四、DataFrame存储+Spark UDF函数
1、储存DataFrame
1)、将DataFrame存储为parquet文件
2)、将DataFrame存储到JDBC数据库
3)、将DataFrame存储到Hive表
2、UDF:用户自定义函数
可以自定义类实现UDFX接口
java:
SparkConf conf = new SparkConf();
conf.setMaster("local");
conf.setAppName("udf");
JavaSparkContext sc = new JavaSparkContext(conf);
SQLContext sqlContext = new SQLContext(sc);
JavaRDD<String> parallelize = sc.parallelize(Arrays.asList("zhansan","lisi","wangwu"));
JavaRDD<Row> rowRDD = parallelize.map(new Function<String, Row>() {
/**
*
*/
private static final long serialVersionUID = 1L;
@Override
public Row call(String s) throws Exception {
return RowFactory.create(s);
}
});
List<StructField> fields = new ArrayList<StructField>();
fields.add(DataTypes.createStructField("name", DataTypes.StringType,true));
StructType schema = DataTypes.createStructType(fields);
DataFrame df = sqlContext.createDataFrame(rowRDD,schema);
df.registerTempTable("user");
/**
* 根据UDF函数参数的个数来决定是实现哪一个UDF UDF1,UDF2。。。。UDF1xxx
*/
sqlContext.udf().register("StrLen", new UDF1<String,Integer>() {
/**
*
*/
private static final long serialVersionUID = 1L;
@Override
public Integer call(String t1) throws Exception {
return t1.length();
}
}, DataTypes.IntegerType);
sqlContext.sql("select name ,StrLen(name) as length from user").show();
//sqlContext.udf().register("StrLen",new UDF2<String, Integer, Integer>() {
//
// /**
// *
// */
// private static final long serialVersionUID = 1L;
//
// @Override
// public Integer call(String t1, Integer t2) throws Exception {
//return t1.length()+t2;
// }
//} ,DataTypes.IntegerType );
//sqlContext.sql("select name ,StrLen(name,10) as length from user").show();
sc.stop(); scala:
1.val spark = SparkSession.builder().master("local").appName("UDF").getOrCreate()
2.val nameList: List[String] = List[String]("zhangsan", "lisi", "wangwu", "zhaoliu", "tianqi")
3.import spark.implicits._
4.val nameDF: DataFrame = nameList.toDF("name")
5.nameDF.createOrReplaceTempView("students")
6.nameDF.show()
7.
8.spark.udf.register("STRLEN",(name:String)=>{
9.name.length
10.})
11.spark.sql("select name ,STRLEN(name) as length from students order by length desc").show(100)五、UDAF函数
1、UDAF:用户自定义聚合函数
1)、实现UDAF函数如果要自定义类要继承
UserDefinedAggregateFunction类
2)、UDAF原理图
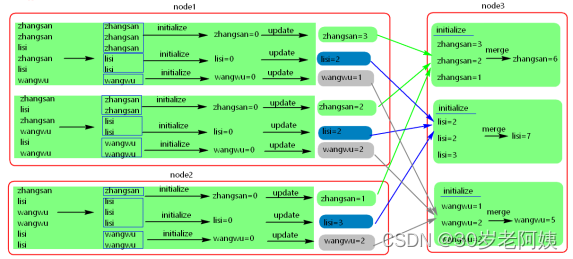
java:
SparkConf conf = new SparkConf();
conf.setMaster("local").setAppName("udaf");
JavaSparkContext sc = new JavaSparkContext(conf);
SQLContext sqlContext = new SQLContext(sc);
JavaRDD<String> parallelize = sc.parallelize(Arrays.asList("zhansan","lisi","wangwu","zhangsan","zhangsan","lisi"));
JavaRDD<Row> rowRDD = parallelize.map(new Function<String, Row>() {
/**
*
*/
private static final long serialVersionUID = 1L;
@Override
public Row call(String s) throws Exception {
return RowFactory.create(s);
}
});
List<StructField> fields = new ArrayList<StructField>();
fields.add(DataTypes.createStructField("name", DataTypes.StringType, true));
StructType schema = DataTypes.createStructType(fields);
DataFrame df = sqlContext.createDataFrame(rowRDD, schema);
df.registerTempTable("user");
/**
* 注册一个UDAF函数,实现统计相同值得个数
* 注意:这里可以自定义一个类继承UserDefinedAggregateFunction类也是可以的
*/
sqlContext.udf().register("StringCount", new UserDefinedAggregateFunction() {
/**
*
*/
private static final long serialVersionUID = 1L;
/**
* 更新 可以认为一个一个地将组内的字段值传递进来 实现拼接的逻辑
* buffer.getInt(0)获取的是上一次聚合后的值
* 相当于map端的combiner,combiner就是对每一个map task的处理结果进行一次小聚合
* 大聚和发生在reduce端.
