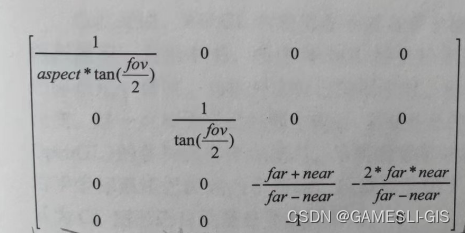第 6 部分 — 对 LLM 的对抗性攻击。数学和战略分析
一、说明
针对大型语言模型(LLM)的对抗性攻击代表了人工智能安全中一个复杂的关注领域,需要数学严谨性和战略远见的复杂结合。这些攻击旨在操纵 LLM 产生意想不到的输出,范围从微妙的输入更改到利用系统漏洞。
在这篇博客中,我提供了深刻的数学理解,这对于制定稳健的对策至关重要。该博客面向人工智能研究人员。

二、输入扰动:高级灵敏度分析
输入扰动攻击是 LLM 安全性中的一个关键问题,可以通过先进的高阶敏感性分析来深刻理解。该分析超越了线性近似,捕捉了LLM对输入变化响应的细微差别且通常是非线性的本质。
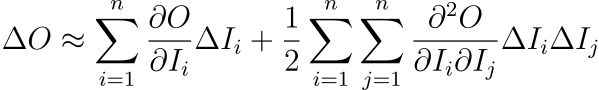
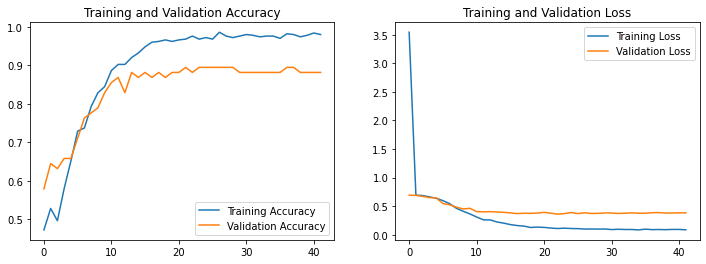
其中,Δ O表示输出的变化,∂ O/ ∂ I_i 和 ∂² O/ ∂ I_i ∂ I_j 是输出相对于输入的一阶和二阶偏导数,表明模型对分别是线性和非线性输入变化。这种高阶分析揭示了输入变化是如何微妙地导致复杂、显着的输出偏差的。
示例:财经新闻分析LLM
想象一下,一个旨在分析金融新闻和预测市场趋势的LLM。金融领域充满了微妙的语言,其中特定术语可能会微妙地影响声明的情绪和含义。
场景:经济指标分析
考虑一份财务报告,其中写道:“央行正在考虑对通胀采取温和立场。” LLM的任务是解释这一声明并预测其对市场的潜在影响。但如果表述稍作修改为“央行正在考虑对通胀采取谨慎立场”,市场解读和情绪分析就会大不相同。
高阶灵敏度分析应用
在这种情况下,高阶敏感性分析涉及了解经济政策背景下的“温和”和“谨慎”等具体术语如何对市场情绪产生截然不同的影响。分析不仅关注这些关键词,还关注它们如何与句子的其余部分以及更广泛的经济背景相互作用。
例如,从“温和”到“谨慎”的转变改变了央行对通胀的看法,这可能导致投资者对未来货币政策及其对市场的影响得出不同的结论。
实际影响
在现实世界的应用中,例如自动化财务咨询服务或投资分析工具,准确解读财经新闻的基调和含义至关重要。由于术语的细微变化而产生的误解可能会导致错误的市场预测,影响投资决策和财务策略。
三. 上下文误导:概率图形模型
LLM中的上下文误导是一种复杂的对抗性攻击形式,可以使用先进的概率图形模型进行复杂的分析。这些模型深入研究输入中各种元素之间复杂的依赖关系和交互作用,提供对上下文如何影响 LLM 输出的更深入的理解。
为了增强分析,我们可以采用更复杂的贝叶斯网络方法,它允许条件依赖关系的细微差别表示:

在这里,
- P ( O ∣ C 1, C 2,…, Cn ) 是在给定一组上下文元素C 1, C 2,…, Cn的情况下生成输出O的概率。
- Pa( Ci ) 表示贝叶斯网络中Ci的父节点集合,捕获每个上下文元素的直接影响因素。
- i上的乘积表明总体概率受到所有上下文元素及其各自父节点的组合的影响。
该模型更详细地表示了不同的上下文元素及其相互关系如何共同影响输出。
示例:新闻文章摘要中的上下文分析
考虑一个专为总结新闻文章而设计的LLM。该模型必须考虑各种上下文元素,例如文章的主题、来源可信度以及特定实体的存在(例如人名或地名)。如果操纵上下文,例如通过引入有偏见的信息或改变对某些实体的重点,则可能会发生误导。先进的概率图形模型有助于识别这些操作如何扭曲摘要,从而导致新闻内容的偏见或不准确的表示。
进一步的数学扩展: 条件随机场 (CRF)
对于更复杂的分析,可以采用条件随机场 (CRF),特别是在文本等序列数据中:

