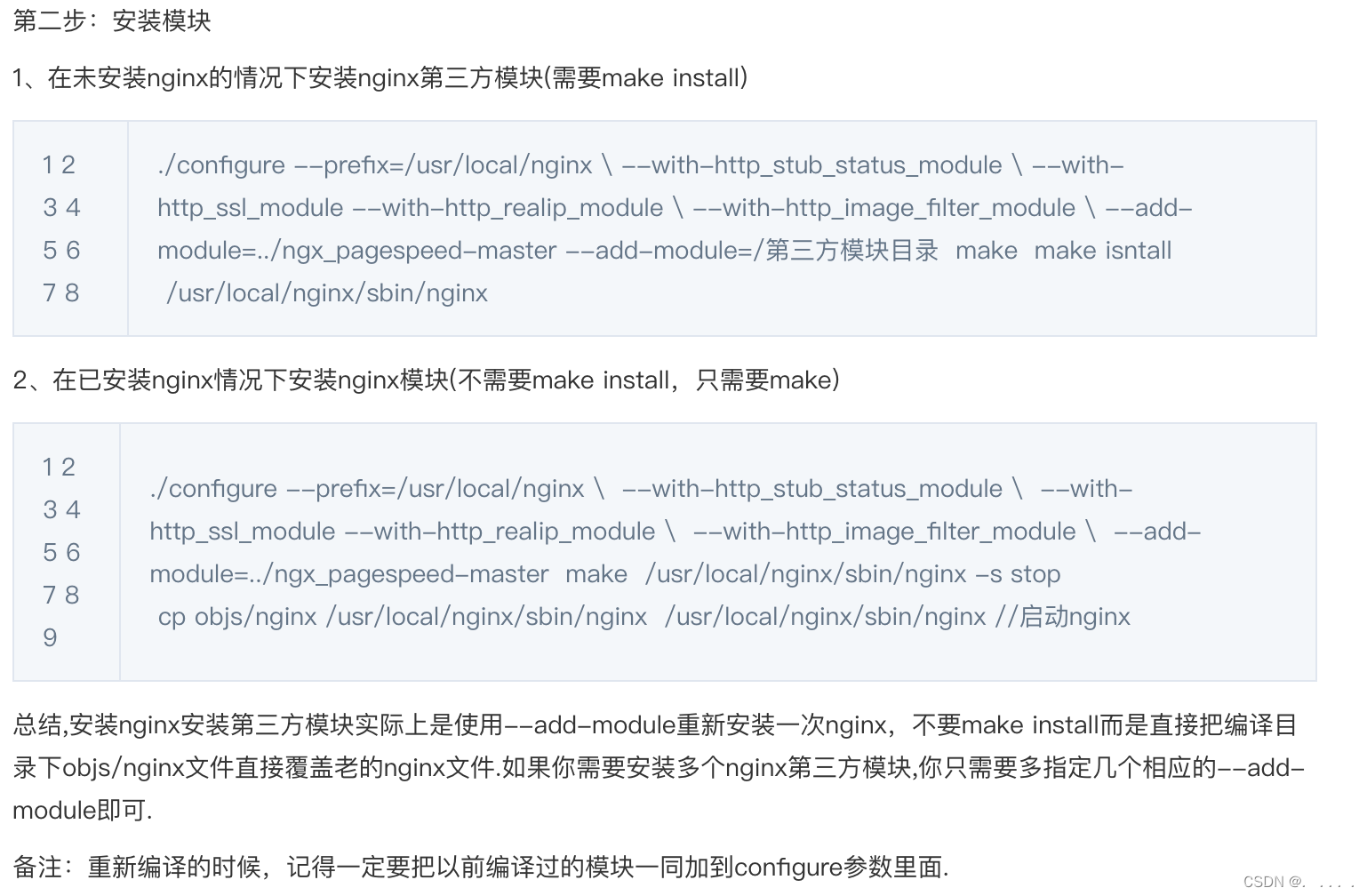
Google为MySQL和InnoDB设计了一个大规模补丁集以量身打造服务器和存储引擎。其中一个修补程序可用于MySQL5.0版本,是半同步的复制补丁。MySQL已经打上了该补丁并在MySQL5.5中发布了。
半同步复制的理念是在允许更改操作继续执行前,确保更改操作至少被写入一个Slave 的磁盘。这意味着对于每一个连接,最多只有一个事务会由于Master崩溃而丢失。
重要的是要明白半同步复制补丁没有暂停提交事务,它只是在事务已被写入到至少一个Slave的中继日志中之前,避免发送一个答复给客户端。图4-7显示了在提交事务时发出的指令顺序。如你所见,在事务发送到Slave之前,它被提交到存储引擎,但只有当Slave 被告知事务已经在持久存储中之后,客户端的提交指令才会返回。
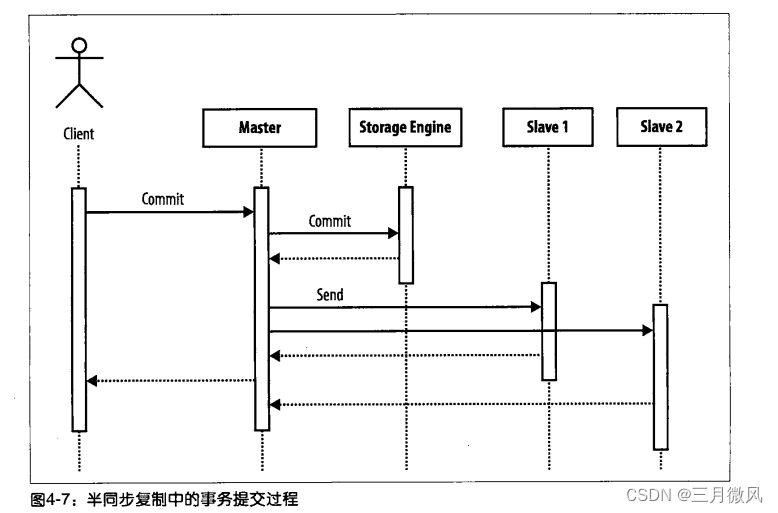
这意味着,在事务被提交给存储引擎之后但还没提交给Slave之前,如果发生系统崩溃,则每个连接都有可能丢失一个事务。然而,由于事务是在已被提交到的Slave后再被确认已提交给客户端的,因此最多只会丢失一个事务。
这通常意味着,每个客户端最多有一个事务丢失,但如果客户端同时和Master有多个连接,这时客户端同时提交多个事务,并且服务器崩溃,那么每个连接就会丢失一个事务。
配置半同步复制