* 这里即是:在进行聚合的时候,每当有新的值进来,对分组后的聚合如何进行计算
*/
@Override
public void update(MutableAggregationBuffer buffer, Row arg1) {
buffer.update(0, buffer.getInt(0)+1);
}
/**
* 合并 update操作,可能是针对一个分组内的部分数据,在某个节点上发生的 但是可能一个分组内的数据,会分布在多个节点上处理
* 此时就要用merge操作,将各个节点上分布式拼接好的串,合并起来
* buffer1.getInt(0) : 大聚和的时候 上一次聚合后的值
* buffer2.getInt(0) : 这次计算传入进来的update的结果
* 这里即是:最后在分布式节点完成后需要进行全局级别的Merge操作
*/
@Override
public void merge(MutableAggregationBuffer buffer1, Row buffer2) {
buffer1.update(0, buffer1.getInt(0) + buffer2.getInt(0));
}
/**
* 指定输入字段的字段及类型
*/
@Override
public StructType inputSchema() {
return DataTypes.createStructType(
Arrays.asList(DataTypes.createStructField("name",
DataTypes.StringType, true)));
}
/**
* 初始化一个内部的自己定义的值,在Aggregate之前每组数据的初始化结果
*/
@Override
public void initialize(MutableAggregationBuffer buffer) {
buffer.update(0, 0);
}
/**
* 最后返回一个和DataType的类型要一致的类型,返回UDAF最后的计算结果
*/
@Override
public Object evaluate(Row row) {
return row.getInt(0);
}
@Override
public boolean deterministic() {
//设置为true
return true;
}
/**
* 指定UDAF函数计算后返回的结果类型
*/
@Override
public DataType dataType() {
return DataTypes.IntegerType;
}
/**
* 在进行聚合操作的时候所要处理的数据的结果的类型
*/
@Override
public StructType bufferSchema() {
return
DataTypes.createStructType(
Arrays.asList(DataTypes.createStructField("bf", DataTypes.IntegerType,
true)));
}
});
sqlContext.sql("select name ,StringCount(name) from user group by name").show();
sc.stop();scala:
1.class MyCount extends UserDefinedAggregateFunction{
2. //输入数据的类型
3. override def inputSchema: StructType = StructType(List[StructField](StructField("xx",StringType,true)))
4.
5. //在聚合过程中处理的数据类型
6. override def bufferSchema: StructType = StructType(List[StructField](StructField("xx",IntegerType,true)))
7.
8. //最终返回值的类型,与evaluate返回的值保持一致
9. override def dataType: DataType = IntegerType
10.
11. //多次运行数据是否一致
12. override def deterministic: Boolean = true
13.
14. //每个分区中每组key 对应的初始值
15. override def initialize(buffer: MutableAggregationBuffer): Unit = buffer.update(0,0)
16.
17. //每个分区中,每个分组内进行聚合操作
18. override def update(buffer: MutableAggregationBuffer, input: Row): Unit = {
19. buffer.update(0,buffer.getInt(0) + 1)
20. }
21.
22. //不同的分区中相同的key的数据进行聚合
23. override def merge(buffer1: MutableAggregationBuffer, buffer2: Row): Unit = {
24. buffer1.update(0,buffer1.getInt(0)+buffer2.getInt(0))
25. }
26.
27. //聚合之后,每个分组最终返回的值,类型要和dataType 一致
28. override def evaluate(buffer: Row): Any = buffer.getInt(0)
29.}
30.
31.object Test {
32. def main(args: Array[String]): Unit = {
33. val session = SparkSession.builder().appName("jsonData").master("local").getOrCreate()
34. val list = List[String]("zhangsan","lisi","wangwu","zhangsan","lisi","zhangsan")
35.
36. import session.implicits._
37. val frame = list.toDF("name")
38. frame.createTempView("mytable")
39.
40. session.udf.register("MyCount",new MyCount())
41.
42. val result = session.sql("select name,MyCount(name) from mytable group by name")
43. result.show()
44.
45. }
46.}
47.