中英文混合输出是文本转语音(TTS)项目中很常见的需求场景,尤其在技术文章或者技术视频领域里,其中文文本中一定会夹杂着海量的英文单词,我们当然不希望AI口播只会念中文,Bert-vits2老版本(2.0以下版本)并不支持英文训练和推理,但更新了底模之后,V2.0以上版本支持了中英文混合推理(mix)模式。
还是以霉霉为例子:
https://www.bilibili.com/video/BV1bB4y1R7Nu/
截取霉霉说英文的30秒音频素材片段:

Bert-vits2英文素材处理
首先克隆项目:
git clone https://github.com/v3ucn/Bert-VITS2_V210.git
安装依赖:
pip3 install -r requirements.txt
将音频素材放入Data/meimei_en/raw目录中,这里en代表英文角色。
随后对素材进行切分:
python3 audio_slicer.py
随后对音频进行识别和重新采样:
python3 short_audio_transcribe.py
这里还是使用语音识别模型whisper,默认选择medium模型,如果显存不够可以针对short_audio_transcribe.py文件进行修改:
import whisper
import os
import json
import torchaudio
import argparse
import torch
from config import config
lang2token = {
'zh': "ZH|",
'ja': "JP|",
"en": "EN|",
}
def transcribe_one(audio_path):
# load audio and pad/trim it to fit 30 seconds
audio = whisper.load_audio(audio_path)
audio = whisper.pad_or_trim(audio)
# make log-Mel spectrogram and move to the same device as the model
mel = whisper.log_mel_spectrogram(audio).to(model.device)
# detect the spoken language
_, probs = model.detect_language(mel)
print(f"Detected language: {max(probs, key=probs.get)}")
lang = max(probs, key=probs.get)
# decode the audio
options = whisper.DecodingOptions(beam_size=5)
result = whisper.decode(model, mel, options)
# print the recognized text
print(result.text)
return lang, result.text
if __name__ == "__main__":
parser = argparse.ArgumentParser()
parser.add_argument("--languages", default="CJ")
parser.add_argument("--whisper_size", default="medium")
args = parser.parse_args()
if args.languages == "CJE":
lang2token = {
'zh': "ZH|",
'ja': "JP|",
"en": "EN|",
}
elif args.languages == "CJ":
lang2token = {
'zh': "ZH|",
'ja': "JP|",
}
elif args.languages == "C":
lang2token = {
'zh': "ZH|",
}
识别后的语音文件:
Data\meimei_en\raw/meimei_en/processed_0.wav|meimei_en|EN|But these were songs that didn't make it on the album.
Data\meimei_en\raw/meimei_en/processed_1.wav|meimei_en|EN|because I wanted to save them for the next album. And then it turned out the next album was like a whole different thing. And so they get left behind.
Data\meimei_en\raw/meimei_en/processed_2.wav|meimei_en|EN|and you always think back on these songs, and you're like.
Data\meimei_en\raw/meimei_en/processed_3.wav|meimei_en|EN|What would have happened? I wish people could hear this.
Data\meimei_en\raw/meimei_en/processed_4.wav|meimei_en|EN|but it belongs in that moment in time.
Data\meimei_en\raw/meimei_en/processed_5.wav|meimei_en|EN|So, now that I get to go back and revisit my old work,
Data\meimei_en\raw/meimei_en/processed_6.wav|meimei_en|EN|I've dug up those songs.
Data\meimei_en\raw/meimei_en/processed_7.wav|meimei_en|EN|from the crypt they were in.
Data\meimei_en\raw/meimei_en/processed_8.wav|meimei_en|EN|And I have like, I've reached out to artists that I love and said, do you want to?
Data\meimei_en\raw/meimei_en/processed_9.wav|meimei_en|EN|do you want to sing this with me? You know, Phoebe Bridgers is one of my favorite artists.
