在配置训练、验证和测试数据集的过程中做出正确决策会在很大程度上帮助大家创建高效的神经网络。训练神经网络时,需要做出很多决策,例如:
-
神经网络分多少层
-
每层含有多少个隐藏单元
-
学习速率是多少
-
各层采用哪些激活函数
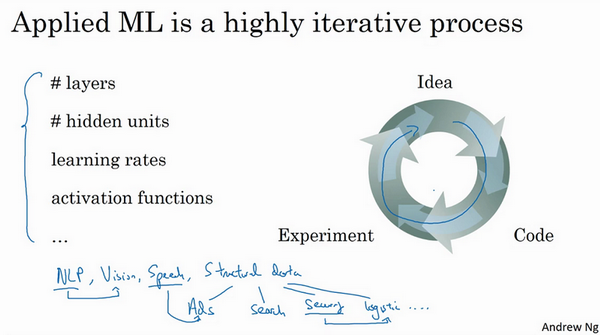
创建新应用的过程中,不可能从一开始就准确预测出这些信息和其他超级参数。实际上,应用型机器学习是一个高度迭代的过程,通常在项目启动时,会先有一个初步想法,比如构建一个含有特定层数,隐藏单元数量或数据集个数等等的神经网络,然后编码,并尝试运行这些代码,通过运行和测试得到该神经网络或这些配置信息的运行结果,可能会根据输出结果重新完善自己的想法,改变策略,或者为了找到更好的神经网络不断迭代更新自己的方案。
现如今,深度学习已经在自然语言处理,计算机视觉,语音识别以及结构化数据应用等众多领域取得巨大成功。结构化数据无所不包,从广告到网络搜索。其中网络搜索不仅包括网络搜索引擎,还包括购物网站,从所有根据搜索栏词条传输结果的网站。再到计算机安全,物流,比如判断司机去哪接送货,范围之广,不胜枚举。
我发现,可能有自然语言处理方面的人才想踏足计算机视觉领域,或者经验丰富的语音识别专家想投身广告行业,又或者,有的人想从电脑安全领域跳到物流行业,在我看来,从一个领域或者应用领域得来的直觉经验,通常无法转移到其他应用领域,最佳决策取决于所拥有的数据量,计算机配置中输入特征的数量,用GPU训练还是CPU,GPU和CPU的具体配置以及其他诸多因素。

目前为止,对于很多应用系统,即使是经验丰富的深度学习行家也不太可能一开始就预设出最匹配的超级参数,所以说,应用深度学习是一个典型的迭代过程,需要多次循环往复,才能为应用程序找到一个称心的神经网络,因此循环该过程的效率是决定项目进展速度的一个关键因素,而创建高质量的训练数据集,验证集和测试集也有助于提高循环效率。