要使用半同步复制,Master和Slave都需要能支持它,所以无论是Master和Slave必须运行MySQL5.5或更高版本,并且启用半同步复制机制。如果Master或Slave不支持半同步复制,它不会被使用,但复制可以正常工作,通常这意味着多个事务可能丢失,除非有特殊的预防措施可以确保新的事务开始前每一个事务都能到达Slave。
使用以下步骤启用半同步复制:
- 在Master上安装Master插件:
master> INSTALL PLUGIN rpl_semi_synC_master SONAME 'semisync_master.so';
- 在每台Slave上安装Slave插件:
slave> INSTALL PLUGIN rpl_semi_sync_slave SONAME 'semisync_slave.so';
- 一旦你已经安装了这些插件,在Master和Slave上启用这些插件。这是通过两个服务器变量控制的,同时作为选项可供选择。为了确保即使重新启动,设置也能生效,最好减少服务器,并且把选项添加到Master的my.cnf文件中:
[mysqld]
rpl-semi-sync-master-enabled=1
从Slave中启用:
[mysqld]
rpl-semi-sync-slave-enabled=1
- 重启服务器。
如果按照刚才的指示做了,现在就有了一个半同步复制setup,并可以对它进行测试,但是需要考虑以下情况。
-
如果所有的Slave崩溃怎么办?如果你只有一个服务器(这不是不可能的),从而没有一个Slave确认它已将事务存储到中继日志中,这时会发生什么?