可以看到,每个切片都有对应的英文字符。
接着就是标注,以及bert模型文件生成:
python3 preprocess_text.py
python3 emo_gen.py
python3 spec_gen.py
python3 bert_gen.py
运行完毕后,查看英文训练集:
Data\meimei_en\raw/meimei_en/processed_3.wav|meimei_en|EN|What would have happened? I wish people could hear this.|_ w ah t w uh d hh ae V hh ae p ah n d ? ay w ih sh p iy p ah l k uh d hh ih r dh ih s . _|0 0 2 0 0 2 0 0 2 0 0 2 0 1 0 0 0 2 0 2 0 0 2 0 1 0 0 2 0 0 2 0 0 2 0 0 0|1 3 3 3 6 1 1 3 5 3 3 3 1 1
Data\meimei_en\raw/meimei_en/processed_6.wav|meimei_en|EN|I've dug up those songs.|_ ay V d ah g ah p dh ow z s ao ng z . _|0 2 0 0 2 0 2 0 0 2 0 0 2 0 0 0 0|1 1 1 0 3 2 3 4 1 1
Data\meimei_en\raw/meimei_en/processed_5.wav|meimei_en|EN|So, now that I get to go back and revisit my old work,|_ s ow , n aw dh ae t ay g eh t t uw g ow b ae k ae n d r iy V ih z ih t m ay ow l d w er k , _|0 0 2 0 0 2 0 2 0 2 0 2 0 0 2 0 2 0 2 0 2 0 0 0 1 0 2 0 1 0 0 2 2 0 0 0 2 0 0 0|1 2 1 2 3 1 3 2 2 3 3 7 2 3 3 1 1
Data\meimei_en\raw/meimei_en/processed_1.wav|meimei_en|EN|because I wanted to save them for the next album. And then it turned out the next album was like a whole different thing. And so they get left behind.|_ b ih k ao z ay w aa n t ah d t uw s ey V dh eh m f ao r dh ah n eh k s t ae l b ah m . ae n d dh eh n ih t t er n d aw t dh ah n eh k s t ae l b ah m w aa z l ay k ah hh ow l d ih f er ah n t th ih ng . ae n d s ow dh ey g eh t l eh f t b ih hh ay n d . _|0 0 1 0 2 0 2 0 2 0 0 1 0 0 2 0 2 0 0 2 0 0 2 0 0 1 0 2 0 0 0 2 0 0 1 0 0 2 0 0 0 2 0 2 0 0 2 0 0 2 0 0 1 0 2 0 0 0 2 0 0 1 0 0 2 0 0 2 0 1 0 2 0 0 2 0 1 1 0 0 0 2 0 0 2 0 0 0 2 0 2 0 2 0 0 2 0 0 0 1 0 2 0 0 0 0|1 5 1 6 2 3 3 3 2 5 5 1 3 3 2 4 2 2 5 5 3 3 1 3 7 3 1 3 2 2 3 4 6 1 1
Data\meimei_en\raw/meimei_en/processed_2.wav|meimei_en|EN|and you always think back on these songs, and you're like.|_ ae n d y uw ao l w ey z th ih ng k b ae k aa n dh iy z s ao ng z , ae n d y uh r l ay k . _|0 2 0 0 0 2 2 0 0 3 0 0 2 0 0 0 2 0 2 0 0 2 0 0 2 0 0 0 2 0 0 0 2 0 0 2 0 0 0|1 3 2 5 4 3 2 3 4 1 3 1 1 1 3 1 1
至此,英文数据集就处理好了。
Bert-vits2英文模型训练
随后运行训练文件:
python3 train_ms.py
就可以在本地训练英文模型了。
这里需要注意的是,中文模型和英文模型通常需要分别进行训练,换句话说,不能把英文训练集和中文训练集混合着进行训练。
中文和英文在语言结构、词汇和语法等方面存在显著差异。中文采用汉字作为基本单元,而英文使用字母作为基本单元。中文的句子结构和语序也与英文有所不同。因此,中文模型和英文模型在学习语言特征和模式时需要不同的处理方式和模型架构。
中英文文本数据的编码方式不同。中文通常使用Unicode编码,而英文使用ASCII或Unicode编码。这导致了中文和英文文本数据的表示方式存在差异。在混合训练时,中英文文本数据的编码和处理方式需要统一,否则会导致模型训练过程中的不一致性和错误。
所以,Bert-vits2所谓的Mix模式也仅仅指的是推理,而非训练,当然,虽然没法混合数据集进行训练,但是开多进程进行中文和英文模型的并发训练还是可以的。
Bert-vits2中英文模型混合推理
英文模型训练完成后(所谓的训练完成,往往是先跑个50步看看效果),将中文模型也放入Data目录,关于中文模型的训练,请移步:本地训练,立等可取,30秒音频素材复刻霉霉讲中文音色基于Bert-VITS2V2.0.2,囿于篇幅,这里不再赘述。
模型结构如下:
E:\work\Bert-VITS2-v21_demo\Data>tree /f
Folder PATH listing for volume myssd
Volume serial number is 7CE3-15AE
E:.
