大家好,我是极智视界,欢迎关注我的公众号,获取我的更多前沿科技分享
邀您加入我的知识星球「极智视界」,星球内有超多好玩的项目实战源码和资源下载,链接:https://t.zsxq.com/0aiNxERDq
12 月 1 日阿里开源了 72B 和 18B 大模型以及音频大模型 Qwen-Audio,再加上之前八月份、九月份开源的 7B 和 14B 大模型,号称是 "全尺寸开源"。我也去 Github 上瞅了一眼,通义应该确实是 "兜库底" 了,所有规格的模型都开源了。
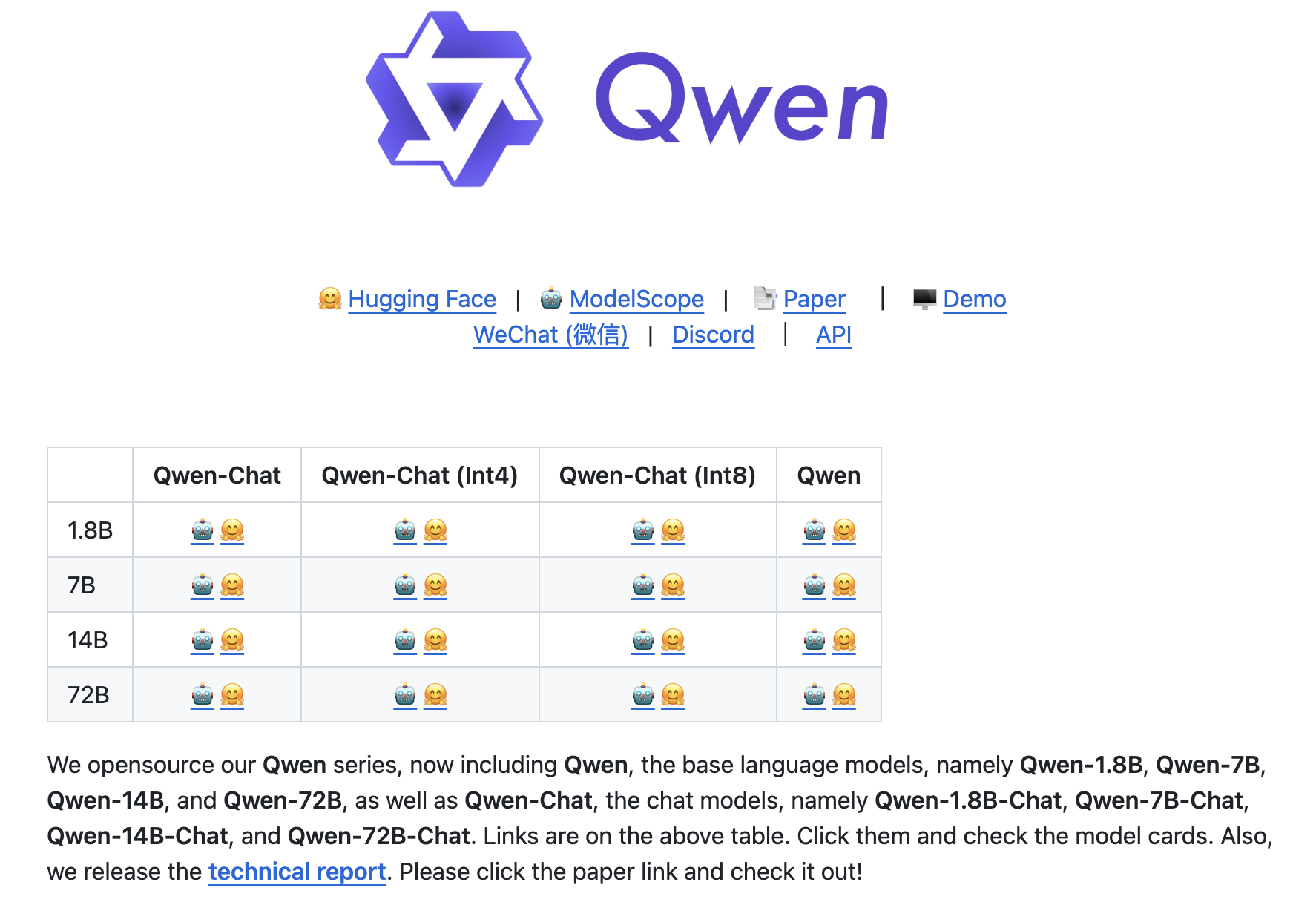
对于这个事情,我的第一反应是:难得啊,对于阿里这种技术相对封闭的公司来说。但是仔细想想,目前对于大模型来说,开不开源真的很重要吗?其实是需要打个问号的,除非你 OpenAI 的 GPT-4 开源,不然业界应该很难激起过多的浪花,因为大家都见多不怪了。现在对于大模型真正卡脖子地方是在 "算力" 和 "数据" 上,而不在 "算法" 上。以前是这三驾马车都很重要,然后算法可能会更加重要一些。但是现在大模型时代则不太一样,特别是在美国芯片禁令的情况下,主要矛盾已经明显倾向于对于算力的需求上。现在国内很多大模型从算法实现角度,都可以用 "套壳" LLaMA 来达到 "自研大模型" 商业化的目的,这个时候你通义开不开源其实并不太重要。而说到 "套壳",就又是另外一个有意思的话题了,这里不过多展开。

