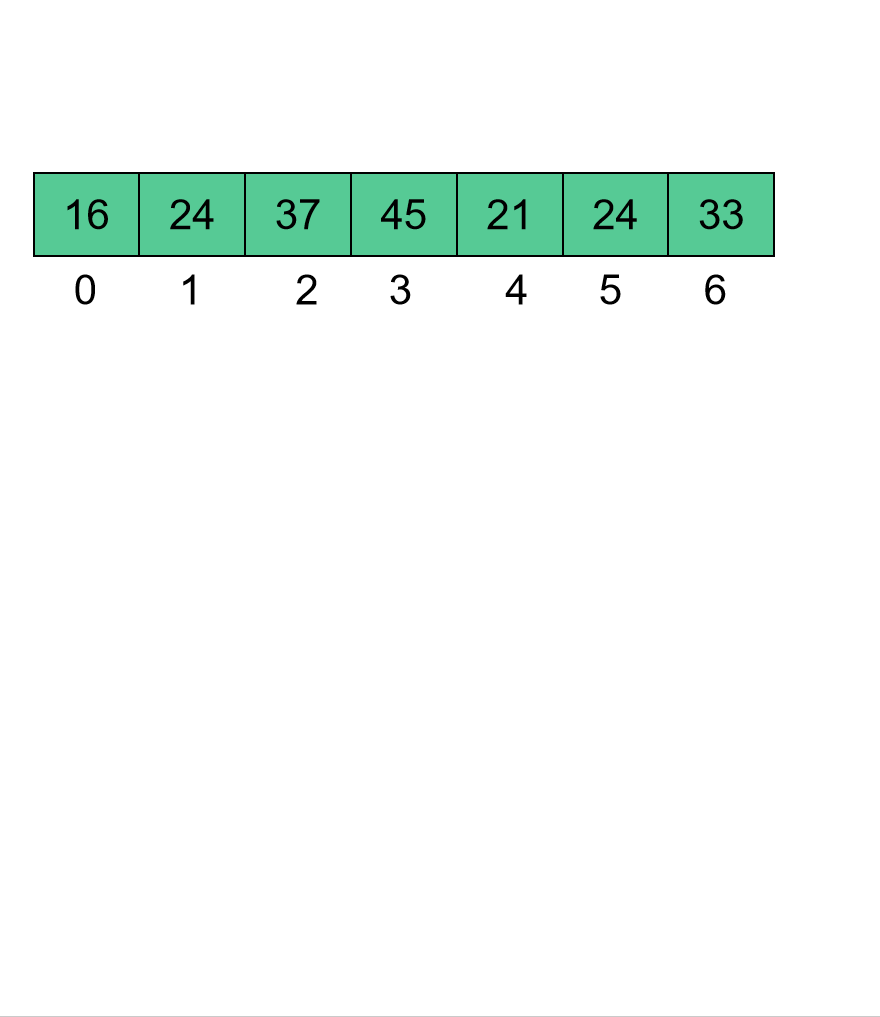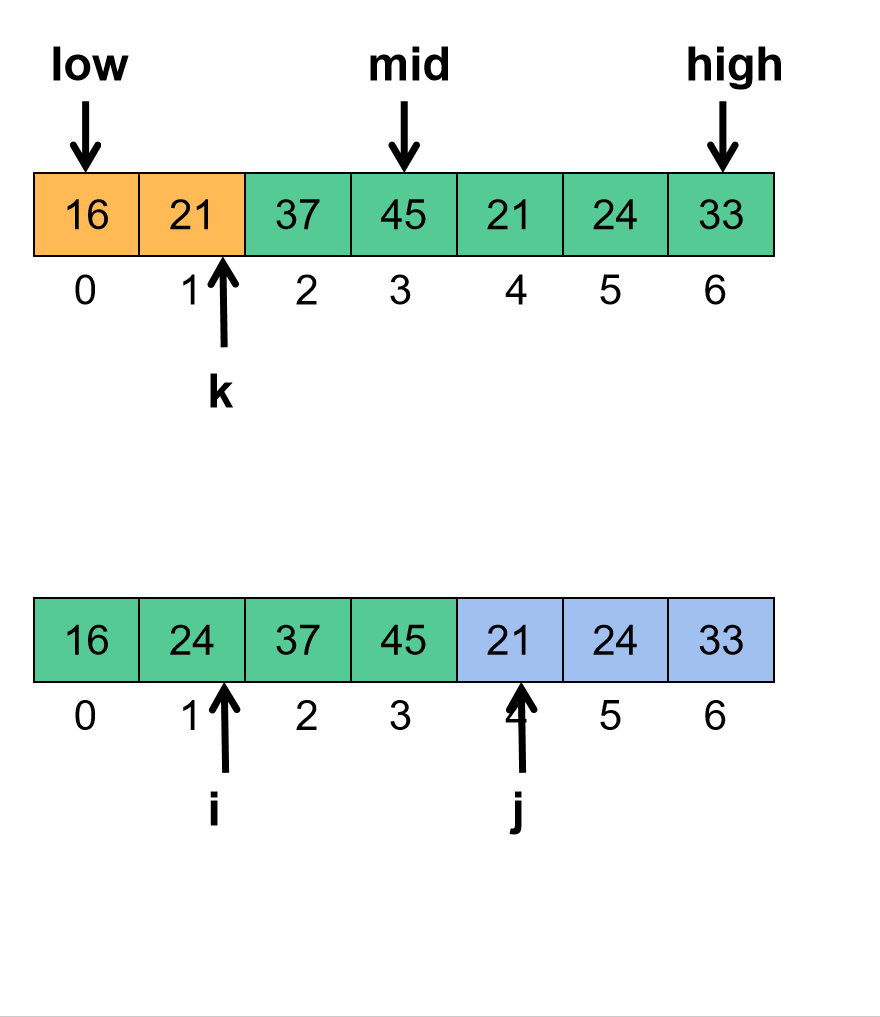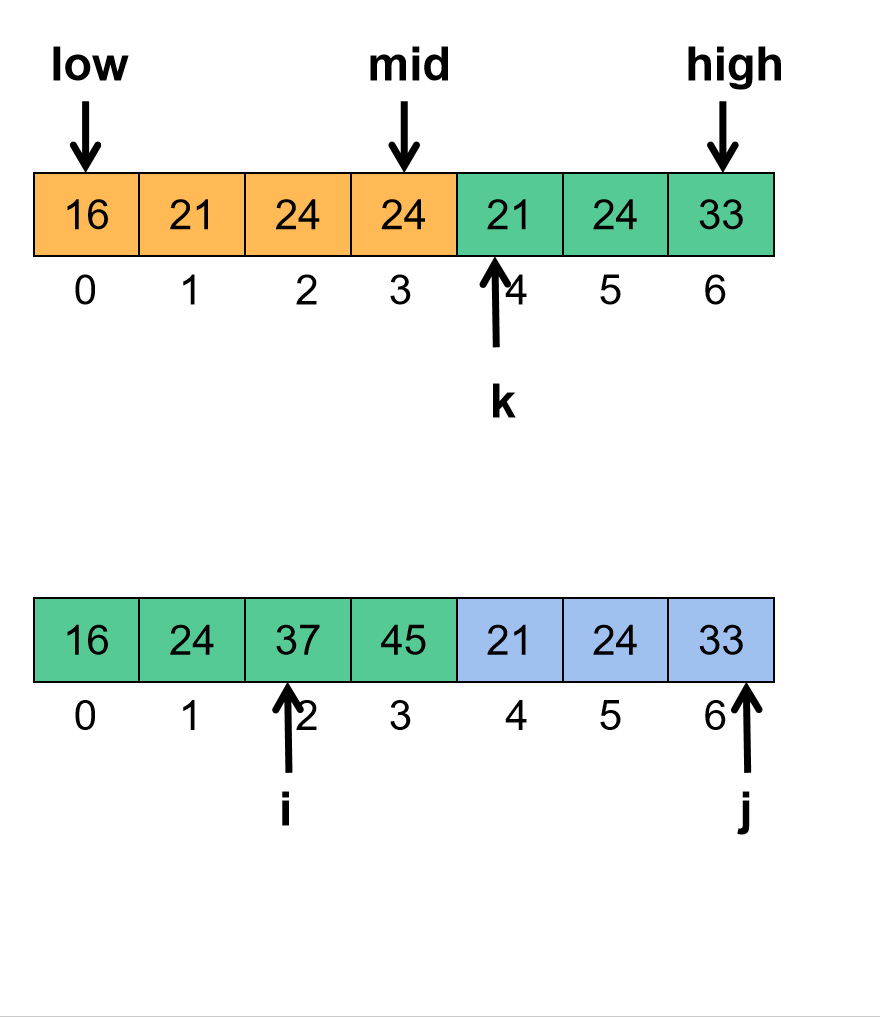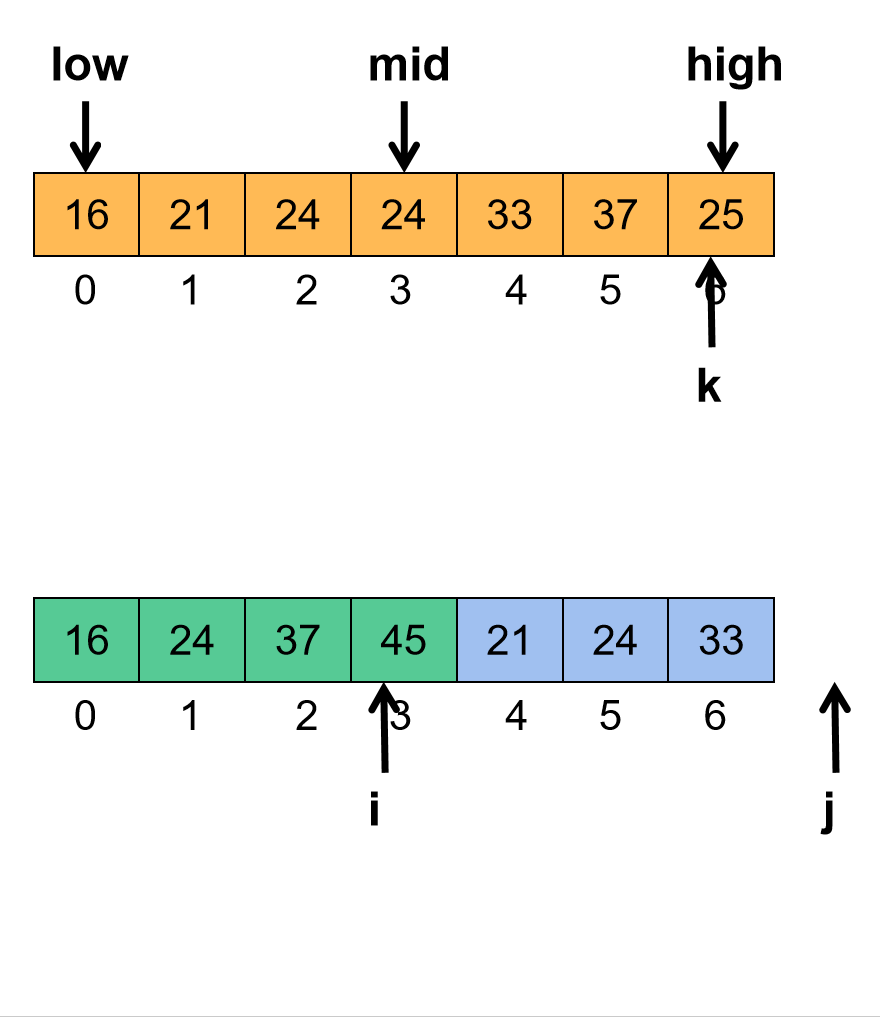
缓存穿透
理解:
缓存穿透是指查询一个根本不存在的数据,缓存层和持久层都不会命中。在日常工作中出于容错的考虑,如果从持久层查不到数据则不写入缓存层,缓存穿透将导致不存在的数据每次请求都要到持久层去查询,失去了缓存保护后端持久的意义。
举例:某商品正在参与促销活动,而后端的运维人员把商品信息删除了,数据库中也没有了商品信息,而这时还有大量的get请求访问当前商品信息,这就叫缓存穿透问题。
解决方案:
(1)缓存空对象:是指在持久层没有命中的情况下,对key进行set (key,null)
缓存空对象会有两个问题:
第一,value为null 不代表不占用内存空间,空值做了缓存,意味着缓存层中存了更多的键,需要更多的内存空间,比较有效的方法是针对这类数据设置一个较短的过期时间,让其自动剔除。
第二,缓存层和存储层的数据会有一段时间窗口的不一致,可能会对业务有一定影响。例如过期时间设置为5分钟,如果此时存储层添加了这个数据,那此段时间就会出现缓存层和存储层数据的不一致,此时可以利用消息系统或者其他方式清除掉缓存层中的空对象。
(2)布隆过滤器拦截
在访问缓存层和存储层之前,将存在的key用布隆过滤器提前保存起来,做第一层拦截,当收到一个对key请求时先用布隆过滤器验证是key否存在,如果存在在进入缓存层、存储层。可以使用bitmap做布隆过滤器。这种方法适用于数据命中不高、数据相对固定、实时性低的应用场景,代码维护较为复杂,但是缓存空间占用少。
布隆过滤器实际上是一个很长的二进制向量和一系列随机映射函数。布隆过滤器可以用于检索一个元素是否在一个集合中。
它的优点是空间效率和查询时间都远远超过一般的算法,缺点是有一定的误识别率和删除困难。
布隆过滤器注释:
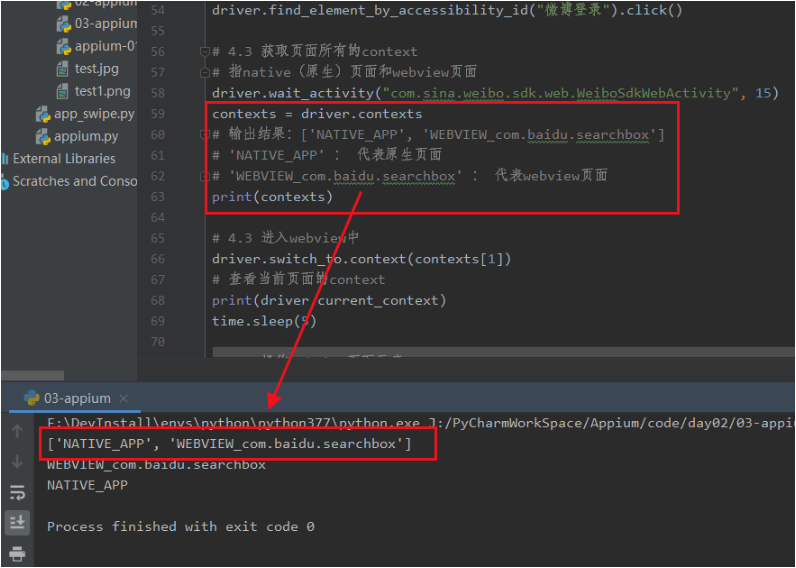
布隆过滤器(Bloom Filter)本质上是由长度为 m 的位向量或位列表(仅包含 0 或 1 位值的列表)组成,最初所有的值均设置为 0,如下图所示。

为了将数据项添加到布隆过滤器中,我们会提供 K 个不同的哈希函数,并将结果位置上对应位的值置为 “1”。在前面所提到的哈希表中,我们使用的是单个哈希函数,因此只能输出单个索引值。而对于布隆过滤器来说,我们将使用多个哈希函数,这将会产生多个索引值。
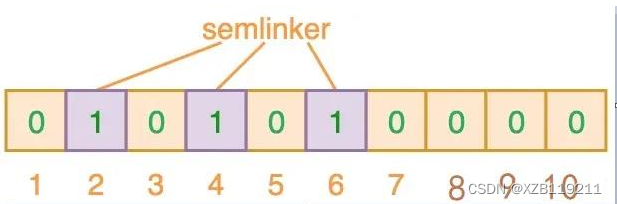
如上图所示,当输入 “semlinker” 时,预设的 3 个哈希函数将输出 2、4、6,我们把相应位置 1。假设另一个输入 ”kakuqo“,哈希函数输出 3、4 和 7。你可能已经注意到,索引位 4 已经被先前的 “semlinker” 标记了。此时,我们已经使用 “semlinker” 和 ”kakuqo“ 两个输入值,填充了位向量。当前位向量的标记状态为:
