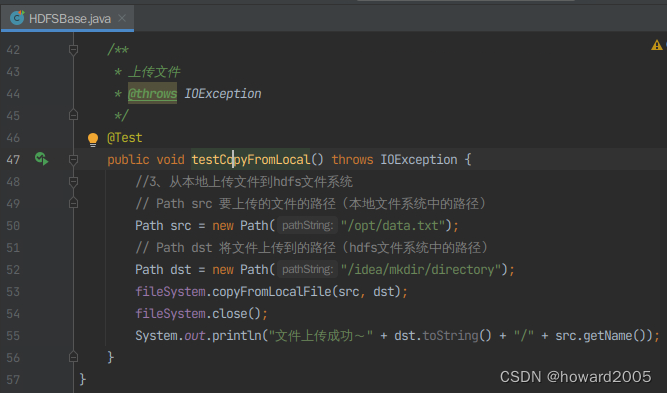
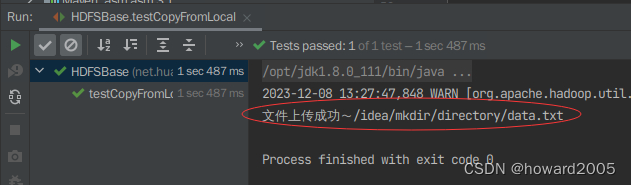
testCopyFromLocal()方法,查看结果
- 查看上传的文件内容
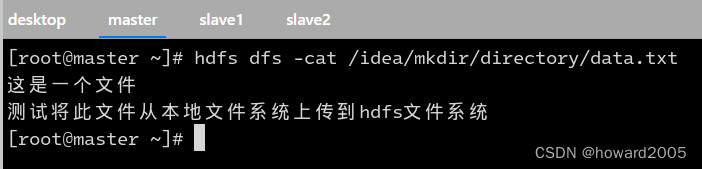
4、下载文件
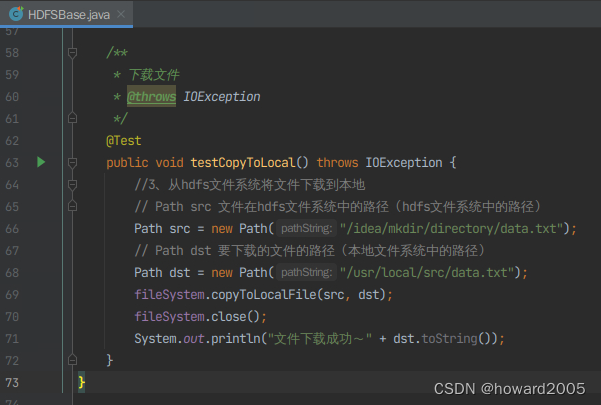
-
创建
testCopyToLocal()方法
-
运行
testCopyToLocal()方法,查看结果

-
在desktop节点上查看下载的文件
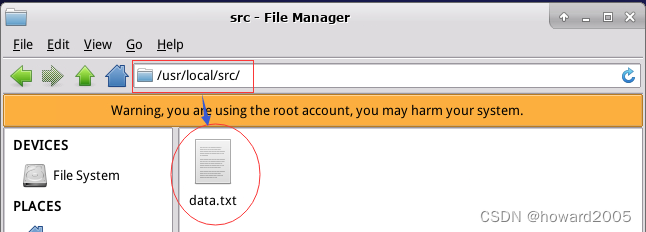
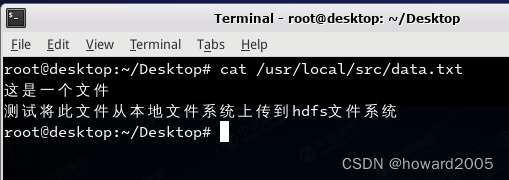
-
在desktop节点上查看下载的文件内容
5、删除文件/目录
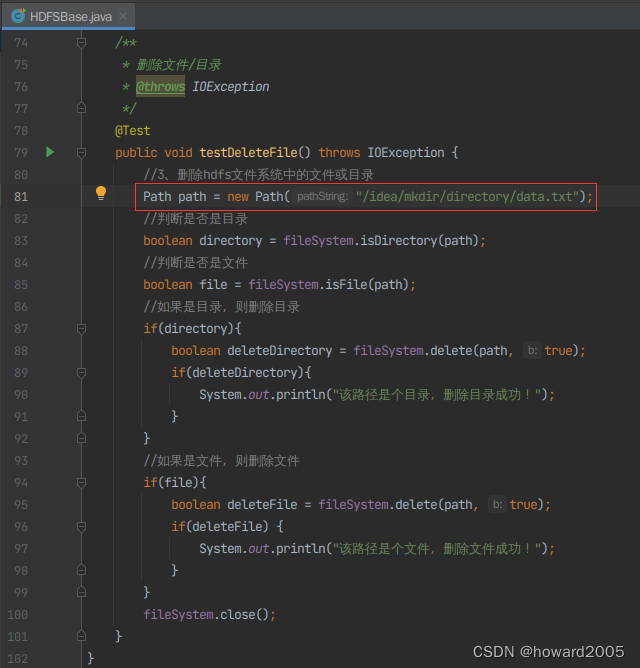
-
创建
testDeleteFile()方法,删除/idea/mkdir/directory/data.txt文件
-
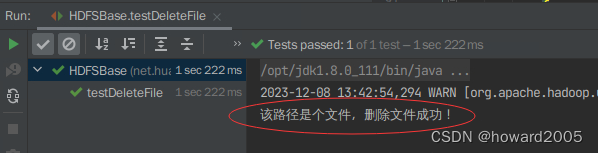
运行
testDeleteFile()方法,查看结果
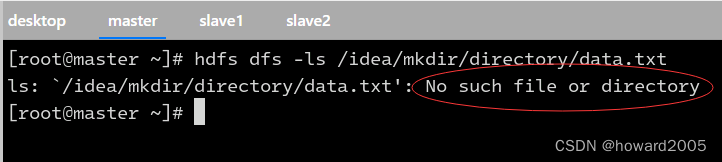
-
查看
/idea/mkdir/directory/data.txt文件,报错说文件不存在
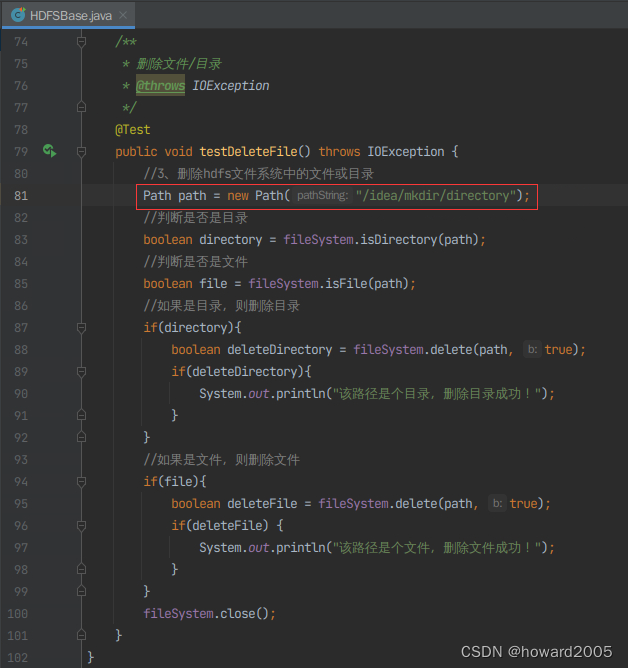
-
修改代码,删除
/idea/mkdir/directory目录
-
运行
testDeleteFile()方法,查看结果
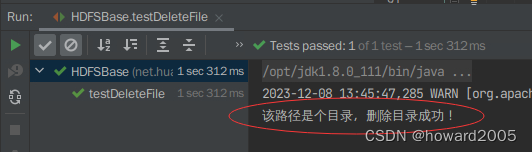
-
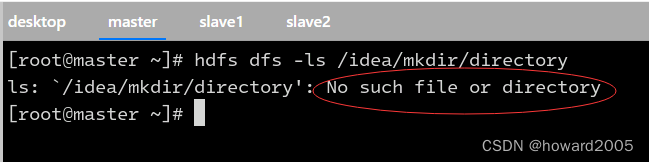
查看
/idea/mkdir/directory目录,报错说目录不存在
6、列出指定路径下的文件和目录
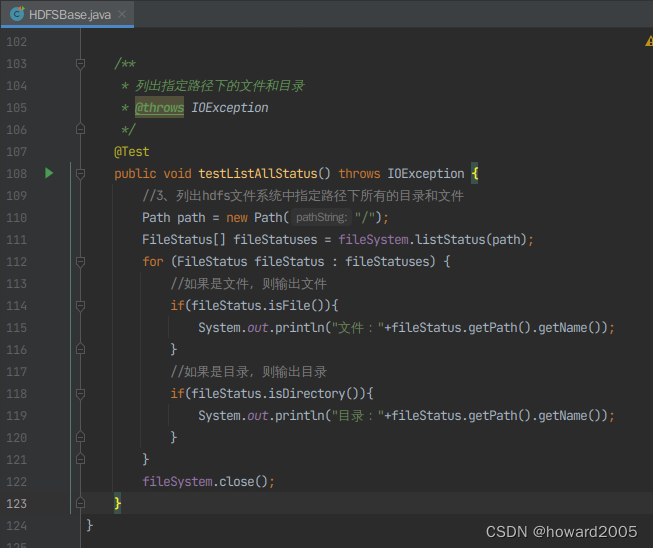
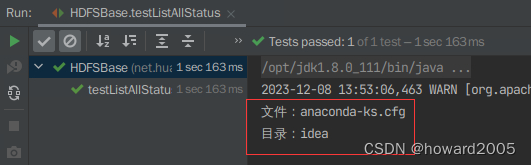
- 创建
testListAllStatus()方法
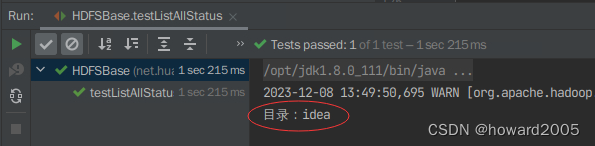
- 运行
testListAllStatus()方法,查看结果
- 上传
anaconda-ks.cfg到HDFS根目录

- 运行
testListAllStatus()方法,查看结果
7、查看完整代码
package net.huawei.usehdfs;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.*;
import org.junit.Before;
import org.junit.Test;
import java.io.IOException;