├───meimei_cn
│ │ config.json
│ │ config.yml
│ │
│ ├───filelists
│ │ cleaned.list
│ │ short_character_anno.list
│ │ train.list
│ │ val.list
│ │
│ ├───models
│ │ G_50.pth
│ │
│ └───raw
│ └───meimei
│ meimei_0.wav
│ meimei_1.wav
│ meimei_2.wav
│ meimei_3.wav
│ meimei_4.wav
│ meimei_5.wav
│ meimei_6.wav
│ meimei_7.wav
│ meimei_8.wav
│ meimei_9.wav
│ processed_0.bert.pt
│ processed_0.emo.npy
│ processed_0.spec.pt
│ processed_0.wav
│ processed_1.bert.pt
│ processed_1.emo.npy
│ processed_1.spec.pt
│ processed_1.wav
│ processed_2.bert.pt
│ processed_2.emo.npy
│ processed_2.spec.pt
│ processed_2.wav
│ processed_3.bert.pt
│ processed_3.emo.npy
│ processed_3.spec.pt
│ processed_3.wav
│ processed_4.bert.pt
│ processed_4.emo.npy
│ processed_4.spec.pt
│ processed_4.wav
│ processed_5.bert.pt
│ processed_5.emo.npy
│ processed_5.spec.pt
│ processed_5.wav
│ processed_6.bert.pt
│ processed_6.emo.npy
│ processed_6.spec.pt
│ processed_6.wav
│ processed_7.bert.pt
│ processed_7.emo.npy
│ processed_7.spec.pt
│ processed_7.wav
│ processed_8.bert.pt
│ processed_8.emo.npy
│ processed_8.spec.pt
│ processed_8.wav
│ processed_9.bert.pt
│ processed_9.emo.npy
│ processed_9.spec.pt
│ processed_9.wav
│
└───meimei_en
│ config.json
│ config.yml
│
├───filelists
│ cleaned.list
│ short_character_anno.list
│ train.list
│ val.list
│
├───models
│ │ DUR_0.pth
│ │ DUR_50.pth
│ │ D_0.pth
│ │ D_50.pth
│ │ events.out.tfevents.1701484053.ly.16484.0
│ │ events.out.tfevents.1701620324.ly.10636.0
│ │ G_0.pth
│ │ G_50.pth
│ │ train.log
│ │
│ └───eval
│ events.out.tfevents.1701484053.ly.16484.1
│ events.out.tfevents.1701620324.ly.10636.1
│
└───raw
└───meimei_en
meimei_en_0.wav
meimei_en_1.wav
meimei_en_2.wav
meimei_en_3.wav
meimei_en_4.wav
meimei_en_5.wav
meimei_en_6.wav
meimei_en_7.wav
meimei_en_8.wav
meimei_en_9.wav
processed_0.bert.pt
processed_0.emo.npy
processed_0.wav
processed_1.bert.pt
processed_1.emo.npy
processed_1.spec.pt
processed_1.wav
processed_2.bert.pt
processed_2.emo.npy
processed_2.spec.pt
processed_2.wav
processed_3.bert.pt
processed_3.emo.npy
processed_3.spec.pt
processed_3.wav
processed_4.bert.pt
processed_4.emo.npy
processed_4.wav
processed_5.bert.pt
processed_5.emo.npy
processed_5.spec.pt
processed_5.wav
processed_6.bert.pt
processed_6.emo.npy
processed_6.spec.pt
processed_6.wav
processed_7.bert.pt
processed_7.emo.npy
processed_7.wav
processed_8.bert.pt
processed_8.emo.npy
processed_8.wav
processed_9.bert.pt
processed_9.emo.npy
processed_9.wav
这里meimei_cn代表中文角色模型,meimei_en代表英文角色模型,分别都只训练了50步。
启动推理服务:
python3 webui.py
访问http://127.0.0.1:7860/,在文本框中输入:
[meimei_cn]<zh>但这些歌曲没进入专辑因为想留着他们下一张专辑用,然後下一張專輯完全不同所以他們被拋在了後面
[meimei_en]<en>But these were songs that didn't make it on the album.
because I wanted to save them for the next album. And then it turned out the next album was like a whole different thing. And so they get left behind.