当对值进行搜索时,与哈希表类似,我们将使用 3 个哈希函数对 ”搜索的值“ 进行哈希运算,并查看其生成的索引值。假设,当我们搜索 ”fullstack“ 时,3 个哈希函数输出的 3 个索引值分别是 2、3 和 7:
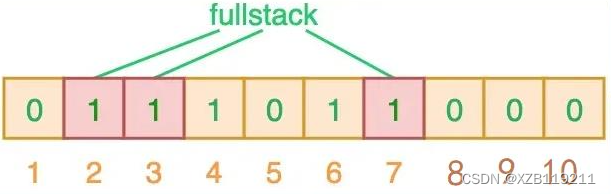
从上图可以看出,相应的索引位都被置为 1,这意味着我们可以说 ”fullstack“ 可能已经插入到集合中。事实上这是误报的情形,产生的原因是由于哈希碰撞导致的巧合而将不同的元素存储在相同的比特位上。
那么我们如何选择哈希函数个数和布隆过滤器长度
很显然,过小的布隆过滤器很快所有的bit位均为1,那么查询任何值都会返回“可能存在”,起不到过滤的目的了。布隆过滤器的长度会直接影响误报率,布隆过滤器越长其误报率越小。
另外,哈希函数的个数也需要权衡,个数越多则布隆过滤器 bit 位置位 1 的速度越快,且布隆过滤器的效率越低;但是如果太少的话,那我们的误报率会变高。
(3)方案对比

缓存击穿
理解:
在电商平台中,有需要批量导入一大批商品的问题,而这些商品的redis缓存过期时间都是24小时, 那当24小时之后,这一大批的商品数据同一时间过期,而此时的商品访问需求还很大,将导致直接区查询数据库的压力倍增, 这就是redis缓存击穿的问题。
解决方案:
(1)商品设置永不过期
(2)商品过期时间设置随机值
缓存雪崩
理解:
如果缓存集中在一段时间内失效,发生大量的缓存穿透,所有的查询都落在数据库上,造成了缓存雪崩。
解决方案:
(1)缓存层高可用:
可以把缓存层设计成高可用的,即使个别节点、个别机器、甚至是机房宕掉,依然可以提供服务。利用sentinel或cluster实现。
(2)做二级缓存,或者双缓存策略:
采用多级缓存,本地进程作为一级缓存,redis作为二级缓存,不同级别的缓存设置的超时时间不同,即使某级缓存过期了,也有其他级别缓存兜底。
(3)数据预热:
可以通过缓存reload机制,预先去更新缓存,再即将发生大并发访问前手动触发加载缓存不同的key,设置不同的过期时间,让缓存失效的时间点尽量均匀。