结构体是一些值的集合,这些值就是成员变量,这些变量可以是不同类型的。
当我们存放一个学生的信息是,包括性别,姓名,学号,年龄等内容,这些值是不同类型的,这是我们就可以使用结构体来存放这个学生的信息。
文章目录
- 结构体的创建和初始化
- 结构体的自引用
- 结构体内存对齐
- 结构体传参
结构体的创建和初始化
struct stu {
char name[20];
int age;
char sex[5];
char id[20];
};
这就是一个用来存放学生信息的结构体的创建。
struct stu {
char name[20];
int age;
char sex[5];
char id[20];
};
int main() {
struct stu s1 = {"zhangsna", 20, "nan", "2022010202"};
struct stu s2 = {"liis", 21, "nv", "2022010203"};
printf("%s", s2.id);
return 0;
}
结构体的初始化可以是上述代码中的方式。
s2.id就是取出第二个学生的学号,
.和-> 是结构体中的两个操作符。
. 操作符用来查找结构体中的成员变量
打印结构体中的一个成员 s1.a 就是结构体中的字符变量
.操作符结构成员访问操作符,左面是结构体变量,右面是结构体成员名
结构体指针
struct stu ps=&s1
ps->a
就是找到成员变量a
结构体的自引用
在结构中包含⼀个类型为该结构本⾝的成员是否可以呢?
看下面的代码
struct Node
{
int date;
struct Node next;
};
看这个结构体,那么,你来试着计算一下这个结构体的大小,
显然,这样的结构i体是不正确的,它的大小会无穷大。
自引用是我们应该使用指针,
正确的自引用
struct Node
{
int date;
struct Node *next;
};
这可以在之后的链表中用到,通过指针找到下一个date。
结构体内存对齐
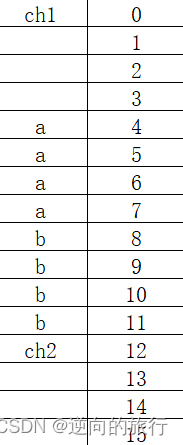
我们先来看看结构体大小,
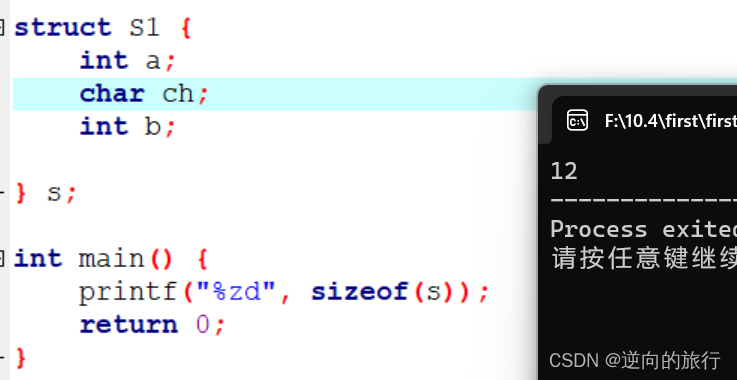
这里的s是一个定义的全局变量,
看计算结果是12,这是为什么呢,
这就要了解一下结构体内存的对齐规则吧,来探讨一下为什么是12.
- 结构体的第⼀个成员对⻬到和结构体变量起始位置偏移量为0的地址处
- 其他成员变量要对⻬到某个数字(对⻬数)的整数倍的地址处。
对⻬数 = 编译器默认的⼀个对⻬数 与 该成员变量⼤⼩的较⼩值。
VS 中默认的值为 8
Linux中 gcc 没有默认对⻬数,对⻬数就是成员⾃⾝的⼤⼩ - 结构体总⼤⼩为最⼤对⻬数(结构体中每个成员变量都有⼀个对⻬数,所有对⻬数中最⼤的)的
整数倍。 - 如果嵌套了结构体的情况,嵌套的结构体成员对⻬到⾃⼰的成员中最⼤对⻬数的整数倍处,结构
体的整体⼤⼩就是所有最⼤对⻬数(含嵌套结构体中成员的对⻬数)的整数倍。

右边对应偏移量
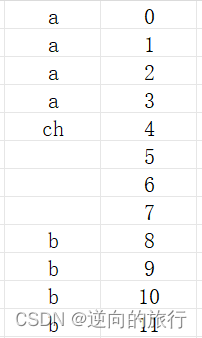
所以这个结构体的大小为12。
接着,我们来看几个例子来更好的理解结构体的对其规则。


内存对齐的原因
数据结构(尤其是栈)应该尽可能地在⾃然边界上对⻬。原因在于,为了访问未对⻬的内存,处理器需要
作两次内存访问;⽽对⻬的内存访问仅需要⼀次访问。假设⼀个处理器总是从内存中取8个字节,则地
址必须是8的倍数。如果我们能保证将所有的double类型的数据的地址都对⻬成8的倍数,那么就可以
⽤⼀个内存操作来读或者写值了。否则,我们可能需要执⾏两次内存访问,因为对象可能被分放在两
个8字节内存块中。
简单来说结构体对齐虽然使内存上存在浪费,但是这也提高了程序的速度,就是以空间来换时间
在创建结构体时也要巧妙利用成员顺序来节省空间

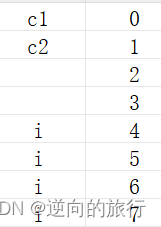
sizeof(S1)=8
sizeof(S2)=12
像S1,让占⽤空间⼩的成员尽量集中在⼀起
结构体传参
struct S {
int data[1000];
int num;
};
struct S s = {{1, 2, 3, 4}, 1000};
//结构体传参
void print1(struct S s) {
printf("%d\n", s.num);
}
//结构体地址传参
void print2(struct S *ps) {
printf("%d\n", ps->num);
}
int main() {
print1(s);
print2(&s);
return 0;
}
这是结构体传参的两种方式,
结构体传参的时候,要传结构体的地址。
函数传参的时候,参数是需要压栈,会有时间和空间上的系统开销。
如果传递⼀个结构体对象的时候,结构体过⼤,参数压栈的的系统开销⽐较⼤,所以会导致性能的下降。
就到这里。
有错误请指出,感谢观看





![[python库] mistune库的基本使用](https://img-blog.csdnimg.cn/direct/c0a5a7a0d9c94e67bb36e8d051fc6db2.png#pic_center)






![[java学习日记]反射、动态代理](https://img-blog.csdnimg.cn/direct/ce9f34e6562d4f1886a770eee93ade85.png)