import java.net.URI;
public class HDFSBase {
private FileSystem fileSystem;
private Configuration configuration;
/**
* 获取文件系统并配置在集群上运行
* @throws IOException
* @throws InterruptedException
*/
@Before
public void init() throws IOException, InterruptedException {
//1、获取文件系统
configuration = new Configuration();
//2、配置在集群上运行
String uri = "hdfs://mycluster:8020";
fileSystem = FileSystem.get(URI.create(uri), configuration, "root");
//System.out.println(fileSystem);
}
/**
* 创建目录
* @throws IOException
*/
@Test
public void testMkdirs() throws IOException {
//3、创建目录
Path path = new Path("/idea/mkdir/directory");
fileSystem.mkdirs(path);
fileSystem.close();
}
/**
* 上传文件
* @throws IOException
*/
@Test
public void testCopyFromLocal() throws IOException {
//3、从本地上传文件到hdfs文件系统
// Path src 要上传的文件的路径(本地文件系统中的路径)
Path src = new Path("/opt/data.txt");
// Path dst 将文件上传到的路径(hdfs文件系统中的路径)
Path dst = new Path("/idea/mkdir/directory");
fileSystem.copyFromLocalFile(src, dst);
fileSystem.close();
System.out.println("文件上传成功~" + dst.toString() + "/" + src.getName());
}
/**
* 下载文件
* @throws IOException
*/
@Test
public void testCopyToLocal() throws IOException {
//3、从hdfs文件系统将文件下载到本地
// Path src 文件在hdfs文件系统中的路径(hdfs文件系统中的路径)
Path src = new Path("/idea/mkdir/directory/data.txt");
// Path dst 要下载的文件的路径(本地文件系统中的路径)
