一、框架架构
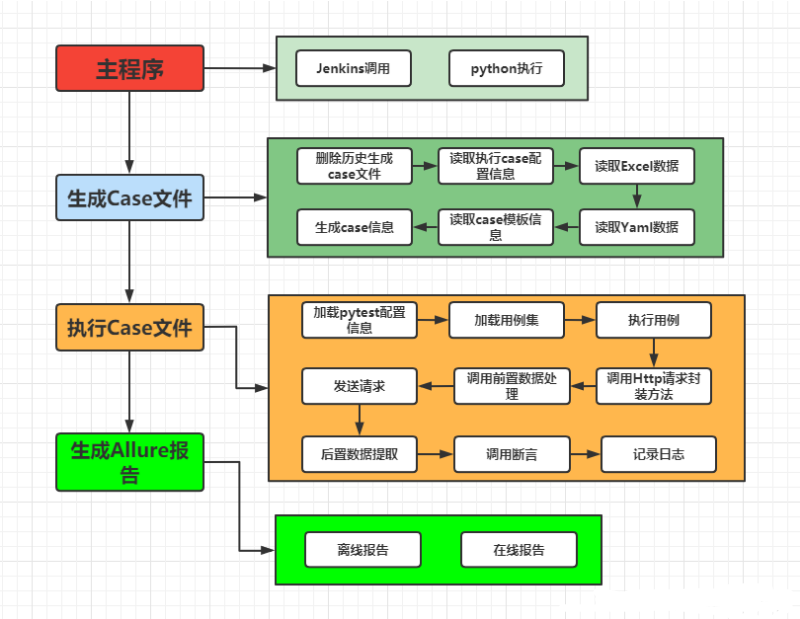
二、项目目录结构

三、框架功能说明
解决痛点:
- 通过session会话方式,解决了登录之后cookie关联处理
- 框架天然支持接口动态传参、关联灵活处理
- 支持Excel、Yaml文件格式编写接口用例,通过简单配置框架自动读取并执行
- 执行环境一键切换,解决多环境相互影响问题
- 支持http/https协议各种请求、传参类型接口
- 响应数据格式支持json、str类型的提取操作
- 断言方式支持等于、包含、大于、小于、不等于等方
- 框架可以直接交给不懂代码的功能测试人员使用,只需要安装规范编写接口用例就行
框架使用说明:
- 安装依赖包:
pip install -r requirements.txt - 框架主入口为
run.py文件 - 编写用例可以在
Excel或者Yaml文件里面,按照示例编写即可,也可以在test_case目录下通过python脚本编写case - 断言或者提取参数都是通过
jsonpath、正则表达式提取数据 - 用例执行时默认读取
Excel和test_case目录下用例
四、核心逻辑说明
工具类封装
assert_util.py 断言工具类封装
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 |
|
case_handle.py Case数据读取工具类
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 |
|
excel_handle.py 读取Excel工具类
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 |
|
yaml_handle.py 读取Yaml文件的工具类
| 1 2 3 4 5 6 7 8 9 10 |
|
配置文件
config.yaml 配置信息
| 1 2 3 4 |
|
输出目录
日志输出目录
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 |
|
报告目录
执行case后自动生成,执行之前自动删除
allure 数据目录
执行case后自动生成,执行之前自动删除
请求工具类
base_request.py 请求封装工具类
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 |
|
pre_handle_utils.py 请求前置处理工具类
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
|
after_handle_utils.py 后置操作处理工具类
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
|
代码编写case
test_demo.py 用例文件示例
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
|
程序主入口
run.py 主入口执行文件
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
|
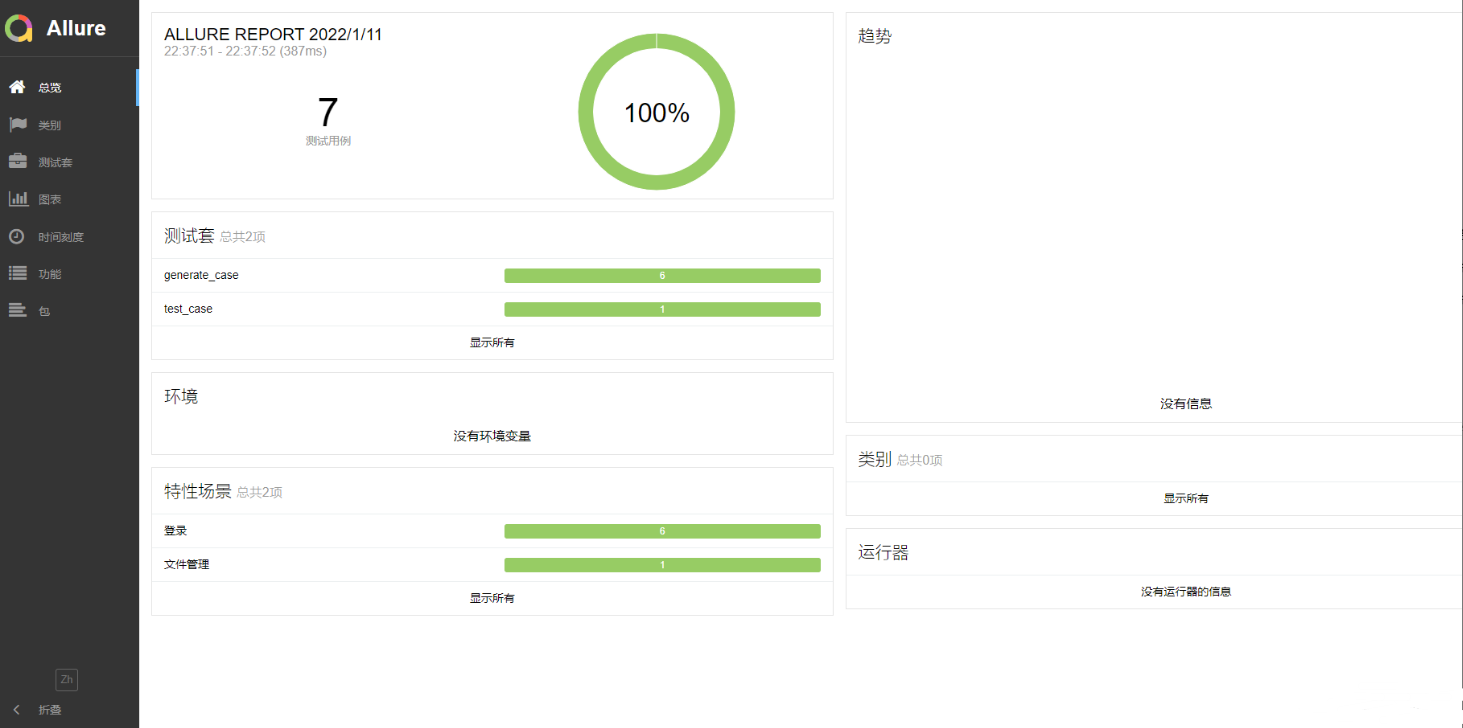
执行记录
allure 报告

日志记录
[2022-01-11 22:36:04,164] base_request.py - INFO - 42 - 开始执行用例: 正常登录
[2022-01-11 22:36:04,165] pre_handle_utils.py - INFO - 37 - 开始进行字符串替换: 替换字符串为:bank/api/login