在哪里:
- O 1、O 2、…、Om 是序列中不同点的输出。
- Z ( C ) 是确保概率总和为 1 的归一化因子。
- λk是训练期间学习到的权重。
- fk ( O , C ) 是捕获输出序列和上下文元素之间关系的特征函数。
简单来说,该方程表示 CRF 模型中特定输出序列的概率如何由捕获输出序列和上下文元素之间关系的特征函数的组合来确定。权重λk表示每个特征函数在确定概率时的重要性。CRF 在序列建模任务中特别有用,其中序列中元素之间的上下文和相互依赖性至关重要,例如在自然语言处理任务中,例如词性标记或命名实体识别。
四、利用模型漏洞:复杂系统漏洞分析
识别和利用模型架构或训练数据中的弱点是确保大型语言模型 (LLM) 稳健性的一个关键方面。这可以通过复杂的系统漏洞分析来实现,采用先进的数学技术来全面评估模型对各种类型弱点的敏感性。
漏洞分析可以扩展到包括更复杂的功能分析方法:
![]()
在哪里,
- V ( M )表示模型M的整体脆弱性。
- Susceptibility( M , W ) 量化模型对特定弱点W的敏感性。
- γ ( W , M ) 是一个权重函数,根据每个弱点对模型的潜在影响为其分配重要性。
- ImpactFactor( M , W ) 是一个附加项,用于评估每个弱点对模型性能和可靠性的潜在影响。
- 对W 的积分可确保考虑所有可能的弱点,从而提供模型漏洞的整体视图。
简而言之,该方程提供了一种通过整合所有潜在弱点来量化模型脆弱性的方法,同时考虑到模型对每个弱点的敏感程度以及每个弱点的潜在影响。这种方法对于识别和解决法学硕士等复杂系统中最重要的漏洞至关重要。
示例:语言翻译LLM中的漏洞分析
考虑专为语言翻译而设计的LLM。这种情况下的漏洞可能包括容易对惯用语产生错误的翻译或无法捕捉文化的细微差别。扩展的脆弱性分析将系统地评估这些弱点,考虑源语言中惯用表达的频率和模型处理文化背景的能力等因素。加权函数γ ( W , M ) 可能会对导致严重误译或文化误解的弱点赋予更高的重要性。影响因子将评估这些弱点如何影响整体翻译质量和用户信任。
进一步的数学扩展:量化模型的稳健性
为了量化模型针对已识别漏洞的稳健性,我们可以引入稳健性指标:
![]()
在这里,
- R ( M ) 是模型M的鲁棒性度量。
- V max是最大可能的漏洞分数,代表最坏的情况。
该指标提供了模型稳健性的标准化度量,值越接近 1 表明稳健性越高。
简而言之,该方程提供了模型鲁棒性的标准化度量。漏洞V ( M ) 是相对于最坏情况漏洞V max 进行评估的。R ( M )值越高(越接近 1)表明鲁棒性越高,这意味着模型不易受到潜在弱点或攻击的影响。该指标在评估和比较不同模型或系统的弹性时特别有用。
五、 缓解策略
针对这些对抗性攻击的有效对策包括:
非线性输入过滤:高级算法公式
可以使用包含高阶张量运算的算法来增强非线性输入滤波,以检测和消除复杂的输入扰动。数学公式可能涉及基于张量的非线性变换:
![]()
在这种情况下,T 表示复杂的非线性变换,用于处理输入数据F_ input以检测和减轻高阶扰动。参数 θ 通常是通过训练学习或优化的,允许转换自适应地过滤掉可能导致不正确的模型输出的细微输入变化。这种方法对于增强 LLM 抵御利用输入数据中的非线性依赖性的复杂对抗性攻击的鲁棒性特别有用。
示例:在文本分类任务中,这种方法可能涉及使用张量运算将输入文本转换为更高维的空间,其中细微的扰动变得更容易区分,并且可以在分类之前有效地消除。
上下文完整性检查:概率模型增强
可以使用包含条件依赖性和潜在变量的增强概率模型来加强上下文完整性检查:
![]()
其中,P ( O ∣ C , L ) 是在给定上下文C和一组潜在变量L的情况下生成输出O的概率。P ( O ∣ C , l ) 是给定上下文和特定潜在变量l的输出的条件概率,P ( l ∣ C ) 是给定上下文的潜在变量的概率。该模型可以更深入地理解上下文影响,包括隐藏因素。
示例:在新闻文章生成的LLM中,该模型不仅可以帮助理解显性内容的影响,还可以帮助理解潜在因素(例如源材料中的潜在语气或偏见)的影响。
动态漏洞修补:自适应学习公式
动态漏洞修补可以使用自适应学习算法进行建模,该算法不断更新模型参数以响应已识别的漏洞:
![]()
其中, θ t +1 表示t +1时刻更新的模型参数, θ t 是当前参数,η是学习率, ∇ V (θ t ) 是脆弱性函数相对于模型参数。这种公式确保模型随着时间的推移适应并提高其防御能力。
示例:在用于自动代码生成的LLM中,这种方法将涉及根据对手使用的最新模式和技术,不断更新模型以识别和缓解代码注入攻击等漏洞。
解决对法学硕士的对抗性攻击需要深刻的数学理解和战略实施。通过集成复杂的数学策略,例如高阶敏感性分析、概率图形模型和全面的系统漏洞分析,我们可以增强LLM抵御各种复杂的对抗策略的能力,确保其在不同应用中的可靠性和完整性。