现在主要矛盾点在于我要有足够的算力、足够高质量的数据来进行微调,甚至是从头训练。对于很多大模型厂商来说,区别只是在我选 LLaMA 来微调还是选通义大模型来微调,而相信大多还是会选 LLaMA。这其实可以类比到手机领域,安卓大家都可以用,很多时候有安卓就够了,你鸿蒙开源对于小米、对于 vivo 的操作系统研发意义大吗,我小米会把自己手机操作系统切到基于鸿蒙的吗 (可能确实有参考意义,比如对于小米澎湃 OS 的研发,但是对于大多数厂商来说还是用安卓就够够的了),大家更加在意的是能够拥有性能更加好的芯片、算力更加好的处理器,比如前段时间经常上热搜的全大核天玑 9300,这才是核心竞争力。

虽然 (是反转没错了),在大家有 LLaMA 可选的情况下,通义的开源意义确实不大。但是开源总能赢得好名声,这点毋庸置疑,何况通义开源了自己全规格的模型,其开源的 70B 大模型也是目前开源大模型中最大规模的,可以说 "诚意满满",对于博一个好名声应该是不难的,这是 "名"。
然后咱们来说说 "利",通义大模型是开源了,大家要用、要微调得要有算力吧,算力哪里来,答案就是阿里云,你品,你细品。来,继续分析,阿里还有个号称国产 HaggingFace 的魔塔 ModelScope,要用开源的通义你就得上魔塔,而魔塔部署在哪里呢,魔塔的算力来源于哪里呢,答案依旧是阿里云,你品,你细品。阿里的这招太 "精明" 了,真的是既想要名也想要利啊。
从这个角度来说,其实在 12 月 1 日阿里宣布全量开源通义前问大模型的时候,阿里已经彻底换赛道了,已经是不想跟大家玩大模型了,已经不再是 "百模大战" 中的一员了。未来,"百模大战" 肯定会继续,而阿里更加聪明,烧钱去做大模型,效果嘛打不过 GPT-4,落地商业化嘛又难,竞争对手又像疯了一样的涌进来,换个赛道,躺着挣钱它不香嘛。这大概率也是在学英伟达、特别是在学 AWS。提供付费算力,这才是大模型时代正确的挣钱的方式啊,这些才是大模型时代挣麻了的企业啊。继续给阿里支招,继续开源数据集,让大家在阿里云上训练(烧钱)彻底没有技术上的障碍,而变成一个愿不愿意花钱的问题。

阿里云,是懂计算的。计算无法计算的价值,数钱数到手抽筋。

【极智视界】
《解读 | 阿里通义千问模型全尺寸开源 "诚意满满"背后的名与利》