[2022-01-11 22:36:04,165] pre_handle_utils.py - INFO - 44 - 字符串替换完成: 替换字符串后为:bank/api/login
[2022-01-11 22:36:04,165] pre_handle_utils.py - INFO - 68 - 处理请求前url:bank/api/login
[2022-01-11 22:36:04,165] pre_handle_utils.py - INFO - 78 - 处理请求后 url:http://localhost:8091/bank/api/login
[2022-01-11 22:36:04,165] pre_handle_utils.py - INFO - 90 - 处理请求前Data: {'password': '123456', 'userName': 'king'}
[2022-01-11 22:36:04,165] pre_handle_utils.py - INFO - 37 - 开始进行字符串替换: 替换字符串为:{'password': '123456', 'userName': 'king'}
[2022-01-11 22:36:04,166] pre_handle_utils.py - INFO - 44 - 字符串替换完成: 替换字符串后为:{'password': '123456', 'userName': 'king'}
[2022-01-11 22:36:04,166] pre_handle_utils.py - INFO - 92 - 处理请求后Data: {'password': '123456', 'userName': 'king'}
[2022-01-11 22:36:04,166] pre_handle_utils.py - INFO - 100 - 处理请求前files: None
[2022-01-11 22:36:04,175] base_request.py - INFO - 53 - 请求响应数据{"code":"0","message":"success","data":null}
[2022-01-11 22:36:04,176] data_handle.py - INFO - 29 - 提取响应内容成功,提取表达式为: $.code 提取值为 0
[2022-01-11 22:36:04,176] assert_util.py - INFO - 49 - 第1个断言数据,实际结果:0 | 预期结果:0 断言方式:eq
[2022-01-11 22:36:04,176] data_handle.py - INFO - 29 - 提取响应内容成功,提取表达式为: $.message 提取值为 success
[2022-01-11 22:36:04,176] assert_util.py - INFO - 49 - 第2个断言数据,实际结果:success | 预期结果:success 断言方式:eq现在我也找了很多测试的朋友,做了一个分享技术的交流群,共享了很多我们收集的技术文档和视频教程。
如果你不想再体验自学时找不到资源,没人解答问题,坚持几天便放弃的感受
可以加入我们一起交流。而且还有很多在自动化,性能,安全,测试开发等等方面有一定建树的技术大牛
分享他们的经验,还会分享很多直播讲座和技术沙龙
可以免费学习!划重点!开源的!!!
qq群号:485187702【暗号:csdn11】最后感谢每一个认真阅读我文章的人,看着粉丝一路的上涨和关注,礼尚往来总是要有的,虽然不是什么很值钱的东西,如果你用得到的话可以直接拿走! 希望能帮助到你!【100%无套路免费领取】