Path dst = new Path("/usr/local/src/data.txt");
fileSystem.copyToLocalFile(src, dst);
fileSystem.close();
System.out.println("文件下载成功~" + dst.toString());
}
/**
* 删除文件/目录
* @throws IOException
*/
@Test
public void testDeleteFile() throws IOException {
//3、删除hdfs文件系统中的文件或目录
Path path = new Path("/idea/mkdir/directory");
//判断是否是目录
boolean directory = fileSystem.isDirectory(path);
//判断是否是文件
boolean file = fileSystem.isFile(path);
//如果是目录,则删除目录
if(directory){
boolean deleteDirectory = fileSystem.delete(path, true);
if(deleteDirectory){
System.out.println("该路径是个目录,删除目录成功!");
}
}
//如果是文件,则删除文件
if(file){
boolean deleteFile = fileSystem.delete(path, true);
if(deleteFile) {
System.out.println("该路径是个文件,删除文件成功!");
}
}
fileSystem.close();
}
/**
* 列出指定路径下的文件和目录
* @throws IOException
*/
@Test
public void testListAllStatus() throws IOException {
//3、列出hdfs文件系统中指定路径下所有的目录和文件
Path path = new Path("/");
FileStatus[] fileStatuses = fileSystem.listStatus(path);
for (FileStatus fileStatus : fileStatuses) {
//如果是文件,则输出文件
if(fileStatus.isFile()){
System.out.println("文件:"+fileStatus.getPath().getName());
}
//如果是目录,则输出目录
if(fileStatus.isDirectory()){
System.out.println("目录:"+fileStatus.getPath().getName());
}
}
fileSystem.close();
}
}


![[Linux] 用LNMP网站框架搭建论坛](https://img-blog.csdnimg.cn/direct/ef63a1bd94014f63b6283a533ca65254.png)