假设这是训练数据,用一个长方形表示,通常会将这些数据划分成几部分,一部分作为训练集,一部分作为简单交叉验证集,有时也称之为验证集,方便起见,就叫它验证集(dev set),其实都是同一个概念,最后一部分则作为测试集。
接下来,开始对训练集执行算法,通过验证集或简单交叉验证集选择最好的模型,经过充分验证,选定了最终模型,然后就可以在测试集上进行评估了,为了无偏评估算法的运行状况。
在机器学习发展的小数据量时代,常见做法是将所有数据三七分,就是人们常说的70%训练集,30%测试集。如果明确设置了验证集,也可以按照60%训练集,20%验证集和20%测试集来划分。这是前几年机器学习领域普遍认可的最好的实践方法。
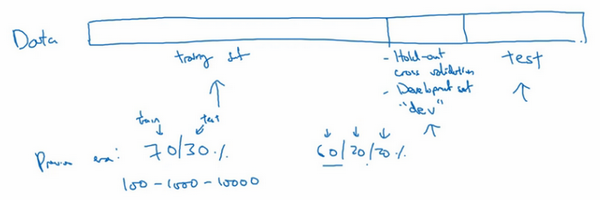
如果只有100条,1000条或者1万条数据,那么上述比例划分是非常合理的。
但是在大数据时代,现在的数据量可能是百万级别,那么验证集和测试集占数据总量的比例会趋向于变得更小。因为验证集的目的就是验证不同的算法,检验哪种算法更有效,因此,验证集只要足够大到能评估不同的算法,比如2个甚至10个不同算法,并迅速判断出哪种算法更有效。可能不需要拿出20%的数据作为验证集。
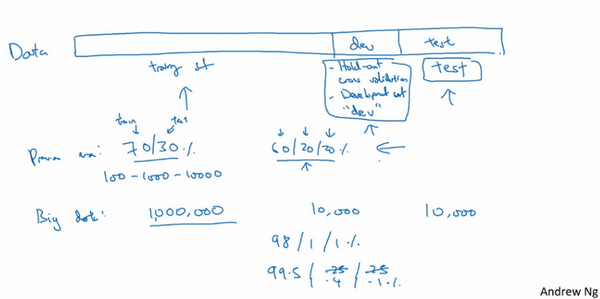
比如有100万条数据,那么取1万条数据便足以进行评估,找出其中表现最好的1-2种算法。同样地,根据最终选择的分类器,测试集的主要目的是正确评估分类器的性能,所以,如果拥有百万数据,只需要1000条数据,便足以评估单个分类器,并且准确评估该分类器的性能。假设有100万条数据,其中1万条作为验证集,1万条作为测试集,100万里取1万,比例是1%,即:训练集占98%,验证集和测试集各占1%。对于数据量过百万的应用,训练集可以占到99.5%,验证和测试集各占0.25%,或者验证集占0.4%,测试集占0.1%。
总结一下,在机器学习中,通常将样本分成训练集,验证集和测试集三部分,数据集规模相对较小,适用传统的划分比例,数据集规模较大的,验证集和测试集要小于数据总量的20%或10%。
现代深度学习的另一个趋势是越来越多的人在训练和测试集分布不匹配的情况下进行训练,假设要构建一个用户可以上传大量图片的应用程序,目的是找出并呈现所有猫咪图片,可能的用户都是爱猫人士,训练集可能是从网上下载的猫咪图片,而验证集和测试集是用户在这个应用上上传的猫的图片,就是说,训练集可能是从网络上抓下来的图片。而验证集和测试集是用户上传的图片。结果许多网页上的猫咪图片分辨率很高,很专业,后期制作精良,而用户上传的照片可能是用手机随意拍摄的,像素低,比较模糊,这两类数据有所不同,针对这种情况,根据经验,建议大家要确保验证集和测试集的数据来自同一分布,关于这个问题也会多讲一些。因为们要用验证集来评估不同的模型,尽可能地优化性能。如果验证集和测试集来自同一个分布就会很好。
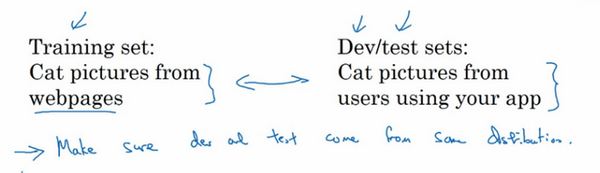
但由于深度学习算法需要大量的训练数据,为了获取更大规模的训练数据集,可以采用当前流行的各种创意策略,例如,网页抓取,代价就是训练集数据与验证集和测试集数据有可能不是来自同一分布。但只要遵循这个经验法则,就会发现机器学习算法会变得更快。
最后一点,就算没有测试集也不要紧,测试集的目的是对最终所选定的神经网络系统做出无偏估计,如果不需要无偏估计,也可以不设置测试集。所以如果只有验证集,没有测试集,要做的就是,在训练集上训练,尝试不同的模型框架,在验证集上评估这些模型,然后迭代并选出适用的模型。因为验证集中已经涵盖测试集数据,其不再提供无偏性能评估。当然,如果不需要无偏估计,那就再好不过了。

在机器学习中,如果只有一个训练集和一个验证集,而没有独立的测试集,遇到这种情况,训练集还被人们称为训练集,而验证集则被称为测试集,不过在实际应用中,人们只是把测试集当成简单交叉验证集使用,并没有完全实现该术语的功能,因为他们把验证集数据过度拟合到了测试集中。如果某团队跟说他们只设置了一个训练集和一个测试集,会很谨慎,心想他们是不是真的有训练验证集,因为他们把验证集数据过度拟合到了测试集中,让这些团队改变叫法,改称其为“训练验证集”,而不是“训练测试集”,可能不太容易。即便认为“训练验证集“在专业用词上更准确。实际上,如果不需要无偏评估算法性能,那么这样是可以的。

所以说,搭建训练验证集和测试集能够加速神经网络的集成,也可以更有效地衡量算法地偏差和方差,从而帮助更高效地选择合适方法来优化算法。