-
如果所有的Slave断开怎么办?在这种情况下,没有Slave可供Master出于安全保护而发送事务。
除了 rpl-semi-sync-master-enabled和 rpl-semi-sync-slave-enabled,还有两个选项可以处理以上情况:
- rpl-semi-sync-master-timeout=milliseconds
为了防止半同步复制在没有收到确认的情况下发生堵塞,可以使用rpl-semi-sync-mastertimeout=milliseconds 选项设置一个计时器。
如果Master在超时之前没有收到任何确认,将恢复到正常异步复制,并继续执行没有半同步复制的操作。此选项可作为服务器变量,并在没有减少服务器的情况下被设置。但是请注意,作为每一个服务器变量,这个值在重启服务器后将不被保存。
- rpl-semi-sync-master-wait-no-slave={ON|OFF}
如果一个事务被提交,但Master没有任何Slave连接,这时Master不可能将事务发送到其他地方保护起来。默认情况下,Master会在时间限制范围内继续等待Slave 的连接,并确认该事务已被正确写入到磁盘上。
可以使用rpl-semi-sync-master-wait-no-slave={0N|OFF}选项关闭这种行为,在这种情况下,如果没有Slave连接,Master会恢复到异步复制。
监控半同步复制
这两个插件都安装了大量的状态变量,可以利用这些变量来监控半同步复制。这里将介绍最有用的一些变量。要获取完整的列表信息,请查阅半同步复制在线参考手册(http∶//dev.mysql.com/doc/refman/5.5/en/replication-semisync-interface.html)。
- rpl_semi_sync_master_clients
此状态变量报告了支持和注册半同步复制的已连接的Slave数量。 - rpl_semi_sync_master_status
Master的半同步复制状态,1是活动状态,0是非活动状态——要么是因为它没有被启用,或是因为它已恢复到异步复制。 - rpl_semi_sync_slave_status
Slave上的半同步复制状态,如果是1,也就是说它已被启用,且I/O线程正在运行,如果是0,就是处于非活动状态。
可以使用SHOW STATUS命令或通过信息模式表GLOBALSTATUS来阅读这些变量。如果一样把这些值用于其他用途,SHOW STATUS命令是很难使用的,且正如示例4-5中显示的查询,它使用信息模式中的SELECT提取信息并将这个信息存储在一个用户定义的变量中。

Slave的提升
如果你有一个可运行的Master,并且可以在切换Master之前,使用Master同步备份服务器和Slave,这时程序可以很好地运行,但当Master突然死机时会发生什么?由于复制已在所有的Slave(包括备用)上停止,它将无法运行复制,充其量只能获取所有必要的更改,并将与新Master同步。
如果备用服务器超前于所有需要重新分配的 Slave,这是没问题的,因为每个Slave都可以从备用服务器停止复制的地方开始复制。你将丢失所有在Master上执行过的、但尚未被发送到备用服务器的更改。我们将单独讨论在这种情况下如何处理Master的恢复。
如果备用服务器滞后于Slave中的一个,不应该使用备用服务器作为新的Master,因为Slave比备用服务器的数据更多,事实上,使用“数据更多的”Slave替换Master将更好,因为Slave复制了原Master的大部分事件。
这正是使用提升Slave来处理Master故障的方法∶不是试图保持一个专门的备用,而是确保任何一个连接到Master的Slave能够在Master发生故障的时候被提升为Master。通过选择“最可信任的”的Slave作为新的Master,确保其他的Slave都不会比新Master 更可信,这样它们就可以连接到新的Master,并从新Master上读取事件。
然而,还有一个关键的问题需要解决——Slave与新的Master的同步问题,以确保没有任何事件丢失或重复。在这种情况下出现的问题是∶所有的Slave都需要读取来自于新Master的事件,但是新Master和老Master的位置不同。那么,一个不专业的数据库管理员能够做什么?
提升Slave的传统方法