随后将语言设置为mix。
这里通过[角色]和<语言>对文本进行标识,让系统选择对应的中文或者英文模型进行并发推理:
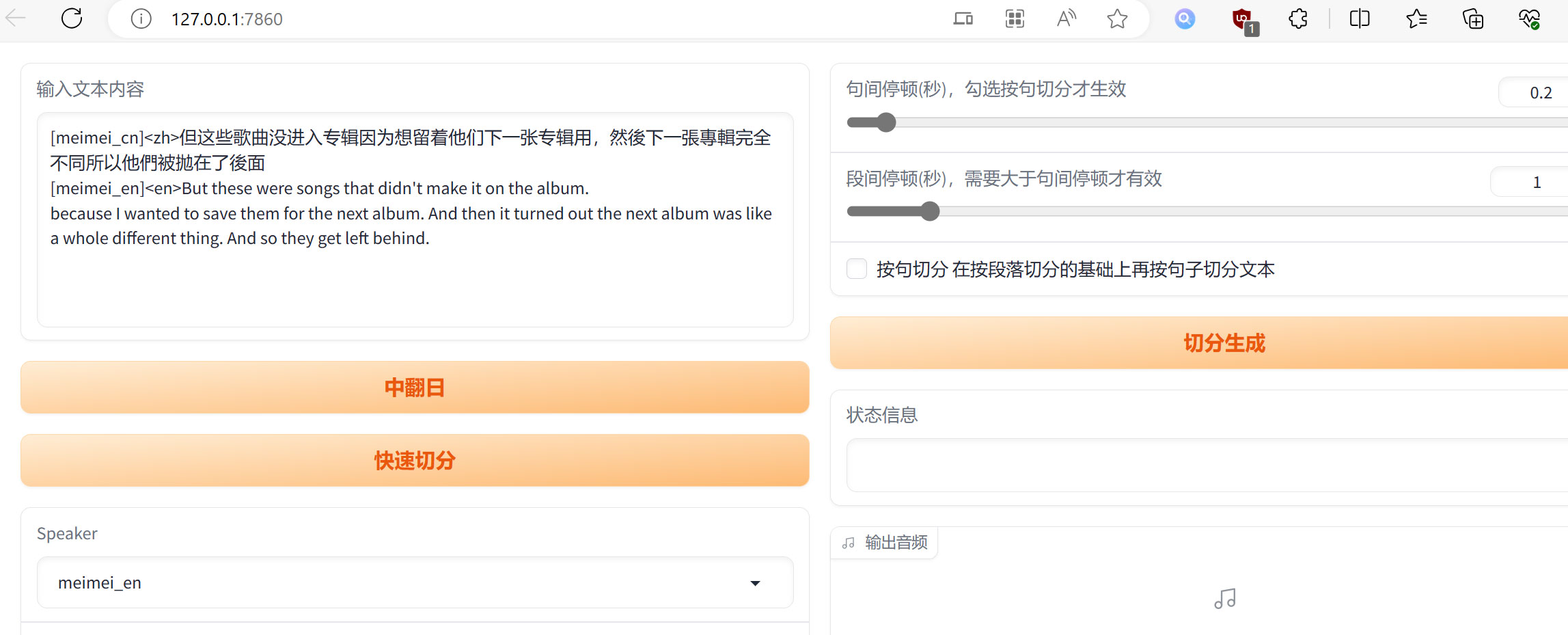
如果本地只有一个英文模型和一个中文模型,也可以选择auto模型,进行自动中英文混合推理:
但这些歌曲没进入专辑因为想留着他们下一张专辑用,然後下一張專輯完全不同所以他們被拋在了後面
But these were songs that didn't make it on the album.
because I wanted to save them for the next album. And then it turned out the next album was like a whole different thing. And so they get left behind.
系统会自动侦测文本语言从而选择对应模型进行推理。
结语
在技术文章翻译转口播或者视频、跨语言信息检索等任务中需要处理中英文之间的转换和对齐,通过Bert-vits2中英文混合推理,可以更有效地处理这些任务,并提供更准确和连贯的结果,Bert-vits2中英文混合推理整合包地址如下:
https://pan.baidu.com/s/1iaC7f1GPXevDrDMCRCs8uQ?pwd=v3uc