redis 中的字符串, 是按照二进制的方式存储和读取的, 即存啥取啥, 所以一般不会出现乱码问题
(乱码问题是因为存储和读取时使用的编码方式不一样, 但是 redis 没有编码转换)
redis 限制了 string 的大小 : 512M, 因为 单线程模型 希望进行的操作能够比较快速, 越大越慢

set key value [expiration EX seconds | PX milliseconds ] [NX | XX]
eg : set key value ex 10
expiration 超时时间
EX 以秒为单位
PX 以毫秒为单位
NX 如果 key 不存在, 才设置, 存在则不设置, 返回 nil
XX 如果 key 存在, 才设置(相当于更新 key 的 value), 不存在则不设置, 返回 nil
setnx key <==> set key NX
不存在才能设置, 存在则设置失效
setex key seconds
设置过期时间 秒
setpx key milliseconds
设置过期时间 毫秒
如果 key 不存在, 就创建新的键值对.
如果 key 存在, 则是让新的 value 覆盖旧的 value, 可能会改变原来的数据类型, 原来的 key 的 ttl (生存时间) 也会失效
mset key value [key value …] – O(k)
一次添加多个键值对
mget key [key …] – O(k)
一次获取多个键的值
下面几个操作要求 key 的 value 必须是整数
redis 中整数代表的范围: 64位 / 8位表示的整数, 相当于 C++ 中的 long long 或 Java 中的 long
incr key – O(1)
针对 key 的值 +1, 返回的是 +1 之后的值, 相当于 (++key)
incrby key n – O(1)
针对 key 的值 +n
decr key – O(1)
针对 key 的值 -1
decrby key n – O(1)
针对 key 的值 -n
incrbyfloat key value – O(1)
把 key 对应的 value 进行 + / - 操作, 运算的操作可以是 浮点数
" - " 操作通过负数来实现
append key value
返回值是增添字符的长度
strlen key
获取到字符串的长度
setrange key offset value
从下表从 offset 开始, 往 key 对应的值中插入value,并顶替掉原来该位置上的字符
getrange key start end
获取 key 对应的 value 的 [start, end] 位之上的字符
-1 代表倒数第一个字符
即 “getrange key 0 -1” ----- 代表获取该 key 对应的值
object encoding key
查看 key 值得编码类型
string 内部有三种编码方式
- int 64位 / 8字节 的整数
- embstr 压缩字符串, 适用于表示比较短的字符串
- raw 普通字符串, 适用于表示比较长的字符串(长度可改写, 所以不建议硬记 ---- 39字节)
string 应用场景
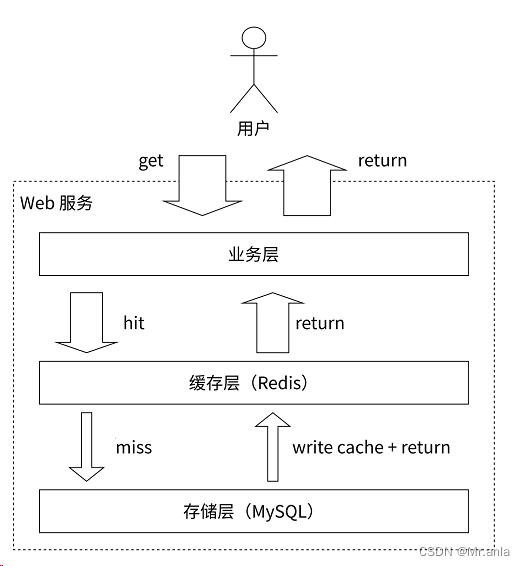
数据查询的整体思路:
应用服务器先查 redis , 查到了就返回数据, 查不到再查 MySQL, 将数据返回服务器的同时, 把数据写入到 redis 中.
上述行为, 经常用来被存储 “热点” 数据 (高频被使用的数据)
但是随着时间推移, redis 上的数据会越来越多, 因此解决方案如下:
- 给存储的数据设置一个过期时间
- redis 在内存不足的时候, 提供了淘汰策略