在得出最终解决方案之前,让我们先来看看处理Slave提升的推荐做法,这个方法将可以很好地介绍这个问题,也使我们能够精确定位需要处理棘手问题的最终解决方案。
图4-8显示了一个典型的Master和多个Slave的格局。
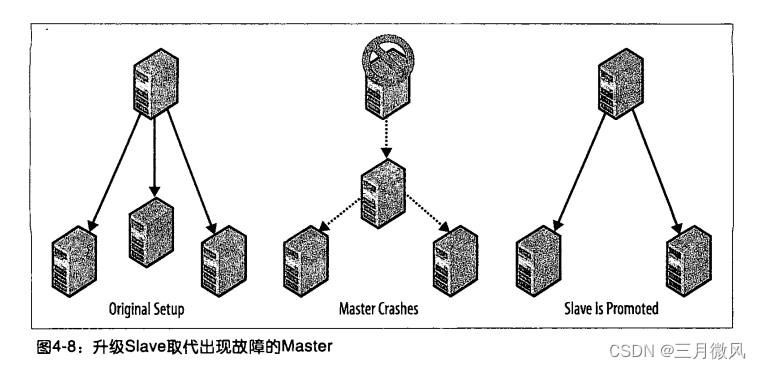
在传统的Slave提升方式中,必须实施下列各项:
- 每个可提升的Slave必须有一个复制用户的账户。
- 每个可提升的Slave必须在运行时启用–log-bin选项,也就是说,需要激活二进制日志。
- 每个可提升的服务器必须在运行时不启用–Log-Slave-updates选项(其原因将会在短期内变得显而易见)。
假设你启用了如图4-8所示的原始安装系统,而Master发生故障,可以通过如下步骤将一个Slave提升为新的Master:
1.使用STOP SLAVE停止Slave。
2.使用RESET MASTER重新设置即将成为新Master的Slave。这将确保Slave作为一个新Master开始被启用,而任何连接的Slave将开始从新Master中读取事件。
3.使用CHANGE MASTER TO将其他的Slave连接到新的Master上。由于重新设置了新的Master,可以从二进制日志的起点开始复制,因此没有必要给CHANGE MASTER TO提供任何位置信息。
不幸的是,这个方法是基于一个通常不真实的假设——Slave已经接收到Master上产生的所有改变。在一个典型的格局中,Slave将在不同程度上落后于Master。可能只是少数事务滞后,但尽管如此,它们还是落后了。无论如何,这种方法非常简单,如果你能处理丢失的事务或者你是在低负荷下运行的,那么这是有用的。
Slave提升的修订方法
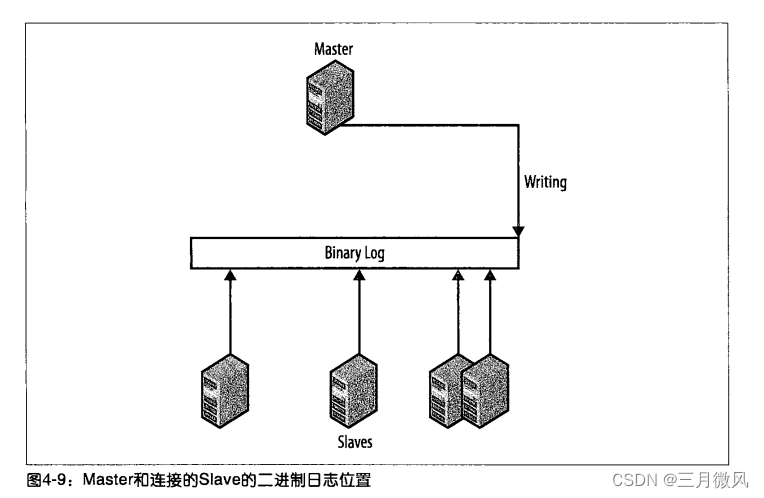
Slave提升的传统方法在大多数情况下是不够用的,因为Slave往往落后于Master。图4-9说明了当Master出乎意料地消失时的典型情况。中间标有“二进制日志”的框是Master的二进制日志,每个箭头代表Slave执行了多少二进制日志。
在这个图中,每个Slave都停止在不同的binlog位置。为解决这个问题并将系统重新联机,一个Slave必须被选为新的Master(最好是有最近binlog位置的那个)且其他的Slave都必须与新Master同步。
关键问题在于将每个Slave的位置转换(在已宕机Master中的位置)到被提升的Slave上的位置。遗憾的是,已经执行的事件的历史记录及它们对应在Slave上的binlog位置在复制过程中丢失了——每次Slave执行来自于Master的事件,它都写一个新事件到二进制日志中,伴随一个新的binlog位置。对于同样的事件,Slave的位置与Master的二进制位置毫无关系。对于我们来说唯一的选择仍然是扫描被提升的Slave的二进制日志。使用下面的技术:
- 启用二进制日志;否则,没有更改可以被复制。
- 启用记录 Slave的更新(使用Log-slave-updates 选项);否则,从原来的 Master上来的更改不会被转送。
- 每个Slave需要有一个复制用户来担当Master,因此如果它成为新Master的最佳候选,其他Slave可以连接到它,并从中复制事件。对没有被提升的每个Slave执行以下步骤:
- 弄明白它执行的最后一个事务。
- 找出被提升的Slave的二进制日志中的事务。
- 从被提升的Slave上取得事务的binlog位置。
- 未被提升的Slave从被提升的Slave上的位置开始复制。
为了将每个Slave上的最新的事务与被提升的Slave的二进制日志中的事件相对应,需要为每个事务加标签。标签的内容和结构并不重要,无论谁实行该事务,它都需要被唯一标识,因此Master上的每个事务都可以在被提升的Slave的二进制日志中找到。这种类型的标签,称为global transaction ID。
最简单的实现方式是在每个事务的结尾插入一条语句去更新一个特殊的表,并用它来追踪每个Slave在哪里。只需在每个事务提交之前,有一个语句使用唯一标识事件的数字更新表信息。
标签的处理主要有两种方式:
- 扩展应用程序代码来执行必要的语句。
- 调用一个存储过程来执行每个提交并在程序中写标签。
由于第一种方式更容易被接受,这里将演示它。如果你对第二种方式感兴趣,请看后面的“提交事务的存储过程”。
为执行 global transaction ID,我们已经在例4-6中创建了两张表:一张表名叫 Global_Trans_ID用来生成序列号,而另一个表名叫Last_Exec_Trans用来记录global transaction ID。
server ID被加入Last_Exec_Trans的定义中,用来区分在不同服务器上提交的事务。例如,如果在所有Slave设法连接上之前,被提升的Slave发生故障,这时区分原始Master的事务ID和被提升的Slave的事务ID是很重要的。否则,当重定向到第二个被提升的Slave时,没有设法连接上被提升的Slave的Slave将从一个错误的位置开始执行。这个例子使用MyISAM来定义计数器表,但用InnoDB也可以做到。
例4-6∶用来生成和跟踪global transaction ID的表
CREATE TABLE GLobal_Trans_ID(
number INT UNSIGNED AUTO INCREMENT PRIMARY KEY
)ENGINE = MyISAM;
CREATE TABLE Last_Exec_Trans (
server_id INT UNSIGNED, trans_id INT UNSIGNED
)ENGINE = InnoDB;
-- Insert a single row with NULLs to be updated.
INSERT INTO Last Exec Trans()VALUES();
下一步是建立一个程序来将global transaction ID添加到二进制日志中,因此提升Slave 的程序可以从日志中读取ID。下面的程序适用于我们的目的。
-
在事务计数表中插入一条数据,并确保在这之前关闭二进制日志,因为插入不会被复制到Slave上。

-
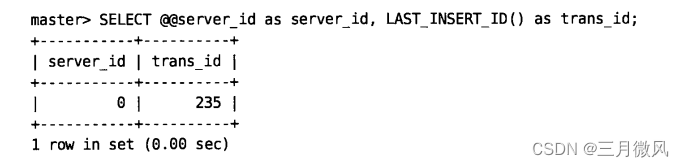
使用函数LAST_INSERT_ID来获得global transaction ID。为简化这个逻辑,同时从
服务器变量server_id获取server ID。
-
在插入 global transaction ID到Last_Exec_Trans 跟踪表之前,可以从计数表删除这一行以节约空间。这个可选步骤只适用于MyISAM表。如果你使用InnoDB,必须小心把最后使用的global transaction ID留在表中。InnoDB是根据表中当前存在的自增字段的最大数值来确定下一个数字的。
master> DELETE FROM GLobal_Trans_ID WHERE number < 235;
Query OK,1 row affected(0.00 sec)
- 打开二进制日志
master> SET SQL_LOG_BIN = 1;
Query OK, O rows affected(0.00 sec)
- 用你在第2步得到的server ID和transaction ID去更新Last_Exec_Trans追踪表。这是通过COMMIT提交事务前的最后一个步骤。
master> UPDATE Last Exec_Trans SET server_id = θ,trans_id = 235;
Query OK,1 row affected(0.00 sec)
master> COMMIT;
Query OK, 0 rows affected(0.00 sec)
每个global transaction ID代表复制可以重新开始的那个点。因此,你必须为每个事务执行这个程序。如果某个事务不使用它,该事务将不会被正确地标上标签,也将不可能从这个位置开始复制。
现在、为了在Master发生故障后将一个Slave提升为新Master,必须从所有Slave中找到那个有最近更改的Slave(也就是说,有最大的binlog位置)并将这个Slave提升为Master。然后让每个其他的Slave连接到它。
为了连接到被提升的Slave的Slave在正确的位置开始复制,必须找到被提升的Slave 上最后执行的事务的位置。扫描被提升的Slave上的二进制日志,从而找到正确的transaction ID。
使用下面的步骤来执行恢复:
-
停止Slave。从它的Last_Exec_Trans表中获得最后global transaction ID。
-
选取有最高的global transaction ID的Slave,将其升级为Master。如果有多个,挑选一个。
-
使用SHOW MASTER LOGS,得到将要被提升的的Slave的Master位置,同时得到Slave的二进制日志。请注意,SHOW MASTER LOGS的最后一行与你在 SHOW MASTER STATUS中看到的是相当的。
-
使被提升的Slave联机,并让其开始接受更新。
-
连接到被提升的Slave,然后扫描二进制日志,找到你在每个Slave的二进制日志中找到的最新的global transaction ID。除非你找到一个已知是合适的文件位置,否则对于读取二进制日志来说,唯一合适的开始位置就是起点。因此,你必须从最后一个开始以反序扫描二进制日志。这个步骤将为你在步骤1中收集的每个 global transaction ID提供被提升的Slave上的二进制日志位置。
-
重新连接每个Slave到被提升的Slave,在Slave上为恢复所有信息而需要开始的位置开始复制,并使用步骤5的信息。
前面的4步是简单的,而第5步则有点复杂。为说明情况,让我们看一个例子。这个例子从前面三步收集基本信息。表4-2列出三个带有 global transaction ID的样本 Slave。

如表4-2所示,Slave-3有最后的Global transaction ID,因此有必要将每个Slave的global transaction ID转换为Slave-3的二进制日志位置,这样,我们就需要Slave-3上的二进制日志的信息,这些信息我们将在例4-7中得到。
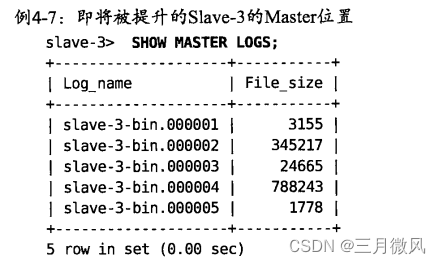
从 SHOW MASTER LOGS的输出中所要知道的重要的信息就是日志的名字,因此你可以为global transaction ID 而扫描它们。例如,当用mysqlbinlog读取Slave-3-bin.00005文件时,部分输出如例4-8所示。Slave-3收到的从位置596开始的事务(在输出的第一行中高亮显示)有Slave-1接收的global transaction ID,正如对Last_Exec_Trans表的一个UPDATE所示。

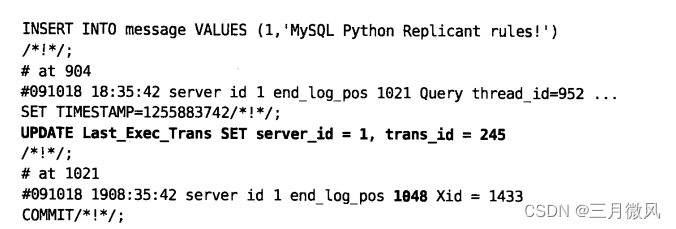
表4-2显示了trans_id 245是Slave-1的最后一个事务,因此现在你知道Slave-1的开始位置是在文件Slave-3-bin.000005的1048字节位置。因此为在正确的位置启动Slave-1,现在可以执行CHANGE MASTER TO和START SLAVE:
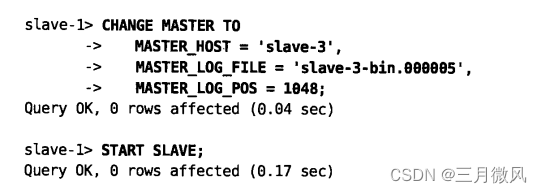
通过这种方式追溯(定位在程序中你第一步记录的每个事务)你可以一个接一个地连接Slave到新的Master的正确位置。
如果update语句被添加进每个事务的提交,该技术将会很有效。遗憾的是,在语句提交之前和之后都有一些语句执行了隐式的提交。典型的例子包括CREATE TABLE,DROP TABLE,和ALTER TABLE。由于这些语句做了隐式的提交,它们不能被正确地标签,因此不可能恰好在他们之后重启。这意味着,如果例4-9中的一系列语句被执行而同时发生系统崩溃,将可能发生潜在问题。
如果Slave只执行了CREATE TABLE接着丢失了Master,最后看到的 global transaction ID就为INSERT INTO的,也就是说,就在CREATE TABLE语句之前。因此,Slave将试图用INSERT INTO语句的transaction ID重新连接到被提升的Slave。由于它将找到其在被提升的Slave的二进制日志中的位置,因此它将从再次复制CREATE TABLE语句开始,从而导致Slave 因为一个错误而停止。
可以通过小心地使用和设计语句来避免这些问题;例如,如果CREATE TABLE被CREATE TABLE IF NOT EXISTS 语句所取代,Slave 将注意到该表已经存在而跳过执行该语句。




![【WSL】[01] windows subsytem linux 配置和使用 - ubuntu GUI安装](https://img-blog.csdnimg.cn/d92b42e3f789407289d57d08aa2ce5a4.png)